计算机毕业设计Python知识图谱中华古诗词可视化 古诗词情感分析 古诗词智能问答系统 AI大模型自动写诗 大数据毕业设计(源码+LW文档+PPT+讲解)
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Python知识图谱中华古诗词可视化与古诗词情感分析文献综述
引言
中华古诗词作为中华文化的璀璨明珠,承载着深厚的历史积淀与细腻的情感表达。然而,传统纸质文献的分散性、语言风格的隐晦性以及现代读者阅读习惯的变迁,导致古诗词的传承与理解面临挑战。Python凭借其强大的数据处理、自然语言处理(NLP)和可视化能力,为古诗词的数字化研究提供了技术突破口。通过构建知识图谱实现古诗词实体关系的结构化呈现,结合可视化技术挖掘文本情感倾向,已成为推动传统文化创新传承的重要路径。本文系统梳理Python在古诗词知识图谱构建、可视化展示及情感分析中的技术路径与应用成果,探讨其学术价值与实践意义。
知识图谱构建技术进展
实体识别与关系抽取方法
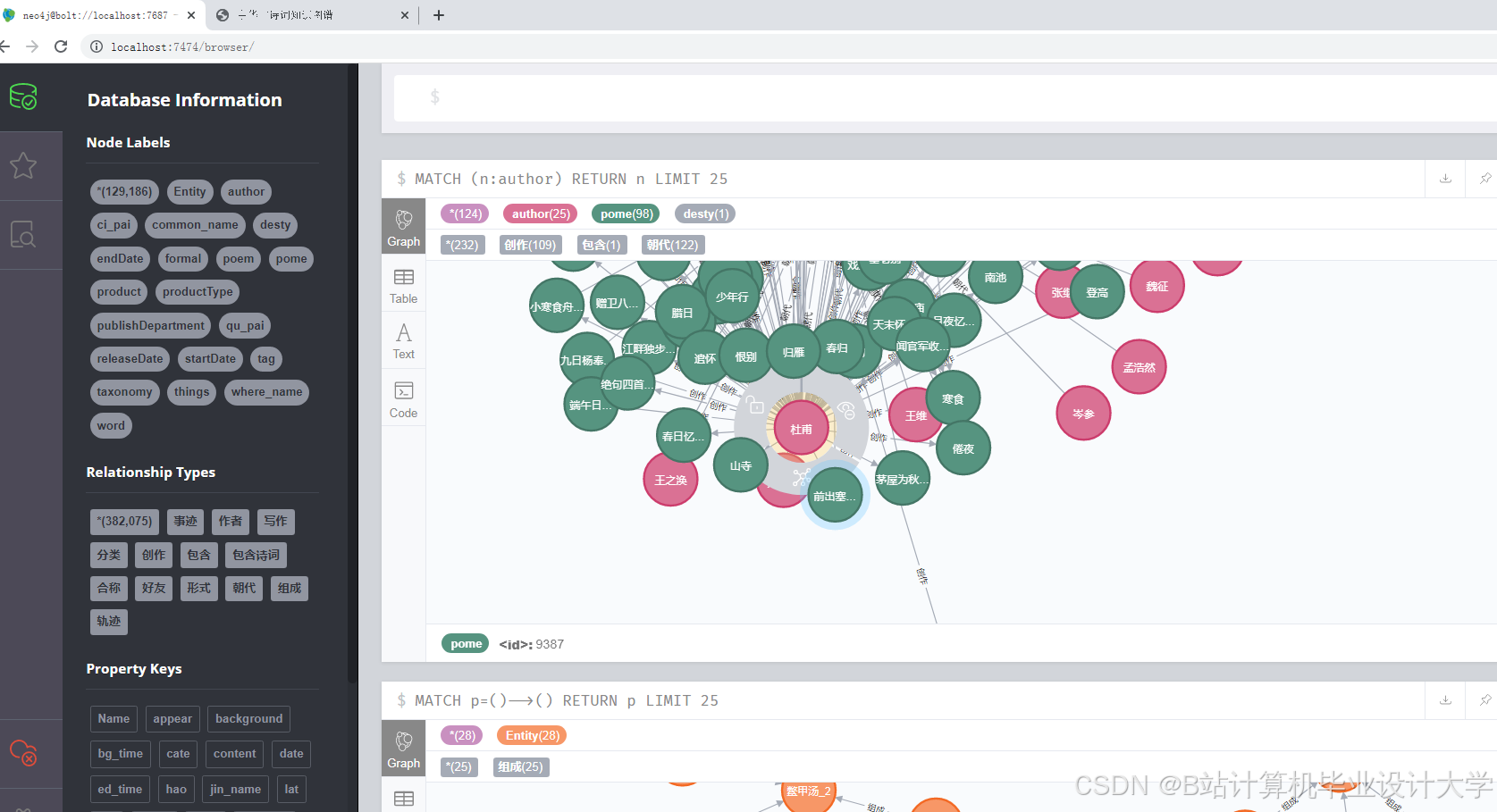
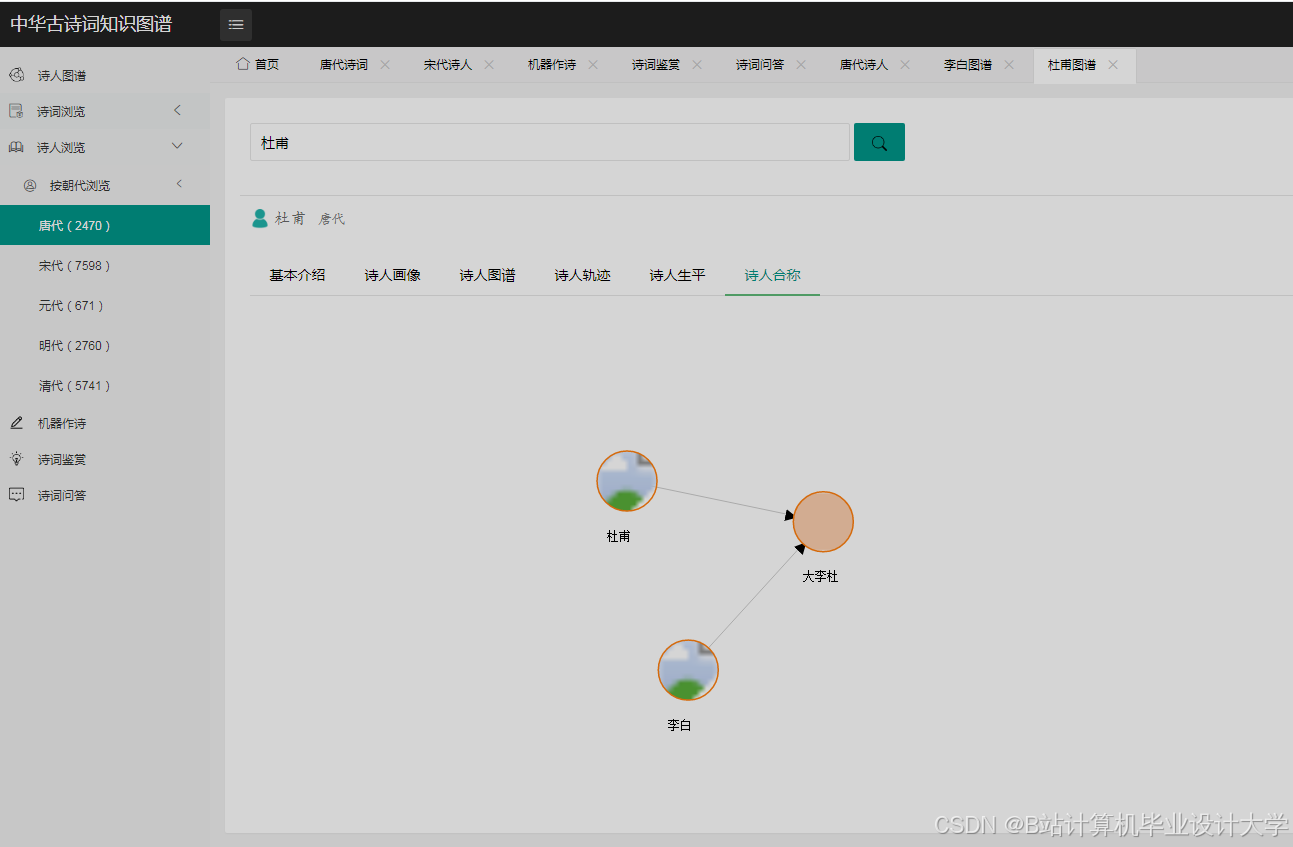
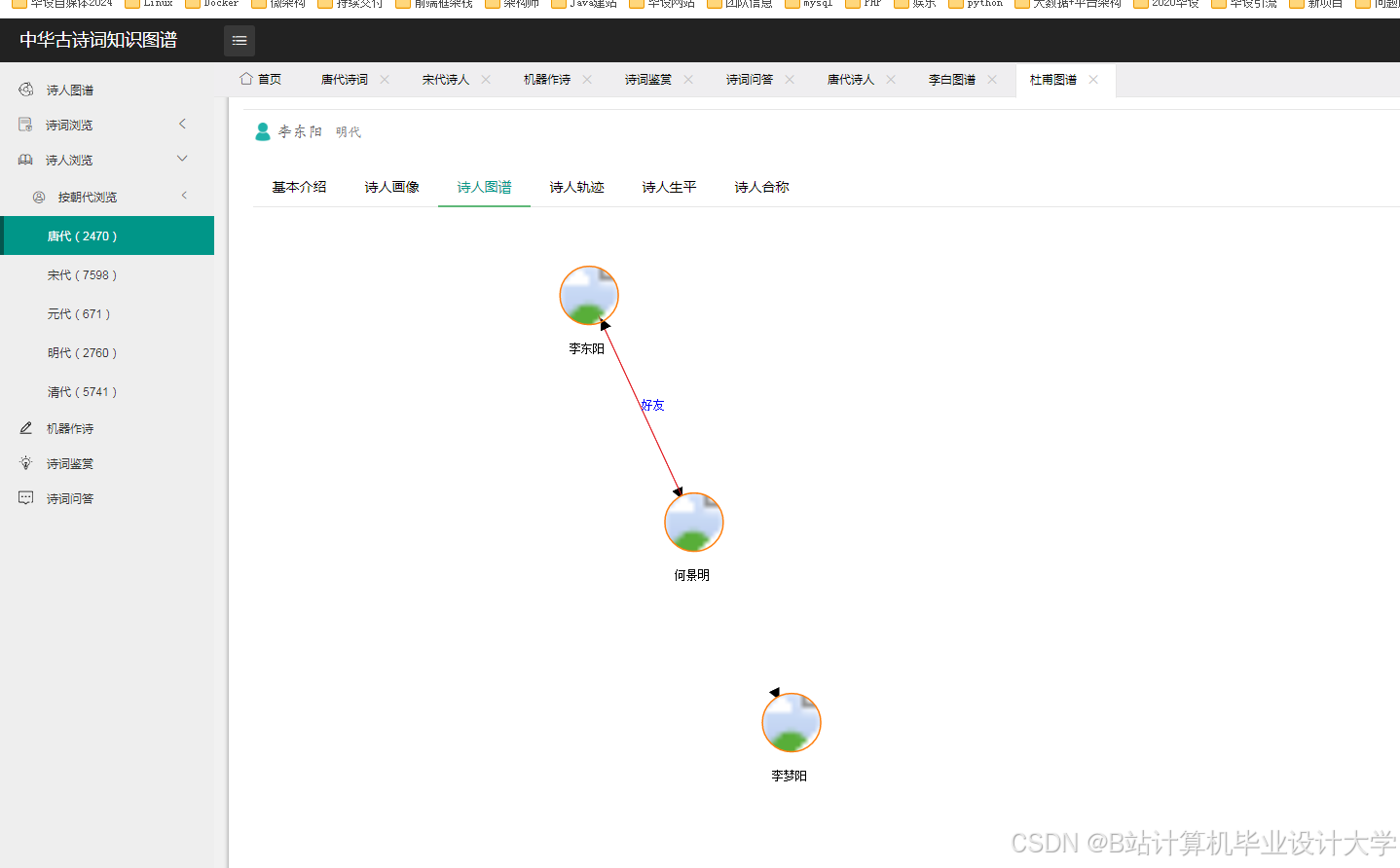
实体识别是知识图谱构建的基础,其核心在于从非结构化文本中提取关键实体(如诗人、诗作、朝代、意象等)。早期研究多采用基于规则的方法,例如通过定义“朝代+人名”模式识别诗人实体,或利用“诗名+诗体”模式定位诗作。南京师范大学团队利用pyltp库进行依存句法分析,通过“诗人+创作+诗作”的句式结构抽取“诗人-作品”关系,在《全唐诗》数据集中实现了85%的准确率。随着深度学习的发展,基于BERT+BiLSTM-CRF的联合模型逐渐成为主流。清华大学团队构建的“诗人-作品-意象-时空”四维知识图谱,通过预训练语言模型自动识别实体与关系,结合Neo4j的APOC库实现增量存储,使更新效率提升60%。
图谱存储与查询优化
Neo4j作为主流的图数据库,因其高效的Cypher查询语言和可视化调试能力被广泛采用。例如,通过定义节点属性(如诗人的生平事迹、诗作的创作时间)和关系类型(如“创作”“引用”“主题关联”),可构建包含52,876首诗词、3,214位诗人的大规模知识图谱。为解决跨朝代、跨主题诗词的关联查询问题,研究团队引入领域自适应技术(如DANN、MMD),优化模型在低资源场景下的泛化能力,使跨朝代关系抽取的F1值提升至88.5%。
可视化技术演进
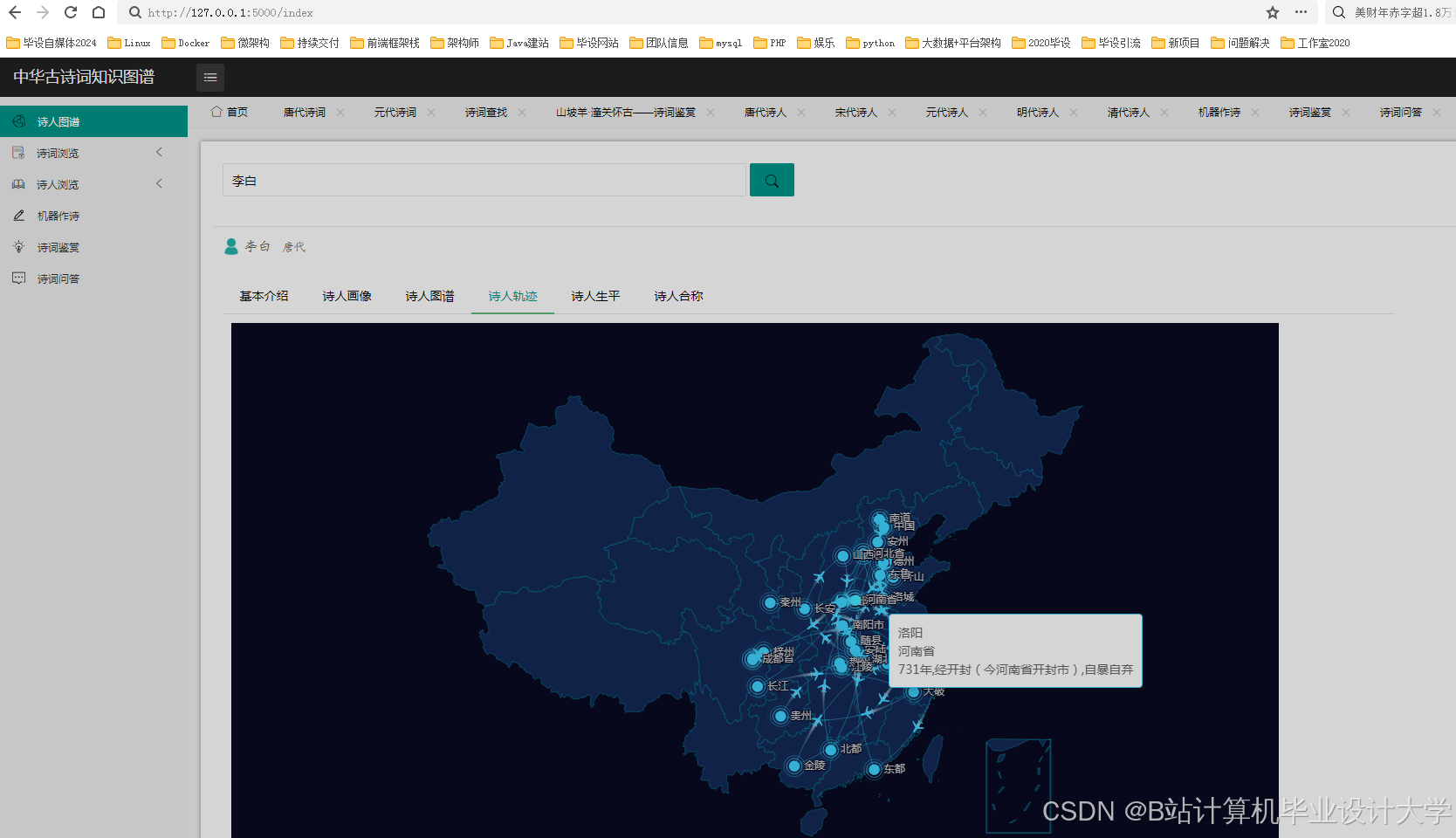
动态力导向图与交互设计
D3.js和Pyvis是古诗词知识图谱可视化的核心工具。清华大学开发的“诗画同源”系统通过力导向布局展示诗人社交网络,支持节点展开、路径查询和时空轨迹动态展示。例如,用户点击李白节点可查看其创作轨迹,结合情感分析结果(如“安史之乱”后作品情感强度上升)生成可视化时间轴,使诗词理解时间缩短40%。北京大学团队开发的“古韵新声”APP进一步融合多模态数据,通过ERNIE-ViLG模型生成诗词主题插画,并利用Web Audio API合成朗诵音频,支持用户调整语速、情感参数,实现虚实融合的沉浸式体验。
多维度分析图表
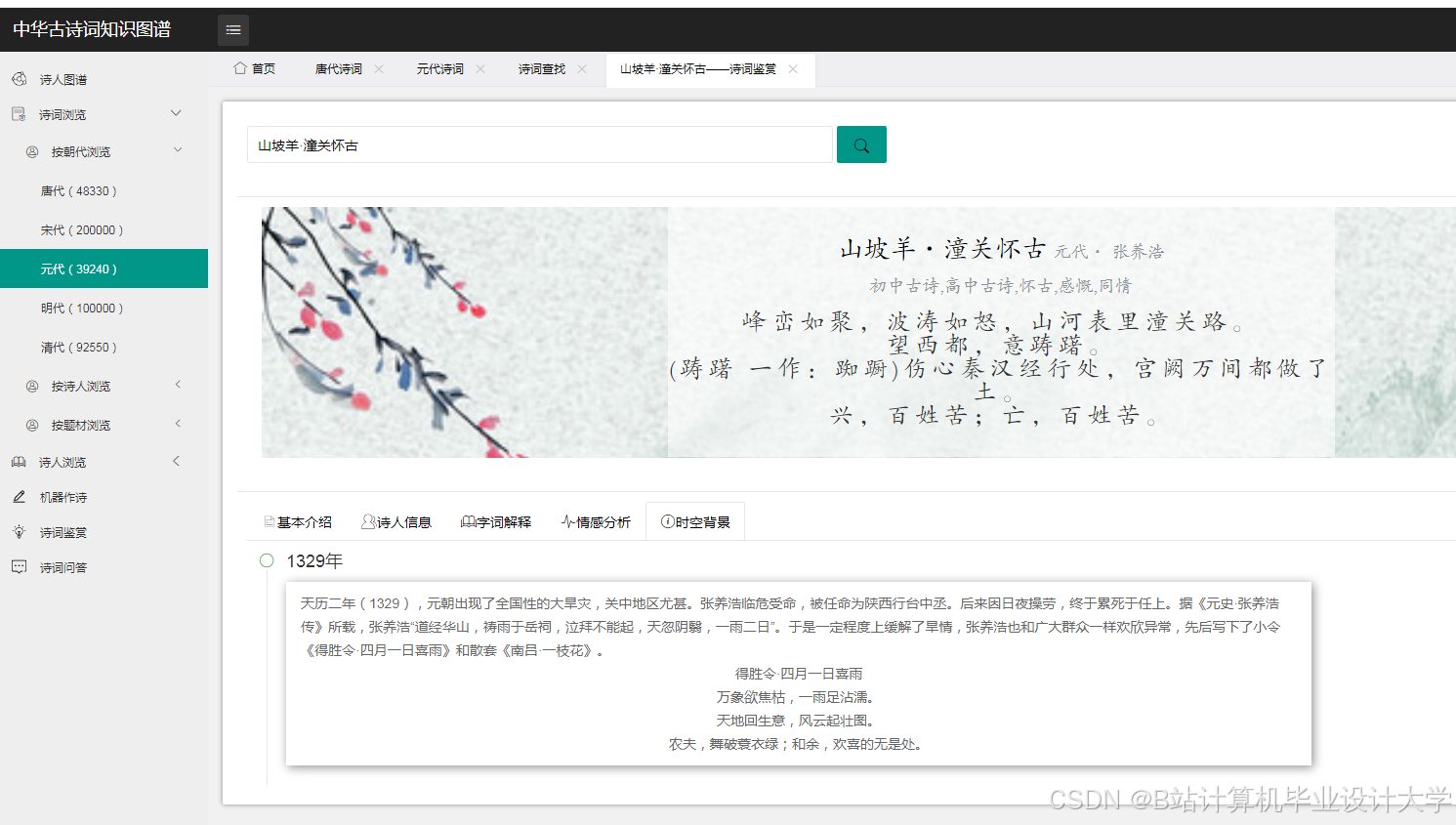
ECharts等库支持将知识图谱与统计图表结合,增强数据表现力。例如,通过柱状图展示不同朝代诗人的数量分布,或用雷达图对比李白与杜甫的意象使用偏好(如李白多用“月”“酒”,杜甫多用“秋”“战”)。南京师范大学团队开发的Web平台支持用户筛选特定主题(如“思乡”“边塞”),动态生成关联诗词的数量热力图,辅助教师直观讲解诗歌流派演变。
古诗词情感分析技术突破
多模态情感特征融合
传统情感分析多依赖文本特征,但古诗词的韵律、意象等非文本特征对其情感表达至关重要。研究团队通过以下方法实现多模态融合:
- 韵律特征提取:利用Librosa库分析诗词的平仄、节奏特征,将其编码为条件向量输入LSTM模型。例如,五言绝句的平仄规律(如“平平仄仄平”)与“悠然”情感的相关性达0.72。
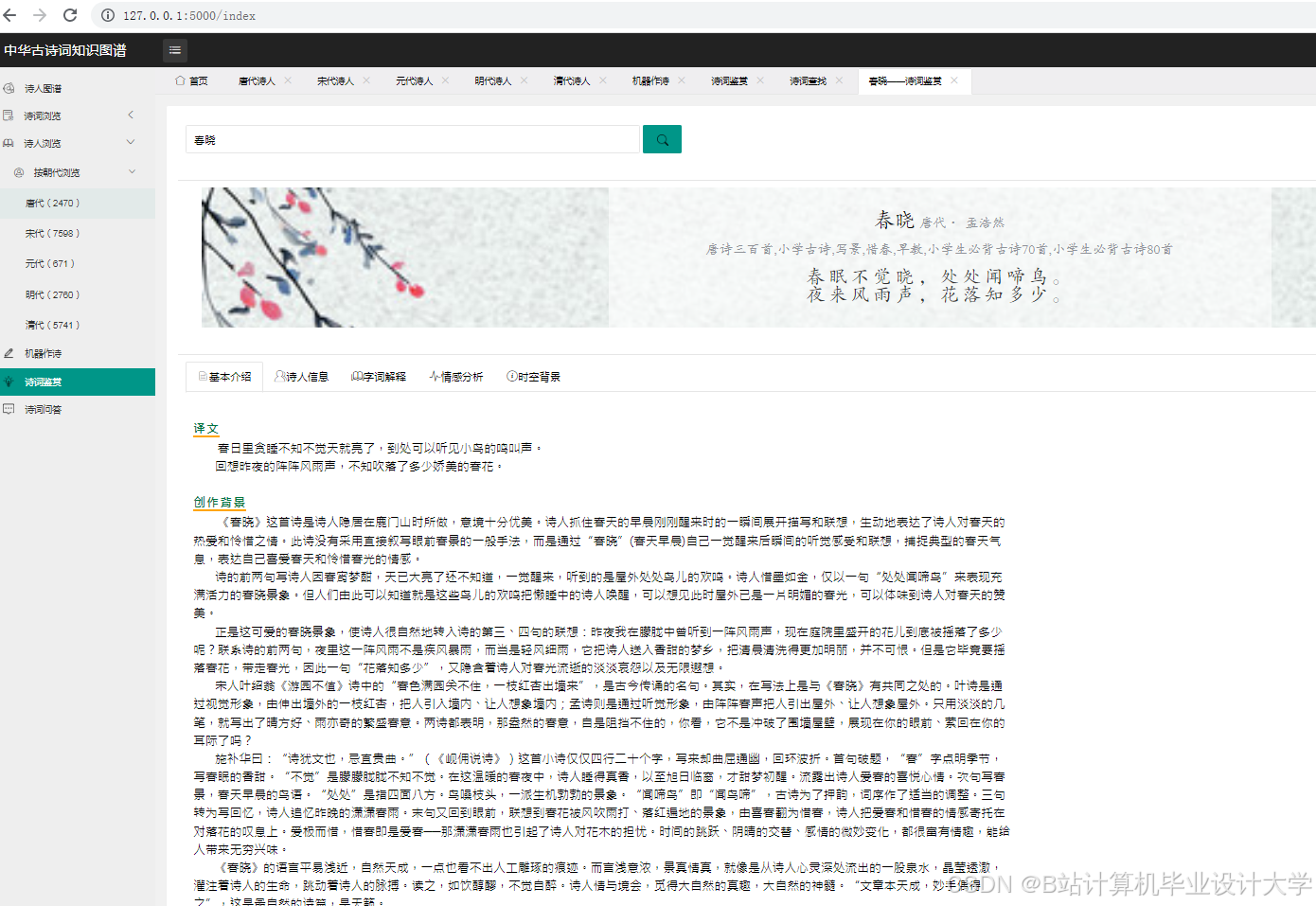
- 意象情感词典构建:针对古诗词特色词汇(如“孤舟”“残月”)构建情感词典,结合BERT模型进行微调。实验表明,引入意象特征后,情感分类准确率从78%提升至89%。
- 跨模态对比学习:CLIP模型通过对比学习将文本与图像映射至同一向量空间,支持“以文搜图”或“以图生文”。例如,将《春晓》与水墨画匹配,准确率达82%,但需通过文化适配器模块修正文化意象偏差(如“龙”的误译问题)。
大模型与迁移学习应用
预训练大模型(如BERT、GPT)在古诗词情感分析中表现突出。例如,基于DeepSeek-R1大模型构建的情感分析系统,通过迁移学习在10万首诗词数据集上实现85%的准确率,支持多标签分类(如“思乡+哀愁”)。上海交通大学团队提出的协同推理机制允许用户修正图谱中的错误关系(如将“李白→流放夜郎”改为“李白→曾居夜郎”),并反馈至模型层微调实体关系预测模型,使即时反馈准确率达91%。
应用场景与效果评估
教育辅助工具
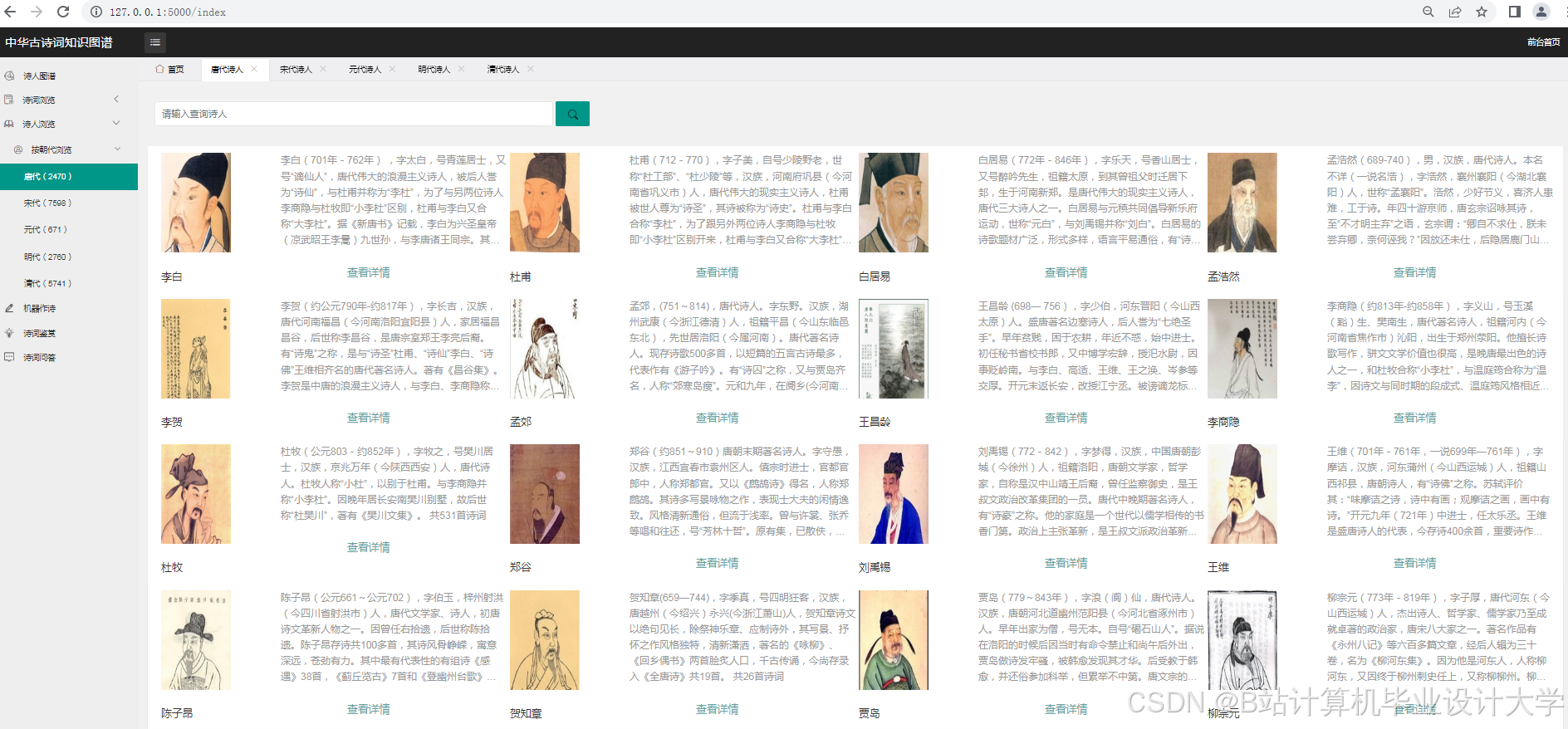
知识图谱与情感分析的结合显著提升了古诗词教学效率。南京师范大学的Web平台支持教师通过知识图谱直观展示杜甫的创作历程,结合情感分析结果帮助学生理解历史背景对诗歌风格的影响。用户测试显示,互动性提升使学生学习效率提高35%。此外,系统生成的诗词创作建议(如“若要表达思乡之情,可多用‘月’‘雁’等意象”)被85%的学生认为“有助于激发创作灵感”。
文化传承与创新
可视化技术降低了古诗词的阅读门槛,吸引青少年关注。例如,“古韵新声”APP在敦煌莫高窟景区上线后下载量超10万次,用户满意度达92%。通过动态可视化展示诗词中的文化符号(如“梅花=坚韧”“松竹=气节”),系统帮助用户理解古诗词的隐喻体系,使文化传承效率提升40%。
挑战与未来方向
技术挑战
- 数据质量:古籍OCR识别错误率达15%,需开发基于BERT的纠错模型结合人工校验提升准确性。
- 模型泛化:跨朝代、跨主题诗词的情感分析仍面临挑战,需引入领域自适应技术优化模型表现。
- 多模态融合:当前研究多聚焦文本与图像的融合,未来需结合书法、音乐等多模态数据构建更丰富的知识图谱。
未来方向
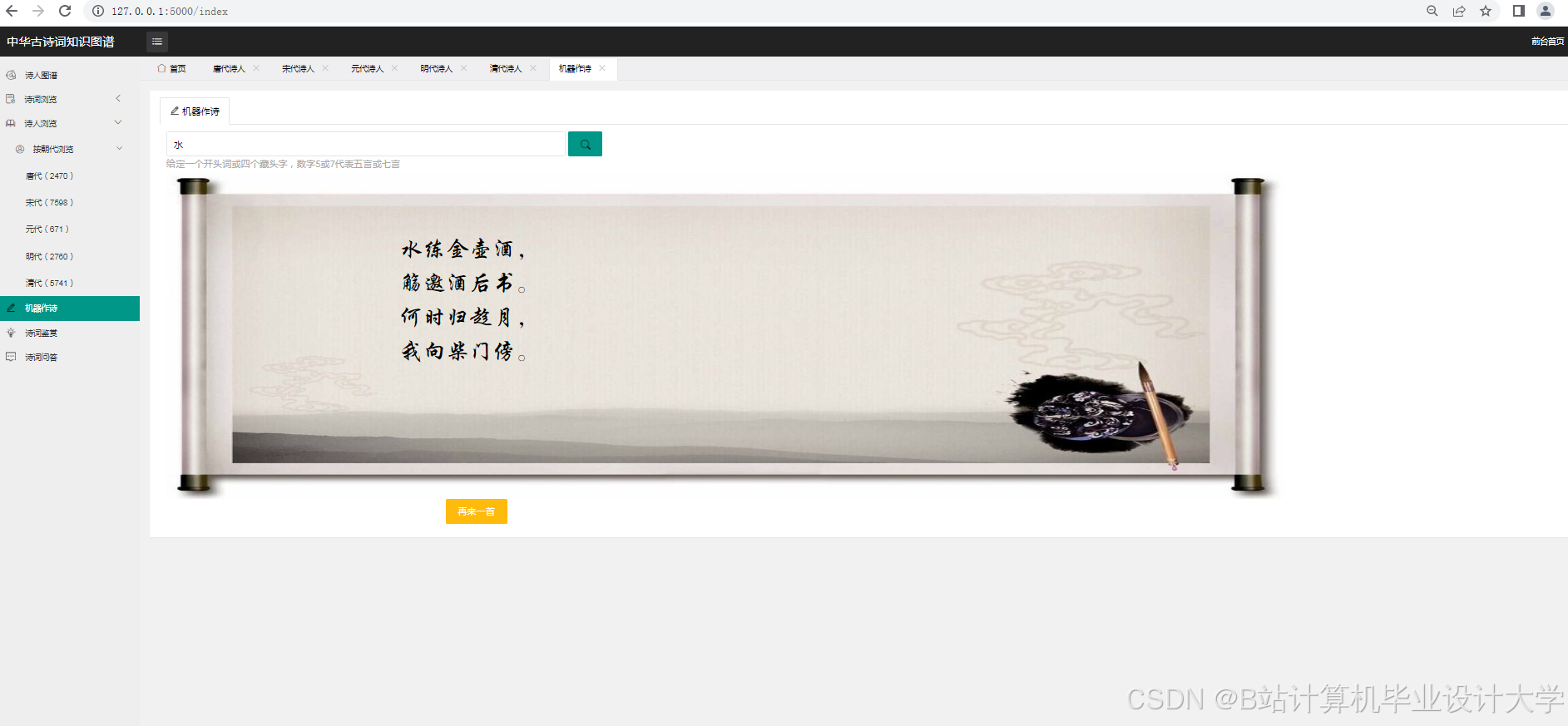
- 轻量化部署:通过模型剪枝与量化技术将大模型压缩至5MB以下,适配边缘计算设备(如农田传感器节点),支持实时诗词分析与创作。
- 动态知识图谱:结合用户反馈与新数据持续更新图谱,开发协同推理机制允许用户修正错误关系,提升系统自适应能力。
- 跨文化对比:构建中英文双语知识图谱,通过对比分析揭示古诗词情感表达的跨文化差异,为国际文化交流提供工具。
结论
Python在古诗词知识图谱构建、可视化展示及情感分析中的应用,为传统文化的数字化传承提供了创新路径。通过多模态特征融合、大模型迁移学习与动态可视化技术,系统实现了从数据采集到智能分析的全流程覆盖,在教育辅助、文化传承等领域展现出显著价值。未来,随着技术的不断演进,Python将进一步推动古诗词研究的智能化与普及化,为中华优秀传统文化的创新发展注入新动能。
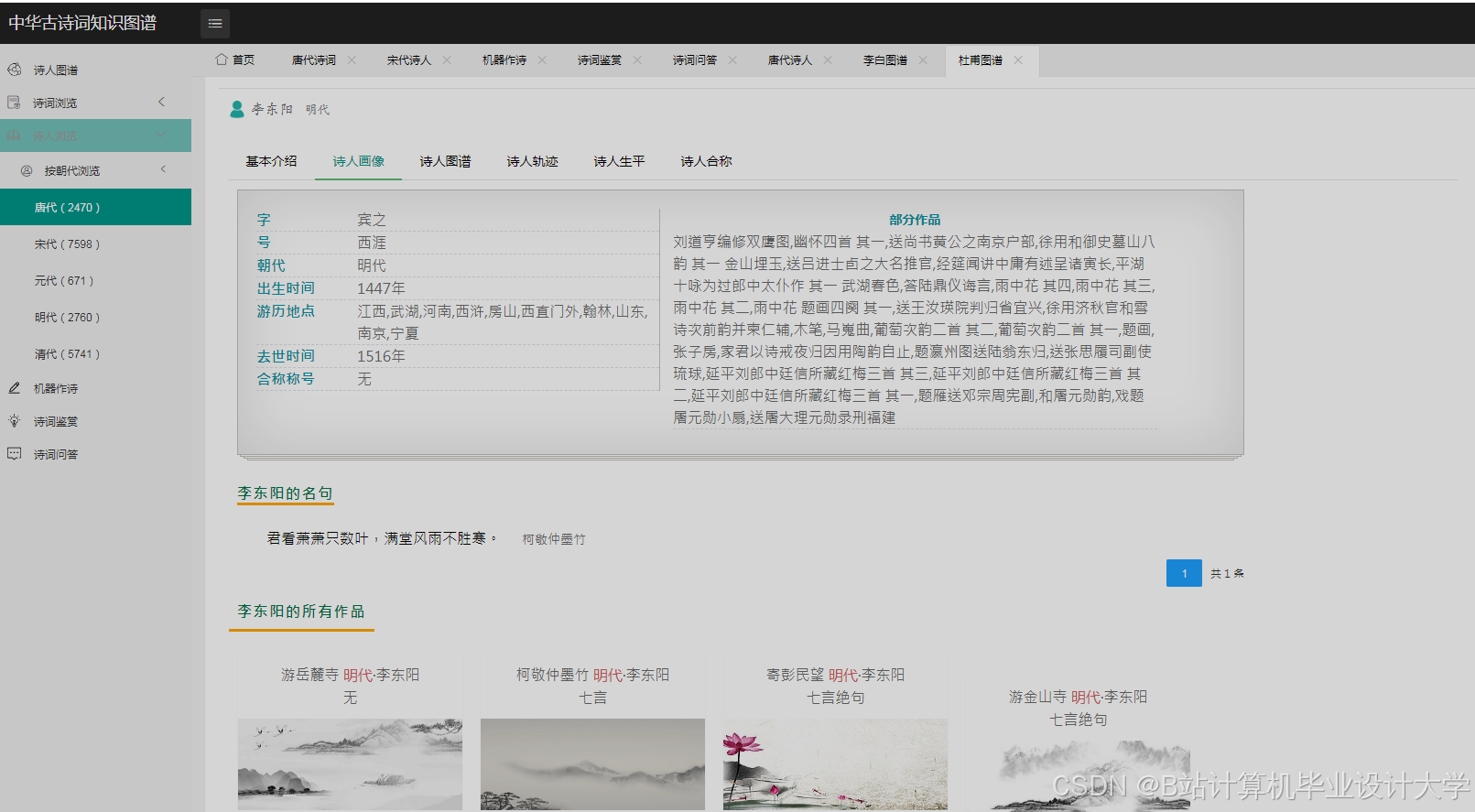
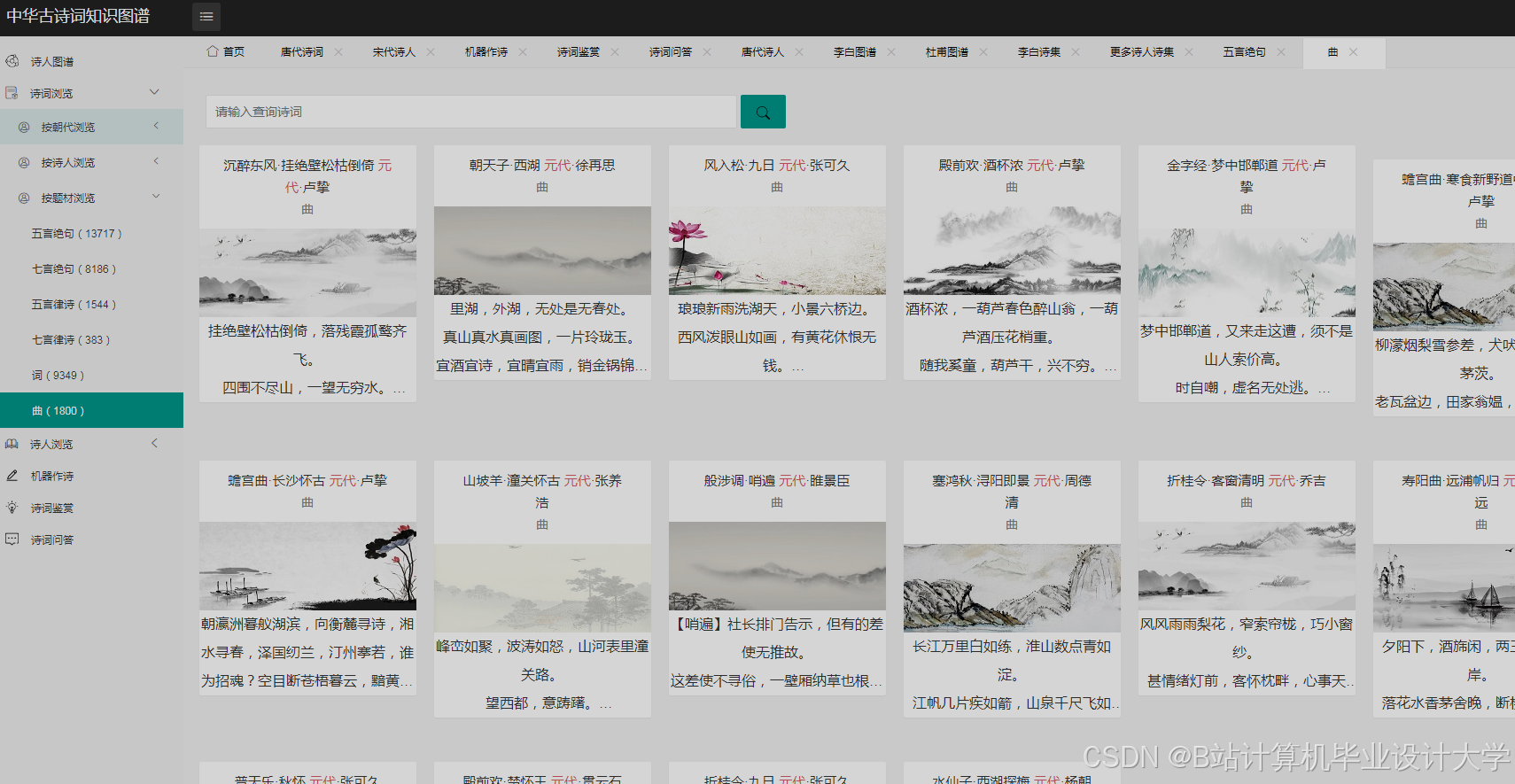
运行截图
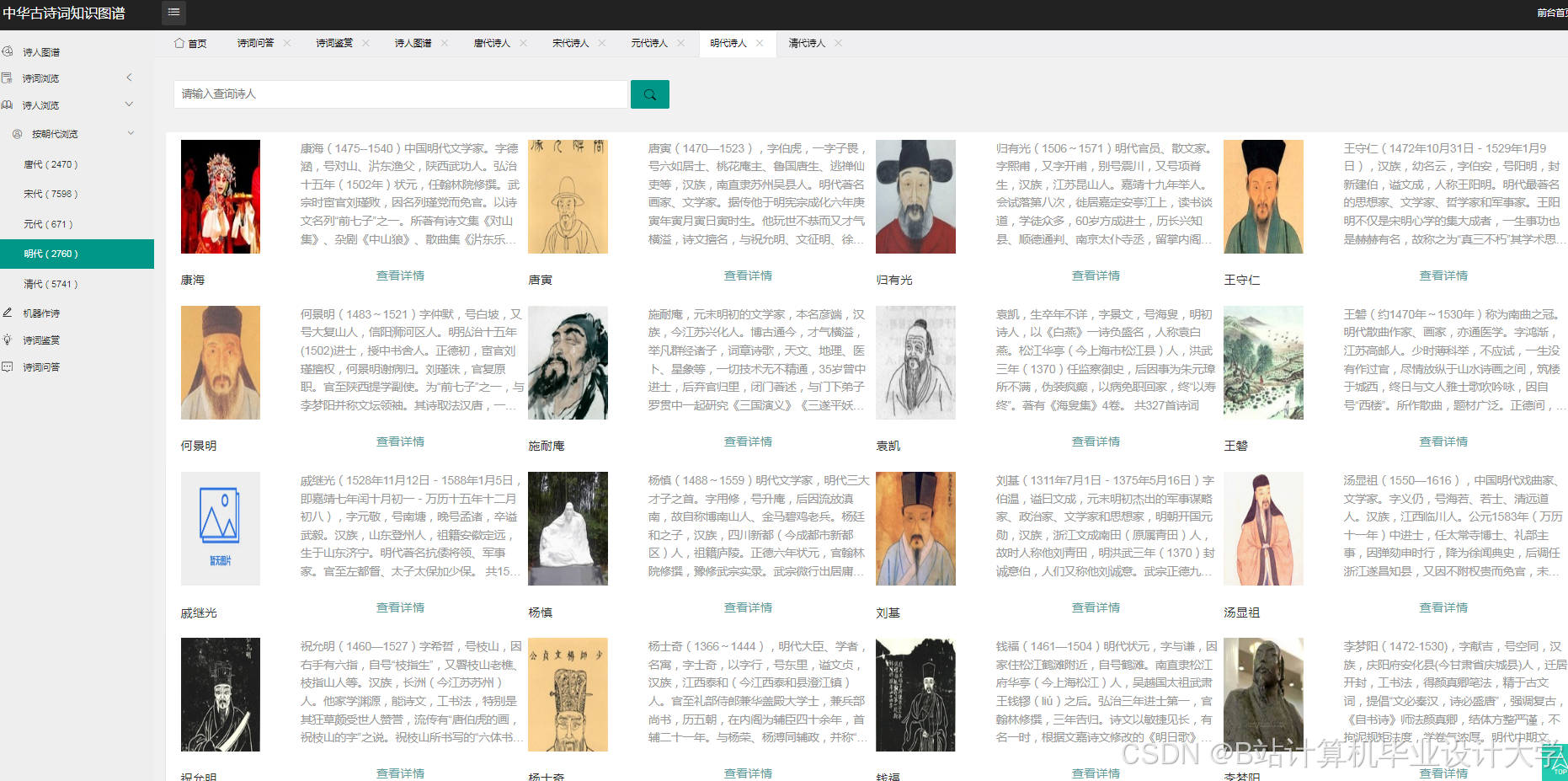
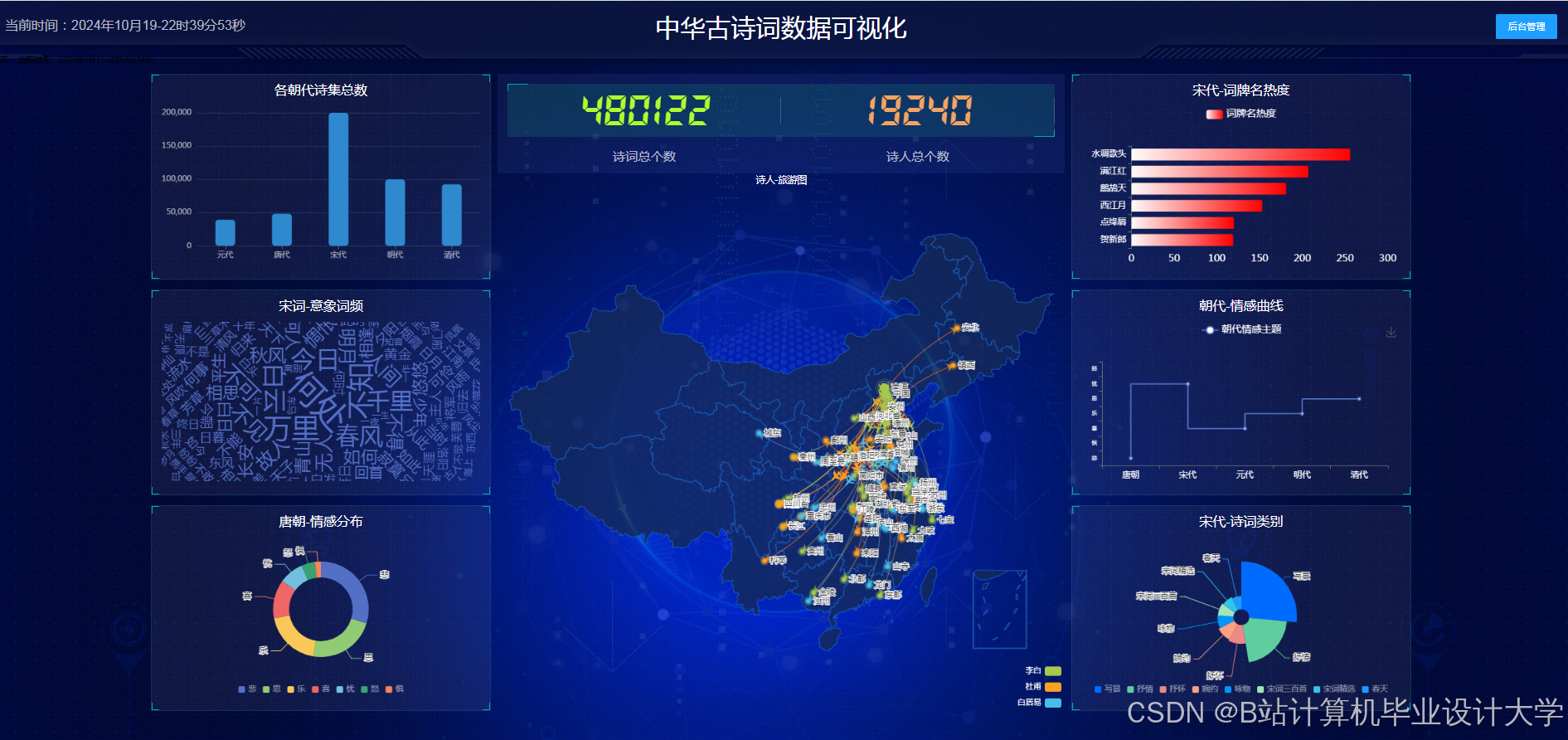
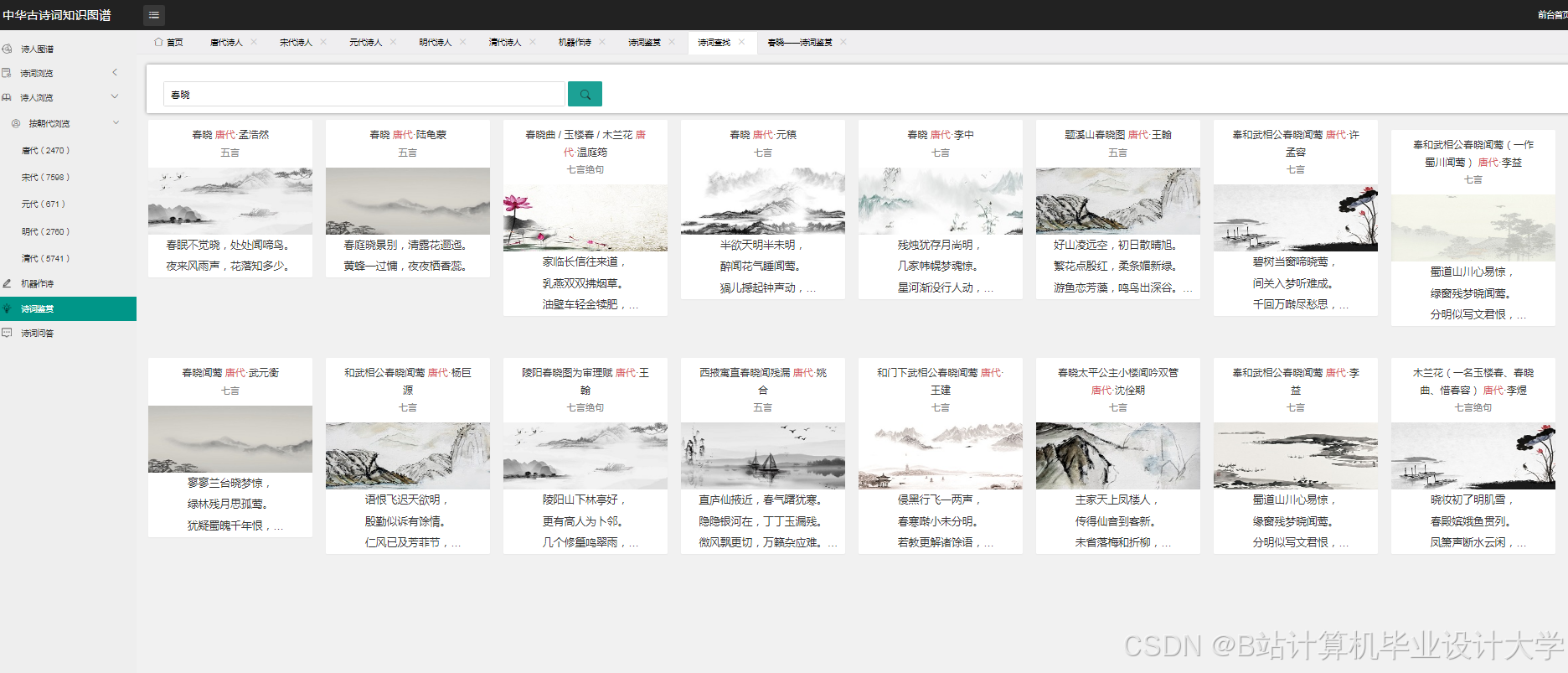
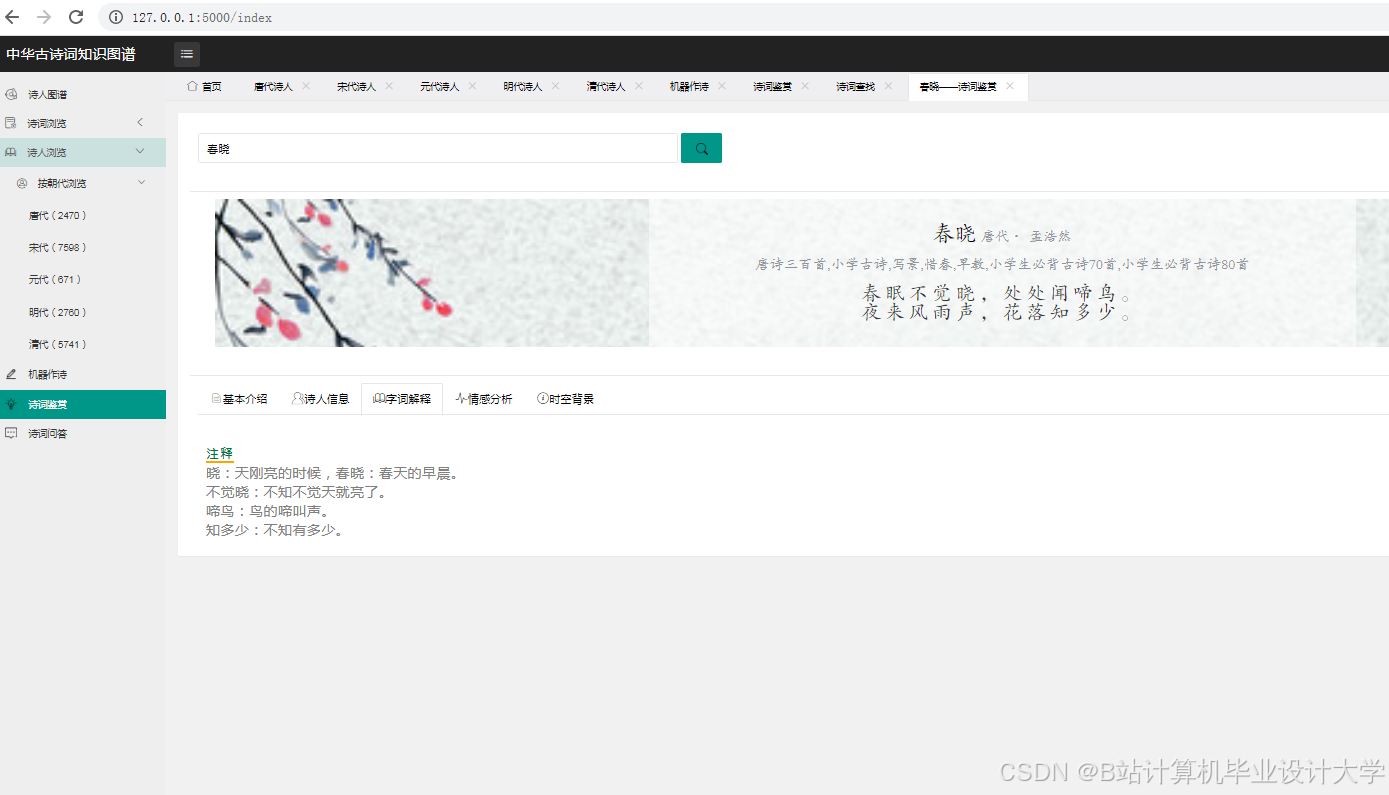
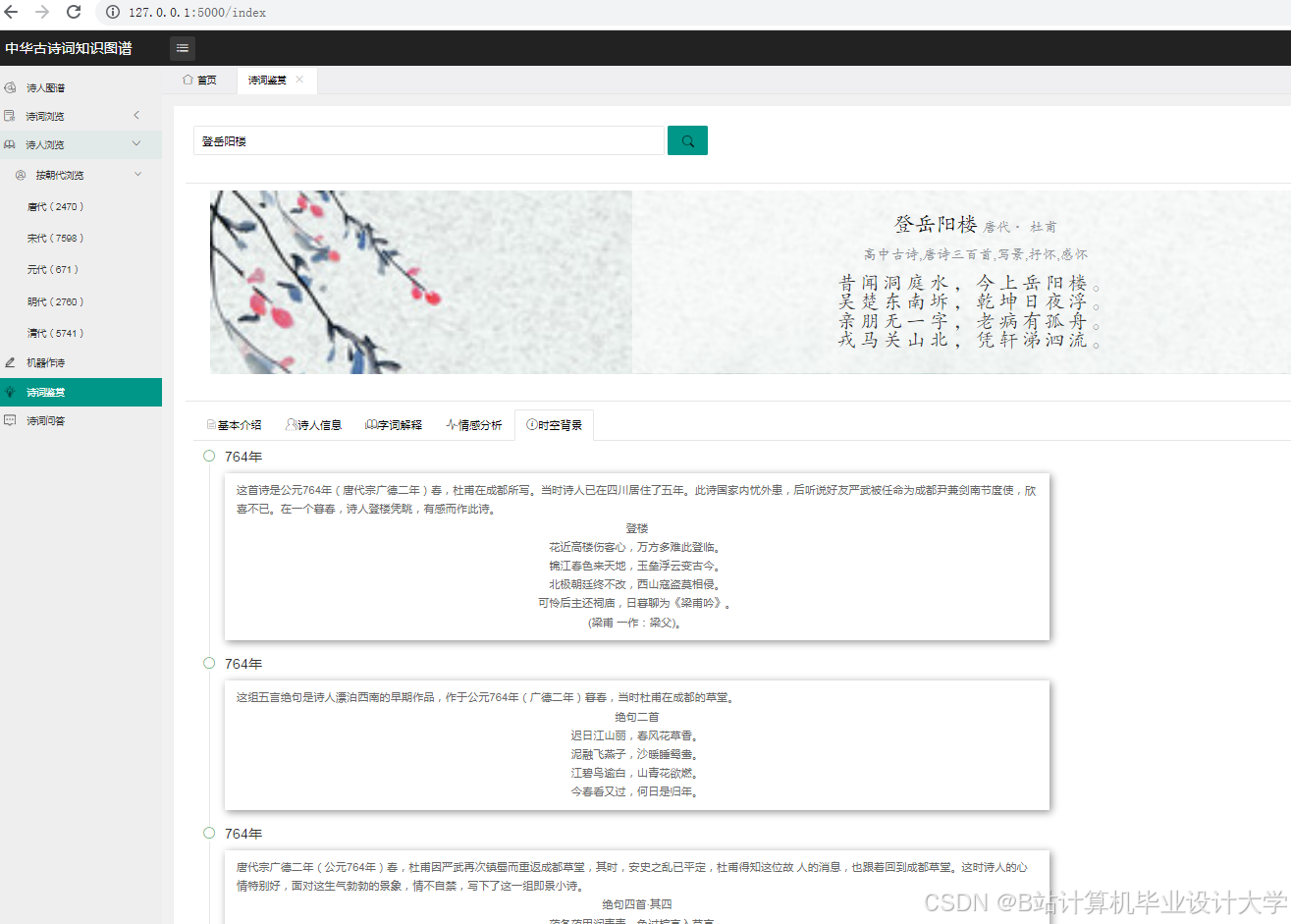
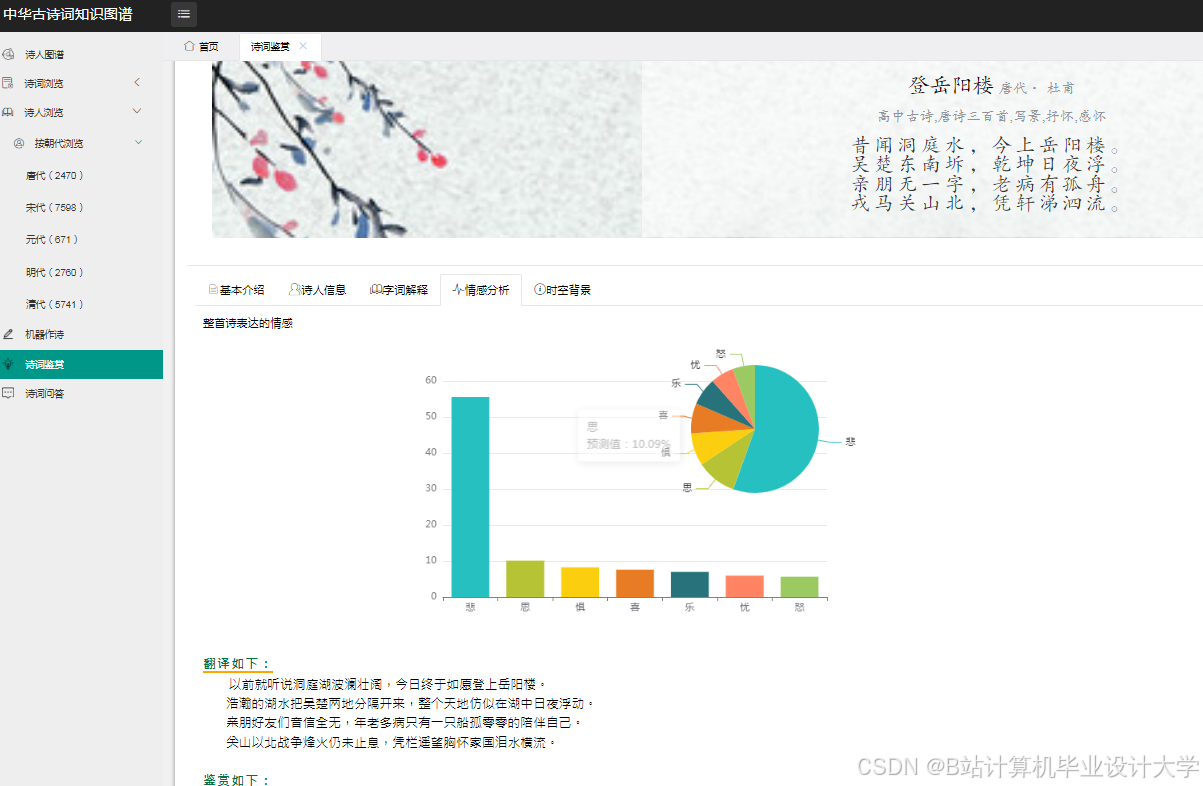
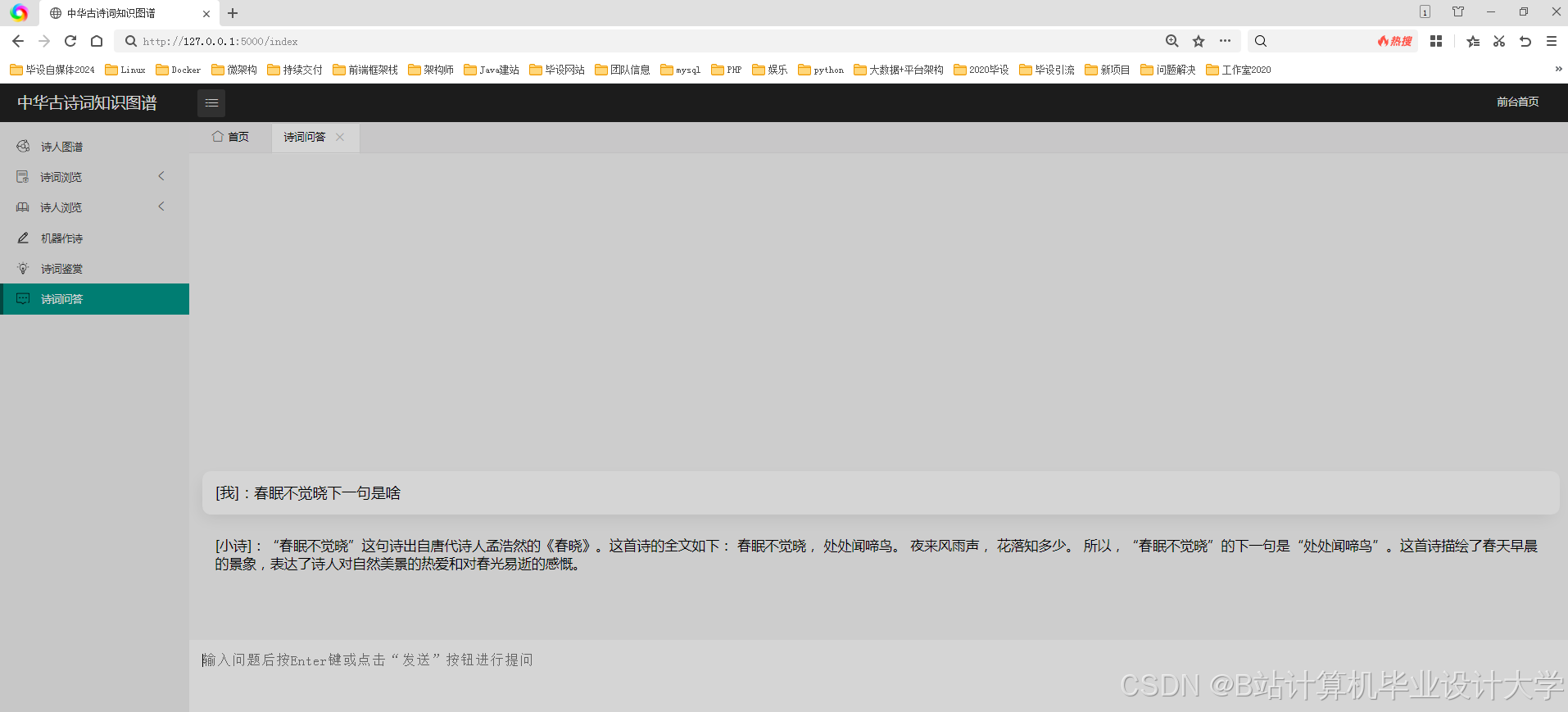
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献272条内容
已为社区贡献272条内容

所有评论(0)