通过LLamaFactory+Qwen3-VL-8B微调多模态医疗大模型
项目背景
针对医疗影像解读链路长、报告非结构化程度高的问题,基于Qwen3-VL-8B开发垂直领域多模态大模型。实现涵盖影像简述、结构化诊断记录及病灶区域定位等多任务辅助诊疗系统。
数据
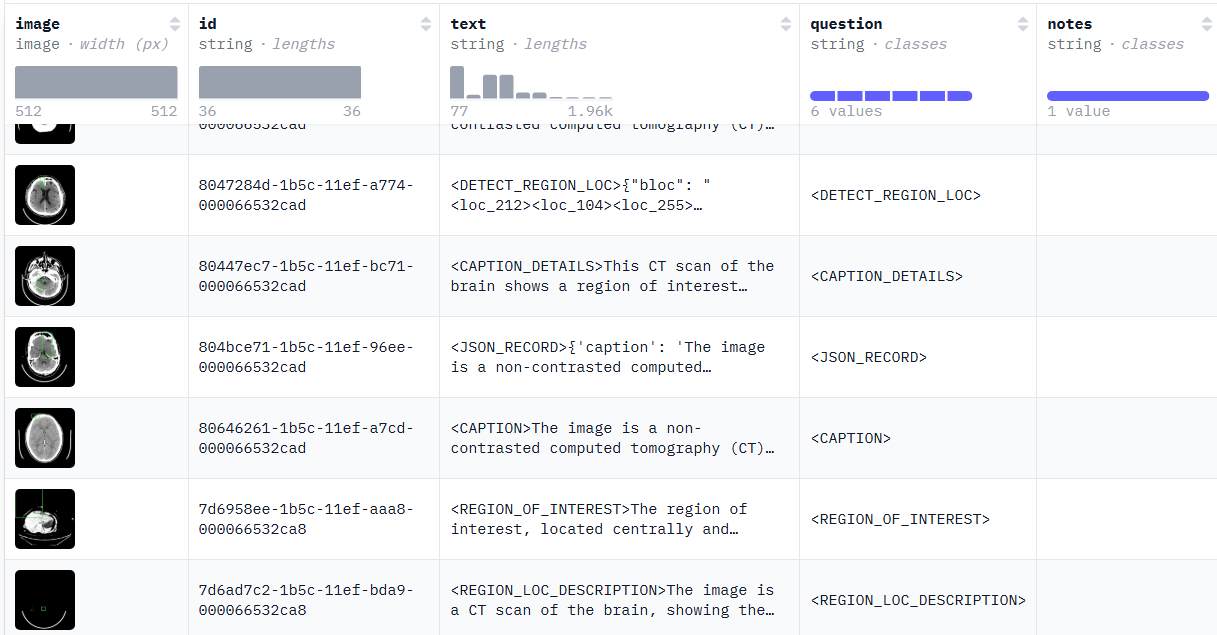
本项目采用huggingface开源医学影像数据集mychen76/medtrinity_brain_30k_hf。该数据集含有30K脑部CT影像,涵盖 6 种 question类型,包括影像简述、结构化诊断记录及病灶区域定位等。
数据集内容如下:
下载数据请运行以下代码
from datasets import load_dataset
ds = load_dataset("mychen76/medtrinity_brain_30k_hf")平台与配置
本项目于autodl云服务器平台完成,配置如下:
---------------------------------------------------------------------------------------------------------------------------------
镜像:Miniconda conda3 Python 3.10(ubuntu22.04) CUDA 11.8
GPU: RTX 4090D(24GB) * 1
CPU: 15 vCPU Intel(R) Xeon(R) Platinum 8474C
内存: 80GB
系统盘:30 GB
数据盘:免费:50GB SSD 付费:0GB
项目代码
1、环境配置
导入环境配置请点击下方链接下载multimodal_llama_environment.yml文件
from datasets import load_dataset
import pandas as pd
from PIL import Image
import matplotlib.pyplot as plt
import os
import ast
import re
import json
from tqdm import tqdm
from modelscope.hub.api import HubApi
from modelscope.hub.file_download import model_file_download
from modelscope.utils.constant import ModelFile
2、数据预览
预览图片属性
img = Image.open('autodl-tmp/json_data/80656265-1b5c-11ef-8b5a-000066532cad.jpg') # 替换为你的图片路径
print(f"尺寸 (宽 x 高): {img.size}")
print(f"色彩模式: {img.mode}")加载数据集,预览训练集、验证集、测试集第一个样本
data_path = "autodl-tmp/medtrinity30K/data"
ds = load_dataset(
"parquet",
data_files={
"train": f"{data_path}/train-*.parquet",
"validation": f"{data_path}/validation-*.parquet",
"test": f"{data_path}/test-*.parquet"
}
)
print(ds['train'][:1])
print(ds['validation'][:1])
print(ds['test'][:1])可视化image内容
from PIL import Image
import matplotlib.pyplot as plt
image = ds['train'][0]['image'] # 获取第一张图像
image1 = ds['validation'][0]['image']
image2 = ds['test'][0]['image']
plt.imshow(image)
plt.axis('off') # 不显示坐标轴
plt.show()
plt.imshow(image1)
plt.axis('off') # 不显示坐标轴
plt.show()
plt.imshow(image2)
plt.axis('off') # 不显示坐标轴
plt.show()3、数据预处理
由于后续我们要通过LLama Factory进行多模态大模型微调,所以我们需要对上述的数据集进行预处理以符合LLama Factory的要求
task_prompts: 将模型内部的标签转换为具体的指令,为不同的任务指令分配人类可读的中文提示词。在训练模型时,模型能学会根据不同的指令输出对应的医学分析
process_text: 由于每种question对应的回答格式固定,因此定义该函数提取其中的有效信息
letterbox_image函数:保持解剖比例的缩放策略。在医疗影像处理中,直接将图像强制 Resize 到固定尺寸(如448* 448)会导致病灶区域发生拉伸或挤压变形,这会严重干扰模型对病变形状(如结节的长径比)的判断。等比例缩放:该函数计算原始图像与目标尺寸的最小缩放比例,确保解剖结构不失真。黑色填充 (Padding):缩放后的图像居中放置,余白部分使用黑色 (0, 0, 0) 填充。这种处理方式能让模型在统一的输入分辨率下,依然能够感知到原始影像的真实长宽比。
CLAHE 局部对比度增强:挖掘医疗影像细节。在 process_batch_parallel 中,代码引入了 CLAHE (Contrast Limited Adaptive Histogram Equalization) 算法。
解决对比度低的问题:医疗 CT 或 X 光片的动态范围通常很大,但感兴趣区域(ROI)的对比度往往很低。
抑制噪声:与普通的直方图均衡化不同,CLAHE 通过限制对比度增益,有效避免了背景噪声被过度放大。
灰度级保留:通过 raw_image.convert("L") 先转为灰度处理再转回 RGB,完整保留了医疗影像的密度特征。
process_batch_parallel:高性能并行处理架构
为了处理海量的医疗数据集,该函数利用了 datasets.map 的多进程(num_proc=15)特性:
原子化操作:集成了图像读取、CLAHE 增强、Letterbox 转换、文本清洗及 ShareGPT 格式构建于一体。
内存优化:通过 remove_columns 参数,在处理完成后立即释放原始的高分辨率图像数据,防止内存溢出(OOM)。
task_prompts = {
"<CAPTION_DETAILS>": "请详细描述这张医学影像中的解剖结构、异常密度及病理特征。",
"<REGION_OF_INTEREST>": "请分析图像中的重点关注区域(ROI),并说明其密度特征和面积占比。",
"<JSON_RECORD>": "请根据该影像提供一份结构化的诊断记录,包含描述、观察、定位信息及建议等。",
"<DETECT_REGION_LOC>": "请在图像中定位病变区域,并给出具体的空间坐标标签。",
"<REGION_LOC_DESCRIPTION>": "请结合空间定位信息,详细描述该影像中的异常发现及其邻近结构关系。",
"<CAPTION>": "请简要描述这张医学影像的主要内容。",
"<OBSERVATION>": "基于此影像观察,请分析病变区域对周围组织可能产生的临床影响。"
}
def process_text(item):
text = item["text"]
prompt = item["question"]
prompt = str(prompt)
if prompt == '<DETECT_REGION_LOC>':
loc_data = text.split('<DETECT_REGION_LOC>')[1].strip()
return loc_data
elif prompt =='<REGION_LOC_DESCRIPTION>':
desc = text.split('<REGION_LOC_DESCRIPTION>')[1].strip()
return desc
elif prompt =='<JSON_RECORD>':
content = text.split('<JSON_RECORD>')[1].strip()
try:
record = ast.literal_eval(content)
res = f"caption:{record.get('caption')}。region of interest:{record.get('region of interest')}。observation:{record.get('observation')}。notes:{record.get('notes')}。bloc:{record.get('bloc')}"
return res
except:
print(f"错误的item的id:{item['id']}")
return 0
elif prompt =='<CAPTION>':
cap = text.split('<CAPTION>')[1].strip()
return cap
elif prompt =='<REGION_OF_INTEREST>':
#使用正则表达式从一段混合了多个标签的长文本中,精准地拆分出每一个“标签”及其对应的“内容”
segments = re.findall(r'<([A-Z_]+)>(.*?)(?=<|$)', text, re.DOTALL)
data_map = {tag: content.strip() for tag, content in segments}
roi = data_map.get('REGION_OF_INTEREST', '')
obs = data_map.get('OBSERVATION', '')
if roi and obs:
# 使用明确的引导词进行拼接,让模型学到逻辑因果
full_answer = f"【区域特征】:{roi}\n【临床观察】:{obs}"
elif roi:
full_answer = roi
else:
full_answer = obs
return full_answer
elif prompt =='<CAPTION_DETAILS>':
cab_det = text.split('<CAPTION_DETAILS>')[1].strip()
return cab_det
else:
print("no task type error")
return 0
def letterbox_image(image, size=(448, 448)):
"""
对图像进行等比例缩放,并进行黑色填充 (Letterbox)
image: PIL.Image 对象
size: 目标尺寸 (width, height)
"""
iw, ih = image.size
w, h = size
scale = min(w/iw, h/ih)
nw = int(iw * scale)
nh = int(ih * scale)
# 等比例缩放
image = image.resize((nw, nh), Image.BICUBIC)
# 创建黑色底板并居中粘贴
new_image = Image.new('RGB', size, (0, 0, 0))
new_image.paste(image, ((w - nw) // 2, (h - nh) // 2))
return new_image
def process_batch_parallel(examples, task_prompts, output_root):
"""
该函数会被 datasets.map 调用,在 15 个子进程中并行运行
"""
processed_messages = []
processed_images = []
# 确保图像存储目录存在
img_dir = os.path.join(output_root, "images")
if not os.path.exists(img_dir):
os.makedirs(img_dir, exist_ok=True)
# 遍历当前 Batch
for i in range(len(examples["id"])):
item_id = examples["id"][i]
image = examples["image"][i]
question_tag = str(examples["question"][i])
# CLAHE 局部对比度增强
# 转换成灰度图进行增强(医疗CT多为单通道特征)
img_array = np.array(image.convert("L"))
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
enhanced_array = clahe.apply(img_array)
# 转回 PIL 格式
enhanced_img = Image.fromarray(enhanced_array).convert("RGB")
# Letterbox 等比例缩放
# 避免直接 Resize 导致的解剖结构形变
final_img = letterbox_image(enhanced_img, size=(448, 448))
# 高效保存图片 (并行 IO)
img_path = os.path.join(img_dir, f"{item_id}.jpg")
if not os.path.exists(img_path):
image.save(img_path, format="JPEG", quality=95)
# 调用文本清洗
item_dict = {"text": examples["text"][i], "question": question_tag, "id": item_id}
final_answer = process_text(item_dict)
# 构建 ShareGPT 格式消息
msg = [
{"role": "user", "content": f"<image>\n{task_prompts.get(question_tag, '')}"},
{"role": "assistant", "content": final_answer}
]
processed_messages.append(msg)
processed_images.append([img_path])
return {"messages": processed_messages, "images": processed_images}
def run_pipeline(ds_dict, task_prompts):
# 配置不同分片的输出路径
configs = {
"train": "/root/autodl-tmp/json_data",
"validation": "/root/autodl-tmp/eval_json_data",
"test": "/root/autodl-tmp/test_json_data"
}
for split, path in configs.items():
if split not in ds_dict: continue
print(f"正在利用 15 vCPU 并行处理 {split} 分片...")
# 使用 .map 替代传统的 save_images_and_json 函数
processed_ds = ds_dict[split].map(
process_batch_parallel,
batched=True,
batch_size=64, # 每一批处理的数量
num_proc=15, # 对应服务器的 15 vCPU,开启 15 个并行进程
fn_kwargs={ # 传递给 process_batch_parallel 的额外参数
"task_prompts": task_prompts,
"output_root": path
},
remove_columns=ds_dict[split].column_names, # 处理完后删除原始列,释放内存
desc=f"Parallel Processing {split}"
)
# 保存为符合 LLaMA Factory 要求的 JSON 映射文件
json_out = os.path.join(path, f"mllm_{split}_data.json")
processed_ds.to_json(json_out, force_ascii=False)
print(f"{split} 分片已保存至: {json_out}")
if __name__ == "__main__":
run_pipeline(ds, task_prompts)4、模型下载
本项目使用Qwen3-VL-8B-Insturct 模型作为底座模型
git lfs install
git clone https://www.modelscope.cn/Qwen/Qwen3-VL-8B-Instruct.git5、准备训练框架
参考以下链接文章
【课程总结】day24(上):大模型三阶段训练方法(LLaMa Factory) - 一起AI技术
由于使用autodl云服务器平台,所以会遇到一些问题,解决方法请参考笔者另一篇文章
autodl上运行llamafactory webui遇到的问题及处理方法-CSDN博客
6、模型训练
数据准备
第一步:将数据处理步骤种生成的mllm_data文件拷贝到LLaMaFactory的data目录下
第二步:将模型下载下载的底座模型 拷贝到LLaMaFactory的model目录下
第三步:修改 LLaMaFactory data目录下的dataset_info.json,增加自定义数据集:
"mllm_train_data": {
"file_name": "mllm_data.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
"mllm_eval_data": {
"file_name": "mllm_eval_data.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
},
"mllm_test_data": {
"file_name": "mllm_test_data.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages",
"images": "images"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
}
}配置训练参数
访问LLaMaFactory的web页面,配置微调的训练参数:
Model name: Qwen3-VL-8B-Instruct
Model path: #your model path
Finetuning method: lora
Stage : Supervised Fine-Tuning
Dataset: mllm_train_data(训练集) mllm_test_data mllm_eval_data(测试集和验证集)
Output dir: # your output path
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /root/autodl-tmp/model_sft_final \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template qwen3_vl_nothink \
--flash_attn auto \
--dataset_dir data \
--dataset mllm_train_data \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 1800000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 500 \
--save_steps 5000 \
--warmup_steps 0.1 \
--packing False \
--enable_thinking True \
--report_to none \
--output_dir saves/Qwen3-VL-8B-Instruct/lora/train_2026-03-21-18-57-11 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--adapter_name_or_path /root/autodl-tmp/llamafactory/saves/Qwen3-VL-8B-Instruct/lora/train_2026-03-15-15-32-59 \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0.1 \
--lora_target all \
--freeze_vision_tower True \
--freeze_multi_modal_projector True \
--image_max_pixels 589824 \
--image_min_pixels 1024 \
--video_max_pixels 65536 \
--video_min_pixels 256 训练结果
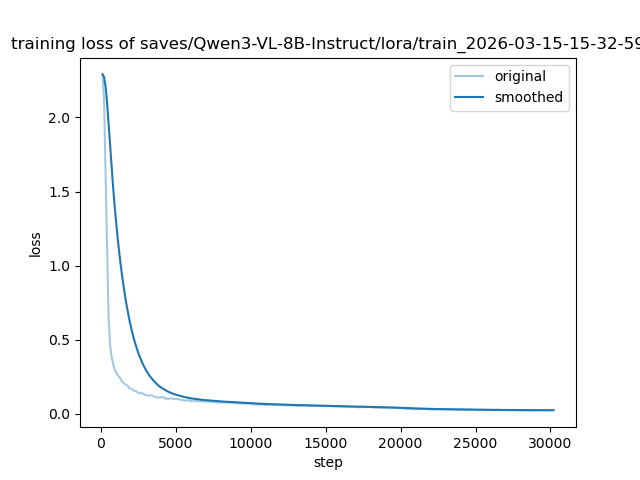
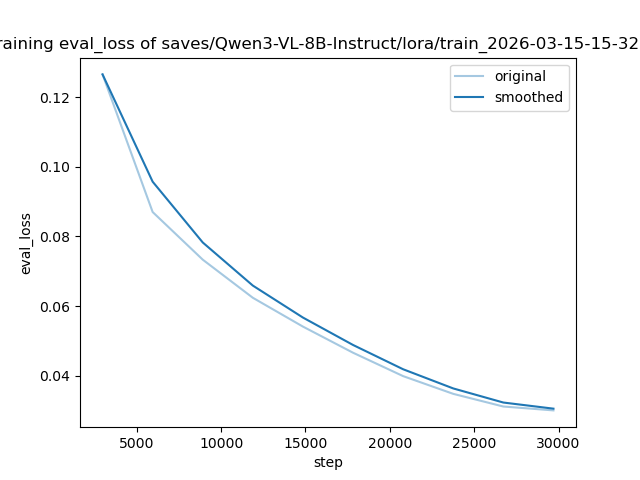
loss曲线和eval_loss曲线均平滑收敛至0.025 附近,拟合效果良好
用测试集和验证集数据进一步评估模型性能:
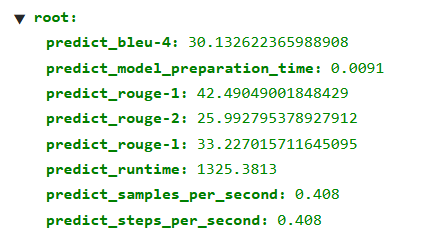
以下是predict_results.json文件内容,bleu_4分数说明模型能够生成语法通顺且包含关键医疗术语的句子,但可能在某些细节表述上与标准答案存在偏差。predict_rouge-1/2/L (42.49 / 25.99 / 33.22)说明模型已经可以准确地抓取标准答案中的关键字,并且逻辑较为通畅。但对于医学短语的学习仍有待提升。
以下为模型预测和标签的示例
观察红色部分内容发现:模型可以准确描述病变位置及大小。观察黄色部分内容发现:label中使用了hyperdense area 等医学专业短语,但模型在描述异常时使用differing density compared to the surrounding brain tissue这种非专业表达。该现象对应于predict_rouge-2得分较低。
\n请结合空间定位信息,详细描述该影像中的异常发现及其邻近结构关系。<|im_end|>\n<|im_start|>assistant\n", "predict": "The image is a non-contrasted computed tomography (CT) scan of the brain, showing the cerebral structures without any medical devices present. The region of interest, located left-center horizontally and in the middle vertically, occupies approximately 1.3% of the area and exhibits an unusual appearance indicative of a disease, possibly a CT scan with a rafts head injury, which is characterized by a differing density compared to the surrounding brain tissue. ", "label": "The image is a non-contrast computed tomography (CT) scan of the brain, showing the cerebral hemispheres, ventricular system, and skull. The region of interest, located left-center and in the middle vertically with an area ratio of 1.3%, exhibits a hyperdense area indicative of an intracranial hemorrhage. \n"}
后续改进思路:
数据清洗:检查训练集中是否存在大量含有非专业性描述的干扰数据,清理这些数据或者借助LLM重写,并计算语义相似度
eval_loss可能还有下降空间,再训练1-2个epoch效果可能会更好
引入多模态RAG增强检索
增加prompt的多样性及专业约束

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)