9B 参数打赢 120B 对手,马斯克点赞:这才叫智能密度
文章目录
Qwen3.5 小尺寸系列正式开源,平台镜像已上线,五分钟完成部署

马斯克为什么专门点这条
2026 年 3 月,阿里云 Qwen 团队开源 Qwen3.5 小尺寸系列(0.8B / 2B / 4B / 9B)。消息发布数小时内,埃隆·马斯克在 X 平台转发了这条动态:
随后,他留下了一句评语:
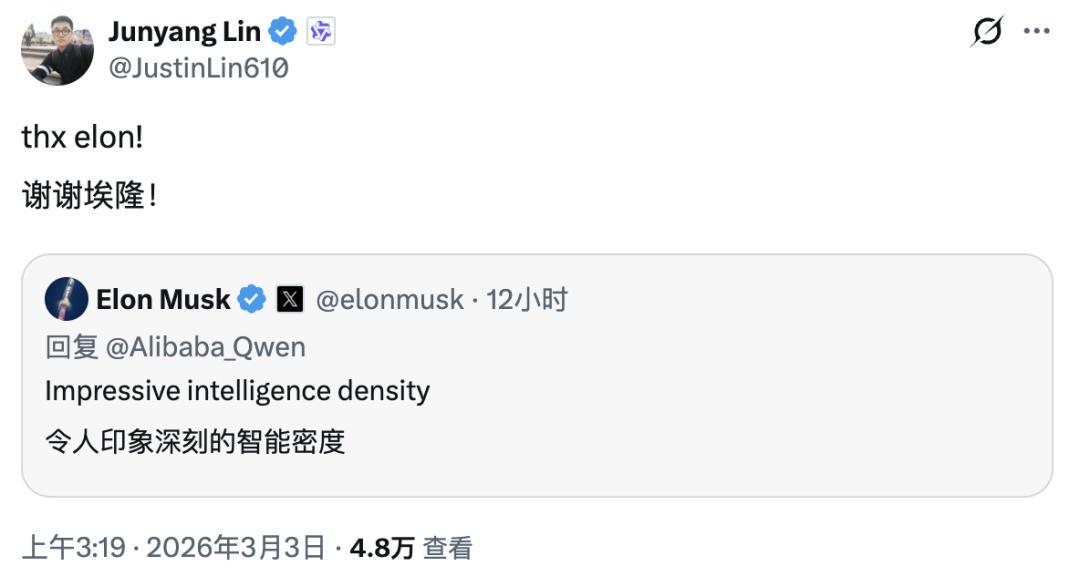
“令人印象深刻的智能密度(impressive intelligence density)”
马斯克不做广告,也不替别人站台。他点赞的是"智能密度"这个概念——用最小的参数规模,逼近甚至超越大得多的模型。这件事在 AI 工程圈意味着什么,他比任何人都清楚。
这条点赞,发生在中美 AI 竞争最白热化的时间节点。Qwen3.5 能引起他的注意,说明这不只是一个新模型发布,而是一个技术方向被公开承认的时刻。
9B 打赢 120B,不是噱头,是数据
开源社区的口碑,从来都是测评说了算。
Qwen3.5-9B 在发布后迅速登上多项基准测试的榜首。XDA Developers 的评测标题直接写明:“Qwen3.5-9B 目前横扫所有 AI 基准”。更引人注目的是,它的对手不是同量级的模型,而是 OpenAI 发布的 gpt-oss-120B——一个参数量是它 13 倍的模型。
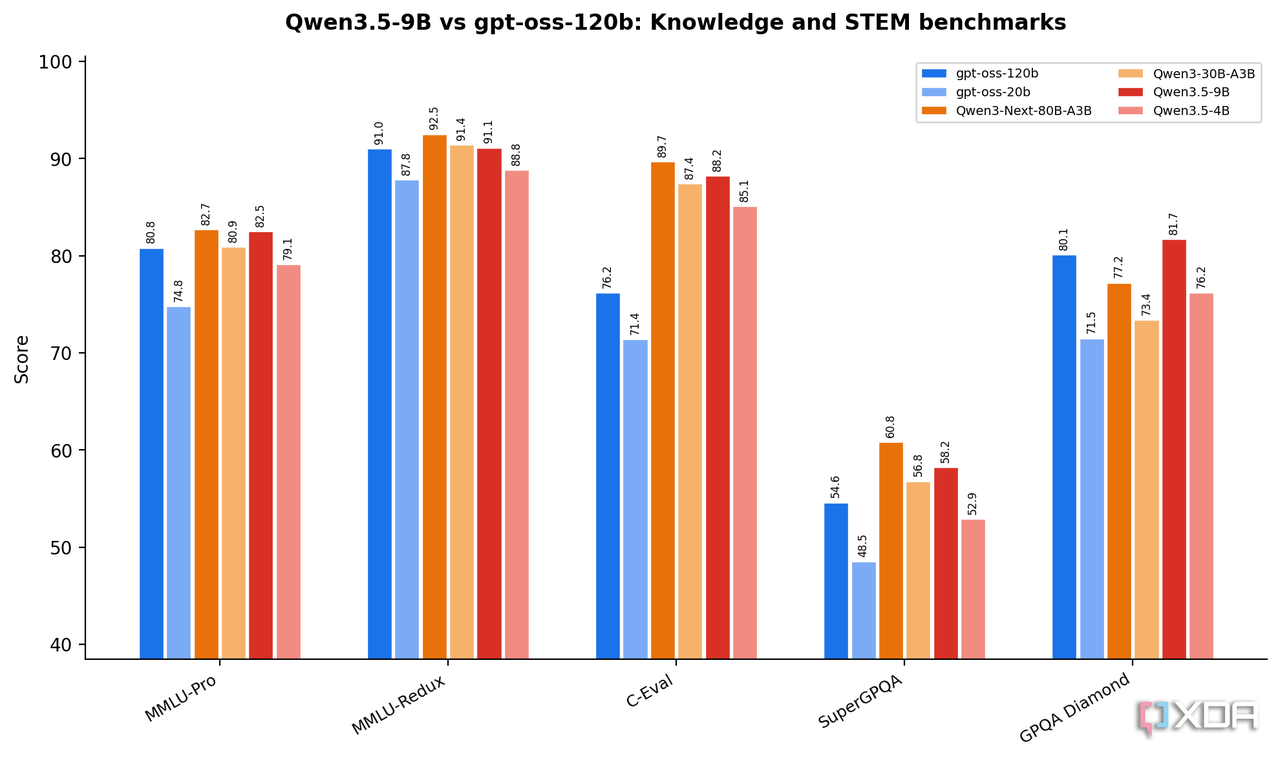
知识与推理
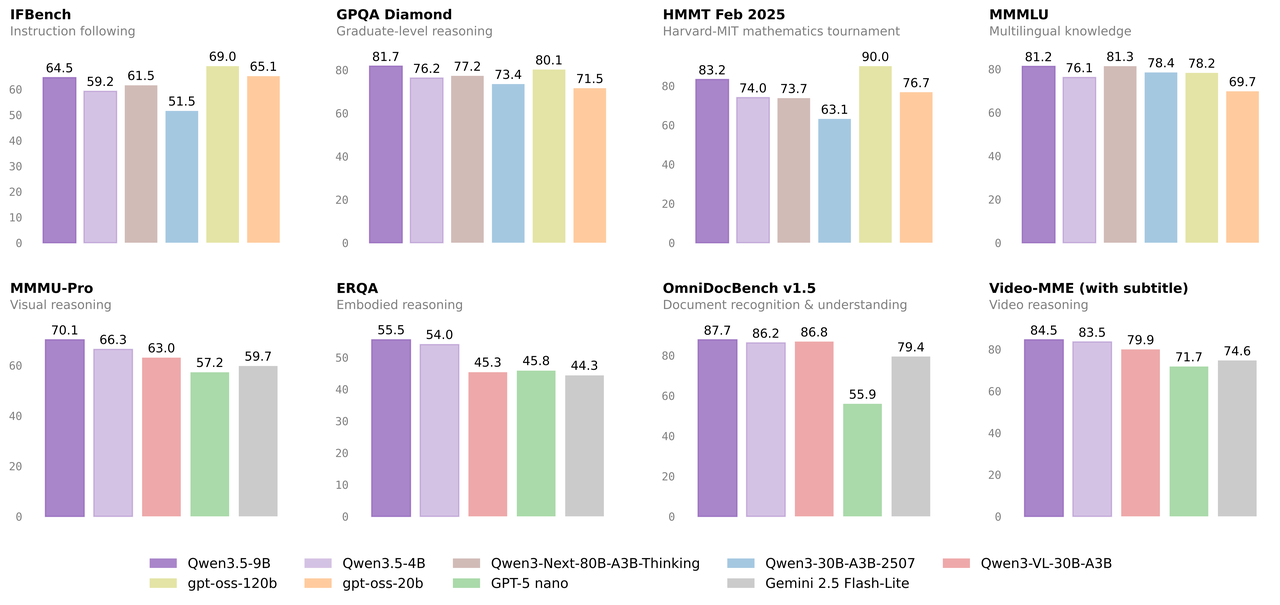
GPQA Diamond 是研究生级别的科学推理测试,被认为是最能区分模型真实理解能力的基准之一。Qwen3.5-9B 得分 81.7,超过 gpt-oss-120B 的 80.1。
MMLU-Pro 覆盖 57 个专业学科,Qwen3.5-9B 得分 82.5,超过 gpt-oss-120B 的 80.8。
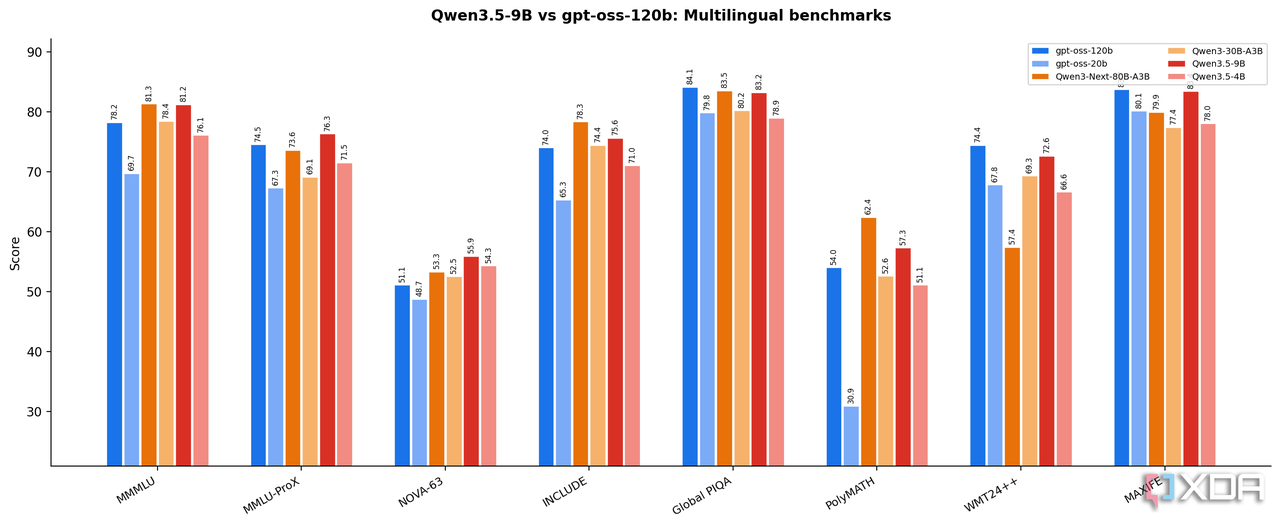
多语言能力
多语言 MMMLU 基准上,Qwen3.5-9B 得分 81.2,超过 gpt-oss-120B 的 78.2。中文场景的优势尤为明显,这是西方模型在同等规模下很难逾越的壁垒。
视觉理解
MMMU-Pro 视觉推理测试中,Qwen3.5-9B 得分 70.1,超过 Gemini 2.5 Flash-Lite 的 59.7,甚至高于专为视觉设计的 Qwen3-VL-30B-A3B(63.0)。
推理与代码
HumanEval、MBPP 等代码类基准,以及 MATH、GSM8K 数学推理测试,Qwen3.5 均处于同尺寸开源模型的绝对前列。复杂多步骤推理的稳定性,尤为突出。
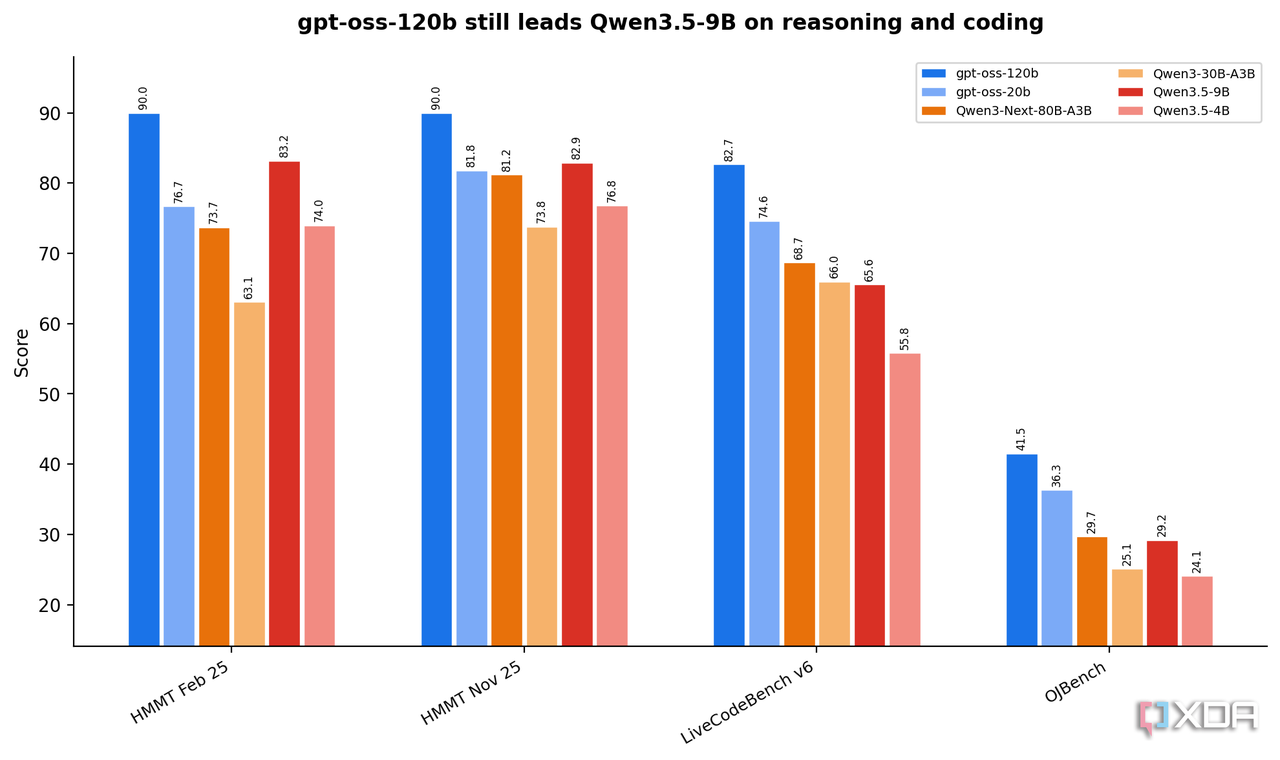
指令遵循
IFEval 是衡量模型"听不听话"的测试——面对多个条件同时约束的复合指令,模型是否会丢失细节、私自简化。Qwen3.5 在这一项的得分同样处于第一梯队,意味着它在实际产品中更加可靠、可控。
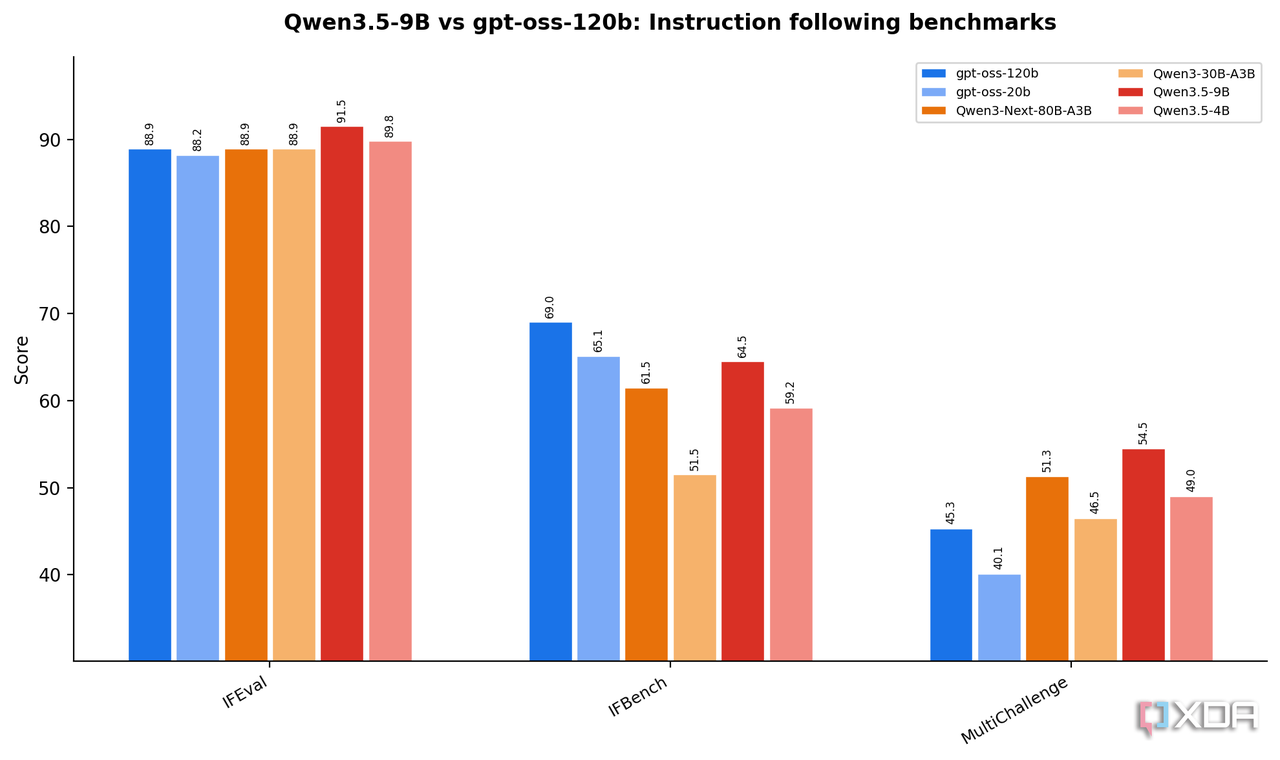
长文本处理
长上下文历来是小模型的弱项。Qwen3.5 在这一方向的投入同样可见,处理长篇文档和多轮对话历史的能力超出同量级预期。
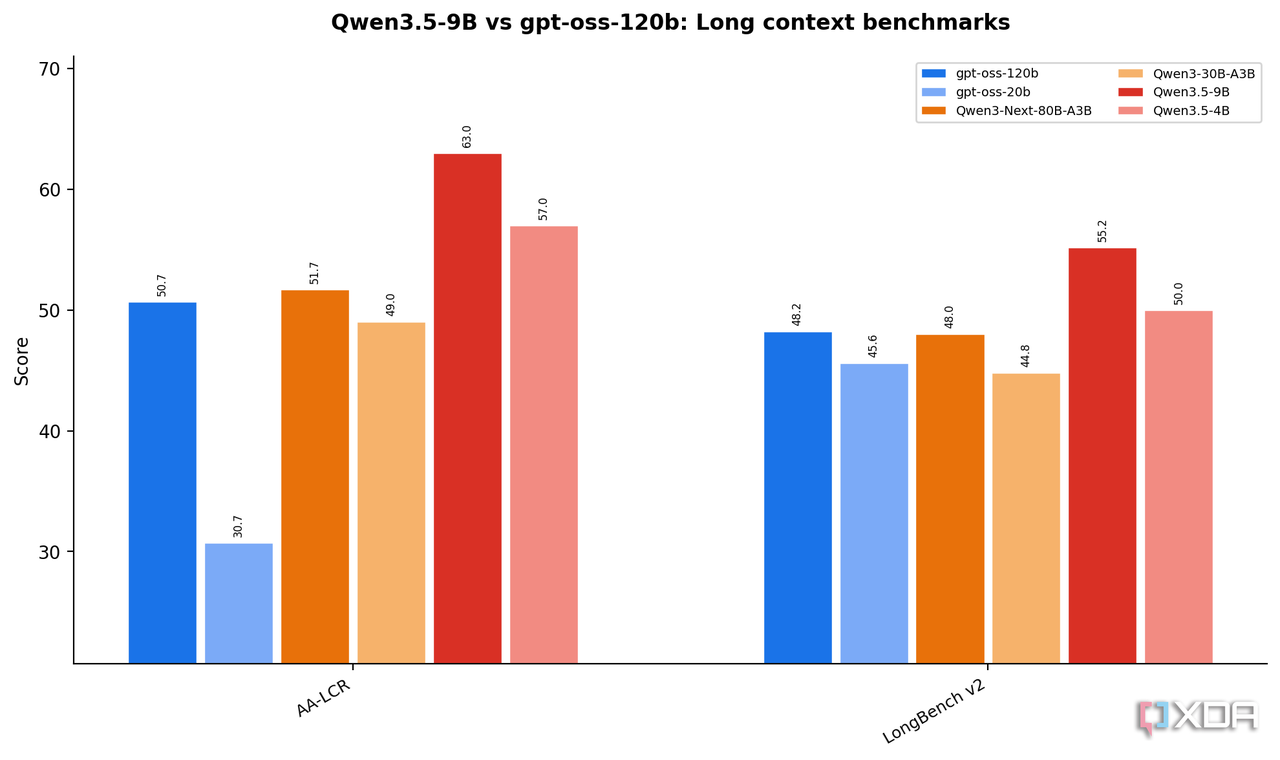
小尺寸系列综合对比
以下是官方发布的小尺寸模型(9B / 4B)与主流竞品的综合测评对比,数据来自 Qwen 团队官方报告:
"小而精"为什么是对的方向
过去三年,AI 圈的主流叙事是"参数越大越强"。这个逻辑在一段时间内是成立的,但它掩盖了一个更根本的问题:大模型绝大多数团队根本用不起、部署不了。
Qwen3.5 的出现,代表了另一种路线的成熟:
落地才是硬道理。 单张消费级显卡即可运行 9B 模型,普通笔记本可以跑 0.8B。从边缘设备到企业服务器,Qwen3.5 系列几乎覆盖了所有真实部署场景——这是 700B 模型永远给不了的。
推理成本决定商业可行性。 模型越小,单次推理消耗的算力越低,意味着更低的服务成本和更高的并发上限。对于需要百万级调用的产品,这一点往往比绝对精度更重要。
训练质量正在超越参数量的影响。 Qwen3.5 的数据配比、对齐策略、混合注意力机制等设计,让它在同等参数规模下远超竞品。模型能力的天花板,已经不完全由参数量决定了。
马斯克说"智能密度"——这正是 Qwen3.5 证明的事:同样的算力预算,聪明的训练比堆参数更有价值。
平台已上线全系列镜像,开箱即用
我们的平台已完成 Qwen3.5 镜像部署,预置完整推理环境。无需配置 CUDA、无需下载权重、无需处理依赖冲突,选择规格、启动实例、调用 API,整个流程五分钟完成。
目前上线三个镜像,覆盖从边缘设备到生产服务的完整场景:
Qwen3.5-0.8B
体积极小、推理速度极快的超轻量模型,专为资源受限场景设计。
1.75 GB 的体积意味着它可以运行在几乎任何设备上——树莓派、嵌入式开发板、老旧笔记本、手机芯片。普通 CPU 上即可实现流畅的实时输出,响应延迟极低。对于需要在断网环境下部署 AI 能力的场景(工业质检、本地语音助手、离线文档处理),0.8B 往往是唯一实际可行的选择。
| 镜像大小 | 推理框架 |
|---|---|
| 1.75 GB | vLLM |
Qwen3.5-9B
测评中以 9B 参数压制 120B 对手的那个版本。兼容 OpenAI API,适合生产环境直接部署。
单张 A100 或两张 A10 即可流畅运行。采用 vLLM 框架驱动,支持高并发推理和动态 batching,可同时服务大量并发请求而不显著增加延迟。现有基于 GPT 系列开发的应用,只需修改一个 base_url,无需改动任何业务逻辑即可完成迁移。
vLLM 版本同时支持持续批处理(Continuous Batching)和量化推理,可进一步降低显存占用、提升单机吞吐,对成本敏感的团队尤为友好。
| 镜像大小 | 推理框架 | API 兼容 |
|---|---|---|
| 39.06 GB | vLLM | OpenAI API |
vLLM 基础镜像
想自定义部署任意 Hugging Face 格式的模型?vLLM 基础镜像是最灵活的起点。
vLLM 由加州大学伯克利分校团队开发,核心创新是 PagedAttention 技术——借鉴操作系统虚拟内存分页管理的思路,对 KV Cache 进行非连续分块存储,从根本上解决了显存碎片化和预分配浪费的问题。相比 Hugging Face 原生推理,相同硬件下吞吐量可提升数倍。目前已被 Mistral AI、Cohere、字节跳动等大量团队在生产环境中采用。
| 镜像大小 | 支持格式 | API 兼容 |
|---|---|---|
| 9.77 GB | HuggingFace、GGUF 等 | OpenAI API |
vLLM 还是 Ollama?一张表看清楚
Qwen3.5 系列同时支持两套推理框架,第一次接触可以参考下表快速做决定:
| 对比维度 | Ollama | vLLM |
|---|---|---|
| 核心定位 | 本地易用,一命令启动 | 生产高性能,极致吞吐 |
| 硬件要求 | CPU 即可运行 | 需要 GPU |
| 并发能力 | 中等 | 极高,支持动态 batching |
| 部署难度 | 极低 | 中(平台镜像已预配好) |
| API 兼容 | OpenAI API | OpenAI API |
| 适合人群 | 开发者、研究者、边缘设备 | 后端工程师、企业生产环境 |
| 推荐场景 | 本地调试、快速验证 | 高并发服务、企业内部 API、0.8B / 9B 部署 |
两套框架都兼容 OpenAI API,迁移成本极低,可以随业务阶段灵活切换。
为什么不建议自己从零搭
从零部署一个 LLM 推理服务,你大概率会经历:
-
CUDA / cuDNN / 驱动版本三方兼容地狱,光这一步就可能卡半天
-
从 Hugging Face 拉权重,网络不稳定、中途断线、重新来过
-
vLLM、Transformers 依赖冲突,pip install 一把报错
-
写启动脚本、配 API 服务、处理进程守护、日志、异常重启
-
批大小、并发数、量化策略、显存分配反复调优
使用平台镜像,以上全部省略。
选好规格 → 启动实例 → 拿到 API 端点,五分钟内完成,剩下的时间全部还给真正有价值的业务开发。
接入只需改一行
镜像启动后,用标准 OpenAI SDK 接入,无需学习任何新接口:
需要流式输出(打字机效果):
已有 GPT 接入代码的项目,只需把 base_url 指向平台实例,其余代码零改动。
哪些场景最值得用
企业知识库问答:基于私有文档构建 RAG 系统,9B 在中文检索增强生成任务中表现稳定,对国内企业场景尤其友好。
代码辅助:集成进 IDE 插件或 CI 流程,完成代码补全、注释生成、代码审查,开发效率显著提升,推理速度满足实时响应要求。
客服与对话机器人:高指令遵循得分保证了对话的一致性和可控性,避免"答非所问"或私自简化要求的问题。
文档自动化:合同摘要、报告撰写、多语言翻译——扎实的通用语言能力让它能胜任大多数文字处理工作。
边缘与离线场景:0.8B 版本赋予终端设备本地运行 AI 的能力,无需联网、数据不出设备,满足数据安全与隐私合规要求。
写在最后
Qwen3.5 证明了一件事:
AI 的下一个阶段,比拼的不是谁的模型最大,而是谁能用最小的代价,交付最高密度的智能。
9B 参数打赢 120B 对手,不是意外,是设计。马斯克看到了这一点,全球开发者社区也看到了。
现在,它在我们的平台上已经准备好了。你只需要五分钟。
去部署试试吧。
平台镜像持续更新,关注我们获取最新模型上线通知。
你在用哪套推理框架?或者在哪个场景上想试试 Qwen3.5?欢迎在留言区聊聊。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)