中草药智能识别与科普系统
·
中草药智能识别与科普系统
1. 项目背景与目标
1.1 背景
中草药作为传统医学的重要组成部分,其种类繁多,形态各异。对于非专业人士而言,准确识别中草药不仅困难,而且容易混淆。随着计算机视觉和深度学习技术的发展,利用人工智能辅助中草药识别成为可能。
1.2 项目目标
本项目旨在构建一个高精度、低延时、多终端的中草药智能识别系统。
- 核心能力:通过拍摄或上传图片,毫秒级返回中草药名称、置信度及详细百科信息。
- 多端覆盖:提供 Web 管理端供管理员进行数据维护和模型训练,提供移动端 App 供普通用户随身使用。
- 闭环生态:实现从“数据采集 -> 模型训练 -> 终端识别 -> 知识科普”的全流程闭环。
2. 系统架构设计
2.1 总体架构
系统采用经典的 B/S (Browser/Server) 和 C/S (Client/Server) 混合架构。
- 客户端层:
- Mobile App (UniApp):用户侧应用,负责图像采集、展示识别结果和个人中心管理。
- Web Dashboard (Vue3):管理侧应用,负责数据可视化、知识库管理和模型训练监控。
- 服务层 (Backend):
- API 网关 (Django):处理 HTTP 请求,进行权限验证和路由分发。
- 业务逻辑:包含用户管理、百科查询、历史记录管理等。
- AI 推理引擎:集成 PyTorch 和 Ultralytics,加载训练好的模型进行实时推理。
- 数据层:
- 关系型数据库 (SQLite/MySQL):存储业务数据。
- 文件存储:存储用户上传的图片、模型权重文件 (.pt) 和数据集。
2.2 技术栈详细说明
| 模块 | 技术组件 | 版本/说明 |
|---|---|---|
| 算法核心 | PyTorch | 深度学习框架,支持动态计算图 |
| Ultralytics YOLOv8 | SOTA 目标检测/分类模型,速度快精度高 | |
| ResNet (18/34/50) | 经典的残差网络,用于对比实验 | |
| 后端服务 | Django | v5.2, Python Web 框架 |
| Django Rest Framework | 构建 RESTful API 的强大工具 | |
| JWT / Token Auth | 无状态身份认证机制 | |
| 前端 Web | Vue 3 | v3.5, 使用 Composition API |
| TypeScript | 强类型语言,提高代码健壮性 | |
| Element Plus | v2.12, 企业级 UI 组件库 | |
| Pinia | v3.0, 新一代状态管理库 | |
| ECharts | v6.0, 数据可视化图表 | |
| 移动端 | UniApp | 基于 Vue 的跨平台框架 (iOS/Android/小程序) |
2.3 目录结构
program/
├── algorithm/ # 算法相关
│ ├── dataset/ # 数据集 (YOLO格式: images/labels)
│ └── ...
├── system/
│ ├── backend/ # Django 后端
│ │ ├── api/ # 核心应用 (Views, Models, Serializers)
│ │ ├── herbal_system/ # 项目配置 (Settings, URLs)
│ │ ├── models/ # 训练好的模型文件 (.pt)
│ │ └── manage.py
│ ├── frontend/ # Vue3 Web 端
│ │ ├── src/ # 源码 (Views, Components, Store)
│ │ └── vite.config.ts
│ └── mobile/ # UniApp 移动端
│ ├── pages/ # 页面文件
│ └── static/ # 静态资源
└── explaination/ # 项目文档
└── images/ # 文档配图
3. 核心算法与数据分析
本系统采用先进的计算机视觉算法进行模型训练,以下结合训练过程中的可视化图表进行详细解读。
3.1 数据集分布分析
在训练开始前,我们对采集的中草药数据集进行了详细的统计分析,以确保数据的均衡性。
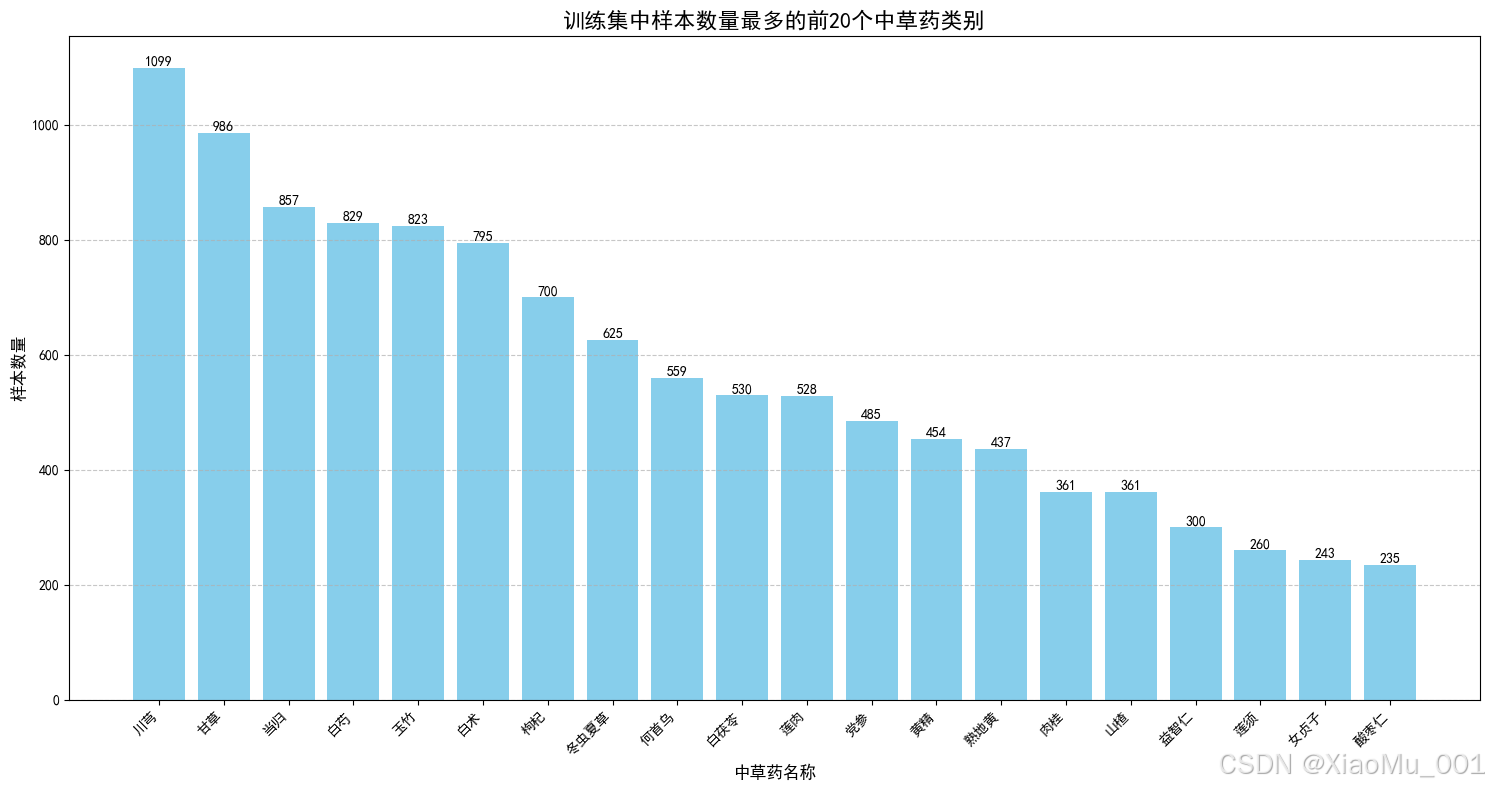
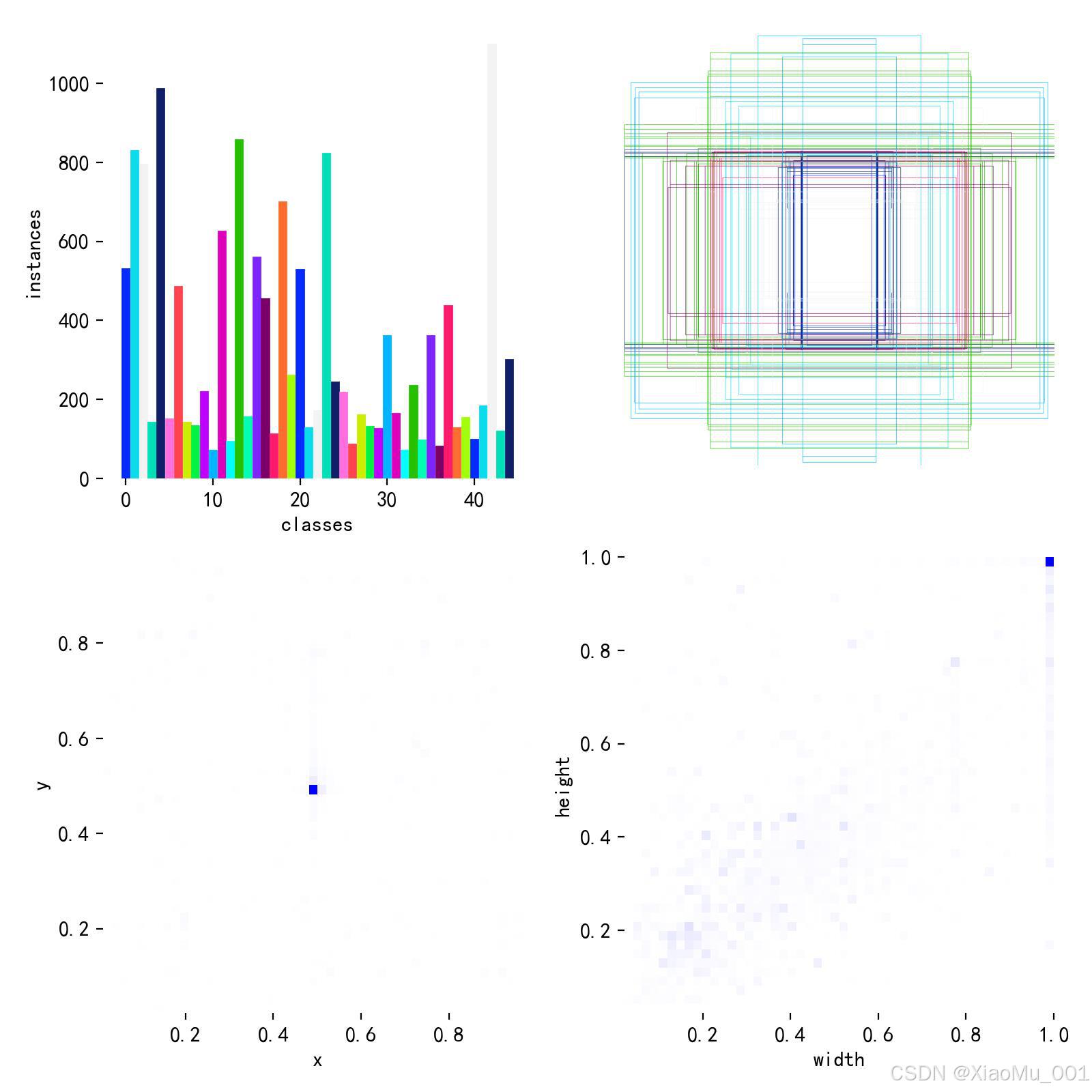
- 图表解读:
- 左上 (Classes):展示了不同中草药类别(如人参、当归等)的样本数量分布。柱状图越平齐,说明数据越均衡,有利于模型公平地学习每一类特征。
- 左下 (Labels):展示了所有标注框在归一化图像坐标系中的中心点分布。密集区域表明目标物体在图像中出现的常见位置(通常居中)。
- 右侧 (Box Size):展示了标注框的宽 (Width) 和高 (Height) 的分布。这有助于了解目标物体的大小变化范围,指导 Anchor Box(锚框)的设置或验证无锚框算法的适应性。
3.2 训练过程监控
通过 TensorBoard 或 YOLO 内置记录工具,我们追踪了模型在训练周期 (Epochs) 内的各项指标变化。
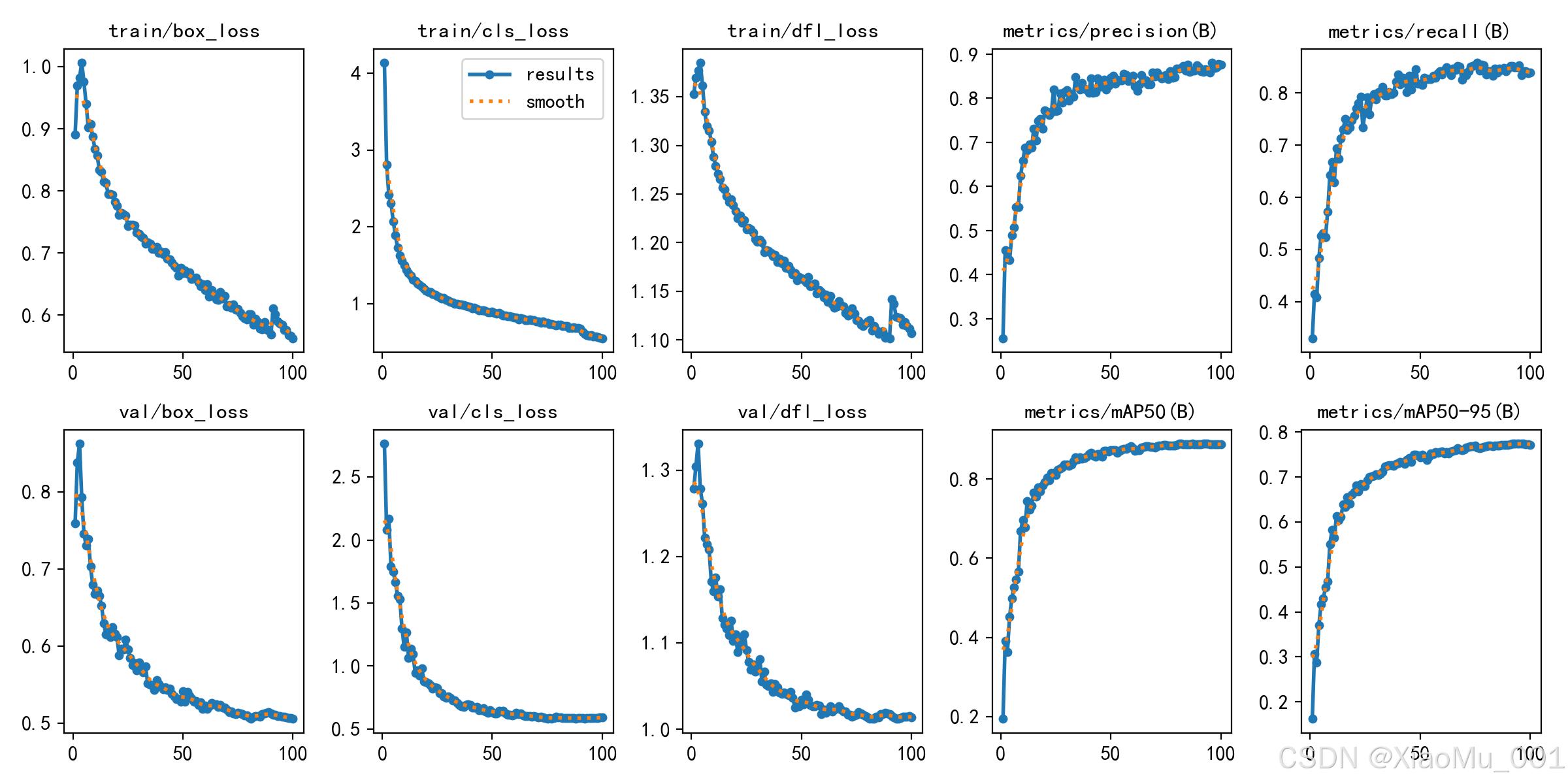
- 图表解读:
- Loss (损失) 曲线:前三列分别代表 Box Loss (边界框定位损失)、Cls Loss (分类概率损失) 和 DFL Loss (分布焦点损失)。随着 Epoch 增加,训练集 (train) 和验证集 (val) 的损失值均呈现显著下降趋势,表明模型正在有效学习。
- Metrics (指标) 曲线:
- Precision (B):准确率,预测为正样本中实际正确的比例。
- Recall (B):召回率,实际正样本中被正确预测的比例。
- mAP50 (B):IoU=0.5 时的平均精度均值,是衡量检测性能的核心指标。曲线快速上升并趋于平稳,说明模型性能达到收敛状态。
3.3 模型性能评估
模型训练完成后,通过混淆矩阵和 PR 曲线对模型在测试集上的表现进行定量评估。
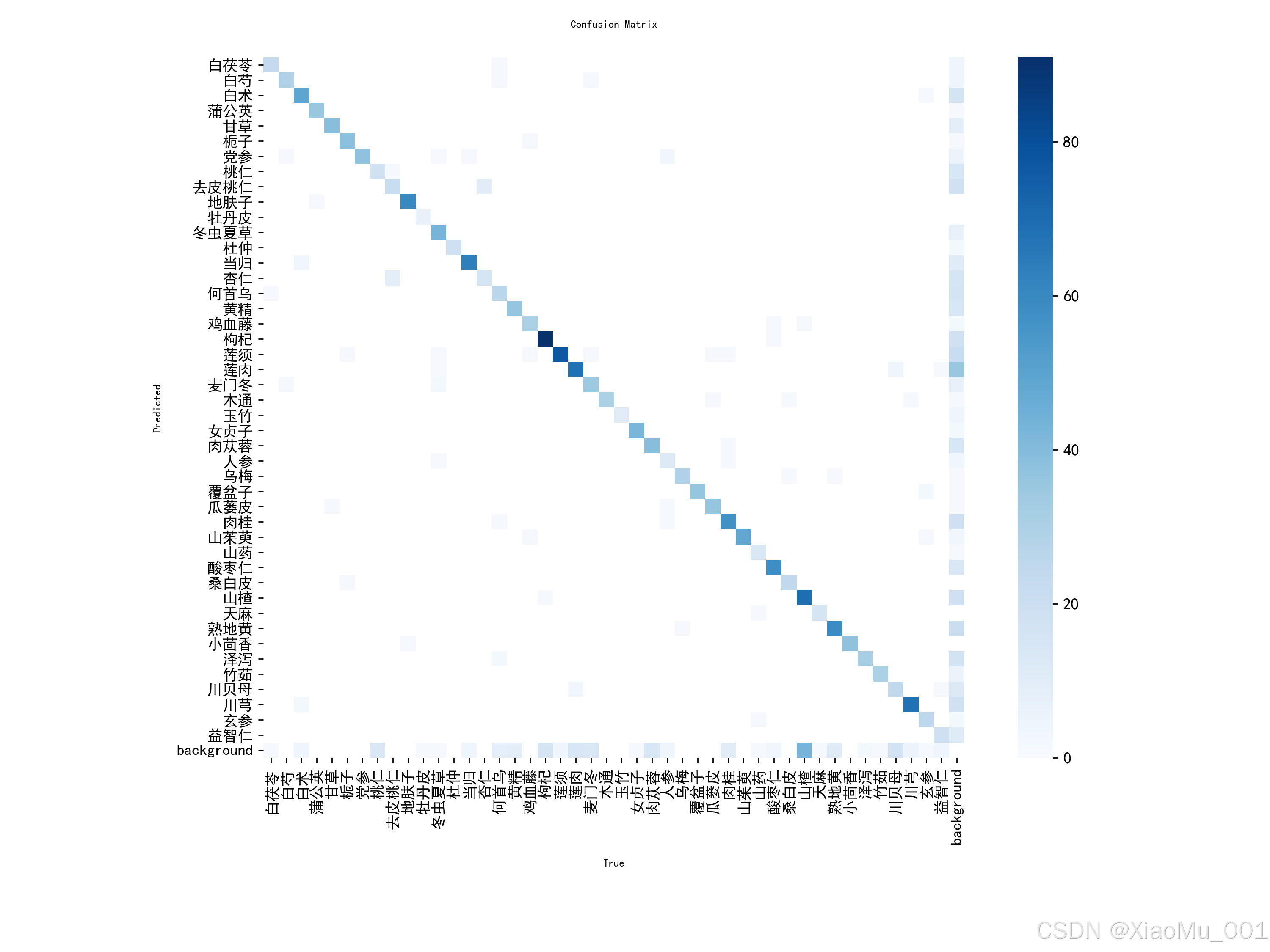
- 图表解读:
- 对角线:颜色最深的对角线方块代表模型预测正确的数量(或比例)。对角线越清晰、颜色越深,说明模型区分不同草药的能力越强。
- 非对角线:代表误判的情况。例如,如果“黄芪”行的“党参”列有颜色,说明模型容易将黄芪误认为党参。通过分析混淆矩阵,我们可以针对性地补充易混淆类别的样本数据。
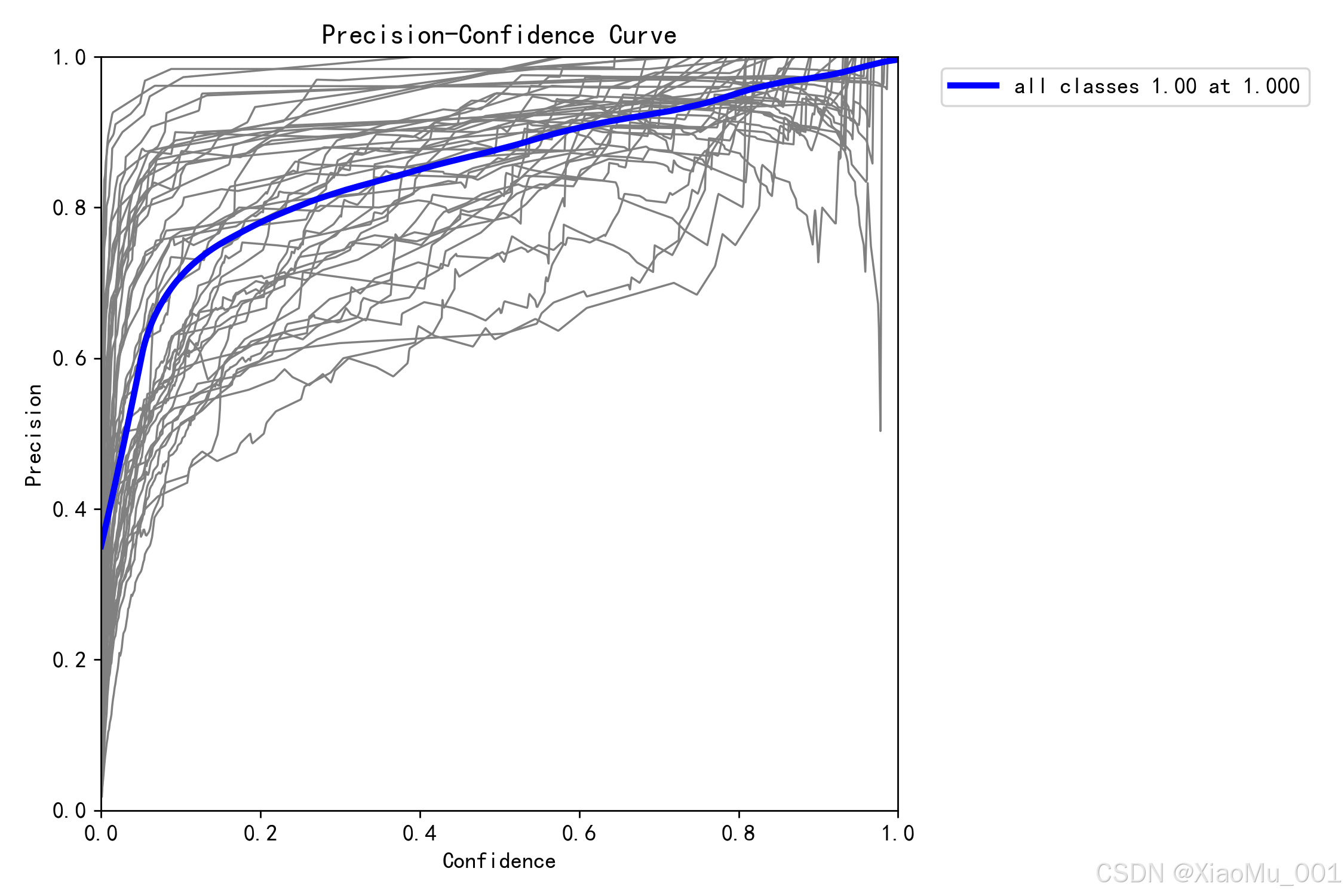
- 图表解读:
- P Curve (Precision-Confidence Curve):展示了在不同置信度阈值 (Confidence Threshold) 下,模型的准确率变化。
- 理想情况下,曲线应尽可能靠近右上角(即在所有置信度下都保持高准确率)。图中标注的
all classes 1.00 at 0.963表示在置信度阈值设为 0.963 时,所有类别的平均准确率达到了 1.00(最佳状态)。
4. 后端系统设计
4.1 数据模型 (Models)
后端采用 Django ORM 定义数据结构:
HerbInfo: 知识库核心表。包含字段:name,category,image,properties(性味),efficacy(功效),usage(用法)。RecognitionRecord: 识别流水表。记录user(用户),image(原图),predicted_class(结果),confidence(置信度)。TrainingRecord: 训练任务表。记录model_name,status,epoch_data(训练曲线数据)。
4.2 API 接口与异步任务
- RESTful API: 使用 DRF 构建,提供
/api/predict/(识别),/api/herb-info/(知识库) 等标准接口。 - 异步训练: 由于深度学习训练耗时较长,后端采用多线程技术异步执行
train_task,并通过数据库实时更新训练进度,避免阻塞 Web 请求。
5. 系统功能界面详解
5.1 移动端 App (用户侧)
移动端基于 UniApp 开发,旨在为普通用户提供便捷的识别和查询服务。
5.1.1 用户认证与个人中心
- 登录注册:提供简洁的账号密码登录/注册界面,确保用户数据(如识别历史)的私密性。
- 个人中心:用户可在此管理个人资料,查看账号状态,是应用的个人设置入口。
5.1.2 首页与导航
- 首页设计:采用卡片式布局,顶部轮播图展示热门草药或系统公告。
- 功能导航:底部 TabBar 清晰划分了“首页”、“知识”、“识别”、“记录”、“我的”五大核心板块,方便用户快速切换。
5.1.3 智能识别功能
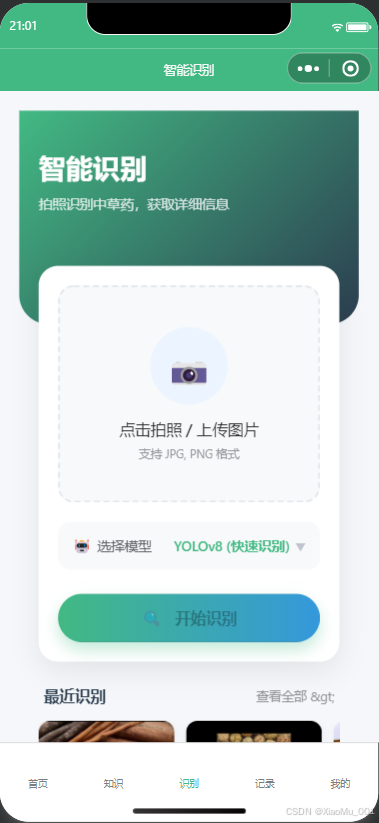
- 核心交互:用户点击中间的相机图标,可选择“拍照”或“从相册选择”图片。
- 实时反馈:图片上传后,系统自动调用后端 API 进行推理,并在页面下方展示识别结果(草药名称)及置信度。
5.1.4 知识库与历史记录
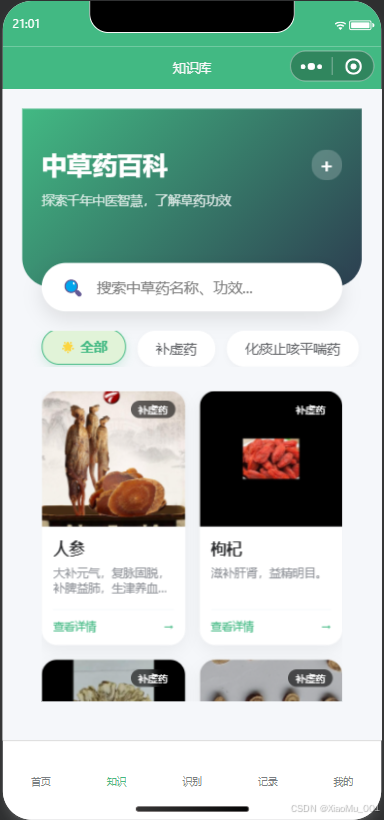
- 知识库:以列表形式展示系统收录的所有中草药,支持点击查看详情(性味、功效等)。
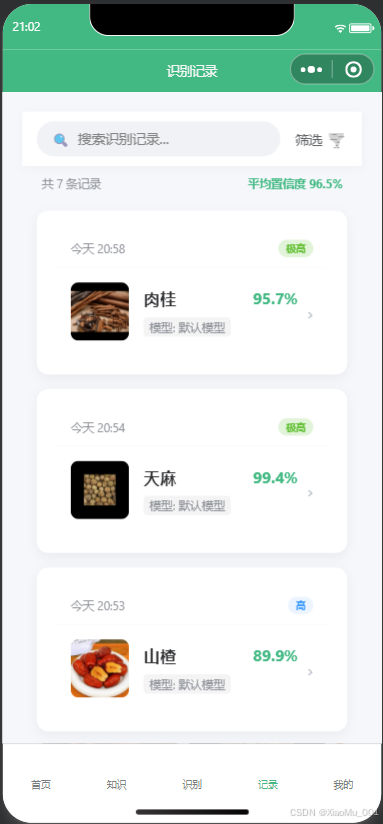
- 识别记录:自动保存用户的每一次识别结果,按时间倒序排列,方便用户随时回溯查看之前的识别历史。
5.2 Web 管理端 (管理员侧)
Web 端基于 Vue3 + Element Plus 开发,提供强大的数据管理和系统监控功能。
5.2.1 系统数据看板
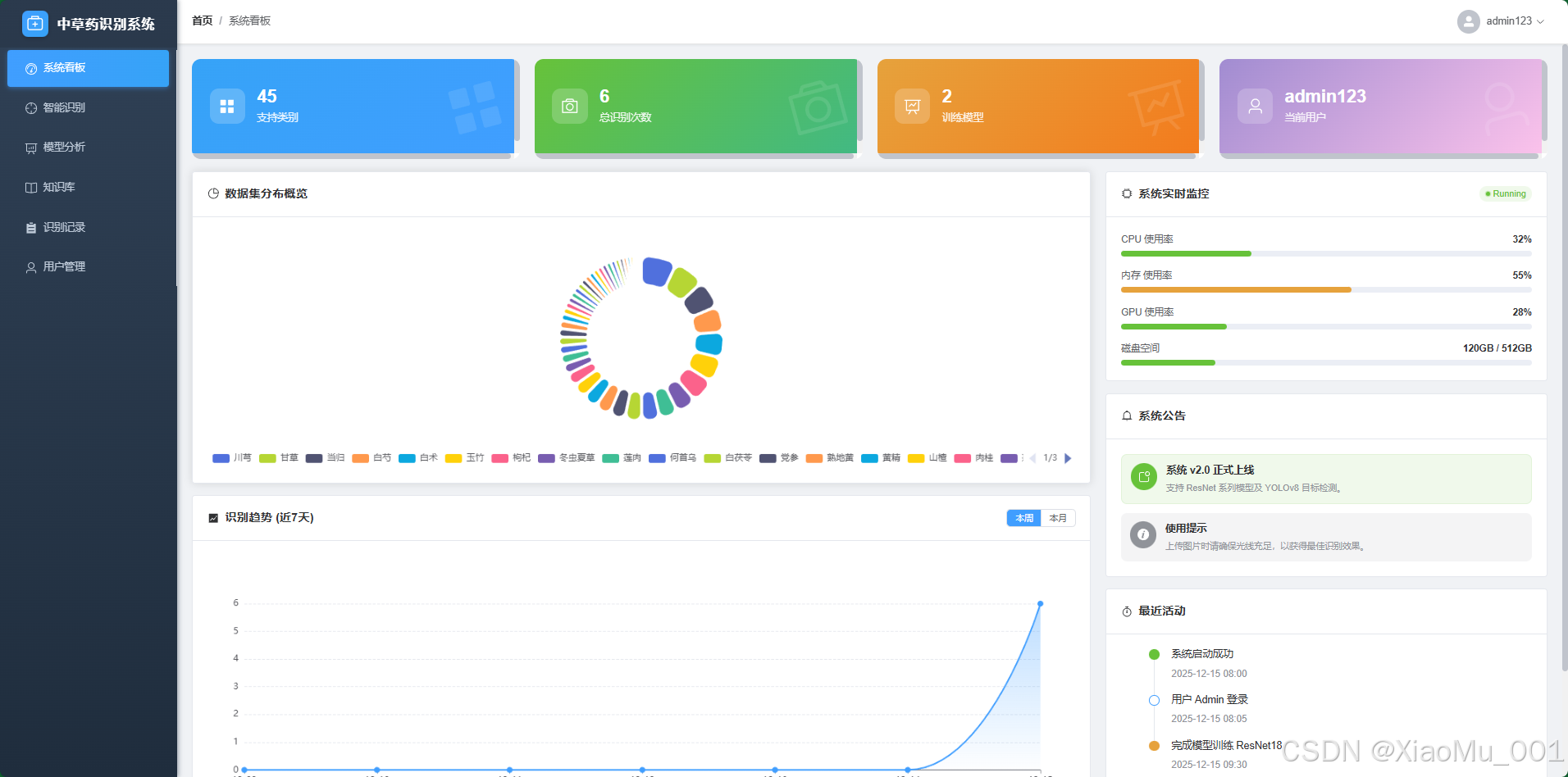
- 数据可视化:集成了 ECharts 图表库。
- 左侧饼图:展示热门草药识别比例,帮助管理员了解用户关注度。
- 底部折线图:展示近七日的系统访问量/识别量趋势,监控系统负载。
- 顶部卡片:实时统计总识别次数、今日新增等关键 KPI。
5.2.2 知识库数据管理
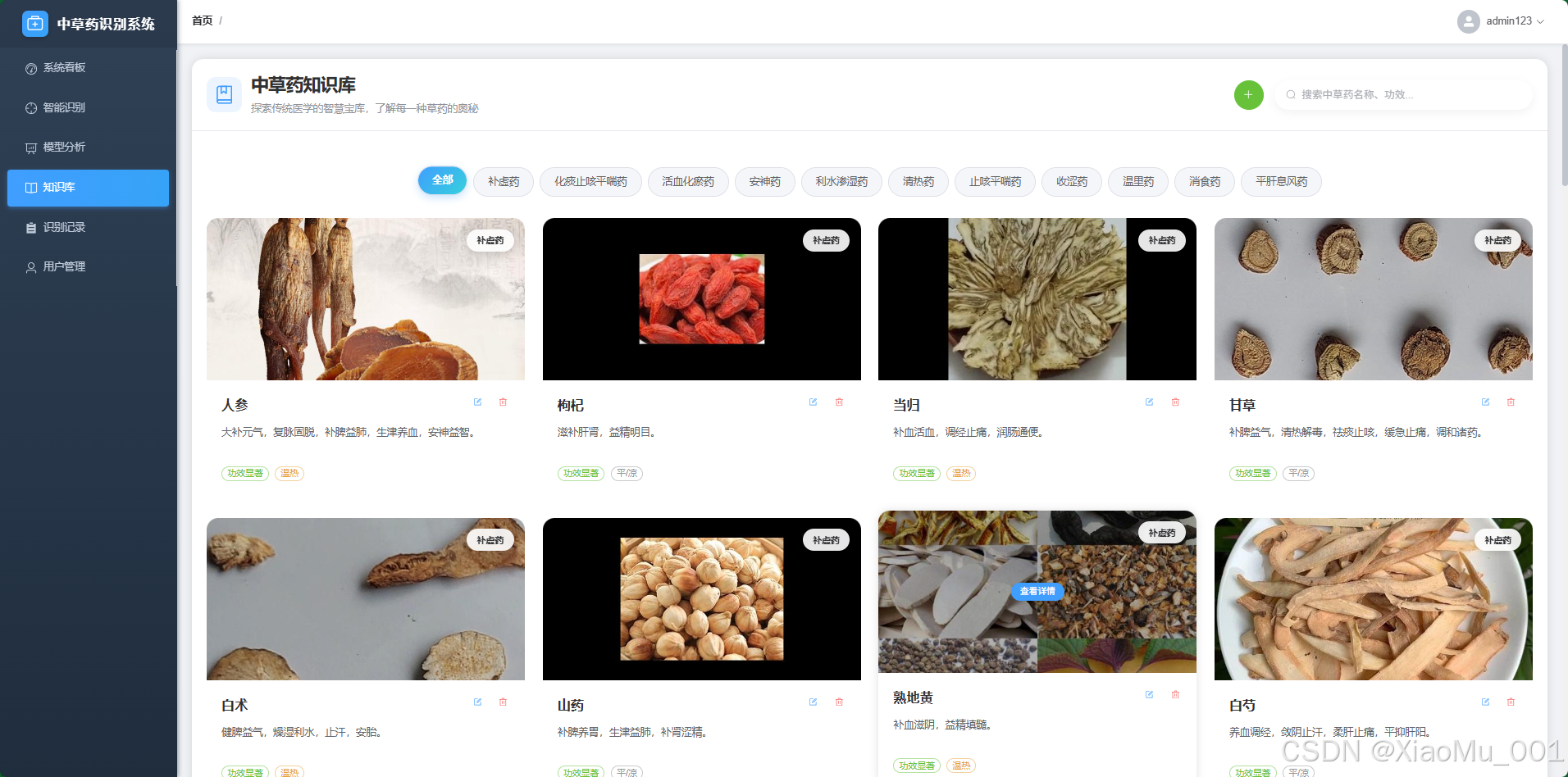
- CRUD 管理:管理员可在此界面对中草药百科数据进行增、删、改、查操作。
- 交互设计:支持按名称搜索,表格支持分页展示,操作列提供“编辑”和“删除”快捷按钮。
5.2.3 智能识别 (Web版)
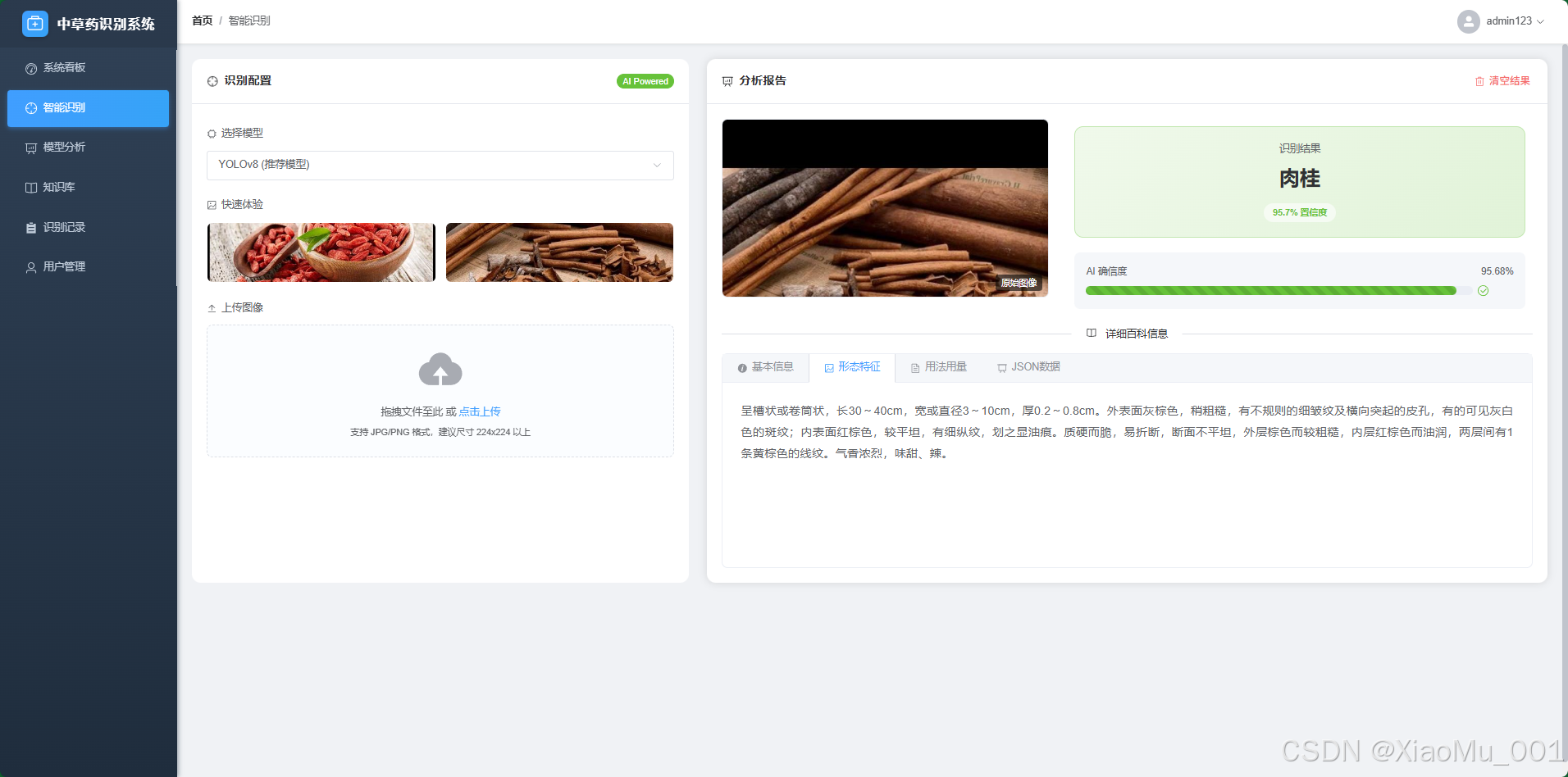
- 功能定位:除了移动端,Web 端也提供了识别入口,方便管理员测试模型效果或批量处理图片。
- 结果展示:识别成功后,不仅显示名称和置信度,还会自动关联并展示该草药的详细百科信息。
5.2.4 模型训练与分析
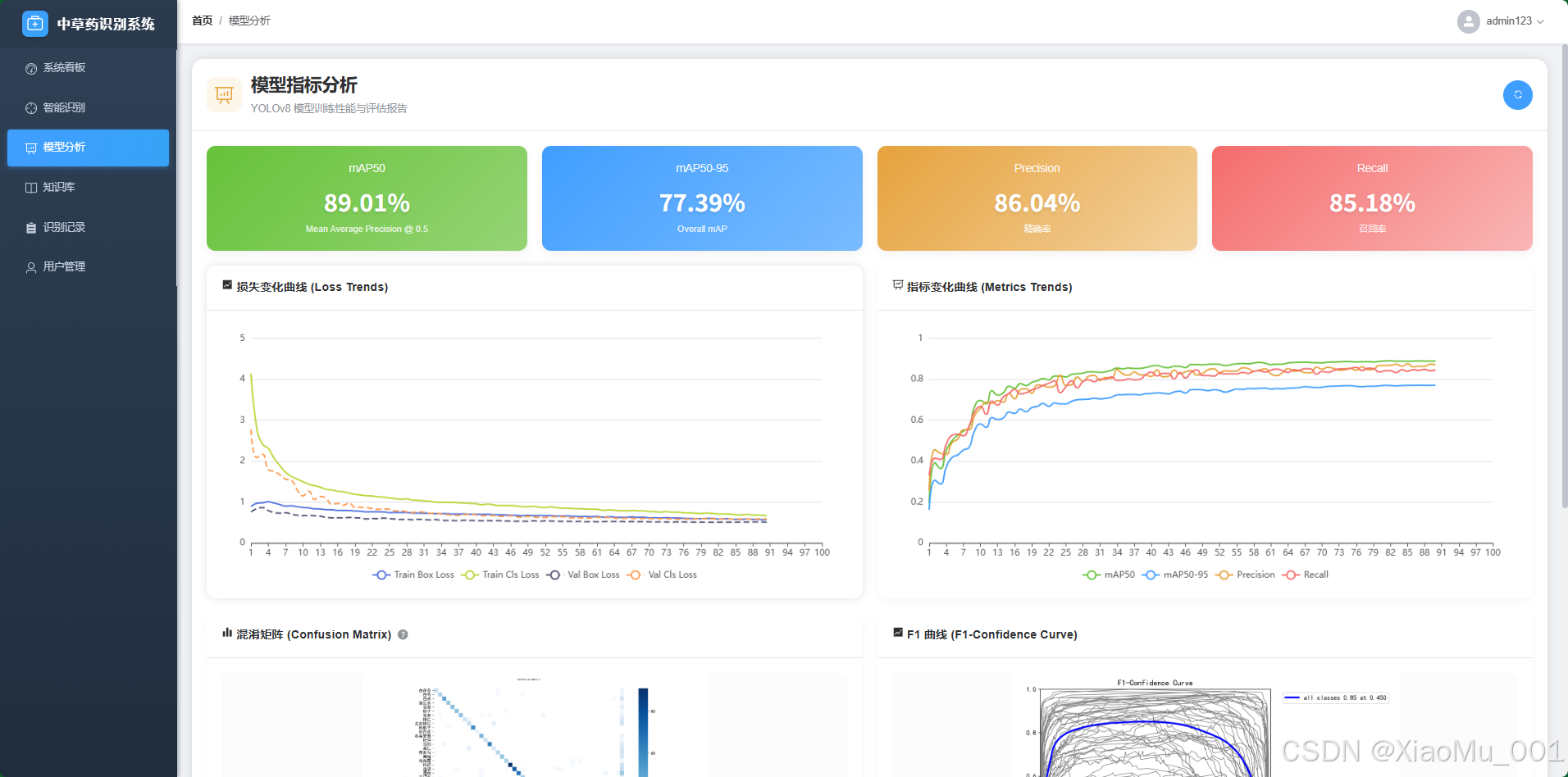
- 训练监控:管理员可在此发起新的模型训练任务(选择模型架构如 YOLOv8/ResNet,设置 Epochs)。
- 日志分析:点击历史训练记录,可查看详细的训练日志和 Loss/Accuracy 变化曲线,评估模型优劣。
5.2.5 用户与记录管理
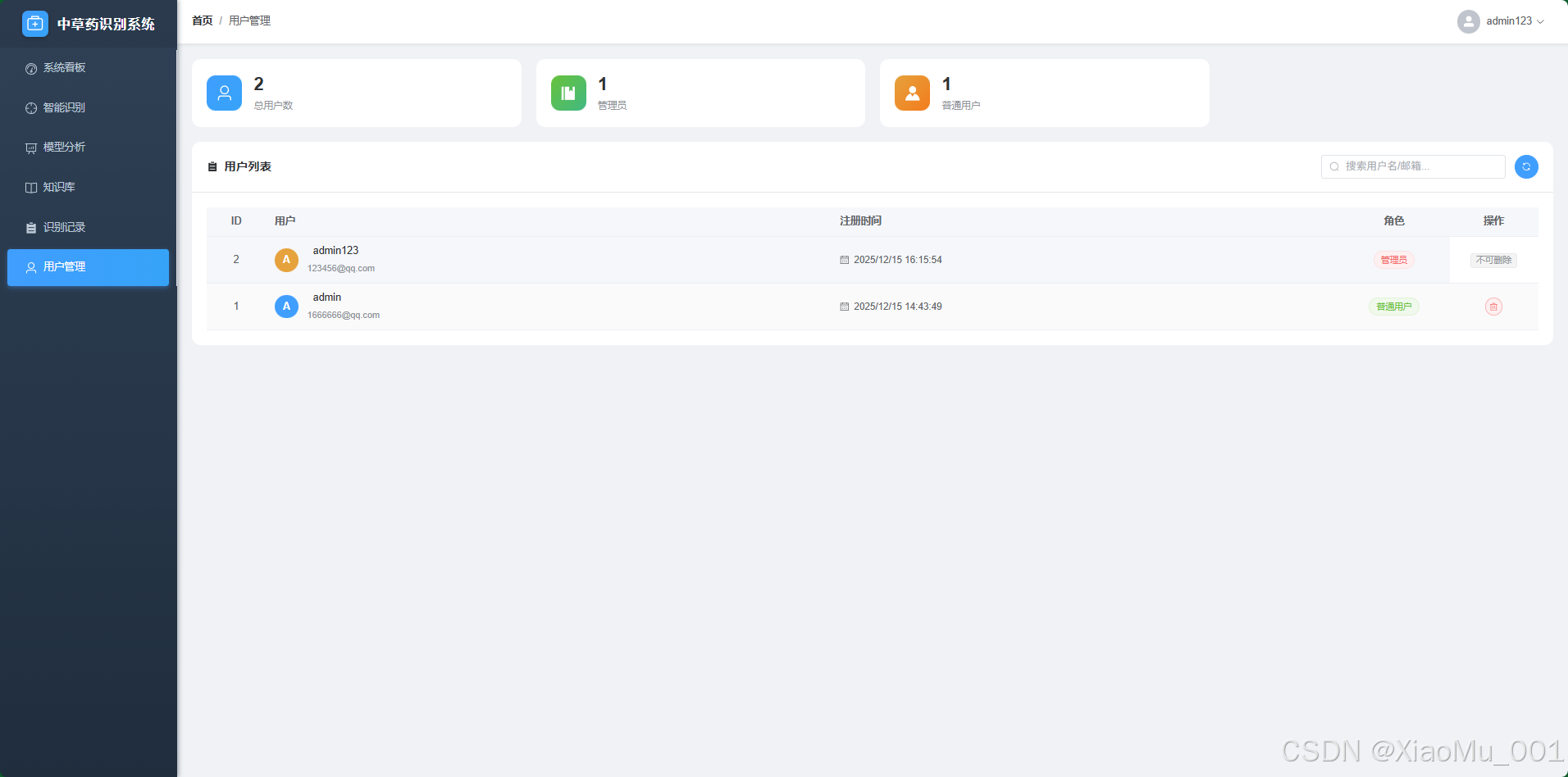
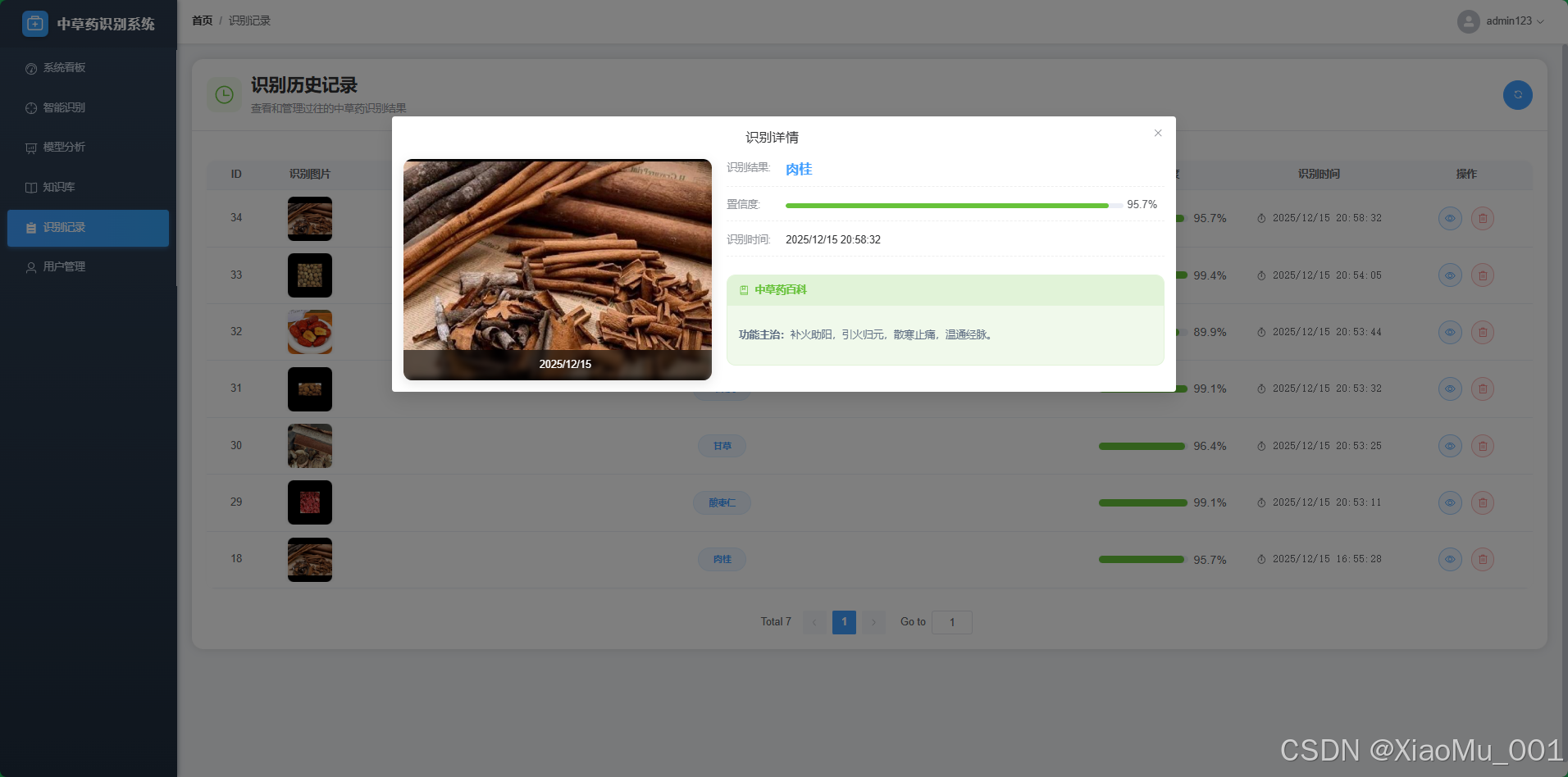
- 用户管理:管理员可查看注册用户列表,重置密码或封禁违规账号。
- 全站记录:管理员拥有查看所有用户识别记录的权限,用于数据分析和系统审计。
5.2.6 认证与个人设置
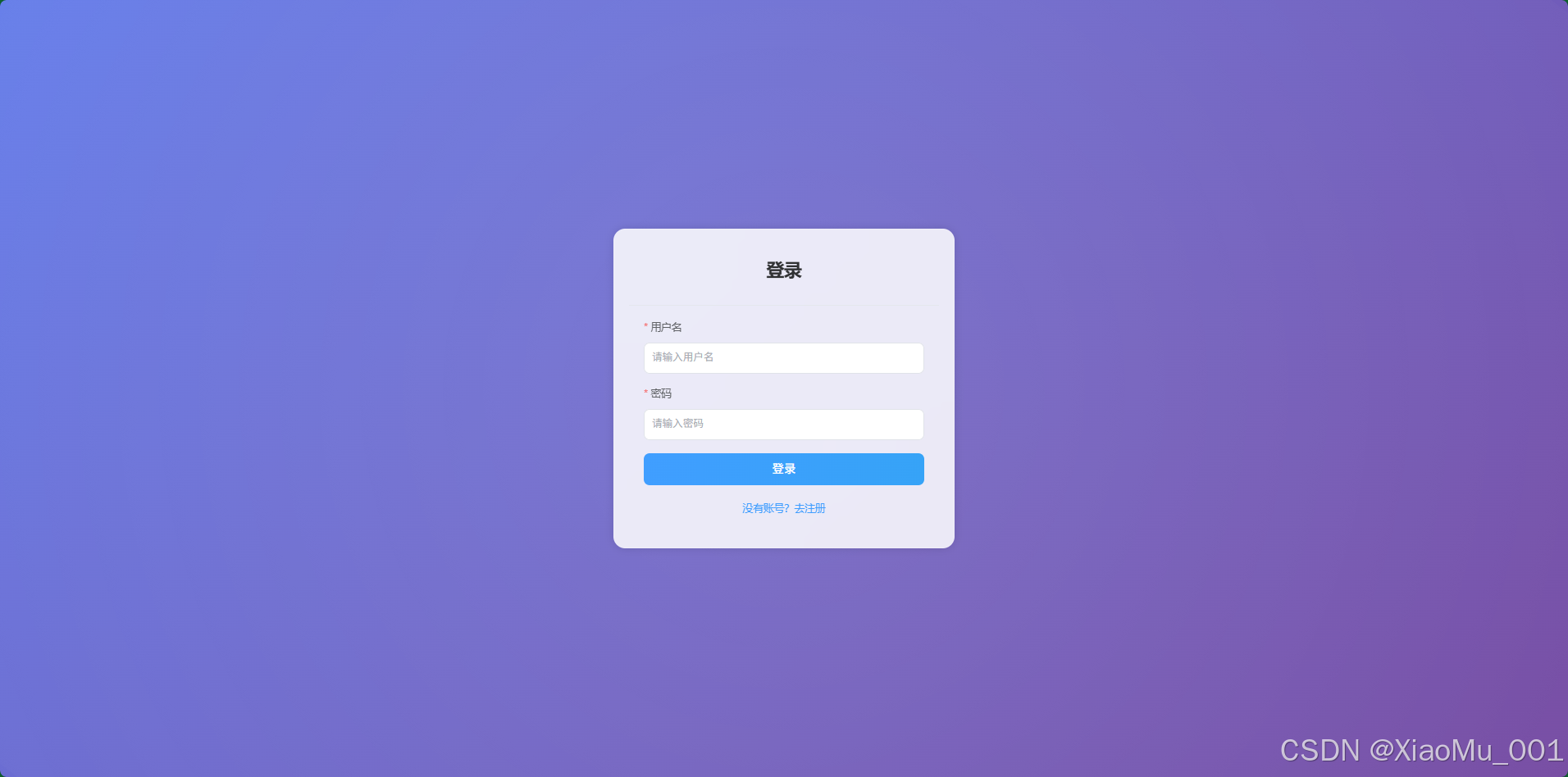
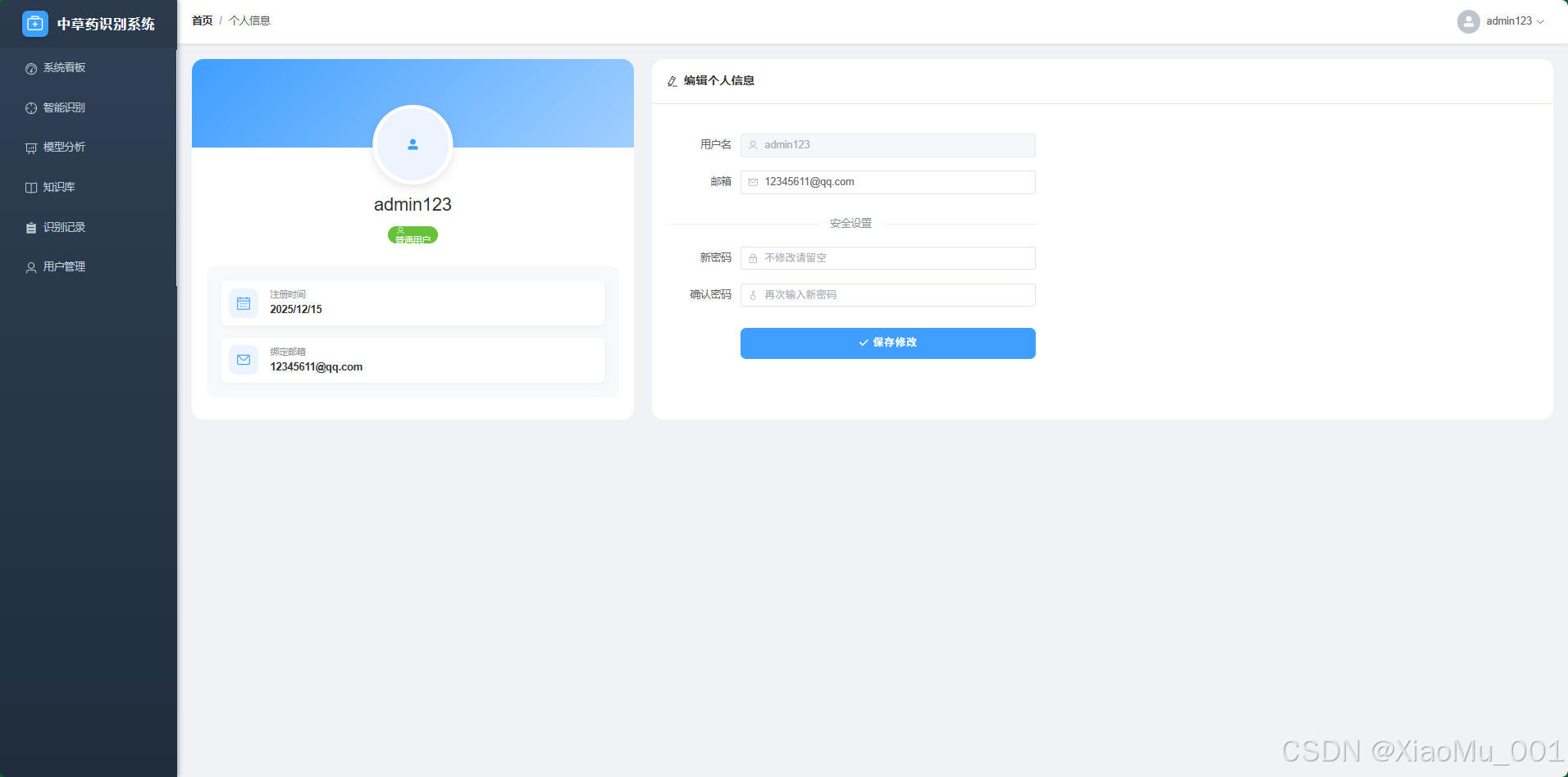
- 统一认证:Web 端与移动端共享同一套用户体系,管理员登录后自动进入后台管理界面。
6. 环境搭建与部署
6.1 依赖环境
- Python: 3.8+ (推荐 3.10)
- Node.js: 16+ (推荐 18 LTS)
- CUDA (可选): 如果需要 GPU 加速训练,需安装 NVIDIA 显卡驱动和 CUDA Toolkit。
6.2 安装步骤
后端
cd system/backend
pip install -r requirements.txt # 安装 Python 依赖
python manage.py migrate # 初始化数据库
python manage.py runserver # 启动开发服务器
前端 Web
cd system/frontend
npm install # 安装 Node 依赖
npm run dev # 启动开发服务器 (默认端口 5173)
移动端
- 下载并安装 HBuilderX 编辑器。
- 导入
system/mobile目录。 - 点击菜单栏“运行” -> “运行到内置浏览器”或“运行到手机模拟器”。
7. 总结与展望
本项目通过整合 YOLOv8、Django 和 Vue3 等前沿技术,成功实现了一个功能完备的中草药智能识别系统。
未来改进方向:
- 模型优化:引入 Transformer 架构 (如 ViT) 进一步提升细粒度分类精度。
- 边缘计算:将模型量化并部署到移动端本地 (TFLite/NCNN),实现离线识别。
- 多模态交互:增加语音播报功能,方便老年用户使用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 31
31 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)