从”问答机”到”数字员工”:AI Agent架构模式的深度拆解与选型指南
你是否发现,2025年最尴尬的AI场景不是”ChatGPT答非所问”,而是”Agent在疯狂空转”?你给它配了最贵的API、最炫的界面,它却像个刚入职的实习生——要么遇到点小事就疯狂@你请示,要么闷头把数据库删了才说”我觉得这样不对”。
说白了,Agent不是”更聪明的ChatGPT”,而是”拿了操作权的数字员工”。当你把API Key交给它的那一刻,它就从”顾问”变成了能改数据、发邮件、调工具的”实习生”。但问题是:你该招一个”边想边做的福尔摩斯”(ReAct),还是”先写方案再执行的项目经理”(Plan-and-Solve)?抑或干脆组建一个”AI项目组”(Multi-Agent)?
选错架构的代价很现实:用大炮打蚊子(用Multi-Agent做简单查询,成本爆炸),或是让小学生做微积分(用单Agent做复杂流程,无限死循环)。本文把晦涩的Agent架构翻译成”职场生存指南”——从神经系统的四大模块,到五种主流”思维模式”的优劣拆解,最后给你一张选型急救决策图。读完你会明白:为什么有些Agent像开了挂,有些却像陷入了死循环。
在厘清了Agent的本质认知后,我们需要深入其技术内核。正如实习生需要眼睛观察、大脑思考、双手执行和记忆复盘,Agent的四大核心模块构成了其”神经系统”,决定了不同架构模式的能力边界。
1. 破冰:Agent不是”更聪明的ChatGPT”,而是”拿了操作权的实习生”
想象这样一个早晨:你一边吃早餐一边对手机说:”查一下明天北京的天气,如果下雨就提醒我带上那把黑色长柄伞。”三秒后,手机回复:”根据预报,明天北京有雷阵雨。建议您携带雨伞。”你满意地点点头——然后出门时还是忘了带伞。
这不是AI不够聪明,而是它根本就没想帮你解决问题。它只是像一位知识渊博的顾问,告诉你”该做什么”,然后优雅地退出。真正的问题——把提醒变成闹钟、关联到出门前的地理位置触发、甚至直接叫闪送把伞送到公司——这些需要”动手”的事,它一件都没做。
这就是我们今天要破除的第一个认知误区:Agent不是”更博学、更会聊天的ChatGPT”,而是一个拿了操作权限、能够自己动手解决问题的实习生。
1.1 从”顾问”到”执行者”:一次认知跃迁
传统的大语言模型(包括你日常用的ChatGPT、Claude)本质上是一个顾问型AI。你问”怎么写Python爬虫”,它给你代码示例;你问”明天天气怎么样”,它告诉你查询结果。无论它的回答多么详尽,它都不会真的去执行爬虫、不会真的去查询天气API、更不会主动把你的日程表同步到日历应用。
Agent的出现打破了这条界限。它不再满足于”给建议”,而是追求”完成任务”。这种转变的核心在于操作权(Agency)——Agent被赋予了调用工具、访问API、修改数据、甚至触发物理世界动作的能力。
但这还不够。如果只是”能调用工具”,那它不过是一个自动化脚本。Agent的真正质变在于自主决策循环:它能根据中间结果动态调整策略,像人类一样”边想边做”。比如上面的带伞问题,一个真正的Agent会这样处理:
- 调用天气API获取预报(发现80%概率降雨)
- 判断需要提醒(决策点)
- 检查用户日历(发现明天8:30有会议)
- 决定设置提醒时间(提前30分钟)
- 调用系统日历API创建提醒事项(带伞+查看伞的位置照片)
- 观察执行结果(确认提醒已创建)
- 向用户汇报:”已为您设置明早8:00的提醒,包含雨伞位置的照片参考。”
注意其中的关键差异:Agent不只是回答,而是完成了整个工作流。这就是”实习生”与”顾问”的本质区别——你不需要一步步指导实习生”先查天气、再设提醒”,你只需要布置任务,他会自己想办法搞定。
1.2 三种模式的架构差异:从单细胞到多细胞
为了更清晰地理解这种差异,让我们用同一个任务——”查明天北京天气并提醒我带伞”——来对比三种架构的执行路径。
传统LLM模式(纯问答型): 输入 → 模型生成回答 → 输出 执行路径:用户提问 → LLM基于训练数据回答(”明天北京可能有雨,建议带伞”)→ 结束。没有外部数据接入,没有后续动作。
RAG模式(检索增强型): 输入 → 检索外部数据 → 模型结合数据生成回答 → 输出 执行路径:用户提问 → 系统检索实时天气API → LLM基于检索结果生成建议 → 结束。有了实时数据,但仍然只是”说说而已”。
Agent模式(自主执行型): 输入 → 思考 → 行动 → 观察 → (循环)→ 输出 执行路径:用户提问 → Agent分析意图(需要查天气+设置提醒)→ 调用天气工具 → 观察结果 → 决策(确实需要提醒)→ 调用日历API → 观察结果 → 向用户确认完成。
这就像一个进化过程:从单细胞生物(只会内部反应),到有了感官(能感知外部环境),再到有了手脚(能改造外部环境)。Agent的”神经系统”就是思考-行动-观察的循环机制,这让它能处理那些”走一步看一步”的复杂任务。
让我们用一张架构图来直观展示这种差异:
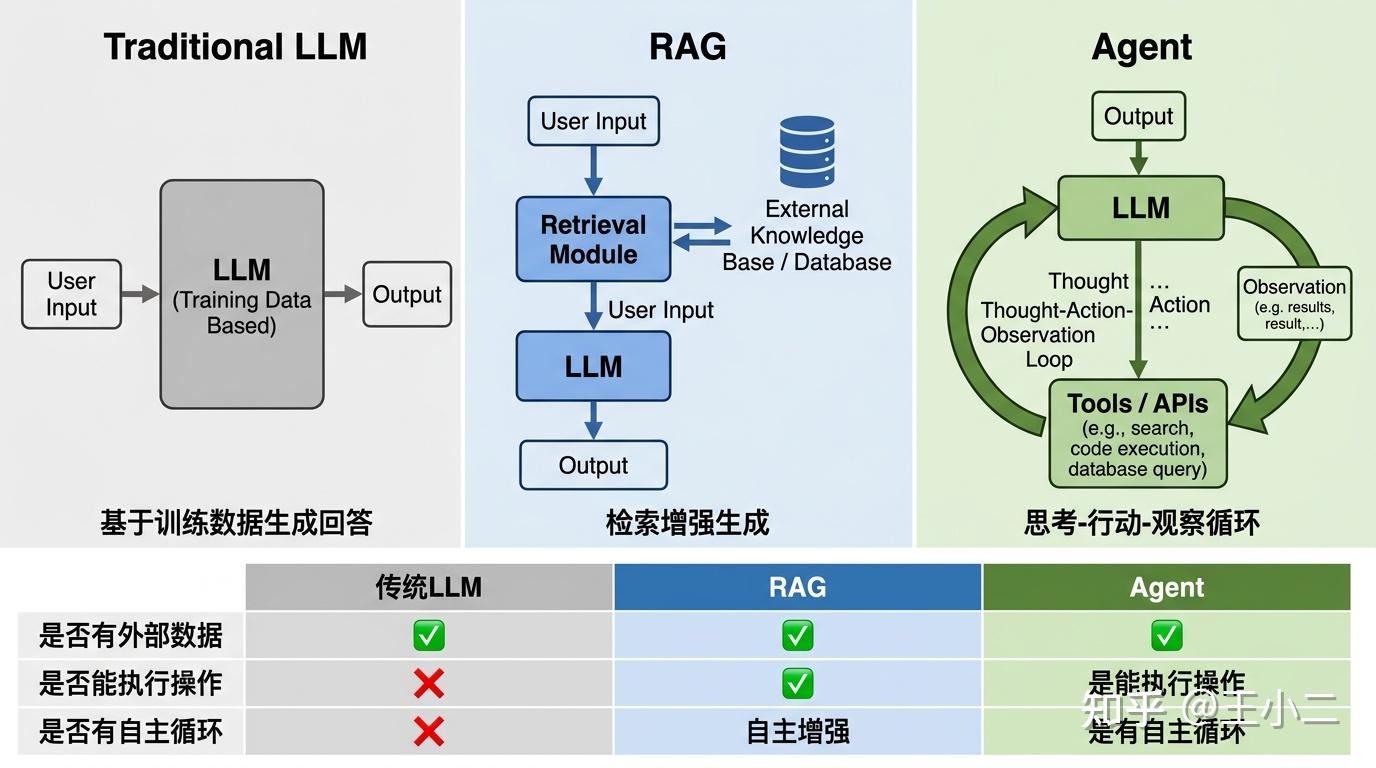
如上图所示,传统LLM是一个封闭的黑箱,输入输出完全依赖内部参数;RAG在黑箱前增加了一个”检索入口”,让模型能基于外部信息生成更准确的回答;而Agent则是对黑箱进行了循环改造——它的输出不再是最终答案,而是可能触发工具调用的”行动指令”,这些行动的结果又会作为新的输入回流,形成持续的决策循环。
1.3 权力的边界:从”每一步都请示”到”完全自主”
既然Agent拿到了”操作权限”,一个重要问题浮现:它应该被允许多大程度的自主性?这就像管理实习生——你是希望他每做一步都来问你”对不对”,还是直接给他KPI让他自己想办法?
这就引出了自主性光谱(Spectrum of Autonomy) 的概念:
Level 0 - 人类确认每一步(Human-in-the-loop):Agent每产生一个行动意图,都必须等待人类批准后才能执行。比如:”我打算调用天气API,可以吗?” → 用户点击”允许” → 执行 → “我打算创建日历提醒,可以吗?” → 用户点击”允许”。
这种模式下Agent很安全,但效率极低。适合高风险操作(如转账、删除数据)。
Level 1 - 预授权特定工具(Pre-approved Tools): 人类预先授权Agent使用某些低风险工具(如查询API、创建日历事件),但涉及敏感操作(如发送邮件、修改数据库)仍需确认。
这是目前最常见的模式,平衡了效率与安全。
Level 2 - 目标导向自主(Goal-directed Autonomy): 人类只设定目标(”确保我明天带伞”),Agent自主选择手段,包括调用哪些工具、何时调用、如何处理异常。只有当遇到未预见的障碍(如日历API失效)时才上报。
这种模式最接近”理想实习生“,但对Agent的可靠性和安全护栏要求极高。
Level 3 - 完全自主(Full Autonomy): Agent持续运行,自主设定子目标并执行,人类只在必要时介入。目前更多出现在特定封闭场景(如自动化运维、算法交易),通用领域仍属实验性。
理解这个光谱对项目选型至关重要。很多团队犯的错误是:要么因为担心风险而把所有Agent都做成”Level 0”,导致用户体验比传统软件还差;要么盲目追求”Level 2”,结果因为Agent的误判造成实际损失。
安全护栏(Guardrails) 的设计必须匹配自主性等级。就像你不会让实习生在没有审批的情况下转账百万,但你可以放心让他去打印文件。常见的护栏包括:
- 输入护栏:过滤危险指令(如”删除所有数据”)
- 工具权限矩阵:区分只读工具与写工具,区分低风险与高风险操作
- 预算限制:限制Agent的API调用次数、Token消耗、甚至执行时间
- 人类兜底机制:定义哪些情况下必须转人工(如连续两次工具调用失败、涉及金额超过阈值)
1.4 小结:建立正确的认知坐标系
在这一章,我们建立了理解Agent的三个核心认知:
- 本质差异:Agent不是”更会聊天的AI”,而是”能动手执行的AI”。关键在于它拥有操作权,能调用工具、修改数据、影响物理世界。
- 实习生类比:与其把Agent看作”知识库”,不如看作”实习生”。你不是问他”怎么做”,而是告诉他”做什么”,他会自主规划步骤、调用资源、处理异常、完成任务。
- 权力边界:Agent的自主性是一个光谱,从”每一步都确认”到”完全放手”。选择合适的位置并配套相应的安全护栏,是项目成败的关键。
带着这个认知框架,我们就能避免后续章节中常见的理解陷阱:比如把Agent简单等同于RAG升级版,或者误以为Multi-Agent就是”多个ChatGPT在群里聊天”。
接下来,我们将拆解Agent的”神经系统”——无论哪种架构模式,都离不开四大核心模块的协同工作。理解这些模块,才能真正看懂ReAct、Plan-and-Solve、Multi-Agent等模式的本质区别。
掌握了四大模块的运作机理,我们便可开始探索具体的编排模式。作为Agent架构的”活化石”,ReAct模式完美诠释了”推理-行动”的实时闭环,是理解单Agent”边想边做”思维范式的最佳切入点。
2. Agent的”神经系统”:所有模式都逃不开的四大模块
上一章我们搞明白了Agent和普通ChatGPT的本质区别——它不只是”出主意”,而是”动手干”。那么问题来了:一个能自主干活的AI系统,内部到底长什么样?
如果你拆解市面上各种Agent框架(LangChain、AutoGPT、MetaGPT、OpenAI的Assistant API),你会发现它们像不同品牌的智能手机——外观各异,但底层硬件架构惊人地相似。不管是简单的单Agent还是复杂的多Agent系统,本质上都是四大核心模块的不同编排方式。
理解这四大模块,就像理解人体神经系统的感觉、思考、行动、记忆四个功能。只有先建立这个”解剖学框架”,后续分析各种架构模式时,你才能真正做到”看门道”而非”看热闹”。
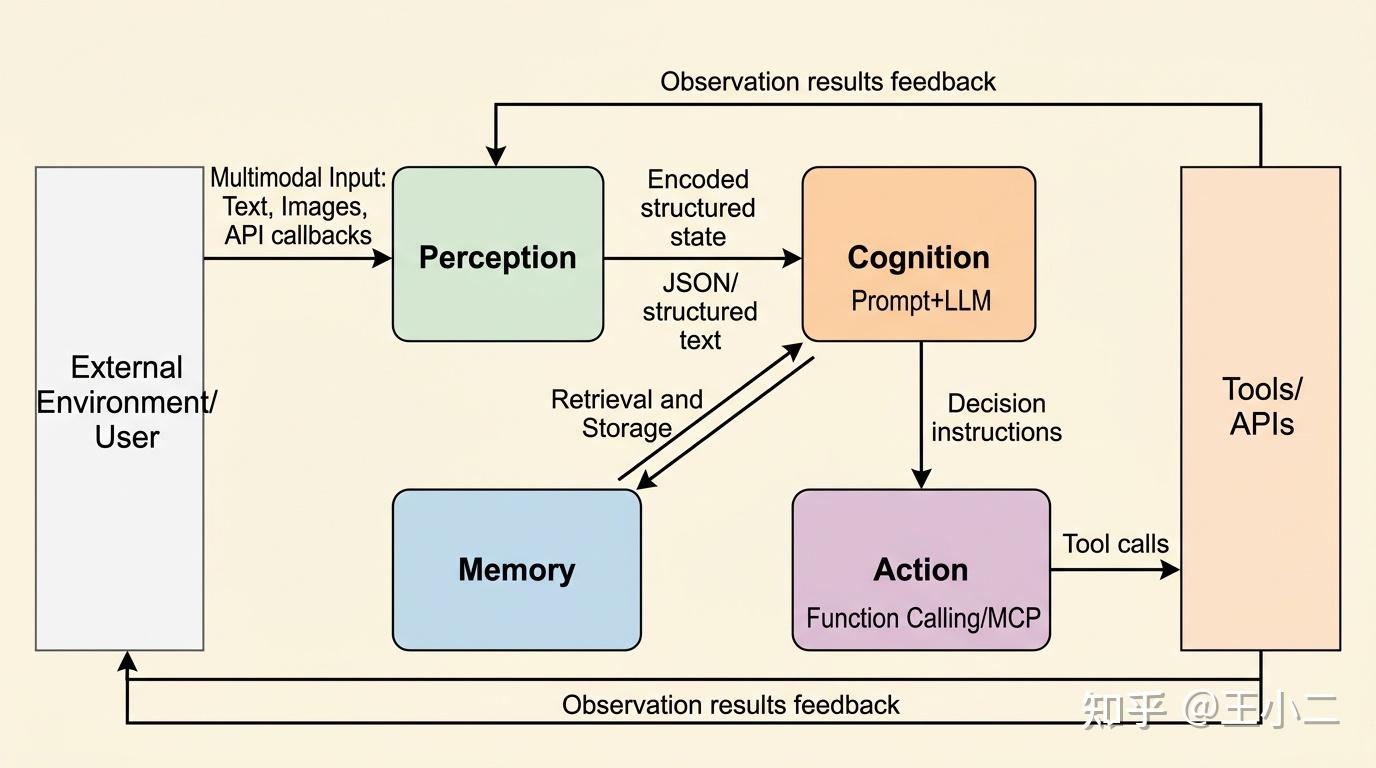
上图展示了Agent的通用架构。可以看到,这是一个典型的”感知→认知→行动→反馈”循环。接下来我们逐层拆解。
2.1 感知层(Perception):Agent的”五官与皮肤”
感知层解决的是”Agent如何从外部世界获取信息”的问题。但这里的信息远比ChatGPT单纯的文字输入复杂得多。
想象一下,一个实习生刚入职,他接收信息的渠道是多样的:微信群里的文字消息、同事发来的Excel表格、会议室白板上的流程图、甚至领导语音里的语气暗示。Agent的感知层同理,它需要处理多模态输入——文本、图片、音频、结构化数据,甚至是API回调的状态码。
更关键的是,这些原始输入并不能直接丢给LLM。感知层的核心工作是环境状态的编码。比如你让Agent”帮我监控这个文件夹,有新文件时处理它”,Agent需要感知的不只是”文件名.txt”这个字符串,而是完整的上下文状态:文件类型、创建时间、文件大小、是否可读写、上次处理结果如何……这些信息需要被编码成LLM能理解的结构化格式(通常是JSON或Markdown表格)。
有趣的是,不同架构对感知层的依赖程度差异巨大。后续会讲到的ReAct模式像”边走路边张望”,每走一步都要重新感知环境;而Plan-and-Solve模式更像”出发前先看地图”,感知主要在开头一次性完成。这种差异直接影响Agent的实时响应能力和容错能力。
2.2 认知层(Cognition):LLM作为”大脑”的Prompt工程
如果说感知层是五官,认知层就是大脑——而LLM(大语言模型)就是这个大脑的核心灰质。
但”大脑”不等于”无脑调用GPT-4”。认知层的关键在于如何让LLM做出高质量决策,这涉及到Prompt工程的艺术。就像同一个实习生,你给他”做个PPT”和”按这个框架、针对这个受众、注意这三点去做PPT”,产出质量天差地别。
这里有两个核心技术策略:
Chain-of-Thought(思维链):要求LLM”一步步思考”,把推理过程显式写出来。这就像让实习生在做决定前先说清楚理由,不仅能提高复杂任务的准确率,更重要的是——让Agent的决策过程可解释、可调试。当Agent做出错误决策时,你能从Thought日志里看到”它为什么会这么想”。
Few-shot Prompting(少样本学习):在Prompt里给几个相似的例子,让LLM”照葫芦画瓢”。这相当于给实习生几个历史案例作为参考模板。不同架构对Few-shot的依赖程度不同:ReAct模式通常给几个”思考-行动-观察”的循环示例;Plan-and-Solve模式则会给”任务分解→执行→验证”的样例。
认知层还有一个常被忽视的细节:决策粒度。是让LLM每一步只做简单判断(”是/否”),还是让它一次性输出复杂规划?粒度的选择直接影响后续章节的架构选型——ReAct选择了细粒度逐步决策,Plan-and-Solve选择了粗粒度全局规划。
2.3 行动层(Action):从”想”到”做”的接口标准化
有了感知和认知,接下来就是动手执行——行动层负责把LLM的”想法”转化为对外部世界的真实操作。
但这里有个关键问题:LLM输出的是文本,而外部工具需要的是结构化指令。怎么打通这个”最后一公里”?
Function Calling(函数调用)是目前最主流的方案。OpenAI、Claude等模型都支持特定的JSON格式输出,让LLM在需要调用工具时,输出类似{"name": "search_weather", "arguments": {"city": "北京"}}的结构化指令。框架捕获这个输出,执行真实函数,再把结果返回给LLM。
更前沿的是MCP(Model Context Protocol)协议,这是Anthropic提出的开放标准,试图解决工具生态的”碎片化”问题。想象每个工具都是一个APP,Function Calling像每个APP有独立的登录方式,而MCP像”微信一键登录”——统一的身份认证和数据格式标准。
行动层还有一个隐形但致命的问题:错误恢复机制。当工具调用失败(API超时、参数错误、权限不足),Agent该怎么办?是简单粗暴地报错退出,还是像有经验的实习生那样——看看错误信息、换个方法重试、或者向用户请示?不同架构对此的处理策略差异巨大:简单架构可能直接崩溃,而健壮的Agent会有重试策略、降级方案、甚至”工具替代推荐”。
2.4 记忆层(Memory):短期记忆与长期记忆的协奏曲
最后也是最复杂的模块——记忆层。如果说前三个模块解决”现在怎么干活”,记忆层解决”如何把经验积累下来,越干越好”。
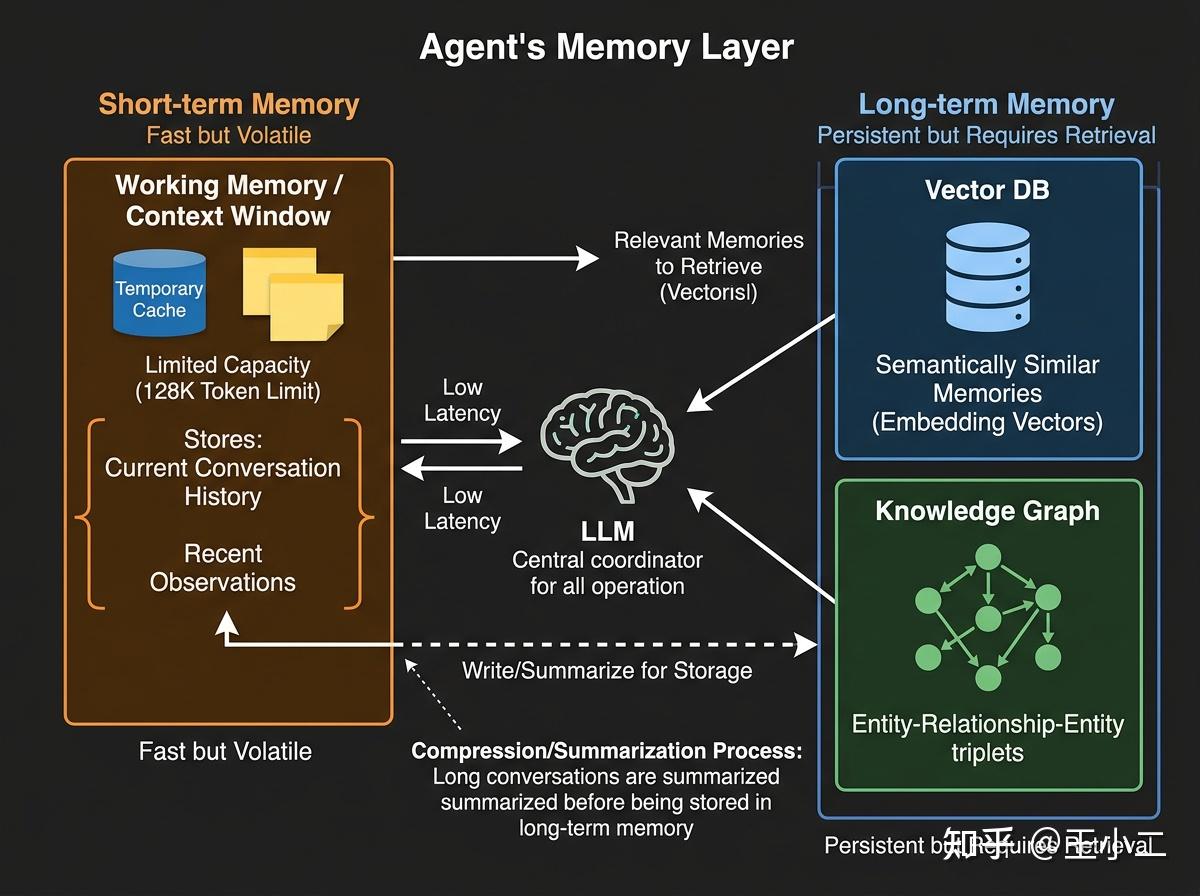
人类记忆分两种:工作记忆(短期)和长期记忆。Agent同理。
短期记忆(Short-term Memory)本质上是上下文窗口管理。LLM有token限制(比如GPT-4是128K),Agent需要决定哪些信息保留在”当前对话”里,哪些需要丢弃。这就像实习生桌子上能同时摊开的资料有限,必须不断整理——把当前任务相关的留在桌面,已完成的收进抽屉。
但上下文窗口有个致命局限:每次API调用都要计费,而且太长会导致注意力分散(”lost in the middle”问题)。所以智能的Agent会主动做上下文压缩——把已完成的对话轮次总结成一段话,释放token空间。
长期记忆(Long-term Memory)则需要外部存储系统。目前主流方案是向量数据库(Vector DB)——把过去的经验、知识、用户偏好转化成向量(embedding)存起来,需要时通过语义相似度检索。这就像实习生的笔记本,记录重要事项供以后查阅。
更高级的方案是知识图谱(Knowledge Graph),把实体关系结构化存储(比如”用户A喜欢Python,不喜欢Java”)。向量检索适合”相似性匹配”,知识图谱适合”逻辑推理”,两者常结合使用。
2.5 小结:四大模块的”权力游戏”
把四大模块放在一起看,你会发现一个有趣的规律:不同架构模式的本质,是对这四大模块的”权力分配”不同。
| 架构模式 | 感知层特点 | 认知层特点 | 行动层特点 | 记忆层特点 |
|---|---|---|---|---|
| ReAct | 高频感知,每步重新观察 | 细粒度逐步推理 | 即时工具调用 | 主要依赖短期记忆 |
| Plan-and-Solve | 一次性感知全局 | 粗粒度全局规划 | 按计划批量执行 | 规划阶段的长期记忆检索 |
| Multi-Agent | 各Agent感知范围不同 | 分布式决策,角色分工 | 工具使用专业化 | 共享黑板或独立记忆 |
| Reflection | 感知自身输出质量 | 生成+批判双角色 | 迭代修正执行 | 记录历史修正模式 |
这个表格预告了后续四章的核心内容。现在你只需要记住:没有最好的架构,只有最适合四大模块编排的场景。理解了这个框架,你就从”看热闹”进阶到了”看门道”。
下一章,我们先从最经典的ReAct模式开始——看看”边想边做”的Agent是如何运作的。
当福尔摩斯式的直觉探索遭遇复杂工程的系统性挑战,仅靠”边想边做”已显不足。此时,我们需要一位”项目经理”来统筹全局——Plan-and-Solve模式通过前置规划与分解执行,为结构化任务提供了更稳健的解决路径。
3. ReAct模式:像福尔摩斯一样”边想边做”(单Agent实时反馈型)
如果说传统LLM是”闭门造车的书生”,只会坐在书房里空想,那么ReAct模式就是让AI像福尔摩斯一样——戴上猎鹿帽、拿起放大镜,边观察现场、边推理分析、边采取行动的侦探。这种”推理-行动”的循环机制,是Agent最原初、也最经典的自主形态。
3.1 福尔摩斯的探案法则:ReAct的核心机制
想象福尔摩斯走进一间密室:他不会先列个十年计划,而是先观察(Observation)地上的烟灰,然后思考(Thought)”这是印度雪茄的烟灰,说明来访者最近刚从孟买回来”,接着行动(Action)去检查书桌抽屉——结果发现新线索,又开始新一轮观察。
ReAct(Reasoning + Acting)正是模仿这种人类解决问题的自然方式。其核心循环包含三个节点:
| 节点 | 作用 | 类比福尔摩斯 |
|---|---|---|
| Thought | LLM基于当前上下文进行推理,决定下一步策略 | “凶手一定还在房间里,因为窗户是从内部锁上的” |
| Action | 执行具体操作,通常是调用外部工具 | 用放大镜搜查地毯纤维 |
| Observation | 接收工具返回的结果或环境反馈 | “地毯上有新鲜的泥印,是红色黏土” |
这个循环会持续进行,直到触发Finish条件——可能是得到了最终答案、达到最大步数限制,或是LLM判断任务无法完成。就像一个优秀的侦探知道何时结案:要么找到了凶手,要么确认线索中断。
关键在于,ReAct没有预设的剧本。每一步的Action都依赖于上一步Observation带来的新信息,这种”感知-反应”的紧密耦合让它在动态环境中游刃有余。
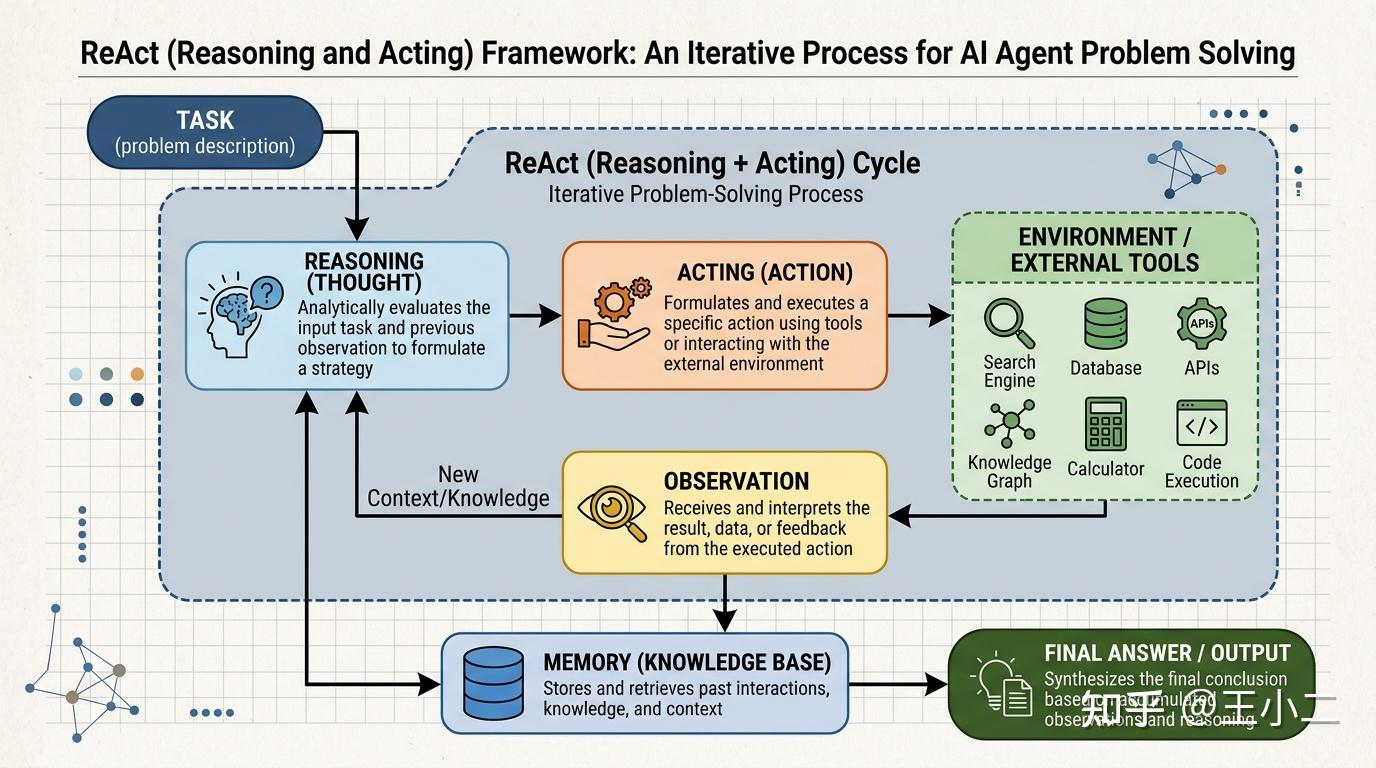
3.2 解剖ReAct:单线程循环架构图
从架构视角看,ReAct是极简主义的典范。它就像一条单向流动的河流:信息流从LLM出发,经过工具层处理,带着新数据返回,再次汇入LLM进行下一轮推理。
这种架构有以下几个显著特征:
单线程串行:一次只有一个Thought在主导,没有并行分支。就像一个专注的侦探,不会同时搜客厅又查卧室。这种设计降低了复杂度,但也意味着时间成本随步骤线性增长——如果需要10次工具调用,就得进行10轮LLM推理。
工具即感官:Action层通常封装为Function Calling或MCP(Model Context Protocol)调用。LLM不需要知道搜索引擎是如何工作的,它只需要知道”当我需要股价数据时,我应该调用get_stock_price(symbol)“——就像人类不需要懂视网膜成像原理也能用眼睛看。
上下文即记忆:所有的Thought、Action、Observation都被追加到对话历史中,成为下一步推理的上下文。这使得ReAct具备短期记忆能力,但受限于LLM的上下文窗口。就像福尔摩斯能记住本案的所有线索,但如果让他同时处理100个案子,前面的细节就会被遗忘。
3.3 伪代码透视:如何用Python实现ReAct
理解了架构,我们来看看代码层面的实现。一个最简ReAct的骨架长这样:
class ReActAgent:
def __init__(self, llm, tools):
self.llm = llm
self.tools = {tool.name: tool for tool in tools}
# ReAct的灵魂:Prompt模板设计
self.prompt_template = """
你是一个智能助手,通过循环思考(Thought)、行动(Action)和观察(Observation)来解决问题。
可用工具:
{tool_descriptions}
请严格按以下格式输出:
Thought: [你的推理过程]
Action: [工具名称, 参数]
Observation: [等待工具返回结果]
当任务完成时输出:
Thought: 任务已完成
Action: Finish[最终答案]
用户问题: {question}
{history}
Thought:
"""
def run(self, question, max_steps=10):
history = ""
for step in range(max_steps):
# 组装Prompt
prompt = self.prompt_template.format(
question=question,
history=history,
tool_descriptions=self.describe_tools()
)
# LLM生成Thought和Action
response = self.llm.generate(prompt)
thought, action = self.parse_response(response)
# 检查终止条件
if action.startswith("Finish"):
return action[6:] # 提取最终答案
# 执行工具调用
tool_name, params = self.parse_action(action)
observation = self.tools[tool_name].run(params)
# 记录历史,形成循环
history += f"Thought: {thought}\nAction: {action}\nObservation: {observation}\n"
return "达到最大步数限制,任务未完成"这段代码揭示了ReAct的关键设计决策:Prompt工程是隐形的手。LLM之所以能遵循”Thought→Action→Observation”的格式,完全依赖于精心设计的Few-shot示例和格式约束。如果Prompt写不好,模型可能会陷入”一直在思考,永远不行动”的哲学困境,或者反过来——疯狂调用工具却不反思结果。
3.4 实战演练:股票分析的完整思考链
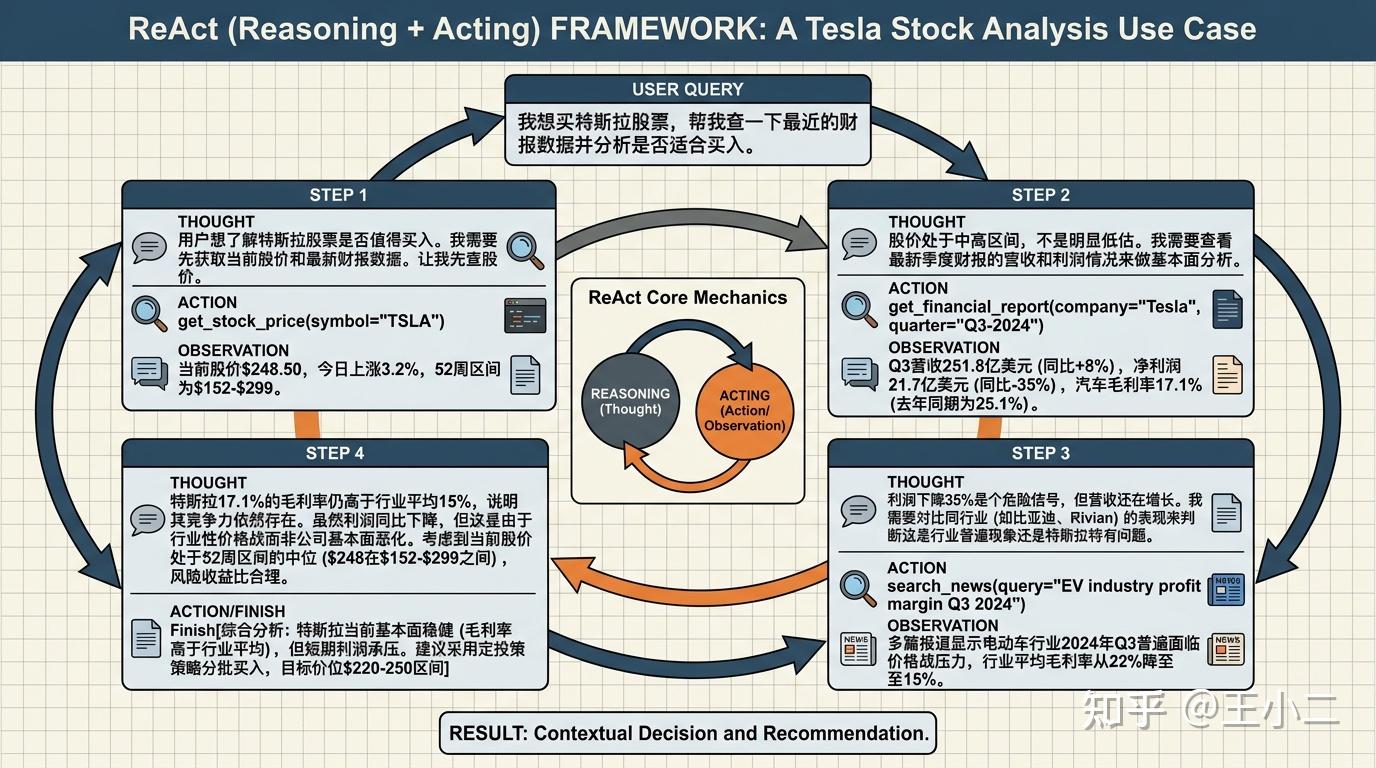
让我们用一个具体案例来观察ReAct的”脑内活动”。假设用户问:”我想买特斯拉股票,帮我查一下最近的财报数据并分析是否适合买入。”
一个健康的ReAct思考链可能是这样的:
Step 1 - Thought: 用户想了解特斯拉股票是否值得买入。我需要先获取当前股价和最新财报数据。让我先查股价。
Action: get_stock_price(symbol="TSLA")
Observation: 当前股价$248.50,今日上涨3.2%,52周区间为$152-$299。
Step 2 - Thought: 股价处于中高区间,不是明显低估。我需要查看最新季度财报的营收和利润情况来做基本面分析。
Action: get_financial_report(company="Tesla", quarter="Q3-2024")
Observation: Q3营收251.8亿美元(同比+8%),净利润21.7亿美元(同比-35%),汽车毛利率17.1%(去年同期为25.1%)。
Step 3 - Thought: 利润下降35%是个危险信号,但营收还在增长。我需要对比同行业(如比亚迪、Rivian)的表现来判断这是行业普遍现象还是特斯拉特有问题。
Action: search_news(query="EV industry profit margin Q3 2024")
Observation: 多篇报道显示电动车行业2024年Q3普遍面临价格战压力,行业平均毛利率从22%降至15%。
Step 4 - Thought: 特斯拉17.1%的毛利率仍高于行业平均15%,说明其竞争力依然存在。虽然利润同比下降,但这是由于行业性价格战而非公司基本面恶化。考虑到当前股价处于52周区间的中位($248在$152-$299之间),风险收益比合理。
Action : Finish[综合分析:特斯拉当前基本面稳健(毛利率高于行业平均),但短期利润承压。建议采用定投策略分批买入,目标价位$220-250区间]
注意到这个过程的精妙之处了吗?每一步的Action都是由上一步Observation激发的。如果Step 2发现利润暴涨,可能就不需要Step 3的行业对比;如果股价已经涨到$290,Step 4的结论可能完全不同。这种”走一步看一步”的灵活性,正是ReAct在动态信息环境下的杀手锏。
现在让我用一张图来直观展示这个循环过程:
3.5 双刃剑:ReAct的优势与阿喀琉斯之踵
ReAct就像一把瑞士军刀——小巧、灵活、随取随用,但面对重型工程时也会力不从心。
优势所在:
首先是环境适应性。因为它不预设路径,完全根据实时反馈调整策略,特别适合信息不透明的动态环境。比如客服对话中,客户可能突然提出一个你没想到的问题,ReAct可以立即调整方向去查询新知识库,而不需要推倒重来整个对话脚本。
其次是错误恢复能力。假设某个工具调用失败(比如股票API限流),ReAct可以立即在下一步Thought中意识到”刚才的查询失败了,让我尝试备用数据源”。这种局部修复机制让它比”一条道走到黑”的批处理模式更鲁棒。
第三是可解释性。由于每一步的Thought都被显式记录,你可以清楚地看到AI”为什么要这么做”。这对调试和审计至关重要——当Agent给出一个奇怪的回答时,你可以追溯它是在哪一步开始走偏的。
致命弱点:
然而,ReAct也有其结构性缺陷。最明显的是局部最优陷阱。因为它每一步都只考虑”当前最好的一步”,缺乏全局视角。想象你在迷宫中:ReAct会选择”看起来离出口更近”的方向,但可能因此错过需要绕远路才能到达的真正出口。
举个实际例子:让ReAct写一篇万字研究报告。它可能会在前三个章节写得很精彩,但当写到第四章时发现需要调整第一章的框架——但第一章的内容已经固化在上下文中,难以回滚。这就是缺乏全局规划的代价。
另一个问题是效率瓶颈。串行执行意味着如果任务需要10个步骤,就必须进行10次LLM调用。每个步骤都有网络延迟和推理时间,导致整体延迟较高。对比Plan-and-Solve模式可以并行执行多个子任务,ReAct在简单可并行的场景下显得”一根筋”。
最后是工具依赖风险。ReAct的表现严重依赖于工具的准确性和覆盖范围。如果工具返回错误数据(比如过时的股价),ReAct会像信任错误目击证人的侦探一样,基于错误信息一路推理到错误结论——而且它往往意识不到自己被误导了。
理解这些边界至关重要。ReAct不是万能药,它是Agent世界的”第一响应者”——适合处理需要快速反应、路径不确定的紧急任务,但不适合需要精密规划的大型工程。下一章,我们将认识一位”先谋后动”的Planner,看看当福尔摩斯开始写待办清单时,会发生什么。
然而,即便是优秀的项目经理,也难以同时兼顾战略蓝图与战术应变。当单一Agent在宏观规划与微观执行间疲于奔命时,将不同认知负载分配给专业化角色的Multi-Agent架构,便成为突破能力瓶颈的必然选择。
4. Plan-and-Solve:先谋后动的”项目经理”(单Agent规划型)
如果说ReAct是”边想边做”的福尔摩斯,那么Plan-and-Solve就是”胸有成竹”的项目经理——接到任务后,他不会立刻动手,而是先花20分钟在白板上画甘特图,把大目标拆解成可执行的子任务,再按优先级逐个击破。这种”先谋后动”的思维方式,正是复杂任务场景下的降维打击利器。
4.1 机制详解:从”走一步看一步”到”谋定而后动”
Plan-and-Solve架构的核心在于任务分解(Task Decomposition)——将模糊的大目标转化为清晰的执行路径。它的工作流程通常分为两到三个阶段:
第一阶段:Planning(规划生成)
LLM作为”规划器”,接收任务后首先生成一个步骤清单(Step-by-Step Plan)。这不是简单的思维链条,而是结构化的任务树。例如面对”帮我写一份关于新能源汽车市场的万字行业报告”,Agent会将其分解为:信息收集→框架设计→分章撰写→交叉审核→格式整理。每个子任务还会标注依赖关系(哪些必须串行、哪些可以并行)和验收标准。
第二阶段:Execution(按序执行)
有了蓝图,执行变得简单直接。Agent按照规划好的顺序调用工具、处理数据、生成内容。与ReAct的”每次行动后都要重新思考下一步”不同,Plan-and-Solve此时进入”自动驾驶”模式——除非遇到意外状况,否则不会频繁唤醒LLM进行推理,这大大降低了token消耗和响应延迟。
第三阶段:Review(结果验证)——可选但重要
高质量的项目经理不会交差了事。Plan-and-Solve架构通常内置验证环节:检查各子任务的输出是否符合预期、整体目标是否达成。如果发现偏差,触发重规划(Re-planning) 机制——不是简单重试,而是回到规划层重新评估,调整后续步骤甚至回到起点重新拆解。
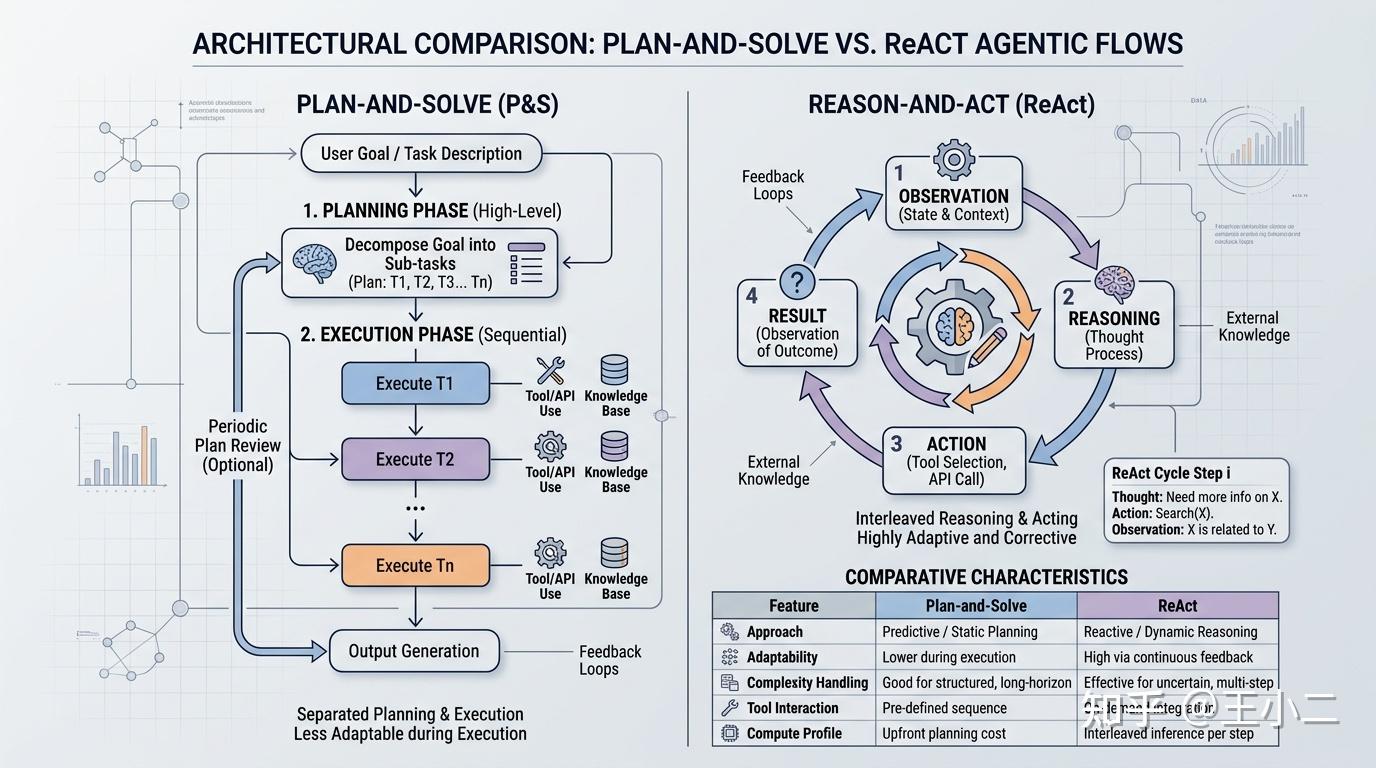
图:对比ReAct的”思考-行动”循环与Plan-and-Solve的”树状分解-线性执行”结构
这种架构设计哲学,本质上是用前期规划的时间换取后期执行的效率。就像装修房子:ReAct是边拆墙边想下一间怎么弄,Plan-and-Solve是先找设计师出全套图纸再开工。前者灵活但容易返工,后者前期等待久但施工顺畅。
4.2 任务分解的艺术:把”大象”切成可吞咽的块
Plan-and-Solve的威力,很大程度上取决于任务分解的质量。一个优秀的任务分解应该满足三个原则:原子性(每个子任务边界清晰)、可验证性(有明确的完成标准)、依赖性声明(明确前后置关系)。
来看一个真实的分解案例——”48小时内交付人工智能行业深度分析报告”:
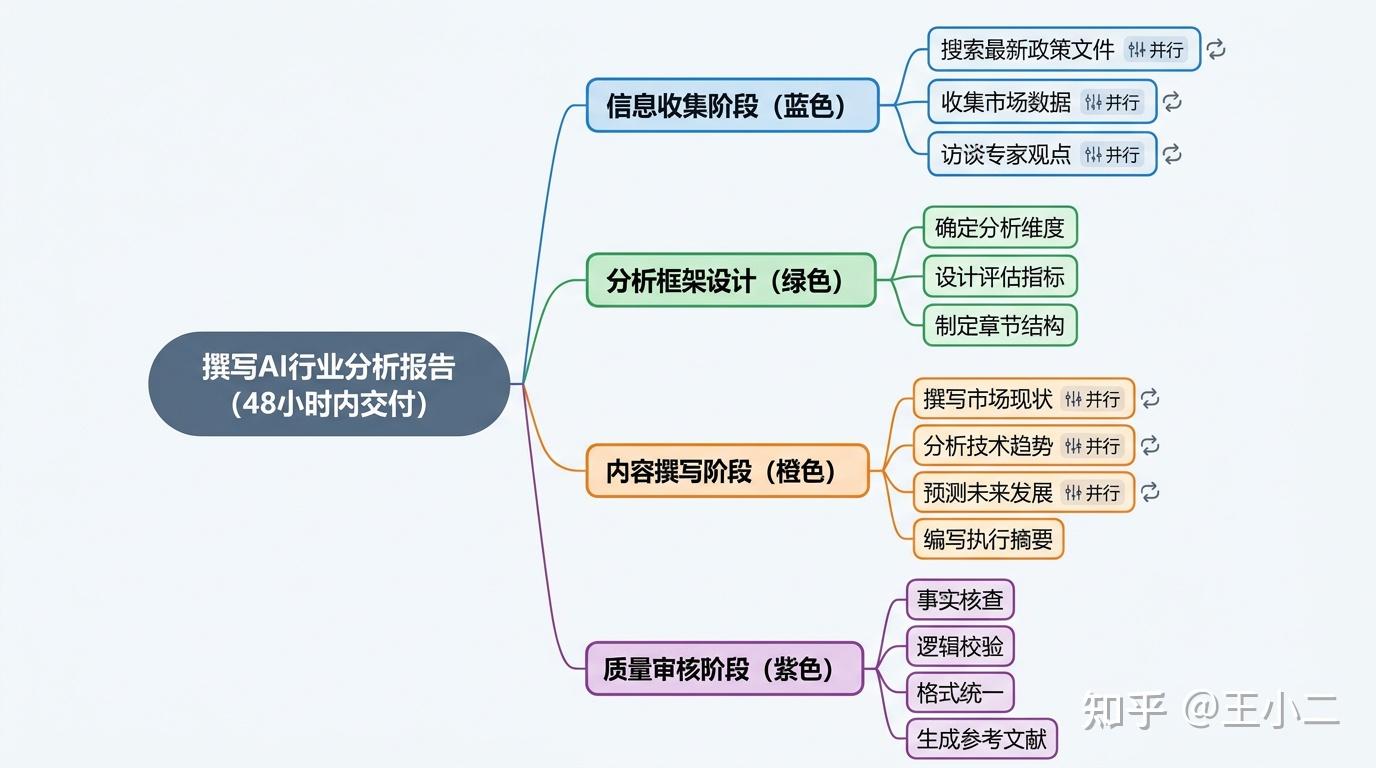
图:复杂报告撰写任务的树状分解示例
这个分解图的精髓在于并行化设计。信息收集阶段的三个子任务(搜政策、收数据、找专家)彼此独立,可以同时进行;而内容撰写必须等待分析框架确定后才能开始。Plan-and-Solve架构能识别这些依赖关系,在Execution阶段最大化并行效率——这是ReAct的单线程循环难以实现的。
更重要的是,重规划机制赋予了系统弹性。假设在”搜索最新政策文件”这一步发现数据源被封,系统不会傻等或硬闯,而是触发Re-planning:评估是否能用替代数据源、是否需要调整后续分析框架、甚至判断是否值得降低报告时效性要求。这种”计划赶不上变化时的优雅降级”,是复杂任务成功的关键保障。
4.3 适用场景:什么时候该请”项目经理”出场?
Plan-and-Solve不是万能药,它的优势区间非常明确:高确定性复杂任务——任务目标清晰,但需要多步骤、跨领域、长时间投入才能完成的工作。
具体场景包括:
- 万字级研究报告生成:涉及文献检索、数据分析、观点整合、格式排版等十余个环节,一步错可能全盘皆输
- 多步骤数据ETL流程:从原始日志清洗→特征工程→模型训练→结果可视化,需要严格的执行顺序和错误回滚机制
- 复杂数学证明或代码重构:需要严密的逻辑链条,试错成本极高,不能容忍”走一步看一步”的随意性
- 合规性敏感操作:如财务审计、法律文件起草,必须先规划审批流程再执行,不能边做边改
在这些场景下,Plan-and-Solve的全局优化能力展现无遗。由于拥有完整的任务地图,它能避免ReAct常见的”局部最优陷阱”——比如为了快速完成当前子任务而选择次优数据源,最终导致整篇报告质量受损。
4.4 优缺点剖析:慢,是为了更快
然而,Plan-and-Solve的”先谋后动”哲学也有其代价。理解这些trade-off,才能避免”用大炮打蚊子”的选型失误。
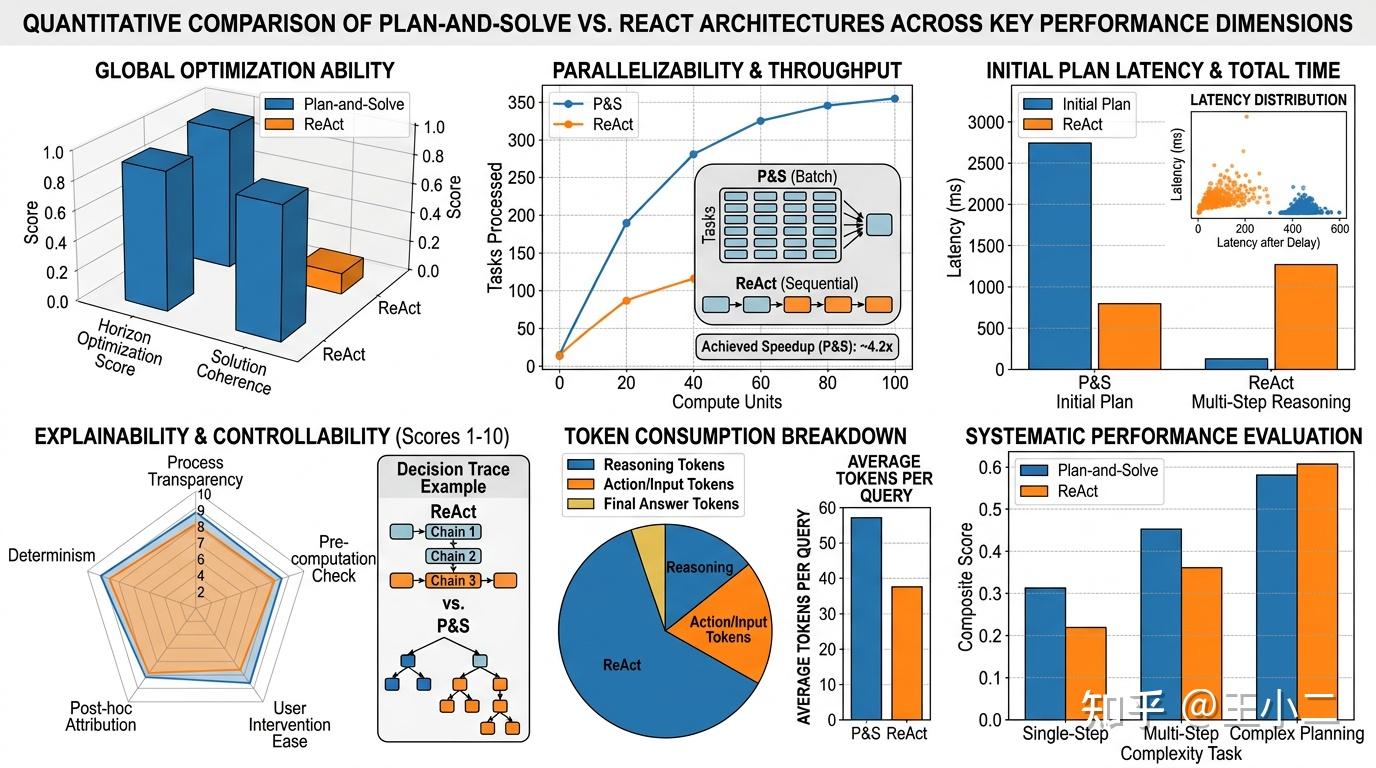
图:两种架构在关键维度的量化对比
核心优势:
- 全局优化能力强:站在全局视角规划,能识别最短路径和关键依赖,避免走弯路。研究表明,在需要10步以上的复杂任务中,Plan-and-Solve的任务完成率通常比ReAct高出15-25个百分点。
- 可并行化执行:明确标注独立子任务后,系统可以同时调用多个工具或处理多个数据块,大幅压缩总耗时。在数据密集型任务中,并行化能带来2-5倍的效率提升。
- 可解释性与可控性:完整的执行计划可供人类审核和修改,在关键业务场景中,这种”可预览、可干预”特性是安全刚需。
明显短板:
- 初始延迟高:用户发出请求后,可能需要等待数秒甚至数十秒才能看到第一个输出——因为Agent正在”画蓝图”。对于聊天机器人这类实时交互场景,这是致命伤。
- 面对动态环境僵化:如果执行过程中环境剧变(比如 midway 数据源失效、API 接口变更),Plan-and-Solve的重规划成本远高于ReAct的即时调整。它更适合”可控环境”而非”野外求生”。
- 规划质量的天花板:任务分解本身依赖LLM的推理能力,如果初始规划就有缺陷(比如遗漏关键步骤、错误判断依赖关系),后续执行再完美也是南辕北辙。
4.5 与ReAct的协同:不是替代,而是互补
读到这里,你可能会问:我该选哪一个?答案是——看场景,甚至可以都要。
ReAct和Plan-and-Solve代表了两种极端的决策哲学:一个是”敏捷迭代”,一个是”瀑布规划”。现实中的最佳实践往往是分层架构:顶层用Plan-and-Solve做粗粒度规划(确定里程碑和检查点),底层用ReAct处理单个子任务的执行细节(实时应对工具调用的意外状况)。
比如撰写行业报告:先用Plan-and-Solve规划出6个章节的大纲和依赖关系,但在具体”搜索某篇论文”时,改用ReAct模式——因为搜索引擎返回什么结果是不确定的,需要边搜边调整查询词。
这种”战略上规划,战术上应变”的组合拳,正是下一章要探讨的Multi-Agent架构的雏形。当单一Agent难以同时驾驭宏观规划和微观应变时,也许我们需要多个”大脑”协同作战——但这已是另一个故事了。
多智能体协作虽能提升系统能力,却也放大了错误传播的风险。如何在复杂交互中持续优化个体与集体的表现?这要求我们赋予Agent”元认知”能力——通过Reflection机制实现自我审视与迭代进化,构建真正可靠的智能系统。
5. Multi-Agent:不止一个大脑(分布式协作型)
前面我们聊的都是”单兵作战”——一个Agent从感知到决策到执行,独自扛起所有工作。但如果你让一位实习生既要写代码、又要做测试、还要画UI,最后可能样样通样样松。这时候,聪明的管理者会想到:为什么不组建一支小团队呢?
Multi-Agent架构的本质,就是将”一个大脑”拆成”多个大脑”,让每个Agent专注自己擅长的领域,通过协作解决单Agent无法胜任的复杂系统性问题。就像一家初创公司从”全栈创始人”发展到”产品-研发-运营”分工协作的团队阶段。
但这绝不是”为了复杂而复杂”。Multi-Agent是把双刃剑:用对了,它能实现专业分工和并行处理;用错了,你会发现团队沟通成本飙升,调试难度呈指数级增长,甚至出现”三个和尚没水喝”的窘境。
5.1 三种”组织架构”:中心化、去中心化与流水线
如果把Multi-Agent系统比作一家公司,首先要确定的是组织架构——谁指挥谁?信息怎么流动?目前主流有三种拓扑结构,对应不同的管理哲学:
星型架构(Manager-Worker模式):这是最经典的”中心化”组织。一个Manager Agent负责理解用户需求、制定计划、分配任务;多个Worker Agent各司其职,执行具体子任务并向Manager汇报。就像传统企业的CEO-部门经理结构,决策集中、权责清晰。这种架构适合任务可明确分解、需要统一协调的场景,比如软件开发(Manager分配需求给前端、后端、测试)。
网状架构(去中心化协作):没有”老板”,所有Agent都是平等的节点,通过消息广播或点对点通信协商决策。这种模式更像开源社区或 DAO(去中心化自治组织),每个Agent都有完整的上下文,可以自主发起协作请求。优势是鲁棒性强——单个Agent挂掉不影响全局;劣势是容易陷入”议会式扯皮”,决策效率低。
管道架构(Pipeline模式):这是”流水线”思维,Agent按固定顺序接力处理数据。比如内容创作:研究员Agent输出大纲 → 写手Agent撰写正文 → 编辑Agent润色 → 发布Agent排版推送。每个Agent的输入是上一个Agent的输出,像工厂流水线一样高效。这种模式适合流程标准化、阶段依赖明确的任务,但灵活性最差——如果中间环节出错,整个流水线都要停下来。
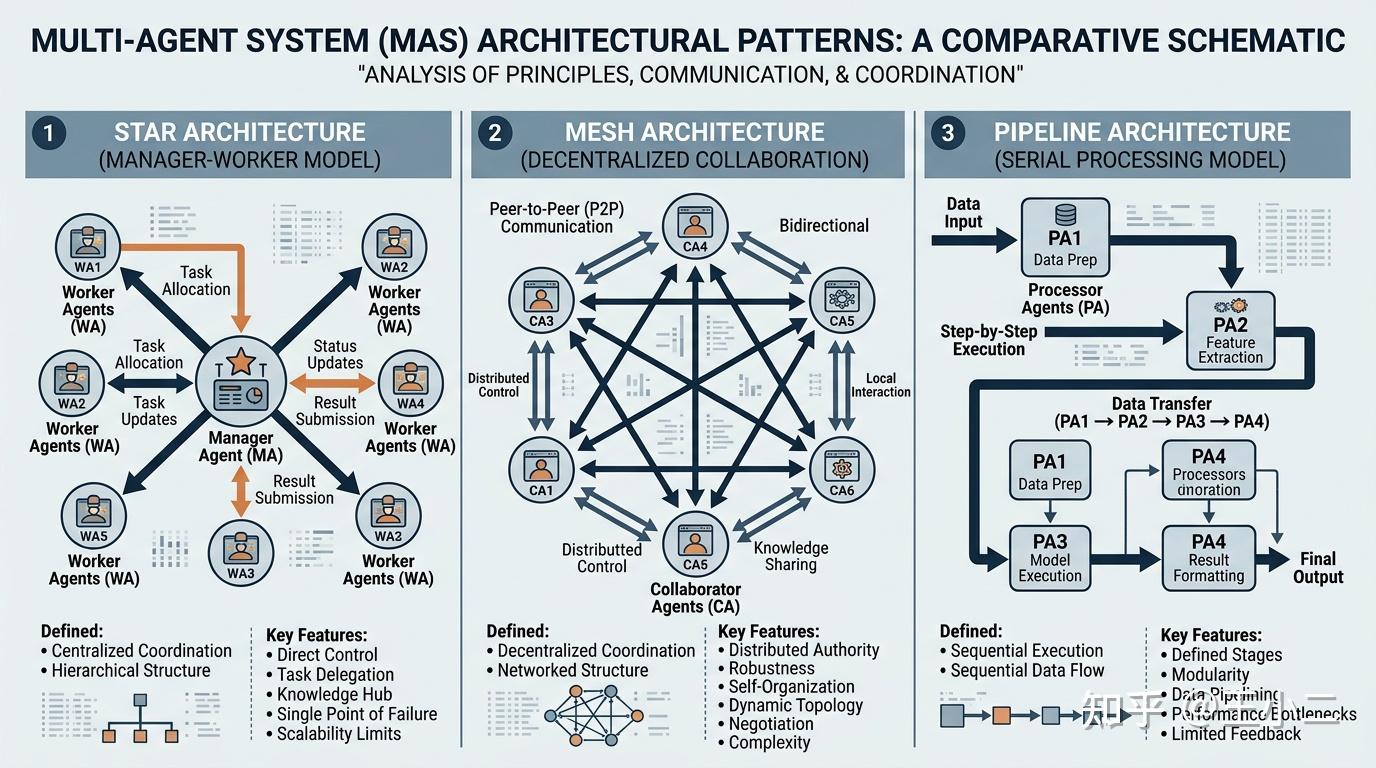
三种架构并非互斥,实际系统常采用混合模式。比如MetaGPT采用”类星型”的SOP(标准作业程序)结构,而AutoGen支持灵活的对话拓扑配置。
5.2 角色设计:Planner、Executor、Verifier与Critic的黄金组合
组织架构定好了,接下来要招聘什么样的员工?在Multi-Agent系统中,角色设计决定了系统的能力边界。以下是四种经典角色:
Planner(规划者):团队的大脑,负责将模糊目标拆解为可执行的任务清单,制定执行策略。Planner不直接干活,但决定了”干什么”和”怎么干”。在一个软件开发团队中,Planner相当于产品经理+架构师的结合体。
Executor(执行者):真正的”手“,负责调用工具、操作API、生成代码或文本。Executor通常配置有特定的工具集和领域知识,比如Python开发Agent可能配备代码解释器、Git工具、搜索引擎等。
Verifier(验证者):质量守门员,负责检查Executor的输出是否符合要求、是否包含错误。Verifier可以是基于规则的(如语法检查器),也可以是另一个LLM Agent(如代码Reviewer)。在多Agent系统中,Verifier是防止错误级联的关键防线。
Critic(批评者):这是更高级的元角色,不仅检查对错,还要评估策略是否最优、是否存在更好的方案。Critic像团队里的”挑刺王”,负责提出建设性意见,推动系统从”做完”到”做好”。
一个典型的Multi-Agent协作流程可能是:Planner制定方案 → Executor分头执行 → Verifier检查产出 → Critic评估整体效果 → Planner根据反馈调整策略。这种循环让系统具备了持续优化的能力。
但角色设计有个陷阱:不要为了分工而分工。如果任务本身很简单(比如”查北京天气”),硬拆成四个Agent讨论半天,就是典型的”用大炮打蚊子”。
5.3 协作机制:Agent之间如何”开会”
多个人协作,最难的是沟通。Multi-Agent系统需要明确的通信协议来解决”谁说话”“说什么”“听谁的”三个核心问题。
消息传递协议是最基础的机制。Agent通过标准化的消息格式(如JSON)交换信息,包含发送者、接收者、消息类型(请求、响应、广播)、内容负载等字段。这类似于公司内部的邮件系统或Slack频道。一个关键设计是对话历史管理——每个Agent都能看到完整的对话上下文,还是只能看到与自己相关的部分?全量上下文信息丰富但容易超出LLM的窗口限制,部分上下文节省Token但可能导致信息不对称。
共享内存(黑板架构) 是另一种协作范式。所有Agent共享一个公共的”黑板”(可以是数据库、缓存或结构化存储),任何Agent都可以读写。比如软件开发中,架构设计文档、接口定义、Bug列表都贴在黑板上,前端Agent和后端Agent可以随时查看对方的进展。这种松耦合设计降低了直接通信的复杂度,但需要解决并发写入的冲突问题。
冲突解决与投票机制是分布式系统的经典难题。当两个Agent给出矛盾的建议时怎么办?常见策略包括:Manager Agent拥有最终裁决权(中心化决策)、多数投票制(民主决策)、或基于置信度的加权决策(专家决策)。在MetaGPT中,甚至引入了”角色互评”机制——代码Agent写的程序,不仅要过测试Agent的关,还要接受产品经理Agent的需求符合度检查,形成制衡。
让我们看一个具体的协作场景:程序员Agent写完一段代码后,提交给测试Agent验证:
程序员Agent → 测试Agent: “我完成了用户登录功能,代码已提交到分支feature/login,请测试” 测试Agent → 程序员Agent: “发现边界问题:密码为空时的异常处理缺失,请修复” 程序员Agent → 测试Agent: “已修复,添加了非空校验,请重新验证” 测试Agent → 全员: “测试通过,可以合并到主分支”
这种对话看似简单,但在系统层面需要处理状态管理(”请重新验证”意味着回到之前的测试状态)、错误恢复(如果程序员Agent拒绝修复怎么办)、以及并发控制(多个功能同时开发时的分支管理)。
5.4 什么时候该组建”团队”:Multi-Agent的适用边界
了解了Multi-Agent的机制,最关键的问题是:你的项目真的需要组建团队吗?
Multi-Agent架构在以下场景展现独特价值:
多视角验证任务:当单一视角容易遗漏关键问题时,多Agent模拟不同角色能提供全面检查。典型例子是代码Review模拟——让Reviewer Agent、Security Agent、Performance Agent分别从不同维度审查同一段代码,比单个Agent逐项检查更全面。红蓝军对抗测试也是经典场景:红方Agent负责找漏洞,蓝方Agent负责防御,双方在对抗中不断提升系统安全性。
天然并行的子任务:当任务可以拆分为无依赖或弱依赖的子任务时,Multi-Agent能显著提升效率。比如生成一份行业报告:Research Agent并行搜索5个数据源,Writer Agent并行撰写不同章节,最后由Editor Agent统一整合。相比单Agent串行处理,时间复杂度从O(n)降到O(max(n/m)),其中m是Agent数量。
复杂系统的角色扮演:某些任务天然需要多个”人格”。比如多人游戏NPC、虚拟社交场景、或创意写作中的角色对话。每个Agent拥有独立的性格、目标和记忆,通过互动产生涌现行为(Emergent Behavior),这是单Agent无法实现的。
专业领域的深度分工:当任务涉及多个专业领域(如医疗诊断需要影像分析、病历解读、药物相互作用检查),为每个领域配置专门的Expert Agent,比让通用Agent”又当医生又当药师”更可靠。
但请记住:复杂度是逐级递增的。先用单Agent试试,只有当遇到瓶颈(准确率不足、任务太复杂、需要并行加速)时,才考虑引入Multi-Agent。
5.5 “人多力量大”的代价:通信开销与调试噩梦
组建团队不是没有成本的。Multi-Agent架构的三大暗礁,每个都可能让项目搁浅:
通信开销与成本指数级增长。假设单Agent完成一个任务需要1000 Token,5个Agent协作并不意味着5000 Token——由于Agent间需要多轮对话确认,实际消耗可能是3-5倍。如果采用全连接的网状通信,复杂度甚至是O(n²)。更重要的是延迟问题:Agent A等Agent B的响应,Agent B等Agent C的结果,层层依赖导致总响应时间远超单Agent模式。
调试困难与涌现行为的不可控。单Agent的决策链是线性的,你可以追踪”它为什么这么想”。但Multi-Agent系统中,两个各自表现良好的Agent放在一起,可能产生意想不到的负面互动——比如互相踢皮球、陷入无限循环、或达成某种”共谋”偏离用户目标。这种涌现行为(Emergent Behavior)是复杂系统的固有特性,难以预测和复现。
系统设计的复杂性爆炸。你需要设计角色分工、通信协议、冲突解决机制、错误恢复策略……任何一个环节设计不当,都会导致系统瘫痪。更糟糕的是,故障定位极其困难——是Planner分配的任务不合理?Executor执行不到位?还是Verifier标准太苛刻?问题可能在交互界面中,而非单个Agent内部。
因此,Multi-Agent是高级玩家的工具。建议从简单的两Agent协作开始(如Generator+Verifier),逐步增加复杂度,并建立完善的监控和日志系统来追踪Agent间的每一次交互。
5.6 实战解析:MetaGPT如何模拟软件公司
让我们以MetaGPT为例,看看Multi-Agent如何在实践中运作。MetaGPT的目标是让多个Agent协作完成一个小软件项目,它模拟了真实软件公司的组织架构:
产品经理Agent(Product Manager):接收用户需求,撰写PRD(产品需求文档),定义用户故事和验收标准。
架构师Agent(Architect):根据PRD设计系统架构,确定技术栈,编写接口定义文件。
项目经理Agent(Project Manager):将架构拆解为具体任务,分配开发优先级,协调开发节奏。
工程师Agent(Engineer):分前后端两个角色,根据任务列表编写代码,实现具体功能。
QA工程师Agent(Quality Assurance):编写测试用例,执行测试,提交Bug报告。
整个流程采用类星型结构,但带有Pipeline特征:需求 → 架构 → 任务分配 → 开发 → 测试。每个Agent都有明确的输入输出标准(比如产品经理的PRD必须符合特定格式,架构师才能解析)。Agent之间通过共享的”项目文档”(黑板)协作,而非直接对话,这降低了通信复杂度。
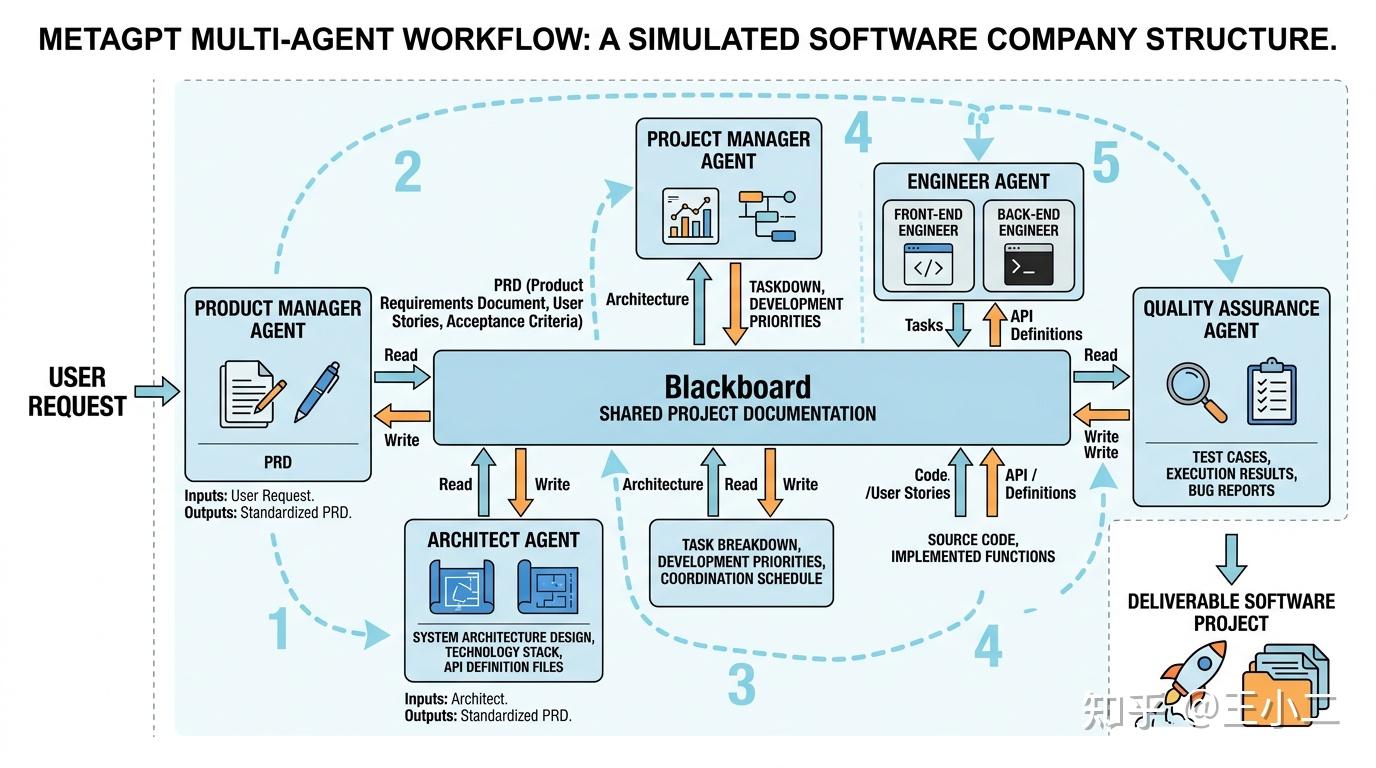
这种设计的巧妙之处在于:用结构化输出约束Agent行为。不是让Agent自由聊天,而是强制它们生成标准化的中间产物(PRD、接口文档、代码),下一阶段的Agent基于这些产物继续工作。这既保留了Multi-Agent的分工优势,又避免了开放式对话的混乱。
当然,MetaGPT也有局限:它对任务的确定性要求较高,适合标准化的软件开发,不适合探索性研究或创意写作。这再次印证了我们的核心观点:没有银弹,只有适合的工具。
5.7 小结:从”实习生”到”团队”
从ReAct的单兵作战,到Plan-and-Solve的项目管理,再到Multi-Agent的团队协作,Agent架构的演进本质上是对”如何组织智能”的不断探索。Multi-Agent突破了单Agent的能力边界,通过角色分工和并行处理解决了复杂系统性问题,但也带来了通信开销、调试困难和成本飙升的挑战。
选择Multi-Agent前,请自问三个问题:1)任务是否真的需要多角色协作?2)能否接受更高的延迟和成本?3)是否有能力调试复杂的涌现行为?如果答案都是肯定的,那么恭喜你,可以开始组建你的”AI团队”了。
下一章,我们将探讨Agent的”元认知”能力——如何让Agent学会自我反省和持续进化,这是从”执行者”迈向”思考者”的关键一跃。
从即时反馈到深度规划,从单体智能到群体协作,再到自我反省机制,各类架构模式各有利弊。面对这些技术选项,如何避免”选择困难症”?下一章的决策框架将帮助你在任务特征、成本约束与质量要求间找到最优平衡点。
6. Reflection与Self-Improvement:会”自我反省”的进化型
想象你正在写一篇重要的工作报告。初稿完成后,你不会立刻提交,而是会通读一遍,标出逻辑漏洞、数据矛盾、表达不清的地方,然后逐条修改——甚至可能推翻重写某个章节。这个”写-审-改”的循环,正是人类区别于普通AI的核心能力:元认知(Meta-cognition),即”对思考的思考”。
前面几章介绍的ReAct、Plan-and-Solve、Multi-Agent,本质上都是让AI按照某种固定策略”向外探索”。但当任务质量要求极高时(比如学术论文、关键代码、数学证明),我们需要的不是更复杂的协作流程,而是让Agent具备向内审视的能力——能够评判自己的输出、发现错误、主动修正。这就是Reflection与Self-Improvement架构的核心价值。
6.1 机制设计:从”一气呵成”到”迭代精修”
Reflection架构打破了”一次生成定终身”的范式,引入了一套类似编辑审稿的质量控制流程。最基础的实现是Generator-Critic-Refiner循环:
- Generator(生成器):LLM首先产出初始答案(代码、文章、解题步骤)
- Critic(批判器):另一个LLM实例(或同一模型的不同Prompt角色)扮演”严苛的审稿人”,从正确性、完整性、风格、安全性等维度挑剔问题
- Refiner(修正器):基于批判意见,对原输出进行修改或重写
- 循环终止条件:达到质量阈值,或达到最大迭代次数(防止无限循环)
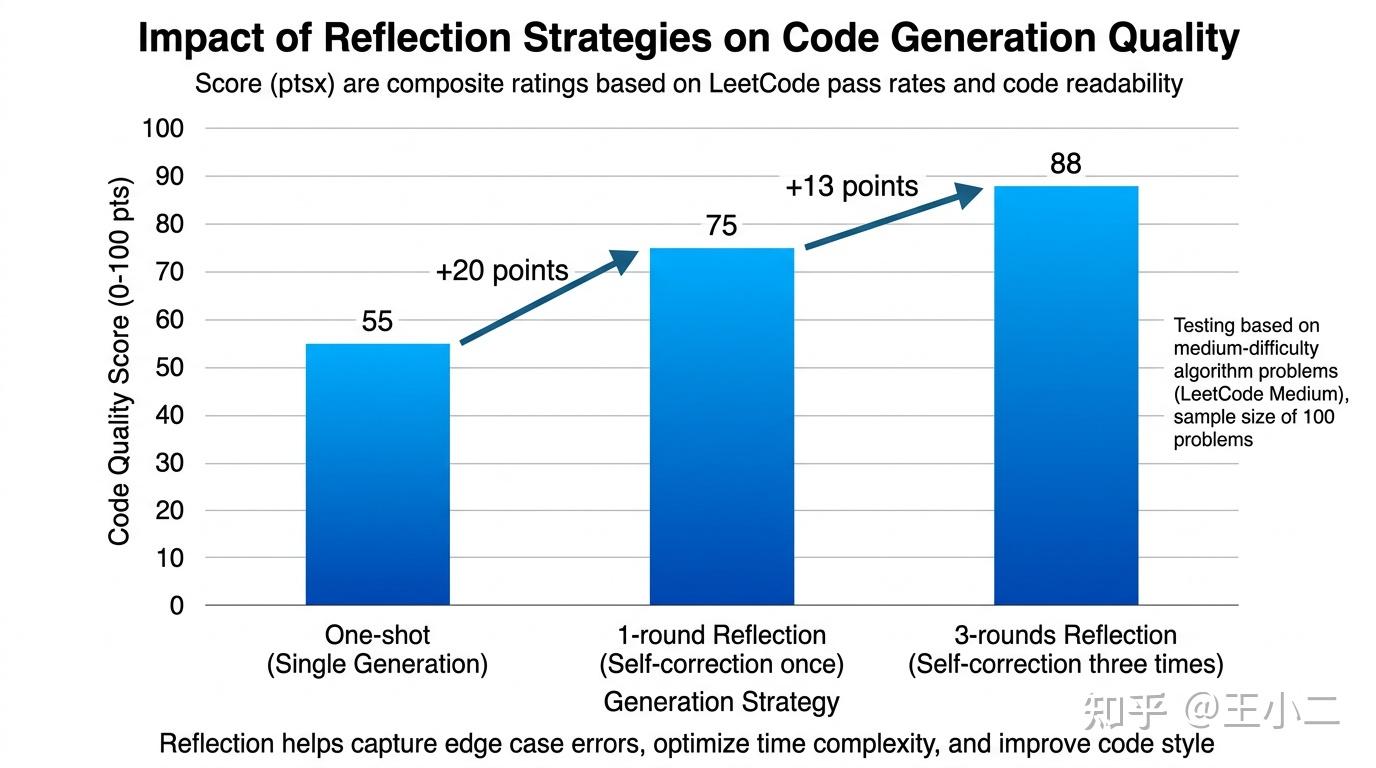
这个机制听起来简单,但效果惊人。以代码生成为例:研究显示,单次生成的中等难度算法题通过率通常在40-50%左右,而经过3轮Reflection迭代后,通过率可以提升至85-90%。原因很直观——LLM在生成时容易”一条路走到黑”,而批判环节能迫使其重新审视边界条件、时间复杂度、异常处理等容易被忽略的细节。
但更高级的策略不止于此。Tree of Thoughts(ToT,思维树)将Reflection提升到了搜索层面。不同于Chain of Thought(CoT)的直线推理(一步一步往下走,不回头),ToT允许Agent在每个决策点探索多条路径,然后通过评估函数(Evaluator)判断哪条分支更有希望,主动”剪枝”掉低质量路径。
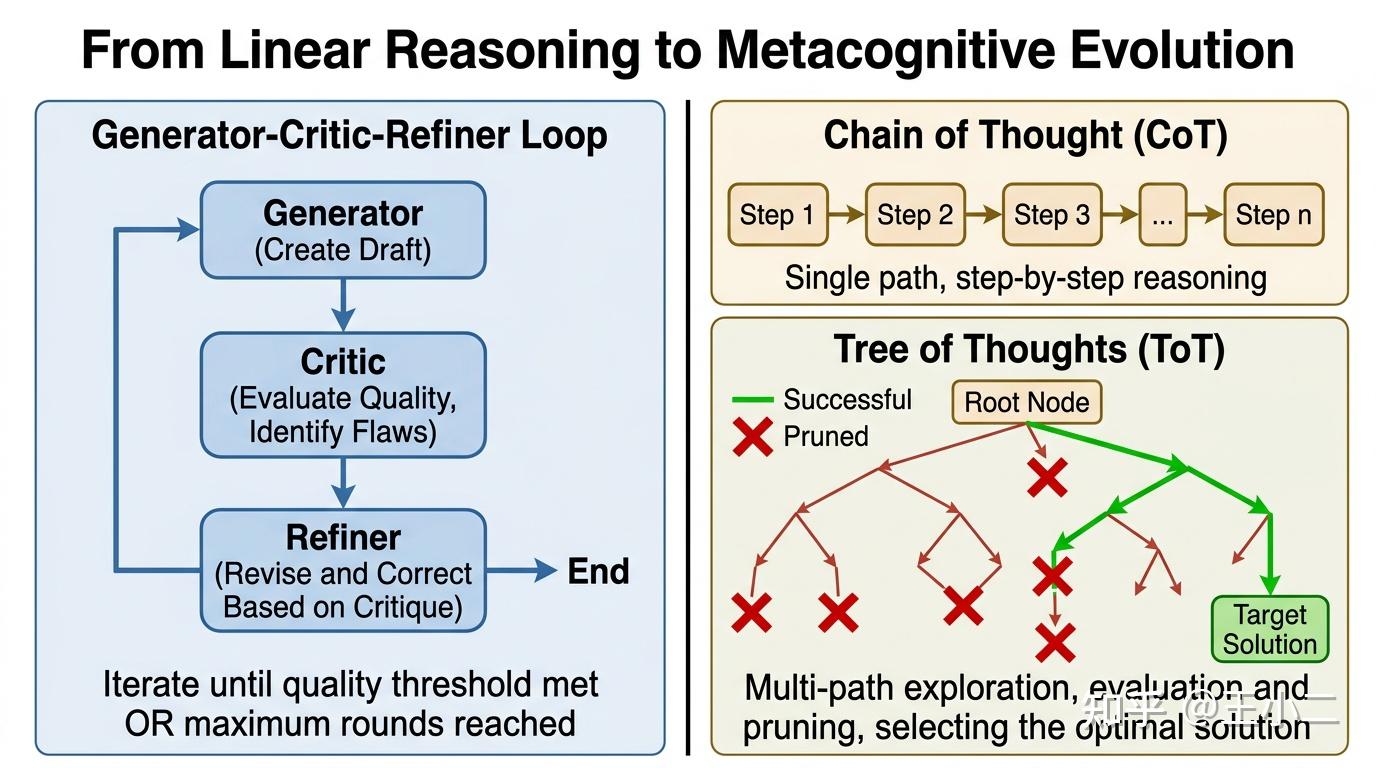
如果把CoT比作走迷宫时闭着眼睛凭直觉前进,ToT就是站在每个岔路口先派人探路,根据反馈决定往哪边走——甚至发现死胡同时能回溯到上一个决策点重新选择。这种”探索-评估-选择”的能力,让Agent在开放式问题(创意写作、策略游戏、数学证明)上展现出接近人类的灵活性。
6.2 关键挑战:Verifier的”裁判员困境”
Reflection架构的命门在于Verifier(验证器)的质量。Generator可以天马行空,但如果没有可靠的Critic把关,整个迭代过程就变成了”瞎改”——甚至可能把好答案改坏。
目前验证器主要有两类实现:
| 验证器类型 | 原理 | 优点 | 局限 |
|---|---|---|---|
| 基于规则的验证 | 预定义检查清单(如代码能否编译、数学题结果是否匹配、格式是否符合规范) | 可靠、可解释、成本低 | 只能覆盖已知错误模式,对开放性任务(创意写作)无能为力 |
| 学习得到的奖励模型 | 训练专门的LLM或小型判别模型,学习人类偏好(RLHF思路) | 能处理模糊质量标准(如”文章是否有说服力”) | 训练成本高,可能出现”奖励黑客”(Reward Hacking),且对分布外样本不稳定 |
一个有趣的对比是:在数学证明任务中,验证最终结论的正确性相对容易(代入数值检验即可),但验证中间推理步骤是否合理则困难得多——这正是当前Reflection架构的瓶颈所在。研究者发现,当Critic与Generator使用相同规模的模型时,批判质量往往不够严苛(“互相放水”现象)。实践中常见的解法是让Critic使用更强的模型(如GPT-4审查GPT-3.5的生成结果),或者引入多Critic投票机制(类似Multi-Agent中的Verifier角色)。
6.3 适用场景:质量敏感型任务的”奢侈品”
Reflection机制的计算成本极高——单次任务可能需要调用3-5次甚至更多LLM,Token消耗呈线性甚至指数增长。因此,它只适合质量敏感、成本不敏感的场景:
最佳适用场景:
- 学术写作与专业报告:需要反复推敲逻辑链条、数据引用的准确性
- 关键代码生成:如金融交易系统、医疗诊断算法的核心模块,必须确保边界条件全覆盖
- 数学证明与复杂推理:需要逐步验证每一步的合法性,ToT的搜索策略尤为有效
- 创意内容的精修:初稿由Generator快速产出,Refiner负责打磨风格、检查一致性
不建议使用的场景:
- 实时性要求高的对话系统(用户等不了3轮迭代)
- 简单的信息检索或格式化任务(”用大炮打蚊子”)
- Verifier无法明确定义质量标准的开放式创作(如纯艺术创作)
6.4 优缺点剖析:高上限与高开销的权衡
Reflection架构代表了一种”用算力换质量”的极端策略,其优缺点都极为鲜明:
核心优势:
- 输出质量上限高:自我纠错机制让Agent能从错误中学习,逐步逼近最优解。研究表明,在HumanEval代码基准测试上,Reflection能将 pass@1 指标提升15-25个百分点。
- 可解释性强:整个思考过程(生成→批判→修正)被显式记录,用户可以追溯”为什么最终答案是好的”——这对需要审计的高风险决策至关重要。
- 模块化扩展:Generator、Critic、Refiner可以独立优化,甚至可以接入外部验证工具(如代码解释器、数学求解器)形成混合验证链。
致命局限:
- 计算成本极高:ToT的分支搜索可能产生指数级增长的调用次数,即使简单的Generator-Critic循环也让成本翻3-5倍。
- 依赖Verifier的准确性:如果Critic本身是”睁眼瞎”(比如对专业领域知识不足),迭代不仅无益,反而可能引入”过修正”错误——把原本正确的内容改错。
- 收敛性不确定:某些任务可能陷入”改来改去都不满意”的震荡,需要精心设计终止条件。
6.5 与其他模式的融合:Reflection作为”插件”
值得强调的是,Reflection并非与前几章架构互斥的”第五种模式”,而是一种可叠加的增强机制。
- ReAct + Reflection:在执行循环中定期插入Critic检查点,避免在错误路径上越走越远
- Plan-and-Solve + Reflection:规划阶段用Reflection评估任务分解的合理性,执行阶段验证子任务输出
- Multi-Agent + Reflection:让专门的Critic Agent持续监控其他Agent的输出,甚至形成”红队-蓝队”对抗机制
这种”插件化”思维是当前工程实践的主流趋势——先搭建基础架构(ReAct或Plan-and-Solve),再根据质量要求在关键节点插入Reflection模块。例如,MetaGPT在第5章描述的软件开发流程中,代码Review阶段本质上就是一个Reflection环节:Programmer生成代码,Reviewer批判,然后迭代修改。
当然,这种增强是有代价的。当你在第7章做最终选型时,必须回答一个灵魂问题:为了那20%的质量提升,是否值得付出300%的成本? 对于内部工具原型,答案可能是否定的;但对于面向客户的生产系统,答案可能是肯定的——毕竟,一个能自我纠错的Agent,比一个频繁犯错的Agent更值得信赖。
7. 选择困难症急救包:一张决策图搞定架构选型
读完前面五章,你可能会有种感觉:每种架构都很厉害,都想试试。但就像装修房子——你不能因为喜欢日式极简、法式复古、工业风酷感,就把三种风格全塞进一个客厅。Agent架构选型也是如此,选错模式的代价比你想象的更痛:用Multi-Agent做简单的天气查询,就像为了买瓶酱油组建一个采购委员会;用基础ReAct做复杂的行业研究,就像让实习生边查资料边写报告,最后得到一份前后矛盾的初稿。
这一章给你一套”急救工具”:不需要成为架构专家,也能在短时间内做出靠谱选择的决策框架。
7.1 决策矩阵:在正确的地方用正确的工具
想象你在安排工作:让实习生处理突发邮件(需要灵活应变),让项目经理操盘年度规划(需要全局视角),让专家团队攻克技术难题(需要多领域协作)。Agent架构的选择逻辑完全相同。
我们用一个二维矩阵来定位:横轴是环境动态性(任务执行过程中外部环境会不会突变),纵轴是任务复杂度(步骤多少、依赖关系多复杂)。
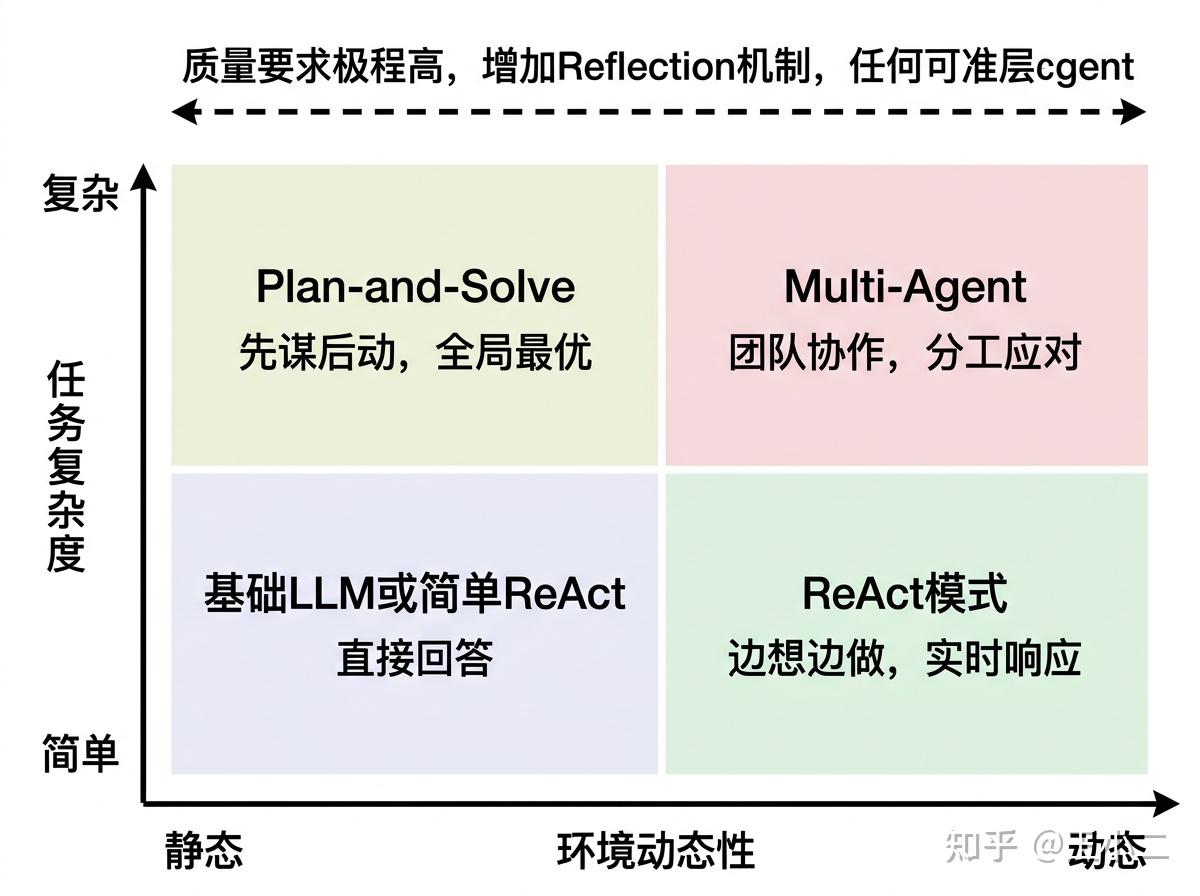
左下角(简单+静态):比如”总结这段文本”、”翻译这句话”。别折腾了,直接用基础LLM,或者最简单的单步ReAct。这时候上Plan-and-Solve就像用Excel做1+1——能算,但没必要。
右下角(简单+动态):比如实时客服、股票监控、交互式问答。环境在变,但任务本身不复杂。这是ReAct的主场——像福尔摩斯一样边观察边行动,错了能及时纠偏。前面第三章讲的股票分析案例就是典型:股价每秒都在变,你需要根据最新数据调整判断,而不是先写个三年规划再执行。
左上角(复杂+静态):比如撰写行业深度报告、批量数据ETL、数学定理证明。步骤多、依赖关系复杂,但执行过程中外部条件不会突然改变。这是Plan-and-Solve的舒适区——先花时间做全局规划,再并行或串行执行,最后统一review。就像第四章说的”项目经理”模式:先画好甘特图,再开工,比边干边改效率高得多。
右上角(复杂+动态):这是Multi-Agent的舞台。任务本身复杂(需要多领域知识),环境还在持续变化(需要实时协调)。比如模拟一家创业公司运营:既要管产品、又要管销售、还要应付突发竞品动态。第五章讲的MetaGPT就是典型——让不同角色(产品经理、架构师、工程师)各司其职,通过消息机制同步信息,比让一个超级Agent单打独斗更靠谱。
当然,矩阵只是起点。如果你的任务对错误”零容忍”(比如医疗诊断建议、关键代码生成、法律文书起草),无论落在哪个象限,都要考虑叠加Reflection机制——就像重要文件需要多级审核,Generator写完后,Verifier和Refiner轮流把关,质量才能上得去。
7.2 成本的隐形战场:延迟 vs Token预算
选架构时,除了”能不能完成任务”,还得算两笔账:用户愿意等多久(延迟),以及你愿意花多少钱(Token消耗)。
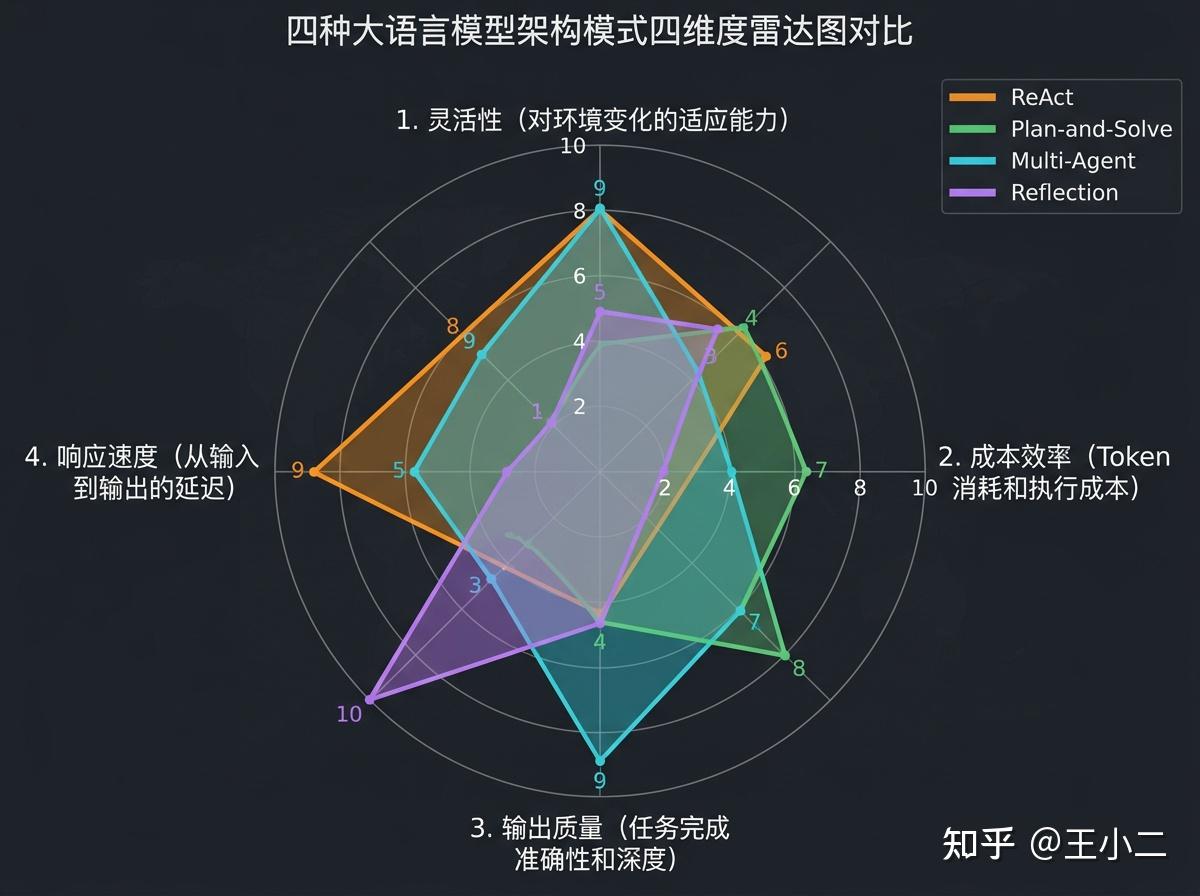
从雷达图能直观看到四种架构的trade-off:
ReAct是”短跑选手”:响应快(每步都有反馈)、Token消耗中等(不会一次性生成超长规划)。适合对延迟敏感的场景——用户问”现在北京天气怎么样”,你不可能先规划5分钟再回答。
Plan-and-Solve是”马拉松选手”:起步慢(要先生成完整规划)、但执行阶段稳定。Token消耗在规划阶段集中爆发,适合后台异步任务——比如凌晨跑批生成报告,用户早上来看结果,没人关心你花了10秒还是30秒。
Multi-Agent是”团队作战”:沟通成本极高。每个Agent的每次发言都要消耗Token,再加上协作冲突、消息传递的冗余,整体成本可能是单Agent的3-5倍。但换来的是复杂任务的更高成功率——就像雇一个专家团队贵,但能解决一个人搞不定的问题。
Reflection是”完美主义者”:质量最高,但成本和延迟都是最差的。Generator生成→Critic批判→Refiner改写,每一轮都要重新走完整流程。适合”错了代价极高”的场景——比如生成一份要向董事会汇报的战略分析,值得多花10倍成本换99%准确率,而不是省成本拿80分去冒险。
实战建议:画一张”成本-延迟”坐标系,标出你业务的可接受区间。如果做实时客服,延迟必须秒,Token预算再充足也不能上Multi-Agent——用户等不了五个Agent开完会再回复。
7.3 决策树:从问题到答案的五分钟路径
如果矩阵让你还是有点晕,这张决策树更直接——从回答四个问题开始,一步步走到推荐架构。
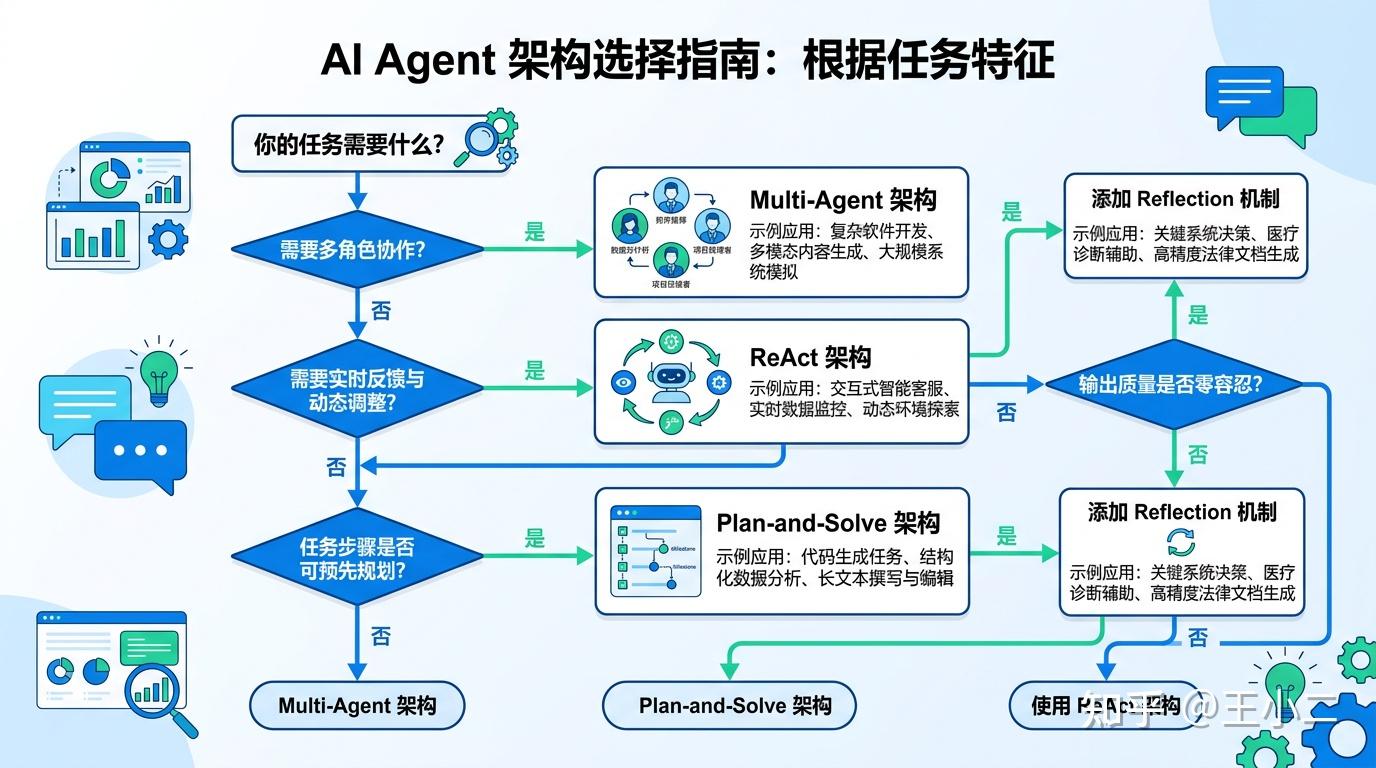
问题1:是否需要多角色协作?
- 是的 → 进入Multi-Agent分支(比如需要同时处理产品需求、技术架构、测试用例)
- 否 → 继续问题2
问题2:是否需要实时反馈/环境动态变化?
- 是的 → 进入ReAct分支(比如股价查询、实时客服)
- 否 → 继续问题3
问题3:任务步骤是否可预先规划/依赖关系明确?
- 是的 → 进入Plan-and-Solve分支(比如标准ETL流程、结构化报告生成)
- 否 → 回到ReAct(任务本身混乱,规划了也白搭,不如边干边调整)
问题4:输出质量是否零容忍/可事后review?
- 是的 → 在当前架构上叠加Reflection(哪怕用ReAct,也可以加一轮Verifier检查)
- 否 → 当前架构即可
走一遍这个流程,通常5分钟内就能锁定候选架构。比如:
- 智能客服:不需要多角色(1否)+ 需要实时反馈(2是)→ ReAct
- 行业研究报告:不需要多角色(1否)+ 不需要实时(2否)+ 可预规划(3是)→ Plan-and-Solve
- 软件项目开发:需要多角色(1是)→ Multi-Agent
- 医疗诊断辅助:走完后发现质量零容忍(4是)→ Plan-and-Solve + Reflection 或 Multi-Agent + Reflection
7.4 混合架构:成年人的选择是”全都要”
现实世界的复杂任务,往往不会乖乖落在某个象限。这时候需要的不是”选A还是选B”,而是”怎么组合”。
分层设计:上层Plan,下层ReAct
这是目前工业界最实用的混合模式。顶层用Plan-and-Solve做全局任务分解,把大目标拆成若干子任务;每个子任务交给底层的ReAct Agent执行,保留实时应变能力。
举个例子:智能投资助手。顶层规划”分析某股票”→分解为”查财务数据”、”读新闻情绪”、”看技术指标”、”生成结论”四个子任务。每个子任务用ReAct执行:查财务数据时,如果API返回异常,能当场换数据源,不需要推翻整个规划重新来。这样既保留了全局视野,又不失灵活性。
Reflection插件化:给任何架构加”质检员”
Reflection不一定要作为独立架构使用,可以当作”外挂”插件。在ReAct的Finish之前加一轮Verifier检查;在Plan-and-Solve的Review阶段引入Critic评分;在Multi-Agent的最终输出前让专门的质量Agent把关。就像工厂流水线的质检环节,哪里需要加哪里。
渐进式演进:从单Agent到Multi-Agent
不要一开始就上Multi-Agent。建议路径是:先用单Agent(ReAct或Plan-and-Solve)跑通核心流程→发现瓶颈(某类任务总失败、某个环节需要专业知识)→把瓶颈环节拆成独立Agent→逐步形成Multi-Agent系统。
就像创业:先让创始人全能跑通业务,业务大了再招CTO、CMO、COO,而不是第一天就凑齐高管团队等活干。
7.5 避坑指南:那些让人后悔的选型失误
最后,列出几个常见的”反模式”——看别人掉过的坑,比成功经验更有价值。
反模式1:用Multi-Agent做简单问答
见过一个团队,为了做”公司知识库问答”,设计了五个Agent:理解Agent、检索Agent、总结Agent、审核Agent、输出Agent。结果一个简单的”我们公司年假几天”问题,要流转五个节点,延迟3秒,Token消耗是单Agent的4倍,准确率反而因为沟通误差下降了。
诊断:这是典型的”过度工程”。简单任务用简单架构,别为了技术炫技增加复杂度。
反模式2:用ReAct做多步复杂科研
另一个案例是做药物分子筛选:任务涉及十几步生物计算,每步依赖前一步结果,且需要严格遵循实验协议。团队选了ReAct,想着”边做边调整”。结果执行到第8步时发现第3步的参数选错了,但前面已经生成了大量中间结果,只能全部推倒重来,浪费了大量计算资源。
诊断:高确定性、强依赖的复杂任务,必须用Plan-and-Solve先做完整规划,全局优化后再执行。ReAct的局部最优陷阱在这种场景是致命的。
反模式3:忽视工具链的容错设计
无论选哪种架构,如果工具调用(Function Calling)没有做好错误处理,都会翻车。见过ReAct调用天气API失败,没有fallback机制,Agent陷入”调用-失败-再调用-再失败”的循环,直到Token耗尽。也见过Multi-Agent中某个Agent的API超时,其他Agent干等,整个系统卡死。
诊断:架构选型只是第一步,工具层的健壮性(重试、降级、超时控制)必须同步考虑。
反模式4:Reflection滥用
有个做内容生成的团队,给所有任务都加了Reflection:Generator写→Critic评→Refiner改,循环3轮。结果一篇短文生成要30秒,成本是原来的8倍,用户根本等不及。实际上,只有关键场景(如金融分析报告、医疗建议)才值得这个成本,日常内容生成用单轮即可。
诊断:Reflection是”奢侈品”,不是”必需品”。评估质量提升带来的收益,是否值得额外成本。
7.6 选型速查表:直接抄作业
如果你看完还是觉得抽象,这张速查表直接给答案。覆盖了最常见的8个场景:
| 应用场景 | 核心特征 | 推荐架构 | 关键考量 |
|---|---|---|---|
| 在线客服 | 实时响应、对话流畅性优先 | ReAct | 延迟秒,牺牲一定准确性换速度 |
| 代码生成助手 | 逻辑严谨、错误代价高 | Plan-and-Solve + Reflection | 先生成整体架构,再逐函数实现,最后静态检查 |
| 股票实时分析 | 数据动态变化、需快速迭代 | ReAct | 每步都能根据最新数据调整策略 |
| 行业研究报告 | 结构化、多数据源整合 | Plan-and-Solve | 先规划章节,再并行收集数据,最后统一润色 |
| 软件项目开发 | 多角色协作、需求技术联动 | Multi-Agent | 模拟真实团队分工,角色间消息同步 |
| 医疗辅助诊断 | 零容忍错误、可解释性要求高 | Plan-and-Solve + 强Reflection | 每步推理可追溯,多级Verifier把关 |
| 智能数据分析 | 探索性、用户需求可能变化 | ReAct或Plan-and-Solve灵活切换 | 用户明确目标时用Plan,模糊探索时用ReAct |
| 个性化内容推荐 | 实时反馈、用户兴趣动态变化 | ReAct | 根据用户实时行为调整推荐策略 |
这张表不是圣经,而是起点。实际项目中,建议先用推荐架构做MVP,跑真实数据,再根据瓶颈调整。架构是活的,不是选完就锁死的。
到这里,全文的核心内容已经交付完毕。我们从”Agent是什么”讲到”四大模块怎么工作”,再深入四种主流架构模式(ReAct、Plan-and-Solve、Multi-Agent、Reflection)的原理与局限,最后给出这套选型框架。
记住一个核心原则:没有最好的架构,只有最适合当下任务、成本约束、质量要求的架构。别让”选择困难”阻碍行动——先用决策树锁定候选方案,用MVP验证假设,在真实反馈中迭代优化。Agent技术还在快速演进,但”理解任务本质、匹配工具特性”的选型逻辑,是穿越技术周期的底层能力。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?
别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明:AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。


四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)