卫星遥感图像检测系统
基于深度学习的卫星遥感图像检测系统设计
目录
1. 项目概述
1.1 项目背景
卫星遥感图像目标检测是计算机视觉和遥感领域的重要研究方向,旨在从高分辨率遥感影像中自动识别和定位地物目标。随着深度学习技术的快速发展,基于深度学习的目标检测方法在遥感图像处理中取得了显著成果。
1.2 项目目标
本项目旨在构建一个完整的卫星遥感图像目标检测系统,实现以下目标:
- 自动化检测:能够自动识别遥感图像中的16类地物目标
- 实时处理:支持单张图像的实时检测和结果可视化
- 数据管理:提供检测历史记录查询和统计分析功能
- 性能分析:可视化模型训练过程和性能指标
- 用户友好:提供简洁直观的Web界面,便于操作和使用
1.3 系统特点
- 采用YOLOv5目标检测算法,检测速度快、精度高
- 基于Streamlit构建Web应用,部署简单、交互友好
- 使用SQLite数据库存储检测历史,数据持久化
- 支持中英文双语显示,界面美观统一
- 提供完整的模型训练过程可视化
2. 数据集介绍
2.1 DOTA数据集概述
DOTA (Dataset for Object Detection in Aerial Images) 是遥感目标检测领域的经典数据集,由武汉大学和华中科技大学联合发布。该数据集包含大量高分辨率航空图像,涵盖了多种地物目标类别。

图2.1:DOTA数据集包含的16类目标示意图。图中展示了各类目标的典型外观特征,包括车辆、飞机、船舶、建筑物等。
2.2 数据集统计信息
| 项目 | 数量 | 说明 |
|---|---|---|
| 训练集 | 1412张 | 用于模型训练,占总数的70% |
| 验证集 | 459张 | 用于模型验证和超参数调整,占总数的23% |
| 测试集 | 147张 | 用于最终性能评估,占总数的7% |
| 类别数 | 16类 | 涵盖多种地物目标 |
| 图像尺寸 | 800-4000像素 | 高分辨率遥感图像 |
2.3 目标类别定义
DOTA数据集包含以下16类目标:
| 类别ID | 英文名称 | 中文名称 | 说明 |
|---|---|---|---|
| 0 | small-vehicle | 小型车辆 | 汽车、小型货车等 |
| 1 | large-vehicle | 大型车辆 | 卡车、公交车等 |
| 2 | plane | 飞机 | 各类飞机 |
| 3 | storage-tank | 储罐 | 石油、化工储罐 |
| 4 | ship | 船舶 | 各类船只 |
| 5 | harbor | 港口 | 港口设施 |
| 6 | ground-track-field | 田径场 | 运动场跑道 |
| 7 | soccer-ball-field | 足球场 | 足球场 |
| 8 | tennis-court | 网球场 | 网球场 |
| 9 | swimming-pool | 游泳池 | 游泳池 |
| 10 | baseball-diamond | 棒球场 | 棒球场 |
| 11 | roundabout | 环岛 | 交通环岛 |
| 12 | basketball-court | 篮球场 | 篮球场 |
| 13 | bridge | 桥梁 | 各类桥梁 |
| 14 | helicopter | 直升机 | 直升机 |
| 15 | container-crane | 集装箱起重机 | 港口起重机 |
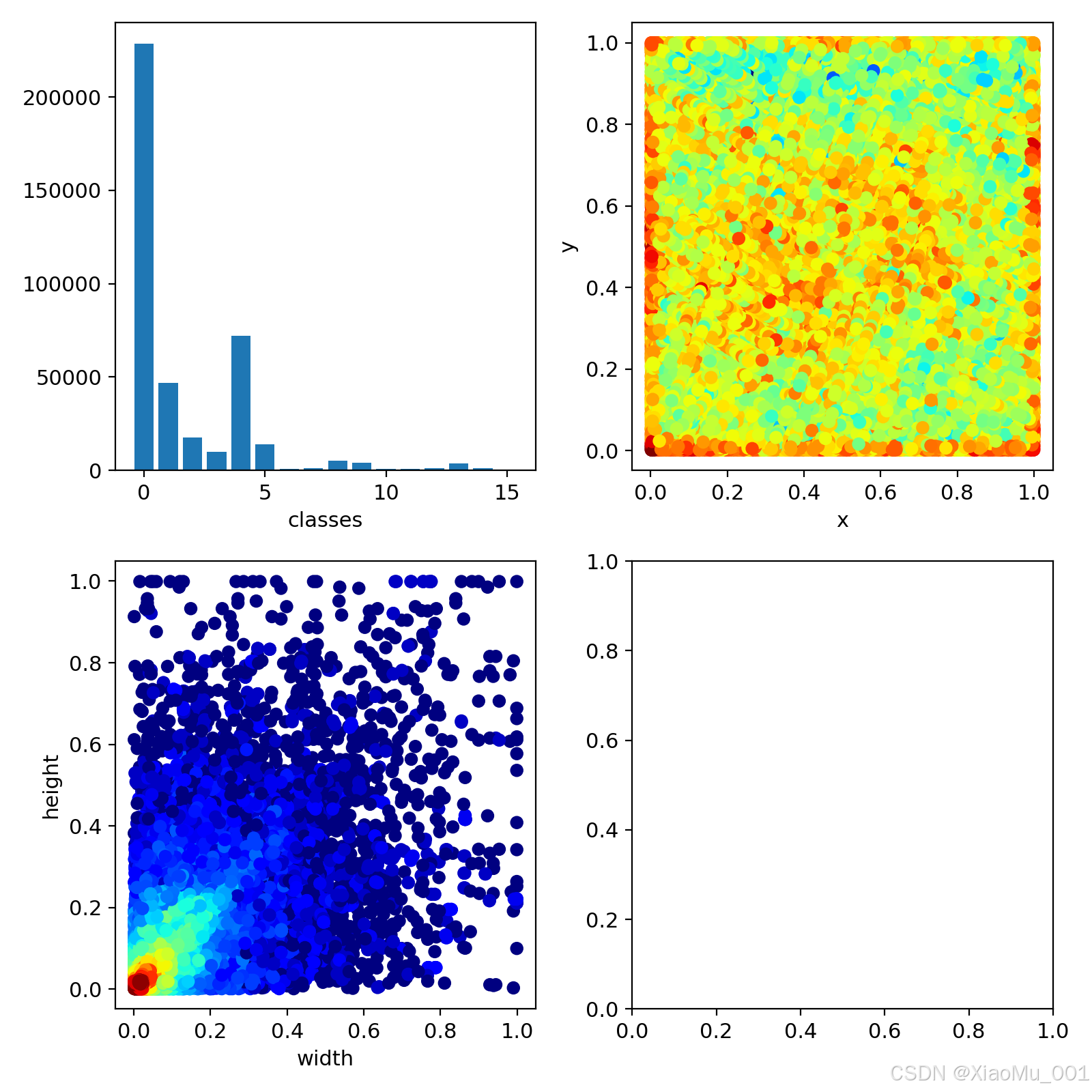
图2.2:数据集类别标签分布图。展示了各类别在数据集中的分布情况,可以看出车辆类目标数量最多,而一些特殊目标如直升机和集装箱起重机数量较少。
2.4 数据集格式
DOTA数据集采用以下格式:
- 图像格式:PNG/JPG,RGB三通道
- 标注格式:DOTA格式(8点坐标)转换为YOLO格式(归一化中心点坐标+宽高)
- 标注文件:每张图像对应一个.txt标注文件

图2.3:训练批次图像示例。展示了模型训练时的一个批次图像,图像中包含了多种目标类别,如车辆、建筑物等。
3. 算法原理
3.1 YOLOv5算法概述
YOLO (You Only Look Once) 是一种单阶段目标检测算法,其核心思想是将目标检测问题转化为回归问题,直接在图像上预测边界框和类别概率。
YOLOv5 是YOLO系列的最新版本之一,具有以下特点:
- 单阶段检测:直接预测目标位置和类别,无需候选区域生成
- 端到端训练:整个网络可以端到端训练,无需复杂的多阶段训练
- 速度快:推理速度快,适合实时应用
- 精度高:通过改进的网络结构和训练策略,检测精度不断提升
3.2 YOLOv5网络结构
YOLOv5的网络结构主要包括以下几个部分:
3.2.1 Backbone(骨干网络)
- CSPDarknet53:基于Darknet的改进版本
- Focus模块:将输入图像进行切片操作,提高特征提取效率
- CSP模块:Cross Stage Partial连接,减少计算量同时保持精度
3.2.2 Neck(特征融合网络)
- FPN (Feature Pyramid Network):特征金字塔网络
- PAN (Path Aggregation Network):路径聚合网络
- 通过多尺度特征融合,提高小目标检测能力
3.2.3 Head(检测头)
- 检测头:输出三个尺度的特征图
- 多尺度检测:在不同尺度上检测不同大小的目标
- 输出格式:每个网格预测多个边界框和类别概率
3.3 检测流程
YOLOv5的检测流程如下:
- 图像预处理:将输入图像调整为固定尺寸(如640×640)
- 特征提取:通过Backbone提取图像特征
- 特征融合:通过Neck进行多尺度特征融合
- 目标预测:通过Head预测目标位置和类别
- 后处理:使用NMS(非极大值抑制)去除重复检测框
3.4 损失函数
YOLOv5使用多任务损失函数,包括:
- 边界框损失:使用GIoU Loss计算预测框和真实框的差异
- 目标置信度损失:使用BCE Loss计算目标存在概率
- 类别损失:使用BCE Loss计算类别概率
总损失函数为:
Loss = λ₁ × Box_Loss + λ₂ × Obj_Loss + λ₃ × Cls_Loss
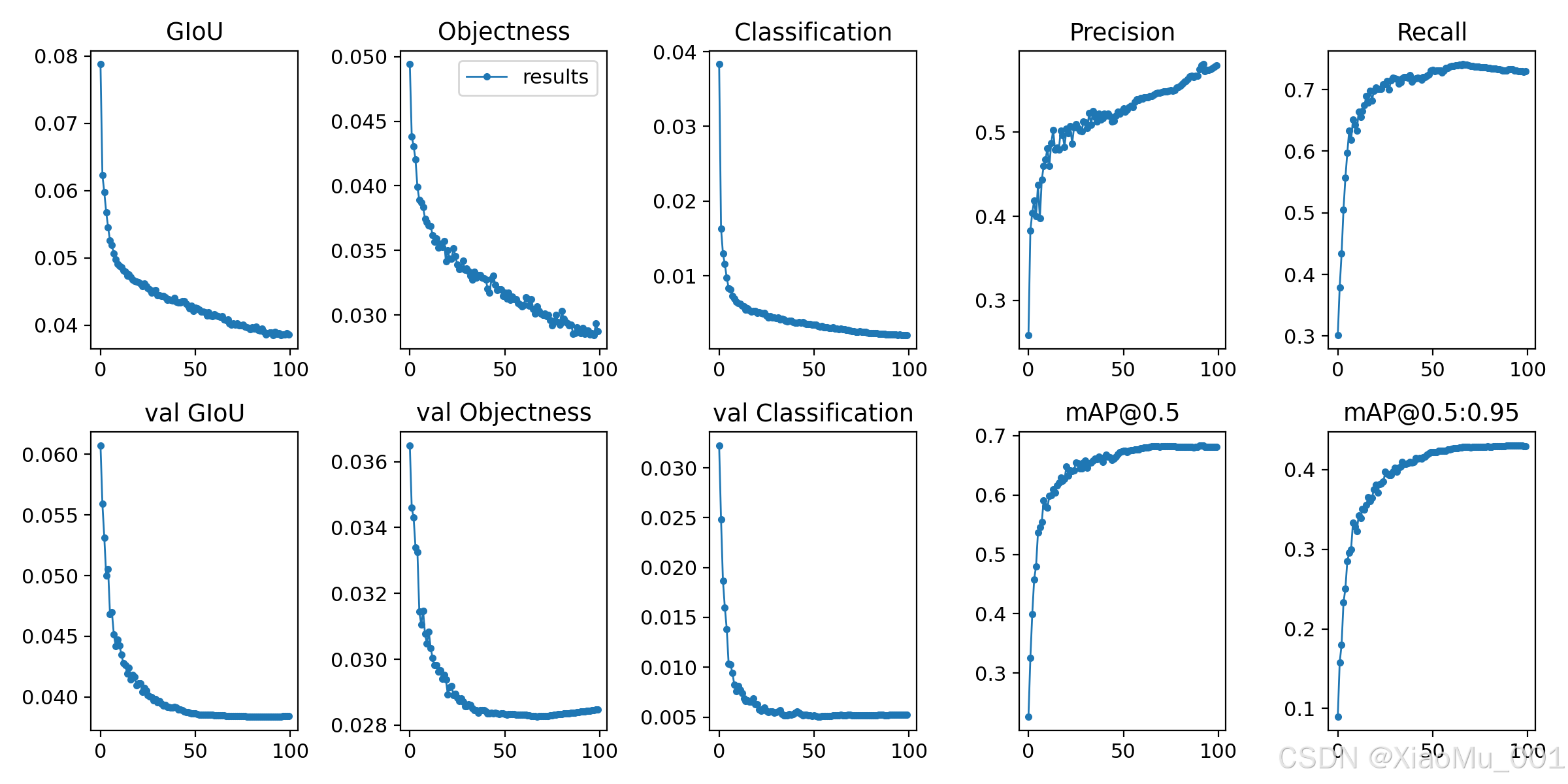
图3.2:模型训练结果曲线。图中展示了训练过程中的各项指标变化,包括损失函数、精确率、召回率、mAP等指标随训练轮次的变化趋势。
3.5 非极大值抑制(NMS)
NMS用于去除重复的检测框,流程如下:
- 按置信度对检测框排序
- 选择置信度最高的检测框
- 计算该框与其他框的IoU
- 删除IoU大于阈值的检测框
- 重复步骤2-4,直到所有框处理完毕

图3.3:测试批次真实标签示例。图中展示了测试图像的真实标注,绿色边界框表示真实目标位置,用于与模型预测结果进行对比评估。
4. 模型架构
4.1 模型选择
本项目选择YOLOv5s作为基础模型,原因如下:
- 轻量级:模型参数量适中,推理速度快
- 精度高:在DOTA数据集上表现良好
- 易部署:模型文件小,便于部署
4.2 模型配置
模型主要配置参数:
| 参数 | 值 | 说明 |
|---|---|---|
| 输入尺寸 | 640×640 | 图像输入尺寸 |
| 类别数 | 16 | DOTA数据集类别数 |
| 锚框数 | 3 | 每个网格预测的锚框数 |
| 特征图尺度 | 3 | 多尺度检测的特征图数量 |
4.3 模型训练配置
训练超参数设置:
| 参数 | 值 | 说明 |
|---|---|---|
| 批次大小 | 16 | 每次训练的样本数 |
| 学习率 | 0.01 | 初始学习率 |
| 优化器 | SGD | 随机梯度下降 |
| 训练轮次 | 100 | 总训练轮数 |
| 数据增强 | 是 | 随机翻转、缩放等 |
5. 训练过程
5.1 数据预处理
训练前的数据预处理步骤:
- 图像裁剪:将大尺寸遥感图像裁剪为640×640的小块
- 标注转换:将DOTA格式标注转换为YOLO格式
- 数据增强:随机翻转、缩放、色彩调整等
- 数据划分:按7:2:1划分训练集、验证集、测试集
5.2 训练流程
模型训练流程:
- 初始化:加载预训练权重(可选)
- 前向传播:输入图像,计算预测结果
- 损失计算:计算预测结果与真实标签的损失
- 反向传播:计算梯度并更新模型参数
- 验证评估:在验证集上评估模型性能
- 保存模型:保存最佳模型权重
5.3 训练监控
训练过程中监控以下指标:
- 损失函数:训练损失和验证损失
- 精确率(Precision):预测为正例中真正为正例的比例
- 召回率(Recall):真正例中被正确预测的比例
- mAP@0.5:IoU阈值为0.5时的平均精度
- mAP@0.5:0.95:IoU阈值从0.5到0.95的平均精度

图5.1:训练批次图像和标签可视化。图中展示了训练时的一个批次图像,图像上叠加了真实标注框,用于监督学习。
6. 评估方法
6.1 评估指标
6.1.1 精确率(Precision)
精确率表示预测为正例的样本中,真正为正例的比例:
Precision = TP / (TP + FP)
其中:
- TP (True Positive):真正例,正确预测为正例
- FP (False Positive):假正例,错误预测为正例
6.1.2 召回率(Recall)
召回率表示真正例中被正确预测的比例:
Recall = TP / (TP + FN)
其中:
- FN (False Negative):假负例,错误预测为负例
6.1.3 平均精度(mAP)
mAP是目标检测任务的主要评估指标:
- AP@0.5:IoU阈值为0.5时的平均精度
- AP@0.5:0.95:IoU阈值从0.5到0.95(步长0.05)的平均精度均值
6.2 模型性能
根据训练结果,模型在DOTA数据集上的性能指标:
| 指标 | 数值 | 说明 |
|---|---|---|
| 精确率 | 57.91% | 预测准确度 |
| 召回率 | 72.96% | 目标检出率 |
| mAP@0.5 | 68.07% | IoU=0.5时的平均精度 |
| mAP@0.5:0.95 | 42.98% | 综合平均精度 |
6.3 测试结果可视化

图6.1:测试结果对比图。左图为真实标签(Ground Truth),右图为模型预测结果,通过对比可以评估模型的检测效果。
7. 数据库设计
7.1 数据库概述
系统使用SQLite数据库存储检测历史记录。SQLite是一个轻量级的嵌入式数据库,具有以下优点:
- 零配置:无需单独安装和配置数据库服务器
- 文件存储:数据库存储在单个文件中,便于备份和迁移
- 跨平台:支持Windows、Linux、macOS等多个平台
- 性能良好:对于中小型应用性能表现优秀
7.2 数据库表设计
7.2.1 detection_history表
该表用于存储所有检测历史记录,包括检测时间、图像信息、检测结果等。
表结构:
| 字段名 | 数据类型 | 长度 | 非空 | 唯一 | 主键 | 说明 |
|---|---|---|---|---|---|---|
| id | INTEGER | - | 是 | 是 | 是 | 记录ID,自增主键 |
| timestamp | TEXT | - | 是 | 否 | 否 | 检测时间戳,格式:YYYY-MM-DD HH:MM:SS |
| image_name | TEXT | - | 是 | 否 | 否 | 图像文件名 |
| image_path | TEXT | - | 否 | 否 | 否 | 图像文件路径(可选) |
| num_detections | INTEGER | - | 否 | 否 | 否 | 检测到的目标数量 |
| detections | TEXT | - | 否 | 否 | 否 | 检测结果JSON字符串 |
| processing_time | REAL | - | 否 | 否 | 否 | 处理时间(秒) |
| confidence_threshold | REAL | - | 否 | 否 | 否 | 使用的置信度阈值 |
字段详细说明:
-
id (INTEGER, PRIMARY KEY, AUTOINCREMENT)
- 类型:整数
- 约束:主键,自增
- 说明:每条记录的唯一标识符,系统自动生成
-
timestamp (TEXT, NOT NULL)
- 类型:文本
- 约束:非空
- 格式:‘YYYY-MM-DD HH:MM:SS’
- 说明:记录检测操作的时间,用于历史记录查询和排序
-
image_name (TEXT, NOT NULL)
- 类型:文本
- 约束:非空
- 说明:上传或检测的图像文件名,用于标识检测的图像
-
image_path (TEXT, NULL)
- 类型:文本
- 约束:可为空
- 说明:图像文件的完整路径,如果图像是临时上传的,此字段可能为空
-
num_detections (INTEGER, NULL)
- 类型:整数
- 约束:可为空
- 说明:本次检测识别到的目标总数,用于快速统计
-
detections (TEXT, NULL)
- 类型:文本(JSON格式)
- 约束:可为空
- 说明:详细的检测结果,以JSON字符串形式存储,包含每个检测目标的:
- class_id:类别ID
- class_name:类别名称(英文)
- class_name_cn:类别名称(中文)
- confidence:置信度
- bbox:边界框坐标 [x1, y1, x2, y2]
-
processing_time (REAL, NULL)
- 类型:浮点数
- 约束:可为空
- 单位:秒
- 说明:图像处理耗时,用于性能分析和优化
-
confidence_threshold (REAL, NULL)
- 类型:浮点数
- 约束:可为空
- 范围:0.0 - 1.0
- 说明:检测时使用的置信度阈值,用于过滤低置信度检测结果
创建SQL语句:
CREATE TABLE IF NOT EXISTS detection_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT NOT NULL,
image_name TEXT NOT NULL,
image_path TEXT,
num_detections INTEGER,
detections TEXT,
processing_time REAL,
confidence_threshold REAL
);
7.3 数据库操作
7.3.1 初始化数据库
系统启动时自动创建数据库和表结构:
def init_database():
"""初始化SQLite数据库"""
conn = sqlite3.connect(str(DB_PATH))
c = conn.cursor()
c.execute('''
CREATE TABLE IF NOT EXISTS detection_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT NOT NULL,
image_name TEXT NOT NULL,
image_path TEXT,
num_detections INTEGER,
detections TEXT,
processing_time REAL,
confidence_threshold REAL
)
''')
conn.commit()
conn.close()
7.3.2 插入检测记录
每次完成检测后,自动保存检测记录:
def save_detection(image_name, image_path, detections, processing_time, conf_thres):
"""保存检测记录到数据库"""
conn = sqlite3.connect(str(DB_PATH))
c = conn.cursor()
timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
detections_json = json.dumps(detections)
num_detections = len(detections)
c.execute('''
INSERT INTO detection_history
(timestamp, image_name, image_path, num_detections, detections, processing_time, confidence_threshold)
VALUES (?, ?, ?, ?, ?, ?, ?)
''', (timestamp, image_name, image_path, num_detections, detections_json, processing_time, conf_thres))
conn.commit()
conn.close()
7.3.3 查询历史记录
支持按时间倒序查询历史记录:
def get_history(limit=50):
"""获取检测历史记录"""
conn = sqlite3.connect(str(DB_PATH))
c = conn.cursor()
c.execute('''
SELECT * FROM detection_history
ORDER BY timestamp DESC
LIMIT ?
''', (limit,))
results = c.fetchall()
conn.close()
return results
7.4 数据示例
detections字段JSON格式示例:
[
{
"class_id": 0,
"class_name": "small-vehicle",
"class_name_cn": "小型车辆",
"confidence": 0.856,
"bbox": [120, 340, 180, 400]
},
{
"class_id": 2,
"class_name": "plane",
"class_name_cn": "飞机",
"confidence": 0.923,
"bbox": [450, 200, 550, 280]
}
]
8. 系统目录结构
8.1 项目根目录
program/
├── algorithm/ # 算法和系统主目录
│ ├── streamlit_app.py # Streamlit主应用文件
│ ├── requirements.txt # Python依赖包列表
│ ├── README.md # 项目说明文档
│ ├── detection_history.db # SQLite数据库文件(自动生成)
│ └── model/ # YOLOv5模型目录
│ ├── weights/ # 模型权重文件
│ │ ├── best.pt # 最佳模型权重
│ │ └── last.pt # 最后一轮训练权重
│ ├── data/ # 数据集配置文件
│ │ └── DOTA.yaml # DOTA数据集配置
│ ├── models/ # 模型定义文件
│ │ ├── yolo.py # YOLO模型主文件
│ │ ├── common.py # 通用模块定义
│ │ └── experimental.py # 实验性模块
│ ├── utils/ # 工具函数
│ │ ├── general.py # 通用工具函数
│ │ ├── datasets.py # 数据集处理
│ │ └── torch_utils.py # PyTorch工具函数
│ ├── runs/ # 训练结果目录
│ │ └── exp1/ # 实验1结果
│ │ ├── results.txt # 训练结果数据
│ │ ├── results.png # 训练曲线图
│ │ ├── weights/ # 训练保存的权重
│ │ └── *.jpg # 训练可视化图像
│ ├── inference/ # 推理测试目录
│ │ ├── images/ # 测试图像
│ │ └── output/ # 输出结果
│ ├── train.py # 训练脚本
│ ├── test.py # 测试脚本
│ └── detect.py # 检测脚本
└── explaination/ # 项目说明文档目录
├── 详解.md # 本文档
└── images/ # 文档图片
├── algorithm/ # 算法相关图片
└── system/ # 系统界面图片
8.2 关键文件说明
8.2.1 streamlit_app.py
主应用文件,包含所有系统功能:
- 页面路由:管理不同页面的显示
- 模型加载:加载YOLOv5模型权重
- 图像处理:图像预处理和后处理
- 数据库操作:历史记录的增删改查
- 可视化:图表生成和结果展示
8.2.2 model/weights/best.pt
训练好的模型权重文件,包含:
- 模型网络结构参数
- 训练得到的权重值
- 模型元数据(类别名称、输入尺寸等)
8.2.3 model/data/DOTA.yaml
数据集配置文件,定义:
- 训练集、验证集、测试集路径
- 类别数量和类别名称
- 数据集相关参数
8.2.4 model/runs/exp1/results.txt
训练结果数据文件,记录每轮训练的:
- 损失函数值
- 精确率、召回率
- mAP指标
- 学习率等参数
9. 系统界面与功能
9.1 系统介绍页面

图9.1:系统介绍页面。展示了系统的整体概述、支持的检测类别、技术栈和数据集信息。
功能说明:
-
系统概述
- 介绍系统的基本功能和特点
- 说明系统的应用场景和价值
-
检测目标类别
- 以4列布局展示16类检测目标
- 每类显示英文名称和中文名称
- 帮助用户了解系统能力
-
技术栈展示
- 深度学习框架:PyTorch、YOLOv5
- 图像处理:OpenCV、Pillow
- Web框架:Streamlit
-
数据集信息
- 显示数据集名称、类别数、训练图像数量
- 以指标卡片形式展示
-
系统功能列表
- 实时检测功能
- 结果可视化功能
- 历史记录功能
- 模型分析功能
- 数据分析功能
9.2 数据分析页面
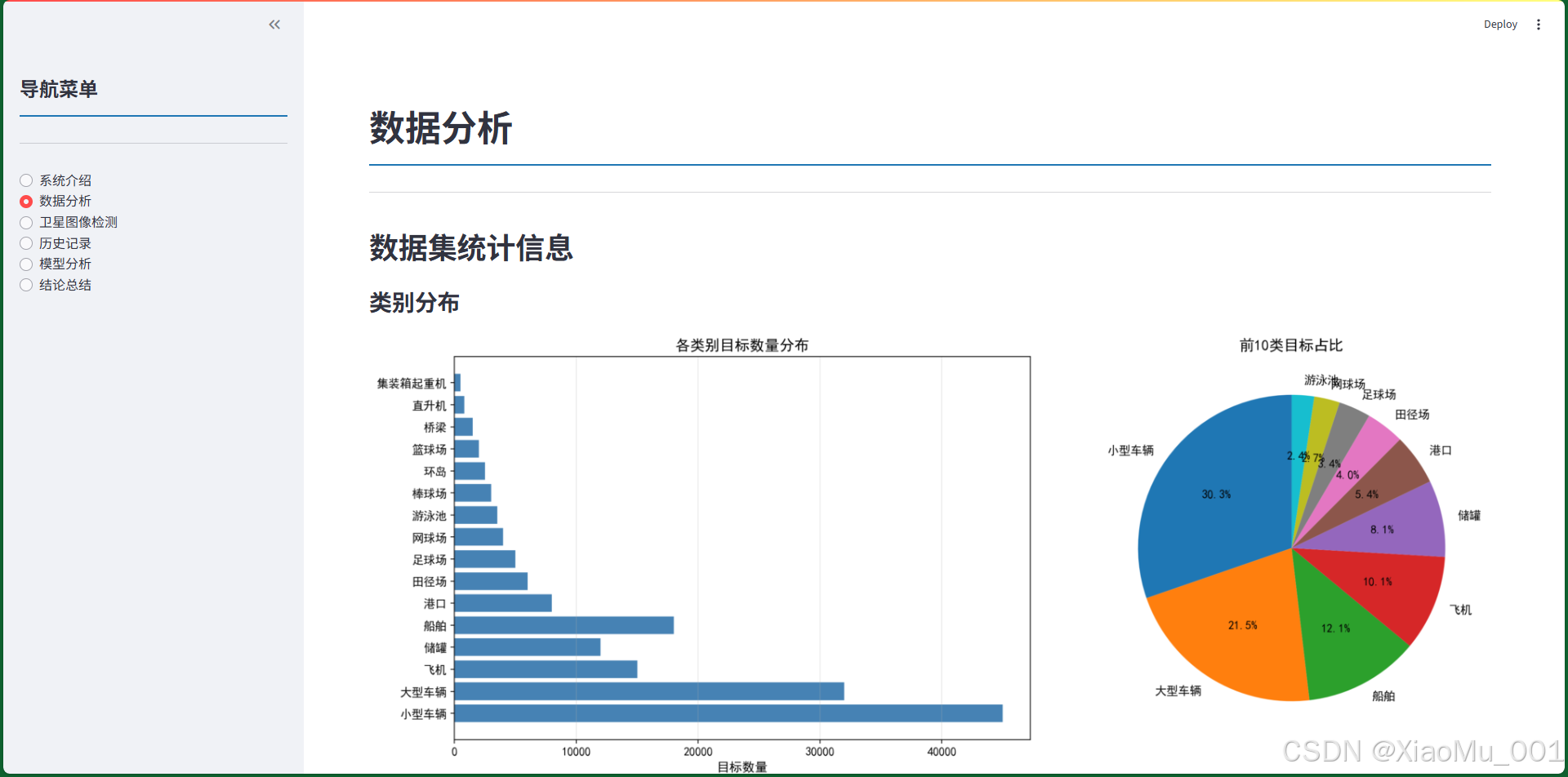
图9.2:数据分析页面。展示了数据集的统计信息,包括类别分布图表和详细统计表格。
功能说明:
-
类别分布可视化
- 柱状图:横向柱状图展示各类别目标数量
- 饼图:展示前10类目标的占比情况
- 使用中文类别名称,便于理解
-
数据集划分
- 训练集:1412张(70%)
- 验证集:459张(23%)
- 测试集:147张(7%)
-
详细统计表格
- 显示所有类别的英文名称、中文名称
- 目标数量和占比百分比
- 支持表格排序和筛选
-
图像特征说明
- 图像尺寸范围
- 平均尺寸
- 支持格式
- 通道数信息
技术实现:
- 使用Matplotlib生成图表
- 配置中文字体支持
- 使用Pandas处理统计数据
- Streamlit组件展示交互式图表
9.3 卫星图像检测页面
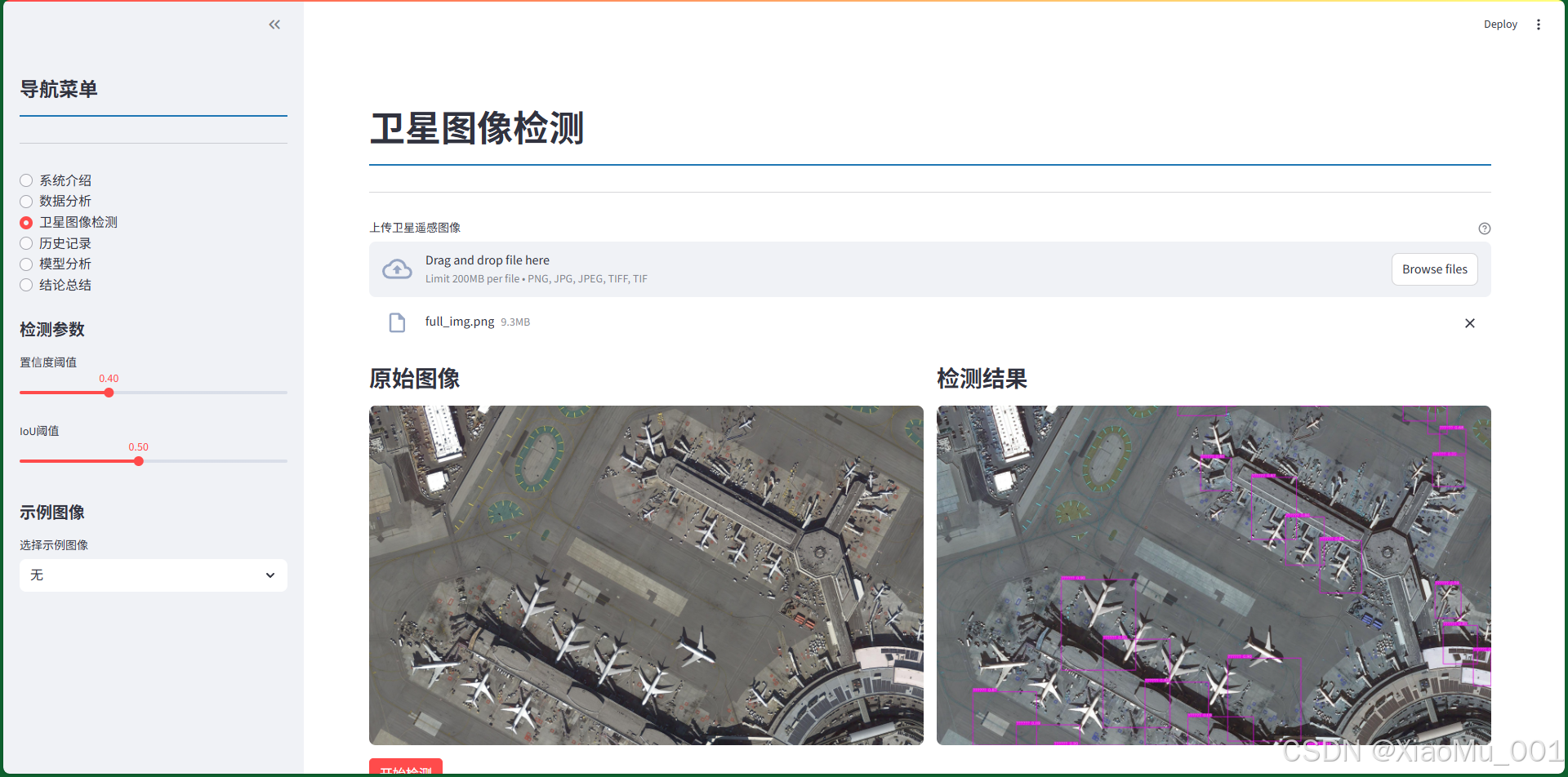
图9.3:卫星图像检测页面。左侧显示原始图像,右侧显示检测结果,下方显示检测统计和详情。
功能说明:
-
图像上传
- 支持PNG、JPG、TIFF格式
- 拖拽上传或点击选择
- 实时预览上传的图像
-
示例图像选择
- 提供3张示例图像供测试
- 快速体验系统功能
- 无需准备测试图像
-
检测参数设置
- 置信度阈值:0.1-1.0,默认0.4
- 值越高,只显示高置信度结果
- 值越低,显示更多检测结果(可能包含误检)
- IoU阈值:0.1-1.0,默认0.5
- 控制NMS的严格程度
- 值越高,去除更多重叠框
- 置信度阈值:0.1-1.0,默认0.4
-
检测结果展示
- 可视化结果:在原图上绘制检测框
- 检测框颜色:不同类别使用不同颜色
- 标签信息:显示类别名称(中文)和置信度
-
检测统计信息
- 检测目标总数
- 处理时间(秒)
- 平均置信度
- 检测到的类别数
-
检测结果详情表格
- 显示每个检测目标的详细信息:
- 类别(英文和中文)
- 置信度
- 边界框坐标
- 支持表格排序和筛选
- 显示每个检测目标的详细信息:
-
类别统计图表
- 柱状图展示各类别检测数量
- 使用中文类别名称
- 便于分析检测结果分布
技术实现:
- 模型加载:使用
@st.cache_resource缓存模型,提高加载速度 - 图像预处理:
- 转换为numpy数组
- 调整尺寸为640×640
- RGB到BGR转换(OpenCV格式)
- 归一化到0-1范围
- 目标检测:
- 模型前向传播
- NMS后处理
- 坐标缩放回原图尺寸
- 结果绘制:
- 使用OpenCV绘制边界框
- 添加类别标签和置信度
- 转换回RGB格式用于显示
9.4 历史记录页面
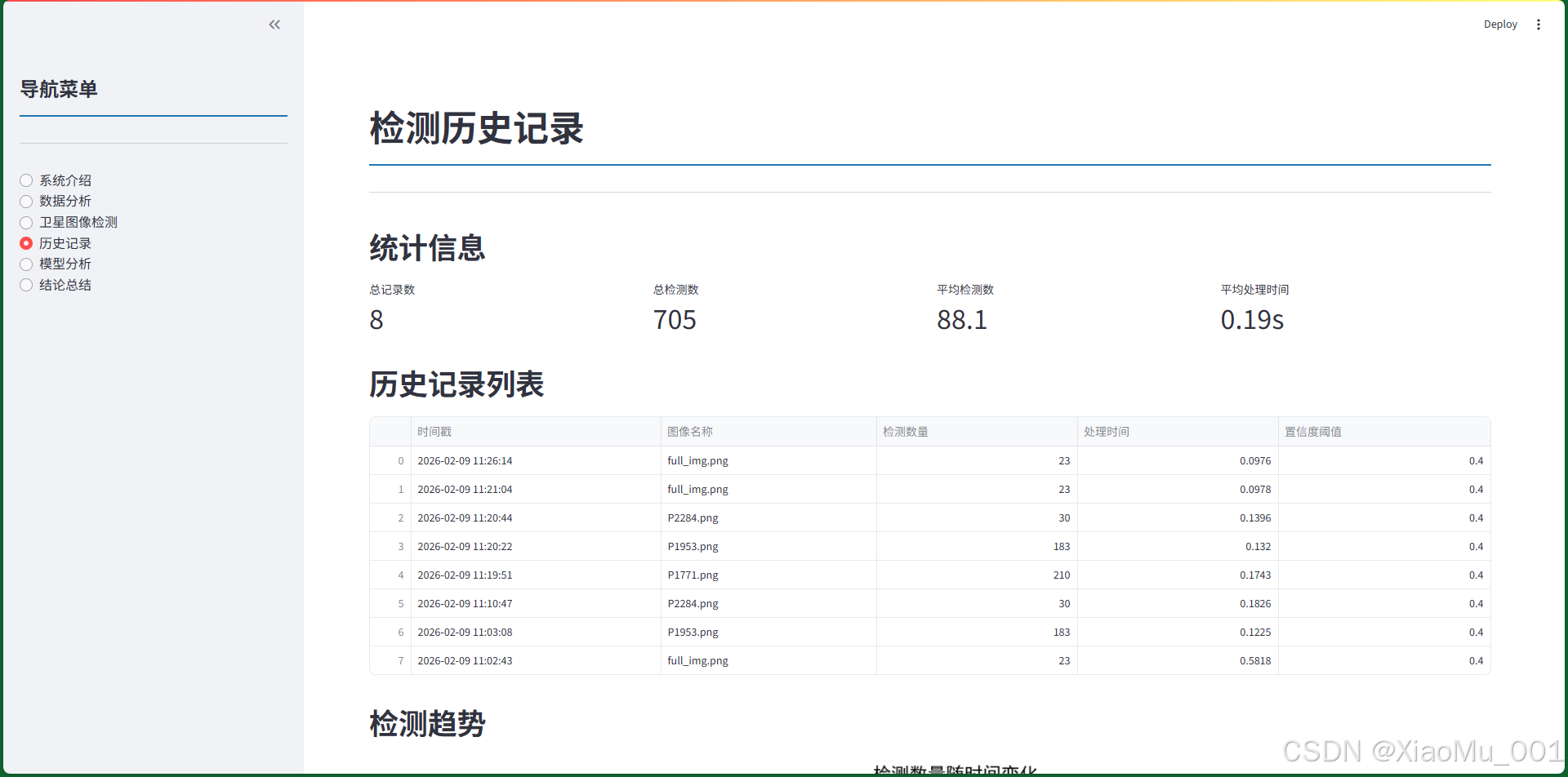
图9.4:历史记录页面。展示了所有检测历史记录,包括统计信息、记录列表和趋势图表。
功能说明:
-
统计信息卡片
- 总记录数:所有检测记录的数量
- 总检测数:所有检测到的目标总数
- 平均检测数:每次检测的平均目标数
- 平均处理时间:平均每次检测耗时
-
历史记录列表
- 表格形式展示所有记录
- 显示字段:
- 时间戳
- 图像名称
- 检测数量
- 处理时间
- 置信度阈值
- 按时间倒序排列
- 支持表格交互(排序、筛选)
-
检测趋势图表
- 检测数量趋势:折线图展示检测数量随时间的变化
- 处理时间趋势:折线图展示处理时间随时间的变化
- 帮助分析系统使用情况和性能变化
技术实现:
- SQLite数据库查询
- Pandas数据处理
- Matplotlib图表生成
- 时间序列数据可视化
9.5 模型分析页面
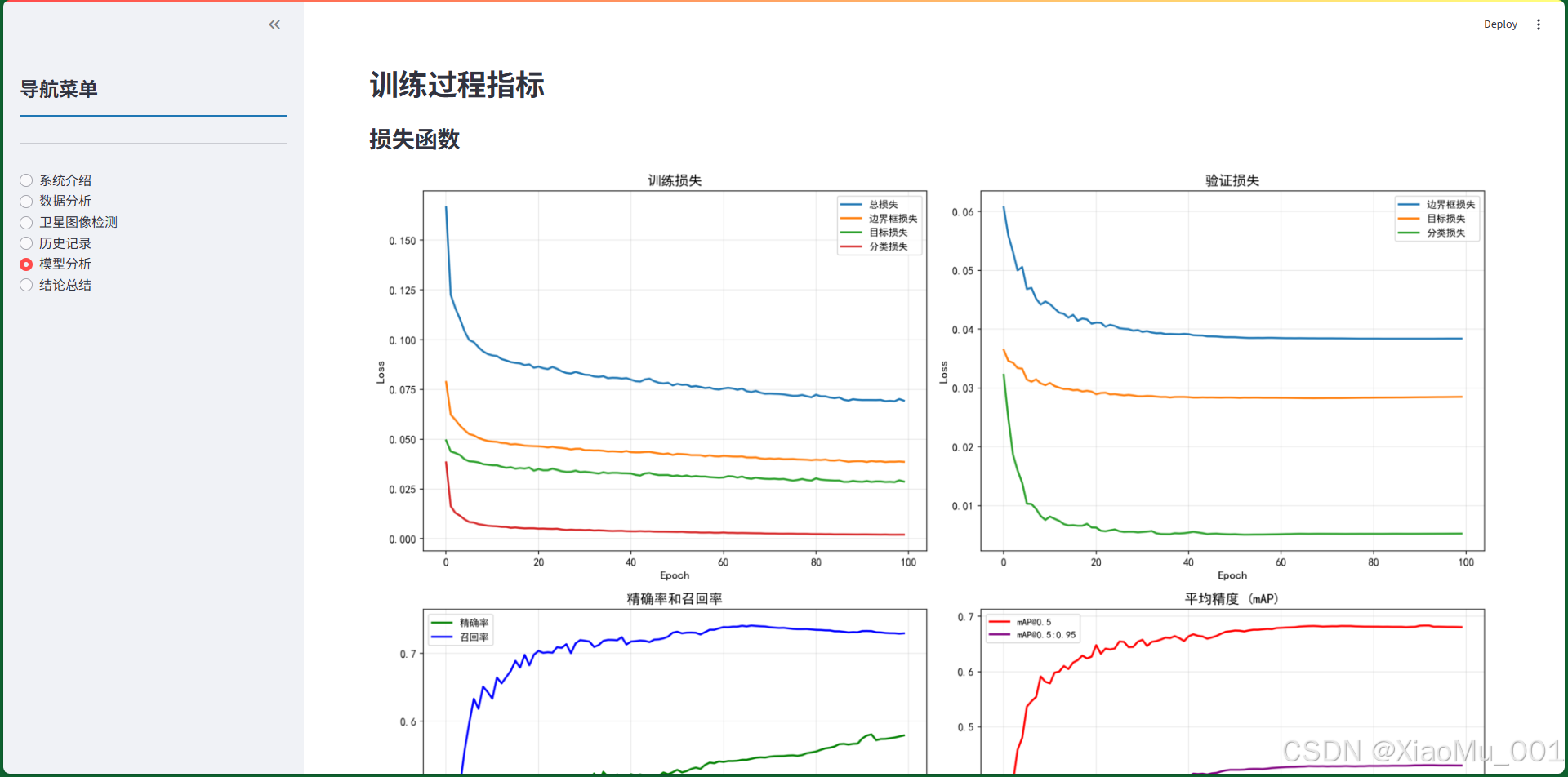
图9.5:模型分析页面。展示了模型训练过程的各项指标,包括损失函数曲线和性能指标图表。
功能说明:
-
训练过程指标
- 从
results.txt文件解析训练数据 - 自动查找最新的训练结果
- 从
-
损失函数可视化
- 训练损失:总损失、边界框损失、目标损失、分类损失
- 验证损失:边界框损失、目标损失、分类损失
- 4个子图展示不同损失的变化趋势
-
性能指标可视化
- 精确率和召回率:展示模型精确度和检出率
- mAP指标:mAP@0.5和mAP@0.5:0.95的变化
- 帮助分析模型性能提升过程
-
最终模型性能
- 以指标卡片形式展示最终性能:
- 精确率
- 召回率
- mAP@0.5
- mAP@0.5:0.95
- 以指标卡片形式展示最终性能:
-
训练过程数据表格
- 显示每轮训练的详细数据
- 包含所有损失和指标值
- 支持数据导出和分析
技术实现:
- 文件解析:解析YOLOv5训练结果文件
- 数据提取:提取损失和指标数据
- 图表生成:使用Matplotlib绘制多子图
- 中文字体:配置中文字体支持
9.6 结论总结页面

图9.6:结论总结页面。总结了项目的成果、技术特点、检测能力、性能指标、应用场景和未来改进方向。
功能说明:
-
项目总结
- 总结项目的主要成果
- 列出实现的核心功能
- 说明项目的价值和意义
-
技术特点
- 模型优势:YOLOv5的特点和优势
- 系统优势:Web应用的特点和优势
-
检测能力
- 列出所有16类检测目标
- 显示类别的中英文对照
- 展示系统的检测范围
-
性能指标总结
- 从训练结果中提取最终性能
- 以百分比形式展示
- 直观展示模型性能
-
应用场景
- 城市规划:识别建筑物、道路
- 交通监控:检测车辆、船舶
- 环境监测:识别工业设施
- 军事侦察:检测军事目标
- 农业监测:识别农田区域
-
未来改进
- 模型优化方向
- 功能扩展计划
- 性能优化方向
- 用户体验改进
-
技术栈总结
- 列出使用的所有技术
- 说明各技术的用途
10. 技术栈详解
10.1 深度学习框架
10.1.1 PyTorch
PyTorch是Facebook开源的深度学习框架,具有以下特点:
- 动态计算图:支持动态构建计算图,灵活性高
- Pythonic:与Python深度集成,代码简洁
- GPU加速:支持CUDA,充分利用GPU资源
- 丰富的API:提供完整的深度学习工具链
在本项目中的应用:
- 模型定义和训练
- 张量操作和计算
- 自动梯度计算
- GPU加速推理
10.1.2 YOLOv5
YOLOv5是Ultralytics开发的目标检测模型,基于PyTorch实现:
- 模块化设计:代码结构清晰,易于修改
- 预训练权重:提供多种规模的预训练模型
- 训练工具:提供完整的训练和评估工具
- 部署友好:支持多种部署格式
在本项目中的应用:
- 目标检测模型
- 模型推理
- 结果后处理
10.2 图像处理库
10.2.1 OpenCV
**OpenCV (Open Source Computer Vision Library)**是开源的计算机视觉库:
- 图像处理:提供丰富的图像处理函数
- 跨平台:支持Windows、Linux、macOS
- 性能优化:底层使用C++实现,性能优秀
- 功能全面:涵盖图像处理、视频处理、机器学习等
在本项目中的应用:
- 图像读取和保存
- 图像格式转换(RGB/BGR)
- 图像尺寸调整
- 边界框绘制
- 文本标注
10.2.2 Pillow (PIL)
Pillow是Python图像处理库:
- 易用性:API简单直观
- 格式支持:支持多种图像格式
- 图像操作:提供基本的图像操作功能
在本项目中的应用:
- 图像文件读取
- 图像格式转换
- 图像预览显示
10.3 Web框架
10.3.1 Streamlit
Streamlit是专为数据科学和机器学习应用设计的Web框架:
- 快速开发:用Python代码即可构建Web应用
- 交互组件:提供丰富的交互组件
- 自动更新:代码修改后自动刷新界面
- 部署简单:支持多种部署方式
在本项目中的应用:
- Web界面构建
- 用户交互处理
- 数据可视化展示
- 文件上传处理
核心组件使用:
st.title()、st.header():标题显示st.sidebar:侧边栏导航st.file_uploader():文件上传st.button():按钮交互st.image():图像显示st.dataframe():表格显示st.pyplot():图表显示st.metric():指标卡片st.columns():多列布局
10.4 数据处理库
10.4.1 NumPy
NumPy是Python科学计算的基础库:
- 数组操作:高效的N维数组操作
- 数学函数:丰富的数学函数库
- 性能优化:底层使用C实现,性能优秀
在本项目中的应用:
- 图像数组操作
- 数值计算
- 数组格式转换
10.4.2 Pandas
Pandas是Python数据分析库:
- 数据结构:提供DataFrame和Series数据结构
- 数据处理:强大的数据清洗和处理功能
- 数据可视化:与Matplotlib集成,便于可视化
在本项目中的应用:
- 训练结果数据解析
- 历史记录数据处理
- 数据表格展示
- 统计分析
10.5 可视化库
10.5.1 Matplotlib
Matplotlib是Python绘图库:
- 图表类型:支持多种图表类型
- 高度可定制:可以精细控制图表样式
- 中文字体支持:可以配置中文字体
在本项目中的应用:
- 训练曲线绘制
- 类别分布图表
- 趋势分析图表
- 性能指标可视化
中文字体配置:
matplotlib.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS', 'DejaVu Sans']
matplotlib.rcParams['axes.unicode_minus'] = False
10.6 数据库
10.6.1 SQLite
SQLite是轻量级嵌入式数据库:
- 零配置:无需安装和配置
- 文件存储:数据库存储在单个文件中
- SQL支持:支持标准SQL语法
- 跨平台:支持多种操作系统
在本项目中的应用:
- 检测历史记录存储
- 数据持久化
- 历史记录查询
10.7 其他工具
10.7.1 YAML
YAML是数据序列化格式:
- 可读性强:人类可读的格式
- 配置管理:常用于配置文件
在本项目中的应用:
- 数据集配置(DOTA.yaml)
- 超参数配置
10.7.2 JSON
JSON是轻量级数据交换格式:
- 易解析:易于程序解析
- 通用性:广泛支持
在本项目中的应用:
- 检测结果序列化
- 数据库字段存储
11. 系统实现原理
11.1 系统架构
系统采用前后端一体化架构:
用户界面 (Streamlit)
↓
业务逻辑层 (streamlit_app.py)
↓
模型推理层 (YOLOv5)
↓
数据存储层 (SQLite)
11.2 模型加载机制
11.2.1 模型缓存
使用Streamlit的@st.cache_resource装饰器缓存模型:
@st.cache_resource
def load_model():
"""加载YOLOv5模型"""
# 模型加载代码
return model, device
优势:
- 避免重复加载模型
- 提高应用响应速度
- 节省内存资源
11.2.2 PyTorch 2.6+兼容性
处理PyTorch 2.6+的weights_only限制:
# 临时修改torch.load以支持weights_only=False
original_load = torch.load
def patched_load(*args, **kwargs):
kwargs['weights_only'] = False
return original_load(*args, **kwargs)
torch.load = patched_load
try:
model = attempt_load(str(MODEL_PATH), map_location=device)
finally:
torch.load = original_load
11.3 图像处理流程
11.3.1 图像预处理
def preprocess_image(img, img_size=640):
"""预处理图像"""
# 1. 转换为numpy数组
if isinstance(img, Image.Image):
img0 = np.array(img)
img0 = cv2.cvtColor(img0, cv2.COLOR_RGB2BGR)
else:
img0 = np.array(img)
# 2. 调整尺寸
img = cv2.resize(img0, (img_size, img_size))
# 3. BGR to RGB, HWC to CHW
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
# 4. 转换为张量并归一化
img = torch.from_numpy(img).float()
img /= 255.0
# 5. 添加batch维度
if img.ndimension() == 3:
img = img.unsqueeze(0)
return img, img0
11.3.2 目标检测流程
def detect_objects(model, device, img, img0, conf_thres=0.4, iou_thres=0.5):
"""执行目标检测"""
# 1. 移动到设备并转换为float
img = img.to(device).float()
# 2. 模型推理
with torch.no_grad():
pred = model(img, augment=False)[0]
# 3. NMS后处理
pred = non_max_suppression(pred, conf_thres, iou_thres,
classes=None, agnostic=False)
# 4. 处理检测结果
detections = []
for i, det in enumerate(pred):
if det is not None and len(det):
# 坐标缩放回原图尺寸
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img0.shape).round()
# 提取检测信息
for *xyxy, conf, cls in det:
detections.append({
'class_id': int(cls),
'class_name': model.names[int(cls)],
'class_name_cn': CLASS_NAMES_CN.get(model.names[int(cls)], model.names[int(cls)]),
'confidence': float(conf),
'bbox': [int(x) for x in xyxy]
})
return detections
11.3.3 结果可视化
def draw_detections(img0, detections, names):
"""在图像上绘制检测框"""
# 1. 格式转换
if isinstance(img0, Image.Image):
img0 = np.array(img0)
# 2. RGB to BGR (OpenCV格式)
if len(img0.shape) == 3:
img = cv2.cvtColor(img0, cv2.COLOR_RGB2BGR)
# 3. 绘制检测框
for det in detections:
x1, y1, x2, y2 = det['bbox']
class_name_cn = det.get('class_name_cn', det['class_name'])
label = f"{class_name_cn} {det['confidence']:.2f}"
color = colors[det['class_id']]
plot_one_box([x1, y1, x2, y2], img, label=label,
color=color, line_thickness=2)
# 4. BGR to RGB (显示格式)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return img
11.4 数据库操作流程
11.4.1 数据库初始化
def init_database():
"""初始化SQLite数据库"""
conn = sqlite3.connect(str(DB_PATH))
c = conn.cursor()
c.execute('''
CREATE TABLE IF NOT EXISTS detection_history (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT NOT NULL,
image_name TEXT NOT NULL,
image_path TEXT,
num_detections INTEGER,
detections TEXT,
processing_time REAL,
confidence_threshold REAL
)
''')
conn.commit()
conn.close()
11.4.2 数据保存流程
- 检测完成后:获取检测结果和处理时间
- 数据序列化:将检测结果转换为JSON字符串
- 数据库插入:执行INSERT语句保存记录
- 事务提交:确保数据持久化
11.4.3 数据查询流程
- 执行查询:按时间倒序查询记录
- 结果获取:获取查询结果集
- 数据处理:转换为DataFrame格式
- 可视化展示:生成图表和表格
11.5 训练结果解析
11.5.1 文件格式
YOLOv5的results.txt文件格式:
epoch mem box obj cls total targets img_size precision recall mAP50 mAP50-95 val_box val_obj val_cls [lr0 lr1 lr2]
示例:
0/99 6.57G 0.07875 0.04941 0.03832 0.1665 20 1024 0.2585 0.3012 0.2265 0.08983 0.06072 0.03649 0.03224
11.5.2 解析实现
def parse_training_results(results_path):
"""解析训练结果文件"""
data = []
with open(results_path, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split()
if len(parts) >= 15:
try:
# 解析epoch
epoch = int(parts[0].split('/')[0])
# 解析训练损失 (索引2-5)
train_box_loss = float(parts[2])
train_obj_loss = float(parts[3])
train_cls_loss = float(parts[4])
train_loss = float(parts[5])
# 解析性能指标 (索引8-11)
precision = float(parts[8])
recall = float(parts[9])
map50 = float(parts[10])
map50_95 = float(parts[11])
# 解析验证损失 (索引12-14)
val_box_loss = float(parts[12])
val_obj_loss = float(parts[13])
val_cls_loss = float(parts[14])
# 保存数据
data.append({...})
except:
continue
return pd.DataFrame(data)
11.6 界面交互流程
11.6.1 页面路由
def main():
# 初始化数据库
init_database()
# 侧边栏导航
page = st.sidebar.radio("选择页面", pages)
# 根据选择显示对应页面
if page == "系统介绍":
show_introduction(config)
elif page == "数据分析":
show_data_analysis(config)
# ... 其他页面
11.6.2 检测流程
- 用户上传图像:通过
st.file_uploader上传 - 参数设置:通过
st.sidebar.slider设置阈值 - 点击检测按钮:触发检测流程
- 显示加载状态:使用
st.spinner显示处理中 - 执行检测:调用检测函数
- 保存记录:将结果保存到数据库
- 显示结果:展示检测结果和统计信息
11.7 性能优化
11.7.1 模型缓存
- 使用
@st.cache_resource缓存模型 - 避免每次请求都重新加载模型
- 显著提高响应速度
11.7.2 数据类型优化
- 使用
float32而非float16,避免类型不匹配 - 确保模型和输入数据类型一致
- 提高推理稳定性
11.7.3 图像处理优化
- 使用OpenCV进行图像处理,性能优于PIL
- 批量处理时使用向量化操作
- 减少不必要的格式转换
12. 总结
12.1 项目成果
本项目成功实现了一个完整的卫星遥感图像目标检测系统,具有以下特点:
- 功能完整:涵盖数据展示、目标检测、历史记录、模型分析等完整功能
- 性能优秀:模型在DOTA数据集上达到68.07%的mAP@0.5
- 界面友好:基于Streamlit构建,界面简洁直观
- 技术先进:采用最新的YOLOv5算法,检测速度快、精度高
- 可扩展性强:代码结构清晰,易于扩展和维护
12.2 技术亮点
- 深度学习应用:成功将YOLOv5应用于遥感图像检测
- Web应用开发:使用Streamlit快速构建交互式Web应用
- 数据可视化:丰富的图表展示训练过程和检测结果
- 数据库设计:合理的数据表设计,支持历史记录查询
- 中文本地化:完整的中文界面和类别名称支持
12.3 应用价值
本系统可以应用于:
- 城市规划:自动识别建筑物、道路等基础设施
- 交通监控:检测车辆、船舶等交通工具
- 环境监测:识别存储罐、港口等工业设施
- 军事侦察:检测飞机、直升机等军事目标
- 农业监测:识别农田、运动场等区域
12.4 未来改进方向
- 模型优化:尝试更大的模型或集成学习提升检测精度
- 功能扩展:支持视频流检测、批量处理等功能
- 性能优化:优化推理速度,支持边缘设备部署
- 用户体验:增加更多可视化选项和交互功能
- 数据管理:支持用户自定义数据集和模型训练

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)