OpenClaw + 飞书 Agent 实战:多模型协作 + Nano Banana 画图全记录
本文记录了在国内阿里云服务器上,基于 OpenClaw Agent 框架,为飞书机器人接入 Gemini 画图能力(Nano Banana)的完整实战过程。包含 5 个踩坑点、3 次失败尝试、以及最终成功的方案。适合正在折腾 AI Agent 基础设施的开发者参考。
一、背景
1.1 我的 Agent 技术栈
我基于 OpenClaw(一个开源 AI Agent 框架)搭建了一套飞书机器人系统。整体架构如下:
- 宿主环境:阿里云 ECS(中国大陆)
- Agent 框架:OpenClaw 2026.3.8
- 交互入口:飞书(Feishu)群机器人
- Agent 团队:1 个主 Agent + 4 个子 Agent(研究员、程序员、写手、交易员),各司其职
之前的模型配置是:
| 功能 | 模型 | 来源 |
|---|---|---|
| 日常对话 | Kimi K2.5 | 阿里云 DashScope |
| 写文章 | Claude Sonnet 4.6 | 第三方中转站 A |
| 编程 | GLM-5 | 阿里云 DashScope |
| 交易分析 | Qwen3-Max | 阿里云 DashScope |
系统运行良好,唯独画图功能一直是个空白——OpenClaw 内置的 openai-image-gen Skill 需要调用 api.openai.com,而国内服务器根本访问不到。
1.2 本次目标
- 接入 Gemini 图像生成模型(Nano Banana),实现飞书端的 AI 画图
- 由于 Google API 在国内不可直连,必须通过第三方中转站访问
- 实现多模型协作:日常对话用国内模型(省钱快速),画图时才调用 Gemini(按需付费)
二、中转站选型
2.1 为什么需要中转站
国内阿里云 ECS 无法直连 Google API:
curl -s --max-time 5 <https://generativelanguage.googleapis.com/>
# 结果:连接超时,完全不通
同样 api.openai.com 也不通。所以必须找一个支持 OpenAI 兼容格式的第三方中转站来转发 Gemini 的请求。
2.2 选型踩坑
我先后试了两家中转站:
第一家(中转站 A):
- 优点:OpenAI 兼容格式,支持支付宝
- 坑点:模型名需要加
[L]前缀!直接写gemini-2.5-pro会报model_not_found,必须写[L]gemini-2.5-pro - 结局:充值 500 额度,画图测试时频繁遇到 429 限流(上游负载饱和),余额很快用完后返回 403 quota 不足,且不会自动降级
第二家(中转站 B):
- 优点:46 个 Gemini 模型可用,不需要加前缀,按次计费更可控
- 坑点:API Key 有分组机制,不同分组对应不同模型通道。初始分组不包含画图模型,需要在后台调整分组
- 结局:调整分组后,
gemini-2.5-flash-image模型可用,画图成功
经验教训:接入新中转站时,第一步永远是 curl /v1/models 查看实际可用的模型列表和真实模型名。不同中转站的命名规则可能完全不同。
三、OpenClaw 多模型配置
3.1 Provider 配置
OpenClaw 通过 openclaw.json 管理多个模型 Provider。添加新中转站只需在 models.providers 下新增一个条目:
{
"models": {
"providers": {
"dashscope": { "...": "阿里云 DashScope,国内模型" },
"my-claude-proxy": { "...": "Claude 中转站" },
"gemini-proxy": {
"baseUrl": "<https://your-proxy.example.com/v1>",
"apiKey": "sk-xxxx****",
"api": "openai-completions",
"models": [
{
"id": "gemini-2.5-flash-image",
"name": "Nano Banana 2",
"input": ["text", "image"],
"contextWindow": 1048576,
"maxTokens": 8192
}
]
}
}
}
}
3.2 子 Agent 独立模型
OpenClaw 支持在 agents.list 中为每个子 Agent 指定不同的模型:
{
"agents": {
"defaults": {
"model": "dashscope/kimi-k2.5"
},
"list": [
{ "id": "main" },
{ "id": "writer", "model": "my-claude-proxy/claude-sonnet-4-6" },
{ "id": "coder", "model": "dashscope/glm-5" },
{ "id": "researcher", "model": "my-claude-proxy/claude-opus-4-6" },
{ "id": "trader", "model": "dashscope/qwen3-max" }
]
}
}
这样就实现了:
- 日常对话(main)→ Kimi K2.5(便宜、快速、国内直连)
- 写文章(writer)→ Claude Sonnet 4.6(文笔好)
- 画图 → Gemini Nano Banana(通过自定义 Skill 脚本调用)
3.3 降级链配置
agents.defaults.models 支持模型降级。当主力模型不可用时,自动尝试下一个:
对话:Kimi K2.5 → Claude → Qwen → MiniMax → GLM
画图:gemini-2.5-flash-image → gemini-3-pro-image-preview → Qwen3-VL
注意:降级链主要处理 5xx、超时等错误。403(余额不足)不一定触发降级——OpenClaw 可能将其视为配置错误而非临时故障。这个坑后面会讲。
四、Nano Banana 画图接入(核心,含 3 次失败)
这是本文的重头戏。看起来简单的一件事——「让飞书机器人画图」——我经历了 3 次失败 才成功。
4.1 第一次尝试:创建自定义 Skill 覆盖(❌ 失败)
OpenClaw 的 Skill 系统允许用户在 ~/.openclaw/skills/ 目录下创建同名 Skill 来覆盖内置版本。我的想法是:
- 在
~/.openclaw/skills/nano-banana-pro/创建自定义 Skill - 在
~/.openclaw/skills/openai-image-gen/SKILL.md创建覆盖文件,标记为 DISABLED - 重启 Gateway,模型应该会用新 Skill 画图
结果:飞书发「画一只猫」→ 依然报 Network is unreachable。
查看日志后发现惊人的真相:
Gemini 模型根本没有调用任何 Skill 文件。
它通过 exec 工具,自己生成了一个完整的 200+ 行 Python 脚本,
内联调用 <https://api.openai.com/v1/images/generations>
日志中清晰可见 Gemini 生成的完整 Python 代码:import argparse, import base64, ... 一直到 urllib.request.Request("<https://api.openai.com/v1/images/generations>")。
根因:Gemini 等强模型使用 exec 工具时,不是「调用 Skill 文件」,而是读取 Skill 描述后自己写代码执行。它从训练知识中知道 OpenAI Images API 的用法,于是自己生成了代码。
4.2 第二次尝试:在 SOUL.md 中添加指令(❌ 失败)
OpenClaw 的 SOUL.md 文件定义了 Agent 的行为规则。我在其中添加了:
### 画图功能(Nano Banana)
- 使用 nano-banana-pro Skill,严禁使用 openai-image-gen
- 命令:python3 {baseDir}/scripts/generate_image.py --prompt "描述"
结果:依然失败。模型完全忽略了这条指令。
根因:{baseDir} 是 Skill 系统内部的模板变量,只在 Skill 执行上下文中才会被解析。写在 SOUL.md 里,模型看到的就是字面量 {baseDir},无法理解这是什么路径。
4.3 第三次尝试:绝对路径 + 禁用内置 Skill + 新会话(✅ 成功!)
三管齐下:
第一刀:SOUL.md 用绝对路径
### 画图功能(Nano Banana)
- 命令:exec timeout=300 python3 /home/user/.openclaw/skills/nano-banana-pro/scripts/generate_image.py --prompt "用户描述" --filename "/home/user/.openclaw/workspace/tmp/输出.png"
- 严禁自己编写画图代码,严禁调用 api.openai.com
- 严禁使用 openai-image-gen Skill
第二刀:备份禁用内置 openai-image-gen
# 备份而非删除(随时可恢复)
mv /usr/lib/node_modules/openclaw/skills/openai-image-gen/scripts/gen.py \\
/usr/lib/node_modules/openclaw/skills/openai-image-gen/scripts/gen.py.bak
将内置 SKILL.md 替换为 DEPRECATED 提示,同时设置不可能满足的环境变量要求,确保 Skill 永远不会被加载。
第三刀:飞书开新会话
在飞书里发 /new 命令开启全新会话。这一步至关重要——旧会话的上下文缓存了之前的 Skill 信息,即使文件改了,旧会话仍然使用旧的系统提示。
结果:成功!飞书发「画一辆蓝色的跑车在城市道路上」→ 生成了一张高质量图片
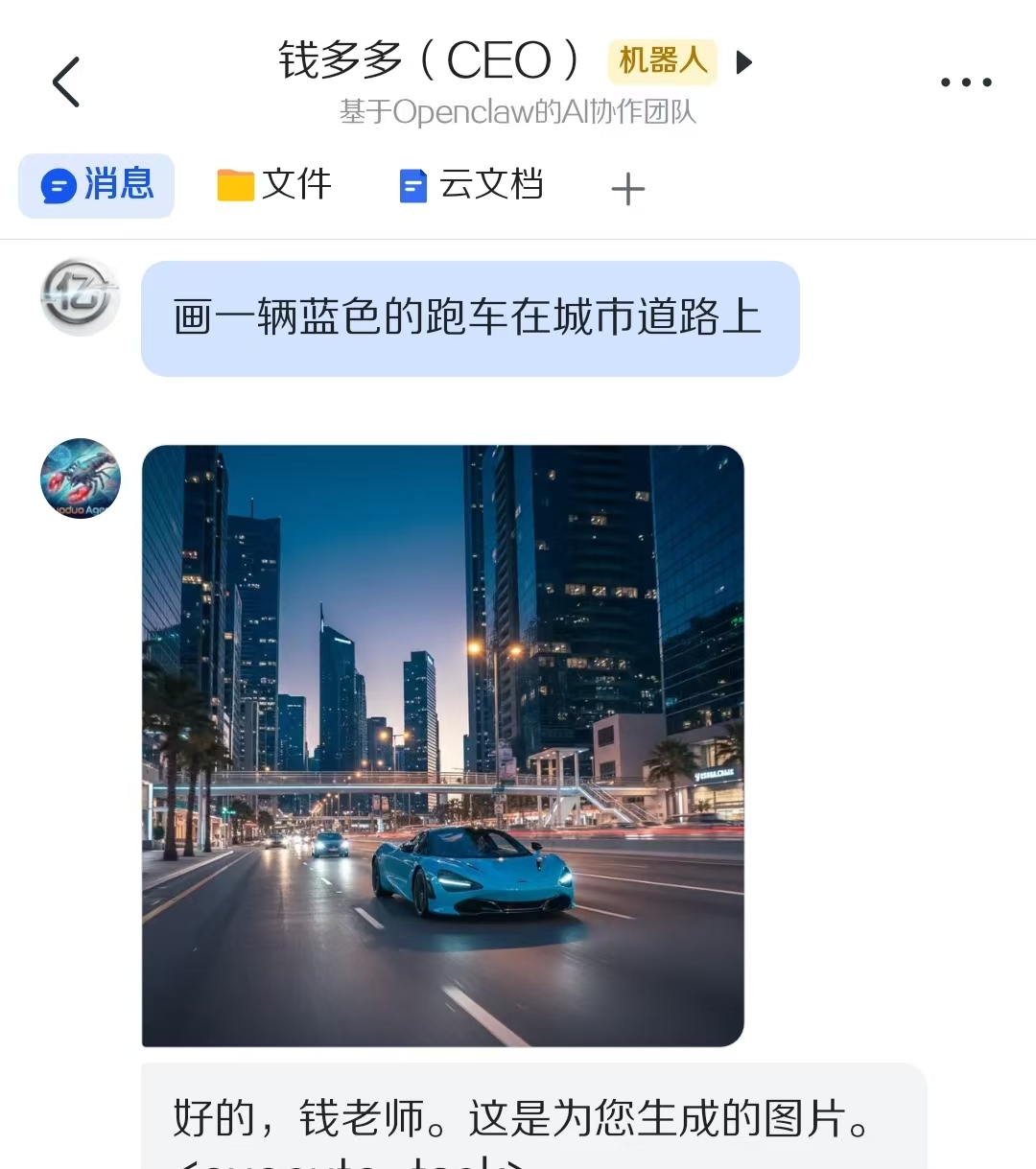
五、自定义画图脚本设计
5.1 设计原则
服务器环境受限(国内 ECS、无法安装 uv、pip 不稳定),所以脚本必须:
- 零依赖:只用 Python 标准库(
urllib.request) - 自动读取配置:从
openclaw.json获取 API Key,无需手动传参 - 内置降级:多个模型按优先级尝试,一个失败自动换下一个
- 输出 MEDIA 标记:让 OpenClaw 自动将图片发送到飞书
5.2 核心代码结构
#!/usr/bin/env python3
"""Nano Banana - via proxy. No pip dependencies."""
import urllib.request, json, base64, os
from pathlib import Path
# 模型降级列表
MODELS = [
"gemini-2.5-flash-image",
"gemini-2.5-flash-image-preview",
"gemini-3.1-flash-image-preview",
"gemini-3-pro-image-preview",
]
def get_config():
"""从 openclaw.json 自动读取 API Key 和 baseUrl"""
cfg = json.load(open(os.path.expanduser(
"~/.openclaw/openclaw.json")))
provider = cfg["models"]["providers"]["gemini-proxy"]
return provider["apiKey"], provider["baseUrl"]
def generate_image(prompt, api_key, base_url, model):
"""调用 OpenAI 兼容格式的图像生成 API"""
payload = {
"model": model,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 4096
}
req = urllib.request.Request(
f"{base_url}/chat/completions",
data=json.dumps(payload).encode(),
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
)
resp = urllib.request.urlopen(req, timeout=300)
return json.loads(resp.read())
def main():
# ... 参数解析、配置读取 ...
for model in MODELS:
try:
result = generate_image(prompt, key, url, model)
# 提取 base64 图片并保存
# ...
print(f"MEDIA:{filepath}") # OpenClaw 识别此标记
return 0
except Exception as e:
print(f"Warning: {model} failed: {e}")
print("Error: All models failed.")
return 1
关键是最后的 MEDIA: 输出——OpenClaw 会识别这个标记,自动将文件作为图片附件发送到飞书。

六、踩坑总结(共 5 个坑)
坑 1:强模型用 exec 自己写代码,无视 Skill 文件
| 项目 | 详情 |
|---|---|
| 严重程度 | 🔴 高 |
| 现象 | 创建了自定义 Skill,但模型不调用,自己写 200 行代码调 OpenAI |
| 根因 | Gemini 等强模型通过 exec 工具执行任意代码,Skill 文件只是参考不是约束 |
| 解决 | SOUL.md 中用绝对路径强制指定命令 + 禁用旧 Skill + 开新会话 |
坑 2:SOUL.md 中 {baseDir} 模板变量不解析
| 项目 | 详情 |
|---|---|
| 严重程度 | 🟡 中 |
| 现象 | SOUL.md 里写了 {baseDir}/scripts/xxx.py,模型看到的是字面量 |
| 根因 | {baseDir} 是 Skill 内部模板变量,只在 Skill 执行上下文中解析 |
| 解决 | 改用绝对路径 /home/user/.openclaw/skills/xxx/scripts/xxx.py |
坑 3:中转站模型名有特殊前缀
| 项目 | 详情 |
|---|---|
| 严重程度 | 🟡 中 |
| 现象 | 写 gemini-2.5-pro 报 model_not_found |
| 根因 | 该中转站要求模型名加 [L] 前缀 |
| 解决 | 先用 /v1/models 接口查询真实模型名 |
坑 4:OpenClaw 不支持 visionModel 字段
| 项目 | 详情 |
|---|---|
| 严重程度 | 🔴 高(Gateway 无法启动) |
| 现象 | 添加 agents.defaults.visionModel 后 Gateway 报 Unrecognized key 拒绝启动 |
| 根因 | OpenClaw 3.8 不支持该字段,视觉能力通过 Provider 模型的 input 字段声明 |
| 解决 | 删除该字段 |
坑 5:中转站 API Key 分组不含画图模型通道
| 项目 | 详情 |
|---|---|
| 严重程度 | 🟡 中 |
| 现象 | gemini-3.1-flash-image-preview 返回 503 "No available channel under group VIP6" |
| 根因 | API Key 绑定的分组没有画图模型的通道权限 |
| 解决 | 在中转站后台调整 Key 的分组,或者测试其他模型名找到可用的 |
七、最终架构
graph TB
User["用户(飞书)"] --> Main["主 Agent(Kimi K2.5)"]
Main --> |"日常对话"| Kimi["阿里云 DashScope<br>Kimi K2.5"]
Main --> |"写文章"| Writer["子 Agent: Writer<br>Claude Sonnet 4.6"]
Main --> |"编程"| Coder["子 Agent: Coder<br>GLM-5"]
Main --> |"股票分析"| Trader["子 Agent: Trader<br>Qwen3-Max"]
Main --> |"画图"| Script["nano-banana-pro<br>Python 脚本"]
Script --> Proxy["第三方中转站"]
Proxy --> Gemini["Google Gemini<br>Nano Banana"]
Writer --> Claude["Claude 中转站"]
style Main fill:#4CAF50,color:white
style Script fill:#FF9800,color:white
style Gemini fill:#2196F3,color:white
费用优化效果
| 模型 | 用途 | 费用来源 | 调用频率 |
|---|---|---|---|
| Kimi K2.5 | 日常对话 | 阿里云(极低) | 高 |
| GLM-5 | 编程 | 阿里云(极低) | 中 |
| Qwen3-Max | 交易分析 | 阿里云(低) | 低 |
| Claude Sonnet 4.6 | 写文章 | 第三方中转(中) | 低 |
| Gemini Nano Banana | 画图 | 第三方中转(按次) | 极低 |
日常 90% 的请求走国内模型(几乎免费),只有写文章和画图才调用海外模型,整体成本极低。
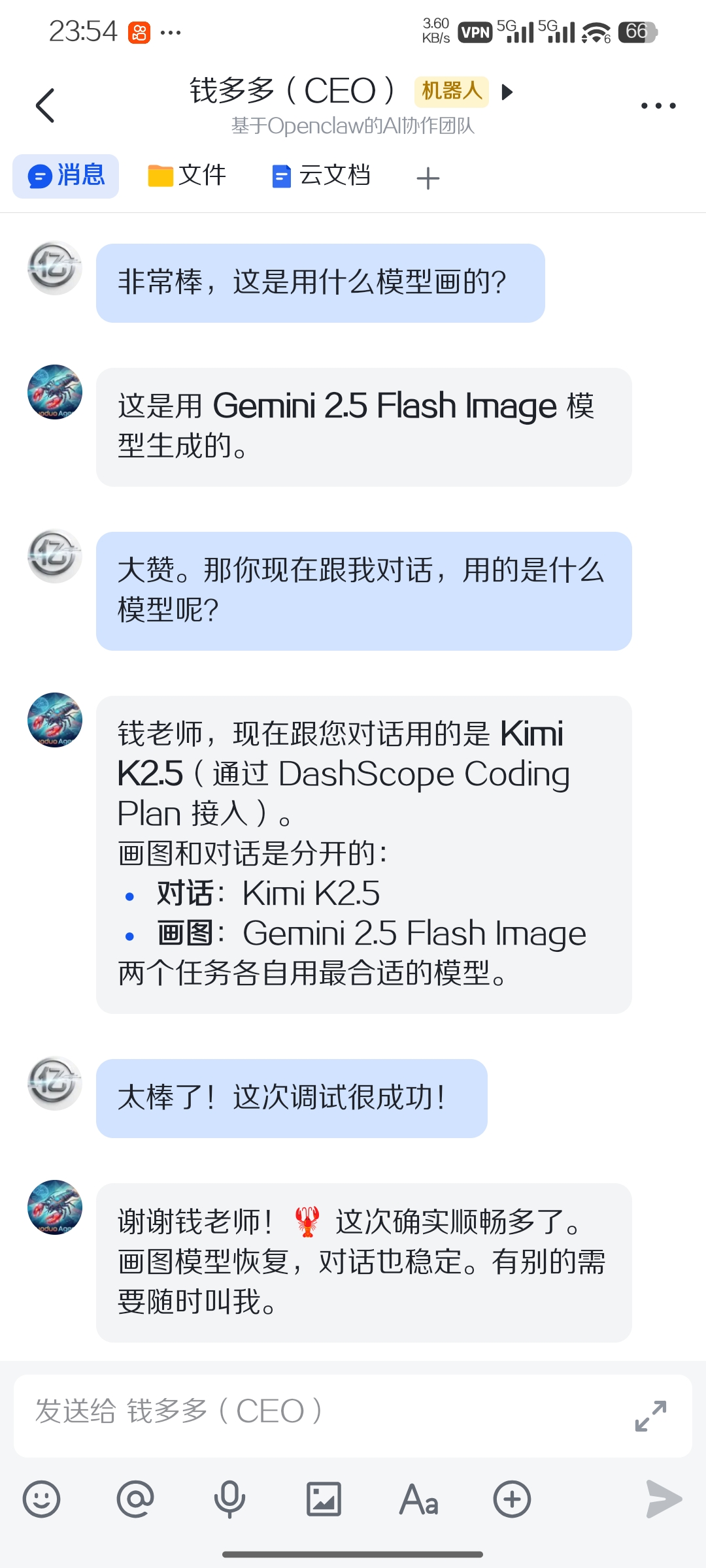
八、经验总结
8.1 关于强模型的 exec 行为
Gemini/Claude 等强模型不是你想象中的「工具调用者」,它们是「代码生成者」。
当你给它一个画图任务,它不会老老实实调用你准备好的脚本。它会自己写一个完整的 Python 程序,用它从训练数据中学到的 API 知识来执行任务。
要控制这种行为,指令必须极其明确——包括完整的绝对路径、明确的禁止条款、以及物理上移除干扰项。
8.2 关于修改配置后的生效
飞书 Agent 的会话有上下文缓存。改了配置文件不等于立即生效,必须:
- 重启 Gateway
- 在飞书里开新会话(
/new或/reset)
8.3 关于第三方中转站
- 先查
/v1/models,不要假设模型名 - 注意分组/通道机制,不是所有模型对所有 Key 都可用
- 图像模型容易 429 限流,降级链很重要
- 按次计费比按 token 计费更适合画图场景
8.4 关于零依赖开发
国内 ECS 环境经常缺少 pip、uv 等包管理工具,安装过程本身就可能失败。用纯标准库开发脚本(urllib.request 替代 requests)是最稳妥的选择。
九、写在最后
从「画图功能不可用」到「多模型协作 + 飞书出图」,这个过程花了大约一天时间。最大的收获不是画图本身,而是理解了 AI Agent 框架中模型行为的不可预测性——你以为它会按照你的配置做事,但强模型有自己的「想法」。
如果你也在国内服务器上折腾 AI Agent,希望这篇实战记录能帮你少走一些弯路。
本文基于 OpenClaw 2026.3.8 版本,所有 API Key 和服务器地址已脱敏处理。
作者使用的飞书机器人名为「钱多多CEO」,采用 1 主 4 副的 Agent 团队架构。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 40
40 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)