MiMo\-V2 三件套:小米 Agent 全能底座——全面进军大模型全家桶
MiMo-V2 三件套:小米 Agent 全能底座——全面进军大模型全家桶
Agent 时代真的来了,但大家有没有发现一个问题:我们至今还缺一个真正的全能 AI 大脑。
说到底,一个合格的 Agent,得能看、能听、能说、能思考,还得会动手解决问题。可现在市面上的情况是什么样呢?大多是东拼西凑——语音合成是一个模型,多模态理解是另一个,推理能力又靠第三个,Agent 专项推理还要再搭一个。这么拼出来的系统,不仅推理效率低,用起来体验很割裂,而且成本还不便宜。
这次小米直接一步到位,放出了 MiMo-V2 三件套,从底层底座到语音输出全覆盖,相当于把底牌直接摊开,给大家一套现成的、完整的 Agent 解决方案。
| 型号 | 定位 |
|---|---|
| MiMo-V2-Pro | 旗舰推理底座,相当于 Agent 的“大脑”,1万亿参数支持100万token上下文,能处理超长内容 |
| MiMo-V2-Omni | 全模态理解底座,负责“看、听、理解”,就连10小时以上的长音频都能轻松解析 |
| MiMo-V2-TTS | 情感语音合成,给 Agent 一个有温度、有灵魂的声音,不再是冷冰冰的机械音 |
简单说,这三个顶级模型拼在一起,就是一个完整的 Agent,从感知世界、思考决策到表达输出,小米直接把 Agent 该走的路,一次性铺好了。
MiMo-V2 三件套架构:各司其职,又融为一体
MiMo-V2 的设计思路特别清晰:Pro 底座负责核心推理,Omni 负责全模态感知,TTS 负责情感表达,三个模型环环相扣,构成一个完整的 Agent 闭环,流程其实很简单:
┌───────────┐
│ 用户输入 │
│ 图像/视频/音频/文本
└─────┬─────┘
↓
┌─────┴─────┐
│ MiMo-V2-Omni │ 全模态感知理解
│ 支持 10 小时连续音频理解
└─────┬─────┘
↓
┌─────┴─────┐
│ MiMo-V2-Pro │ Agent 推理 & 工具调用 & 多步规划
│ 1T 参数,1M 上下文,开源框架支持
└─────┬─────┘
↓
┌─────┴─────┐
│ MiMo-V2-TTS │ 情感语音输出
│ 自然语言风格控制,会唱歌
└─────┬─────┘
↓
┌─────┴─────┘
完整 Agent 闭环
1. MiMo-V2-Pro:万亿参数旗舰底座,专为 Agent 而生
核心规格:
- 总参数超过 1TB,其中 42B 为活跃参数,继承了前代的混合注意力机制,而且把混合比例从5:1提升到了7:1,这就意味着,虽然模型规模更大了,但推理效率反而更高,不会出现“反应慢”的问题。
- 支持 100 万个 token 的上下文窗口
- 轻量级的 MTP(多 token 预测)层实现了快速生成
Agent 原生优化:
- 通过 SFT 和 RL 在复杂多样的代理框架上进行了精细调优
- 工具调用稳定性和准确度大幅提升
- 原生支持 OpenClaw 等主流 Agent 框架,相当于天生就是为 Agent 打造的“大脑”,不用额外适配就能直接用
实际表现也很能打:编码能力超过了 Claude 4.6 Sonnet,接近 Opus 水平;在业内评测中,表现也和 Claude Opus 4.6 不相上下,社区里的实际测试也显示,多数场景下的体验比 Sonnet 更好。
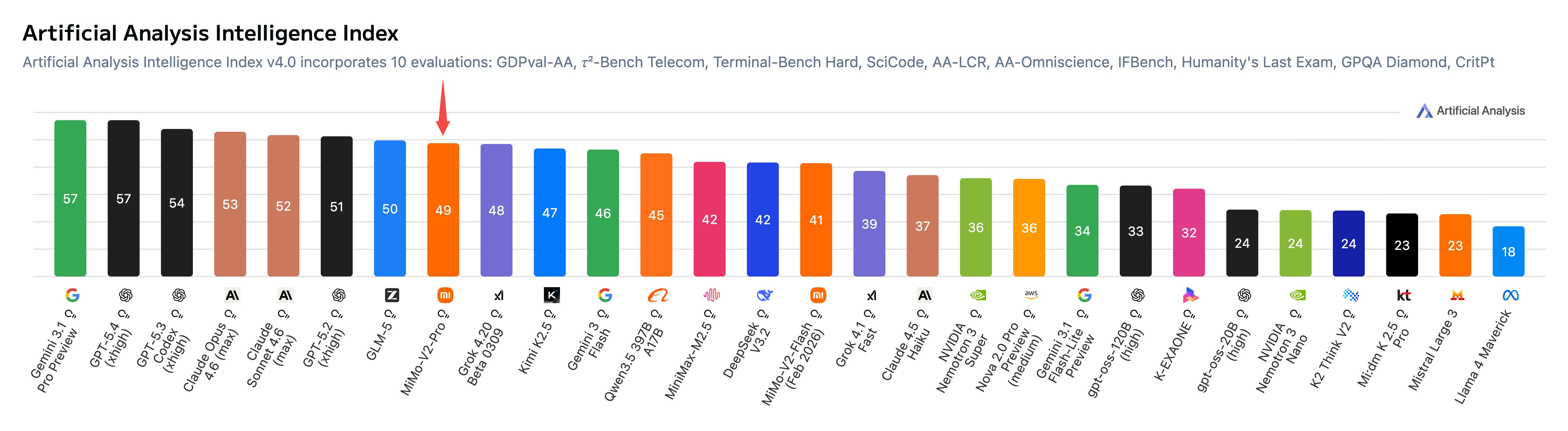
最关键的是价格很亲民,对比同类顶级闭源模型,差价能达到一个数量级,我们可以看一组具体定价(单位:美元):
| Model | Input | Output | Cache Read | Cache Write |
|---|---|---|---|---|
| MiMo-V2-Pro (up to 256K) | $1 | $3 | $0.20 | $0 |
| MiMo-V2-Pro (256K-1M) | $2 | $6 | $0.40 | $0 |
| Claude Sonnet 4.6 | $3 | $15 | $0.30 | $3.75 |
| Claude Opus 4.6 | $5 | $25 | $0.50 | $6.25 |
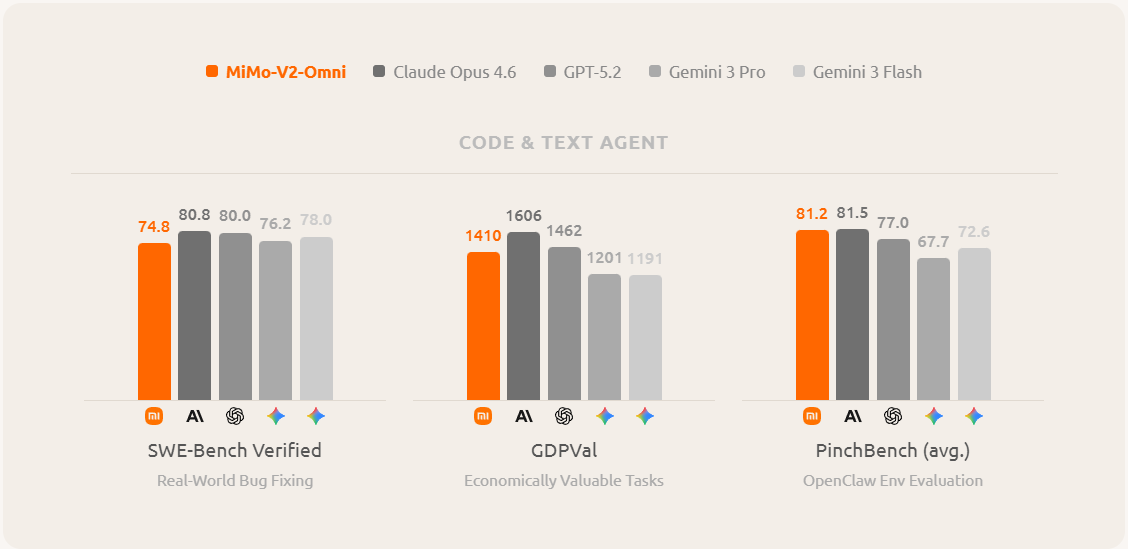
2. MiMo-V2-Omni:全能多模态,感知与行动一体化,能搞定10小时长音频
MiMo-V2-Omni 的核心设计很有亮点,它没有把图像、视频、音频的编码器分开,而是融合进了同一个共享骨干网络——不是事后拼接,而是从训练的第一步开始,就是一体化设计。
它的目标不只是“感知世界”,还要“会行动”:从一开始就训练模型学会“这里有什么→接下来会发生什么→我现在该做什么”,所以它天生就具备 Agent 能力,不用额外改造。
我们可以看看它在不同模态下的表现:
| 模态 | 评测基准 | 表现 | 结果 |
|---|---|---|---|
| 音频理解 | MMAU-Pro, BigBench-Audio | 超过 Gemini 3 Pro | 目前最强音频理解底座之一 |
| 图像理解 | MMMU-Pro, CharXiv RQ | 超过 Claude Opus 4.6,接近 Gemini 3 水平 | 强大跨学科视觉推理能力 |
| 视频理解 | VideoMME, FutureOmni | 原生音视频联合理解,具备预测未来能力 | 不只是感知已发生的事,还能预判接下来的情况 |
举几个实际应用的例子就好理解了:
自动驾驶场景:MiMo-V2-Omni 可以作为自动驾驶的视觉大脑,实时给出风险分析,逐秒识别环岛、施工区、行人等各种潜在危险,精准定位风险点。
文艺分析场景:给它一段母女做声音游戏的视频,它能写出深度的文艺分析,从蒙太奇结构、光影色调,到母女关系的主题解读,都能分析得很到位,看得出来它的跨模态理解能力很强。
播客摘要场景:面对7小时的长时对谈,它能输出精准的结构化摘要,抓住核心观点和脉络,这对现在很多模型来说,都是很难做到的。
在 Agent 能力评测上,它在浏览器操作、移动端交互、复杂工作流等场景下,表现都超过了 Gemini 3 Pro 和 GPT 5.2。和 OpenClaw 集成后,还能端到端控制浏览器,完成各种复杂任务。
3. MiMo-V2-TTS:给 Agent 一个有灵魂的声音,不止能说还会唱
在 Agent 时代,AI 不光要能解决问题,还要会“好好说话”。MiMo-V2-TTS 就是为了解决这个问题,给 Agent 一个有温度、有灵魂的声音,彻底摆脱机械音的尴尬。
它能提供的功能很实用:
- 高度可控的风格调节,不管是设定整段话的整体基调,还是微调某一句的情绪细节,甚至是句子里情绪的转变、单个短语的情感递进,都能轻松实现。
- 自然韵律,能完美还原人类说话的节奏和语气,不会出现生硬卡顿的情况。
- 唱歌能力,能准确抓住歌曲的音高和节奏,唱出来自然流畅,完全没有违和感。
它的能力之所以这么强,和它的训练方式分不开:
- 超过1亿小时的语音数据做预训练,建立了强大的跨模态对齐能力;
- 用少量高质量数据做监督式微调,让它能灵活响应各种指令;
- 通过多维强化学习,持续优化韵律、音频质量、发音准确性,还能实现高保真的语音克隆,在不同场景下用最合适的语气表达。
更让人惊喜的是它的文本理解能力,能自动捕捉文本里的语义、标点甚至重复字符里的情感线索。比如它能读懂“我真是受——够——了!”里的拖长音是愤怒,也能在朗读“请你慢慢闭上眼睛……”时,自动切换成舒缓平和的语调。
值得一提的是,它是目前市面上唯一一个在统一模型里,同时支持说话和歌唱的商用 API,轻松实现从日常对话到艺术表达的无缝切换。
优点与局限性
优点
1. 完整 Agent 闭环:这是第一次有厂商,从底座推理、全模态感知到语音输出,提供一整套全家桶,不用自己东拼西凑,小米直接给你一套能直接用的完整方案。
2. 架构设计简洁高效:Omni 从训练第一步就是一体化设计,感知和行动不是事后拼接,天生就是为 Agent 打造的,用起来更流畅、效率更高。
3. 价格亲民:和顶级闭源模型比,价格差了一个数量级,而且性能不相上下,开发者还能免费体验一周,很容易上手搭建自己的 Agent 生态。
局限性
1. 语言覆盖:目前主要支持中文和英文,其他语言的覆盖还需要后续优化。
2. 深度融合不足:现在 Omni 和 Pro 还是两个独立的模型,未来如果能实现更深层次的融合,推理和感知的协同效率会更高。
结语:从“回答问题”到“完成任务”的跨越
小米 MiMo-V2 三件套,其实指向了一个很明确的未来:AI 智能体不再是被动响应指令的工具,而是能感知世界、会表达情绪、善于解决问题的合作伙伴。
- MiMo-V2-TTS 解决了智能体“怎么自然和人对话”的问题,让它有了温度;
- MiMo-V2-Omni 赋予了智能体“看懂、听懂世界,还能主动行动”的能力;
- MiMo-V2-Pro 则给复杂的智能体系统,装上了一个“最强大脑”。
这三者结合在一起,正在把 AI 从“只能回答问题”的旧模式,推向“能独立完成复杂任务”的新阶段。
想要体验的朋友,可以去这里:https://aistudio.xiaomimimo.com/
需要 API 接入的开发者,可访问:https://platform.xiaomimimo.com

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)