Langgraph 16. Exception Handling and Recovery —— 用 LangGraph 构建「扛得住异常」的智能体(含代码示例)
摘要:本文介绍如何在 LangGraph 中实现 Exception Handling(异常处理)与 Recovery(恢复)。案例介绍:配套 demo 实现一个带反思的健壮位置查询智能体——主查询失败时先反思(分析失败原因、生成改进查询),再用改进查询重试主任务;仍失败则 fallback 粗略查询,实现优雅降级。提供 main.py 命令行演示;支持通过环境变量 SIMULATE_FAILURE_RATE 模拟主查询失败以验证反思与 fallback 逻辑。技术要点:用 LangGraph 的条件边实现「成功→响应、失败且未反思→反思→重试、失败且已反思→fallback」的分支;primary_lookup、reflect、fallback_lookup、response 四节点构成完整流程;错误检测、重试、反思、回退、日志、优雅降级在图中统一实现。
关键词:Exception Handling;Recovery;Reflection;LangGraph;重试;反思;Fallback;优雅降级;条件边;LocationAgentState
源代码链接:Langgraph 16. Exception Handling and Recovery 示例源代码
1. 为什么智能体需要「异常处理与恢复」?
1.1 现实世界的不可预测性
AI 智能体要在真实环境中可靠运行,就必须能够应对不可预见的情况、错误和故障。就像人类遇到意外障碍时会换条路走、退而求其次一样,智能体也需要一套健壮的系统来:检测问题、启动恢复流程,或至少确保受控的失败(controlled failure)——而不是直接崩溃、把烂摊子丢给用户。
想象一下,你使用一个智能客服机器人查询快递物流。当它去调用物流 API 时,可能遇到:网络超时、服务暂时不可用(503)、请求格式错误……如果智能体一遇错就崩溃、直接返回「系统错误」,用户会非常沮丧。这种脆弱性使得智能体难以部署在关键或复杂应用中,因为那里需要持续、稳定的表现。
💡 理解要点:没有结构化异常管理的智能体,在面对工具失败、网络问题、无效数据等干扰时,容易变得脆弱、不可靠,甚至完全失效。Exception Handling and Recovery 正是要解决这一问题。
1.2 模式的核心目标
Exception Handling and Recovery 模式聚焦于构建持久、有韧性的智能体,使其在各种困难和异常面前仍能保持功能连续性和运行完整性。它强调:
- 主动准备(Proactive):提前预判潜在问题(如工具错误、服务不可用),设计应对策略;
- 被动应对(Reactive):在错误发生后,按既定方案响应和恢复。
这种双管齐下的适应性,对智能体在复杂、不可预测环境中成功运行至关重要,能显著提升其有效性和可信度。此外,结合监控与诊断工具,可以更快地发现和解决问题,防止故障升级,在动态变化的环境中保持平稳运行。
1.3 三大核心环节:检测、处理、恢复
该模式可拆解为三个紧密衔接的环节:
(1)错误检测(Error Detection)
细致识别运行中出现的问题,例如:
- 工具输出异常:无效或格式错误的工具返回;
- API 错误:如 404(Not Found)、500(Internal Server Error)等状态码;
- 超时:服务或 API 响应时间异常偏长;
- 输出偏离预期:LLM 或工具返回的内容与预期格式不符、逻辑混乱;
- 主动监控:由其他智能体或专用监控系统进行异常检测,在问题升级前提前发现。
🔍 实际例子:位置查询 API 返回 503,或返回的 JSON 缺少必填字段,都属于需要检测的错误。
(2)错误处理(Error Handling)
一旦检测到错误,需要按既定方案响应:
- 日志(Logging):将错误详情记录到日志,便于后续调试与分析;
- 重试(Retries):对瞬时性错误(如网络抖动、临时 503)重新执行请求,有时可微调参数;
- 回退(Fallbacks):采用备选策略或方法,保证部分功能可用;
- 优雅降级(Graceful Degradation):无法完全恢复时,至少维持部分功能,提供一定价值;
- 通知(Notification):在需要人工介入或协作时,向操作员或其他智能体发出告警。
(3)恢复(Recovery)
将智能体或系统恢复到稳定、可运行状态:
- 状态回滚(State Rollback):撤销最近变更或事务,消除错误影响;
- 诊断(Diagnosis):深入分析错误原因,防止再次发生;
- 自校正(Self-correction):通过调整计划、逻辑或参数,避免同类错误;
- 升级(Escalation):在复杂或严重情况下,将问题交由人工或更高层系统处理。
1.4 与反思(Reflection)的结合
该模式有时可与反思(Reflection)配合使用:若初次尝试失败并抛出异常,反思过程可以分析失败原因,并以改进后的方式(如优化后的 prompt)重新尝试,从而解决错误。这体现了「检测 → 分析 → 再尝试」的闭环。
1.5 小结:要解决什么?
Exception Handling and Recovery 要解决的就是:
- 错误检测:识别工具调用失败、API 错误、超时、无效输出等;
- 错误处理:记录日志、重试、使用备选方案(fallback)、优雅降级、必要时通知人工;
- 恢复:将系统恢复到可运行状态,如状态回滚、自诊断、升级处理。
实施这一模式,可以将智能体从脆弱、不可靠的系统,转变为健壮、可依赖的组件,在充满挑战和不确定性的环境中有效、有韧性地运行,保持功能、减少停机时间,并在面对意外时仍能提供顺畅、可靠的体验。
💡 理解要点:异常处理不是「把错误藏起来」,而是有策略地应对——能重试就重试,能降级就降级,实在不行再升级或告知用户。经验法则:任何部署在动态、真实环境中,且可能面临系统故障、工具错误、网络问题或不可预测输入的智能体,只要运行可靠性是关键需求,就应使用这一模式。
2. 示例设定:一个会「扛错」的位置查询智能体
2.1 案例背景
假设有一个位置查询服务:用户输入地址,智能体调用外部 API 返回精确地理信息(经纬度、行政区划、地标等)。在真实环境中,这类服务常面临两类问题:
- 瞬时性故障:网络抖动、API 临时 503、超时等,重试往往能恢复;
- 输入或逻辑问题:用户地址不完整(如「望京阜通东大街1号」缺少城市前缀)、格式不标准,导致 API 无法识别,单纯重试无效,需要改进查询后再试。
若智能体一遇错就崩溃或直接返回「系统错误」,用户体验会很差。我们希望它在异常面前有策略地应对:能重试就重试,能通过反思改进就改进,实在不行再降级到备选方案,最终仍能提供部分价值。
2.2 方案设计
配套 demo 实现带反思的异常处理流程:
主查询失败 → 反思(分析失败原因,生成改进查询,如补充城市前缀、规范化地址)→ 用改进查询重试主任务 → 仍失败则 fallback(提取城市/区域,调用粗略区域查询)→ 最终响应或道歉。
方案遵循「检测 → 处理 → 恢复」的闭环,在 fallback 前增加「分析失败原因、改进 prompt/查询、再尝试主任务」的步骤,贴近 PDF 中「反思后以改进方式重试」的描述。反思与「盲目重试」的区别在于:先分析失败原因,再根据分析结果改进查询,然后重试主任务,而非简单地用相同参数再试一次。
2.3 典型流程示例
用户输入「望京阜通东大街1号」(不完整)→ 主查询失败 → 反思分析「可能缺少城市前缀」→ 生成「北京市朝阳区望京阜通东大街1号」→ 重试主查询 → 若成功则返回精确信息;若仍失败(如 503)则走 fallback,提取「北京」→ 返回「北京市位于华北平原……」→ 用户至少得到大致区域信息。
💡 理解要点:我们不希望智能体在第一次 API 失败时就「撂挑子」,而是通过重试 + 反思 + fallback + 优雅降级,在异常情况下仍能提供部分价值。
3. 状态与图结构:用 LangGraph 表达「主查询 → 反思 → 重试 / fallback → 响应」
在代码中,我们用 LocationAgentState 描述图中流转的状态(见 exception_handling_graph.py):
class LocationAgentState(TypedDict):
user_query: str # 用户提供的地址或位置描述
refined_query: str # 反思后生成的改进版查询
location_result: str # 最终获取到的位置信息
primary_failed: bool # 主查询是否失败
error_log: list[str] # 错误日志列表
retry_count: int # 主查询重试次数
reflected: bool # 是否已完成反思(避免无限反思循环)
reflection_notes: str # 反思分析笔记(失败原因、改进建议)
verbose: NotRequired[bool] # 是否在 terminal 中显示运行过程(可选)
对应的 LangGraph 结构如下:
START → primary_lookup
├─ 成功 → response → END
├─ 失败且未反思 → reflect → primary_lookup(用 refined_query 重试)
└─ 失败且已反思 → fallback_lookup → response → END
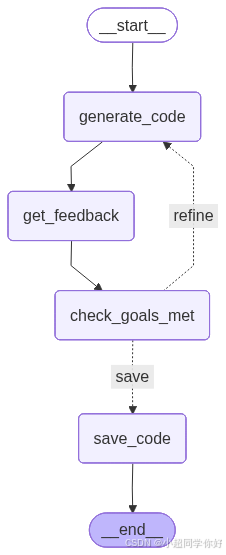
在 build_location_agent() 中,我们用 条件边 实现分支:
def build_location_agent():
"""
构建 Exception Handling and Recovery(含反思)的 LangGraph。
流程:
START → primary_lookup
├─ 成功 → response → END
├─ 失败且未反思 → reflect → primary_lookup(用 refined_query 重试)
└─ 失败且已反思 → fallback_lookup → response → END
"""
graph = StateGraph(LocationAgentState)
graph.add_node("primary_lookup", primary_lookup_node)
graph.add_node("reflect", reflect_node)
graph.add_node("fallback_lookup", fallback_lookup_node)
graph.add_node("response", response_node)
graph.add_edge(START, "primary_lookup")
graph.add_conditional_edges(
"primary_lookup",
_route_after_primary,
{"response": "response", "reflect": "reflect", "fallback_lookup": "fallback_lookup"},
)
graph.add_edge("reflect", "primary_lookup") # 反思后回到主查询重试
graph.add_edge("fallback_lookup", "response")
graph.add_edge("response", END)
return graph
路由逻辑:primary_failed 为 False 时走向 response;为 True 且 reflected 为 False 时走向 reflect;为 True 且 reflected 为 True 时走向 fallback_lookup。
4. 核心节点:主查询、反思、回退、响应
4.1 primary_lookup:主查询 + 重试
该节点负责「精确位置查询」:优先使用反思后的 refined_query,否则使用 user_query。调用 _get_precise_location_info 工具。若抛出异常,则记录错误、重试(最多 2 次);若全部失败,设置 primary_failed=True,由条件边路由到 reflect 或 fallback_lookup。为便于演示,可通过环境变量 SIMULATE_FAILURE_RATE 模拟主查询失败。
def primary_lookup_node(state: LocationAgentState) -> LocationAgentState:
"""
主查询节点:优先使用反思后的 refined_query,否则使用 user_query。
若失败,记录错误并设置 primary_failed=True。
"""
query = state.get("refined_query") or state["user_query"]
retry_count = state.get("retry_count", 0)
max_retries = 2
is_refined = bool(state.get("refined_query"))
_log_and_print(
state,
f"[primary_lookup] 第 {retry_count + 1} 次尝试({'反思后' if is_refined else '初始'})...",
f"\n📍 主查询(第 {retry_count + 1} 次){'[反思后重试]' if is_refined else ''}:{query[:50]}...",
)
for attempt in range(max_retries - retry_count):
try:
result = _get_precise_location_info(query)
state["location_result"] = result
state["primary_failed"] = False
_log_and_print(
state,
f"[primary_lookup] 成功,结果长度 {len(result)} 字符",
f"✅ 主查询成功:{result[:150]}{'...' if len(result) > 150 else ''}",
)
return state
except Exception as e:
err_msg = f"主查询第 {retry_count + attempt + 1} 次失败: {type(e).__name__}: {e}"
state["error_log"] = state.get("error_log", []) + [err_msg]
state["retry_count"] = retry_count + attempt + 1
logger.warning(err_msg)
_log_and_print(state, err_msg, f"⚠️ {err_msg}")
state["primary_failed"] = True
_log_and_print(
state,
"[primary_lookup] 主查询全部失败",
"⚠️ 主查询全部失败。",
)
return state
💡 理解要点:重试适用于瞬时性错误(如网络抖动、临时 503);若错误是持久的(如参数错误),反思会尝试改进查询后再重试。
4.2 reflect:反思节点
该节点在主查询失败且尚未反思时执行:根据 error_log 分析失败原因,调用 LLM 生成改进后的地址查询(如补充城市前缀、规范化格式),写入 refined_query,并设置 reflected=True。反思后 retry_count 重置为 0,以便主查询获得新的 2 次尝试机会。
def reflect_node(state: LocationAgentState) -> LocationAgentState:
"""
反思节点:分析失败原因,生成改进后的查询(refined_query)。
例如:用户输入「望京阜通东大街1号」→ 反思发现可能缺少城市前缀、格式不标准
→ 生成「北京市朝阳区望京阜通东大街1号」。
"""
user_query = state["user_query"]
error_log = state.get("error_log", [])
_log_and_print(
state,
"[reflect] 分析失败原因,生成改进后的查询...",
"\n🔍 反思:分析失败原因,尝试改进查询...",
)
error_log_str = "\n".join(f"- {e}" for e in error_log[-3:])
content = Template(REFLECT_PROMPT).render(
user_query=user_query,
error_log=error_log_str,
)
completion = _client.chat.completions.create(
model=_llm_config.model,
messages=[{"role": "user", "content": content}],
temperature=0.3,
)
raw = (completion.choices[0].message.content or "").strip()
refined_query = user_query
notes = raw
if "改进后的地址查询:" in raw:
try:
start = raw.index("改进后的地址查询:") + len("改进后的地址查询:")
end = raw.find("\n", start) if "\n" in raw[start:] else len(raw)
refined_query = raw[start:end].strip().strip("<>")
if not refined_query:
refined_query = user_query
except Exception:
pass
state["refined_query"] = refined_query
state["reflection_notes"] = notes
state["reflected"] = True
state["retry_count"] = 0 # 反思后重试时重置,给予新的 2 次尝试机会
_log_and_print(
state,
f"[reflect] 生成改进查询: {refined_query[:60]}...",
f"📝 反思结果:{refined_query}\n (分析:{notes[:100]}...)",
)
return state
4.4 response:最终响应
该节点整理 location_result,以友好方式呈现。若 location_result 为空(主查询和 fallback 均失败),则返回礼貌的道歉信息,并可在 verbose 模式下输出 error_log 供排查。
def response_node(state: LocationAgentState) -> LocationAgentState:
"""响应节点:整理最终结果。"""
result = state.get("location_result", "")
_log_and_print(state, "[response] 生成最终回复...", "\n📤 生成最终回复...")
if result:
_log_and_print(
state,
"[response] 成功返回位置信息",
f"\n📋 最终结果:\n{result[:300]}{'...' if len(result) > 300 else ''}",
)
else:
apology = (
"抱歉,暂时无法获取您请求的位置信息。"
"可能原因:服务暂时不可用或地址无法识别。"
"请稍后重试或提供更具体的地址。"
)
state["location_result"] = apology
_log_and_print(state, "[response] 无有效结果,返回道歉信息", f"\n📋 {apology}")
return state
5. 交互入口:命令行与演示
5.1 命令行
cd demo_codes
python main.py
默认运行「望京阜通东大街1号」示例(不完整地址)。主查询失败后,反思节点会分析失败原因、生成改进查询,再重试主任务;若仍失败则走 fallback。可在 main.py 中修改 user_query 测试其他地址。
5.2 演示反思 + Fallback 逻辑
若要模拟主查询失败、触发反思与 fallback,可设置环境变量:
Windows (PowerShell):
$env:SIMULATE_FAILURE_RATE="1.0"
python main.py
Linux / Mac:
export SIMULATE_FAILURE_RATE=1.0
python main.py
此时主查询会 100% 模拟失败,智能体会先反思改进查询再重试,仍失败则走 fallback,输出基于城市/区域的粗略信息。
💡 理解要点:反思与「盲目重试」的区别在于——先分析失败原因,再根据分析结果改进 prompt/查询,然后重试主任务,而非简单地用相同参数再试一次。
6. 异常处理策略一览
| 策略 | 实现方式 |
|---|---|
| 错误检测 | try/except 捕获主查询、fallback 异常 |
| 重试 | primary_lookup 内最多重试 2 次 |
| 反思 | 分析失败原因,生成改进查询,再重试主任务 |
| Fallback | 反思重试仍失败后,提取城市名,调用粗略区域查询 |
| 日志 | 错误写入 error_log,便于排查与审计 |
| 优雅降级 | 无法获取精确信息时,至少返回粗略区域或道歉信息 |
💡 理解要点:生产环境中还可增加超时、通知人工、状态回滚等;LangGraph 也支持 RetryPolicy 对节点级重试进行配置,可按需选用。
7. 实践应用场景
Exception Handling and Recovery 适用于任何依赖外部服务、工具、API 的智能体,例如:
- 客服聊天机器人:数据库暂时不可用时,告知用户「系统维护中,请稍后再试」,或升级到人工;
- 金融交易机器人:遇到「资金不足」「市场已闭市」等错误时,记录日志、不重复无效请求、通知用户;
- 智能家居控制:设备离线或网络异常时,重试后仍失败则通知用户手动干预;
- 批量数据处理:遇到损坏文件时跳过该文件、记录错误、继续处理其余文件,最后汇总报告;
- 网页爬虫:遇到 404、503、CAPTCHA 时,暂停、换代理或报告失败 URL。
🔍 实际例子:这些场景的共同点是——外部依赖不可控,智能体必须能检测、应对、恢复,而不是一遇错就崩溃。
8. 注意事项与改进方向
本示例为教学演示,生产环境需考虑:
- 重试策略:可引入指数退避(exponential backoff)、最大重试次数、仅对特定异常重试;
- Fallback 层级:可设计多级 fallback(如精确 → 城市 → 省份 → 道歉);
- 人工升级:对无法自动恢复的严重错误,可结合 LangGraph 的
interrupt实现人机协作; - 可观测性:将
error_log接入监控、告警系统,便于运维发现与排查问题。
9. 小结:如何在自己的 Agent 中落地 Exception Handling
- 显式建模失败状态:在状态中增加
primary_failed、error_log、reflected等字段,让图能根据失败情况路由; - 节点内重试:对瞬时性错误,在节点内实现有限次重试;
- 反思节点:主路径失败时,先分析失败原因、生成改进方案(如改进 prompt/查询),再重试主任务;
- 条件边实现 fallback:反思重试仍失败时,路由到 fallback 节点;
- 优雅降级:fallback 也失败时,返回部分结果或友好提示,而非直接抛错。
当你把这五步跑通后,再扩展到更复杂的多工具、多服务、多级 fallback 场景,就会发现:方法论是一致的——检测、重试、反思、回退、降级,让智能体在异常面前依然可靠。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)