yolo目标检测性能指标和计算方法
yolo目标检测核心指标与性能评估
前言
本文针对目标检测核心内容梳理,涵盖基础评价指标、IoU、AP/mAP、COCO标准、速度精度权衡全知识点,同步拆解公式误区、算法逻辑
参考教程及ppt来源:【最适合新手入门的【YOLOV5目标实战】教程!基于Pytorch搭建YOLOV5目标检测平台!环境部署+项目实战(深度学习/计算机视觉)】
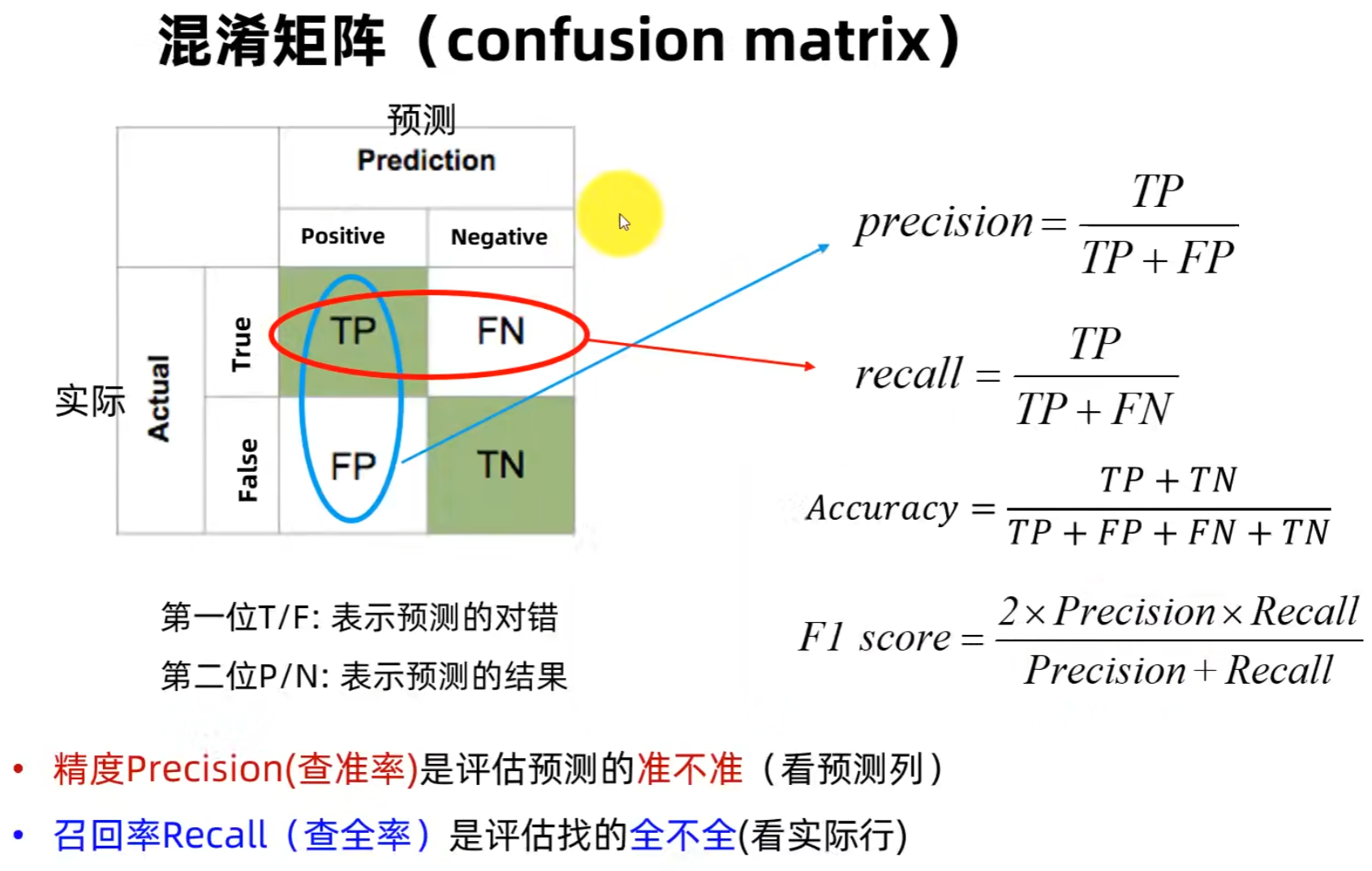
一、基础混淆矩阵与核心指标
1. 四大基础类别(目标检测忽略TN)
-
TP(真正例):检测有效,预测框与真实框匹配达标
-
FP(假正例):误报/框不准,无效检测
-
FN(假负例):漏检,真实目标未识别
-
TN(真负例):背景区域,对目标检测无意义,直接忽略
2. 三大核心评价指标
-
精确率(Precision):预测结果中,真正目标的占比,公式为Precision=TP/(TP+FP),核心是拒绝乱报、保证检测纯度
-
召回率(Recall):真实目标中,被成功检测的占比,公式为Recall=TP/(TP+FN),核心是拒绝漏检、覆盖全部目标
-
F1 Score:精确率+召回率的调和平均数,平衡二者此消彼长的关系,数值越接近1,模型综合性能越好。
通俗理解F1:既不想模型瞎识别(保精确率),也不想漏掉目标(保召回率),F1就是兼顾两者的“综合打分”。
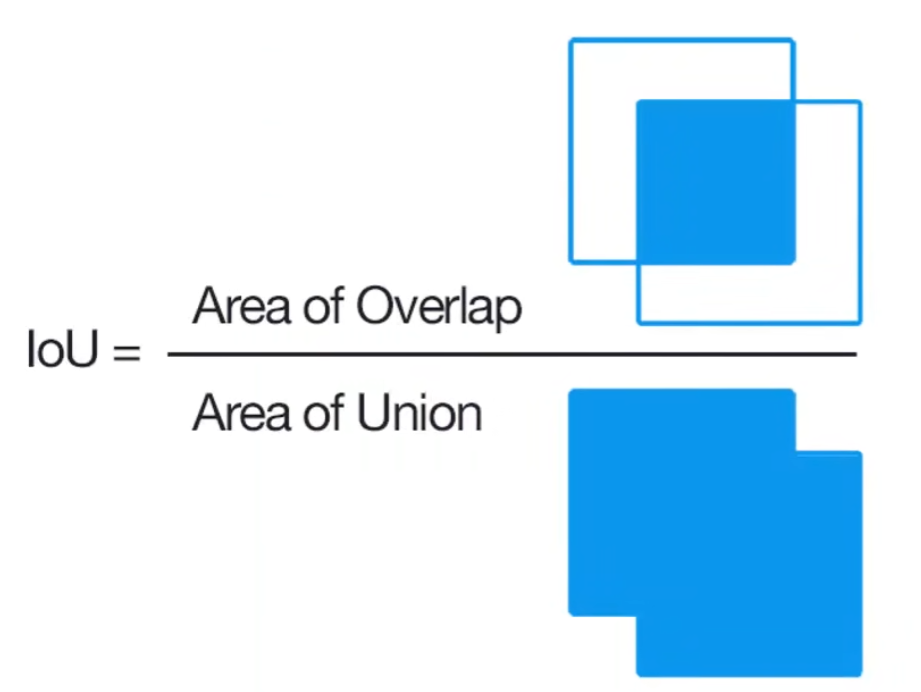
二、IoU 交并比(Intersection over Union 检测有效性判定标准)
1. 核心定义
IoU = 预测框 ∩ 真实框 / 预测框 ∪ 真实框,取值范围0~1,数值越接近1,框选精度越高。
2. 关键作用
设定阈值(常用0.5,严苛场景0.75),划分TP/FP:
-
IoU ≥ 阈值 → 判定为TP(有效检测)
-
IoU < 阈值 → 判定为FP(无效检测)
三、P-R曲线、AP与mAP(精度核心指标)
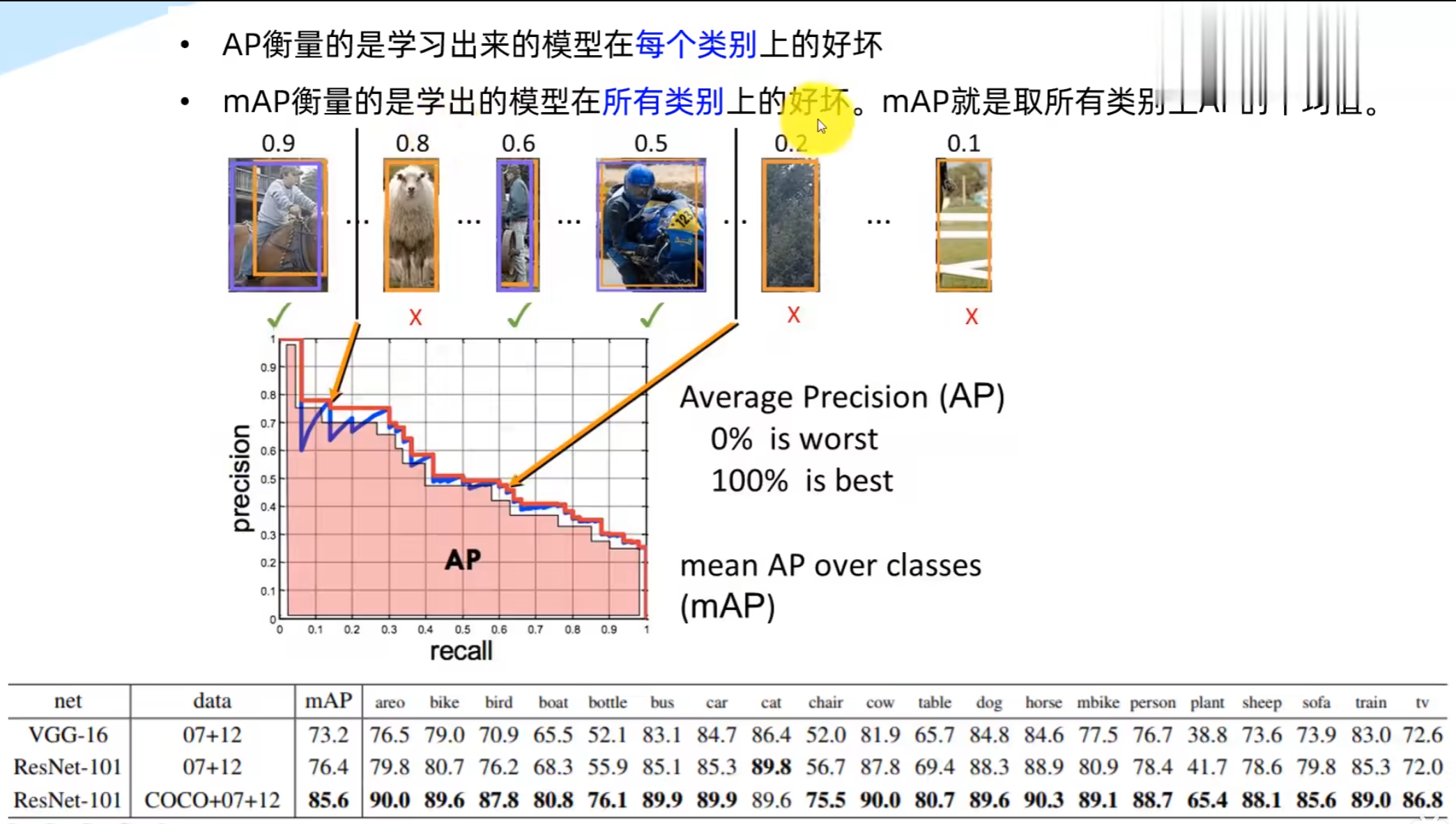
四、目标检测核心指标:P-R曲线、AP、mAP
一、P-R曲线:模型全局性能的完整刻画
1. 基础:精确率(Precision)与召回率(Recall)
先回顾两个单置信度阈值下的单点指标,这是P-R曲线的基础:
- 精确率(Precision, P):预测为正例的结果中,真正是正例的比例
P = T P T P + F P P = \frac{TP}{TP+FP} P=TP+FPTP
核心含义:模型「不乱报」的能力,值越高,误检越少。 - 召回率(Recall, R):真实正例中,被模型成功检测到的比例
R = T P T P + F N R = \frac{TP}{TP+FN} R=TP+FNTP
核心含义:模型「不漏检」的能力,值越高,漏检越少。
⚠️ 关键特性:P和R永远此消彼长
- 置信度阈值越高:模型越保守,只输出最确定的结果 → P高、R低(漏检多)
- 置信度阈值越低:模型越激进,输出所有可能的结果 → R高、P低(误检多)
单个P/R值只能代表某一个阈值下的性能,完全无法衡量模型的全局好坏,因此需要P-R曲线来完整刻画所有状态。
2. P-R曲线的定义与意义
我们遍历模型所有可能的置信度阈值,计算每个阈值对应的P、R值,以召回率®为横轴、精确率§为纵轴,将所有点连接成的连续曲线,就是P-R曲线。
- 曲线越靠右上角(P高、R高):模型性能越好,能在高召回的同时保持高精确率
- 曲线越靠左下角(P低、R低):模型性能越差,高召回时精确率大幅下降
五、AP(Average Precision,平均精度):P-R曲线下的面积
1. 什么是AP?
AP的本质,是模型在「0~100%全召回区间内,精确率的平均值」,数学上等价于P-R曲线与坐标轴围成的面积(Area Under Curve, AUC),积分公式为:
A P = ∫ 0 1 P ( R ) d R AP = \int_{0}^{1} P(R) dR AP=∫01P(R)dR
2. 为什么AP等于P-R曲线下的面积?
物理意义:P的平均值 = 曲线下面积
我们需要的不是某一个阈值下的P,而是模型在「从0%召回(只检最确定的1个目标)到100%召回(检出所有目标)」的全区间内,平均能保持多高的精确率。
- 从积分的物理意义看:对P®在R∈[0,1]上积分,就是对所有召回率水平下的P值求平均
- 面积越大,说明模型在高召回的同时,还能维持高精确率,全局性能越稳定、越优秀
3. 澄清误区:AP ≠ 精确率P
很多人会混淆 P = T P T P + F P P=\frac{TP}{TP+FP} P=TP+FPTP和AP:
- P是单点值:仅代表某一个置信度阈值下的检测效果,无法衡量全局性能
- AP是全区间平均值(面积):代表模型在所有召回率水平下的平均精确率,是全局性能指标
二者完全不是一个概念,不能等同。
六、mAP(mean Average Precision,平均精度均值)
mAP的定义非常简单,就是数据集中所有类别的AP的算术平均值,公式为:
m A P = 1 C ∑ i = 1 C A P i mAP = \frac{1}{C} \sum_{i=1}^{C} AP_i mAP=C1i=1∑CAPi
其中 C C C是数据集的类别总数。
- AP:衡量单个类别的检测精度,反映模型对某一类目标的检测能力
- mAP:衡量整个模型的全局检测精度,是目标检测领域最核心、最通用的评价指标
基于第四五六大点,下面是一个例子: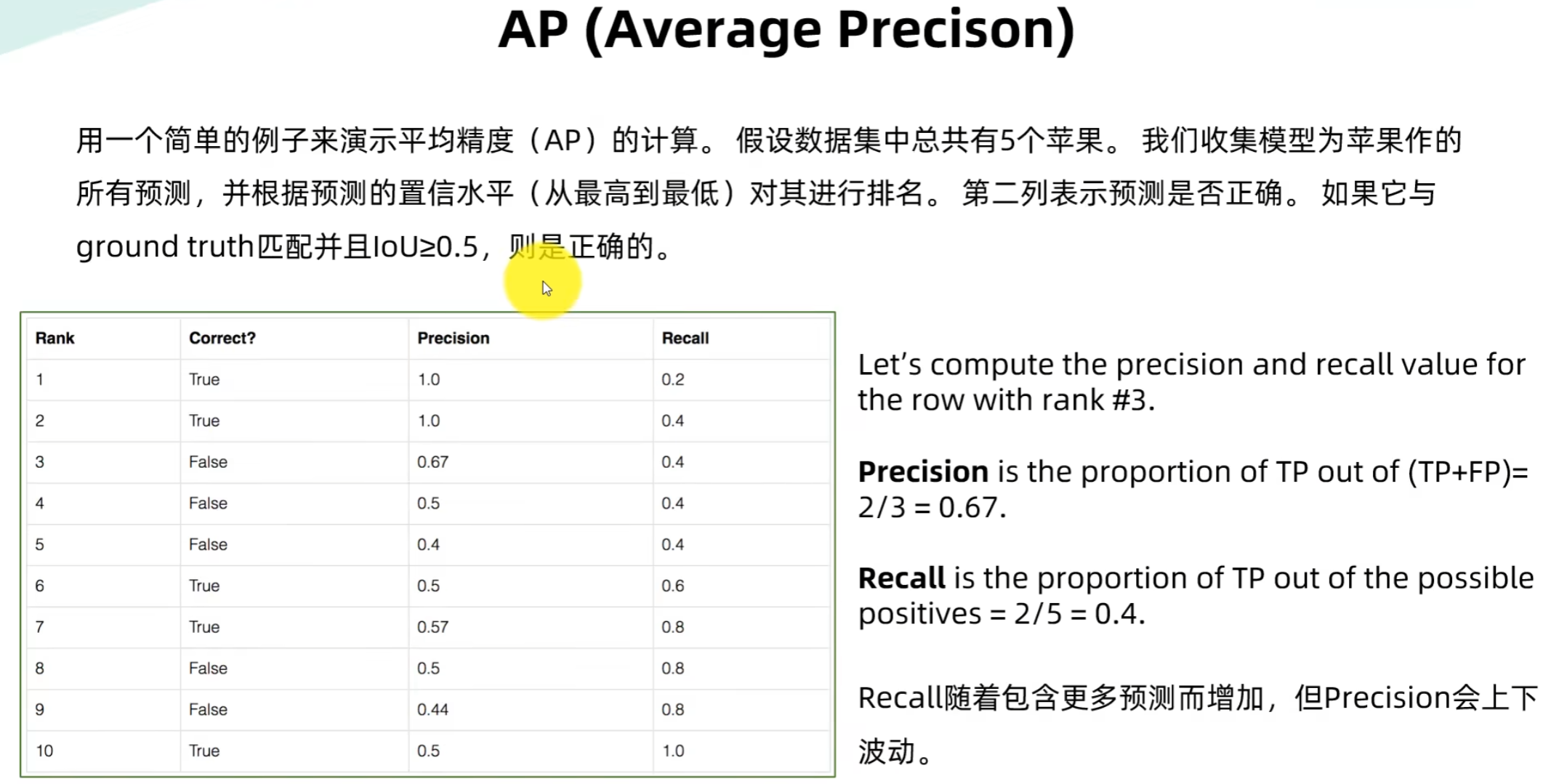
七、AP的两种经典计算方法
1. 11点法(VOC2007标准)
(1)设计初衷
直接积分需要连续的P-R曲线,实际计算中只有离散的P-R点,因此用「离散采样+近似」的方式求面积,11点法是早期经典的近似方案。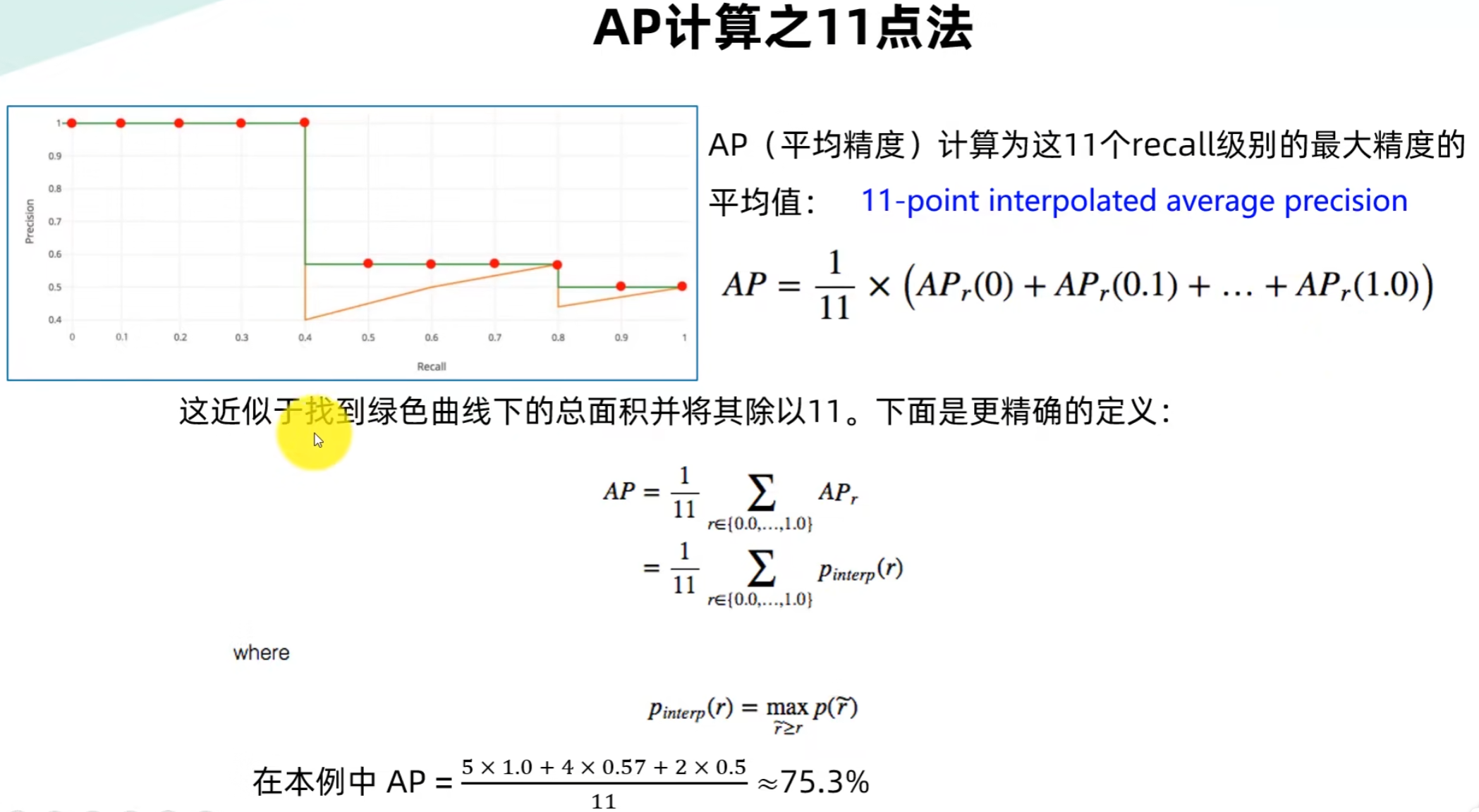
(2)完整计算步骤
-
采样11个召回率点位:在R∈[0,1]区间内,均匀取11个点: R = 0 , 0.1 , 0.2 , . . . , 1.0 R = 0, 0.1, 0.2, ..., 1.0 R=0,0.1,0.2,...,1.0
-
平滑P-R曲线(核心步骤):对每一个采样点 r r r,取「所有 R ≥ r R \geq r R≥r的位置中,最大的P值」作为该点的平滑精确率,公式为:
p i n t e r p ( r ) = max r ~ ≥ r p ( r ~ ) p_{interp}(r) = \max_{\tilde{r} \geq r} p(\tilde{r}) pinterp(r)=r~≥rmaxp(r~)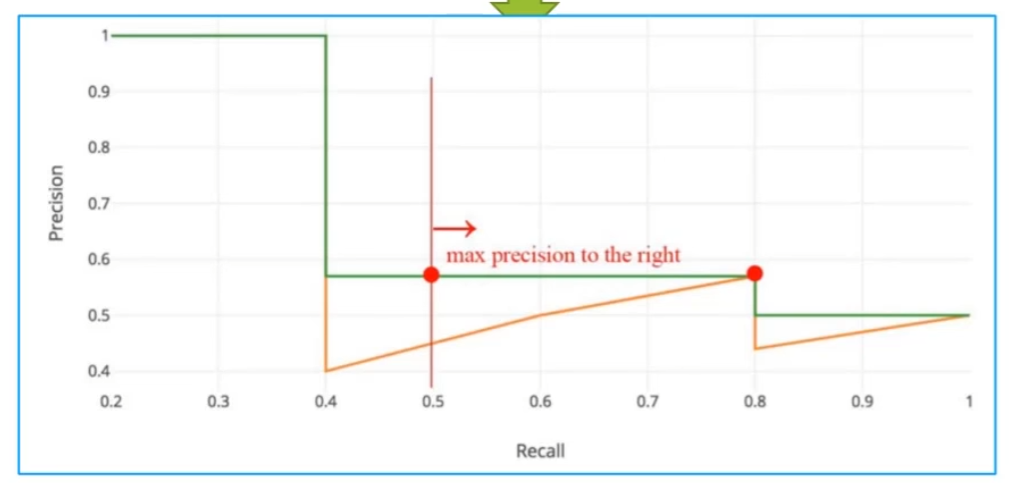
👉 这一步将橙色锯齿线变为非递增的绿色平滑线 (向右看齐) ,消除曲线波动,让AP更稳定。
-
计算11个点的P值的平均值:
A P 11 − p o i n t = 1 11 ∑ r ∈ { 0 , 0.1 , . . . , 1.0 } p i n t e r p ( r ) AP_{11-point} = \frac{1}{11} \sum_{r \in \{0,0.1,...,1.0\}} p_{interp}(r) AP11−point=111r∈{0,0.1,...,1.0}∑pinterp(r)
(3)为什么11点法等价于面积近似?
从数学上,11点法是积分的矩形近似:
- 将[0,1]区间分成11个宽度为0.1的矩形,每个矩形的高度取该区间内的最大P值
- 单个矩形面积 = 宽度 × 高度 = 0.1 × p i n t e r p ( r ) 0.1 \times p_{interp}(r) 0.1×pinterp(r)
- 总面积 = ∑ r = 0 1.0 0.1 × p i n t e r p ( r ) = 0.1 × ∑ p i n t e r p ( r ) = 1 11 ∑ p i n t e r p ( r ) \sum_{r=0}^{1.0} 0.1 \times p_{interp}(r) = 0.1 \times \sum p_{interp}(r) = \frac{1}{11} \sum p_{interp}(r) ∑r=01.00.1×pinterp(r)=0.1×∑pinterp(r)=111∑pinterp(r)(工程上直接用1/11近似)
✅ 因此11点法的本质,就是用11个矩形的面积和,近似P-R曲线下的真实面积,完全是AP的计算方法。
2. 积分法(VOC2010-2012标准)
(1)核心原理
不再用11个点近似,而是直接用所有离散的P-R点,精确计算曲线下的面积。
- 先将P-R点按R从0到1排序,每两个相邻点之间用「梯形面积」计算
- 再将所有梯形面积相加,得到最终AP,公式为:
A P = ∑ i = 1 n − 1 ( R i + 1 − R i ) × P i + P i + 1 2 AP = \sum_{i=1}^{n-1} (R_{i+1} - R_i) \times \frac{P_i + P_{i+1}}{2} AP=i=1∑n−1(Ri+1−Ri)×2Pi+Pi+1
其中 n n n是离散P-R点的总数, ( R i + 1 − R i ) (R_{i+1}-R_i) (Ri+1−Ri)是梯形的底, P i + P i + 1 2 \frac{P_i + P_{i+1}}{2} 2Pi+Pi+1是梯形的高。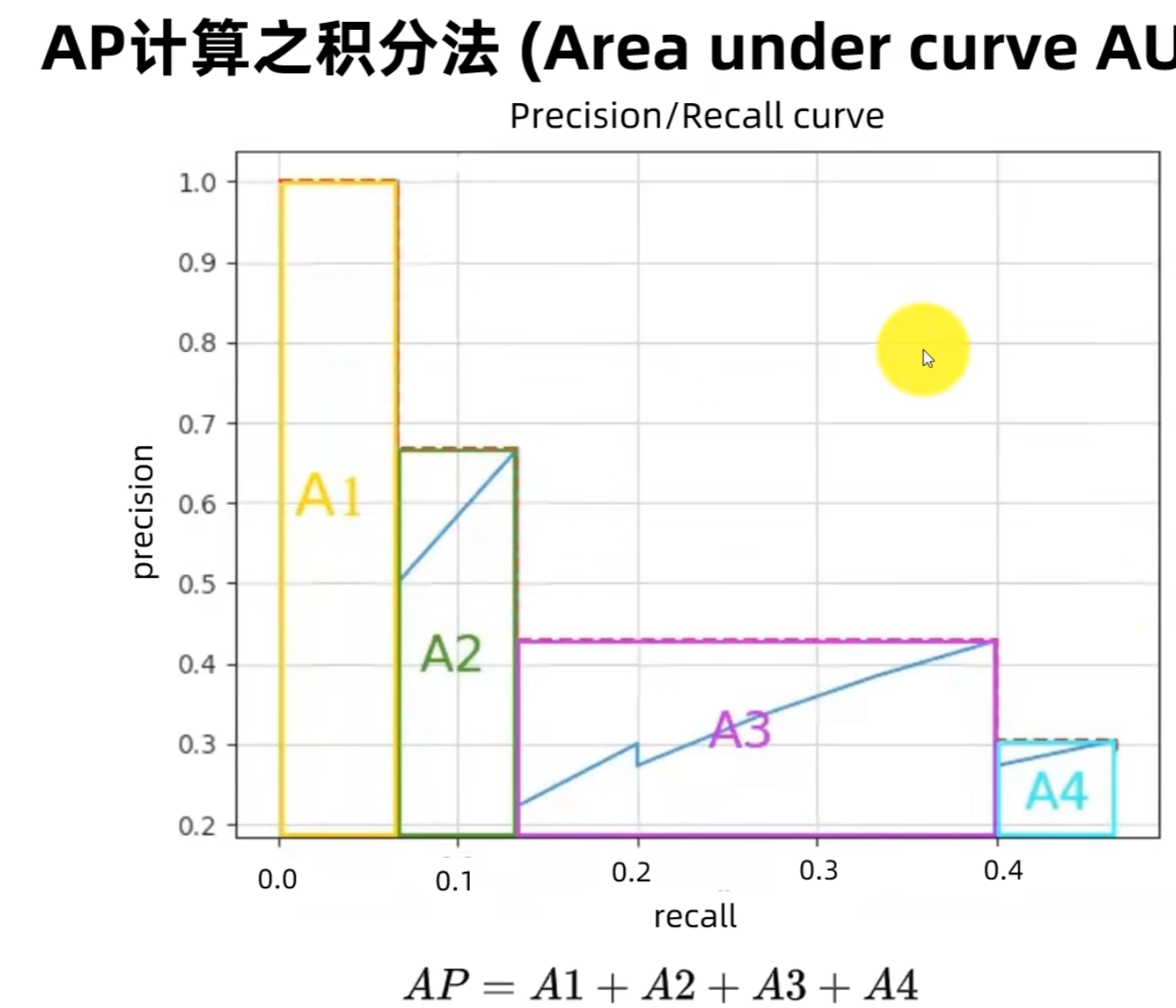
(2)与11点法的核心区别
| 计算方法 | 特点 | 适用标准 |
|---|---|---|
| 11点法 | 近似计算,采样11个R点位,计算快 | Pascal VOC2007 |
| 积分法 | 精确计算,使用所有P-R点,结果更准确 | Pascal VOC2010-2012、现在主流标准 |
八、补充:不同数据集的AP标准
| 数据集 | AP计算方法 | 核心特点 |
|---|---|---|
| Pascal VOC2007 | 11点法 | 取11个R点位,平滑后求平均,近似面积 |
| Pascal VOC2010-2012 | 积分法(全点AUC) | 用所有P-R点,精确计算曲线下面积 |
| MS COCO | 101点法 + 多IoU阈值 | 取101个R点位(01,步长0.01),同时计算IoU=0.50.95的AP平均值,评估更全面 |
九、COCO数据集评价标准
1. 平均精度AP(COCO的AP是按IoU阈值的平均值算的,不是按precision的平均值算的)
-
AP:IoU 0.5~0.95**(步长0.05)**的平均AP,赛事排名核心依据,兼顾不同严苛度下的检测效果
-
AP@0.5:IoU=0.5的AP(VOC标准,要求宽松)
-
AP@0.75:IoU=0.75的AP(严苛标准,框选极准才算有效)
-

2. 尺度AP(按目标像素大小)
-
小目标(small):像素面积<32²,远距离拍摄、特征少,检测难度最高
-
中目标(medium):32²<像素面积<96²,常规距离目标
-
大目标(large):像素面积>96²,近距离拍摄、特征丰富,易检测
3. 平均召回率AR
按单张图最大检测框数量(1/10/100)划分,同时细分小/中/大目标AR,重点评估模型漏检情况,和AP形成互补。
十、模型速度与精度权衡
1. 核心参数含义
-
Size:模型输入图像尺寸(像素),如416=416×416、608=608×608
-
FPS:每秒检测帧数,≥30帧满足实时检测需求
-
FLOPs:浮点运算量,代表模型计算复杂度,数值越小越轻量
2. 核心权衡规律
输入Size越大 → 保留细节越多、小目标识别更准(AP越高)→ 计算量越大、速度越慢(FPS越低);反之Size越小,速度越快、精度越低,实际部署需根据场景取舍。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)