浅谈 Yolo 26
去年去参加了yolo26的深圳发布会,一直没有时间去把这个做一个总结。现在就来进行一个总结。
Yolo v26网络结构图
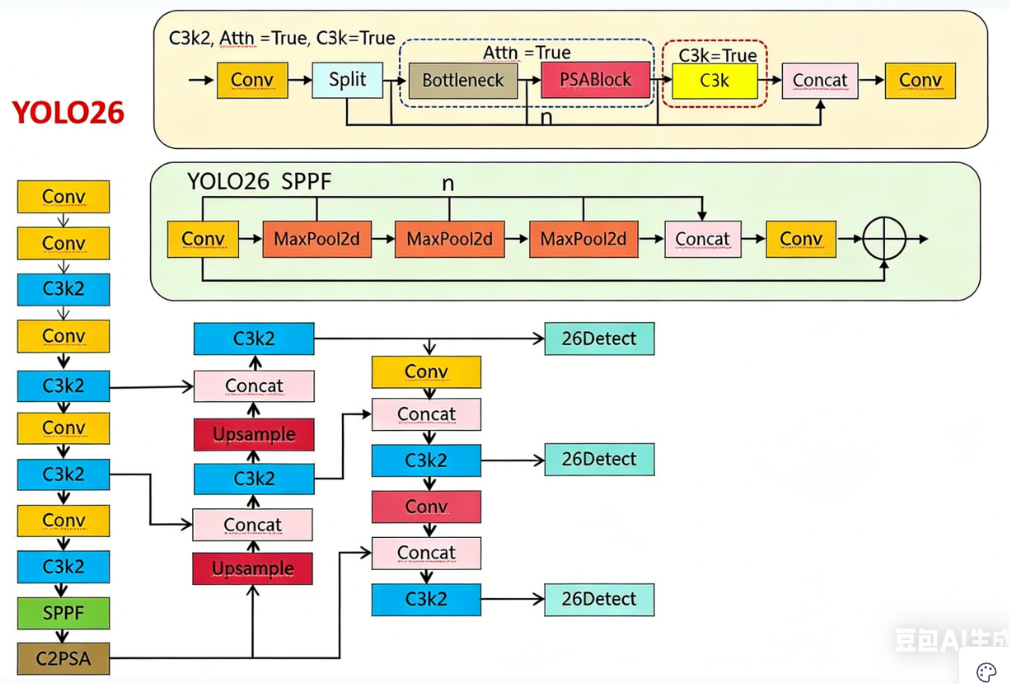
Yolo v26的特点
1.架构简化:移除分布焦点损失(DFL),简化边界框回归,提升导出兼容性。
2.端到端推理:采用无NMS设计,直接输出检测结果,降低延迟与部署复杂度。(一个目标预测一个锚框)。
3.训练增强:引入渐进损失平衡(ProgLoss)与小目标感知标签分配(STAL),提升小目标检测稳定性。
ProgLoss:(分阶段动态调权,前期分类占比高,后期回归权重占比高)
STAL:空间域 和 时间域 两个维度优化。多尺度锚点分配,空间位置优先,困难样本挖掘。
4.优化器创新:使用MuSGD优化器,结合SGD与Muon优势,加速模型收敛。
5. 多任务支持:统一框架支持检测、实例分割、姿态估计、定向检测与分类。
6.cpu推理速度提升。
总结:主要是进行了板端优化,为部署板端做铺垫。据说YOLO26在半精度(FP16)和整型(INT8)量化方案下均表现出一致的精度。
Yolo26架构模块:
1Backbone(主干网络提取特征):
总体描述:YOLO26 的 Backbone 由 ConvModule、C3k2 和 SPPF 组成。负责从输入图像中提取多尺度的特征,为后续的融合与检测提供丰富的语义信息。
①Conv 模块:Conv2d + BatchNorm + SiLU 激活函数。进行标准的卷积特征提取,同时通过 BN 加速收敛,SiLU 提供非线性,保持梯度流动。
②C3K2模块:Conv → Split → Bottleneck → PSABlock → C3k → Concat → Conv。也是沿用yolo11,一种轻量级残差模块,包含瓶颈结构和跨层连接。内部细节:
1.首先通过一个 ConvModule 调整通道数。
2.Split 将特征图按通道分为两部分(分流),一部分进入 Bottleneck 与 PSABlock,另一部分进入 C3k。
3.Bottleneck:标准残差块,由两个 ConvModule 组成,保持输入输出通道一致,增强梯度传播。
4.PSABlock:Position-Sensitive Attention Block,引入位置敏感的注意力机制,强化关键区域的特征表达。
5.C3k:内部包含多个 Bottleneck,采用跨阶段部分连接,减少计算量。
6.最后将分流处理的两部分特征在通道维度拼接,经过一个 ConvModule 输出。
2NecK(PAN-FPN特征融合):
总体描述:Neck 部分采用双向特征金字塔(PAN-FPN),通过 上采样、SPPF、C2PSA 等模块实现多尺度特征的深度融合。
①自上而下(FPN):通过上采样将高层语义信息传递给低层,丰富小目标特征。自下而上(PAN):通过下采样(图中未显式画出,但通常由步长为 2 的卷积实现)将低层的空间细节传递给高层,增强大目标定位。
②SPPF(空间金字塔池化,快速版):Conv → Conv → MaxPool2d → MaxPool2d → MaxPool2d → Concat → Conv。 前两个 ConvModule 用于降维与准备。三个 MaxPool2d 串行连接,每个池化核大小可能为 5×5(或与 YOLOv8 相同),步长=1,padding=2。将原始输入与三个池化输出在通道维度拼接,再通过一个 ConvModule 进行特征整合。
③C2PSA模块:Conv (1x1) → [PSABlock (Conv + PSA_Attn) ] × N → Concat (所有分支) → Conv (1x1)。首先:Conv:起始和结尾各有一个 ConvModule(Conv2d + BN + SiLU),用于调整通道数,保持特征维度匹配。Split:将输入特征在通道维度上分为两路,一路直接传递(shortcut),另一路进入后续处理,实现跨阶段部分连接。Bottleneck × n:多个(通常 n=2 或 3)标准的残差块,每个 Bottleneck 由两个 ConvModule 组成,保持输入输出通道一致,用于深度特征提取。PSA(Position-Sensitive Attention):位置敏感注意力模块,在 Bottleneck 处理后的特征上施加注意力,增强对空间位置的编码能力。Concat:将 shortcut 支路与经过 Bottleneck + PSA 处理后的特征在通道维度拼接,实现特征复用。
3Head(检测头):
总体描述:检测头与yolov8,分别对应 小目标(80×80)、中目标(40×40)、大目标(20×20) 的特征图,但是训练一对多加快收敛,推理的时候一对一头强制为每个目标只选一个最佳框,省去了nms的过程端到端加速后处理仅需设置一个置信度阈值进行过滤,即可得到最终结果。
结构:沿用yolov8 解耦头 设计,将分类和回归任务分离为两个独立的分支,减少任务间干扰,Detect 输出形状为 [batch, 类别数+4, H, W],直接对应最终的检测框坐标和类别置信度。
p3(小目标) 80×80 [1, 84 (4 回归 + 80 分类), 80, 80]
p4(中目标) 40×40 [1, 84, 40, 40]
p5(大目标) 20×20 [1, 84, 20, 20]
总的来说:YOLO26 在 YOLOv8 基础上实现了三大核心革新:训练机制上采用“一对多”与“一对一”双头协同训练,使模型在推理时仅保留一对一预测头,彻底摒弃了传统依赖 NMS 的后处理,实现真正的端到端检测;网络结构上将 Backbone 中的 C2f 升级为引入 PSABlock(位置敏感注意力)的 C3k2 模块,Neck 中增加了融合位置敏感注意力的 C2PSA 模块,并移除了 DFL 分支,回归头直接输出 4 个坐标值,使得输出张量简化为 [4+类别数, H, W],大幅降低了解码复杂度;部署体验上消除了 NMS 带来的不确定性延迟,在 CPU 等边缘设备上推理速度提升最高 43%,且导出的 ONNX、TensorRT 等模型自包含、无后处理依赖,真正实现“导出即用”。这一系列改进使 YOLO26 在保持高精度的同时,特别适用于自动驾驶、机器人导航、无人机巡检、智能安防等对实时性、延迟稳定性及部署便携性要求严苛的场景,成为边缘端实时目标检测的理想选择。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)