V-JEPA 2: Self-Supervised Video Models EnableUnderstanding, Prediction and Planning ——论文翻译
现代人工智能的一大核心挑战,是让智能体仅通过观察就能学习理解世界并做出行动决策(杨立昆,2022)。本文提出一种自监督学习方法,将互联网规模的视频数据与少量交互数据(机器人运动轨迹)相结合,研发出能够在物理世界中实现场景理解、状态预测和行动规划的模型。研究首先在包含超 100 万小时互联网视频的视频与图像数据集上,对无动作依赖的联合嵌入预测架构 V-JEPA 2 进行预训练。该模型在运动理解任务中表现优异(在 Something-Something v2 数据集上取得 77.3 的 Top-1 准确率),在人类行为预测任务中达到 sota(最先进)性能(在 Epic-Kitchens-100 数据集上取得 39.7 的 5 阶召回率),性能超越此前的专用任务模型。此外,将 V-JEPA 2 与大语言模型对齐后,在 80 亿参数规模下,该模型在多个视频问答任务中均实现 sota 性能(如在 PerceptionTest 数据集上达 84.0、TempCompass 数据集上达 76.9)。最后,研究证明通过对基于潜在动作条件的世界模型 V-JEPA 2-AC 进行后训练,仅使用 Droid 数据集中不足 62 小时的无标注机器人视频,就能将自监督学习应用于机器人规划任务。研究人员在两个不同实验室的 Franka 机械臂上零样本部署 V-JEPA 2-AC,借助图像目标规划实现了物体的抓取与放置操作。值得注意的是,这一成果的实现,未在实验环境的机器人上采集任何数据,也未进行任何任务专用训练或设置奖励机制。本文的研究表明,通过互联网规模数据和少量机器人交互数据开展自监督学习,能够训练出可在物理世界中完成规划任务的世界模型。
代码地址:https://github.com/facebookresearch/vjepa2
博文地址:https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks
1 引言
人类在执行新任务、身处陌生环境时,具备适应与泛化的能力。诸多认知学习理论表明,人类通过整合低层感官输入来表征并预测未来状态,从而构建起对世界的内部模型(克雷克,1967;拉奥、巴拉德,1999);这些理论还指出,这一世界模型会影响人类在任一时刻的感知,是我们理解现实世界的关键(弗里斯顿,2010;克拉克,2013;诺尔特曼等,2015)。此外,预测自身行为对世界未来状态的影响,也是实现目标导向规划的核心能力(萨顿、巴托,1981、1998;哈、施密德胡伯,2018;沃尔珀特、加哈拉马尼,2000)。让智能体从视频等感官数据中学习构建世界模型,有望使其像人类一样理解物理世界、预测未来状态,并在新场景中有效规划行动,进而打造出能够处理从未接触过的任务的智能系统。
此前的研究多基于状态 - 动作序列的交互数据,开发预测性世界模型,且往往依赖环境的显式奖励反馈来推导目标(萨顿、巴托,1981;弗拉基亚达基等,2015;哈、施密德胡伯,2018;哈夫纳等,2019b;汉森等,2022)。但现实世界中交互数据的获取存在局限性,制约了这类方法的规模化应用。为解决这一问题,近期研究开始结合互联网规模的视频数据与交互数据,训练用于机器人控制的动作条件视频生成模型,然而这类模型在基于模型的控制策略下,机器人实际执行任务的效果有限(胡等,2023;杨等,2024b;布鲁斯等,2024;阿加瓦尔等,2025)。究其原因,这类研究往往侧重评估预测结果的真实性和视觉质量,而非模型的规划能力,这或许是由于生成视频的规划过程计算成本过高。
本文以自监督学习假说为基础,旨在构建能够通过观察获取世界背景知识的世界模型。具体而言,研究采用联合嵌入预测架构(JEPA)(杨立昆,2022),该架构通过在学习到的表征空间中进行预测完成模型训练。与完全基于交互数据的学习方法不同,自监督学习能够利用互联网规模的视频数据 —— 这类数据仅包含状态序列,无直接的动作观测 —— 学习表征视频观测信息,并在习得的表征空间中构建世界动态的预测模型。此外,与视频生成类方法相比,JEPA 架构专注于学习场景中可预测部分的表征(如运动物体的轨迹),而忽略生成式目标所强调的不可预测细节,因为生成式方法需要进行像素级预测(如草地上每根草叶、树上每片叶子的精确位置)。研究通过规模化 JEPA 预训练证明,该方法能得到具备 sota 场景理解和预测能力的视频表征,且这类表征可作为动作条件预测模型的基础,实现零样本规划。
本文提出的 V-JEPA 2 采用分阶段训练流程:先在互联网规模的视频数据上进行无动作依赖的预训练,再利用少量交互数据进行后训练(见图 1)。第一阶段采用掩码去噪特征预测目标(阿斯拉恩等,2023;巴尔德斯等,2024),让模型在学习到的表征空间中预测视频的掩码片段。研究训练的 V-JEPA 2 编码器参数规模最高达 10 亿,训练数据包含超 100 万小时的视频。实验证实,规模化的自监督视频预训练能提升编码器的视觉理解能力,包括通用的运动和外观识别能力,这一点在基于探针的评估中,以及将编码器与语言模型对齐完成视频问答任务的实验中均得到验证(克罗耶尔等,2024;帕特劳钱等,2023;刘等,2024c;蔡等,2024;上官等,2024)。
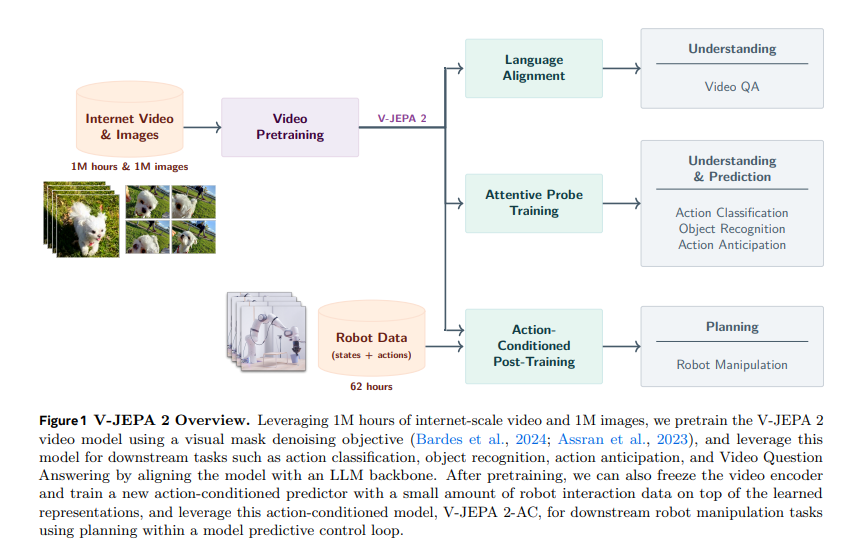
在互联网规模视频数据的预训练完成后,研究利用第一阶段习得的表征,在少量交互数据上训练动作条件世界模型 V-JEPA 2-AC。该动作条件世界模型是一个拥有 3 亿参数的 Transformer 网络,采用块因果注意力机制,能基于动作和历史状态,自回归预测下一视频帧的表征。研究仅使用 Droid 数据集中 62 小时的无标注交互数据(哈扎特斯基等,2024),就证实了训练潜在世界模型的可行性:该模型在给定子目标的情况下,能为 Franka 机械臂规划动作,并通过单目 RGB 相机,在新环境中零样本完成抓取操作类的机器人操控任务。
综上,研究证明基于视频的联合嵌入预测架构自监督学习,能够构建出可理解物理世界、预测未来状态并在新场景中有效规划的世界模型,而这一成果的实现,依托于互联网规模的视频数据和少量交互数据。具体研究成果如下:
- 场景理解 —— 基于探针的分类任务:规模化自监督视频预训练得到的视频表征,可应用于多种任务。V-JEPA 2 擅长编码细粒度的运动信息,在 Something-Something v2 等需要运动理解的任务中表现优异,借助注意力探针取得 77.3 的 Top-1 准确率。
- 场景理解 —— 视频问答任务:V-JEPA 2 编码器可用于训练多模态大语言模型,完成视频问答任务。在需要物理世界理解和时间推理能力的多个基准测试中,该模型在 80 亿参数语言模型类别中达到 sota 性能,如 MVP 数据集(配对准确率 44.5)、PerceptionTest 数据集(测试集准确率 84.0)、TempCompass 数据集(多选题准确率 76.9)、TemporalBench 数据集(多二值短问答准确率 36.7)和 TOMATO 数据集(准确率 40.3)。值得注意的是,研究证明未经过语言监督预训练的视频编码器,与语言模型对齐后仍能实现 sota 性能,这一结论与传统认知相悖(袁等,2025;王等,2024b)。
- 状态预测:大规模自监督视频预训练能提升模型的预测能力。V-JEPA 2 在 Epic-Kitchens-100 人类行为预测任务中,借助注意力探针取得 39.7 的 5 阶召回率,达到 sota 性能,相较此前的最优模型实现了 44% 的相对提升。
- 行动规划:研究表明,仅使用主流 Droid 数据集中 62 小时的无标注机器人操控数据对 V-JEPA 2 进行后训练,得到的 V-JEPA 2-AC 模型,可在新环境中通过给定子目标的规划,完成抓取类操控任务。未在实验室的机器人上采集任何额外数据,也未进行任务专用训练或设置奖励机制的情况下,该模型成功完成了抓取、带新物体的抓取与放置等抓取类操控任务,且能适应新环境。
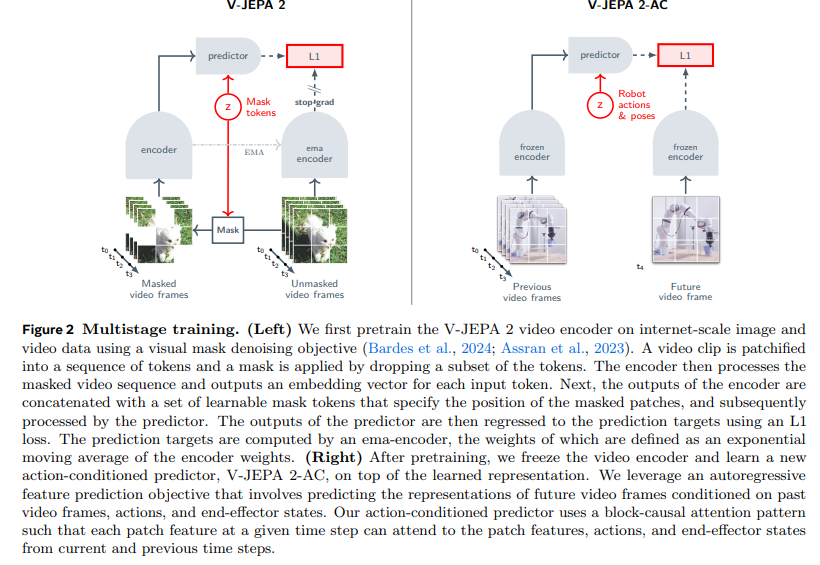
2 V-JEPA 2:规模化自监督视频预训练
本研究在包含超 100 万小时视频的视觉数据集上对 V-JEPA 2 进行预训练,其自监督训练任务基于表征空间中的掩码去噪,且以 V-JEPA 框架为基础(巴尔德斯等人,2024)。本文通过探索更大规模的模型、扩充预训练数据量,并引入时空渐进式分辨率训练策略,对 V-JEPA 框架进行拓展,实现了对超短 16 帧视频片段的高效预训练。
2.1 方法
表征空间中的掩码去噪
V-JEPA 的训练目标是从经过掩码处理(随机丢弃部分图像块)的视频视图x中,预测视频y的学习表征(见图 2 左)。该任务的元架构由两部分构成:用于提取视频表征的编码器Eθ(⋅),以及用于预测视频掩码部分表征的预测器Pϕ(⋅)。编码器与预测器通过如下目标函数联合训练:
![]()
其中,Δy为可学习的掩码标记,用于指示被丢弃图像块的位置;损失函数引入停止梯度操作sg(⋅)和编码器网络权重θ的指数移动平均θˉ,以避免表征坍缩;该损失仅作用于掩码块的预测结果。
模型架构
编码器Eθ(⋅)与预测器Pϕ(⋅)均基于视觉 Transformer(Dosovitskiy 等人,2020,简称 ViT)构建。为在视觉 Transformer 中编码相对位置信息,本研究采用旋转位置嵌入(RoPE),替代巴尔德斯等人(2024)所使用的绝对正余弦位置嵌入。通过将特征维度划分为三个近似相等的分段(分别对应时间、高度、宽度轴),并对每个分段独立应用一维旋转操作,实现了传统一维 RoPE 的三维扩展(苏等人,2024)。实验发现,相较于绝对正余弦位置嵌入(瓦斯瓦尼等人,2017),三维 RoPE 有助于提升大模型训练的稳定性。
在使用 Transformer 编码器处理视频时,首先将视频切分为尺寸为2×16×16(时间 × 高度 × 宽度)的管状图像块序列,并采用与巴尔德斯等人(2024)相同的多块掩码策略。
规模化核心技术
本节将介绍并验证四项关键技术,这些技术实现了 V-JEPA 预训练原理的规模化拓展,最终构建出 V-JEPA 2 模型,具体如下:
- 数据规模化:通过整合并筛选新增数据来源,将数据集规模从 200 万个视频扩充至 2200 万个;
- 模型规模化:将编码器架构从 3 亿参数的 ViT-L 扩展至超 10 亿参数的 ViT-g(翟等人,2022);
- 更长时训练:采用预热 - 恒定 - 衰减的学习率调度策略,简化超参数调优流程,将训练迭代次数从 9 万次提升至 25.2 万次,充分利用新增数据的价值;
- 更高分辨率:基于预热 - 恒定 - 衰减调度策略,实现更高分辨率视频和更长视频片段的高效训练 —— 在预热和恒定阶段训练短时长、低分辨率的视频片段,在最终的衰减阶段提升视频分辨率和 / 或片段时长。
本节后续将详细阐述每项技术,并通过下文介绍的评估方案量化其效果。
评估方案
模型预训练的目标是让编码器具备通用的视觉理解能力。因此,本研究通过评估模型在六项运动和外观分类任务上学到的表征质量,验证数据与模型设计方案的有效性,所选任务包括:Something-Something v2(戈亚尔等人,2017)、Diving-48(李等人,2018)、Jester(马特津斯卡等人,2019)、Kinetics(凯伊等人,2017)、COIN(唐等人,2019)和 ImageNet(邓等人,2009)。
评估采用冻结编码器方案:固定编码器权重,在其表征之上训练一个任务专用的 4 层注意力探针,输出预测类别。本节重点关注六项理解任务的平均准确率,有关任务细节、评估方案及详细结果见第 5 节。
2.2 自监督视频学习的规模化
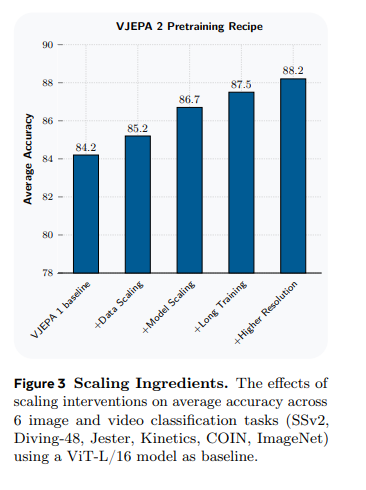
本部分首先总结规模化分析的核心结论,探究上述四项关键技术对下游任务平均性能的影响。图 3 展示了这些规模化改进对六项分类任务平均准确率的提升效果,以基于 200 万个视频、采用 V-JEPA 目标预训练的 ViT-L/16 模型作为基线。结果显示:将数据集从 200 万扩充至 2200 万个视频(VM22M),准确率提升 1.0 个百分点;将模型从 3 亿参数扩展至 10 亿参数(ViT-g/16),准确率再提升 1.5 个百分点;将训练迭代次数从 9 万次增加至 25.2 万次,准确率进一步提升 0.8 个百分点;最后,在预训练和评估阶段同时提升空间分辨率(256→384)和时间时长(16→64 帧),模型平均准确率达到 88.2%,相较 ViT-L/16 基线模型实现了 4.0 个百分点的累计提升。
每项改进均带来了性能正向提升,印证了自监督视频学习中规模化的潜力。
2.3 预训练数据集
本部分将介绍构成预训练数据集的视频和图像来源,以及数据集的筛选方法。
数据集规模扩充
研究通过整合公开可用的数据源,构建了大规模视频数据集,采用公开数据源也便于其他研究者复现实验结果。该数据集包含:Something-Something v2 的第一视角视频(戈亚尔等人,2017)、Kinetics 400/600/700 的第三人称动作视频(凯伊等人,2017;卡雷拉等人,2018、2019)、HowTo100M 的 YouTube 教程视频(米什等人,2019)、YT-Temporal-1B 的通用 YouTube 视频(泽勒斯等人,2022,简称 YT1B);同时加入 ImageNet 的图像数据(邓等人,2009),以提升预训练数据的视觉覆盖度。
为实现图像与视频的联合预训练,将单张图像进行时间维度复制,转化为所有帧完全相同的 16 帧视频。训练过程中,通过经验手动调优确定各数据源的采样权重系数,最终得到的数据集包含 2200 万个样本,命名为 VideoMix22M(简称 VM22M)。各数据源及对应权重见表 1。
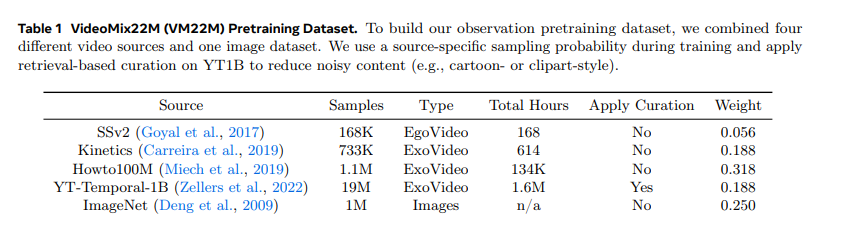
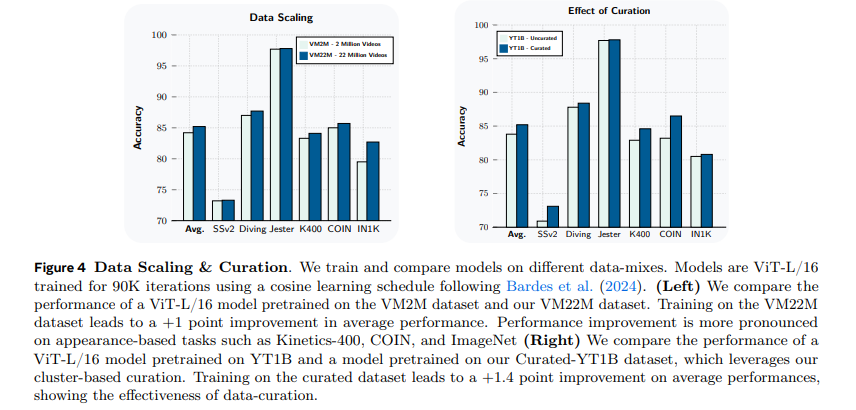
图 4(左)对比了基于 VM22M 预训练的 ViT-L/16 模型,与基于巴尔德斯等人(2024)提出的 200 万个视频的 VideoMix2M 数据集训练的同规格模型性能。结果显示,基于 VM22M 训练的模型,在视觉理解任务上的平均性能提升 1 个百分点,且在 Kinetics-400、COIN、ImageNet 等基于外观的任务上提升更为显著,证明提升视觉覆盖度对这类任务的重要性。
数据筛选
YT1B 是一个大型视频数据集,包含 140 万小时视频,与 Kinetics、Something-Something v2 等小规模视频数据集相比,未经过筛选且几乎无过滤处理。未经筛选和平衡的数据集会影响模型性能(阿斯拉恩等人,2022;奥夸布等人,2023),因此本研究对 YT1B 进行筛选,将现有的基于检索的筛选流程适配于视频数据处理。
具体步骤为:从 YT1B 视频中提取场景片段,为每个场景计算嵌入向量;随后采用基于聚类的检索方法(奥夸布等人,2023),根据由 Kinetics、Something-Something v2、COIN 和 EpicKitchen 训练集构成的目标分布,选择视频场景片段。数据集构建的详细流程见附录 A.2。与奥夸布等人(2023)的方法一致,本研究确保目标验证集中的所有视频均未出现在初始的未筛选数据池中。
图 4(右)对比了基于未筛选 YT1B 和筛选后 YT1B 训练的 ViT-L 模型,在视觉理解任务上的平均性能。结果显示,基于筛选后数据集训练的模型,平均性能相较基线提升 1.4 个百分点;值得注意的是,在 ViT-L 规模下,基于筛选后 YT1B 训练的模型性能,与基于完整 VM22M 训练的模型具有竞争力。但更大规模的模型能从 VM22M 训练中获得更多收益(见附录 A.2),说明将筛选后 YT1B 与其他数据源结合,能进一步提升模型的规模化潜力。
2.4 预训练方案
模型规模扩充
为探究模型的规模化特性,本研究训练了一系列编码器模型,参数规模从 3 亿(ViT-L)覆盖至 10 亿(ViT-g),所有编码器的架构细节见附录表 12。需注意,所有编码器均搭配相同的预测器架构(近似 ViT-small)。
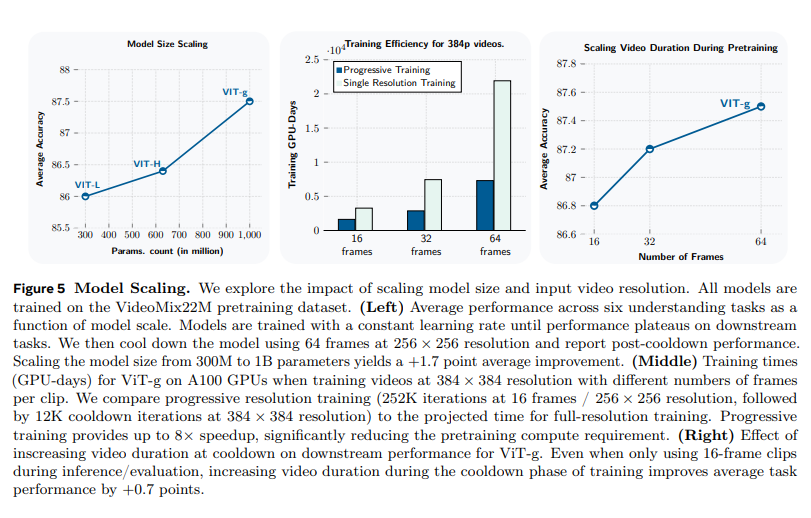
图 5(左)报告了这些编码器在视觉理解任务上的平均性能,结果显示:将模型参数从 3 亿(ViT-L)扩展至 10 亿(ViT-g),平均性能提升 1.5 个百分点;运动和外观理解任务均从模型规模化中受益,其中 Something-Something v2 准确率提升 1.6 个百分点,Kinetics 提升 1.5 个百分点(见表 4)。该结果证实,自监督视频预训练能有效利用更大的模型容量,且这一特性在 10 亿参数的 ViT-g 模型上依然成立。
训练调度策略
V-JEPA 2 的训练采用预热 - 恒定学习率 + 冷却阶段的调度策略(翟等人,2022;哈格勒等人,2024)。与哈格勒等人(2024)的研究结论一致,本研究发现该策略的性能与半余弦调度策略(洛希洛夫和胡特,2016)相当,且能更经济地实现长时训练 —— 可从恒定阶段的不同检查点启动多次冷却训练。
本研究简化了巴尔德斯等人(2024)的训练方案,将教师网络的指数移动平均系数和权重衰减系数设为固定值,而非采用梯度上升调度,因为这类参数调整对下游理解任务的影响极小。图 3 显示,将 ViT-g 模型的训练调度从 9 万次迭代扩展至 25.2 万次,平均性能提升 0.8 个百分点,验证了延长训练时长的收益。同时,该调度策略还支持渐进式训练,可在冷却阶段逐步提升视频分辨率。
高效渐进式分辨率训练
现有多数视频编码器主要针对 16 帧的短片段(约 1 秒)进行训练(巴尔德斯等人,2024;王等人,2024b、2023),本研究则探索对长达 64 帧(16 秒)的更高空间分辨率视频进行训练。但视频时长和分辨率的提升会导致训练时间急剧增加 —— 若直接对 ViT-g 模型采用 64×384×384 的输入尺寸,训练约需 60 个 GPU 年(见图 5 中)。
为降低计算成本,本研究采用渐进式分辨率策略(图夫龙等人,2019;奥夸布等人,2023),在保证下游性能的同时提升训练效率,具体训练流程为:
- 预热阶段:在 1.2 万次迭代内,对 16 帧、256×256 分辨率的视频进行训练,学习率线性预热;
- 主训练阶段:以恒定学习率对相同规格视频训练 22.8 万次迭代;
- 冷却阶段:在 1.2 万次迭代内,线性衰减学习率,同时提升视频的时长和分辨率。
由此,训练更高时长、更高分辨率视频带来的额外计算开销,仅在最终的冷却阶段产生。该方法实现了高效的高分辨率训练:如图 5(中)所示,对于输入为 64 帧、384×384 分辨率的模型,渐进式训练相较全程以全分辨率从头训练,GPU 耗时减少 8.4 倍。下文将进一步验证,处理更长时长、更高分辨率输入的模型,在性能上具备显著优势。
视频时空分辨率的规模化
图 5 探究了输入视频分辨率对下游任务性能的影响:在预训练阶段将视频片段时长从 16 帧提升至 64 帧,而评估阶段仍固定为 16 帧时,模型平均性能提升 0.7 个百分点(图 5 右);此外,在评估阶段同时提升视频时长和分辨率,所有任务的性能均得到显著改善(见表 4 及附录 A.4.2)。
上述结果证实,自监督视频预训练能从训练和评估阶段的时间分辨率提升中双重受益。本研究还尝试将视频片段进一步延长至 128 帧和 256 帧,但发现在所选的理解任务中,性能未实现超出 64 帧的额外提升。
3 V-JEPA 2-AC:学习动作条件世界模型
预训练完成后,V-JEPA 2 模型能够对视频中的缺失部分进行预测,但这些预测并未直接考虑智能体可能采取的动作所产生的因果效应。本节将介绍训练的下一阶段 —— 通过利用少量交互数据,使模型具备规划能力。具体而言,研究在冻结的 V-JEPA 2 视频编码器基础上,训练一个帧因果动作条件预测器(见图 2 右)。模型训练数据来源于 Droid 数据集(哈扎特斯基等人,2024),该数据集包含通过遥操作收集的桌面级 Franka Panda 机械臂实验数据。最终得到的动作条件模型命名为 V-JEPA 2-AC,第 4 节将展示如何将该模型融入模型预测控制规划循环,实现新环境中的动作规划。
3.1 动作条件世界模型训练
本研究的目标是基于预训练后的 V-JEPA 2 模型,构建一个潜在世界模型,通过闭环模型预测控制,实现嵌入式智能系统的控制。为达成这一目标,研究训练了 V-JEPA 2-AC—— 一个自回归模型,能够基于控制动作和本体感受观测,预测未来视频观测的表征。
本节将以配备固定第三人称相机的桌面机械臂为具体实例,详细阐述该框架的实现:控制动作对应末端执行器指令,模型训练使用 Droid 原始数据集中约 62 小时的无标注视频。这些视频片段通常为 3-4 秒,记录了配备两指夹持器的 7 自由度 Franka Emika Panda 机械臂的运动过程。此处的 “无标注视频” 指未使用任何额外元数据(如任务类型、演示是否成功等奖励相关信息),仅利用数据集中的原始视频和末端执行器状态信号(每个视频均附带元数据,记录每帧的末端执行器状态 —— 包括三维位置、三维姿态和一维夹持器状态)。
模型输入
训练的每个迭代中,从 Droid 数据集中随机采样 4 秒的视频片段,为简化流程,丢弃时长不足 4 秒的视频,最终得到的训练数据包含不到 62 小时的视频。采样的视频片段分辨率为 256×256,帧率为 4 帧 / 秒,形成 16 帧的视频片段,记为(xk)k∈[16],其中xk代表单个视频帧。机器人在每个观测时刻的末端执行器状态记为序列(sk)k∈[16],sk是相对于机器人基座定义的 7 维实值向量 —— 前三维编码末端执行器的笛卡尔坐标位置,接下来三维以外部欧拉角形式编码其姿态,最后一维编码夹持器状态。
通过计算相邻帧之间末端执行器状态的变化,构建动作序列(ak)k∈[15]:每个动作ak是 7 维实值向量,代表第k帧与第k+1帧之间末端执行器状态的变化量。对采样的视频片段应用随机缩放裁剪增强,长宽比采样范围为 (0.75, 1.35)。
损失函数
我们使用 V-JEPA 2 的编码器 E(·) 作为图像编码器,对序列中的每一帧独立进行编码,其中 zₖ := E(xₖ) ∈ ℝ^{H×W×D},H × W 表示特征图的空间分辨率,D 表示嵌入维度。在实际实现中,我们的特征图是使用在后训练(post-training)阶段冻结的 ViT 编码器得到的,形状为 16×16,末端执行器(end-effector)状态和动作被时间上交织排列为 (aₖ, sₖ, zₖ){k∈[15]},然后输入到一个 Transformer 预测器网络 P_φ(·),以获得下一状态表示的预测序列 {ẑ{k+1}}_{k∈[15]}。
最终的标量教师强制(teacher-forcing)损失函数计算如下:
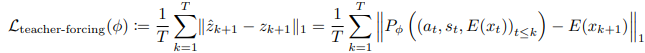
其中 T = 15。
此外,我们还计算了一个两步 rollout 损失( rollout loss),以提升模型在推理时进行自回归 rollout 的能力。为了表述简洁并略微重载记号,我们用 P_φ(a_{1:T}, s_1, z_1) ∈ ℝ^{H×W×D} 表示从 (s₁, z₁) 开始、通过自回归 rollout 得到的最终预测状态序列(使用预测器的输出逐步反馈作为下一步输入)。
相应的 rollout 损失定义为:
![]()
在实践中,我们在计算 rollout 损失时使用 T = 2,从而只通过一个循环步骤来微分预测器(differentiate the predictor through one recurrent step)。
最终的整体训练目标为:
![]()
并针对预测器权重 φ 进行最小化。为了说明目的,训练过程如图 6 所示(其中教师强制损失和 rollout 损失均以 T = 4 为例进行示意)。
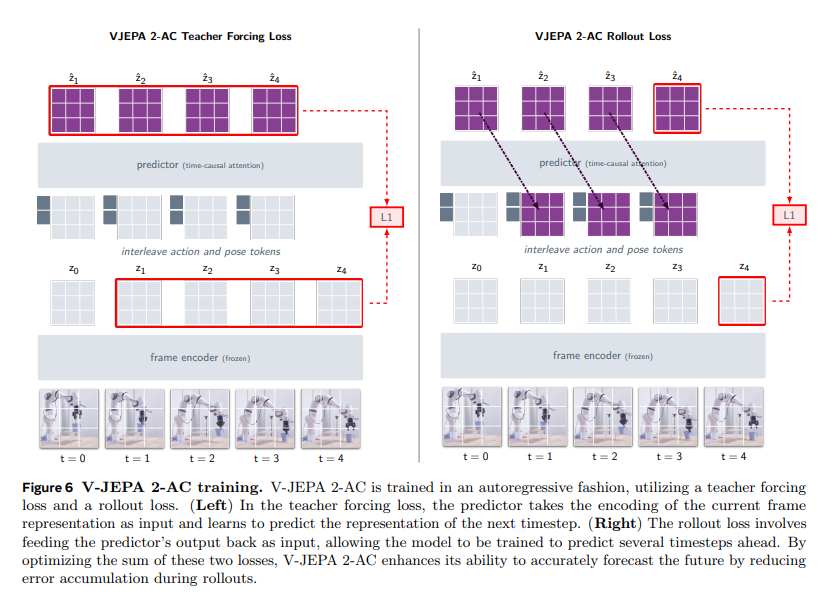
V-JEPA 2-AC 采用自回归方式训练,结合教师强制损失和滚动损失:
- (左)教师强制损失训练中,预测器以当前帧表征的编码结果为输入,学习预测下一时刻的表征;
- (右)滚动损失训练中,将预测器的输出反馈至输入端,使模型能够学习预测多个未来时刻的表征。
通过优化这两项损失的总和,V-JEPA 2-AC 减少了滚动预测过程中的误差累积,提升了未来状态预测的准确性。
模型架构
预测器网络Pϕ(⋅)是一个拥有 3 亿参数的 Transformer 网络,包含 24 层网络、16 个注意力头、1024 维隐藏层维度,激活函数采用 GELU。输入至预测器的动作、末端执行器状态和扁平化特征图,通过独立的可学习仿射变换映射至预测器的隐藏层维度;同样,预测器最后一个注意力块的输出,通过可学习仿射变换映射回编码器的嵌入维度。
研究采用三维旋转位置嵌入(3D-RoPE)实现扁平化特征图中每个视频块的时空位置表征,而仅对动作和姿态标记应用时间旋转位置嵌入。预测器采用块因果注意力模式,使得特定时刻的每个块特征,能够关注到同一时刻及之前时刻的动作、末端执行器状态和其他块特征。
3.2 通过规划推断动作
能量最小化
给定目标状态的图像,研究通过规划将 V-JEPA 2-AC 应用于下游任务:在每个时刻,通过最小化目标条件能量函数,为固定的时间范围规划动作序列;随后执行第一个动作,观测新状态,重复该过程。设sk为当前末端执行器状态,xk和xg分别为当前观测帧和目标图像,通过视频编码器独立编码得到特征图zk和zg。给定规划时域T,通过最小化目标条件能量函数,
![]()
优化机器人动作序列(ai∗)i∈[T]:即(ai∗)i∈[T]:=argmina~1:TE(a^1:T;zk,sk,zg)。
如图 7 所示,模型通过选择使世界模型预测的T步后状态表征,与目标表征的 L1 距离最小的轨迹,推断动作序列(ai∗)i∈[T]。实际应用中,每个规划步骤采用交叉熵方法(鲁宾斯坦,1997)最小化式 (5),并仅在机器人上执行第一个动作,之后按照滚动时域控制的逻辑重新规划。
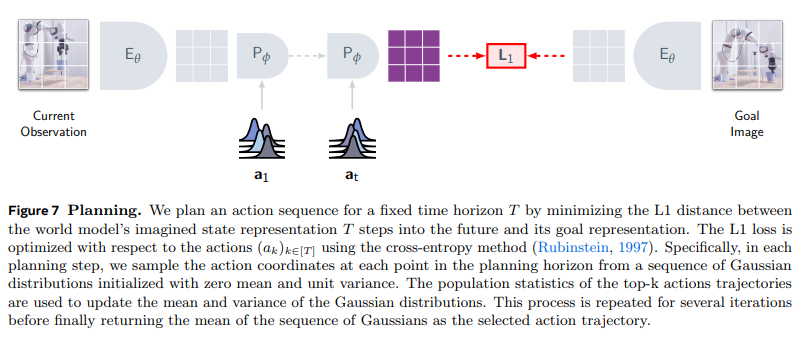
图 7 规划流程
通过最小化世界模型预测的T步后状态表征与目标表征的 L1 距离,为固定时间范围T规划动作序列。针对动作(ak)k∈[T],采用交叉熵方法(鲁宾斯坦,1997)优化 L1 损失:每个规划步骤中,从初始均值为 0、方差为 1 的高斯分布中,采样规划时域内每个时刻的动作坐标;利用表现最优的k个动作轨迹的总体统计信息,更新高斯分布的均值和方差;该过程重复多次迭代后,将高斯序列的均值作为最终选择的动作轨迹。
4 规划:零样本机器人控制
本节将展示如何通过模型预测控制,利用 V-JEPA 2-AC 实现机器人的基础技能,如到达目标位置、抓取和拾取 - 放置操作。研究聚焦于视觉目标指定类任务,验证 V-JEPA 2-AC 在新环境中的零样本泛化能力。
4.1 实验设置
基线模型
研究将 V-JEPA 2-AC 的性能与两个基线模型进行对比:一个是基于行为克隆训练的视觉 - 语言 - 动作模型,另一个是基于视频生成的世界模型。
第一个基线模型基于 Octo 视频 - 语言 - 动作模型,支持目标图像条件控制(Octo 模型团队等,2024)。研究以该模型的开源权重 octo-base-1.5 版本为基础 —— 该版本已在包含超 100 万个轨迹的 Open-X Embodiment 数据集上预训练完成 ¹。利用 Droid 数据集的全部数据,通过行为克隆结合事后重标记(安德里乔维奇等,2017;戈什等,2019),对 Octo 模型进行微调,训练过程中使用图像目标和末端执行器状态:从 Droid 数据集中随机采样轨迹片段,均匀采样未来 20 个时间步内的目标图像;采用官方开源微调代码及 Droid 数据集的标准优化超参数,输入为单视角图像(分辨率 256×256),上下文包含前两帧图像,预测未来 4 个动作。
第二个基线模型基于 Cosmos 视频生成模型(阿加瓦尔等,2025)。研究以无动作依赖的 Cosmos 模型开源权重为基础(采用连续分词器的潜在扩散 70 亿参数模型),该模型已在 2000 万小时视频上预训练完成;利用官方发布的动作条件微调代码,在 Droid 数据集上对其进行微调 ²。为提升模型在 Droid 数据集上的训练效果,研究做了如下调整:(1)降低学习率以匹配视频条件 Cosmos 模型的训练方案;(2)移除视频条件中的 dropout 层,改善训练动态;(3)将噪声水平提升e2倍 —— 实验发现,较低噪声系数训练的模型难以充分利用条件帧中的信息。尽管 Cosmos 的技术报告(阿加瓦尔等,2025)提及未来将世界模型用于规划或模型预测控制,但据研究人员所知,这是首次报道将 Cosmos 模型应用于机器人控制。
机器人部署
所有模型均在配备 RobotiQ 夹持器的 Franka Emika Panda 机械臂上零样本部署,机械臂分别位于两个不同的实验室,且均未出现在 Droid 数据集中。视觉输入由未校准的低分辨率单目 RGB 相机提供,所有机器人使用完全相同的模型权重和推理代码,以及基于操作空间控制的相似底层控制器。
V-JEPA 2-AC 世界模型和 Cosmos 世界模型采用阻塞控制(即系统等待上一个指令动作完成后,再向控制器发送新动作);Octo 模型则同时测试阻塞控制和非阻塞控制,最终报告最优性能。使用 V-JEPA 2-AC 和 Cosmos 进行规划时,每个采样动作被限制在以原点为中心、半径为 0.075 的 L1 球内 —— 这对应于末端执行器每次动作的最大位移约 13 厘米,因为过大的动作相对超出了模型的分布范围。
注:¹ 相比之下,V-JEPA 2-AC 仅在 Droid 数据集的 2.3 万个轨迹上训练,包含成功和失败的轨迹数据;² 代码地址:https://github.com/nvidia-cosmos/cosmos-predict
4.2 实验结果
单目标到达任务
首先评估单目标到达任务 —— 机器人基于单张目标图像,将末端执行器移动到空间中的指定位置。该任务用于测试模型对动作的基础理解能力,以及从单目 RGB 相机输入中获取场景三维空间信息(包括深度)的能力。
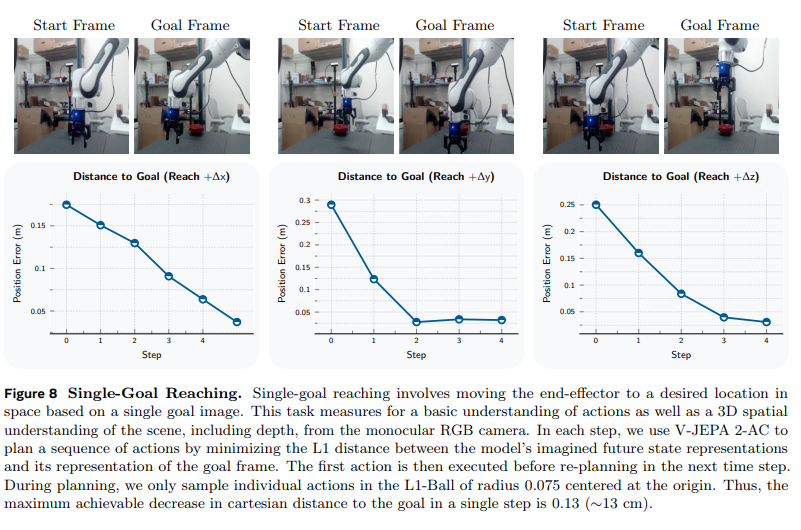
图 8 展示了三个不同单目标到达任务中,机器人执行过程中末端执行器与目标位置的欧氏距离变化。结果显示,所有场景下模型均能将末端执行器移动到距离目标位置不足 4 厘米的范围内,且选择的动作能使误差单调递减。这一过程类似于视觉伺服(希尔,1979)—— 即利用相机的视觉反馈控制机器人运动,但与传统视觉伺服方法不同的是,V-JEPA 2-AC 仅通过无标注的真实世界视频数据训练即可实现该能力。
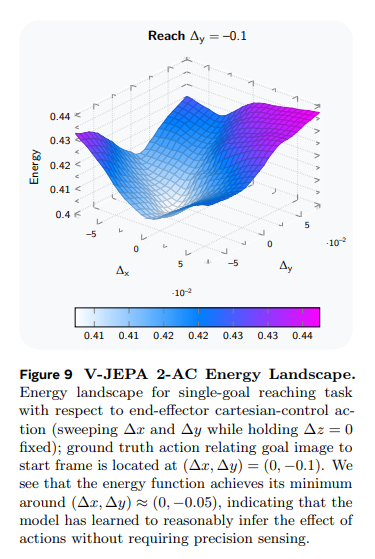
图 9 可视化了Δy到达任务中,V-JEPA 2-AC 的能量 landscape(基于式 (5)):固定Δz=0,遍历Δx和Δy的取值,分析单笛卡尔控制动作对能量的影响。结果显示,能量函数在真实动作附近达到最小值,进一步证明模型无需精确传感即可合理推断动作的效果;同时观察到 V-JEPA 2-AC 诱导的能量 landscape 相对平滑且局部凸,这一特性有助于提升规划效率。
抓取操作任务
接下来,在更具挑战性的抓取类物体操作任务中评估所有模型,包括抓取、带物体到达目标位置和拾取 - 放置。表 2 和表 3 报告了任务成功率,结果为 10 次试验的平均值 —— 每次试验的任务设置(如物体位置、初始姿态等)均有差异。其中,抓取和带物体到达任务仅向模型提供单张目标图像;拾取 - 放置任务则额外提供两张子目标图像:第一张显示物体被抓取的状态,第二张显示物体位于目标位置附近的状态。模型训练流程为:前 4 个时间步针对第一个子目标优化动作,接下来 10 个时间步切换至第二个子目标,最后 4 个时间步针对最终目标优化动作。拾取 - 放置任务的机器人执行示例见图 10,实验室 1 中所有独立任务的初始帧和目标帧见附录 B.2。

抓取任务要求通过视觉反馈实现精确控制,以正确夹持物体;带物体到达任务要求模型在握持物体的同时完成导航,需具备基础的直觉物理知识以避免物体掉落;拾取 - 放置任务则测试模型对这些基础技能的组合应用能力。
所有模型在到达任务中均取得较高成功率,但在涉及物体交互的任务中,性能差异更为显著。实验发现,所有模型的成功率均与被操作物体的类型相关:例如,杯子最容易通过 “一指伸入内部、环绕杯口夹持” 的方式抓取,但如果模型生成的控制动作不够精确,机器人会错过杯口导致抓取失败;盒子的可行抓取构型更多,但模型需要更精确的夹持器控制,确保手指张开幅度足够抓取物体。尽管如此,V-JEPA 2-AC 模型在所有任务中均取得最高成功率,验证了潜在规划在机器人操作任务中的可行性。

表 3 对比了 V-JEPA 2-AC 与基于潜在扩散的 Cosmos 动作条件视频生成模型的规划性能:两者均采用交叉熵方法(鲁宾斯坦,1997)在单块 NVIDIA RTX 4090 GPU 上优化动作序列,能量函数通过在模型的潜在空间中编码目标帧构建(如式 (5) 所示)。Cosmos 模型在每个规划步骤中,采用 80 个样本、10 次优化迭代、规划时域为 1,单次动作计算需 4 分钟;尽管其在到达任务中取得 80% 的高成功率,但在物体交互任务中的表现较弱 —— 按此计算,完成一次完整的拾取 - 放置轨迹需超过 1 小时的机器人执行时间。相比之下,V-JEPA 2-AC 世界模型在每个优化步骤中使用 10 倍于 Cosmos 的样本量,单次动作计算仅需 16 秒,且在所有测试的机器人技能中均表现更优。未来可通过以下方式进一步缩短两种模型的规划时间:利用更多计算资源支持规划过程、减少每个时间步的样本量和优化迭代次数、在世界模型的模拟空间中训练前馈策略以初始化规划问题,或针对 V-JEPA 2-AC 探索基于梯度的规划方法。
4.3 局限性
对相机位置的敏感性
V-JEPA 2-AC 模型通过末端执行器的笛卡尔控制动作预测下一视频帧的表征,未进行任何显式的相机校准,因此需从单目 RGB 相机输入中隐式推断动作坐标轴。但在许多场景中,机器人基座可能未出现在相机帧中,导致动作坐标轴的推断问题缺乏明确解,进而影响世界模型的性能。实际实验中,研究人员通过手动测试不同相机位置,最终选择了在所有实验中表现稳定的位置;附录 B.4 提供了 V-JEPA 2-AC 世界模型对相机位置敏感性的定量分析。
长时域规划
世界模型的长时域规划受多种因素限制:首先,自回归预测存在误差累积问题 —— 随着自回归滚动预测步数增加,表征空间预测的准确性会下降,导致长时域规划的可靠性降低;其次,长时域规划会扩大搜索空间 —— 规划时域的线性增加会导致可能的动作轨迹数量呈指数增长,带来巨大的计算挑战。但长时域规划对于解决非贪心预测任务(如无需图像子目标的拾取 - 放置)至关重要,未来针对世界模型长时域规划的研究,将有望实现更多复杂的任务。
图像目标依赖
与此前许多目标条件机器人操作研究一致(芬恩、莱文,2017;林奇等,2020;切博塔尔等,2021;江等,2022;刘等,2022;古普塔等,2022),本研究的优化目标设定依赖视觉目标。但在真实场景中部署机器人时,通过语言形式指定目标可能更为自然。未来的研究方向包括:将潜在动作条件世界模型与语言模型对齐,通过自然语言实现更通用的任务指定 —— 第 7 节中 V-JEPA 2 与语言模型对齐的研究结果,可为该方向提供基础。
5 场景理解:基于探针的分类任务
如前所述,V-JEPA 2-AC 等表征空间世界模型的能力,本质上受限于其学习到的表征空间所编码的状态信息。本节及后续章节将通过探针探究 V-JEPA 2 习得的表征,并在视觉分类任务中,将 V-JEPA 2 编码器与其他视觉编码器进行性能对比。
视觉分类任务可分为外观理解类和运动理解类:外观理解任务通常仅需输入视频片段中的单帧图像即可完成(即使分类标签描述的是动作),而运动理解任务则需要多帧图像才能实现准确分类(戈亚尔等人,2017)。为平衡评估模型的运动理解和外观理解能力,研究选取了三项运动理解任务 ——Something-Something v2(SSv2)、Diving-48 和 Jester,这些任务要求模型理解人类的手势和动作;同时选取了三项外观理解任务 ——Kinetics400(K400)、COIN 和 ImageNet(IN1K),这些任务涉及动作、场景和物体的识别。实验结果表明,V-JEPA 2 在运动理解任务上的性能超越当前最先进的视觉编码器,在外观理解任务上也具备竞争力。
注意力探针
在每个任务的训练数据上,基于冻结的编码器输出,训练一个 4 层注意力探针。该注意力探针由四个 Transformer 块组成,最后一个 Transformer 块用带可学习查询标记的交叉注意力层,替代标准自注意力层。按照常规流程,推理阶段从单个视频中采样固定帧数的多个片段,然后对所有片段的分类对数概率进行平均。探针的分辨率设置与 V-JEPA 2 预训练阶段保持一致。附录 C.2 详细分析了注意力探针的层数对性能的影响,并提供了下游任务中使用的片段数量、片段大小和其他超参数的完整细节。
评估方案
研究将 V-JEPA 2 在运动和外观任务上的性能,与多个其他视觉编码器进行对比:DINOv2(达塞等人,2024)是当前自监督图像学习的最先进模型;SigLIP2(岑嫩等人,2025)和感知编码器PEcoreG(博利亚等人,2025)是图像 - 文本对比预训练的最先进模型;同时还纳入了两个视频编码器 —— 自监督的 V-JEPA(巴尔德斯等人,2024),以及主要依赖视觉 - 文本对比预训练的 InternVideo2s2-1B(王等人,2024b)。
所有基线模型和 V-JEPA 2 均采用相同的评估方案:在冻结的编码器基础上训练注意力探针,流程与巴尔德斯等人(2024)一致。针对基于图像的模型,研究按照奥夸布等人(2023)的方法对其进行视频适配 —— 拼接每个输入帧的特征;针对 InternVideo2s2-1B,在 ImageNet 任务中使用其图像位置嵌入,在视频任务中将其位置嵌入从 4 帧插值到 8 帧,使标记数量与 V-JEPA 2 保持一致。
尽管采用了统一的评估方案,但基线编码器的训练数据存在差异(例如,DINOv2 基于 LVD-142M 数据集训练,PEcoreG基于 MetaCLIP 数据集训练),因此无法直接进行一对一对比。研究仅在系统层面比较不同方法 —— 即尽管训练方案和数据存在差异,但评估方案保持一致。此外,研究还纳入了文献中采用类似冻结方案(但注意力头架构可能不同)的已有结果,特别是 VideoMAEv2(王等人,2023)、InternVideo-1B 和 6B(王等人,2024b)以及 VideoPrism(张等人,2024c)在本研究涉及的分类任务上的已报道结果(若有)。完整的评估流程和超参数见附录 C.1。
实验结果
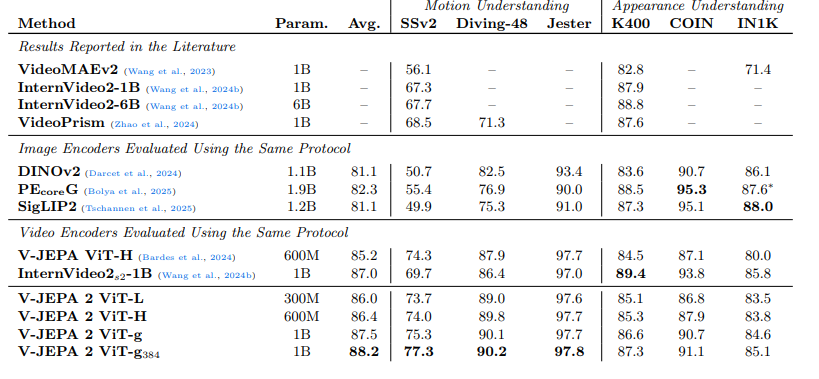
表 4 报告了 V-JEPA 2、其他评估编码器以及文献中其他重要结果的分类性能。V-JEPA 2 ViT-g(256 分辨率)在运动理解任务上的性能显著优于其他视觉编码器:在 SSv2 任务上的 Top-1 准确率达到 75.3,而 InternVideo 为 69.7,PECoreG为 55.4。同时,V-JEPA 2 在外观任务上也具备竞争力,在 ImageNet 任务上的准确率达到 84.6,相较 V-JEPA 提升了 4.6 个百分点。
总体而言,与其他视频和图像编码器相比,V-JEPA 2 在所有六项任务中的平均性能最佳。更高分辨率、更长时长的 V-JEPA 2 ViT-g384 在所有任务中均实现了进一步提升,平均性能达到 88.2。
6 预测任务:基于探针的行为预测
行为预测任务要求根据动作发生前的上下文视频片段,预测未来的动作。研究基于 Epic-Kitchens-100(EK100)基准数据集(达门等人,2022)验证了 V-JEPA 2 的行为预测性能随模型规模的增长而稳步提升。此外,尽管仅在 V-JEPA 2 的表征之上训练了一个注意力探针,该模型仍显著优于此前专门针对该任务设计的最先进方法。
任务说明
EK100 数据集包含 100 小时的烹饪活动视频,采用第一视角拍摄,覆盖 45 个厨房环境。数据集中的每个视频都标注了动作片段,包括开始时间戳、结束时间戳和动作标签 —— 共有 3568 个独特的动作标签,每个标签包含一个动词类别和一个名词类别,总计 97 个动词类别和 300 个名词类别。
EK100 行为预测任务要求根据动作片段开始前的上下文视频片段,预测对应的名词、动词和动作(即同时预测动词和名词)。上下文结束与动作开始之间的时间间隔为预测时长,默认设置为 1 秒。由于给定上下文可能对应多种未来动作,任务采用平均类别 5 阶召回率作为性能评估指标(达门等人,2022)。
预测探针
在冻结的 V-JEPA 2 编码器和预测器之上,训练一个注意力探针以实现未来行为预测。具体流程为:采样动作开始前 1 秒结束的视频片段作为上下文,将其输入 V-JEPA 2 编码器;预测器接收编码器的表征以及对应未来 1 秒帧的掩码标记,预测未来视频帧的表征;将预测器和编码器的输出沿标记维度拼接,输入至与第 5 节结构相似的注意力探针 —— 不同之处在于,该预测探针的最终交叉注意力层学习三个查询标记(而非一个),每个查询标记的输出分别输入至不同的线性分类器,以预测动作类别、动词类别和名词类别。
对每个分类器独立应用焦点损失(林等人,2017),求和后通过探针的共享注意力块反向传播梯度。附录 D.1 提供了详细的实现细节和评估超参数。
基线模型
研究将所提模型与三个专门针对行为预测训练的基线模型进行对比:
- InAViT(罗伊等人,2024):一种监督学习方法,利用显式的手 - 物交互建模;
- Video-LLaMA(张等人,2023)和 PlausiVL(米塔尔等人,2024):均基于大语言模型构建,参数规模最高达 70 亿。
实验结果
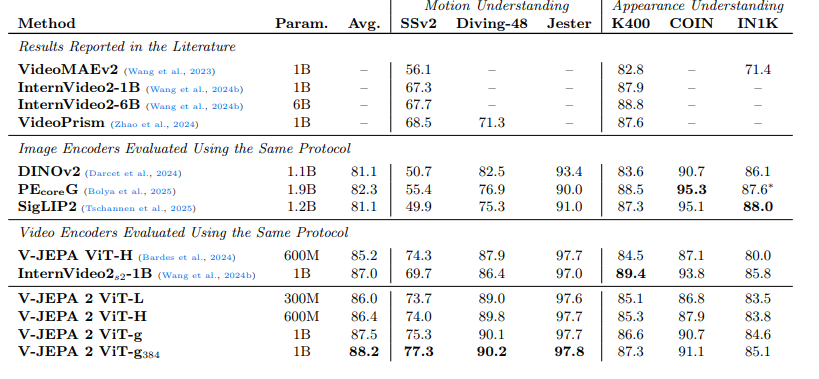
表 5 总结了 EK100 行为预测基准的实验结果。研究对比了参数规模从 3 亿到 10 亿的 V-JEPA 2 ViT-L、ViT-H 和 ViT-g 编码器,三者均采用 32 帧、8 帧 / 秒、256×256 分辨率的视频作为上下文;同时报告了采用 384×384 分辨率的 ViT-g384 的性能。结果显示,V-JEPA 2 的行为预测 5 阶召回率随模型规模呈线性增长:3 亿参数的 V-JEPA 2 ViT-L 的 5 阶召回率为 32.7,将模型参数扩展至 10 亿后,5 阶召回率提升 5.3 个百分点,达到 38.0;此外,更高分辨率的输入也能为 V-JEPA 2 带来性能提升 ——384×384 分辨率的 V-JEPA 2 ViT-g384 相较 256×256 分辨率的模型,5 阶召回率进一步提升 1.7 个百分点。
V-JEPA 2 的性能显著优于此前的最先进模型 PlausiVL:即使 3 亿参数的 V-JEPA 2 与 80 亿参数的 PlausiVL 相比,仍具备竞争力;特别是 V-JEPA 2 ViT-g384,其动作 5 阶召回率较 PlausiVL 提升 12.1 个百分点,相对提升幅度达 44%。

图 11 可视化了 V-JEPA 2 在 EK100 验证集三个样本上的预测结果,包括两个成功案例和一个失败案例。在两个成功案例中,V-JEPA 2 不仅能以最高置信度准确预测正确动作,还能基于给定上下文提出合理的 Top 2 至 Top 5 动作。例如,第一行的正确动作为 “清洗水槽”,但考虑到场景中存在水龙头和墙壁,“打开水龙头” 或 “清洁墙壁” 也是合理动作;模型还预测了 “冲洗海绵” 这一当前正在进行的动作,可能认为该动作在 1 秒后仍会继续。在失败案例中,V-JEPA 2 仍提出了 “关上门”“放下香料包” 等合理动作,但未能准确识别物体类型(实际为 “茶叶包”)。
局限性
V-JEPA 2 和 EK100 基准均存在一定局限性:首先,V-JEPA 2 未能完全解决 EK100 任务,仍存在动词、名词或两者均预测错误的失败案例,附录 D.2 分析了这些失败案例的分布;其次,本研究聚焦于 1 秒预测时长的动作预测,当预测时长延长时,V-JEPA 2 的准确率会下降(见附录 D.2);再次,EK100 基准仅限于厨房环境,且动作类别为固定集合,无法验证 V-JEPA 2 在其他环境中的泛化能力,也限制了模型对未见过的动作类别的泛化;最后,EK100 中的动作选自固定类别集合,导致模型无法泛化到训练集中未包含的动作类别。
7 场景理解:视频问答
本节将探究 V-JEPA 2 执行开放式语言视频问答(VidQA)的能力。为赋予模型语言处理能力,研究采用 LLaVA 系列模型(李等人,2024b)推广的非标记化早期融合架构(瓦德卡尔等人,2024),以 V-JEPA 2 作为视觉编码器,训练多模态大语言模型(MLLM)。这类多模态大语言模型通过投影层将视觉编码器的输出图像块嵌入映射至大语言模型的输入嵌入空间,实现视觉编码器与大语言模型的对齐;训练方式可选择端到端训练,或固定视觉编码器权重。
目前,视频问答任务中多模态大语言模型采用的编码器多为图像编码器,处理视频输入时对每帧图像独立编码(通义千问团队等,2025;张等人,2024b),典型代表包括 CLIP(拉德福德等人,2021)、SigLIP(岑嫩等人,2025)和感知编码器(博利亚等人,2025)—— 这类编码器之所以被广泛采用,主要因其通过图像 - 文本对预训练,已实现与语言的语义对齐。据研究人员所知,本研究首次采用未经过任何语言监督预训练的视频编码器,训练用于视频问答的多模态大语言模型。
多模态大语言模型在下游任务中的性能还高度依赖对齐数据。本实验使用包含 8850 万图像 - 文本对和视频 - 文本对的数据集,与训练 PerceptionLM(赵等人,2025)所用数据集类似。为验证 V-JEPA 2 编码器的有效性,研究首先在第 7.2 节的受控数据设置中(使用 1800 万样本子集),将 V-JEPA 2 与其他最先进的视觉编码器进行对比;随后在相同受控设置下,于第 7.3 节验证扩大视觉编码器规模和输入分辨率对视频问答性能的持续提升作用;最后在第 7.4 节扩大对齐数据规模(使用全部 8850 万样本),测试 V-JEPA 2 的语言对齐上限。实验结果表明,在受控数据设置下,V-JEPA 2 在开放式视频问答任务上的性能与其他视觉编码器相当;扩大对齐数据规模后,V-JEPA 2 在多个视频问答基准测试中达到最先进性能。
7.1 实验设置
视频问答任务
研究选取的评估数据集包括:PerceptionTest(帕特劳钱等人,2023)—— 用于评估模型在记忆、抽象、物理和语义等多维度的技能;MVP 数据集(克罗耶尔等人,2024)—— 采用最小视频对评估框架,减少文本和外观偏差,用于测试物理世界理解能力;TempCompass、TemporalBench 和 TOMATO(刘等人,2024c;蔡等人,2024;上官等人,2024)—— 用于探究模型的时间理解和记忆能力;MVBench(李等人,2024c)—— 存在单帧外观特征偏向(克罗耶尔等人,2024;科雷斯等人,2024),用于评估通用理解能力;TVBench(科雷斯等人,2024)—— 作为通用和时间理解的替代评估基准,可减轻上述偏差。
视觉指令微调
为评估 V-JEPA 2 表征在视觉问答任务中的性能,研究采用 LLaVA 框架的视觉指令微调流程(刘等人,2024a),通过可学习的投影模块(通常为多层感知机)将视觉编码器输出(或视觉标记)转换为大语言模型的输入。遵循刘等人(2024b)的三阶段渐进式训练流程训练多模态大语言模型:
- 第一阶段:仅在图像描述数据上训练投影模块;
- 第二阶段:在大规模图像问答数据上训练整个模型;
- 第三阶段:在大规模视频描述和问答数据上进一步训练模型。
通过该分阶段训练,大语言模型对视觉标记的理解能力逐步提升。视觉编码器可选择固定权重或与多模态大语言模型的其他部分一起微调:固定视觉编码器权重能更清晰地反映视觉特征的质量,而微调视觉编码器能获得更优的整体性能。视觉指令训练的详细流程见附录 E。
7.2 与图像编码器的对比
为隔离视觉编码器对多模态大语言模型性能的影响并与 V-JEPA 2 进行对比,研究设计了受控设置:使用相同的大语言模型骨干网络、数据和训练设置,分别训练基于不同最先进编码器的多模态大语言模型。
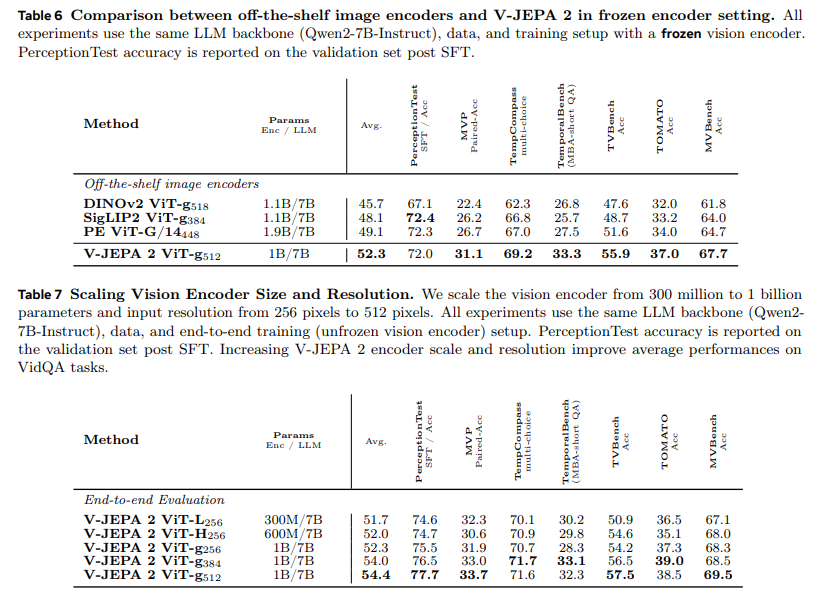
表 6 报告了固定编码器设置下,现成图像编码器与 V-JEPA 2 的性能对比 —— 所有实验均采用 Qwen2-7B-Instruct(杨等人,2024a)作为大语言模型骨干网络,视觉编码器权重固定。结果显示,V-JEPA 2 在固定设置下表现出竞争力,除 PerceptionTest 任务略逊于 SigLIP 和感知编码器(PE)外,在所有测试基准中均优于 DINOv2、SigLIP 和感知编码器;尤其在 MVP、TemporalBench 和 TVBench 等侧重时间理解的基准测试中,性能提升更为显著。
由于实验仅更换了视觉编码器,该结果证明:未经过语言监督训练的视频编码器,能够优于经过语言监督训练的编码器 —— 这与传统认知相悖(童等人,2024;李等人,2024b;刘等人,2024d;袁等人,2025)。同时表明,在视频问答任务中使用视频编码器替代图像编码器,能提升模型的时空理解能力,凸显了开发更优视频编码器的必要性。
7.3 视觉编码器规模和分辨率的规模化
已有研究(范等人,2025)表明,扩大视觉编码器规模和输入分辨率,能显著提升自监督图像编码器的视觉问答性能。因此,研究将 V-JEPA 2 的参数规模从 3 亿扩展至 10 亿,输入分辨率从 256 像素提升至 512 像素,实验结果见表 7—— 所有实验均采用 Qwen2-7B-Instruct 作为大语言模型骨干网络,使用相同数据和端到端训练(视觉编码器权重不固定)设置,PerceptionTest 的准确率为微调后的验证集结果。
结果显示,扩大 V-JEPA 2 编码器规模和分辨率,能持续提升视频问答任务的平均性能:固定输入分辨率为 256 像素,将视觉编码器参数从 3 亿扩展至 10 亿时,PerceptionTest 准确率提升 0.9 个百分点,TVBench 准确率提升 3.3 个百分点,MVBench 准确率提升 1.2 个百分点;将输入分辨率提升至 512 像素后,所有下游任务的性能均进一步提升,例如 PerceptionTest 准确率提升 2.2 个百分点,TemporalBench 准确率提升 4.0 个百分点,TVBench 准确率提升 3.3 个百分点。这一结果表明,进一步扩大视觉编码器规模和输入分辨率,是提升视频问答性能的有效方向。
7.4 扩大数据规模实现性能突破
在受控设置下明确 V-JEPA 2 训练多模态大语言模型的能力后,研究通过扩大对齐数据集规模,探索视频问答性能的突破潜力 —— 正如赵等人(2025)所观察到的,下游任务性能的跨越式提升往往源于训练数据规模的扩大。为此,研究将多模态大语言模型的训练数据从 1800 万扩展至完整的 8850 万(扩大 4.7 倍)。
尽管提升模型分辨率有助于下游性能,但会带来大语言模型输入中视觉标记数量过多的问题。因此,研究选择 V-JEPA 2 ViT-g384,每帧生成 288 个视觉标记;遵循赵等人(2025)的训练方案,以 Llama 3.1 为骨干网络训练 V-JEPA 2 ViT-g384;为简化训练流程,采用无池化的多层感知机投影模块。规模化训练设置的详细细节见附录 E。
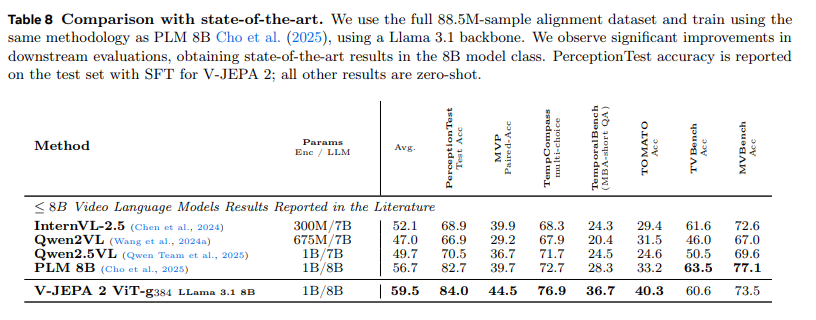
扩大数据规模后,所有下游基准测试的性能均全面提升,在多个基准测试中达到最先进结果(表 8)—— 包括 PerceptionTest、MVP、TempCompass、TemporalBench 和 TOMATO。与当前最先进的 PerceptionLM 8B(赵等人,2025)相比,V-JEPA 2 在 PerceptionTest 测试集上的准确率提升 1.3 个百分点,MVP 的配对准确率提升 4.8 个百分点,TempCompass 的准确率提升 4.2 个百分点,TemporalBench 短问答的多二值准确率提升 8.4 个百分点,TOMATO 的准确率提升 7.1 个百分点。
尽管 V-JEPA 2 在 TVBench 和 MVBench 上的性能未超越 PerceptionLM,但仍显著优于其他相关基线模型(InternVL 2.5、Qwen2VL 和 Qwen2.5VL)。这些结果凸显了扩大视觉 - 语言对齐训练数据的重要性,并证明:即使是未经过语言监督预训练的编码器(如 V-JEPA 2),在足够的数据规模下也能实现最先进的性能。
8 相关工作
世界模型与规划
早在萨顿和巴托(1981)、沙蒂拉和劳蒙(1985)的研究中,人工智能研究者就致力于构建能够利用世界内部模型 —— 既建模世界动态,又映射静态环境 —— 实现高效规划与控制的智能体。此前的研究已在模拟任务(弗拉基亚达基等,2015;哈、施密德胡伯,2018;哈夫纳等,2019b、a;汉森等,2022、2023;施里特维泽等,2020;萨米等,2024)以及真实世界的移动和操作任务(李等,2020;纳加班迪等,2020;芬恩等,2016;埃伯特等,2017、2018;严晨等,2020)中探索了世界模型。
世界模型方法主要分为三类:直接在像素空间学习预测模型(芬恩等,2016;埃伯特等,2017、2018;严晨等,2020)、在习得的表征空间学习预测模型(瓦特等,2015;阿格拉沃尔等,2016;哈、施密德胡伯,2018;哈夫纳等,2019b;奈尔等,2022;吴等,2023b;托马尔等,2024;胡等,2024;兰开斯特等,2024),或利用更结构化的表征空间(如关键点表征)(马努埃利等,2020;达斯等,2020)。此前在真实世界机器人任务中表现出性能的方法,均训练了任务专用的世界模型,且依赖智能体部署环境的交互数据;评估重点在于验证世界模型方法在特定任务空间内的性能,而非对新环境或未见过物体的泛化能力。本研究训练了与任务无关的世界模型,并验证了其在新环境和新物体上的泛化能力。
近期部分研究结合互联网规模的视频数据和交互数据,训练用于自主机器人的通用(与任务无关)动作条件视频生成模型(布鲁斯等,2024;阿加瓦尔等,2025;拉塞尔等,2025)。然而,这些方法目前仅能根据机器人动作生成视觉上合理的规划,尚未实现利用这些模型实际控制机器人。
另有研究探索将生成式建模融入策略学习(杜等,2024;吴等,2023a;赵等,2025;朱等,2025;杜等,2023;郑等,2025;拉贾塞加兰等,2025)。与这类研究不同,本研究的目标是通过模型预测控制利用世界模型,而非通过策略学习避免需要专家轨迹的模仿学习阶段。这两种方法互为补充,未来可结合使用。与本研究最接近的是周等(2024)、索巴尔等(2025)的研究,其表明可通过分阶段或端到端方式学习世界模型,并利用该模型零样本解决规划任务。但这些研究聚焦于小规模规划评估,而本研究证明类似原理可规模化应用于解决真实世界的机器人任务。
机器人控制的视觉 - 语言 - 动作模型
近期真实世界机器人控制领域的模仿学习方法取得了显著进展,通过利用互联网规模视频和文本数据预训练的视频 - 语言模型,再通过专家演示的行为克隆微调(或适配)模型以预测动作(德里耶斯等,2023;布罗汉等,2023;布莱克等,2024;金等,2024;比约尔克等,2025;布莱克等,2025),模型的泛化能力不断提升。尽管这些方法展现出良好的泛化潜力,但由于缺乏明确的世界预测模型,且未利用推理时的计算资源进行规划,其能否学习预测训练数据中未演示的行为仍不明确;同时,这类方法需要大规模高质量的遥操作数据,且仅能利用成功的轨迹。相比之下,本研究聚焦于利用任何交互数据 —— 无论其是与环境成功交互还是失败交互的结果。
视觉基础模型
计算机视觉领域的视频基础模型已证明,通过自监督学习方法,可利用由图像和 / 或视频组成的大规模观测数据集,训练出在多种下游任务中表现优异的通用视觉编码器 —— 这类方法包括基于图像的自监督学习(格里尔等,2020;阿斯拉恩等,2023;奥夸布等,2023;范等,2025)、基于视频的自监督学习(巴尔德斯等,2024;卡雷拉等,2024;王等,2023;拉贾塞加兰等,2025)、弱语言监督学习(王等,2024b;博利亚等,2025),或上述方法的组合(岑嫩等,2025;菲尼等,2024)。
然而,此前的研究往往聚焦于通过基于探针的评估,或与大语言模型对齐后的视觉问答任务,验证模型的理解能力。尽管这类任务推动了相关领域的发展,但视觉系统的重要目标之一仍是使智能体能够与物理世界交互(吉布森,1979)。除视觉理解任务的结果外,本研究还探究了基于视频的大规模自监督学习,如何实现零样本解决新环境中的规划任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)