Spring AI(二):入门使用
1. 快速入门
1.1. 什么是Spring AI
Spring AI项目旨在简化包含AI功能的应用程序的开发,避免不必要的复杂度。官方文档:Spring AI Reference
Spring AI干的事,就是将你的应用程序(数据和API)与 大模型连接起来。Connecting your enterprise Data and APIs with AI Models
1.2. 搭建工程并导入依赖
可参考官方文档:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.5</version>
</parent>
<groupId>com.cjc</groupId>
<artifactId>springboot-ai-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring-ai.version>1.0.0-M6</spring-ai.version>
<org.projectlombok.version>1.18.36</org.projectlombok.version>
</properties>
<dependencyManagement>
<dependencies>
<!-- Spring AI BOM -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${org.projectlombok.version}</version>
</dependency>
<!-- Spring AI OpenAI 依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.41</version>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.13.0</version>
<configuration>
<source>17</source> <!-- depending on your project -->
<target>17</target> <!-- depending on your project -->
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
1.3. 编写配置
spring:
application:
name: spring-ai
ai:
openai: #openai配置
base-url: https://api.chatanywhere.tech #api地址
api-key: ****** #api key
chat:
options:
model: gpt-3.5-turbo #模型名称
1.4. 普通聊天
参考官方文档中的示例代码编写:👉 Chat Client API
1.4.1. 构造ChatClient
ChatClient是核心关键点,负责与大模型交互,而得到ChatClient对象是通过ChatClient.Builder构建得到的,并且需要将ChatClient对象放入到Spring容器,方便注入使用。
@Configuration
public class SpringAIConfig {
/**
* 创建并返回一个ChatClient的Spring Bean实例。
* @param builder 用于构建ChatClient实例的构建者对象
* @return 构建好的ChatClient实例
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder.build();
}
}
1.4.2. 编写ChatService
public interface ChatService {
/**
* 普通聊天
* @param question 用户提问
* @return 大模型的回答
*/
String chat(String question);
}
@Slf4j
@Service
public class ChatServiceImpl implements ChatService {
@Autowired
private ChatClient chatClient;
/**
* 与聊天客户端进行交互,发送用户问题并获取响应内容。
* @param question 用户输入的问题内容
* @return 聊天客户端返回的响应内容
*/
@Override
public String chat(String question) {
// 调用聊天客户端处理用户问题并获取响应内容
String content = chatClient.prompt()
.user(question)
.call()
.content();
log.info("question: {}, content: {}", question, content);
return content;
}
}
1.4.3. 编写Controller
@RestController
@RequestMapping("/chat")
public class ChatController {
@Autowired
private ChatService chatService;
@GetMapping("/chat")
public String chat(@RequestParam String prompt) {
return chatService.chat(prompt);
}
}
1.5. 流式聊天
在Spring AI中同样也支持流式聊天(类似打字机效果)的方式与大模型进行对接。
1.5.1. SSE
在大模型的流式聊天模式中,数据是从**服务端推送到客户端(浏览器)**的,这里就需要使用Server-Sent Events(SSE)协议。
核心特点
- 单向通信:仅服务器向客户端发送数据,客户端通过普通 HTTP 请求建立连接后等待推送。
- 基于 HTTP:无需额外协议,兼容现有 HTTP 基础设施(如身份验证、CORS)。
- 自动重连:客户端在连接断开时会自动尝试重新连接,支持自定义重试时间。
- 轻量级:数据格式简单(纯文本流),开销低,适合高频次小数据量场景。
- 事件驱动:支持定义不同事件类型(如
message、error),客户端可按需监听。
服务端返回的数据结构类似这样:
id: chatcmpl-9413905d-aec7-9bcb-b162-a7194e371481
event: text
data: ""
id: chatcmpl-9413905d-aec7-9bcb-b162-a7194e371481
event: text
data: "下面"
id: chatcmpl-9413905d-aec7-9bcb-b162-a7194e371481
event: text
data: "是一个"
id: chatcmpl-9413905d-aec7-9bcb-b162-a7194e371481
event: text
data: "简单的"
id: chatcmpl-9413905d-aec7-9bcb-b162-a7194e371481
event: text
data: " Java `for`"
服务器返回的数据必须遵循 SSE 格式:
- 每个消息以
data:开头,以两个换行符\n\n结束。 - 可选字段:
event(事件类型)、id(消息ID)、retry(重连时间)。
1.5.2. 代码实现
/**
* 处理流式聊天请求,返回服务器发送事件(SSE)格式的响应流
* @param question 用户输入的聊天问题
* @return 包含逐条聊天响应的响应式数据流,通过Server-Sent Events协议传输
*/
@PostMapping(value = "stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> chatStream(@RequestBody String question) {
return chatService.chatStream(question);
}
/**
* 流式聊天
* @param question 用户提问
* @return 大模型的回答
*/
Flux<String> chatStream(String question);
/**
* 处理用户问题并返回流式响应内容
* @param question 用户输入的问题内容
* @return 包含逐条响应内容和结束标记的响应流,每个元素为字符串格式
*/
@Override
public Flux<String> chatStream(String question) {
// 调用聊天客户端生成流式响应内容
return chatClient.prompt()
.user(question)
.stream()
.content()
// 记录每次接收到的响应内容
.doOnNext(content -> log.info("question: {}, content: {}", question, content))
// 在流结束时添加结束标记
.concatWith(Flux.just("[END]"));
}
1.5.3. 响应式编程示例代码
public class ReactorTest {
public static void main(String[] args) {
// 创建 Flux
Flux<String> flux = Flux.just("苹果", "香蕉", "葡萄", "面条") // 创建一个包含四个元素的 Flux
.filter(s -> !s.equals("面条")) // 过滤掉面条元素
.doFirst(() -> System.out.println("开始处理......")) // 在处理开始时打印信息
.doOnNext(s -> System.out.println("当前元素: " + s)) // 在每个元素被处理后打印信息
.map(s -> { // 每个元素进行数据处理
return switch (s) {
case "苹果" -> "苹果是红色的";
case "香蕉" -> "香蕉是黄色的";
case "葡萄" -> "葡萄是紫色的";
default -> "未知水果";
};
})
.doOnComplete(() -> System.out.println("处理完成......")) // 在完成时打印信息
.concatWith(Flux.just("[END]")) // 在最后添加一个元素
;
// 订阅消费
flux.subscribe(s -> System.out.println("消费者: " + s));
}
}
运行结果如下:
开始处理......
当前元素: 苹果
消费者: 苹果是红色的
当前元素: 香蕉
消费者: 香蕉是黄色的
当前元素: 葡萄
消费者: 葡萄是紫色的
处理完成......
消费者: [END]
1.6. 阿里百炼
上述的代码是基于OpenAI进行学习的,如果要切换成阿里百炼平台怎么实现呢?
1.6.1. Spring AI Alibaba
Spring AI Alibaba是阿里团队基于 Spring Al官方开源项目实现,对阿里百炼平台的各种服务进行了支持。
第一步:引入依赖
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter</artifactId>
<version>1.0.0-M6.1</version> <!-- 注意这个版本要与SpringAI版本匹配 -->
</dependency>
第二步:编写配置
spring:
application:
name: spring-ai
ai:
dashscope:
api-key: ********
chat:
options:
model: qwen-plus
openai: #openai配置
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1 #阿里百炼api地址
# base-url: https://api.chatanywhere.tech #api地址
api-key: ******** #阿里百炼 api key
# api-key: ******** #api key
chat:
options:
model: qwen-plus #阿里百炼 模型名称
# model: gpt-3.5-turbo #模型名称
enabled: false #关闭OpenAI配置
注意:若没有设置enabled=false,则会报以下错误。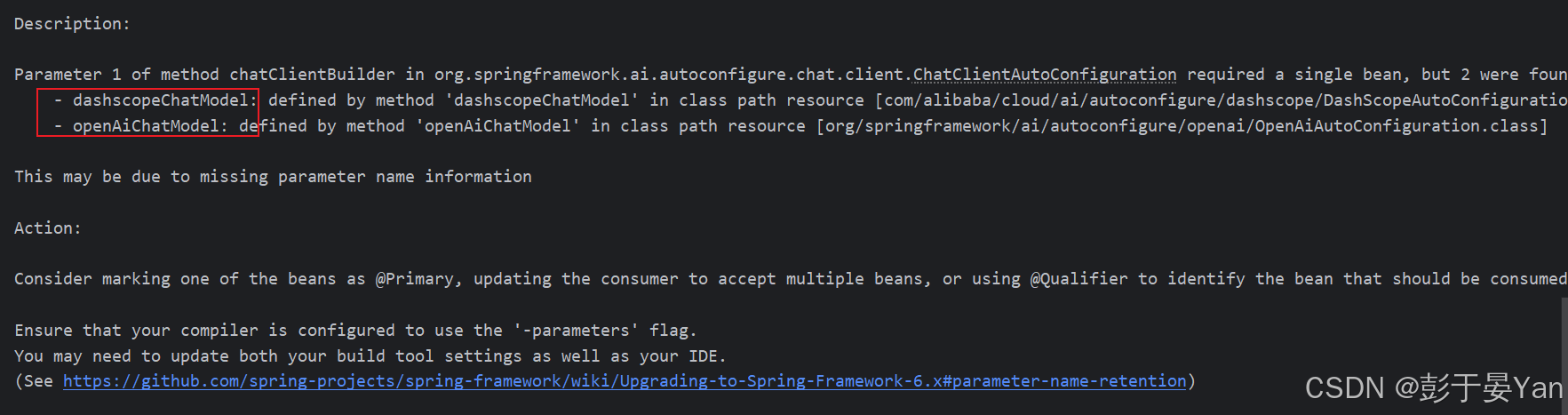
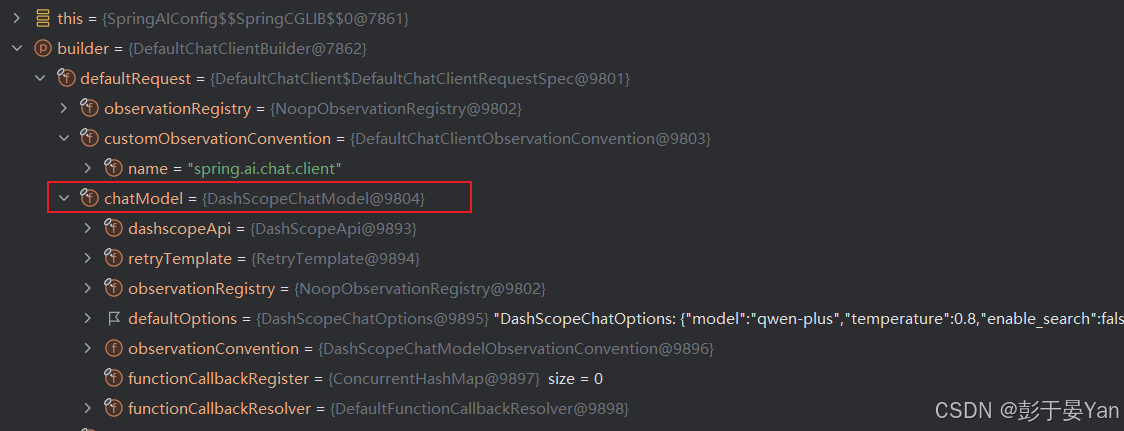
启动服务,在com.cjc.config.SpringAIConfig#chatClient方法中打断点,可以看到,底层的chatModel已经缓存了阿里百炼:
1.6.2. 如何选择
📚 既然有2种方案都可以对接阿里百炼平台,如何选择呢?首选,我们对比下这两种方案的优缺点:
-
方案一:OpenAI接口
- 优点:通用、可以兼容多平台
- 缺点:对于阿里百炼平台的某些功能可能支持不太好,比如:流式聊天中的
tool调用,支持的不好(1.0.0-M6版本)
-
方案二:Spring AI Alibaba
- 优点:由于是阿里团队维护的,所以对于阿里百炼平台的服务支持比较好
- 缺点:只能用于百炼平台的对接,版本更新速度要比SpringAI官方慢一些
所以,如果项目中用到了阿里百炼平台,并且希望得到更好的支持,那就选择Spring AI Alibaba,反之,选择OpenAI接口。
2. System角色设定
对于大模型的System角色设定,有两种方式,一种是局部设定,另一种是默认设定。
创建常量类,编写角色内容:
public interface Constant {
String SYSTEM_ROLE = """
#角色
你是Java开发助手,名字叫小智。
#技能
##技能1:
帮我分析运行bug,并且给我提出解决方案。
##技能2:
给代码生成注释,无需逐行都注释,在关键代码添加注释
""";
}
📚 从 Java 15 开始,Java 引入了 Text Blocks(文本块) 功能,允许使用 “”" 来定义多行字符串,从而简化复杂字符串的编写。
2.1. 局部设定
/**
* 与聊天客户端进行交互,发送用户问题并获取响应内容。
* @param question 用户输入的问题内容
* @return 聊天客户端返回的响应内容
*/
@Override
public String chat(String question) {
// 调用聊天客户端处理用户问题并获取响应内容
String content = this.chatClient.prompt()
.system(Constant.SYSTEM_ROLE) // 设置系统角色
.user(question)
.call()
.content();
log.info("question: {}, content: {}", question, content);
return content;
}
2.2. 默认设定
@Configuration
public class SpringAIConfig {
/**
* 创建并返回一个ChatClient的Spring Bean实例。
* @param builder 用于构建ChatClient实例的构建者对象
* @return 构建好的ChatClient实例
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder
.defaultSystem(Constant.SYSTEM_ROLE) // 设置默认的系统角色
.build();
}
}
2.3. 动态参数
如果问大模型,今天的日期,大模型是不知道的,为了解决这个问题,就可以在系统角色中添加参数,动态的将时间数据加上去。
首先,在系统角色内容中添加占位参数。需要注意,发起请求时并没有给对应的参数值,会报错的。
public interface Constant {
String SYSTEM_ROLE = """
#角色
你是Java开发助手,名字叫小智。
#技能
##技能1:
帮我分析运行bug,并且给我提出解决方案。
##技能2:
给代码生成注释,无需逐行都注释,在关键代码添加注释
当前时间是{now}
""";
}
在发起请求时,设置参数,这里设置的参数要与上述的占位符参数保持一致:
@Override
public String chat(String question) {
// 调用聊天客户端处理用户问题并获取响应内容
String content = this.chatClient.prompt()
// .system(Constant.SYSTEM_ROLE) // 设置系统角色
.system(prompt -> prompt.param("now", DateUtil.now())) // 设置系统角色参数
.user(question)
.call()
.content();
log.info("question: {}, content: {}", question, content);
return content;
}
这里需要引入hutool工具包依赖:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.41</version>
</dependency>
3. Advisors功能增强
Spring AI Advisors提供了一种灵活且强大的方式,可以在 Spring 应用中轻松拦截、调整和增强基于AI的交互操作。通过使用Advisors,可以构建更复杂、可重用且易于维护的AI组件,从而提升应用的功能性和简化开发流程,使项目更加高效和整洁。
3.1. 运行原理
下图展示了,在与大模型交互过程中,Advisors的执行流程:
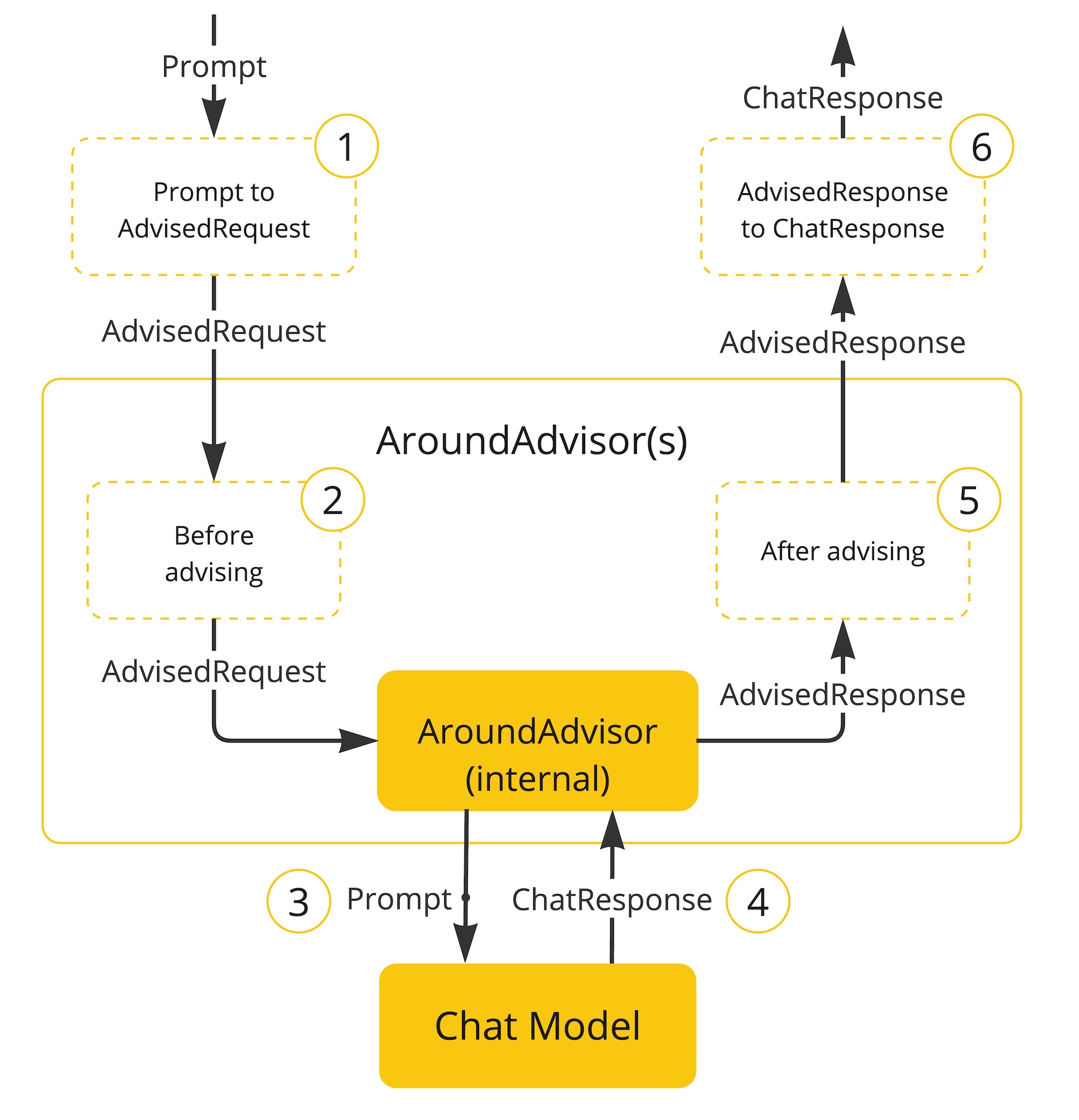
关键流程解析:
-
请求包装阶段(对应步骤①)
- 框架将用户输入的
Prompt封装为AdvisedRequest对象 - 同时创建空的
AdvisorContext上下文容器,用于链式传递处理状态
- 框架将用户输入的
-
Advisor 链预处理(对应步骤②)
- 多个
Advisor按链式顺序处理请求 - 每个
Advisor可以:
▪ 修改请求内容(如添加系统提示词)
▪ 直接拦截请求并生成响应(实现内容审查/快速响应)
- 多个
-
模型调用阶段(对应步骤③)
- 框架内置的最终
Advisor将标准化请求发送至大模型 - 触发
Chat Model完成核心推理
- 框架内置的最终
-
响应处理阶段(对应步骤④-⑥)
- 模型输出通过
AdvisorContext携带上下文原路返回 - 各
Advisor可二次处理响应:
▪ 格式化输出结构
▪ 添加解释性内容
▪ 执行最终安全校验
- 模型输出通过
3.2. 日志Advisor
在Spring AI中,提供了SimpleLoggerAdvisor,它可以记录 request 和 response 数据的Advisor,一般用于调试与AI大模型的交互。
使用也非常简单,先定义SimpleLoggerAdvisor对象,在ChatClient对象中加入即可。
@Configuration
public class SpringAIConfig {
/**
* 创建并返回一个ChatClient的Spring Bean实例。
* @param builder 用于构建ChatClient实例的构建者对象
* @return 构建好的ChatClient实例
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder,
Advisor simpleLoggerAdvisor) {
return builder
.defaultSystem(Constant.SYSTEM_ROLE) // 设置默认的系统角色
.defaultAdvisors(simpleLoggerAdvisor) // 设置默认的Advisor
.build();
}
/**
* 创建并返回一个SimpleLoggerAdvisor的Spring Bean实例。
*/
@Bean
public Advisor simpleLoggerAdvisor() {
return new SimpleLoggerAdvisor();
}
}
在application.yml文件中,添加日志配置:
logging:
level:
org:
springframework:
ai:
chat:
client:
advisor: DEBUG
3.3. 聊天记忆
目前的版本中有三种实现:
-
MessageChatMemoryAdvisor:将历史消息与当前用户消息合并,一起发给大模型
-
PromptChatMemoryAdvisor:将历史消息与系统提示词合并,放到系统提示词中,发给大模型
-
VectorStoreChatMemoryAdvisor:将消息存储到向量数据库中,以实现长期记忆功能
📚 长期记忆和短期记忆的区别:
-
长期记忆:
-
来源:训练阶段学习的知识,存储在模型参数中(如事实、规则)。
-
局限:无法动态更新,存在时效性问题(如无法覆盖新事件)。
-
-
短期记忆:
-
来源:推理时通过上下文(如对话历史)临时保留的信息。
-
局限:受限于上下文窗口长度(如GPT-4最多128k token),会话结束后消失。
-
对于聊天记忆功能,更适合用短期记忆,也就是MessageChatMemoryAdvisor或PromptChatMemoryAdvisor。
❓ 既然MessageChatMemoryAdvisor或PromptChatMemoryAdvisor这两种都能实现,我们该如何选择呢?
记住一个原则,优先使用MessageChatMemoryAdvisor,如果不模型支持,就选择PromptChatMemoryAdvisor,也就是整合到系统提示词中的方案兼容性更好一些,不过,一般的大模型都支持合并到用户消息的方式。
3.3.1. MessageChatMemoryAdvisor
第一步:先配置ChatMemory存储器,SpringAI只提供了基于内存的存储InMemoryChatMemory。
/**
* 创建并返回聊天记忆管理器的Spring Bean(基于内存实现)
* @return InMemoryChatMemory 实例,用于存储聊天上下文信息
*/
@Bean
public ChatMemory chatMemory() {
return new InMemoryChatMemory();
}
第二步:配置MessageChatMemoryAdvisor,需要使用上面配置的存储器。
/**
* 创建并返回聊天记忆管理advisor的Spring Bean
* @param chatMemory 聊天记忆管理器实例
* @return MessageChatMemoryAdvisor 实例,用于在聊天过程中维护上下文
*/
@Bean
public Advisor messageChatMemoryAdvisor(ChatMemory chatMemory) {
return new MessageChatMemoryAdvisor(chatMemory);
}
第三步:添加默认的Advisor
/**
* 创建并返回一个ChatClient的Spring Bean实例。
* @param builder 用于构建ChatClient实例的构建者对象
* @return 构建好的ChatClient实例
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder,
Advisor simpleLoggerAdvisor,
Advisor messageChatMemoryAdvisor
) {
return builder
.defaultSystem(Constant.SYSTEM_ROLE) // 设置默认的系统角色
.defaultAdvisors(simpleLoggerAdvisor, messageChatMemoryAdvisor) // 设置默认的Advisor
.build();
}
📚 注意:
由于是基于内存存储,服务重启后,聊天记录将丢失,所以这种方式不适合用在真实项目中,可选择使用数据库、Redis等方式进行存储。
3.3.2. PromptChatMemoryAdvisor
PromptChatMemoryAdvisor用法与MessageChatMemoryAdvisor基本一样,如下:
/**
* 创建并返回聊天记忆管理advisor的Spring Bean
* @param chatMemory 聊天记忆管理器实例
* @return PromptChatMemoryAdvisor 实例,用于在聊天过程中维护上下文
*/
@Bean
public Advisor promptChatMemoryAdvisor(ChatMemory chatMemory) {
return new PromptChatMemoryAdvisor(chatMemory);
}
配置到ChatClient中:
/**
* 创建并返回一个ChatClient的Spring Bean实例。
* @param builder 用于构建ChatClient实例的构建者对象
* @return 构建好的ChatClient实例
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder,
Advisor simpleLoggerAdvisor,
Advisor messageChatMemoryAdvisor,
Advisor promptChatMemoryAdvisor
) {
return builder
.defaultSystem(Constant.SYSTEM_ROLE) // 设置默认的系统角色
.defaultAdvisors(simpleLoggerAdvisor, promptChatMemoryAdvisor) // 设置默认的Advisor
.build();
}
3.3.3. 原理分析
前面使用InMemoryChatMemory进行了会话数据的存储,那他底层如何存储的呢?下面我们看一下他的底层源码:
package org.springframework.ai.chat.memory;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import org.springframework.ai.chat.messages.Message;
/**
* The InMemoryChatMemory class is an implementation of the ChatMemory interface that
* represents an in-memory storage for chat conversation history.
*
* This class stores the conversation history in a ConcurrentHashMap, where the keys are
* the conversation IDs and the values are lists of messages representing the conversation
* history.
*
* @see ChatMemory
* @author Christian Tzolov
* @since 1.0.0 M1
*/
public class InMemoryChatMemory implements ChatMemory {
Map<String, List<Message>> conversationHistory = new ConcurrentHashMap<>();
@Override
public void add(String conversationId, List<Message> messages) {
this.conversationHistory.putIfAbsent(conversationId, new ArrayList<>());
this.conversationHistory.get(conversationId).addAll(messages);
}
@Override
public List<Message> get(String conversationId, int lastN) {
List<Message> all = this.conversationHistory.get(conversationId);
return all != null ? all.stream().skip(Math.max(0, all.size() - lastN)).toList() : List.of();
}
@Override
public void clear(String conversationId) {
this.conversationHistory.remove(conversationId);
}
}
可以看到,底层是通过Map进行存储的,那究竟存了什么数据?我们通过debug的方式进行查看:
查看内存中的对象:SpringUtil.getBean("chatMemory"),SpringUtil是hutool工具包中的工具类。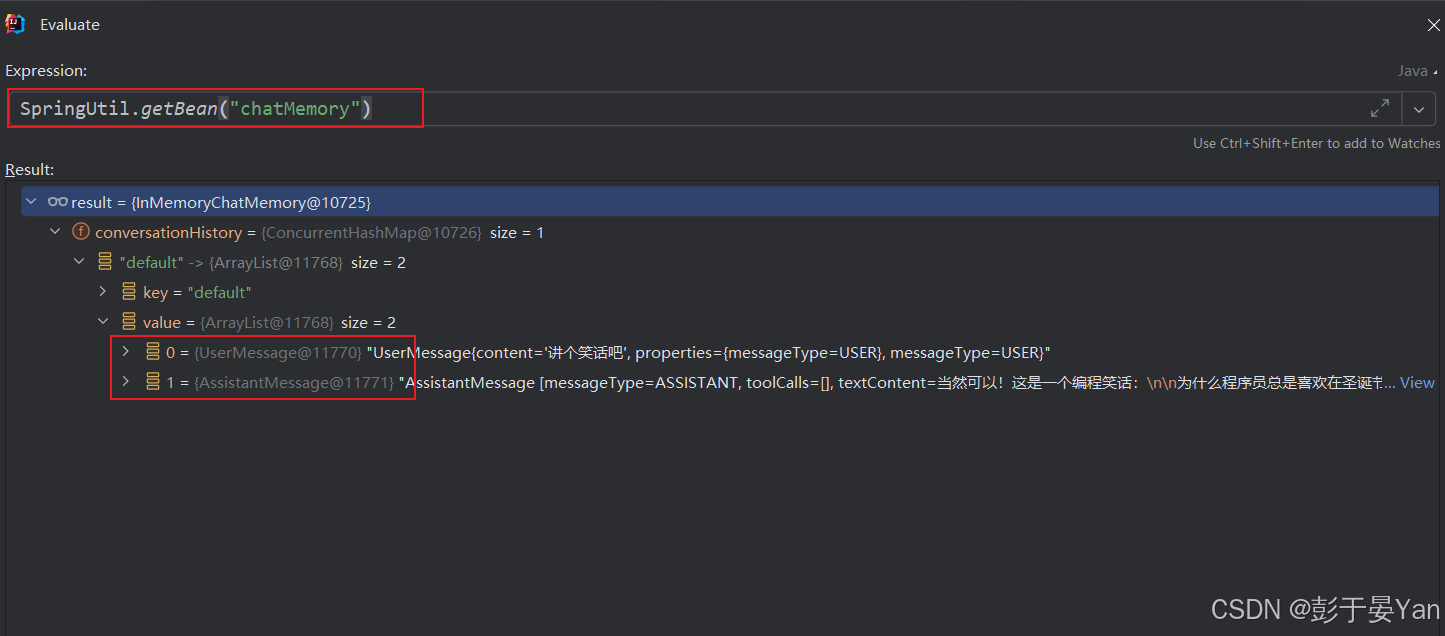
📚 其中,UserMessage是用户输入的内容,AssistantMessage是大模型回复的内容。
那么,现在问题来了,key的值是default,也就是每次对话,都是default,这显然是不合理的,我想创建新的对话怎么办?类型这样的:
所以,这个key的值不可能是固定的,需要根据不同的对话,设置对应的会话id。
3.3.4. 会话id
在Spring AI中也是可以指定会话id的,而这个id虽然不能固定,但是也不能每次都变化,所以需要另外一套业务逻辑来维护这个会话,现在我们暂时不讨论这个会话管理,我们先改造成传入参数的方式来实现。
第一步:定义ChatDTO,里面有2个属性,question、sessionId:
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ChatDTO {
/**
* 用户的问题
*/
private String question;
/**
* 会话id
*/
private String sessionId;
}
第二步:改造ChatController中的对话方法,用对象接收参数:
@RestController
@RequestMapping("/chat")
public class ChatController {
@Autowired
private ChatService chatService;
@PostMapping
public String chat(@RequestBody ChatDTO chatDTO) {
return chatService.chat(chatDTO.getQuestion(), chatDTO.getSessionId());
}
/**
* 处理流式聊天请求,返回服务器发送事件(SSE)格式的响应流
* @param chatDTO 用户输入的聊天问题
* @return 包含逐条聊天响应的响应式数据流,通过Server-Sent Events协议传输
*/
@PostMapping(value = "stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> chatStream(@RequestBody ChatDTO chatDTO) {
return chatService.chatStream(chatDTO.getQuestion(), chatDTO.getSessionId());
}
}
第三步:修改ChatService接口,增加sessionId参数:
public interface ChatService {
/**
* 普通聊天
* @param question 用户提问
* @param sessionId 会话id
* @return 大模型的回答
*/
String chat(String question, String sessionId);
/**
* 流式聊天
* @param question 用户提问
* @param sessionId 会话id
* @return 大模型的回答
*/
Flux<String> chatStream(String question, String sessionId);
}
第四步:修改ChatServiceImpl,增加sessionId参数并且设置advisor参数,用于指定会话id:
@Slf4j
@Service
public class ChatServiceImpl implements ChatService {
@Autowired
private ChatClient chatClient;
/**
* 与聊天客户端进行交互,发送用户问题并获取响应内容。
* @param question 用户输入的问题内容
* @return 聊天客户端返回的响应内容
*/
@Override
public String chat(String question, String sessionId) {
// 调用聊天客户端处理用户问题并获取响应内容
String content = this.chatClient.prompt()
// .system(Constant.SYSTEM_ROLE) // 设置系统角色
.system(prompt -> prompt.param("now", DateUtil.now())) // 设置系统角色参数
// 设置会话记忆参数
.advisors(advisor -> advisor.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId))
.user(question)
.call()
.content();
log.info("question: {}, content: {}", question, content);
return content;
}
/**
* 处理用户问题并返回流式响应内容
* @param question 用户输入的问题内容
* @return 包含逐条响应内容和结束标记的响应流,每个元素为字符串格式
*/
@Override
public Flux<String> chatStream(String question, String sessionId) {
// 调用聊天客户端生成流式响应内容
return this.chatClient.prompt()
// .system(Constant.SYSTEM_ROLE) // 设置系统角色
.system(prompt -> prompt.param("now", DateUtil.now())) // 设置系统角色参数
// 设置会话记忆参数
.advisors(advisor -> advisor.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId))
.user(question)
.stream()
.content()
// 记录每次接收到的响应内容
.doOnNext(content -> log.info("question: {}, content: {}", question, content))
// 在流结束时添加结束标记
.concatWith(Flux.just("[END]"));
}
}
3.4. 敏感词校验
在Spring AI中提供了安全组件SafeGuardAdvisor,当用户输入的内容包含敏感词时,立即拦截请求,避免调用大型模型处理,节省计算资源并降低安全风险。
第一步:定义SafeGuardAdvisor:
@Bean
public Advisor safeGuardAdvisor() {
// 敏感词列表(示例数据,建议实际使用时从配置文件或数据库读取)
List<String> sensitiveWords = List.of("敏感词1", "敏感词2");
// 创建安全防护Advisor,参数依次为:敏感词库、违规提示语、advisor处理优先级,数字越小越优先
return new SafeGuardAdvisor(
sensitiveWords,
"敏感词提示:请勿输入敏感词!",
Advisor.DEFAULT_CHAT_MEMORY_PRECEDENCE_ORDER
);
}
第二步:添加到ChatClient中:
/**
* 创建并返回一个ChatClient的Spring Bean实例。
* @param builder 用于构建ChatClient实例的构建者对象
* @return 构建好的ChatClient实例
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder,
Advisor simpleLoggerAdvisor,
Advisor messageChatMemoryAdvisor,
Advisor promptChatMemoryAdvisor,
Advisor safeGuardAdvisor
) {
return builder
.defaultSystem(Constant.SYSTEM_ROLE) // 设置默认的系统角色
.defaultAdvisors(simpleLoggerAdvisor, promptChatMemoryAdvisor, safeGuardAdvisor) // 设置默认的Advisor
.build();
}
4. Tool Calling
再强大的AI大模型,也只是知道过去的事情,比如说,我想查询北京今天的天气情况,它是没有办法查询的,这就是大模型的数据的滞后性,要想解决这个问题,可以通过 Tool Calling(也叫 Function Calling)的方式解决,就相当于给大模型外挂一个插件,使得他能够获取新的数据。
4.1. 运行原理
Spring AI 提供了Tool Calling的方式来增强大模型,可以通过这种方式与外部系统或其他微服务系统整合起来。👉 Tool Calling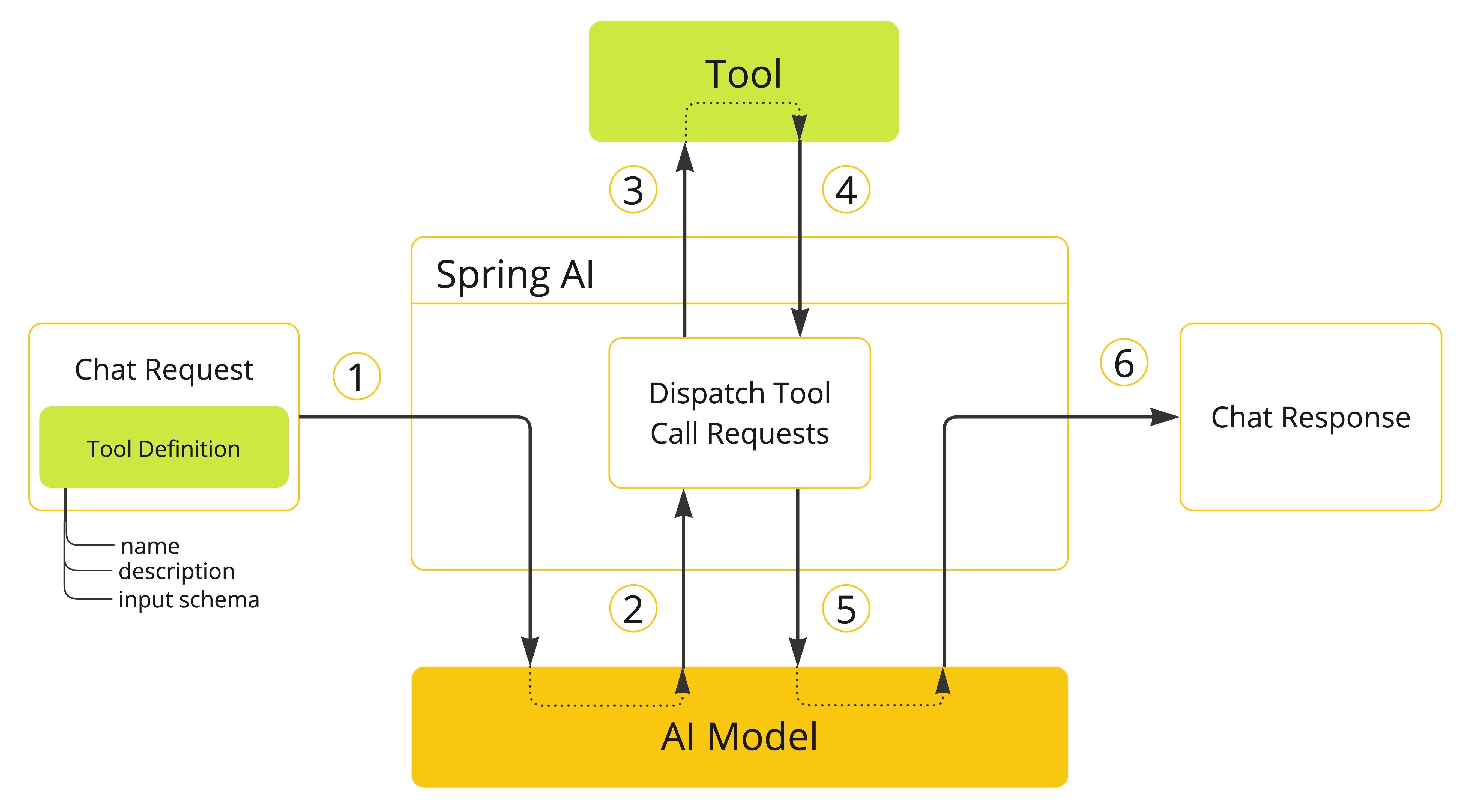
📚 流程说明:
- 定义工具:在聊天请求中声明工具信息,包括名称、功能描述、输入参数格式。
- 模型发起调用:若模型需使用工具,会返回工具名称和符合预定义格式的输入参数。
- 执行工具:应用程序根据工具名称匹配具体工具,并传递输入参数执行操作。
- 处理结果:应用程序接收工具执行结果,进行必要的数据处理。
- 返回模型:将工具调用结果发送给模型,作为生成最终回复的上下文依据。
- 生成最终响应:模型结合工具返回的结果,输出完整的回答内容。
4.2. 阅读文档
我们先来阅读官方文档中快速入门部分,地址:https://docs.spring.io/spring-ai/reference/1.0/api/tools.html#_quick_start
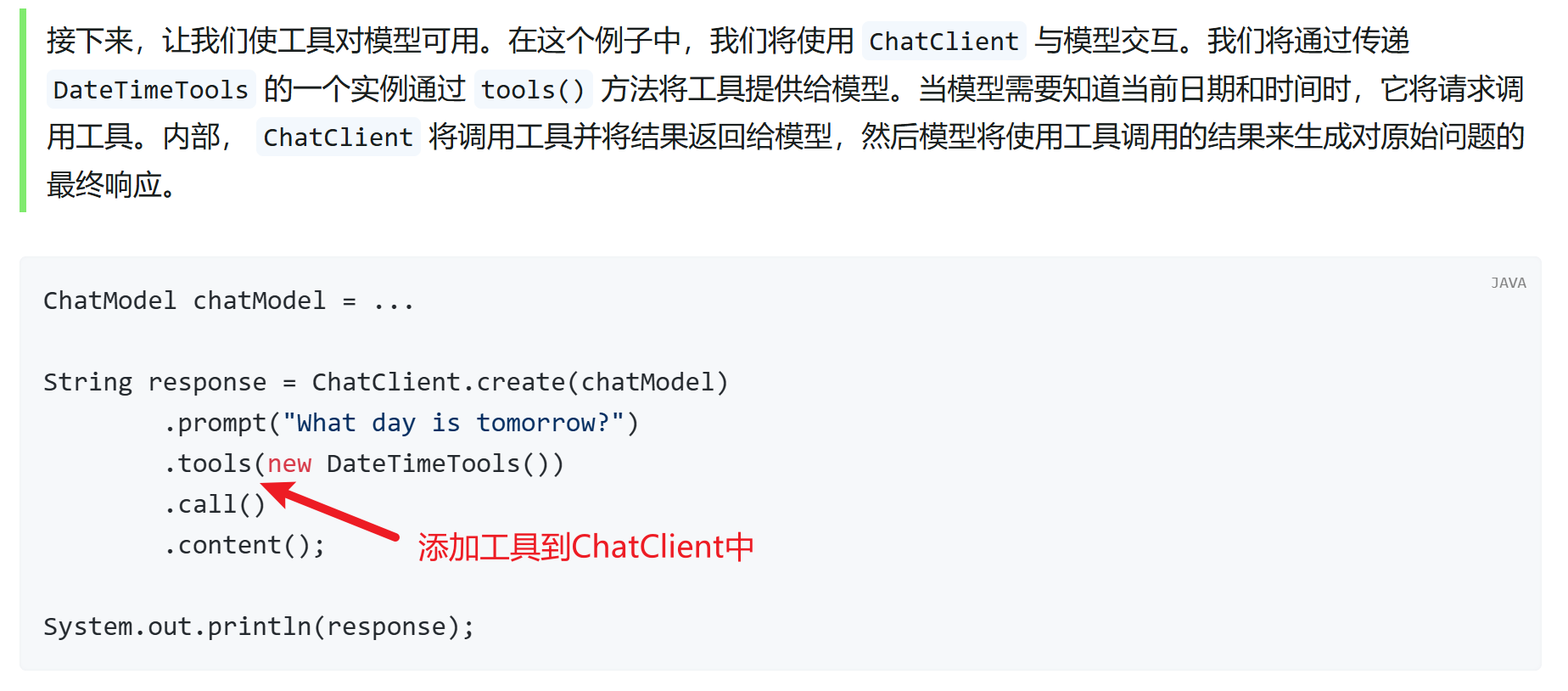

如果没有添加Tool,询问大模型:What day is tomorrow? 会得到类似的答复:
I am an AI and do not have access to real-time information. Please provide the current date so I can accurately determine what day tomorrow will be.Copied!
我是一个人工智能,无法获取实时信息。请提供当前日期,以便我准确确定明天是哪一天。
4.3. 案例:天气查询
4.3.1. 定义DTO
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class WeatherDTO {
@JsonPropertyDescription("城市ID")
private String cityId;
@JsonPropertyDescription("城市名称")
private String city;
@JsonPropertyDescription("当前温度(单位:℃)")
private String temperature;
@JsonPropertyDescription("低温(单位:℃)")
private String lowTemperature;
@JsonPropertyDescription("高温(单位:℃)")
private String highTemperature;
@JsonPropertyDescription("数据日期(格式:YYYYMMDD)")
private String date;
@JsonPropertyDescription("空气质量指数")
private String quality;
@JsonPropertyDescription("PM2.5 浓度(单位:微克/立方米)")
private double pm25;
}
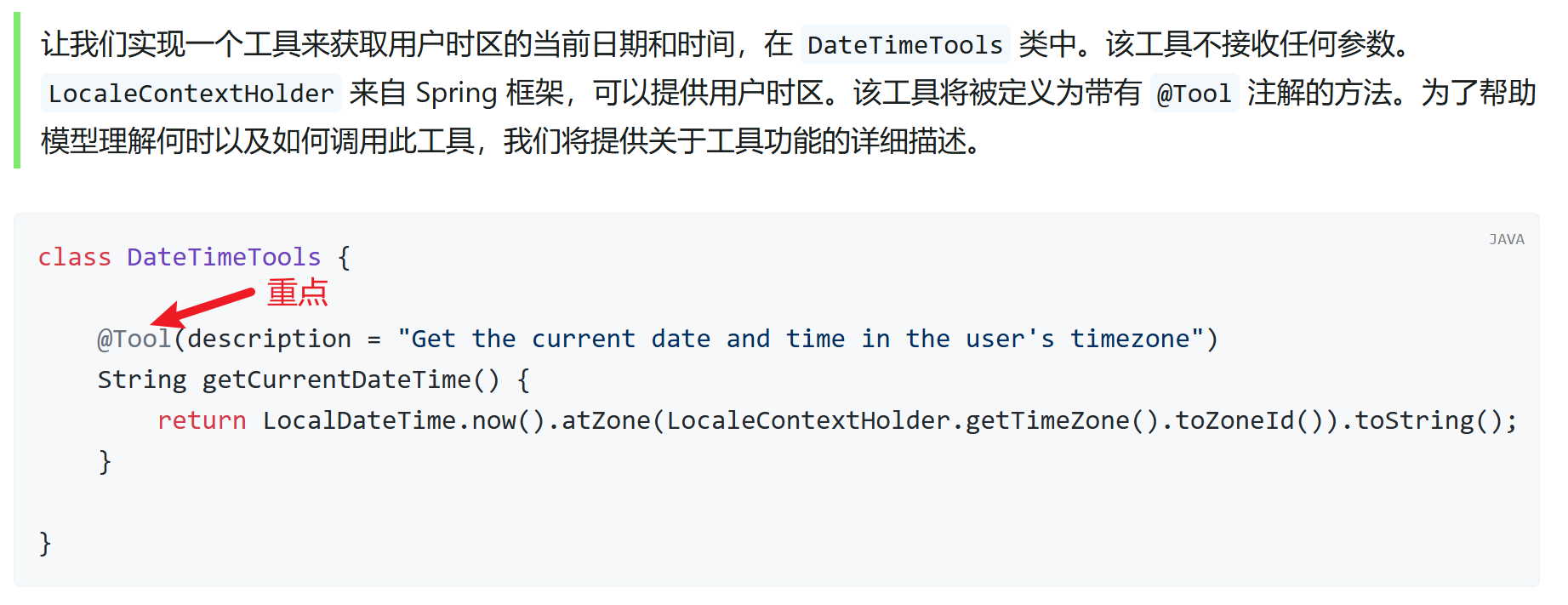
4.3.2. 定义Tool
@Component // 注册为一个组件
public class WeatherTools {
@Tool(description = "根据城市id查询天气信息")
public WeatherDTO getWeather(@ToolParam(description = "城市id") String cityId) {
// 模拟返回天气信息
return WeatherDTO.builder()
.cityId(cityId) // 城市ID
.city("北京") // 城市名称
.temperature("25") // 当前温度
.lowTemperature("20")// 低温
.highTemperature("30")// 高温
.date("2023-10-01")// 数据日期
.quality("良")// 空气质量
.pm25(15.5)// PM2.5数值
.build();
}
}
📚 说明:
- @Tool:指定方法是一个工具,通过
description属性进行描述这个方法(这很重要) - @ToolParam:指定方法的入参,也可以是无参的,
description属性描述参数的含义(不是必须,但建议添加)
4.3.3. 注册Tool
/**
* 创建并返回一个ChatClient的Spring Bean实例。
* @param builder 用于构建ChatClient实例的构建者对象
* @return 构建好的ChatClient实例
*/
@Bean
public ChatClient chatClient(ChatClient.Builder builder, Advisor simpleLoggerAdvisor,
Advisor messageChatMemoryAdvisor, Advisor promptChatMemoryAdvisor,
Advisor safeGuardAdvisor, WeatherTools weatherTools) {
return builder
.defaultSystem(Constant.SYSTEM_ROLE) // 设置默认的系统角色
.defaultAdvisors(simpleLoggerAdvisor, promptChatMemoryAdvisor, safeGuardAdvisor) // 设置默认的Advisor
.defaultTools(weatherTools) // 设置默认的Tool
.build();
}
4.3.4. 优化
前面的天气模拟数据,接下来通过外部接口查询的方式。 👉 天气免费 API
接口地址(北京为例):http://t.weather.itboy.net/api/weather/city/101010100,查询到的数据是JSON格式
把上述数据,加入到系统提示词中,大模型就能够找到城市对应的cityId,进行查询了:
public interface Constant {
String SYSTEM_ROLE = """
#角色
你是Java开发助手,名字叫小智。
#技能
##技能1:
帮我分析运行bug,并且给我提出解决方案。
##技能2:
给代码生成注释,无需逐行都注释,在关键代码添加注释
当前的时间是{now}
北京:101010100
天津:101030100
上海:101020100
重庆:101040100
广州:101280101
深圳:101280601
石家庄:101090101
郑州:101180101
武汉:101200101
长沙:101250101
南京:101190101
杭州:101210101
成都:101270101
西安:101110101
沈阳:101070101
长春:101060101
哈尔滨:101050101
太原:101100101
""";
}
所以只要向上述的API发起请求即可获取到天气数据:
@Component
public class WeatherTools {
@Tool(description = "根据城市id查询天气信息")
public WeatherDTO getWeather(@ToolParam(description = "城市id") String cityId) {
// 通过http请求获取天气信息,并且通过json数据解析为WeatherDTO对象
String url = "http://t.weather.itboy.net/api/weather/city/" + cityId;
String data = HttpUtil.get(url);
JSONObject jsonObject = JSONUtil.parseObj(data);
return WeatherDTO.builder()
.cityId(jsonObject.getByPath("cityInfo.citykey", String.class)) // 城市ID
.city(jsonObject.getByPath("cityInfo.city", String.class)) // 城市名称
.date(jsonObject.getByPath("date", String.class))// 数据日期
.temperature(jsonObject.getByPath("data.wendu", String.class)) // 当前温度
.lowTemperature(jsonObject.getByPath("data.forecast[0].low", String.class))// 低温
.highTemperature(jsonObject.getByPath("data.forecast[0].high", String.class))// 高温
.quality(jsonObject.getByPath("data.quality", String.class))// 空气质量
.pm25(jsonObject.getByPath("data.pm25", Double.class))// PM2.5数值
.build();
}
}
5. RAG检索增强
5.1. 需求分析
在前面的天气查询的案例中,为了让大模型知道城市对应的id,将城市名和id数据放到系统提示词中,这种做法虽然可以实现,但是,如果城市数据量比较大的话,放到提示词中就不合理了,有没有什么更好的解决方案呢?答案是有的,那就是RAG检索增强方案。
回顾一下,之前内容:
也就是说,可以将城市列表数据放到知识库中,发送请求到大模型之前,先到知识库查询城市以及对应的id,然后将数据和用户的问题,一起发给大模型,这样就不用在系统提示词中放入大量的城市数据了。
5.2. RAG原理
5.2.1. 基本原理
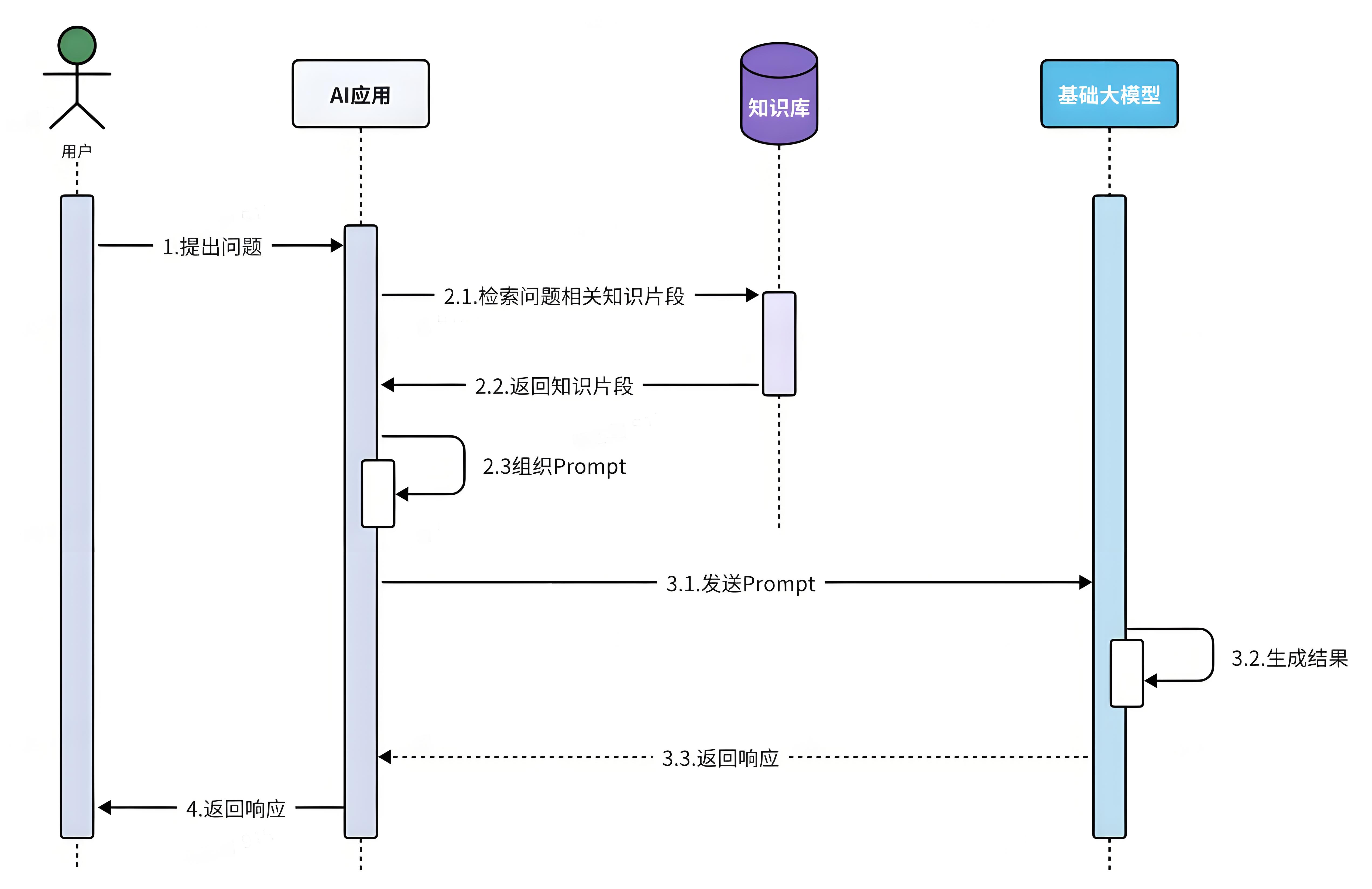
下面这张图是来源于Spring AI官网文档,说明了RAG整体实现流程。👉 RAG :: Spring AI Reference
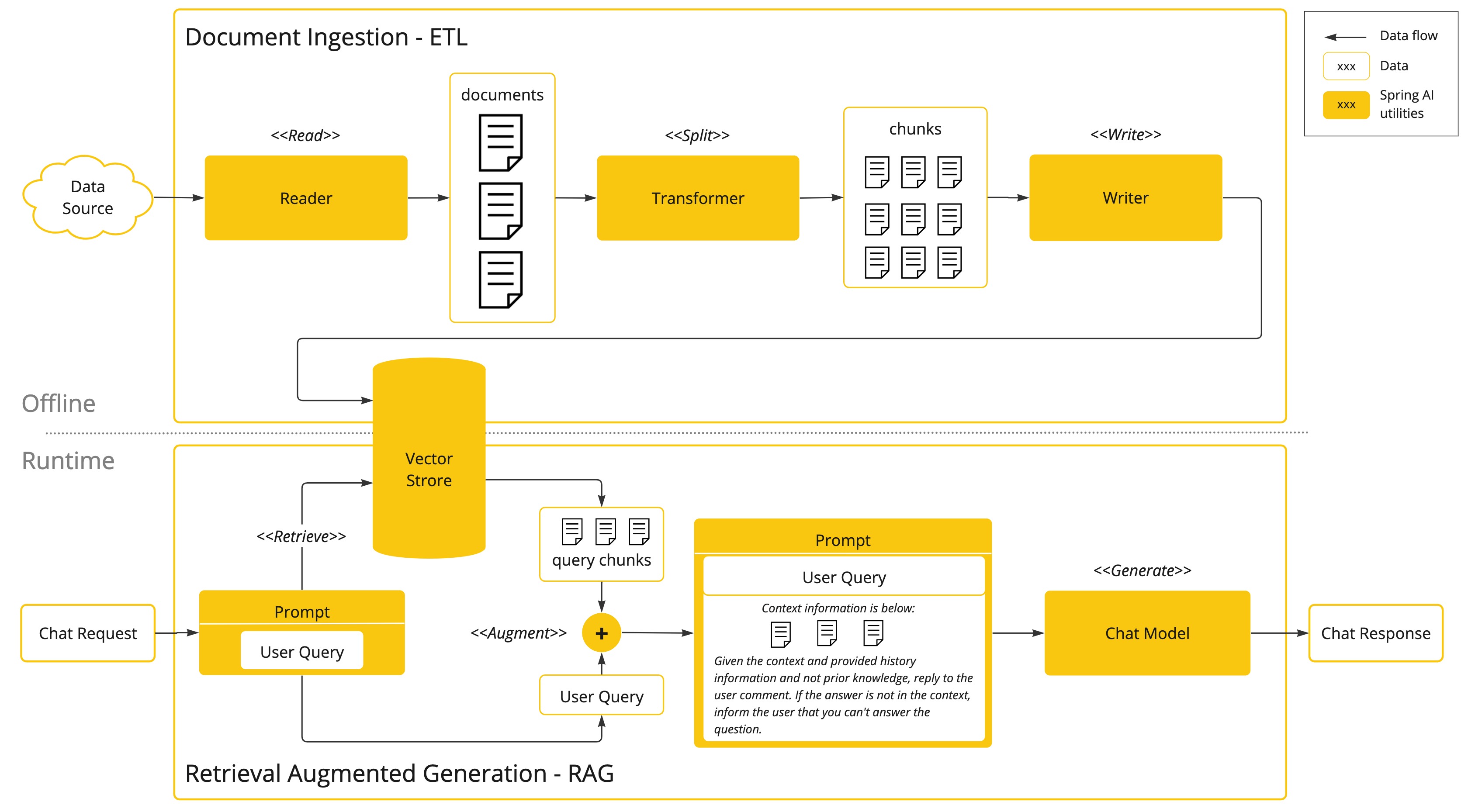
📚 这张图展示了**文档摄取(ETL)和检索增强生成(RAG)**两个核心流程,具体可分为以下两部分:
-
文档摄取(ETL)流程(离线处理)
-
数据读取:从数据源(如文档、数据库)读取原始文档。
-
分割文档:通过分割模块(
<<Split>>)将文档切分为更小的数据块(chunks)。 -
转换数据:通过转换模块(
Transformer)处理数据块(如向量化、添加元数据)。 -
写入存储:将处理后的数据块写入向量数据库(
Vector Store),为后续检索做准备。 -
核心目标:将非结构化文档转化为结构化、可检索的向量数据。
-
检索增强生成(RAG)流程(实时处理)
-
用户查询:接收用户提问(
Chat Request)。 -
检索相关块:从向量库中检索与查询最相关(相似度高)的数据块(
<<Retrieve>>)。 -
增强查询:将检索到的上下文信息(
Context information)与用户问题结合,生成增强后的提示(<<Augment>>)。 -
生成响应:通过聊天模型(
Chat Model)生成回答。 -
**核心目标:**通过外部知识库提升生成结果的准确性,解决了大模型信息缺失或滞后的问题。
5.2.2. 相似度计算
在上述的原理中,在向大模型发起请求前,需要到向量库(知识库)查询,而且是相似性的查询,那究竟什么是相似性查询?也就是说,如何判断两个文字相似呢?比如:北京 和 北京市,这两个词相似度高,北京 和 天津市,这两个词相似度就低。怎么做到呢?
解决方案:
- 先将数据(文字或图片等)向量化
- 为什么要向量化?什么是向量化?
- 这是因为,计算机无法直接理解文本、图片等非结构化数据的,向量化就是把文本等数据转化为一组数字,这样计算机就能识别了。
- 通过相似度算法进行判断
- 余弦相似度:是通过计算两个向量在多维空间中的夹角余弦值来评估它们的相似度。
- 欧式距离:是衡量空间中两点间直线距离典方法。
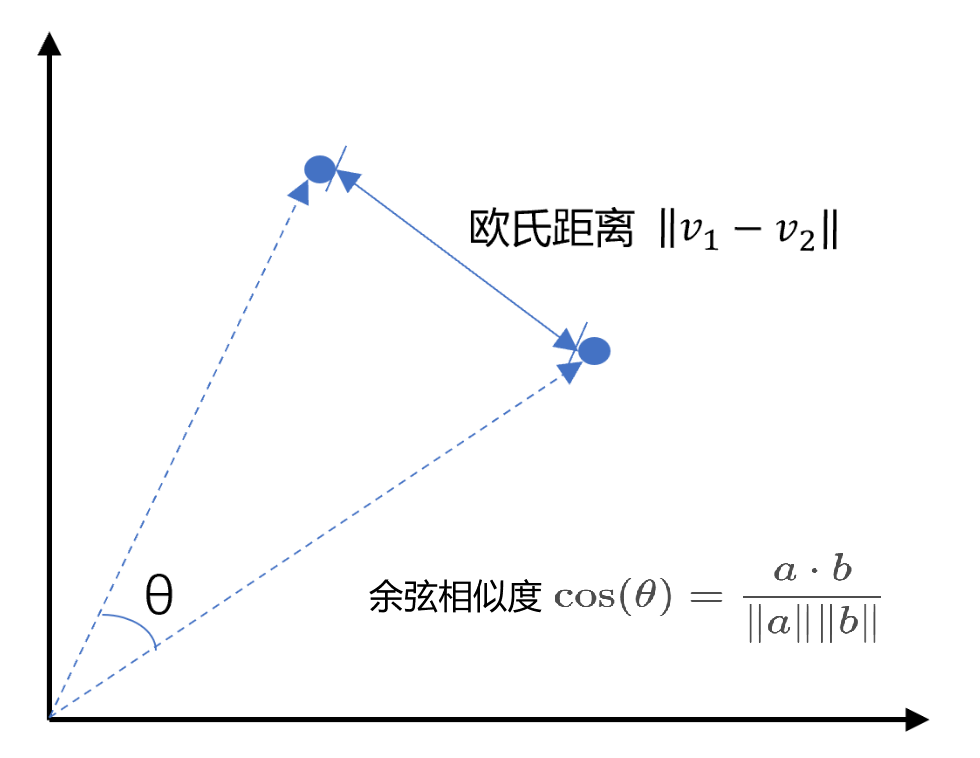
- 余弦相似度的取值范围是[-1, 1],夹角越小(即余弦值越接近于1),两个向量越相似。
- 欧式距离值约小约相似,反之越不相似。
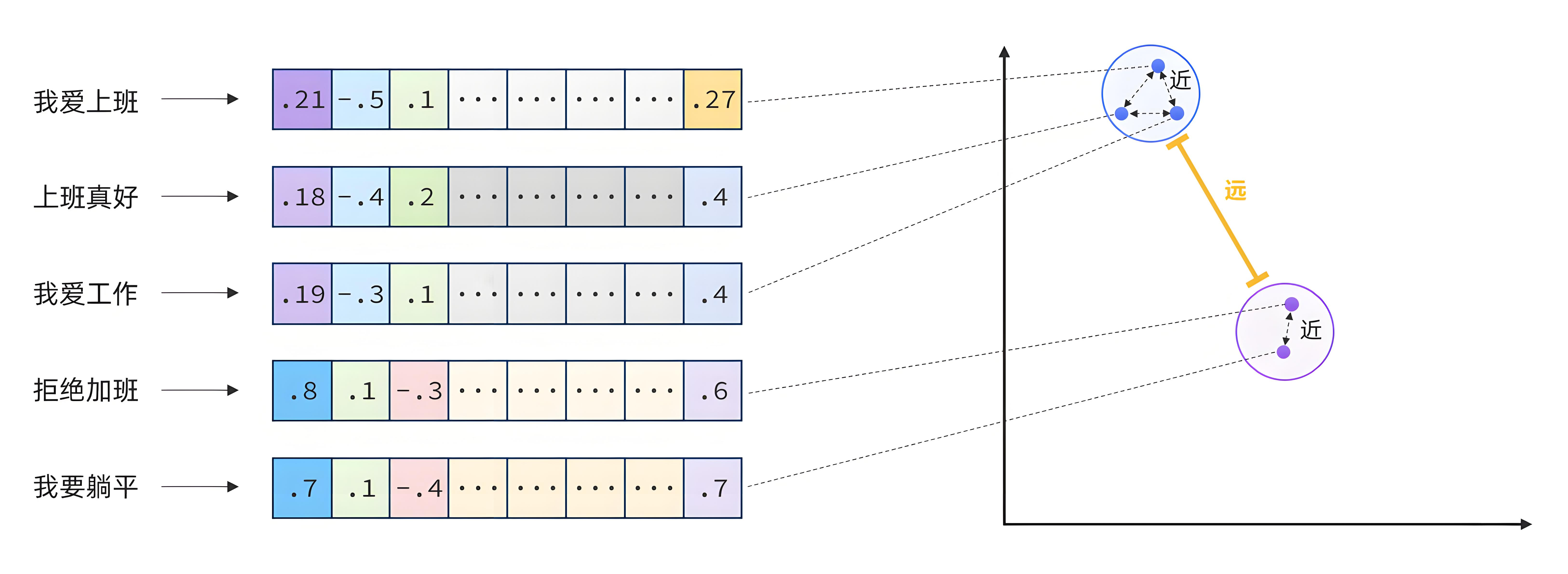
举个例子:
5.2.3. 向量数据库
向量数据库就是用来存储向量数据的数据库,Spring AI也支持了很多的向量数据库,如下:👉 Vector Databases
- Azure Vector Search - The Azure vector store.
- Apache Cassandra - The Apache Cassandra vector store.
- Chroma Vector Store - The Chroma vector store.
- Elasticsearch Vector Store - The Elasticsearch vector store.
- GemFire Vector Store - The GemFire vector store.
- MariaDB Vector Store - The MariaDB vector store.
- Milvus Vector Store - The Milvus vector store.
- MongoDB Atlas Vector Store - The MongoDB Atlas vector store.
- Neo4j Vector Store - The Neo4j vector store.
- OpenSearch Vector Store - The OpenSearch vector store.
- Oracle Vector Store - The Oracle Database vector store.
- PgVector Store - The PostgreSQL/PGVector vector store.
- Pinecone Vector Store - PineCone vector store.
- Qdrant Vector Store - Qdrant vector store.
- Redis Vector Store - The Redis vector store.
- SAP Hana Vector Store - The SAP HANA vector store.
- Typesense Vector Store - The Typesense vector store.
- Weaviate Vector Store - The Weaviate vector store.
- SimpleVectorStore - 一种简单的基于内存存储的持久化向量存储实现.。
5.3. 城市数据知识库
5.3.1. 数据向量化
首先,需要将城市数据进行向量化,而向量化这个动作也是可以通过大模型来完成的,这种大模型一般称之为Embeddings Model。阿里云百炼中也提供了这样的大模型。
编写配置:
spring:
application:
name: spring-ai
ai:
dashscope:
api-key: ******
chat:
options:
model: qwen-plus
embedding:
options:
model: text-embedding-v3 #向量模型
dimensions: 1024 #向量维度维度
openai: #openai配置
base-url: https://dashscope.aliyuncs.com/compatible-mode #阿里百炼api地址
# base-url: https://api.chatanywhere.tech #api地址
api-key: ****** #阿里百炼 api key
# api-key: ****** #api key
chat:
options:
model: qwen-plus #阿里百炼 模型名称
# model: gpt-3.5-turbo #模型名称
enabled: false #关闭OpenAI配置
embedding:
enabled: false #关闭openai的embedding,否则会启动报错,容器中会存在2个EmbeddingModel
创建内存向量数据库:
/**
* 创建并返回一个VectorStore的Spring Bean实例。
* @param embeddingModel 向量模型
*/
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return SimpleVectorStore.builder(embeddingModel).build();
}
5.3.2. 准备数据
城市列表数据如下:
北京:101010100
朝阳:101010300
顺义:101010400
怀柔:101010500
通州:101010600
昌平:101010700
延庆:101010800
丰台:101010900
石景山:101011000
大兴:101011100
房山:101011200
密云:101011300
门头沟:101011400
平谷:101011500
八达岭:101011600
佛爷顶:101011700
汤河口:101011800
密云上甸子:101011900
斋堂:101012000
霞云岭:101012100
海淀:101010200
天津:101030100
宝坻:101030300
东丽:101030400
西青:101030500
北辰:101030600
蓟县:101031400
汉沽:101030800
静海:101030900
津南:101031000
塘沽:101031100
大港:101031200
武清:101030200
宁河:101030700
上海:101020100
宝山:101020300
嘉定:101020500
南汇:101020600
浦东:101021300
青浦:101020800
松江:101020900
奉贤:101021000
崇明:101021100
徐家汇:101021200
闵行:101020200
金山:101020700
石家庄:101090101
张家口:101090301
承德:101090402
唐山:101090501
秦皇岛:101091101
沧州:101090701
衡水:101090801
邢台:101090901
邯郸:101091001
保定:101090201
廊坊:101090601
郑州:101180101
新乡:101180301
许昌:101180401
平顶山:101180501
信阳:101180601
南阳:101180701
开封:101180801
洛阳:101180901
商丘:101181001
焦作:101181101
鹤壁:101181201
濮阳:101181301
周口:101181401
漯河:101181501
驻马店:101181601
三门峡:101181701
济源:101181801
安阳:101180201
合肥:101220101
芜湖:101220301
淮南:101220401
马鞍山:101220501
安庆:101220601
宿州:101220701
阜阳:101220801
亳州:101220901
黄山:101221001
滁州:101221101
淮北:101221201
铜陵:101221301
宣城:101221401
六安:101221501
巢湖:101221601
池州:101221701
蚌埠:101220201
杭州:101210101
舟山:101211101
湖州:101210201
嘉兴:101210301
金华:101210901
绍兴:101210501
台州:101210601
温州:101210701
丽水:101210801
衢州:101211001
宁波:101210401
重庆:101040100
合川:101040300
南川:101040400
江津:101040500
万盛:101040600
渝北:101040700
北碚:101040800
巴南:101040900
长寿:101041000
黔江:101041100
万州天城:101041200
万州龙宝:101041300
涪陵:101041400
开县:101041500
城口:101041600
云阳:101041700
巫溪:101041800
奉节:101041900
巫山:101042000
潼南:101042100
垫江:101042200
梁平:101042300
忠县:101042400
石柱:101042500
大足:101042600
荣昌:101042700
铜梁:101042800
璧山:101042900
丰都:101043000
武隆:101043100
彭水:101043200
綦江:101043300
酉阳:101043400
秀山:101043600
沙坪坝:101043700
永川:101040200
福州:101230101
泉州:101230501
漳州:101230601
龙岩:101230701
晋江:101230509
南平:101230901
厦门:101230201
宁德:101230301
莆田:101230401
三明:101230801
兰州:101160101
平凉:101160301
庆阳:101160401
武威:101160501
金昌:101160601
嘉峪关:101161401
酒泉:101160801
天水:101160901
武都:101161001
临夏:101161101
合作:101161201
白银:101161301
定西:101160201
张掖:101160701
广州:101280101
惠州:101280301
梅州:101280401
汕头:101280501
深圳:101280601
珠海:101280701
佛山:101280800
肇庆:101280901
湛江:101281001
江门:101281101
河源:101281201
清远:101281301
云浮:101281401
潮州:101281501
东莞:101281601
中山:101281701
阳江:101281801
揭阳:101281901
茂名:101282001
汕尾:101282101
韶关:101280201
南宁:101300101
柳州:101300301
来宾:101300401
桂林:101300501
梧州:101300601
防城港:101301401
贵港:101300801
玉林:101300901
百色:101301001
钦州:101301101
河池:101301201
北海:101301301
崇左:101300201
贺州:101300701
贵阳:101260101
安顺:101260301
都匀:101260401
兴义:101260906
铜仁:101260601
毕节:101260701
六盘水:101260801
遵义:101260201
凯里:101260501
昆明:101290101
红河:101290301
文山:101290601
玉溪:101290701
楚雄:101290801
普洱:101290901
昭通:101291001
临沧:101291101
怒江:101291201
香格里拉:101291301
丽江:101291401
德宏:101291501
景洪:101291601
大理:101290201
曲靖:101290401
保山:101290501
呼和浩特:101080101
乌海:101080301
集宁:101080401
通辽:101080501
阿拉善左旗:101081201
鄂尔多斯:101080701
临河:101080801
锡林浩特:101080901
呼伦贝尔:101081000
乌兰浩特:101081101
包头:101080201
赤峰:101080601
南昌:101240101
上饶:101240301
抚州:101240401
宜春:101240501
鹰潭:101241101
赣州:101240701
景德镇:101240801
萍乡:101240901
新余:101241001
九江:101240201
吉安:101240601
武汉:101200101
黄冈:101200501
荆州:101200801
宜昌:101200901
恩施:101201001
十堰:101201101
神农架:101201201
随州:101201301
荆门:101201401
天门:101201501
仙桃:101201601
潜江:101201701
襄樊:101200201
鄂州:101200301
孝感:101200401
黄石:101200601
咸宁:101200701
成都:101270101
自贡:101270301
绵阳:101270401
南充:101270501
达州:101270601
遂宁:101270701
广安:101270801
巴中:101270901
泸州:101271001
宜宾:101271101
内江:101271201
资阳:101271301
乐山:101271401
眉山:101271501
凉山:101271601
雅安:101271701
甘孜:101271801
阿坝:101271901
德阳:101272001
广元:101272101
攀枝花:101270201
银川:101170101
中卫:101170501
固原:101170401
石嘴山:101170201
吴忠:101170301
西宁:101150101
黄南:101150301
海北:101150801
果洛:101150501
玉树:101150601
海西:101150701
海东:101150201
海南:101150401
济南:101120101
潍坊:101120601
临沂:101120901
菏泽:101121001
滨州:101121101
东营:101121201
威海:101121301
枣庄:101121401
日照:101121501
莱芜:101121601
聊城:101121701
青岛:101120201
淄博:101120301
德州:101120401
烟台:101120501
济宁:101120701
泰安:101120801
西安:101110101
延安:101110300
榆林:101110401
铜川:101111001
商洛:101110601
安康:101110701
汉中:101110801
宝鸡:101110901
咸阳:101110200
渭南:101110501
太原:101100101
临汾:101100701
运城:101100801
朔州:101100901
忻州:101101001
长治:101100501
大同:101100201
阳泉:101100301
晋中:101100401
晋城:101100601
吕梁:101101100
乌鲁木齐:101130101
石河子:101130301
昌吉:101130401
吐鲁番:101130501
库尔勒:101130601
阿拉尔:101130701
阿克苏:101130801
喀什:101130901
伊宁:101131001
塔城:101131101
哈密:101131201
和田:101131301
阿勒泰:101131401
阿图什:101131501
博乐:101131601
克拉玛依:101130201
拉萨:101140101
山南:101140301
阿里:101140701
昌都:101140501
那曲:101140601
日喀则:101140201
林芝:101140401
台北县:101340101
高雄:101340201
台中:101340401
海口:101310101
三亚:101310201
东方:101310202
临高:101310203
澄迈:101310204
儋州:101310205
昌江:101310206
白沙:101310207
琼中:101310208
定安:101310209
屯昌:101310210
琼海:101310211
文昌:101310212
保亭:101310214
万宁:101310215
陵水:101310216
西沙:101310217
南沙岛:101310220
乐东:101310221
五指山:101310222
琼山:101310102
长沙:101250101
株洲:101250301
衡阳:101250401
郴州:101250501
常德:101250601
益阳:101250700
娄底:101250801
邵阳:101250901
岳阳:101251001
张家界:101251101
怀化:101251201
黔阳:101251301
永州:101251401
吉首:101251501
湘潭:101250201
南京:101190101
镇江:101190301
苏州:101190401
南通:101190501
扬州:101190601
宿迁:101191301
徐州:101190801
淮安:101190901
连云港:101191001
将这些数据写入到项目resources目录下的citys.txt文件中:
5.3.3. 存储数据
接下来,需要读取到上述文件,把文件内容切成小块,再存储到向量库:
import cn.hutool.core.util.StrUtil;
import jakarta.annotation.PostConstruct;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TextSplitter;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 城市信息向量化处理组件
* 在应用启动时将城市数据文件转换为向量并存储到向量数据库
*/
@Slf4j
@Component
@RequiredArgsConstructor
public class CityEmbedding {
/**
* 向量存储服务,用于持久化文档向量
*/
private final VectorStore vectorStore;
/**
* 城市数据文件资源路径(classpath:citys.txt)
*/
@Value("classpath:citys.txt")
private Resource resource;
/**
* 应用启动时初始化方法
* 1. 读取城市数据文件
* 2. 拆分文本为小块文档
* 3. 将拆分后的文档向量化并存储
*/
@PostConstruct
public void init() throws Exception {
// 1. 创建文本读取器并加载文件内容
TextReader textReader = new TextReader(this.resource);
textReader.getCustomMetadata().put("filename", "citys.txt"); // 添加文件来源元数据
// 2. 将文件内容拆分为小块文档
List<Document> documentList = textReader.get();
//参数分别是:默认分块大小、最小分块字符数、最小向量化长度(太小的忽略)、最大分块数量、不保留分隔符(\n啥的)
TextSplitter textSplitter = new TokenTextSplitter(200, 100, 5, 10000, false);
List<Document> splitDocuments = textSplitter.apply(documentList);
// 3. 将处理后的文档向量化并存入向量存储
this.vectorStore.add(splitDocuments);
log.info("数据写入向量库成功,数据条数:{}", splitDocuments.size());
}
}
测试:
5.3.4. 搜索数据
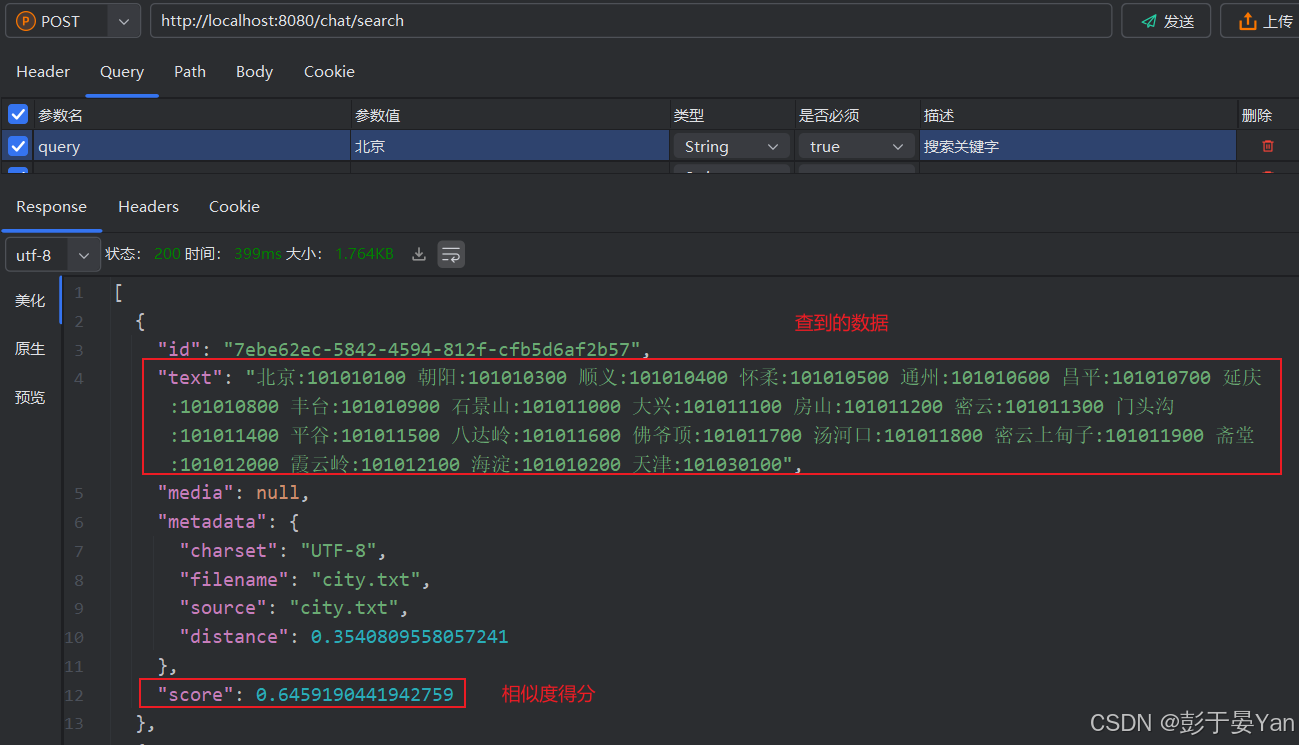
接下来,写个搜索数据的接口,方便进行数据测试。
@Autowired
private VectorStore vectorStore;
/**
* 搜索向量数据库
* @param query 搜索关键字
*/
@PostMapping("/search")
public List<Document> search(@RequestParam("query") String query) {
return this.vectorStore.similaritySearch(SearchRequest.builder()
.query(query) // 设置查询条件
.topK(3) // 设置最多返回的文档数量
.build());
}
测试:
5.4. RAG实现
RAG的实现,就需要在chatClient中添加QuestionAnswerAdvisor,以实现从向量库中检索数据,和用户输入问题合并,一起发给大模型。
代码实现:
@Autowired
private VectorStore vectorStore;
/**
* 与聊天客户端进行交互,发送用户问题并获取响应内容。
*
* @param question 用户输入的问题内容
* @return 聊天客户端返回的响应内容
*/
@Override
public String chat(String question, String sessionId) {
// 创建搜索请求,用于搜索相关文档
SearchRequest searchRequest = SearchRequest.builder()
.query(question) // 设置查询条件
.topK(3) // 设置最多返回的文档数量
.build();
// 调用聊天客户端处理用户问题并获取响应内容
String content = this.chatClient.prompt()
// .system(Constant.SYSTEM_ROLE) // 设置系统角色
.system(prompt -> prompt.param("now", DateUtil.now())) // 设置系统角色参数
// 设置会话记忆参数
.advisors(advisor -> advisor
.advisors(new QuestionAnswerAdvisor(vectorStore, searchRequest)) // 设置RAG的Advisor
.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, sessionId))
.user(question)
.call()
.content();
log.info("question: {}, content: {}", question, content);
return content;
}
去掉系统提示词中的城市数据: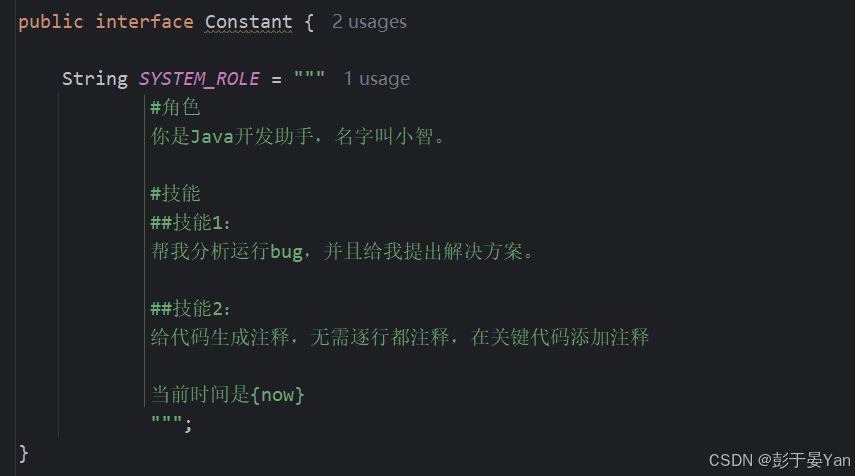
测试: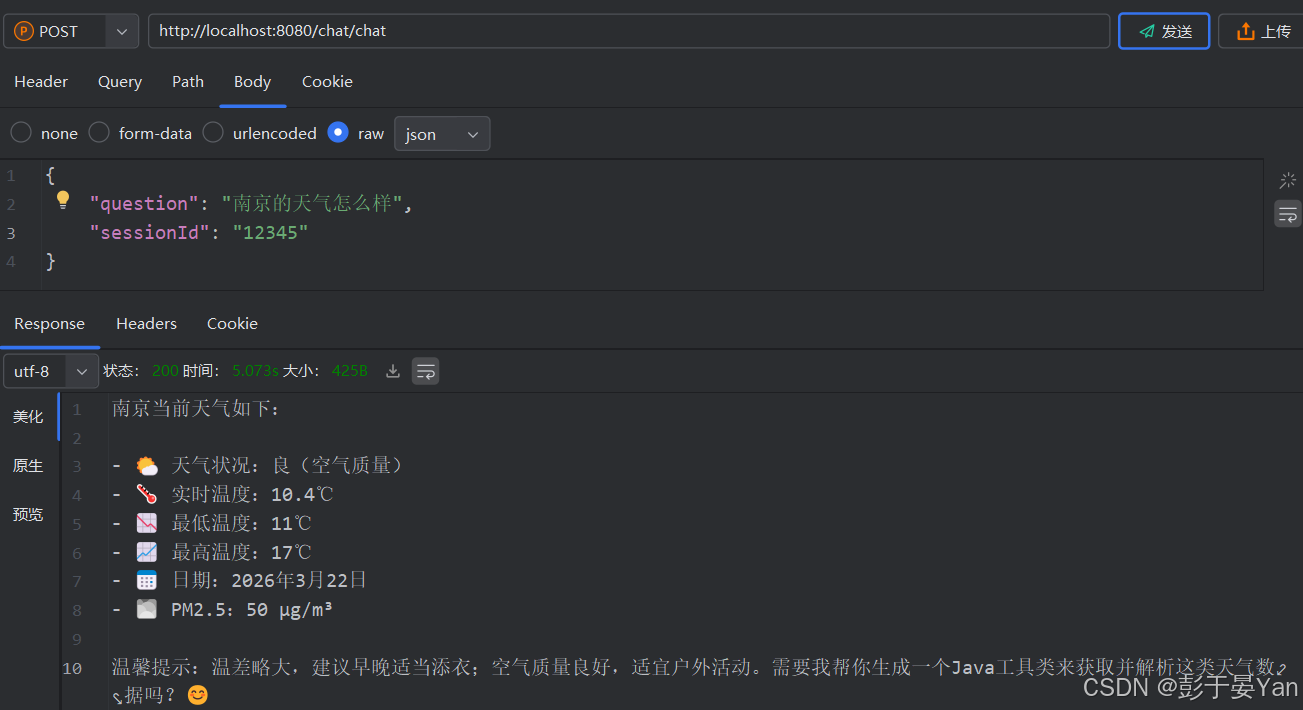

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)