【AI大模型前沿】Google MedGemma 1.5技术解析:开源多模态医疗AI从2D影像到3D CT/MRI的跨越式进化
系列篇章💥
前言
医疗AI正从"可用"迈向"好用"的关键阶段。2026年1月13日,Google Research重磅发布了MedGemma 1.5,这是其健康AI开发者基础(HAI-DEF)计划下的最新开源医疗多模态大模型。相比初代MedGemma仅能处理X光片等2D图像,1.5版本首次实现了对3D CT、MRI全容积数据以及病理全扫描切片的原生支持,标志着开源医疗AI正式进入高维影像理解时代。本文将深入解析MedGemma 1.5的技术架构、核心能力与落地实践,为医疗AI开发者提供全面的技术参考。
一、项目概述
MedGemma 1.5是Google基于Gemma 3架构开发的开源医疗多模态大语言模型,采用40亿参数(4B)的轻量化设计,支持文本、2D图像、3D容积影像(CT/MRI)、全切片病理图像(WSI)及纵向时序影像的多模态理解与推理。该模型在继承前代 dermatology、眼底摄影等2D影像分析能力的基础上,突破性地实现了高维医学影像的端到端处理,在CT疾病分类准确率提升至61%、MRI分类准确率跃升至65%(较1.0版本提升14%),同时支持从实验室报告中结构化提取数据,成为首款能够同时理解3D医疗影像和自然语言的开源多模态医学AI模型,为全球医疗机构和研究者提供了可本地部署、可商业应用的基础医疗AI底座。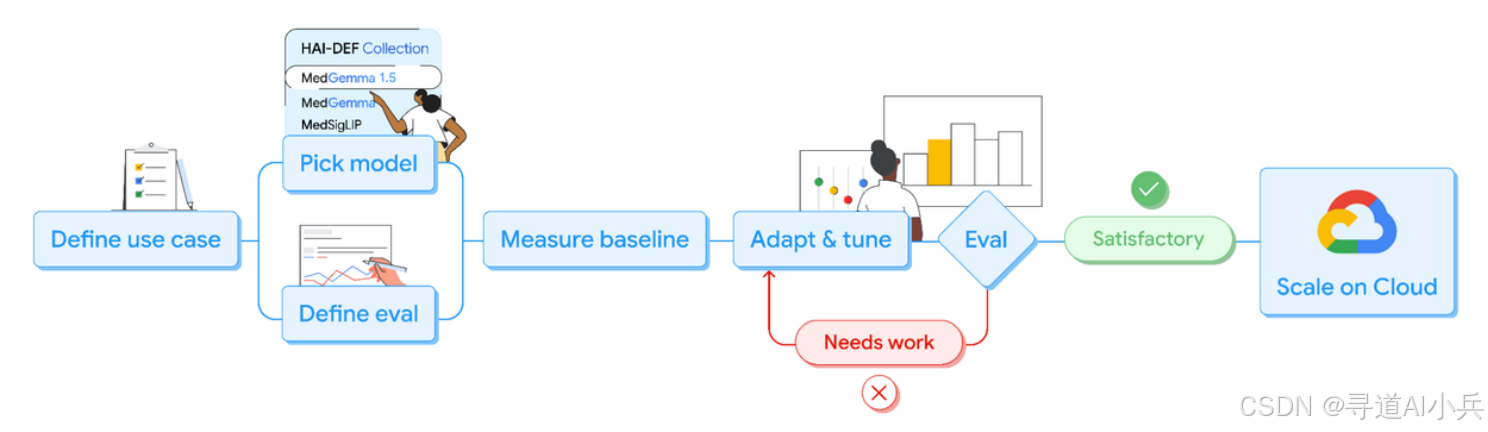
二、核心功能
(一)、三维容积影像解析
原生支持CT/MRI全容积数据的端到端处理,通过多切片联合编码机制实现三维空间上下文理解。CT疾病分类准确率达61%,MRI分类准确率从51%跃升至65%,提升14%。智能切片选择技术自动识别关键区域,支持头、胸、腹等多部位病灶的跨切面关联分析,实现肺结节连续追踪等高级功能。
(二)、全切片病理分析
创新支持多补丁联合分析病理全切片图像(WSI),可同时处理数十亿像素级别的多个高分辨率区域,实现跨区域的肿瘤细胞浸润模式识别。病理报告生成质量(ROUGE-L指标)从0.02飙升至0.49,达到专业病理模型水平,支持肿瘤分级、biomarker表达评估等金标准诊断任务。
(三)、纵向时序追踪
新增纵向影像分析能力,可对比不同时间点影像序列监测疾病进展。胸部X光时序对比宏平均准确率达66%,较1.0版本提升5%。自动识别肺炎、肿瘤等病灶的恶化、稳定或消退趋势,基于前后对比生成结构化随访建议,为慢病管理和疗效评估提供量化依据。
(四)、解剖定位与信息提取
解剖定位精度实现质的飞跃,在Chest ImaGenome数据集上IoU从3%提升至38%。支持心脏、肺叶、肋骨等结构的精确框选。实验室报告解析F1分数达78%,较1.0版本提升18%,可从非结构化化验单中提取关键指标,结合影像与检验数据进行多维度综合分析。
(五)、医疗文本推理
在纯文本医疗任务上表现优异,MedQA医学考试准确率达69%,电子病历问答(EHRQA)准确率从68%跃升至90%,提升22%。支持医学文献摘要、临床指南快速查询、病历结构化信息提取,可作为临床决策支持系统的自然语言接口,实现复杂医疗数据的智能检索与知识推理。
三、技术揭秘
(一)、架构设计
MedGemma 1.5采用SigLIP视觉编码器+Gemma 3语言解码器的多模态架构。视觉层基于SigLIP架构针对医学影像进行领域适配,支持可变分辨率输入,通过空间-时间补丁策略处理3D容积数据。语言层采用Gemma 3 4B模型,保留128K长上下文窗口,通过多模态投影层实现视觉-文本特征对齐。整体采用早期融合策略,在Transformer底层实现跨模态交叉注意力,支持影像、文本、数值的联合推理。
(二)、训练策略
模型遵循"通用预训练→医疗适配→任务微调"三阶段范式。首先继承Gemma 3的通用多模态权重,随后使用超过5000小时医疗音频、数百万张去标识化影像及报告进行继续预训练,采用对比学习增强影像-文本对齐,引入掩码建模提升病理特征敏感度。最后针对分类、检测、分割、报告生成等任务进行指令微调,结合LoRA参数高效微调技术和医师反馈的强化学习,优化临床实用性。
(三)、计算优化
坚持40亿参数轻量化设计,FP16精度下显存占用约9GB,单张RTX 4090即可流畅运行,支持4-bit/8-bit量化进一步降低部署门槛。采用混合专家(MoE)变体结构,通过路由机制激活特定子网络处理不同类型输入,实现动态计算深度——简单病例使用浅层网络快速响应,复杂病例自动启用深层推理,在性能与效率间取得最佳平衡。
(四)、多模态协同
MedGemma 1.5与同步发布的MedASR构成"听-视-思"医疗AI闭环。MedASR基于Conformer架构,在胸部X光口述场景下词错误率仅5.2%,较Whisper降低58%。两者协同实现语音指令实时转录为结构化文本,驱动影像分析生成报告草案,完整模拟放射科医师"口述-阅片-书写"的工作流,显著提升临床工作效率与标准化程度。
四、应用场景
(一)、放射科辅助诊断
覆盖胸部X光筛查、CT肺结节三维重建、MRI纵隔肿瘤评估等全流程。自动检测肺炎、肺结核、气胸等常见病变,计算结节体积倍增时间辅助良恶性鉴别,多序列分析软组织特性。在资源匮乏地区可作为初筛工具,在三甲医院承担病灶量化与随访对比,显著提升影像诊断效率与标准化水平。
(二)、病理科数字化 workflow
实现全切片病理图像的智能分析,包括癌症手术切缘评估、淋巴结转移筛查、免疫组化量化分析。自动标记疑似阳性切缘区域缩短术中冰冻诊断时间,快速定位乳腺癌等转移灶,提供HER2、Ki-67等标志物的半定量评分。支持CAP协议结构化报告生成,推动病理诊断从人工镜检向AI辅助的数字化转型。
(三)、临床决策支持
基于90%准确率的EHRQA能力构建医院内部知识问答机器人,支持"近三个月血红蛋白持续下降的糖尿病患者"等复杂查询。自动生成病历摘要,提取入院记录、出院小结关键信息。结合影像表现与检验指标进行多维度推理,模拟临床医生的综合诊断思维,为诊疗方案制定提供循证依据。
(四)、纵向慢病管理
针对COPD患者追踪历年胸片量化肺气肿进展,术后患者监测手术部位变化早期发现并发症。通过时序影像对比自动评估疾病演变趋势,生成个性化随访建议。支持居家健康管理的移动端应用,实现从急性期治疗向全周期健康管理的延伸,提升慢病控制的依从性与精准度。
(五)、医学教育与科研
自动生成带标注的教学影像与鉴别要点解释,基于真实数据分布合成罕见病例用于住院医师培训。支持影像组学高维特征自动提取,关联基因表达与预后数据加速临床研究。在临床试验中实现RECIST标准等终点的标准化测量,减少人为误差,为药物疗效评估提供客观量化工具。
五、快速使用
(一)、环境准备与模型获取
1. 硬件要求
- 最低配置:NVIDIA GPU with 12GB+ VRAM(支持4-bit量化推理)
- 推荐配置:NVIDIA RTX 4090(24GB)或A100(40GB/80GB)
- 纯CPU推理可行但速度较慢,建议用于测试而非生产环境
2. 模型下载
MedGemma 1.5为gated model,需先在Hugging Face完成授权申请:
# 安装依赖库
pip install torch torchvision transformers accelerate bitsandbytes
# 登录Hugging Face(需先获取access token)
huggingface-cli login
访问Google MedGemma 1.5-4B-it Hugging Face页面接受使用条款后,即可通过以下代码加载模型:
from transformers import AutoProcessor, AutoModelForImageTextToText
import torch
# 加载处理器和模型
model_id = "google/medgemma-1.5-4b-it"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForImageTextToText.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
print(f"模型加载完成,设备:{model.device}")
3. 模型变体选择
- MedGemma 1.5 4B-it:推荐版本,指令微调版,适合对话式交互
- MedGemma 1 27B:纯文本大模型,适合复杂医学推理(无多模态能力)
- MedASR:语音转文本专用模型,需配合音频处理流程使用
(二)、基础推理实践
场景1:胸部X光报告生成
from PIL import Image
import requests
# 加载示例胸部X光图像(替换为本地路径或URL)
image_path = "chest_xray.jpg" # 支持DICOM转换后的PNG/JPG
image = Image.open(image_path).convert("RGB")
# 构造医疗提示模板
prompt = """You are an expert radiologist. Analyze this chest X-ray and generate a structured report including:
1. Findings (pulmonary, cardiac, skeletal)
2. Impression (summary diagnosis)
3. Recommendations
Chest X-ray Analysis:"""
# 预处理
inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
# 生成报告
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
do_sample=False, # 医疗任务建议贪婪解码保证确定性
temperature=0.1
)
# 解码输出
report = processor.decode(outputs[0], skip_special_tokens=True)
print(report)
场景2:CT容积数据分析(3D)
MedGemma 1.5支持将CT的多个切片作为序列输入。实际操作中需先使用pydicom或SimpleITK加载DICOM序列,提取关键切片:
import pydicom
import numpy as np
from PIL import Image
def load_ct_slices(dicom_folder, slice_indices=None):
"""加载CT序列的指定切片"""
dicom_files = sorted([f for f in os.listdir(dicom_folder) if f.endswith('.dcm')])
if slice_indices is None:
# 自动选择中间20个关键切片
center = len(dicom_files) // 2
slice_indices = range(center-10, center+10)
images = []
for i in slice_indices:
ds = pydicom.dcmread(os.path.join(dicom_folder, dicom_files[i]))
img = ds.pixel_array.astype(float)
# 窗宽窗位调整(肺窗示例)
img = np.clip((img - 600) / 1200 * 255, 0, 255).astype(np.uint8)
images.append(Image.fromarray(img).convert("RGB").resize((512, 512)))
return images
# 加载CT序列
ct_slices = load_ct_slices("patient_ct_scan/")
# 构造3D分析提示
prompt = "Analyze this lung CT volume. Identify any nodules, masses, or infiltrates. Compare findings across slices:"
# 多图像输入(模型支持多图序列)
inputs = processor(
text=prompt,
images=ct_slices, # 传入切片列表
return_tensors="pt"
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1024)
analysis = processor.decode(outputs[0], skip_special_tokens=True)
print(analysis)
场景3:与MedASR的语音-影像协同
# 伪代码示例:语音输入触发影像分析
import sounddevice as sd
import wavio
# 1. 录制医生口述
print("Recording...")
recording = sd.rec(int(10 * 44100), samplerate=44100, channels=1, dtype='int16')
sd.wait()
wavio.write("dictation.wav", recording, 44100, sampwidth=2)
# 2. MedASR语音转文本(需单独加载MedASR模型)
# asr_model = load_medasr()
# text_prompt = asr_model.transcribe("dictation.wav")
text_prompt = "Compare with prior study from three months ago, focus on the right upper lobe nodule."
# 3. MedGemma分析当前影像+历史影像+语音指令
current_image = Image.open("current_cxr.jpg")
prior_image = Image.open("prior_cxr_3mo.jpg")
inputs = processor(
text=f"[Current]{text_prompt}\n[Prior Comparison]",
images=[current_image, prior_image],
return_tensors="pt"
).to(model.device)
result = model.generate(**inputs, max_new_tokens=512)
comparison_report = processor.decode(result[0], skip_special_tokens=True)
print(comparison_report)
(三)、本地部署与API封装
使用Gradio快速构建Web界面:
import gradio as gr
def medgemma_analysis(image, query_type):
prompts = {
"report": "Generate a radiology report for this image:",
"findings": "List all abnormal findings visible in this medical image:",
"differential": "Provide a differential diagnosis based on this image:"
}
prompt = prompts.get(query_type, prompts["report"])
inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.1)
return processor.decode(outputs[0], skip_special_tokens=True)
interface = gr.Interface(
fn=medgemma_analysis,
inputs=[
gr.Image(type="pil", label="Upload Medical Image (X-ray/CT/MRI)"),
gr.Radio(["report", "findings", "differential"], label="Query Type")
],
outputs=gr.Textbox(label="AI Analysis"),
title="MedGemma 1.5 Medical AI Assistant",
description="Upload medical images for AI-assisted analysis. Not for diagnostic use."
)
interface.launch(server_name="0.0.0.0", server_port=7860)
(四)、微调适配特定场景
针对特定病种(如肺结核筛查)进行LoRA微调:
from peft import LoraConfig, get_peft_model
# 配置LoRA
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
# 应用PEFT
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 仅训练<1%的参数
# 准备领域数据(肺结核影像-报告配对)
# 使用Hugging Face Trainer进行微调...
(五)、Google Cloud Vertex AI云端部署
对于生产环境,推荐部署至Google Cloud Vertex AI:
# 使用Google Cloud SDK部署端点
gcloud ai models upload \
--region=us-central1 \
--display-name=medgemma-15-4b \
--artifact-uri=gs://your-bucket/medgemma-1.5-4b \
--container-image-uri=us-docker.pkg.dev/vertex-ai/prediction/pytorch-gpu.1-13:latest
gcloud ai endpoints deploy-model medgemma-endpoint \
--model=medgemma-15-4b \
--accelerator=type=NVIDIA_TESLA_T4,count=1
生产环境注意事项:
- 启用VPC-SC(VPC Service Controls)保护患者数据隐私
- 配置DICOM adapter直接对接医院PACS系统
- 实施模型输出的后处理规则(如强制免责声明)
- 建立人工审核闭环,所有AI输出需经执业医师确认
六、结语
MedGemma 1.5的发布标志着开源医疗AI从"实验室玩具"向"临床工具"的关键跨越。其核心价值在于首次将3D CT/MRI分析能力开放给全球开发者,体现了Google降低医疗AI创新门槛的开放生态思维。然而,这是开发者的起点,而非临床的终点——尽管遵循Apache 2.0协议,直接用于患者诊疗仍需医疗器械监管审批。开发者必须建立严格的质量控制体系,包括本地化验证、偏见审计和人在回路机制。随着MedGemma Impact Challenge的推进,我们期待更多创新应用涌现,从基层筛查助手到三甲医院智能MDT系统,技术民主化正站在改变全球医疗可及性的历史节点上。
项目地址
- 官方博客:https://research.google/blog/next-generation-medical-image-interpretation-with-medgemma-15-and-medical-speech-to-text-with-medasr/
- MedGemma 1.5模型卡:https://developers.google.com/health-ai-developer-foundations/medgemma/model-card
- Hugging Face模型库:https://huggingface.co/google/medgemma-1.5-4b-it
- MedASR模型卡:https://developers.google.com/health-ai-developer-foundations/medasr/model-card

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)