AI教我UE渲染-学习笔记(4):测试新写个全屏复制贴图的shader与pass
0. ScreenPass 的 AddDrawTexturePass
实际上,对于目前蓝色区域没有铺满视窗的情况,只要换一个函数就行:
将原先使用的 “RenderGraphUtils 的 AddDrawTexturePass” 换为 “ScreenPass 的 AddDrawTexturePass” 即可(你没有看错,这俩函数名字一样,只是所在的文件不同,只靠参数来区分,一开始也把我混淆到了。。。但这是AI给出的最简单的实现方式)
不过这里,为了学习,我想让AI重新帮我实现一版简化的shader以及pass,来方便我学习。
1. 从零实现一版简化的shader和pass
给AI说:
我的想法是:
你新实现一个 AddDrawTexturePass_Learning函数来代替原先AddDrawTexturePass的职责,即给RDG加一个pass。
同时,内部要使用你新创建的顶点着色器和像素着色器。而你的着色器逻辑无比简单,他就是复制图像,只是是以uv映射的方式而非之前的像素拷贝。
注意:为了便于学习,你就不用嵌套那么多层级了,尽量在AddDrawTexturePass_Learning实现所有逻辑吧。
另外注意,你可以省略掉一些不重要分支判断,可以省略一些安全性检查,尽量只出现我需要学习的代码,不要分散我的注意力。
它实现了着色器 Engine\Shaders\Private\Tools\DrawTextureLearning.usf 如下:
// DrawTextureLearning.usf
// 学习用:用 UV 采样方式将一张纹理画到另一张上(区别于 DrawTexture.usf 的 Load 方式)。
#include "../Common.ush"
Texture2D InputTexture;
SamplerState InputSampler;
// 顶点着色器:把顶点缓冲里的 Position 和 UV 传给像素着色器。
// ATTRIBUTE0 = FFilterVertex::Position (float4),ATTRIBUTE1 = FFilterVertex::UV (float2)。
void MainVS(
in float4 InPosition : ATTRIBUTE0,
in float2 InUV : ATTRIBUTE1,
out float2 OutUV : TEXCOORD0,
out float4 OutPosition : SV_POSITION)
{
// InPosition.xy 范围是 [0,1],转换到 NDC [-1,1](y 翻转)。
OutPosition = float4(InPosition.xy * float2(2, -2) + float2(-1, 1), 0, 1);
OutUV = InUV;
}
// 像素着色器:用 UV 采样输入纹理,输出到渲染目标。
float4 MainPS(
in float2 InUV : TEXCOORD0) : SV_Target0
{
return InputTexture.Sample(InputSampler, InUV);
}
C++方面代码如下:(直接写在了Engine/Source/Runtime/Renderer/Private/DeferredShadingRenderer.cpp中)
// ========== [Render_Learning] 学习用的 shader 定义 ==========
// 学习用顶点着色器:把顶点的 Position 和 UV 传给像素着色器。
class FDrawTextureLearningVS : public FGlobalShader
{
DECLARE_GLOBAL_SHADER(FDrawTextureLearningVS);
SHADER_USE_PARAMETER_STRUCT(FDrawTextureLearningVS, FGlobalShader);
BEGIN_SHADER_PARAMETER_STRUCT(FParameters, )
END_SHADER_PARAMETER_STRUCT()
};
IMPLEMENT_GLOBAL_SHADER(FDrawTextureLearningVS, "/Engine/Private/Tools/DrawTextureLearning.usf", "MainVS", SF_Vertex);
// 学习用像素着色器:用 UV 采样输入纹理并输出到渲染目标。
class FDrawTextureLearningPS : public FGlobalShader
{
DECLARE_GLOBAL_SHADER(FDrawTextureLearningPS);
SHADER_USE_PARAMETER_STRUCT(FDrawTextureLearningPS, FGlobalShader);
BEGIN_SHADER_PARAMETER_STRUCT(FParameters, )
SHADER_PARAMETER_RDG_TEXTURE(Texture2D, InputTexture)
SHADER_PARAMETER_SAMPLER(SamplerState, InputSampler)
RENDER_TARGET_BINDING_SLOTS()
END_SHADER_PARAMETER_STRUCT()
};
IMPLEMENT_GLOBAL_SHADER(FDrawTextureLearningPS, "/Engine/Private/Tools/DrawTextureLearning.usf", "MainPS", SF_Pixel);
// 学习用的 AddDrawTexturePass:把 InputTexture 用 UV 采样的方式画到 OutputTexture 上。
// 逻辑尽量平铺,便于理解"一个 RDG 绘制 pass 从创建到执行"的完整流程。
static void AddDrawTexturePass_Learning(
FRDGBuilder& GraphBuilder,
const FGlobalShaderMap* ShaderMap,
FRDGTextureRef InputTexture,
FRDGTextureRef OutputTexture)
{
// 1. 从 GlobalShaderMap 中取出已编译的 VS 和 PS
TShaderMapRef<FDrawTextureLearningVS> VertexShader(ShaderMap);
TShaderMapRef<FDrawTextureLearningPS> PixelShader(ShaderMap);
// 2. 分配参数结构体,填入 PS 需要的输入纹理、采样器、渲染目标
FDrawTextureLearningPS::FParameters* Parameters = GraphBuilder.AllocParameters<FDrawTextureLearningPS::FParameters>();
Parameters->InputTexture = InputTexture;
Parameters->InputSampler = TStaticSamplerState<SF_Bilinear>::GetRHI();
Parameters->RenderTargets[0] = FRenderTargetBinding(OutputTexture, ERenderTargetLoadAction::ENoAction);
// 3. 向 RDG 添加一个光栅化 pass
const FIntPoint OutputExtent = OutputTexture->Desc.Extent;
GraphBuilder.AddPass(
RDG_EVENT_NAME("DrawTextureLearning"),
Parameters,
ERDGPassFlags::Raster,
[VertexShader, PixelShader, Parameters, OutputExtent](FRDGAsyncTask, FRHICommandList& RHICmdList)
{
// 4. 设置视口:决定画到输出纹理的哪块区域(这里铺满整张输出)
RHICmdList.SetViewport(0.0f, 0.0f, 0.0f, (float)OutputExtent.X, (float)OutputExtent.Y, 1.0f);
最后替换了原先的函数
编译通过,结果也符合预期。
2. PSO(管线状态对象)
关于PSO,AI的解释:
PSO(Pipeline State Object):GPU 一次绘制要用到的一整份固定状态的打包(在 D3D12 等 API 里很常见),包括绑哪套顶点布局、哪个 VS、哪个 PS、混合/光栅/深度、图元类型等。
在你这段代码里,最核心的就是:把 VertexShaderRHI 设成你的 MainVS,把 PixelShaderRHI 设成你的 MainPS,再配上和顶点缓冲一致的 VertexDeclaration(GFilterVertexDeclaration),这样 GPU 才知道「顶点数据怎么解析、顶点程序跑谁、像素程序跑谁」。
目前的管线配置如下:
// 5. 构建管线状态对象(PSO):把 VS、PS、RT、混合/光栅/深度状态绑在一起
FGraphicsPipelineStateInitializer GraphicsPSOInit;
RHICmdList.ApplyCachedRenderTargets(GraphicsPSOInit);
GraphicsPSOInit.BlendState = TStaticBlendState<>::GetRHI();
GraphicsPSOInit.RasterizerState = TStaticRasterizerState<>::GetRHI();
GraphicsPSOInit.DepthStencilState = TStaticDepthStencilState<false, CF_Always>::GetRHI();
GraphicsPSOInit.BoundShaderState.VertexDeclarationRHI = GFilterVertexDeclaration.VertexDeclarationRHI;
GraphicsPSOInit.BoundShaderState.VertexShaderRHI = VertexShader.GetVertexShader();
GraphicsPSOInit.BoundShaderState.PixelShaderRHI = PixelShader.GetPixelShader();
GraphicsPSOInit.PrimitiveType = PT_TriangleList;
SetGraphicsPipelineState(RHICmdList, GraphicsPSOInit, 0);
3. VertexDeclaration(顶点声明)
关于顶点声明,AI解释:
VertexDeclaration(顶点声明):告诉 GPU 顶点缓冲里每一帧顶点数据怎么排布——每条流用几个属性、每个属性是什么类型(float2/float4)、在顶点结构体里偏移多少字节、对应 shader 里的 哪个输入槽(semantic/slot)。
和你当前实例的对应关系:
GFilterVertexDeclaration描述的是FFilterVertex:Position(float4)在流 0 偏移 0 → 作为 slot 0;UV(float2)在流 0 的下一偏移 → 作为 slot 1。- 你的 MainVS 里
ATTRIBUTE0/ATTRIBUTE1就和这两个 slot 对上,所以 GPU 从GScreenRectangleVertexBuffer读出来的字节,会按这份声明解析成InPosition/InUV。
一句话:VertexDeclaration =「顶点缓冲的二进制布局说明书」;没有它,同一串字节无法正确拆成 Position 和 UV。
也就是说,当前管线假设了进入shader的顶点类型是FFilterVertex,他被FFilterVertexDeclaration描述,并且与顶点着色器的输入对应: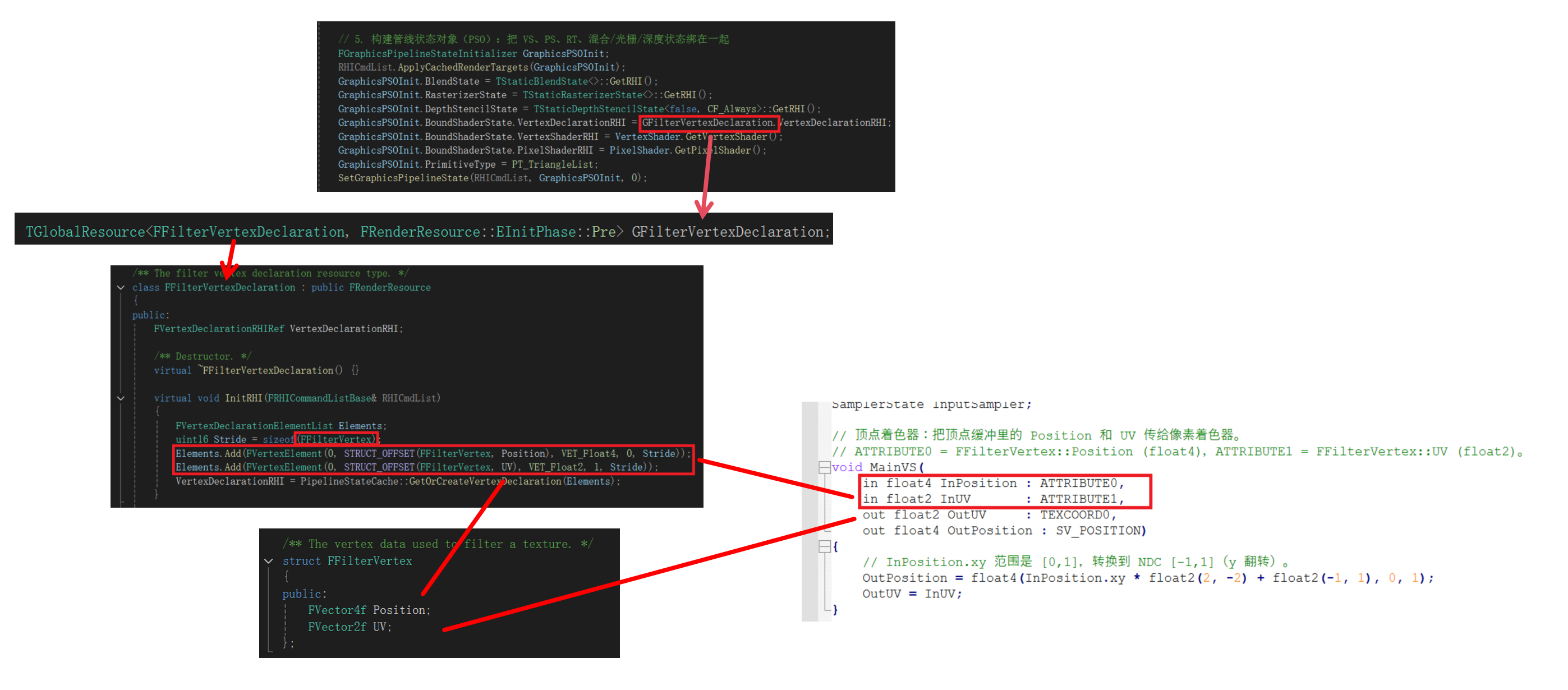
4. GScreenRectangleVertexBuffer 详解
GScreenRectangleVertexBuffer 是为了画全屏的三角形,它的顶点类型就是FFilterVertex,与我们之前在管线中声明的对应。
它的VertexBuffer和IndexBuffer的数据如下: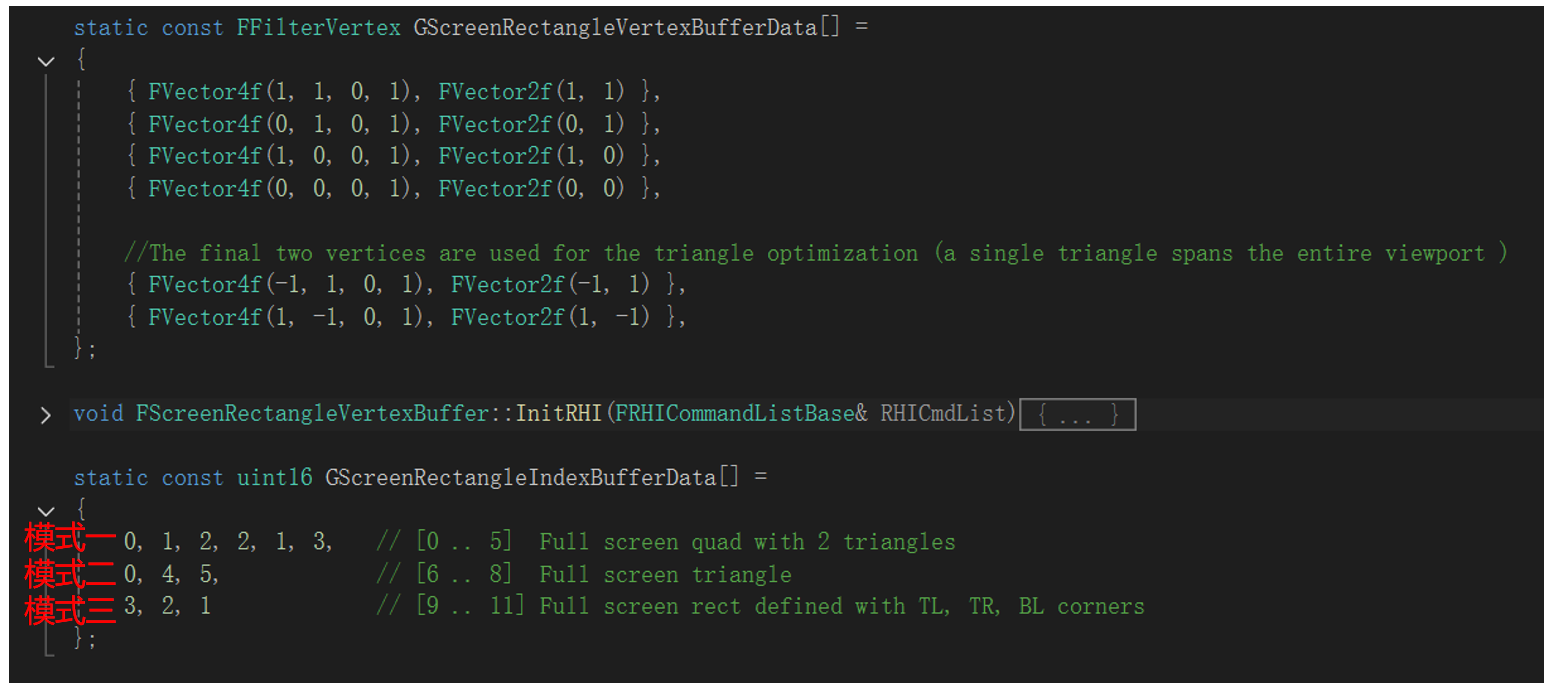
它其实有三个模式: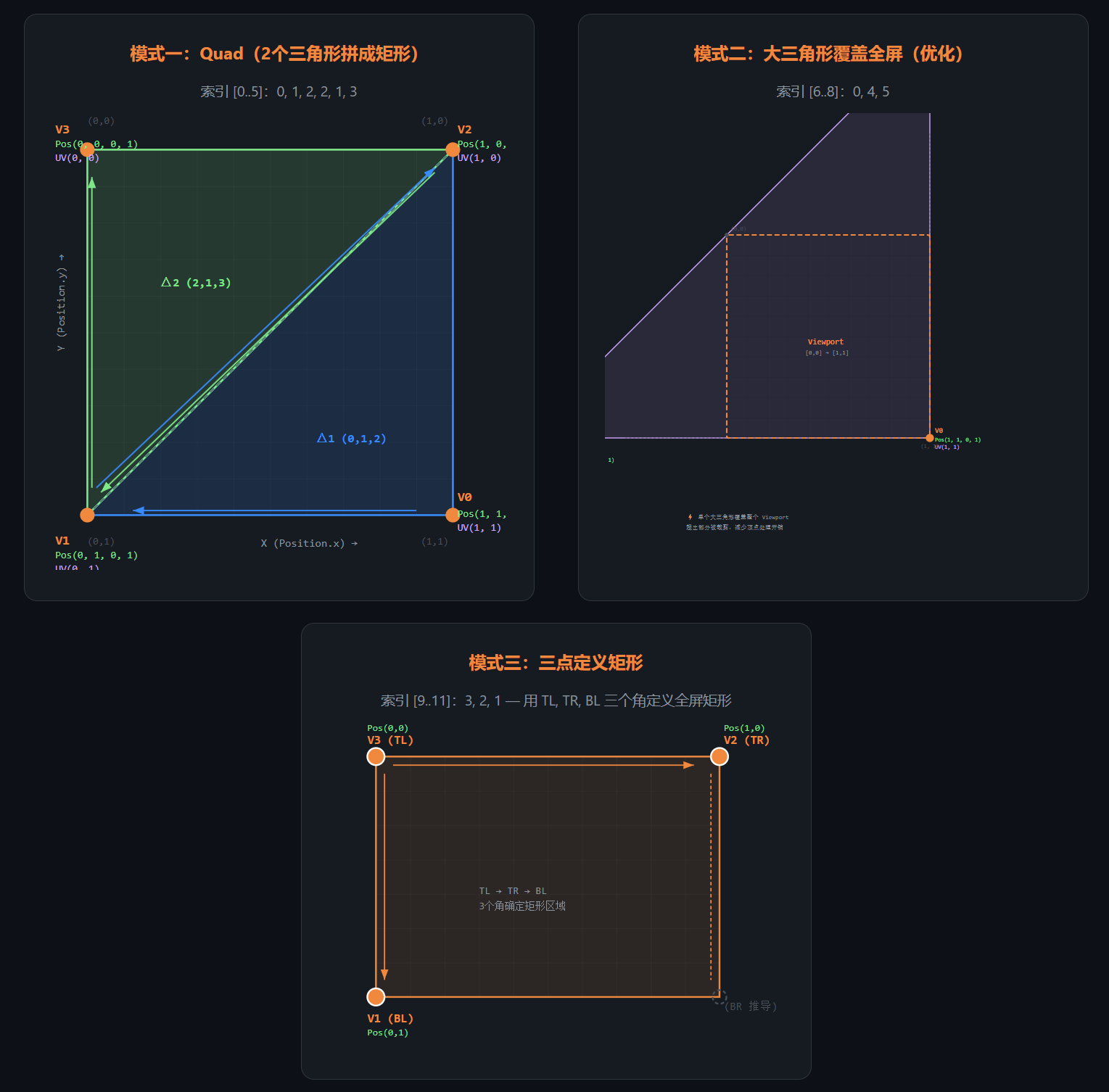
5. 传入顶点数据并Draw
// 7. 绑定全屏四边形的顶点缓冲并发出 DrawCall(2 个三角形 = 铺满视口的矩形)
RHICmdList.SetStreamSource(0, GScreenRectangleVertexBuffer.VertexBufferRHI, 0);
RHICmdList.DrawIndexedPrimitive(
GScreenRectangleIndexBuffer.IndexBufferRHI,
0, 0, 4, // BaseVertexIndex, FirstInstance, NumVertices
0, 2, 1); // StartIndex, NumPrimitives(2 三角形), NumInstances
关于上面两次RHI调用,AI的解释:(仅供参考)
SetStreamSource 指定第几路顶点流从哪块顶点缓冲、从哪个字节偏移开始读,后面的 draw 就按 VertexDeclaration 从那里取顶点。
| 参数名 | 意义 | 你当前的值表示什么 |
|---|---|---|
StreamIndex |
顶点流序号(和 VertexDeclaration 的 stream 对应) | 0:第 0 路流,对应 GFilterVertexDeclaration 里绑在 stream 0 的 Position/UV。 |
VertexBuffer |
顶点缓冲的 RHI | 这里数据来源就是我们刚介绍的GScreenRectangleVertexBuffer 里的VertexBuffer |
Offset |
从该 VB 开头的字节偏移 | 0:从缓冲最开头当作「逻辑顶点 0」,与索引 0~3 对齐。 |
DrawIndexedPrimitive:用索引缓冲里的一段索引,到当前已绑定的顶点缓冲里取顶点,按当前 PSO 的图元类型画出 NumPrimitives 个图元,可带 BaseVertexIndex / 实例 偏移。
| 参数名 | 意义 | 你当前的值表示什么 |
|---|---|---|
IndexBuffer |
索引缓冲 RHI | 这里数据来源就是我们刚介绍的GScreenRectangleVertexBuffer 里的IndexBuffer:开头是 0,1,2 和 2,1,3 拼成四边形的两段三角形。(所以是模式一) |
BaseVertexIndex |
加到每个索引上的顶点偏移 | 0:索引 i 就读 VB 里的第 i 个顶点,不做整体平移。 |
FirstInstance |
实例化时的起始实例 ID(传给 VS 的 SV_InstanceID 相关路径) |
0:从第 0 个实例开始;你 NumInstances=1 时就是普通单次绘制。 |
NumVertices |
UE 侧用于校验/统计等的顶点规模提示(具体 RHI 实现里会参与 SetupDraw 等) |
4:声明这次 draw 与 4 个顶点槽位相关(对应四边形用的顶点 0~3)。 |
StartIndex |
从索引缓冲的第几个索引开始读 | 0:从第一条索引开始,即走「四边形」那 6 个索引,而不是后面「单大三角形」那段。 |
NumPrimitives |
要画的图元个数(三角形个数由当前 PSO 的 PrimitiveType 决定,这里是 PT_TriangleList) |
2:2 个三角形 → 一张矩形。 |
NumInstances |
实例数量 | 1:只画一遍,不用 instancing。 |
6. 顶点着色器输出裁剪空间
这里有个教程 Shader Basics - Vertex Shader | GPU Shader Tutorial 介绍了顶点着色器:
顶点着色器处理各个顶点,并给出它们在 「裁剪空间(clip-space)」 里的坐标。裁剪空间是一种便于计算机判断 哪些顶点在相机可见范围内、哪些不可见并需要被裁掉(clipped) 的坐标系。
这样在后续阶段 GPU 要处理的数据更少,会更快。
它的工作方式是:每次只接收顶点列表里的一个顶点作为输入,并输出一个结果,用来决定这个顶点在 裁剪空间里应该出现在哪里。
因为这种着色器会对 传入 GPU 管线的每一个顶点各执行一次,所以凡是 需要改顶点 的操作(只要最终输出仍是该顶点在裁剪空间中的位置)都可以在这里做。
关于 NDC(Normalized Device Coordinates,归一化设备坐标)和 裁剪空间(clip space)的关系,AI是如下解释的:(仅供参考)
关系(一句话)
裁剪空间(clip space) 是带 w 的齐次坐标 ((x,y,z,w));在裁剪之后做 透视除法 (x’ = x/w,; y’ = y/w,; z’ = z/w)(以及视口映射)得到的那一步,习惯上才叫 NDC(归一化设备坐标)。
所以:NDC ≈ 裁剪空间在「除以 w 之后」的 (x,y,z) 那一层(w 不再单独参与成比例)。
更细一点
- 裁剪空间:裁剪体用 w 参与的不等式判断(例如 D3D 常见 (-w < x \le w) 这类),图元在这里被裁掉部分。
- NDC:已经除掉 w,坐标落在规范化的盒子/范围内(具体 x,y,z 范围随 API/投影略有差别),再乘视口尺寸变成像素。
VS 输出的是 NDC 还是裁剪空间?
按 HLSL / Direct3D 的官方说法:顶点着色器写的是SV_Position,即齐次裁剪空间,不是已经除过 w 的 NDC。
硬件在 VS 之后做:裁剪 →(透视)除 w → 视口映射 等。
你那种w = 1的全屏 pass:数学上 除 w 不改变 x,y,z,所以看起来「像在写 NDC」,但语义上仍算裁剪空间输出,只是 w=1 时与 NDC 数值相同。
目前因为我的测试中只牵扯到2D的位置,所以对于 z 和 w 的描述目前还不好理解与证伪。
对于xy这俩坐标,就比较明确了,顶点着色器要输出 -1 ~ 1的坐标。而我们输入的顶点是 0 ~ 1,因此才有顶点着色器中的转换:(这里还对y反转了下)
// InPosition.xy 范围是 [0,1],转换到 NDC [-1,1](y 翻转)。
OutPosition = float4(InPosition.xy * float2(2, -2) + float2(-1, 1), 0, 1);
然后,UV就是原封不动的传递给接下来的像素着色器了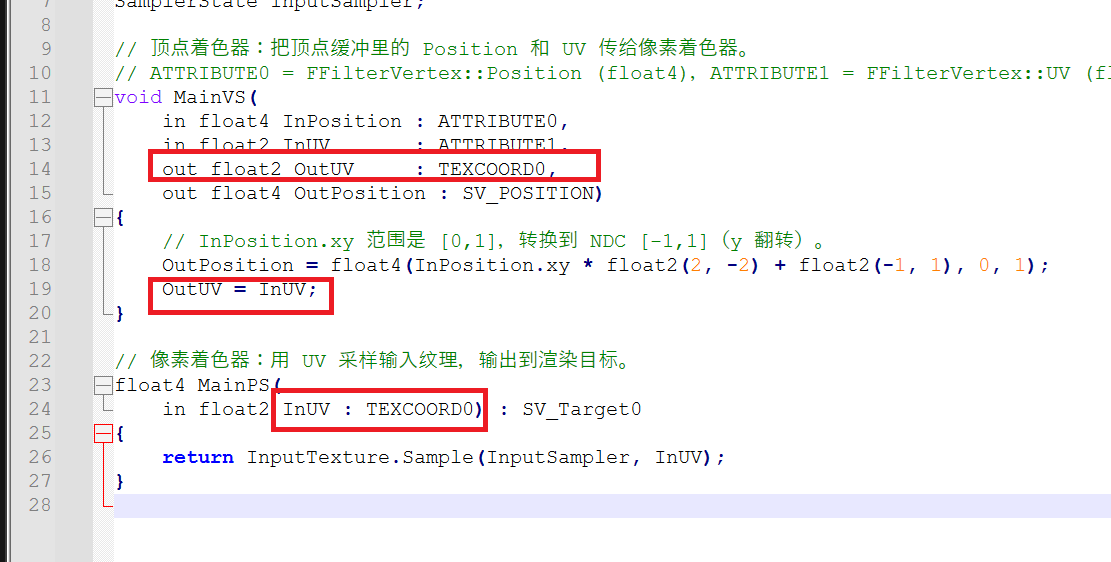
7. 像素着色器
AI描述:
像素着色器(PS)在光栅化之后运行:对 每个可能被三角形盖住的像素(更严格说是 fragment) 各调用一次。
输入:该像素在三角形内插值后的数据(例如 UV、法线、颜色等),以及可选的 SV_Position(像素在目标上的位置等)。
输出:通常往 SV_Target 写颜色;也可写深度、模板等(若声明了对应输出)。
和你当前 MainPS 的关系 :用插值得到的 InUV 对纹理 Sample,得到颜色写到 SV_Target0,即当前绑定的渲染目标上这个像素的颜色。
8. 测试一下uv是否准确
为了测试下这里的uv是否准确,我让AI直接输出uv作为颜色,修改了下像素着色器
// 像素着色器:用 UV 采样输入纹理,输出到渲染目标。
// 【临时调试】输出 UV 为颜色:R=U、G=V、B=0
float4 MainPS(
in float2 InUV : TEXCOORD0) : SV_Target0
{
return float4(InUV, 0.0f, 1.0f);
}
结果符合预期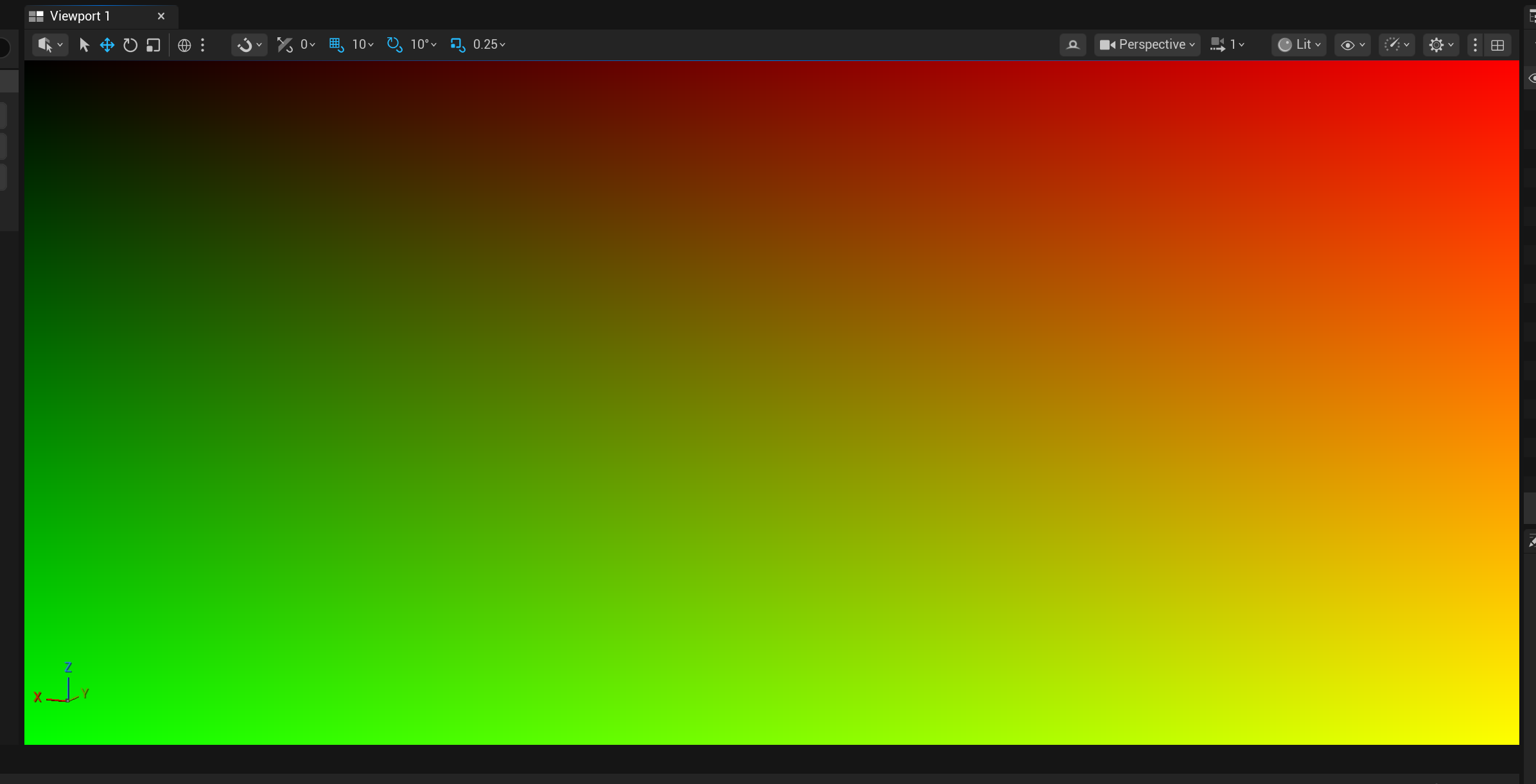

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)