以乳腺癌诊断数据为例的医学AI分类建模方法入门
1、背景说明(医学AI分类建模入门案例)
在医学人工智能中,分类模型(classification modeling)是最基础且应用最广泛的任务之一,其核心目标是基于患者的多维度信息(如影像特征、临床指标或结构化数据),对疾病状态进行自动判别,从而辅助医生进行诊断与风险分层。
在真实临床场景中,这类任务通常具有以下特点:
- 样本量相对有限(数百至数千例)
- 特征来源多样(影像、检验指标、结构化数据等)
- 输出为明确的离散标签(如良恶性、是否患病等)
因此,在入门阶段,需要一个兼具医学意义与建模可操作性的数据集来系统演示医学AI分类模型的完整流程。
2、为什么选择该数据集
本教程选用 Breast Cancer Wisconsin (Diagnostic) 数据集 作为示例,其原因在于该数据集符合医学分类任务的典型特征:
- 每个样本对应一名患者
- 每个特征来源于医学影像分析(细胞核形态学)
- 标签对应明确的诊断结果(良性 vs 恶性)
从建模角度来看,该任务可以抽象为:
基于多维医学特征,对患者进行疾病分类(良性 / 恶性)
该形式与临床中常见的任务高度一致,例如:
- 肿瘤良恶性判别
- 病变是否存在
- 影像结构是否异常
3、医学语义与建模本质
该数据集的输入并非原始图像,而是从影像中提取的定量特征,例如:
- 细胞核大小(radius / area)
- 边界复杂度(concavity / compactness)
- 灰度纹理(texture)
这类特征在医学AI中通常归属于:
影像组学(Radiomics)特征
因此,本案例本质上模拟的是如下标准流程:
影像 → 特征提取 → 结构化数据 → 分类模型
这一流程与实际临床应用(如CT定量分析、超声测量、心脏结构建模等)在方法学上是一致的。
4、标签定义的医学处理
在原始数据中:
- 恶性(malignant)标记为 0
- 良性(benign)标记为 1
但在医学建模中,通常会进行标签重定义:
将“更重要或更关注的类别”定义为正类(positive class)
因此本教程中采用:
- 恶性(重点关注) → 1
- 良性 → 0
这样做的好处是:
- 模型输出概率可解释为“属于恶性的概率”
- Sensitivity(敏感性)直接对应“检出恶性能力”
5、分类任务的临床意义
该任务本质属于诊断型分类模型,其临床意义在于:
- 辅助医生进行早期筛查
- 提高恶性病变检出率
- 减少漏诊风险
在实际应用中,这类模型常用于:
- 影像辅助诊断系统(CAD)
- 自动筛查工具
- 风险分层前置模型
6、本案例的教学意义
通过该数据集,可以完整覆盖医学AI分类建模的核心流程:
- 医学数据理解
- 特征语义解析
- 标签规范化处理
- 数据划分(避免数据偏倚)
- 模型训练与预测
- 分类指标评估(AUC / Sensitivity / Specificity)
相比直接使用深度学习方法,本案例更强调:
结构化数据建模能力 + 医学解释能力 + 指标理解
7、完整版本(医学建模规范版)
# ===============================
# 1. 数据加载
# ===============================
import numpy as np
import pandas as pd
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = pd.Series(data.target, name="target")
# 0 = malignant(恶性), 1 = benign(良性)
print("原始标签分布:")
print(y.value_counts())
# ===============================
# 2. 标签医学重定义
# ===============================
# 恶性=1(正类),良性=0
y_med = (y == 0).astype(int)
print("\n医学标签分布:")
print(y_med.value_counts())
# ===============================
# 3. 训练 / 测试集划分(分层)
# ===============================
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y_med,
test_size=0.2,
random_state=42,
stratify=y_med
)
# ===============================
# 4. 建模(Gradient Boosting)
# ===============================
from sklearn.ensemble import GradientBoostingClassifier
gbc = GradientBoostingClassifier(
n_estimators=300,
learning_rate=0.05,
max_depth=3,
subsample=0.8,
random_state=42
)
gbc.fit(X_train, y_train)
# ===============================
# 5. 概率预测
# ===============================
proba = gbc.predict_proba(X_test)[:, 1]
pred = (proba > 0.5).astype(int)
# ===============================
# 6. 基础指标(AUC)
# ===============================
from sklearn.metrics import roc_auc_score, average_precision_score
roc_auc = roc_auc_score(y_test, proba)
pr_auc = average_precision_score(y_test, proba)
print("\n==== AUC指标 ====")
print(f"ROC-AUC : {roc_auc:.4f}")
print(f"PR-AUC : {pr_auc:.4f}")
# ===============================
# 7. 临床核心指标
# ===============================
from sklearn.metrics import confusion_matrix
tn, fp, fn, tp = confusion_matrix(y_test, pred).ravel()
sensitivity = tp / (tp + fn) # 召回率(检出恶性能力)
specificity = tn / (tn + fp) # 排除良性能力
accuracy = (tp + tn) / (tp + tn + fp + fn)
print("\n==== 临床指标 ====")
print(f"Accuracy : {accuracy:.4f}")
print(f"Sensitivity : {sensitivity:.4f}")
print(f"Specificity : {specificity:.4f}")
# ===============================
# 8. ROC曲线
# ===============================
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve
fpr, tpr, _ = roc_curve(y_test, proba)
plt.figure()
plt.plot(fpr, tpr)
plt.plot([0,1], [0,1], linestyle="--")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve")
plt.show()
# ===============================
# 9. PR曲线
# ===============================
from sklearn.metrics import precision_recall_curve
precision, recall, _ = precision_recall_curve(y_test, proba)
plt.figure()
plt.plot(recall, precision)
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.title("PR Curve")
plt.show()
# ===============================
# 10. 特征重要性(解释性)
# ===============================
importances = pd.Series(
gbc.feature_importances_,
index=X.columns
).sort_values(ascending=False)
print("\n==== Top 10 特征重要性 ====")
print(importances.head(10))
# 可视化
plt.figure(figsize=(8,6))
importances.head(10).sort_values().plot(kind='barh')
plt.title("Top 10 Feature Importance")
plt.show()
8、结果
这里是引用
原始标签分布:
target
1 357
0 212
Name: count, dtype: int64
医学标签分布:
target
0 357
1 212
Name: count, dtype: int64
==== AUC指标 ====
ROC-AUC : 0.9967
PR-AUC : 0.9951
==== 临床指标 ====
Accuracy : 0.9649
Sensitivity : 0.9048
Specificity : 1.0000
==== Top 10 特征重要性 ====
worst perimeter 0.290685
mean concave points 0.247690
worst radius 0.153131
worst concave points 0.095205
worst area 0.033282
mean texture 0.029821
worst texture 0.029599
worst concavity 0.026854
area error 0.018976
worst smoothness 0.012514
dtype: float64
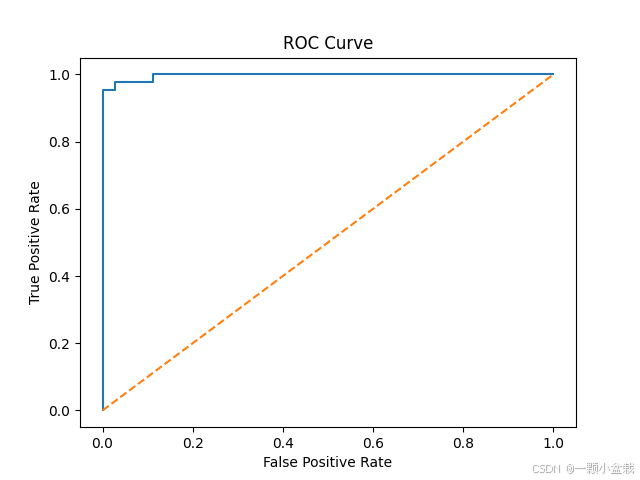
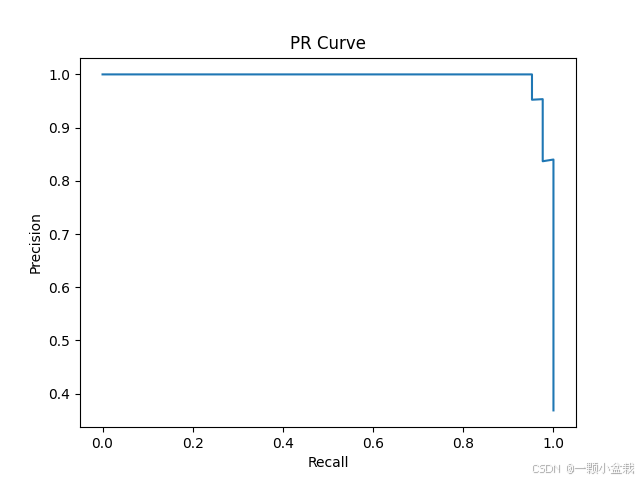
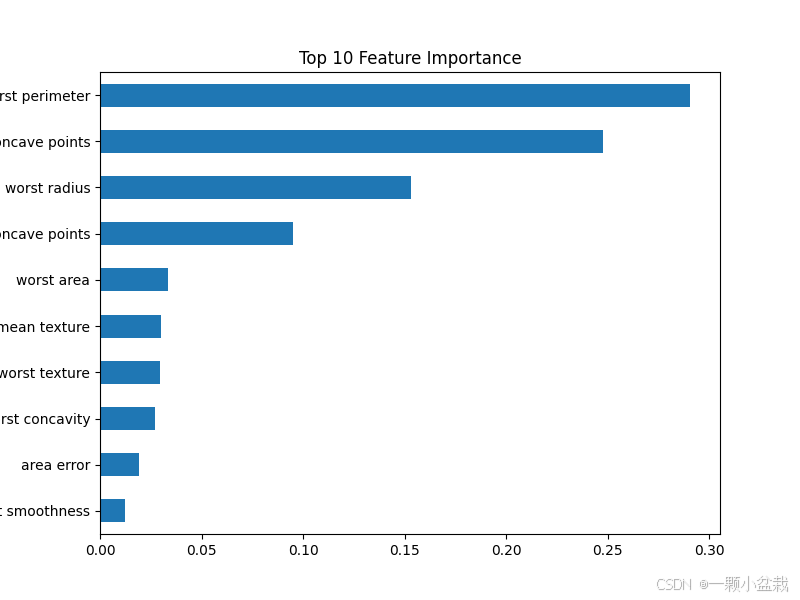
本示例通过经典乳腺癌数据集,系统演示了医学AI分类模型的完整流程,从特征构建到分类预测及临床指标评估,为后续更复杂的医学建模任务奠定基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)