RAG开发
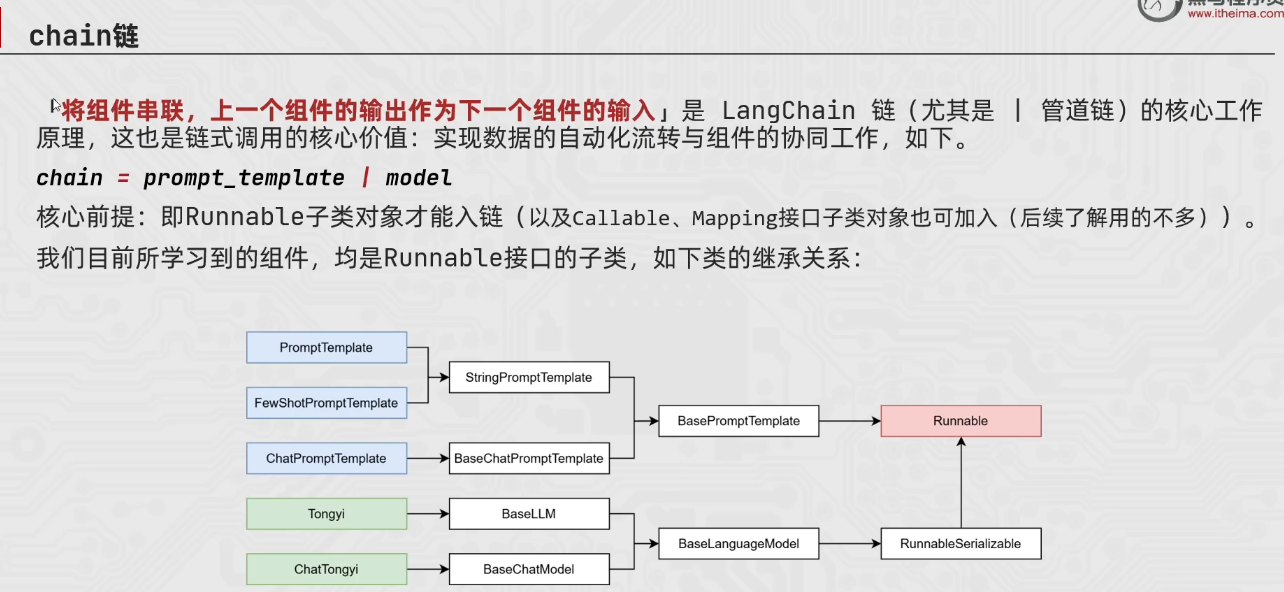
langchain简介
核心理念:为各种llms实现通用的接口,将llms相关组件链接在一起,简化llms应用开发难度(相当于编程SDK(software development kit))
主要功能: all in langchain
①prompts(优化提示词)
②models(调用各类模型)
③history(管理会话历史记录/记忆)
④indexes(管理和分析各类文档)
⑤chains(构建功能执行链条)
⑥agent(构建智能体)
支持的三种类型的模型:
LLMs
chat models
embeddings models
langchain环境部署
pip install langchain langchain-community langchain-ollama dashscope chromadb -i https://pypi.tuna.tsinghua.edu.cn/simple
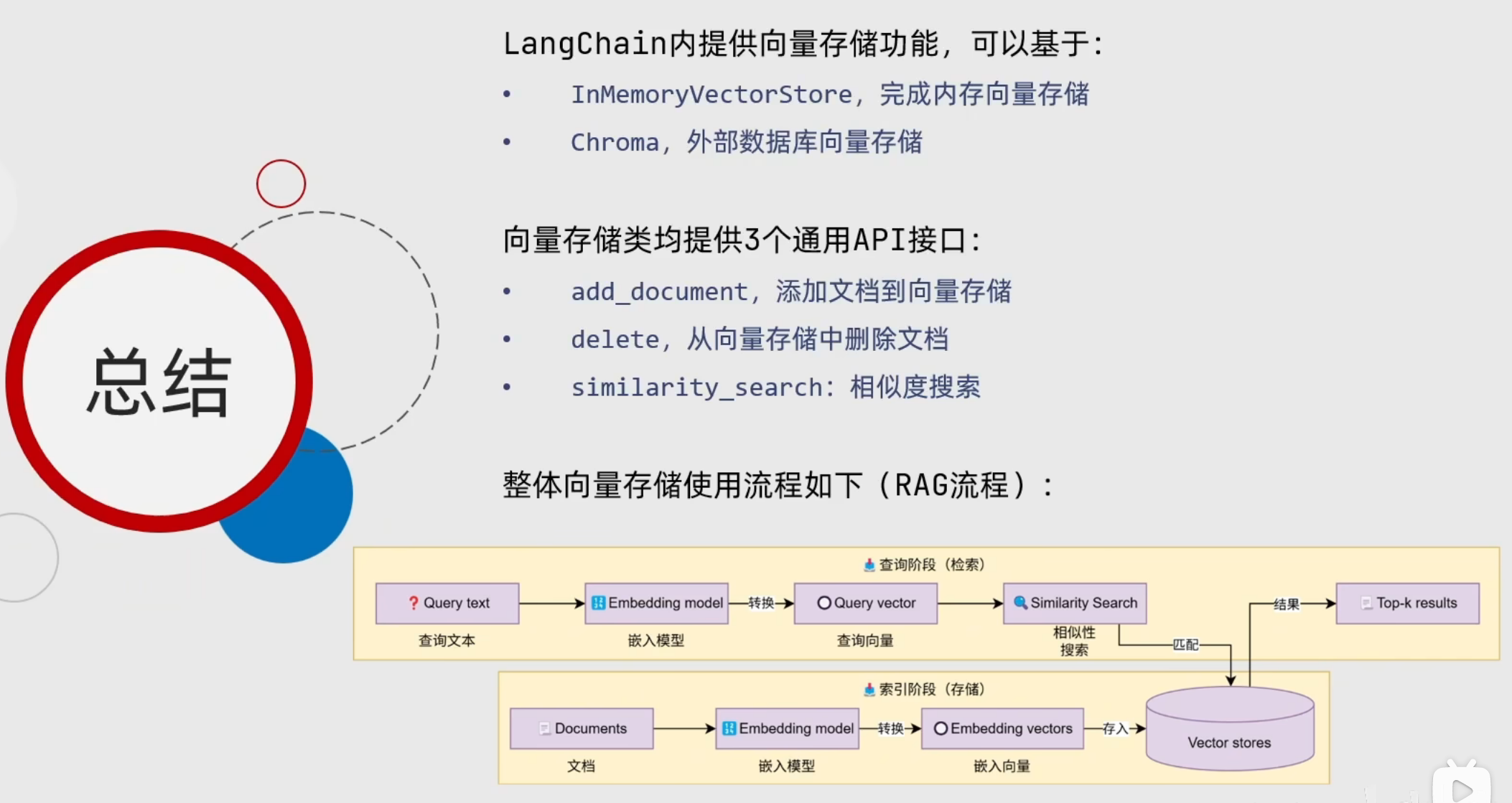
RAG介绍
通用基础大模型存在问题:
①知识不是实时的,不具备自动更新知识能力
②领域知识缺乏(主要知识来源于训练数据)
③幻觉问题(看似正确实则错误)
④数据安全性
RAG(retrieval augmented generation):检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正和补充生成的答案
RAG = 检索技术 + LLM提示
标准流程:
(1)索引:处理文档提取文本,切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)
(2)检索:用户输入的查询(query)被转换为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块
(3)生成:检索到的相关文本与原始查询共同构成提示词,输入大语言模型,生成精确且具备上下文关联的回答
离线流程:知识和信息——>向量嵌入——>存入向量库
在线流程:用户提问——>向量嵌入——>在向量库中匹配
向量的基础概念
将一段文字的语义信息,转换成一串固定长度的数字列表,让计算机能看懂文字的含义并做相似度计算
向量的计算(文本嵌入的过程),可借助文本嵌入模型实现
文本嵌入模型(如:text-embedding-v1)通过深度学习等技术,从文本提取语义特征并映射为固定长度的数字序列
向量的维度表示一段文本在多个抽象语义特征方面的强度:
维数代表模型用多少个抽象语义特征来描述文本
维度越多,做语义匹配越精准
但性能压力也会增强
余弦相似度算法
向量的数字序列,共同决定了向量在高维空间中的方向和长度。
余弦相似度主要为了撇除长度的影响,得到方向的夹角。夹角越小越相似,即方向相同
余弦相似度 = 两个向量的点积 / 两个向量模长的乘积
(即两个向量夹角)
import numpy as np
# 计算点积
def get_dot(vec_a,vec_b):
if len(vec_a) != len(vec_b):
raise ValueError
dot_sum = 0
for a,b in zip(vec_a,vec_b):
dot_sum += a * b
return dot_sum
# 计算模长
def get_norm(vec):
sum_square = 0
for v in vec:
sum_square += v * v
return np.sqrt(sum_square)
# 计算余弦相似度(计算两个向量夹角)
def cosine_similarity(vec_a,vec_b):
result = get_dot(vec_a,vec_b) / (get_norm(vec_a) * get_norm(vec_b))
return result
if __name__ == '__main__':
vec_a = [0.5, 0.5]
vec_b = [0.7, 0.7]
vec_c = [0.7, 0.5]
vec_d = [-0.6, -0.5]
print("ab:", cosine_similarity(vec_a, vec_b))
print("ac:", cosine_similarity(vec_a, vec_c))
print("ad:", cosine_similarity(vec_a, vec_d))
langchain调用大语言模型
from langchain_community.llms.tongyi import Tongyi
# 实例化模型 注意:qwen-max是大语言模型 qwen3-max是聊天模型
llm = Tongyi(model='qwen-max')
# 模型推理
res = llm.invoke("帮我讲个笑话,要很冷,且简短") # 调用invoke方法向模型提问(invoke:调用)
print(res)
'''
#ollama本地访问大语言模型
from langchain_ollama import OllamaLLM
model = OllamaLLM(model='qwen3-vl:8b')
res = model.invoke(input="你是谁呀?你能做什么?")
print(res)
'''
langchain模型的流式输出
'''
from langchain_community.llms.tongyi import Tongyi
model = Tongyi(model = "qwen-max")
res = model.stream(input = "给我讲一个简短的冷笑话")
for chunk in res:
print(chunk,end=' ',flush=True) # flush 是为了让结果立刻刷新出来
'''
from langchain_ollama import OllamaLLM
model = OllamaLLM(model="qwen3-vl:8b")
res = model.stream(input="你是谁呀?能做什么")
for chunk in res:
print(chunk, end=' ', flush=True)
langchain调用聊天模型
AImessage:AI输出的消息,可以是针对问题的回答(=OpenAI库的assistant角色)
HumanMessage:人类消息(=OpenAI库的user角色)
SystemMessage:可以用于指定模型具体所处的环境和背景(=OpenAI库的system角色)
'''
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage,SystemMessage,AIMessage
# 得到模型对象 qwen3-max就是聊天模型
model = ChatTongyi(model = "qwen3-max")
# 准备消息列表
messages = [
SystemMessage(content = "你是一个边塞诗人"),
HumanMessage(content = "给我写一首唐诗"),
AIMessage(content = "锄禾日当午,汗滴禾下土。谁知盘中餐,粒粒皆辛苦。"),
HumanMessage(content = "按照上面你写的格式,再写一首给我看看")
]
# 调用stream流式输出
res = model.stream(input=messages)
# for循环打印输出 要通过.content来获取到内容,不然输出乱七八糟
for chunk in res:
print(chunk.content,end="",flush=True)
'''
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage,SystemMessage,AIMessage
# 得到模型对象 qwen3-max就是聊天模型
model = ChatOllama(model = "qwen3-vl:8b")
# 准备消息列表
messages = [
SystemMessage(content = "你是一个边塞诗人"),
HumanMessage(content = "给我写一首唐诗"),
AIMessage(content = "锄禾日当午,汗滴禾下土。谁知盘中餐,粒粒皆辛苦。"),
HumanMessage(content = "按照上面你写的格式,再写一首给我看看")
]
# 调用stream流式输出
res = model.stream(input=messages)
# for循环打印输出 要通过.content来获取到内容,不然输出乱七八糟
for chunk in res:
print(chunk.content,end="",flush=True)
langchain消息简写形式
from langchain_community.chat_models.tongyi import ChatTongyi
model = ChatTongyi(model = "qwen3-max")
messages = [
("system", "你是一个边塞诗人"),
("human", "帮我写一首唐诗"),
("ai", "锄禾日当午吗,汗滴禾下土。谁知盘中餐,粒粒皆辛苦。"),
("human", "你按照上面你给的格式,再写一首")
]
res = model.stream(input=messages)
for chunk in res:
print(chunk.content, end="", flush=True)
原来使用类对象时是静态的,一步到位 直接得到了message类的类对象
简写形式是动态的(元组),需要在运行时,由langchain机制转换为message类对象
好处在于:简写形式避免导包,写起来更简单,更重要的是支持在内部填充{ 变量 }占位
可在运行时填充具体值(提示词模板)
langchain调用嵌入模型
# from langchain_community.embeddings import DashScopeEmbeddings
#
# # 创建模型对象 不传model默认为 text-embeddings-v1
# model = DashScopeEmbeddings()
#
# # 将字符串转化为向量(这样计算机才嫩读取)
# print(model.embed_query("我喜欢你")) # 只读取一个字符串
# print(model.embed_documents(["我真的好喜欢你", "我稀饭你", "晚上吃什么"])) # 读取多个字符串
from langchain_ollama.embeddings import OllamaEmbeddings
model = OllamaEmbeddings(model="qwen3-embedding:4b")
print(model.embed_query("我喜欢你"))
print(model.embed_documents(["我喜欢你", "我爱你", "我超级爱你"]))
总结目前已掌握的LangChain API
(阿里云千问/ollama本地调用)
LLMs:from langchain_community.llms.tongyi import Tongyi or from langchain_ollama import OllamaLLM
聊天模型:from langchai_community.chat_models.tongyi import ChatTongyi or from langchain_ollama import ChatOllama
以上两种模型均支持invoke批量和stream流式 两种方法
文本嵌入模型:from langchain_community.embeddings import DashScopeEmbeddings or from langchain_ollama import OllamaEmbeddings
支持embed_query单次转换 还有 embed_documents 批量转换
langchain通用提示词模板

from langchain_core.prompts import PromptTemplate
from langchain_community.llms.tongyi import Tongyi
# zero_shot思想
prompt_template = PromptTemplate.from_template( # 创建类对象,调用方法
"我的邻居姓{lastname},刚生了一个{gender},你帮我起个名字,简单回答"
) # 相较于字符串 使用模板类更容易做标准化模板
model = Tongyi(model="qwen-max")
# 调用.format方法注入信息
# prompt_text = prompt_template.format(lastname="张",gender="男")
# res = model.invoke(input = prompt_text)
# print(res)
# 链式
chain = prompt_template | model
res = chain.invoke(input={"lastname":"张","gender":"男"})
print(res)
fewshot提示词模板
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_community.llms.tongyi import Tongyi
# 示例的模板
example_template = PromptTemplate.from_template("单词:{word},反义词:{antonym}")
# 示例动态数据的注入
examples_data = [
{"word": "大", "antonym": "小"},
{"word": "上", "antonym": "下"}
]
# 调用方法
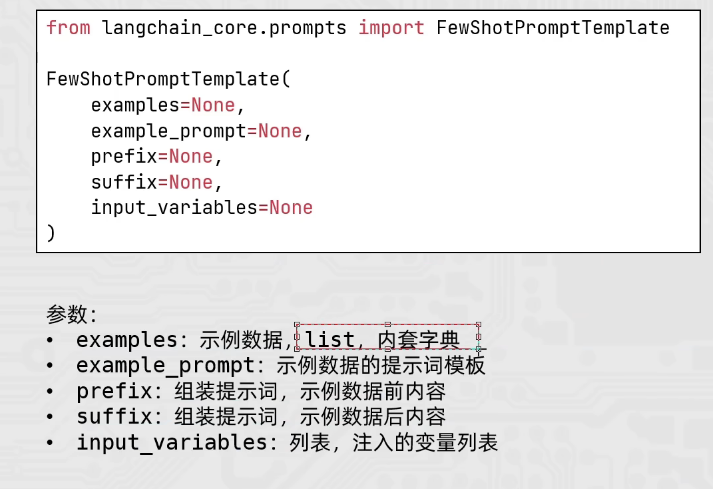
few_shot_template = FewShotPromptTemplate(
example_prompt=example_template, # 示例数据的模板
examples=examples_data, # 示例的数据(用来注入动态数据的),list内套字典
prefix="告知我单词的反义词,我提供一下示例", # 示例之前的提示词
suffix="基于前面的示例,{input_word}的反义词是?", # 示例之后的提示词
input_variables=["input_word"] # 声明在前缀或后缀中所需要的注入的变量名
)
prompt_text = few_shot_template.invoke(input={"input_word": "左"}).to_string() # 调用to_string这个方法使得输出更易读
print(prompt_text)
model = Tongyi(model="qwen-max")
print(model.invoke(input=prompt_text))
模板类的format和invoke方法
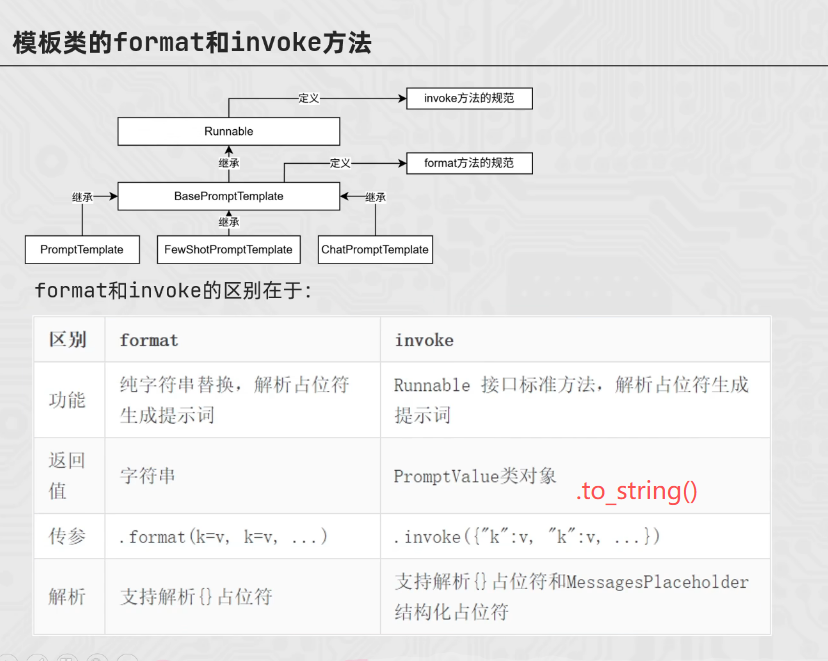
from langchain_core.prompts import PromptTemplate
template = PromptTemplate.from_template("我的邻居是:{lastname},最喜欢{hobby}")
res = template.format(lastname="周杰伦",hobby="唱歌")
print(res)
res2 = template.invoke({"lastname":"林俊杰","hobby":"和周杰伦一起唱歌"}).to_string()
print(res2)
ChatPromptTemplate的使用
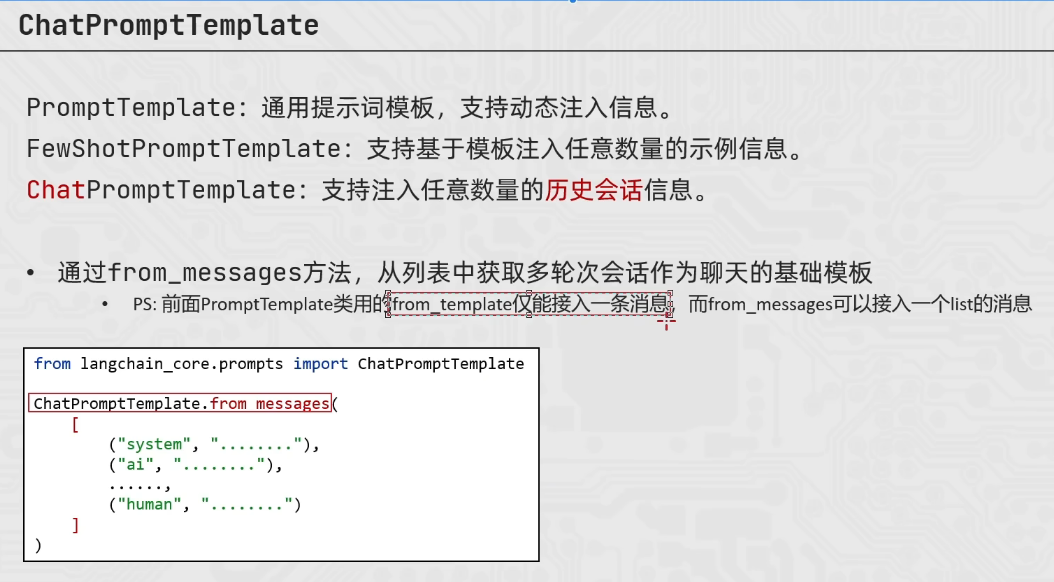
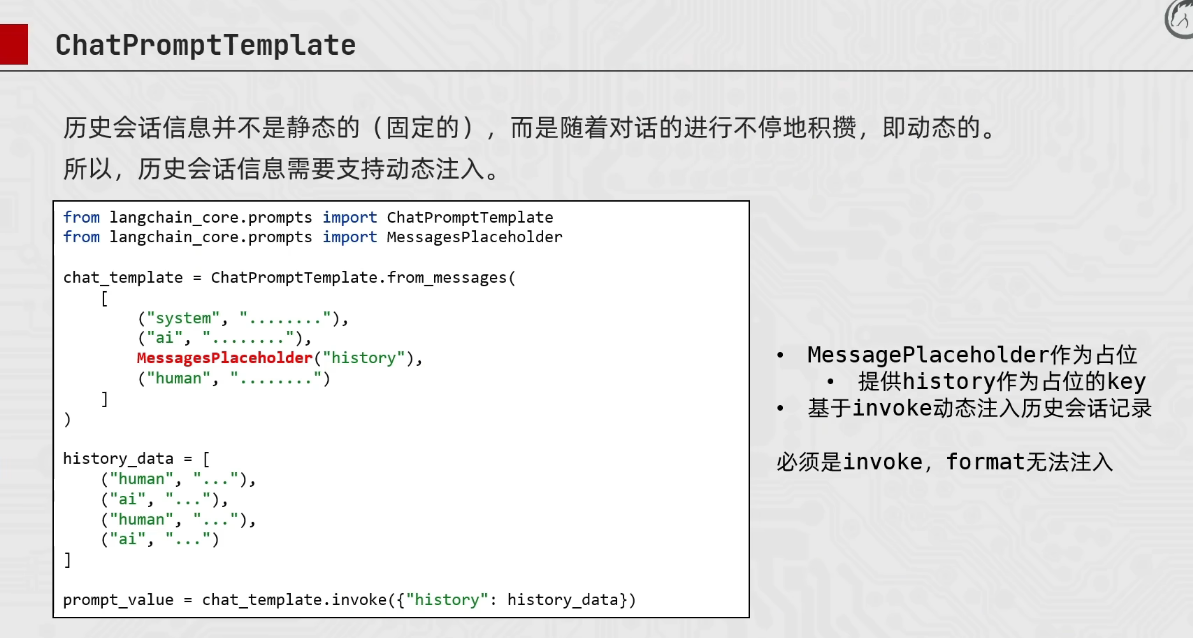
from langchain_core.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_community.chat_models.tongyi import ChatTongyi
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system","你是一个边塞诗人"),
MessagesPlaceholder("history"),
("user","再来一首唐诗")
]
)
history_data = [
("human","你来写一首唐诗"),
("ai","床前明月光,疑是地上霜。举头望明月,低头思故乡"),
("human","好诗,再给我来一首"),
("ai","锄禾日当午,汗滴禾下土。谁之盘中餐,粒粒皆辛苦。")
]
# 返回类型是stringpromptvalue这个类 所以需要to_string()
prompt_text = chat_prompt_template.invoke({"history":history_data}).to_string()
model = ChatTongyi(model="qwen-max")
res = model.invoke(prompt_text)
print(res.content)
Chain的基础使用
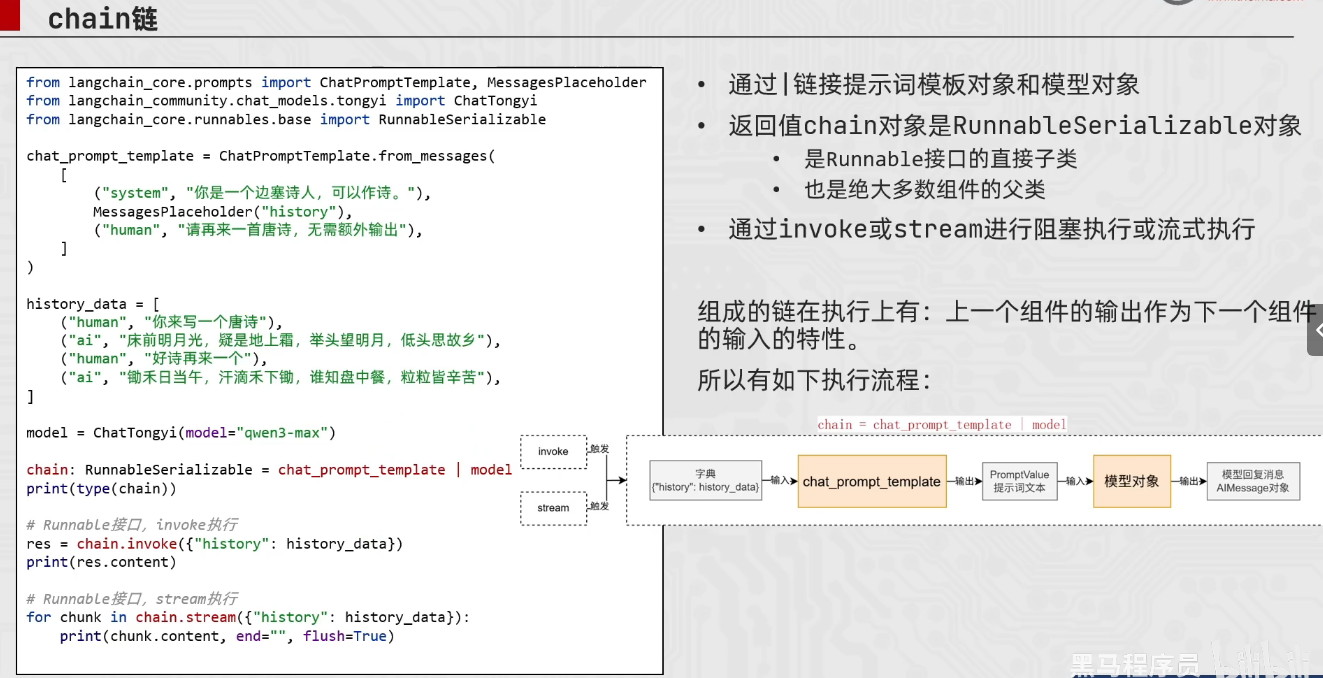
from langchain_core.prompts import ChatPromptTemplate,MessagesPlaceholder
from langchain_community.chat_models.tongyi import ChatTongyi
chat_prompt_template = ChatPromptTemplate.from_messages(
[
("system","你是一个边塞诗人"),
MessagesPlaceholder("history"),
("user","再来一首唐诗")
]
)
history_data = [
("human","你来写一首唐诗"),
("ai","床前明月光,疑是地上霜。举头望明月,低头思故乡"),
("human","好诗,再给我来一首"),
("ai","锄禾日当午,汗滴禾下土。谁之盘中餐,粒粒皆辛苦。")
]
model = ChatTongyi(model="qwen-max")
# 组成链,要求每一个组件都是runnable接口的子类
chain = chat_prompt_template | model
# # 通过链去调用invoke/stream
# res = chain.invoke({"history": history_data})
# print(res.content)
# 通过stream流式输出
for chunk in chain.stream({"history": history_data}):
print(chunk.content,end="",flush=True)
或运算符的重载
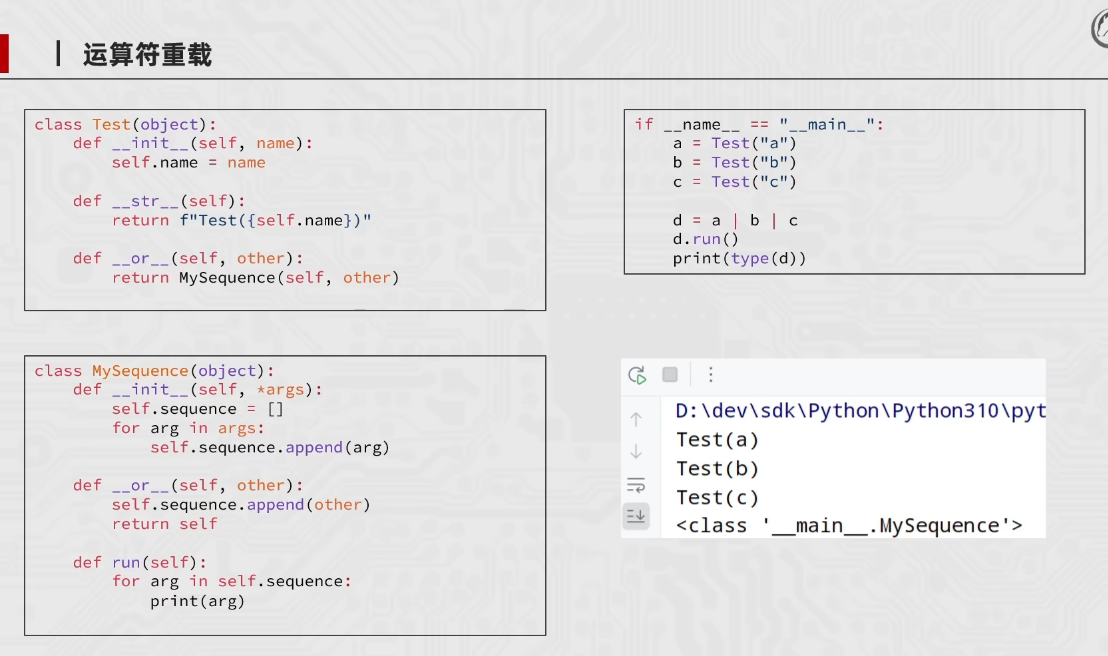
# 定义第一个类 Test,继承自object(Python3中所有类默认继承,可省略)
class Test(object):
# 构造方法:创建Test类的对象时,自动调用的方法
# self 代表当前创建的对象本身,name 是传入的参数(给对象起的名字)
def __init__(self,name):
# 给当前对象绑定一个name属性,值等于传入的name参数
self.name = name
# 【核心重点】重写Python的 | 或运算符
# 魔法方法__or__:当对象使用 | 运算符时,自动触发这个方法
# self:| 左边的对象,other:| 右边的对象
def __or__(self,other):
# 把左右两个对象,打包传入MySequence类,返回一个MySequence对象
return MySequence(self,other)
# 重写打印对象时的显示内容(默认打印对象内存地址,重写后更直观)
def __str__(self):
# 打印Test对象时,直接返回它的name属性值
return self.name
# 定义第二个类 MySequence,用来存储Test对象的序列(管理用|连接的所有对象)
class MySequence(object):
# 构造方法:*args 表示接收【任意多个参数】(0个、1个、多个都可以)
def __init__(self,*args):
# 创建一个空列表,用来存储所有用|连接的Test对象
self.sequence = []
# 遍历传入的所有参数,逐个添加到sequence列表中
for arg in args:
self.sequence.append(arg)
# 【核心重点】再次重写|运算符,实现【链式调用】(a|b|c|d...)
# 因为a|b会返回MySequence对象,再|c时,就会调用这个方法
def __or__(self,other):
# 把|右边的新对象,追加到自身的sequence列表里
self.sequence.append(other)
# 关键:返回自身(self),这样才能继续用|连接下一个对象
return self
# 自定义方法:执行序列,打印所有存储的Test对象的名字
def run(self):
# 遍历存储所有Test对象的列表
for i in self.sequence:
# 打印每个Test对象(因为Test重写了__str__,所以直接打印name)
print(i)
# 主程序入口:只有直接运行这个文件时,才会执行下面的代码
if __name__ == '__main__':
# 创建3个Test类的对象,分别命名为a、b、c
a = Test('a')
b = Test('b')
c = Test('c')
# 【核心逻辑】链式使用|运算符
# 第一步:a | b → 调用Test类的__or__ → 返回 MySequence(a, b)
# 第二步:上一步的结果 | c → 调用MySequence类的__or__ → 把c追加到列表,返回自身
d = a | b | c
# 调用MySequence的run方法,遍历打印所有对象
d.run()
# 打印d的类型,验证d是MySequence类的对象(不是Test对象)
print(type(d))
StrOutputParser
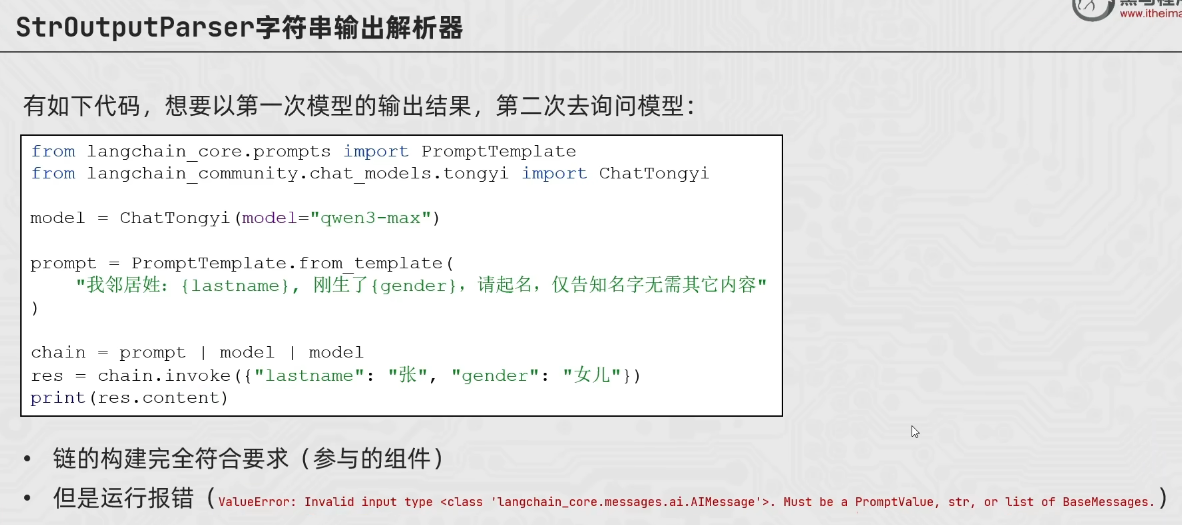
第二个model的接收参数不对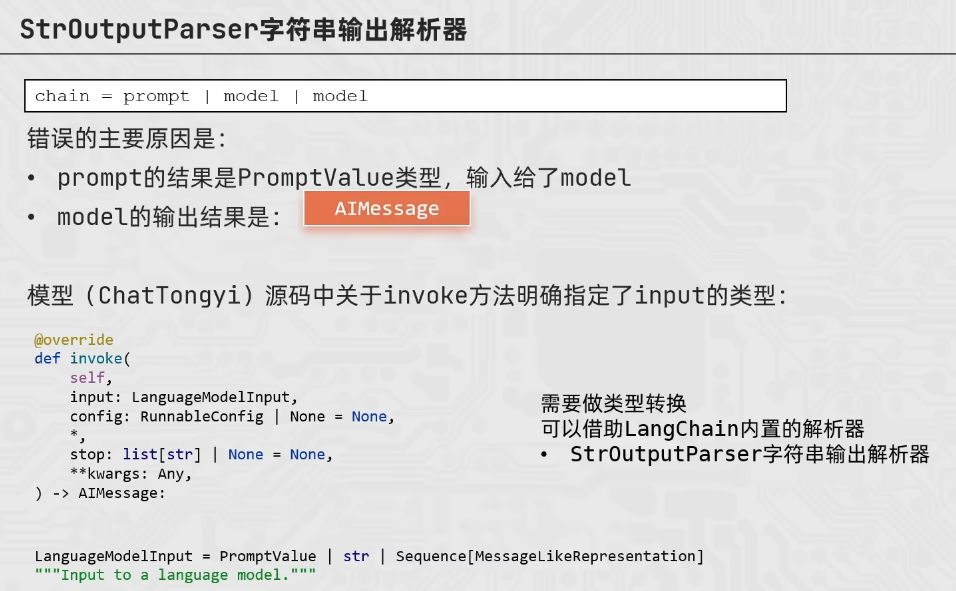
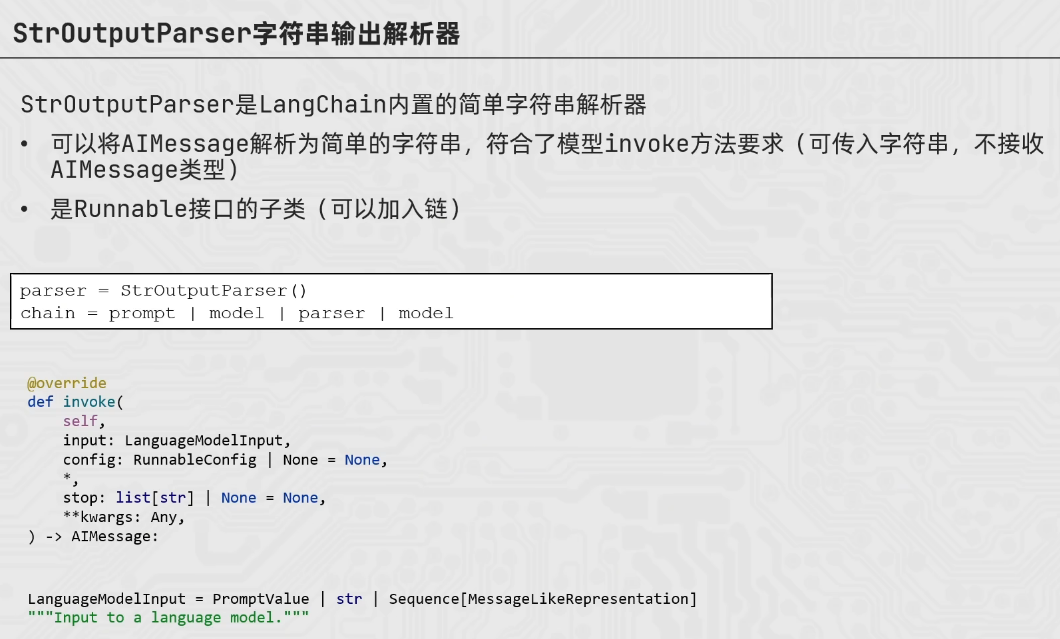
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
parser = StrOutputParser()
model = ChatTongyi(model="qwen3-max")
prompt = PromptTemplate.from_template(
"我的邻居姓:{lastname},刚生了{gender},请起名,仅告知我名字无需其他内容"
)
# chain = prompt | model | parser | model | parser
#
# res = chain.invoke({"lastname":"张","gender":"女"})
# print(res)
# 或者也可以不用parser(第二个model的输出仍为AIMessage)就需要.content直接获取内容
chain = prompt | model | parser | model
res = chain.invoke({"lastname":"张","gender":"女"})
print(res.content)
# 第一个模型输出的内容只有一个名字,再输入给第二个模型的时候没有记忆历史消息的功能,所以模型就乱回答了
JsonOutputParser和多模型链
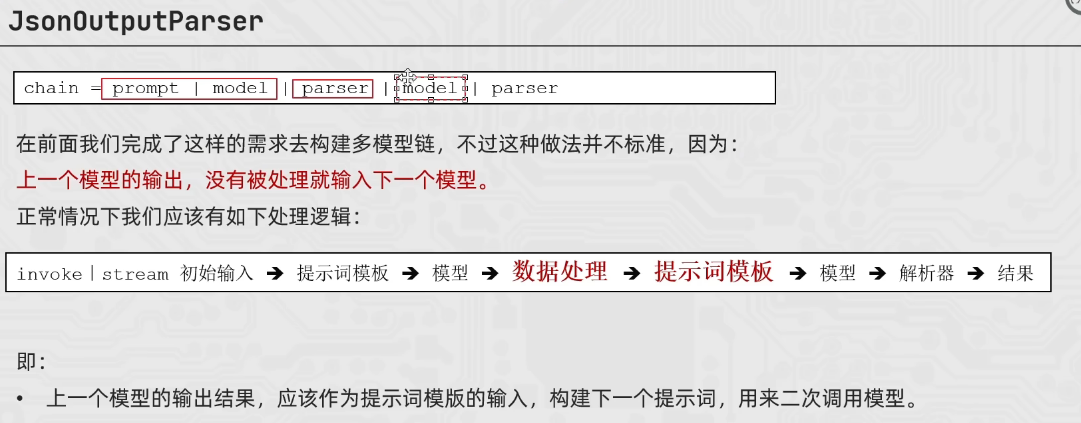

from langchain_core.prompts import PromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
strparser = StrOutputParser()
jsonparser = JsonOutputParser()
model = ChatTongyi(model="qwen3-max")
first_prompt = PromptTemplate.from_template(
"我的邻居姓{lastname},他们家刚生了一个小孩,性别{gender},请你帮他们给小孩起一个名字。回答名字给我即可。"
"注意以JSON格式返回给我,并且key是name,value就是你起的名字。严格按照格式要求返回给我"
)
second_prompt = PromptTemplate.from_template(
"姓名是{name},请你帮我解析含义"
)
chain = first_prompt | model | jsonparser | second_prompt| model | strparser
for chunk in chain.stream({"lastname":"黄","gender":"女"}):
print(chunk,end="",flush=True)
自定义函数加入链

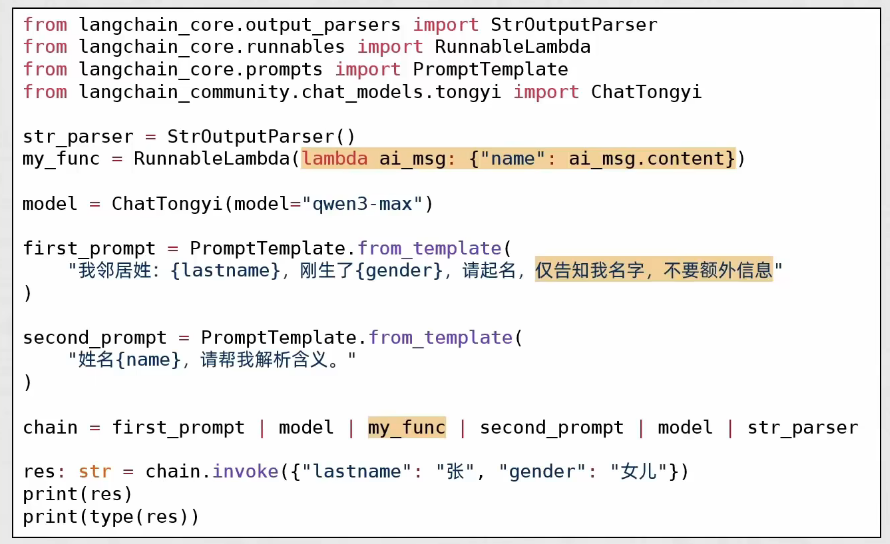

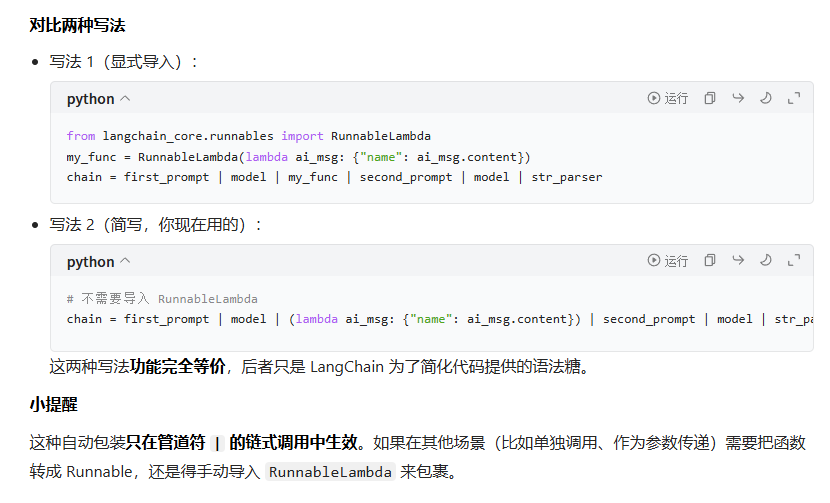
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser,JsonOutputParser
from langchain_community.chat_models.tongyi import ChatTongyi
str_outputparser = StrOutputParser()
model = ChatTongyi(model="qwen3-max")
first_prompt = PromptTemplate.from_template(
"我的邻居姓{lastname},他们家生了一个小孩,性别为{gender}。请你帮他们起一个名字,回答名字即可"
)
second_prompt = PromptTemplate.from_template(
"名字是{name},请你解析这个名字的含义"
)
chain = first_prompt | model | (lambda ai_msg:{"name":ai_msg.content}) | second_prompt | model | str_outputparser
for chunk in chain.stream({"lastname":"黄","gender":"女"}):
print(chunk,end="",flush=True)
memory临时记忆功能
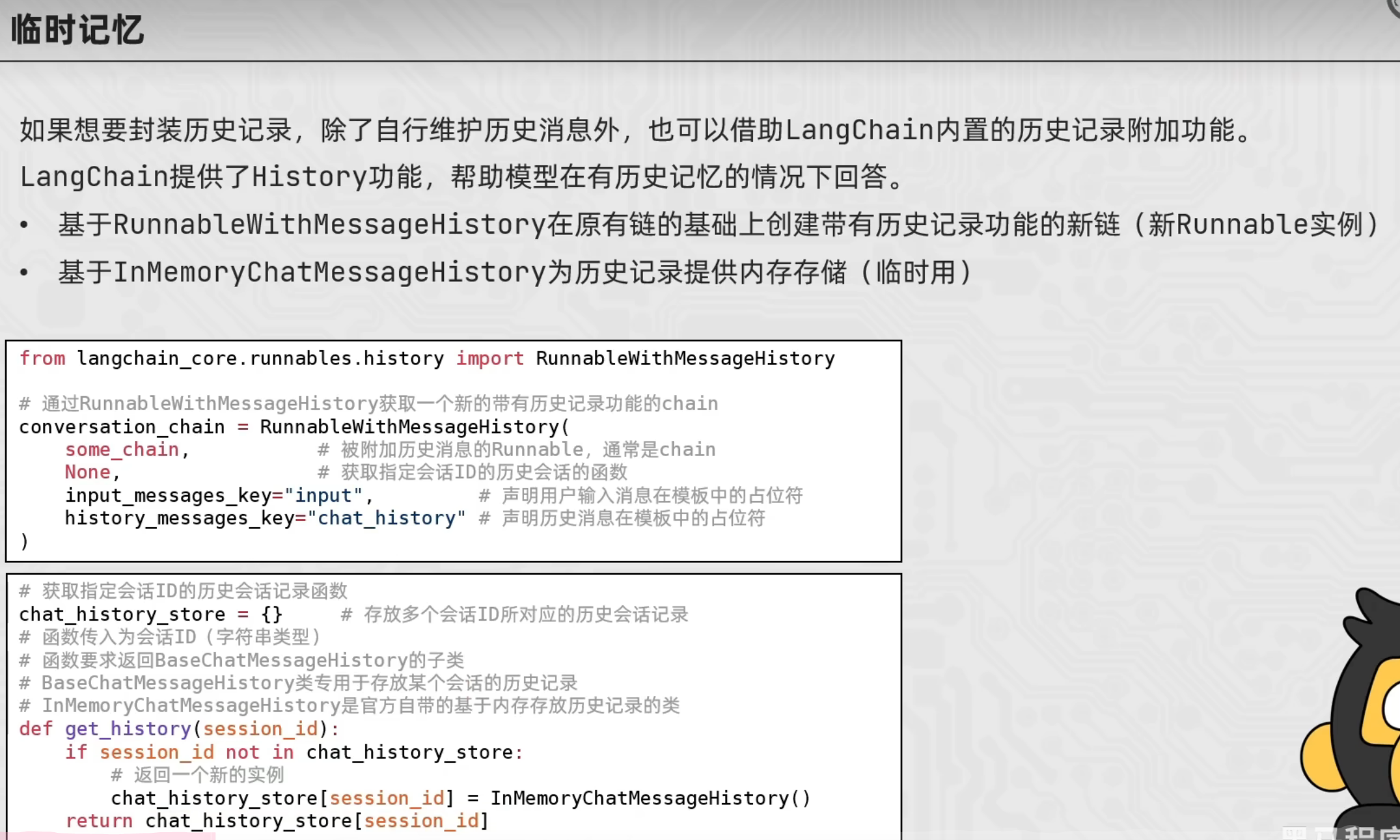
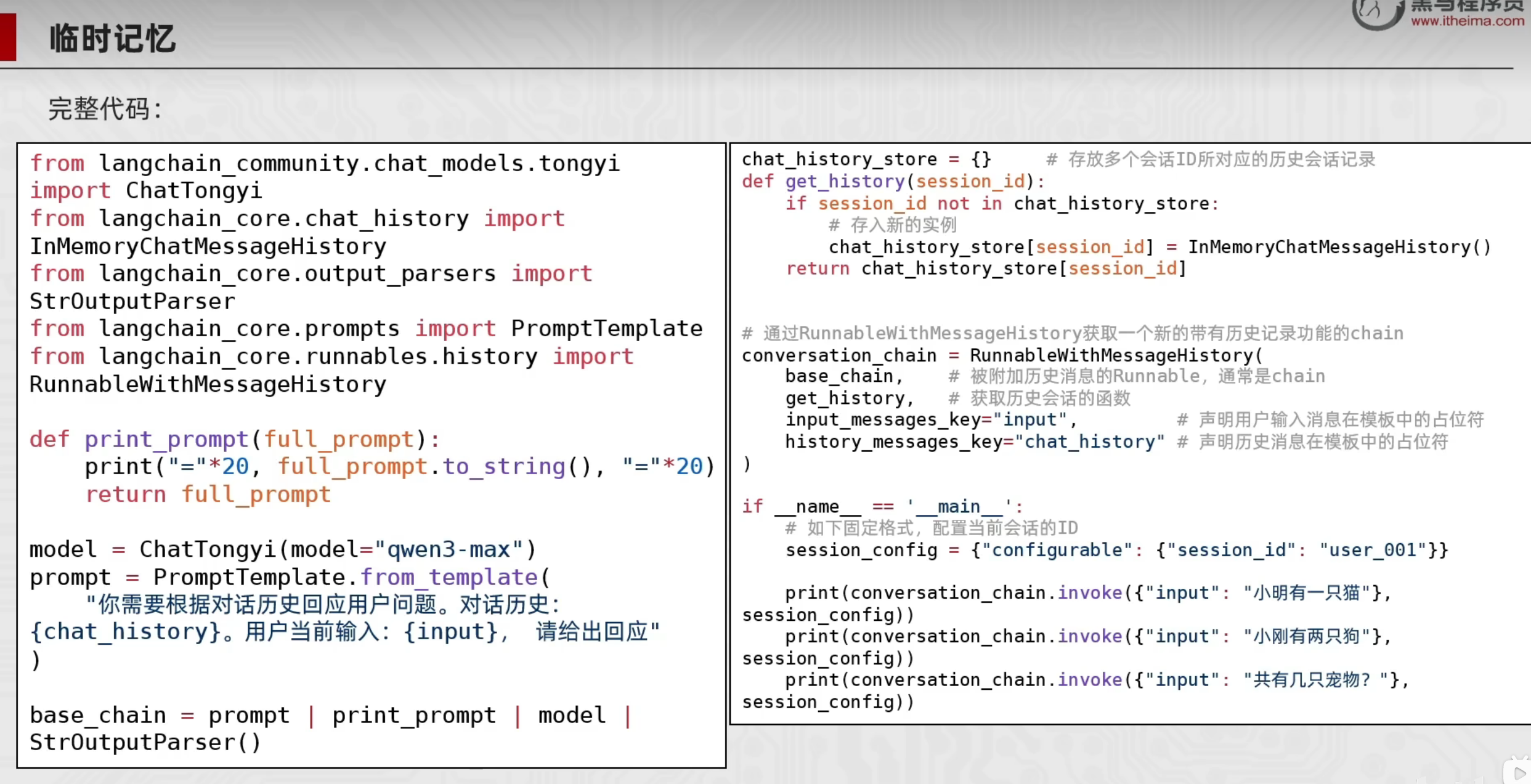
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.prompts import PromptTemplate,MessagesPlaceholder,ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.chat_history import InMemoryChatMessageHistory
# 选用模型 构建提示词模板和解析器 构建基础chain
model = ChatTongyi(model="qwen3-max")
# prompt = PromptTemplate.from_template(
# "你需要根据会话历史来回答用户的问题。对话历史{chat_history},用户提问{input},请回答"
# )
# 比通用提示词模板更为规范
prompt = ChatPromptTemplate.from_messages(
[
("system","你需要根据会话历史来回答用户的问题"),
MessagesPlaceholder("chat_history"),
("human","请回答如下问题:{input}")
]
)
str_parser = StrOutputParser()
base_chain = prompt | model | str_parser
###
# 获取对话ID,增加聊天记录实例
store = {}
def get_history(session_id):
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 构建增强链
conversation_chain = RunnableWithMessageHistory(
base_chain, # 被增强的链
get_history, # 实现函数:通过对话id获取InMemoryChatMessageHistory()实例
input_messages_key="input", # 用户输入在模板中的占位符
history_messages_key="chat_history" # 用户输入在模板中的占位符
)
# 实现以上业务
if __name__ == '__main__':
# 固定格式:添加langchain配置,为程序配置所需的session_id 字典套字典的模式
session_config = {
"configurable": {
"session_id": "user001"
}
}
res = conversation_chain.invoke({"input": "小明有2只猫"}, session_config) # 同时自动创建session_id
print("第一次执行:", res)
res = conversation_chain.invoke({"input": "小贝有1只狗"}, session_config)
print("第二次执行:", res)
res = conversation_chain.invoke({"input": "请问有几只宠物?"}, session_config)
print("第三次执行:", res)

长期会话记忆功能的实现
import os,json
from typing import Sequence
from langchain_community.chat_models import ChatTongyi
from langchain_core.messages import message_to_dict,messages_from_dict, BaseMessage
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnableWithMessageHistory
# message_to_dict: 单个消息对象(BaseMessage类实例) -> 字典
# messages_from_dict: [字典、字典...] -> [消息、消息...]
# aimessage humanmessage systemmessage都是BaseMessage的子类
class FileChatMessageHistory(BaseChatMessageHistory): # 用于替换临时记忆,作为文件存储会话记忆
def __init__(self,session_id,storage_path):
self.session_id = session_id # 会话id
self.storage_path = storage_path # 不同会话id的存储文件所在的文件夹路径
# 完整的文件路径(将上面的内容都拼接在一起)
self.file_path = os.path.join(self.session_id, self.storage_path)
# 确保文件夹是存在的(如果存在就不创建了 不存在就创建)
os.makedirs(os.path.dirname(self.file_path),exist_ok=True)
def add_messages(self,messages: Sequence[BaseMessage]) -> None:
# Sequence序列 类似与list tuple
all_messages = list(self.messages) # 已有的消息列表
all_messages.extend(messages) # 新的和已有的融合为1个list
# 将数据同步写入到本地文件中
# 类对象写入文件 -> 一堆二进制
# 为了方便, 可以将BaseMessage消息转换为字典(借助json模块以json字符串写入文件)
# 官方message_to_dict: 单个消息对象(BaseMessage类实例) -> 字典
# new_messages = []
# for message in all_messages:
# d = message_to_dict(message)
# new_messages.append(d)
# 用推导式更为简洁
new_messages = [message_to_dict(message) for message in all_messages]
# 将数据写入文件
with open(self.file_path,'w', encoding="utf-8") as f:
json.dump(new_messages, f) # 转换为json格式
# 获取消息 同时返回值是list[BaseMessage]
@property # @property装饰器将messages方法变为成员属性用
def messages(self) -> list[BaseMessage]:
# 当前文件内: list[字典]
try:
with open(self.file_path,'r',encoding="utf-8") as f:
messages_data = json.load(f) # 返回值就是list[字典]
return messages_from_dict(messages_data)
except FileNotFoundError: # 抓一下异常
return []
# 清除文件内容 往文件里面写一个空列表也相当于清除了
def clear(self) -> None:
with open(self.file_path,'w',encoding="utf-8") as f:
json.dump([],f)
# 下面的核心代码都一样 直接copy
# 选用模型 构建提示词模板和解析器 构建基础chain
model = ChatTongyi(model="qwen3-max")
# prompt = PromptTemplate.from_template(
# "你需要根据会话历史来回答用户的问题。对话历史{chat_history},用户提问{input},请回答"
# )
# 比通用提示词模板更为规范
prompt = ChatPromptTemplate.from_messages(
[
("system","你需要根据会话历史来回答用户的问题"),
MessagesPlaceholder("chat_history"),
("human","请回答如下问题:{input}")
]
)
str_parser = StrOutputParser()
base_chain = prompt | model | str_parser
###
# 获取对话ID,增加聊天记录实例
store = {}
# 将底层存储修改一下就能够继续使用了
def get_history(session_id):
return FileChatMessageHistory(session_id,"./chat_history") # ctrl + p 查看参数列表
# 构建增强链
conversation_chain = RunnableWithMessageHistory(
base_chain,
get_history,
input_messages_key="input",
history_messages_key="chat_history"
)
if __name__ == '__main__':
session_config = {
"configurable": {
"session_id": "user001"
}
}
res = conversation_chain.invoke({"input": "小明有2只猫"}, session_config)
print("第一次执行:", res)
res = conversation_chain.invoke({"input": "小贝有1只狗"}, session_config)
print("第二次执行:", res)
res = conversation_chain.invoke({"input": "请问有几只宠物?"}, session_config)
print("第三次执行:", res)
CSVLoader
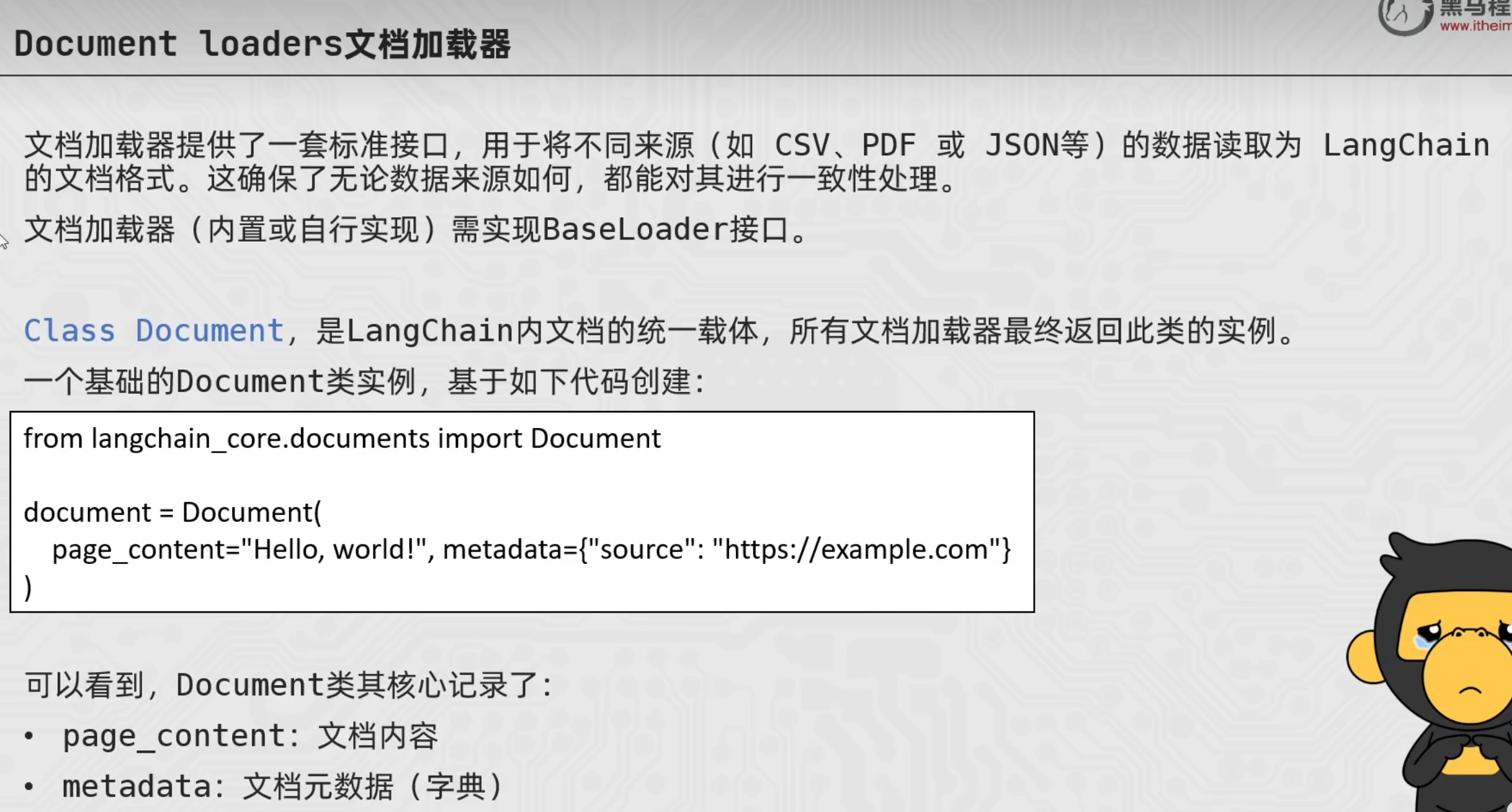
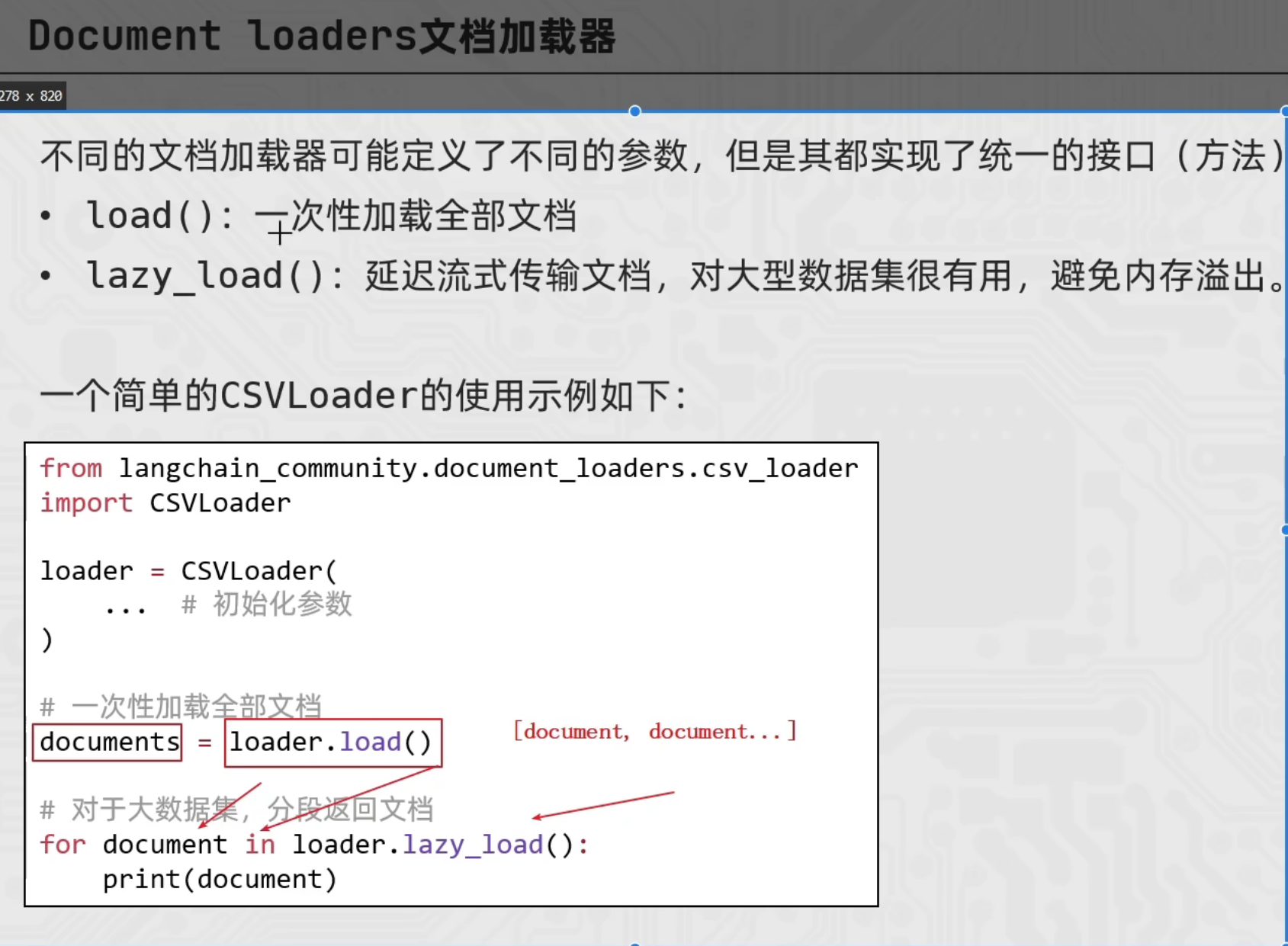
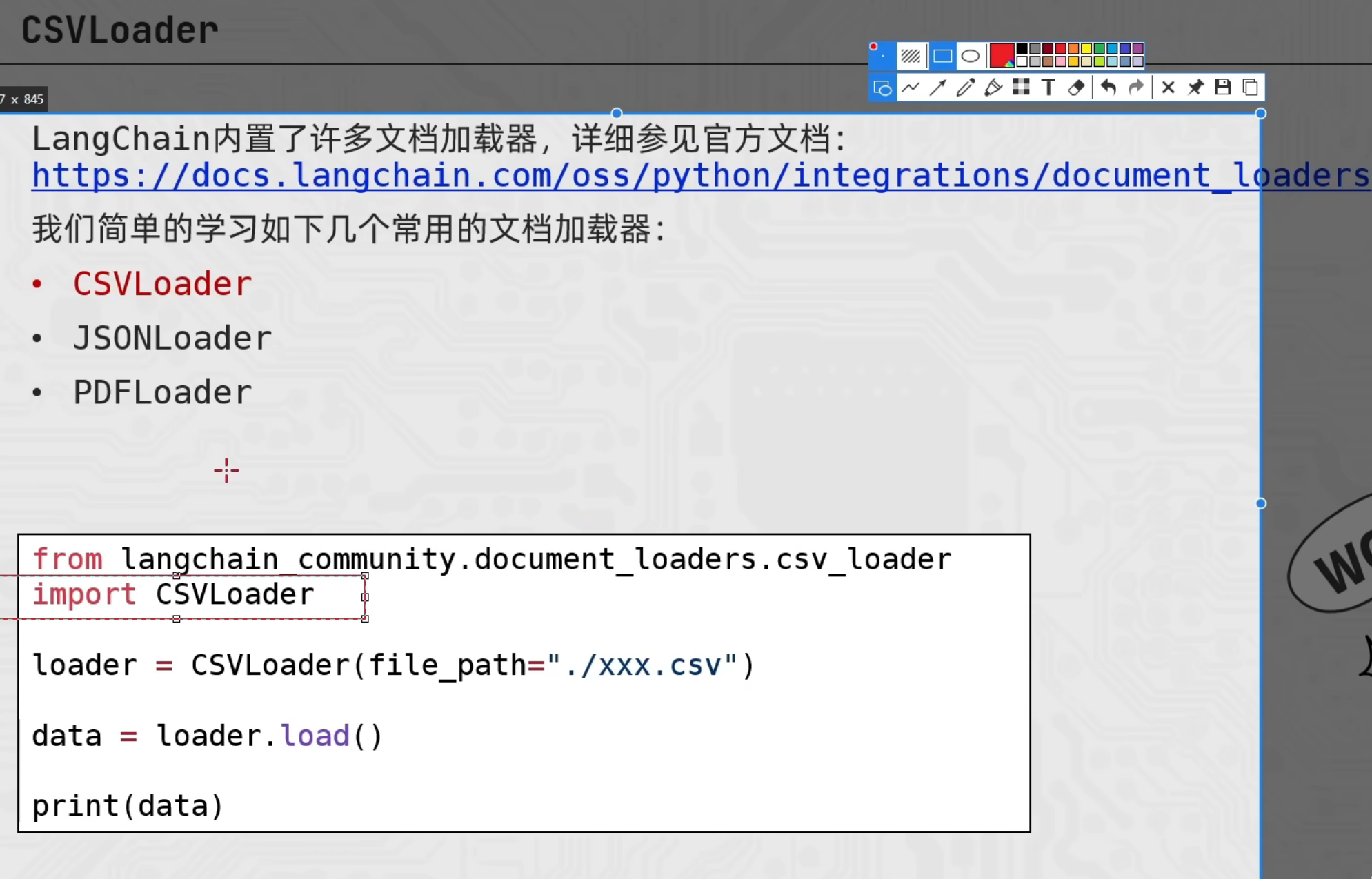
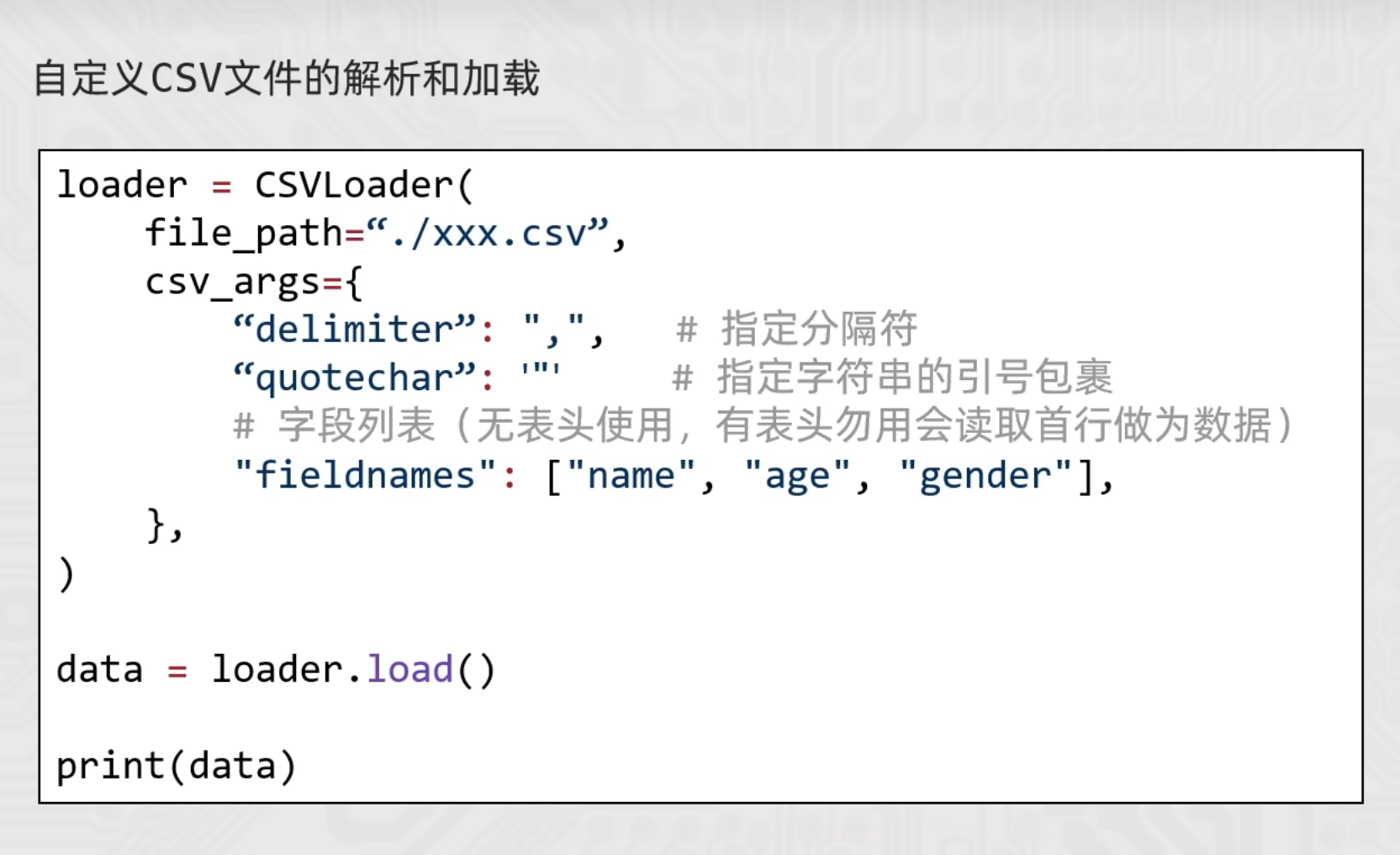

from langchain_community.document_loaders import CSVLoader
loader = CSVLoader(
file_path="./user001/stu.csv", # 指定读取的文件路径
csv_args={
"delimiter": ",", # 指定分隔符
"quotechar": '"', # 指定带有分隔符的文本被引号包围是单引号还是双引号
"fieldnames": ['a','b','c','d'] # 如果原本数据有表头,就不要下面的代码 否则会把原本数据的表头当作第一行也读取进来
},
encoding="utf-8" # 指定编码为UTF-8(报错:UnicodeDecodeError: 'gbk' codec can't decode byte 0xa2 in position 29: illegal multibyte sequence)
)
# 批量加载 .load() -> [document,document...] 最终目的都是为了得到document对象 方便后续操作
# documents = loader.load()
# print(documents)
# 懒加载 .lazy_load() -> [document,document...]
for document in loader.lazy_load():
print(document)
JSONLoader

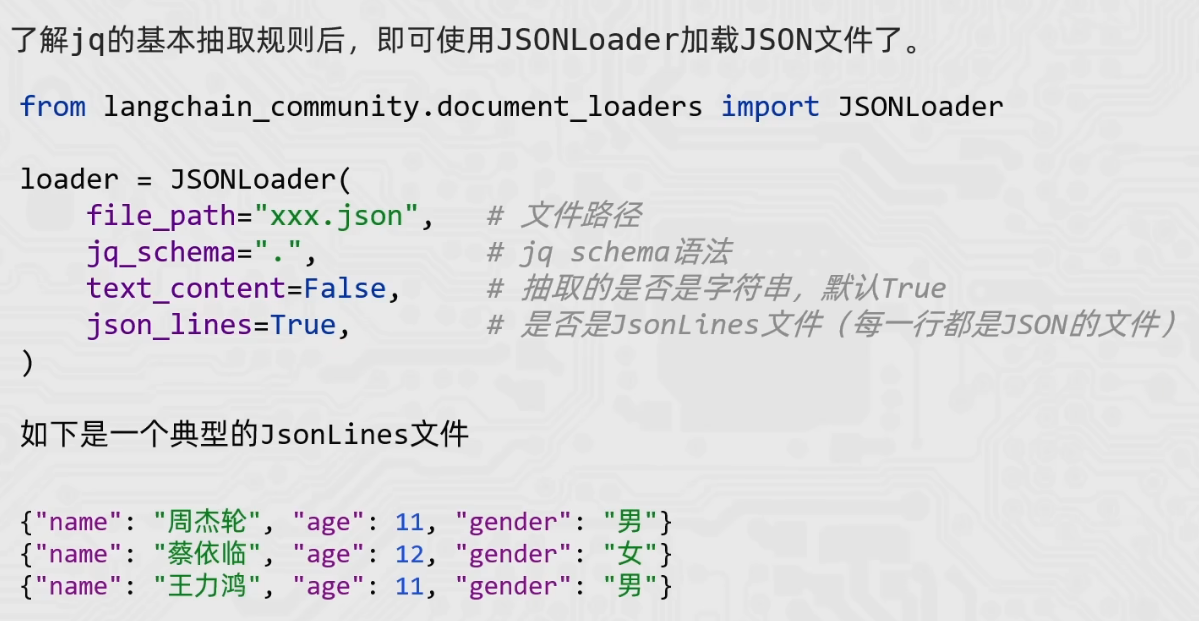

from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="./数据/stu_json_lines.json",
jq_schema=".name",
text_content=False, # 告知jsonloader 我读取的不是字符串
json_lines=True # 告知jsonloader 我读取的数据每一行都是标准的json格式
)
document = loader.load()
print(document)
TextLoader和文档分割器
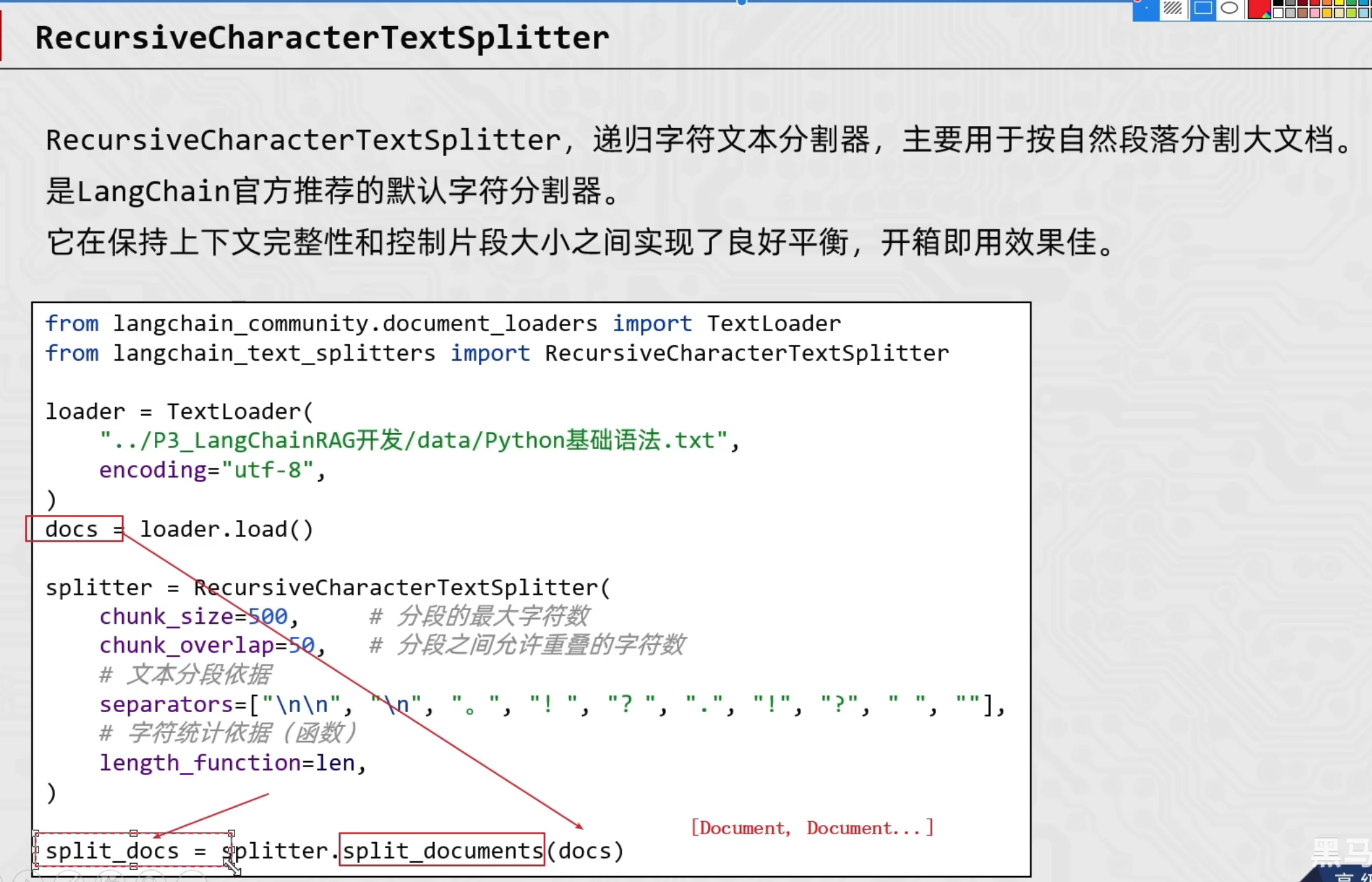

from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = TextLoader("./数据/Python基础语法.txt","utf-8")
docs = loader.load()
# 进行文本分割 类的实例化
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 分段允许的最大字符数
chunk_overlap=50, # 分段之间允许重叠的最大字符数
# 文本分割段落之间的依据符号
separators=["\n\n", "\n", ",", ".", ",", "。", "?", "!", "!"],
length_function=len # 统计字符的依据函数(chunk_size & chunk_overlap)
)
# 方法的调用
split_docs = splitter.split_documents(docs)
print(len(split_docs))
for doc in split_docs:
print("="*20)
print(doc)
print("="*20)
# 这样是不合适的,单个document太大,不利于后续的操作
# document = loader.load() # 得到[document]
# print(document)
# print(len(document))
pypdfLoader
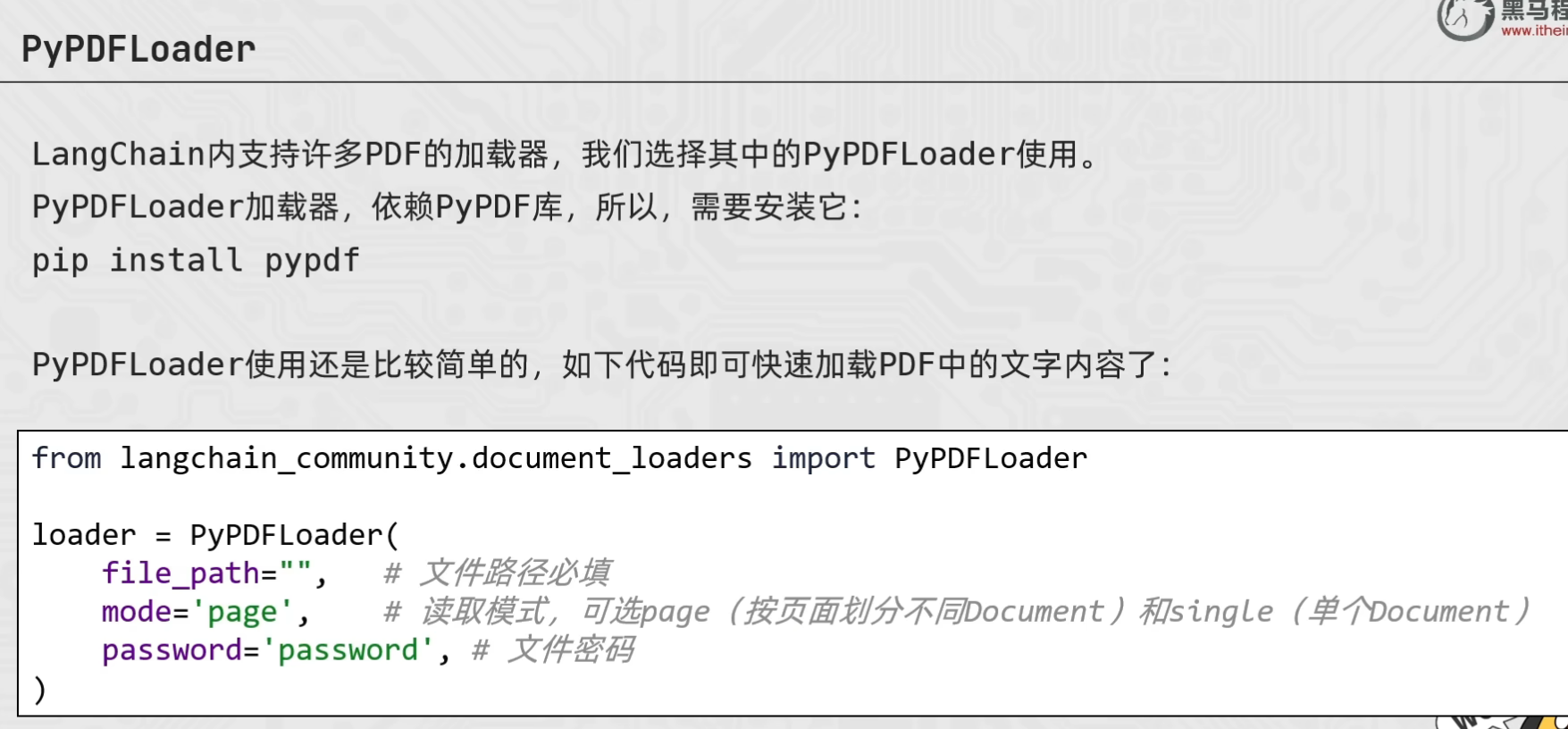
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(
file_path="./数据/pdf2.pdf",
mode="single", # 默认是page模式 即每一页形成一个document文档对象 single模式则不管有多少页,都只返回一个document对象
password="itheima"
)
i = 0
for doc in loader.lazy_load():
i += 1
print(doc)
print("="*20)
向量存储
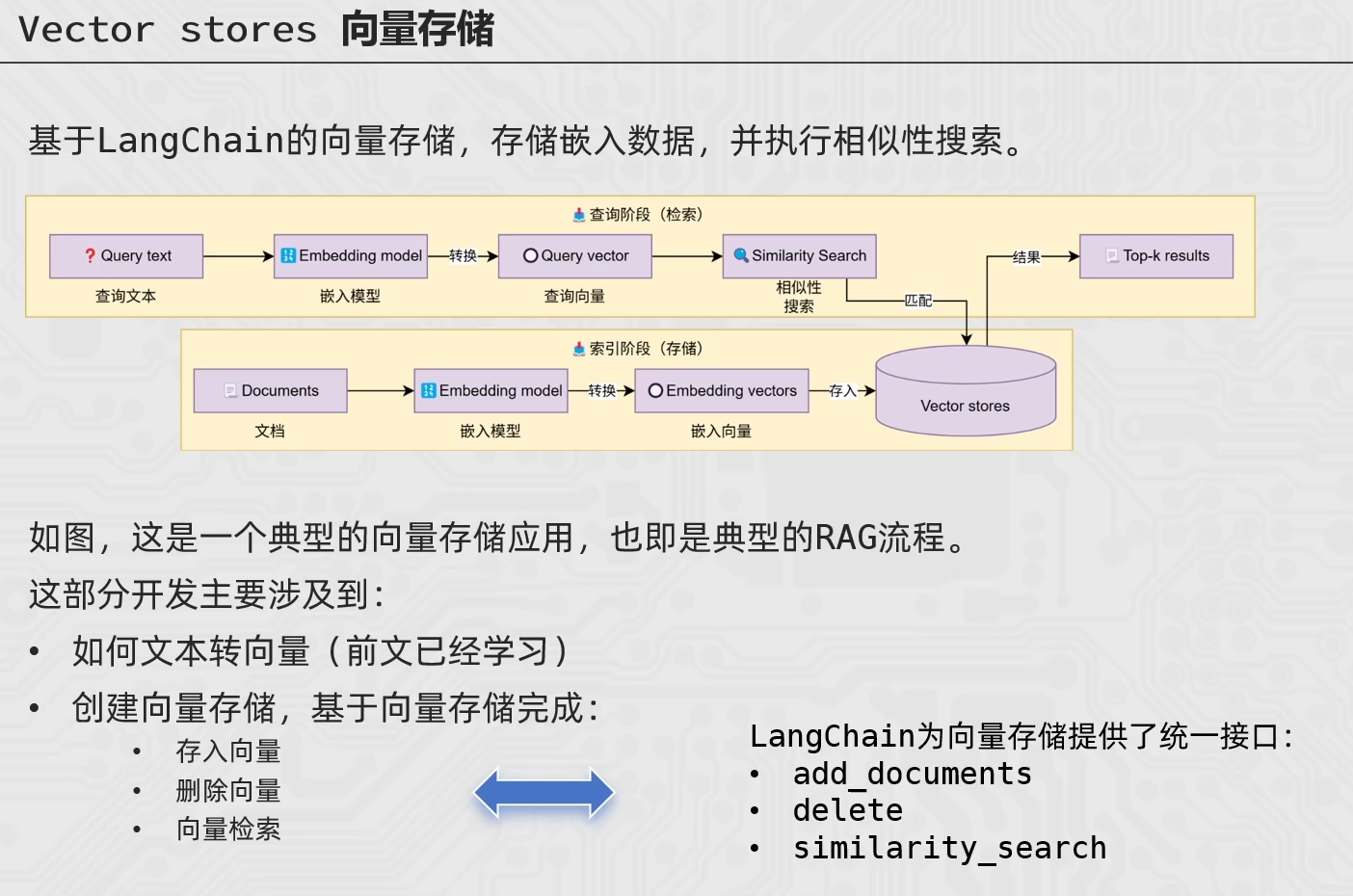
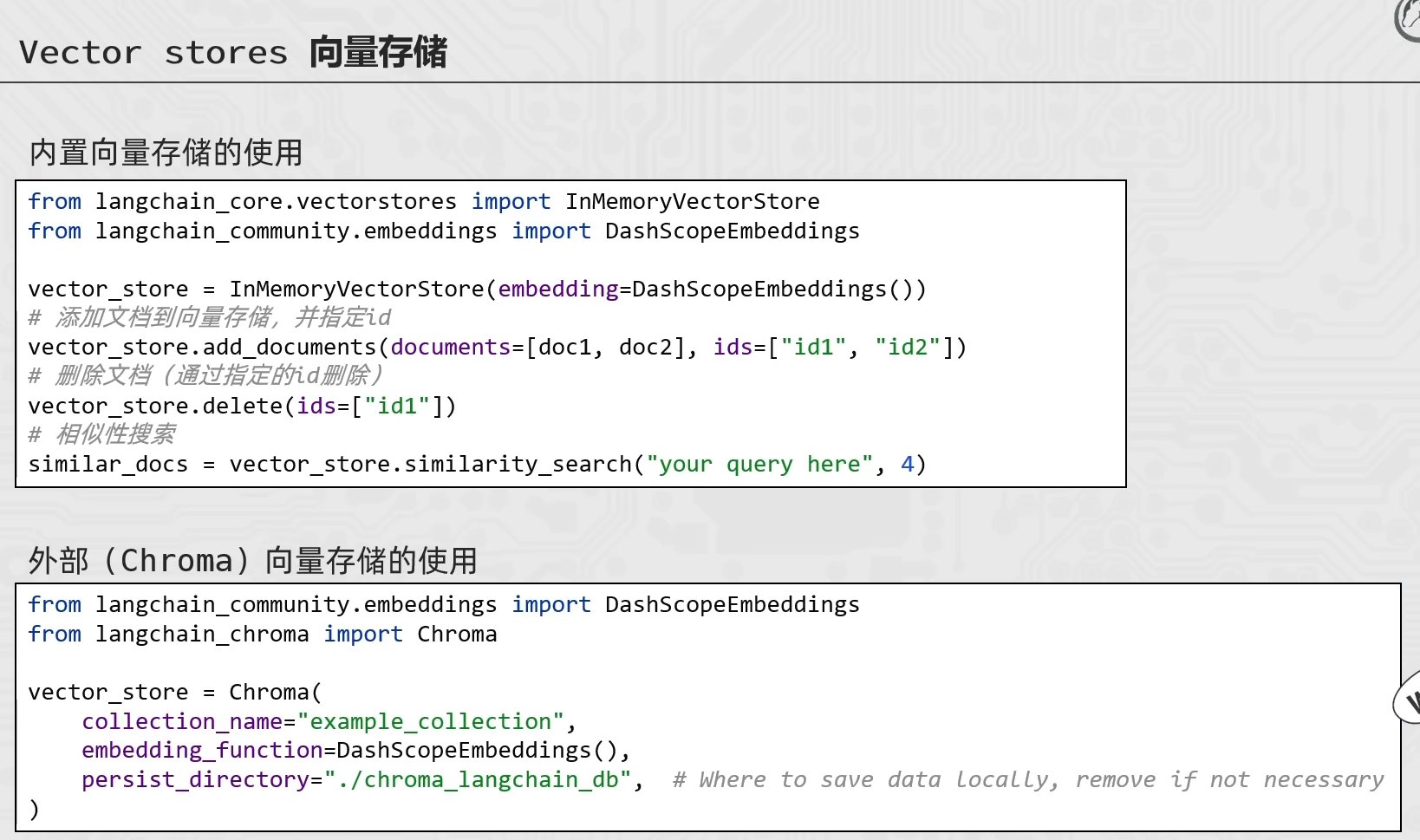
外部长期存储
from langchain_chroma import Chroma
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.document_loaders import CSVLoader
vector_store = Chroma(
collection_name="test", # 给当前向量存储起个名字,类似数据库的表名称
embedding_function=DashScopeEmbeddings(), # 嵌入模型
persist_directory="./chroma_db" # 指定数据存放的文件夹
)
loader = CSVLoader(
file_path="./数据/info.csv",
encoding="utf-8",
source_column="source" # 指明本条数据是来源于哪里的
)
documents = loader.load()
# id1 id2 id3 id4 id5
# 向量存储的 新增 删除 检索
# 新增
vector_store.add_documents(
documents=documents, # 被添加的文件(前面load进来的文件) 类型:list[document]
ids=["id"+str(i) for i in range(1,len(documents)+1)], # 给添加的文件提供id(字符串) list[str]
)
# 删除
vector_store.delete(["id1","id2"])
# 检索 返回类型为list[document]
result = vector_store.similarity_search(
"python是不是简单易学呀?", # 询问内容
3 , # 检索的结果(按照相似度排行 由高到低)
filter={"source" : "黑马程序员"} # 相较于原本的临时存储 多了一个过滤
)
print(result)
临时存储
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.document_loaders import CSVLoader
vector_store = InMemoryVectorStore(
embedding=DashScopeEmbeddings()
)
loader = CSVLoader(
file_path="./数据/info.csv",
encoding="utf-8",
source_column="source" # 指明本条数据是来源于哪里的
)
documents = loader.load()
# id1 id2 id3 id4 id5
# 向量存储的 新增 删除 检索
# 新增
vector_store.add_documents(
documents=documents, # 被添加的文件(前面load进来的文件) 类型:list[document]
ids=["id"+str(i) for i in range(1,len(documents)+1)], # 给添加的文件提供id(字符串) list[str]
)
# 删除
vector_store.delete(["id1","id2"])
# 检索 返回类型为list[document]
result = vector_store.similarity_search(
"python是不是简单易学呀?", # 询问内容
3 # 检索的结果(按照相似度排行 由高到低)
)
print(result)
基于向量存储构建提示词
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.chat_models.tongyi import ChatTongyi
str_parser = StrOutputParser()
model = ChatTongyi(model="qwen3-max")
prompt = ChatPromptTemplate.from_messages(
[
("system", "以我提供的参考资料为主,简洁且专业地回答用户的问题。参考资料{context}"),
("user", "用户提问{input}")
]
)
vector_store = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v4"))
# 准备资料(向量库的数据)
# add_texts 传入一个 list[str] 此处是为了简便(不用再导入文件)
vector_store.add_texts(
["减肥就是要少吃多练", "在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来", "跑步是很好的运动哟"])
input_text = "怎么减肥呢?"
# 检索向量库 拿到参考资料
result = vector_store.similarity_search(input_text, 2) # 返回类型: list[document] 但想要的是字符串
reference_text = "["
for doc in result:
reference_text += doc.page_content # 用.page_content 获取document中的字符串内容
reference_text += "]"
# 构建执行链条
def print_prompt(prompt):
print(prompt.to_string())
print("=" * 20)
return prompt
# 构建完整的提示词链条
chain = prompt | print_prompt | model | str_parser
res = chain.invoke({"input": input_text,"context": reference_text})
print(res)

runnablepassthrough的使用
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.chat_models.tongyi import ChatTongyi
str_parser = StrOutputParser()
model = ChatTongyi(model="qwen3-max")
prompt = ChatPromptTemplate.from_messages(
[
("system", "以我提供的参考资料为主,简洁且专业地回答用户的问题。参考资料{context}"),
("user", "用户提问{input}")
]
)
vector_store = InMemoryVectorStore(embedding=DashScopeEmbeddings(model="text-embedding-v4"))
# 准备资料(向量库的数据)
# add_texts 传入一个 list[str] 此处是为了简便(不用再导入文件)
vector_store.add_texts(
["减肥就是要少吃多练", "在减脂期间吃东西很重要,清淡少油控制卡路里摄入并运动起来", "跑步是很好的运动哟"])
input_text = "怎么减肥呢?"
# langchain中的向量存储对象,有一个方法:as_retriever 可以返回1个runnable接口的子类对象(runnable接口的子类才能入链,还有callable 以及mapping(str的顶级父类))
retriever = vector_store.as_retriever(search_kwargs={"k": 2}) # 相当于similarity_search 返回相似个数为2
# 这个retriever就是检索结果
def format_func(docs: list[Document]): # docs的类型
if not docs: # 因为向量的检索并不是百分百都有结果
return "无相关参考资料"
formatted_str = "["
for doc in docs:
formatted_str += doc.page_content
formatted_str += "]"
return formatted_str
def print_prompt(prompt):
print(prompt.to_string())
print("=" * 20)
return prompt
# 构建chain
# chain = retriever | prompt | model | StrOutputParser()
chain = (
{"input": RunnablePassthrough(),
"context": retriever | format_func} | prompt | print_prompt | model | StrOutputParser()
)
res = chain.invoke(input_text) # 因为retriever的输入接收类型是str 所以这里就不用字典了
# 同时:context的value最好也是str 所以要写一个format_func函数将list[document]转换为str
print(res)
"""
invoke取到用户的输入,同时传输给input和context中的retriever,这样就不会造成用户输入的丢失
"""
"""
retriever:
- 输入:用户的提问 str
- 输出:向量库的检索结果 list[Document]
prompt:
- 输入:用户的提问 + 向量库的检索结果 dict
- 输出:完整的提示词 PromptValue
不仅输入输出类型对不上 还会丢失用户的提问数据
查看输入输出类型:找到对应方法,ctrl点击 然后structure找到在对应类下找到invoke
"""

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)