AAAI 2026 | 解锁LLM真实想法!EAGLE从多层隐藏状态出发,让置信度评估告别“表面功夫”
大语言模型(LLMs)早已成为自然语言处理领域的“顶流”,能写代码、答问题、生成文案,看似无所不能。但你是否遇到过这种情况:模型斩钉截铁给出一个答案,结果却是错的?这种“过度自信”的幻觉问题,成了LLM安全部署的一大拦路虎。想要让模型的置信度和真实准确率对齐,校准技术必不可少。今天要分享的这篇AAAI 2026的研究——EAGLE,就为LLM的不确定性估计打开了新思路,不靠额外训练,仅凭挖掘模型内部隐藏状态,就能让置信度评估更精准!
我整理了“不确定性估计+大语言模型”方向10篇相关论文,帮助大家了解学习“不确定性估计+大语言模型”方向,选题,挖创新点。
一、痛点:LLM的“表面自信”靠不住
在实际应用中,LLM的“口是心非”特别突出:明明内部可能对答案存疑,最终输出却表现得无比确定。传统的校准方法大多依赖模型的最终输出,比如让模型自评估给出一个置信度分数,但这种“表面功夫”往往无法反映模型的真实想法——毕竟RLHF训练后的模型,很容易为了“显得正确”而掩盖内部的不确定性。
而研究者们发现,LLM的中间层隐藏状态藏着大秘密:不同层的隐藏表示天然能区分高置信和低置信的预测,这意味着模型的“内心想法”早就编码在这些内部状态里了!既然如此,何不绕开不可靠的最终输出,直接从内部挖真相?这就是EAGLE方法的核心动机。
二、EAGLE:拆解模型“内心戏”,精准计算置信度
EAGLE全称为“聚合内部信念的期望(Expectation of Aggregated Internal Belief)”,光听名字就能猜到它的核心思路:不看模型“嘴上说的”置信度,而是扒开它的“内部表征”,聚合多层信息后算出最贴合真实想法的置信度分数。
先放一张EAGLE的核心流程示意图,帮大家直观理解: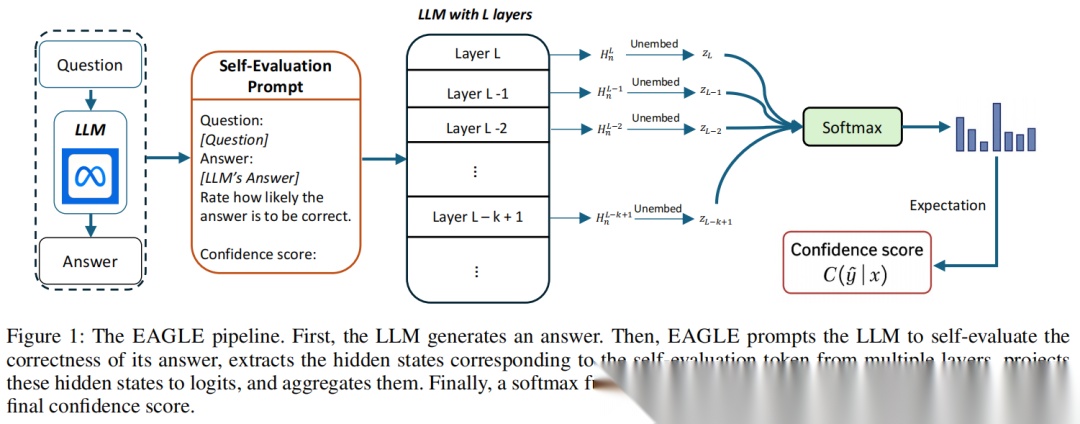
整个过程可以拆解为4个关键步骤,每一步都踩中了传统方法的痛点:
1. 第一步:让模型“自评估”,锁定关键令牌
首先给模型发一个自评估提示,让它对自己给出的答案打分(0-9分表示置信度)。这一步和传统方法看似相似,但重点不在模型最终给出的分数,而是要找到这个“打分令牌”对应的各层隐藏状态——这才是模型的“真心话”载体。
2. 第二步:提取多层隐藏状态,映射为对数几率
传统方法只盯着最后一层的输出,而EAGLE会提取最后k层的隐藏状态,把每一层的隐藏表示都映射到词汇空间,得到“分层对数几率”。为什么选对数几率?因为这是Softmax归一化前的原始信息,能保留更多细微的置信信号,不像归一化后的概率会丢失细节。
3. 第三步:加权聚合多层对数几率
把这些分层的对数几率做加权平均(论文里直接等权平均,简单又高效),形成一个整合了多层信息的对数几率向量。这一步的妙处在于,不同层的隐藏状态能捕捉不同层次的语义和推理信息,聚合之后,就能拿到比单一层更全面的置信信号。
4. 第四步:算分布期望,得到最终置信度
最后对聚合后的对数几率做Softmax,得到0-9分的概率分布——这就像模型内心对“自己答案对不对”的完整信念分布。和传统方法只取最高分不同,EAGLE计算这个分布的期望值作为最终置信度。这一步直接利用了整个分布的信息,能更稳健地反映模型的真实想法。
三、四大创新点,直击传统方法痛点
EAGLE的亮眼表现,离不开四个关键创新设计,每一个都精准解决了过往校准方法的短板:
1. 全新范式:绕过表层输出,挖内部表征
这是最核心的创新——不再依赖模型最终输出的“表层置信度”,转而从多层隐藏状态中提取真实置信信号。就像看人不能只听表面话术,要读懂内心想法,EAGLE让LLM的置信度评估从“看表面”升级为“读内心”。
2. 聚合策略:Softmax前聚合对数几率
传统方法要么聚合各层概率,要么直接用最后一层输出,而EAGLE选择在Softmax前聚合对数几率。这种设计能保留更丰富的置信细节,避免归一化导致的信息丢失,是校准性能提升的关键。
3. 最终得分:用分布期望替代单点估计
以往只取最高概率的分数,相当于只看模型“最倾向的答案”,而忽略了它的犹豫和不确定。计算分布期望则把模型的“整个思考过程”纳入考量,结果更稳健、更贴合真实不确定性。
4. 实用优势:无需训练+提示鲁棒
EAGLE是纯后处理方法,不用额外训练任何模块,计算高效,落地成本极低。同时它对自评估提示的细微变化有鲁棒性——哪怕提示词没那么精准,核心机制依然能工作(当然清晰的评分标准效果最好)。
四、实验结果:ECE大幅下降,校准+判别双优秀
研究者在TriviaQA、GSM8k、MMLU三大数据集,Qwen2.5(7B/72B)、Llama3(8B/70B)四大模型上做了全面测试,结果堪称“降维打击”:
先看核心校准指标ECE(期望校准误差,越小越好):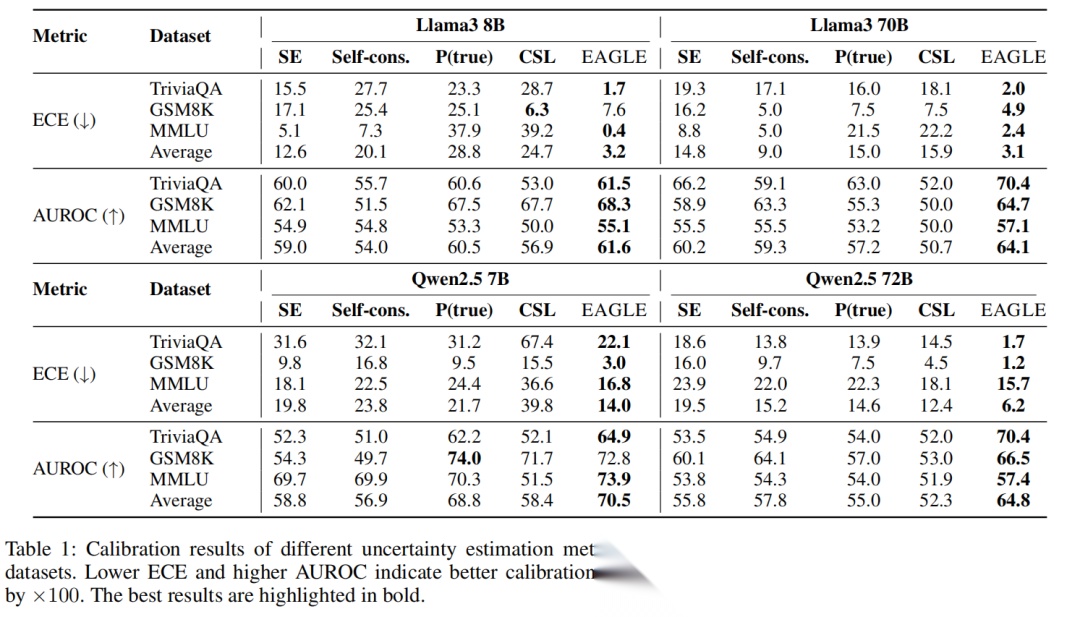 在TriviaQA数据集上,Llama3 8B的ECE从最佳基线的15.5降到1.7,Llama3 70B从16.0降到2.0;Qwen2.5系列模型也呈现同样趋势,EAGLE始终拿下最低的ECE,意味着模型的置信度和真实准确率几乎完美对齐。
在TriviaQA数据集上,Llama3 8B的ECE从最佳基线的15.5降到1.7,Llama3 70B从16.0降到2.0;Qwen2.5系列模型也呈现同样趋势,EAGLE始终拿下最低的ECE,意味着模型的置信度和真实准确率几乎完美对齐。
除了校准,EAGLE的判别能力(AUROC)也拉满——能精准区分正确和错误答案。比如Llama3 70B在TriviaQA上的AUROC达到70.4,远超所有基线。对比下来,传统方法要么校准差,要么判别弱,而EAGLE实现了“两全其美”。
五、消融研究:验证每一步设计的必要性
为了证明EAGLE各环节的价值,研究者做了全面的消融实验: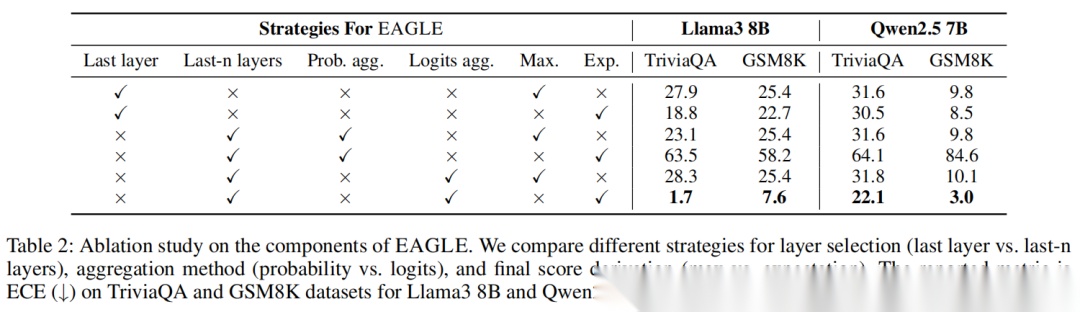
- 聚合多层vs仅用最后一层:聚合多层的ECE显著更低,证明多层隐藏状态能提供更稳健的信号;
- 对数几率聚合vs概率聚合:对数几率聚合完胜,验证了Softmax前聚合的优势;
- 分布期望vs取最高分:期望计算的结果校准更好,说明完整分布的信息不可替代。
还有逐层分析的热图,也印证了“最后几层隐藏状态最有价值”: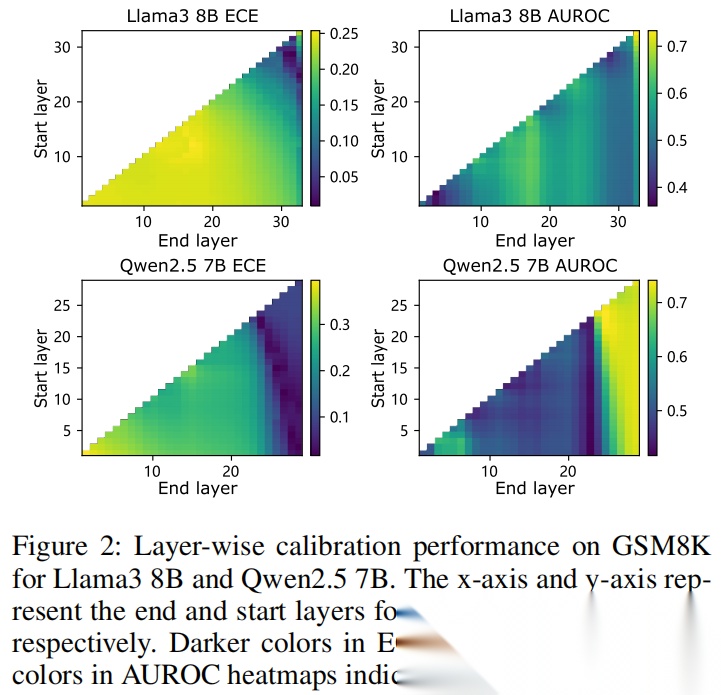 不管是Llama3还是Qwen2.5,聚合最后几层的隐藏状态时,ECE最低、AUROC最高,这也为“选最后k层”的策略提供了实证支撑。
不管是Llama3还是Qwen2.5,聚合最后几层的隐藏状态时,ECE最低、AUROC最高,这也为“选最后k层”的策略提供了实证支撑。
六、实用延伸:不止校准,还能选更靠谱的答案
EAGLE的价值不只是校准——用它来筛选模型生成的答案,能直接提升准确率!在TriviaQA数据集上,给每个问题生成5个答案,选EAGLE置信度最高的那个,Qwen2.5 7B和Llama3 8B的准确率都比直接用第一个答案更高,这也让EAGLE的落地场景更丰富。
七、总结:从“表面”到“内部”,解锁LLM置信度新高度
EAGLE的出现,打破了“依赖最终输出做校准”的固有思路,把目光投向了LLM的内部表征。它不用额外训练,却能通过聚合多层对数几率、计算分布期望,精准捕捉模型的真实信念,让校准性能实现质的飞跃。
对于实际应用来说,这意味着LLM的输出不再是“盲目的自信”,我们能更可靠地判断模型答案的可信度——不管是智能问答、代码生成还是决策辅助,EAGLE都能让LLM的部署更安全、更可信。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献133条内容
已为社区贡献133条内容

所有评论(0)