MoE架构爆火!揭秘AI“专家团”如何实现大容量低成本,性能竟对标GPT-4?
MoE(混合专家模型)架构通过组建“专家团队”替代传统大模型的“全才”模式,大幅降低计算资源消耗。专家网络分工协作,门控网络智能调度,稀疏激活技术实现高效计算。尽管面临负载均衡、通信开销和内存墙等工程挑战,但MoE在Mixtral、DeepSeek-V3等模型中表现优异,推动AI技术发展,降低使用门槛,重塑大模型竞争格局。
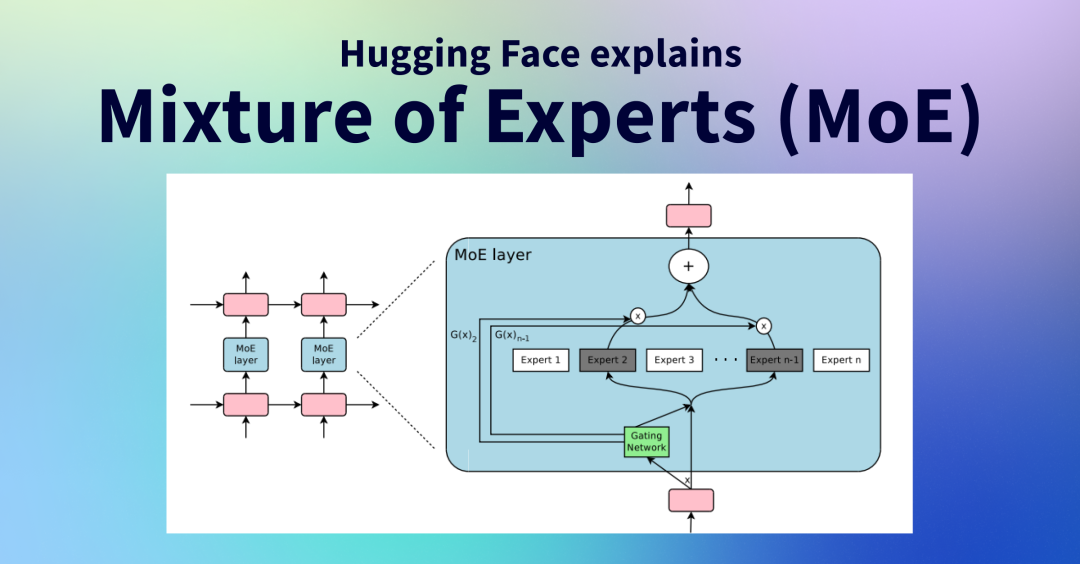
MoE 架构示意图
一、从”全才”到”专家团”
2024 年以来,AI 圈有个趋势越来越明显:那些参数动辄上千亿的大模型,背后几乎都藏着一套”分工协作”的机制。GPT-4、DeepSeek-V3、Mixtral、Qwen3——这些名字背后,都是混合专家模型(Mixture of Experts,简称 MoE)架构在支撑。
这套思路其实很好理解。传统的大模型像是一个什么都要学的”全才”,每次回答问题都要动用全部知识储备,耗费的计算资源自然惊人。而 MoE 换了个思路:与其培养一个全能选手,不如组建一支”专家团队”,各司其职,按需调用。
具体数据来看,DeepSeek-V3 总参数量达到 6710 亿,但处理每个 token 时实际激活的参数只有 370 亿,占比约 5.5%。这意味着什么?模型有着近万亿参数的知识容量,推理成本却接近一个 370 亿参数的”小”模型。这种”大容量、低成本”的特性,正是 MoE 架构受到追捧的核心原因。
二、MoE 的三板斧
MoE 并非什么新鲜概念,早在 1991 年就有人提出类似思路。但直到近几年,这套架构才真正在大模型领域大放异彩。拆解开来,现代 MoE 主要依赖三个核心组件协同工作:
1. 专家网络:术业有专攻
每个”专家”本质上是一个独立的前馈神经网络(FFN),结构相同但参数独立。主流模型的专家数量通常在 8 到 256 个之间。比如 Mixtral 8×7B 有 8 个专家,DeepSeek-V3 则部署了 256 个(含 64 个共享专家和 192 个路由专家)。
这些专家并非简单重复,而是在训练中自然分化出不同特长。有的擅长处理代码逻辑,有的精通数学推理,有的对中文语境更敏感。这种专业化分工,让模型整体能力远超同等规模的单一网络。
2. 门控网络:智能调度员
门控网络(Gating Network)是 MoE 的”大脑”。它接收输入后,快速计算每个专家的适配分数,然后挑选出最相关的 K 个专家(通常是 Top-2)来处理当前任务。
这个选择过程很有讲究。早期实现直接用 Softmax 计算概率,但容易出现”马太效应”——几个表现好的专家被过度使用,其他专家则闲置不用,造成训练崩溃。现在的主流方案是带噪声的 Top-K 门控(Noisy Top-K Gating),在路由分数中加入随机噪声,强制模型探索不同专家的组合,避免路径依赖。
3. 稀疏激活:该省省该花花
这是 MoE 最具颠覆性的设计。传统模型处理每个 token 都要遍历全部参数,称为”稠密激活”;而 MoE 只激活被选中的少数专家,其余专家保持”休眠”状态,不参与计算。
举个例子:一个 470 亿参数的 MoE 模型(如 Mixtral 8×7B),每次只激活约 130 亿参数,计算量降至稠密模型的 1/3.6,但生成质量却与 450 亿级别的稠密模型相当。这种”稀疏性”让模型在保持高性能的同时,大幅降低了训练和推理成本。
三、从理论到工程:那些看不见的坑
MoE 听起来很美,但真要做成可用的产品,还得解决不少工程难题。
负载均衡是第一道坎。 训练过程中,门控网络容易”偏科”,把大部分任务都派给某几个专家,导致这些专家过载,其他专家却无所事事。这不仅浪费参数,还会拖慢收敛速度。 Google’s Switch Transformer 和 DeepSeek-V3 都引入了辅助损失函数(Auxiliary Loss),通过惩罚不均衡的专家使用频率,强制”均匀分配”任务。DeepSeek 甚至设计了动态偏置项,给使用率低的专家额外加分,引导门控网络雨露均沾。
通信开销是第二道坎。 专家数量多起来后,单个 GPU 根本放不下,必须分布式部署。这就带来一个问题:不同 token 需要路由到不同 GPU 上的专家,卡与卡之间的数据传输很容易成为瓶颈。DeepSeek-V3 通过专家并行(Expert Parallelism)与数据并行混合的策略,把通信开销降低了 40%。微软的 DeepSpeed-MoE 框架也在这一方向做了大量优化,让训练成本比稠密模型降低了 5 倍。
内存墙是第三道坎。 虽然每次只激活部分专家,但所有专家的权重都得常驻内存。一个 6710 亿参数的模型,即便用 4-bit 量化,也需要约 400GB 显存。这对硬件配置提出了极高要求,也是 MoE 模型本地部署的主要障碍。
四、MoE 的实战表现
纸上谈兵终觉浅,看看几个代表性模型的成绩单:
| 模型 | 总参数量 | 激活参数量 | 专家数 | 亮点 |
|---|---|---|---|---|
| Mixtral 8×7B | 470 亿 | 130 亿 | 8 | 开源 MoE 的先驱,推理速度是同等质量稠密模型的 6 倍 |
| DeepSeek-V3 | 6710 亿 | 370 亿 | 256 | 训练成本仅 557 万美元,性能对标 GPT-4o |
| Grok-1 | 3140 亿 | 860 亿 | 8 | xAI 开源的重量级模型,专家分工更粗粒度 |
| Qwen3-235B | 2350 亿 | 220 亿 | 128 | 阿里最新开源模型,支持多模态 |
从这组数据能看出两个趋势:一是专家数量越来越多,从早期的 8 个发展到现在的 256 个甚至更多;二是激活比例越来越低,DeepSeek-V3 的激活率已降至 5.5%,效率优化空间还在持续挖掘。
五、MoE 正在改变什么?
对于普通用户来说,MoE 最大的价值在于降低了使用高性能 AI 的门槛。以前要跑一个 GPT-4 级别的模型,需要天价算力支撑;现在借助 MoE,消费级显卡也能本地运行 470 亿参数的 Mixtral,虽然速度不快,但至少能用。
对于开发者而言,MoE 提供了一条低成本扩展模型能力的路径。增加专家数量几乎不增加计算成本,却能显著提升模型的知识容量和任务覆盖范围。DeepSeek-V3 能在 2048 块 H800 GPU 上训练完成,靠的就是 MoE 带来的效率红利。
对于整个行业,MoE 正在重塑大模型的竞争格局。它证明了”大力出奇迹”不是唯一出路,架构创新同样能带来代际提升。这也解释了为什么 2024 年以来,几乎所有新发布的大模型都转向了 MoE 架构——从闭源的 GPT-4、Gemini,到开源的 Llama 4、Qwen3,莫不如此。
六、写在最后
MoE 的崛起,本质上是对”智能”组织方式的一次重新思考。人类社会的专业分工带来了效率飞跃,AI 模型也在走同样的路。当一个个”专家”被有机组合起来,形成的整体智能远超个体之和。
当然,MoE 并非万能药。它增加了系统的复杂度,对工程实现要求极高;它带来了通信和内存的新瓶颈;它的可解释性也远不如单一模型——门控网络为什么把某个任务派给 A 专家而不是 B 专家,往往是个黑箱。
但瑕不掩瑜,MoE 已经成为当前大模型领域最主流的架构范式。理解它的工作原理,有助于我们更好地把握 AI 技术的发展脉络,也能在实际应用中做出更明智的选择。毕竟,当你知道手里的 AI 工具是如何”思考”的,用起来也会更得心应手。
最近两年大模型发展很迅速,在理论研究方面得到很大的拓展,基础模型的能力也取得重大突破,大模型现在正在积极探索落地的方向,如果与各行各业结合起来是未来落地的一个重大研究方向
大模型应用工程师年包50w+属于中等水平,如果想要入门大模型,那现在正是最佳时机
2025年Agent的元年,2026年将会百花齐放,相应的应用将覆盖文本,视频,语音,图像等全模态
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
扫描下方csdn官方合作二维码获取哦!

给大家推荐一个大模型应用学习路线
这个学习路线的具体内容如下:
第一节:提示词工程
提示词是用于与AI模型沟通交流的,这一部分主要介绍基本概念和相应的实践,高级的提示词工程来实现模型最佳效果,以现实案例为基础进行案例讲解,在企业中除了微调之外,最喜欢的就是用提示词工程技术来实现模型性能的提升

第二节:检索增强生成(RAG)
可能大家经常会看见RAG这个名词,这个就是将向量数据库与大模型结合的技术,通过外部知识来增强改进提升大模型的回答结果,这一部分主要介绍RAG架构与组件,从零开始搭建RAG系统,生成部署RAG,性能优化等

第三节:微调
预训练之后的模型想要在具体任务上进行适配,那就需要通过微调来提升模型的性能,能满足定制化的需求,这一部分主要介绍微调的基础,模型适配技术,最佳实践的案例,以及资源优化等内容

第四节:模型部署
想要把预训练或者微调之后的模型应用于生产实践,那就需要部署,模型部署分为云端部署和本地部署,部署的过程中需要考虑硬件支持,服务器性能,以及对性能进行优化,使用过程中的监控维护等

第五节:人工智能系统和项目
这一部分主要介绍自主人工智能系统,包括代理框架,决策框架,多智能体系统,以及实际应用,然后通过实践项目应用前面学习到的知识,包括端到端的实现,行业相关情景等

学完上面的大模型应用技术,就可以去做一些开源的项目,大模型领域现在非常注重项目的落地,后续可以学习一些Agent框架等内容
上面的资料做了一些整理,有需要的同学可以下方添加二维码获取(仅供学习使用)


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献138条内容
已为社区贡献138条内容

所有评论(0)