OmniVLA:面向机器人导航的全模态VLA基础模型
论文《OmniVLA: An Omni-Modal Vision-Language-Action Model for Robot Navigation》是 UC Berkeley 联合 Toyota、Princeton 推出的首个端到端全模态 VLA 导航基础模型。论文核心突破为统一语言、2D 位姿、自中心图像三大目标模态,用 9500 小时跨平台真实机器人数据训练,实现了单模型适配多模态指令、跨环境泛化、跨机型迁移,彻底解决传统导航策略单模态受限、泛化差的痛点。
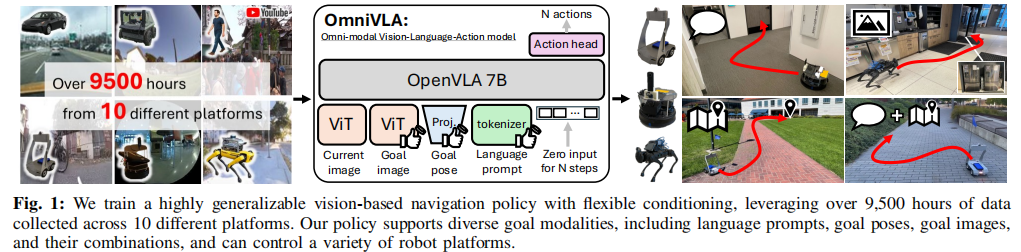
原文链接:OmniVLA: An Omni-Modal Vision-Language-Action Model for Robot Navigation
代码链接:NHirose/OmniVLA: Official repository for OmniVLA training and inference code
沐小含持续分享前沿算法论文,欢迎关注...
1. 研究背景与动机
1.1 人类导航的天然多模态性
人类导航会灵活组合多种信息:
- 近距离用自然语言:「沿着建筑走到入口」
- 远距离用 GPS 坐标:精准定位目标位置
- 复杂场景用视觉地标:看到目标图像后导航
多模态信息互补,是完成复杂导航任务的核心。
1.2 现有机器人导航的核心痛点
传统导航策略存在三大致命缺陷:
- 单模态训练:仅支持语言 / 位姿 / 图像一种输入,无法融合多源信息
- 数据集割裂:只能用单一模态标注数据,无法利用海量多模态数据
- 泛化能力弱:对 unseen 环境、新模态、新机器人平台适配性差
1.3 研究核心目标
提出全模态视觉 - 语言 - 动作(OmniVLA)框架,实现:
- 单模型支持语言、2D 位姿、自中心图像及任意组合输入
- 利用 9500 小时跨平台数据,学习通用导航能力
- 强泛化: unseen 环境、稀缺模态、OOD 语言指令均能适配
- 可微调:快速适配新模态、新环境、新机器人
2. 相关工作梳理
论文从导航模态、VLA 模型、机器人基础模型三个维度对比现有工作:
2.1 面向导航任务的单模态目标指定方法
在机器人导航中,目标可通过自中心图像、2D 位姿、自然语言三种模态指定,而现有工作几乎均为单模态专用策略,无法组合多源信息,无法复用跨模态数据集,限制了真实场景的通用性。这也是 OmniVLA 要解决的核心痛点。
2.1.1 自中心图像条件导航(Egocentric Image-Conditioned Navigation)
- 核心定位:依赖视觉地标完成导航,适合室内无 GPS 环境。
- 现有工作特点:
- 融合多机器人具身的公开数据集,训练通用导航策略;
- 依赖丰富视觉信息,无法利用 GPS 等空间信号;
- 代表工作:ViNT、NoMaD、GNM 等系列模型。
- 局限性:仅支持图像目标,无法融合语言或位姿指令。
2.1.2 2D 位姿条件导航(2D Pose-Conditioned Navigation)
- 核心定位:依赖 GPS 等空间坐标,适合室外长视野(long-horizon)导航。
- 现有工作特点:
- 以 2D 坐标作为目标条件,在室外定位可靠的场景效果最优;
- 代表工作:MBRA,提出基于模型的重标注(reannotation)方案,可利用大规模数据源完成更远距离的位姿条件导航。
- 局限性:仅依赖空间位置,缺乏视觉与语义理解。
2.2 语言条件导航(Language-Conditioned Navigation)
论文将语言导航单独作为重点子领域梳理,完整还原其发展脉络与瓶颈。
2.2.1 语言导航的价值
- 提供用户友好、灵活的交互接口;
- 可指导机器人到达指定物体 / 区域,支持长距离任务。
2.2.2 技术发展脉络
- 早期方法依赖预训练语言编码器,仅能处理简单物体指向类指令。
- 近期方法采用大规模VLM 主干,直接用于导航或在机器人数据上微调;引入反事实动作生成(counterfactual action generation)、非机器人数据提升训练稳定性与泛化性。
- 代表工作:LeLaN同时利用机器人与非机器人视频数据;基于模型生成反事实动作与 VLM 推导语言提示;支持可扩展训练,但合成标注的不准确性会成为性能瓶颈。
2.2.3 语言导航的核心局限
即便语言导航最先进的方法,仍只支持单一语言模态,无法与位姿、图像模态联合使用;且依赖特定格式指令,泛化性受限。
2.3 具身操作领域的机器人基础模型(Robotic Foundation Models in Manipulation)
论文强调:OmniVLA 的全模态 + Mask 训练思路并非凭空创新,而是受具身操作领域成功范式的启发,并首次迁移到导航领域。
2.3.1 核心思想
操作领域的机器人基础模型(RFM)旨在统一视觉、语言、动作以提升泛化能力,从早期多模态 Transformer 发展为大规模、面向真实部署的通用控制框架。
2.3.2 关键技术:多输入掩码训练
- 部分操作领域工作使用掩码(masking)机制处理训练时缺失的输入(语言、位姿等);
- 证明同时训练多种输入类型能显著提升模型泛化性;
- 代表工作:Octo、
等开源通用机器人策略。
2.3.3 与导航领域的鸿沟
- 操作领域的多模态 VLA 范式尚未被引入导航;
- 导航缺乏统一全模态架构、超大规模跨具身数据集;
- 导航任务的空间推理、长视野、环境分布复杂度远高于桌面操作。
2.4 本文创新点
基于以上梳理,论文给出 OmniVLA 的精准创新定位:
- 首次将操作领域的全模态 VLA 范式落地到机器人导航,统一图像、位姿、语言三大目标模态;
- 构建迄今最大规模的导航预训练数据集:近 10,000 小时真实机器人导航数据,覆盖 10 种具身平台;
- 用模态随机掩码策略解决模态不平衡与稀缺问题;
- 超越所有单模态专用导航模型,并具备基础模型的微调与泛化特性。
3. 核心技术原理
3.1 核心定位
OmniVLA 的核心定位:一个支持全模态目标条件的端到端视觉 - 语言 - 动作导航策略。它的设计严格遵循三大原则:
- 基座复用:基于成熟高容量 VLA 模型,继承互联网预训练视觉 - 语言先验与跨具身机器人动作先验;
- 模态统一:将语言、位姿、图像三种目标模态投影到共享Token空间,实现统一编码与融合;
- 模态鲁棒:用 ** 模态 Dropout(训练)+ 模态 Mask(推理)** 解决模态缺失、不平衡、稀缺问题。
最终输出:连续动作序列,直接控制机器人完成避障、路径跟随、目标到达等导航行为。
3.2 OmniVLA 网络架构
OmniVLA 包含两个版本,分别面向高性能与边缘部署。
3.2.1 基座模型选型
- 主模型:OmniVLA(7B 参数)
- 基座:OpenVLA(7B 参数 VLA 模型)
- 主干:Llama2-7B LLM + DINOv2+SigLIP 视觉编码器
- 能力:强泛化、支持 OOD 语言、长距离导航
- 轻量模型:OmniVLA-edge(50M 参数)
- 基座:ViNT(面向导航的轻量化 Transformer)
- 主干:EfficientNet-B0 视觉编码器 + CLIP 语言编码
- 能力:低算力、边缘端实时推理
3.2.2 全模态输入流水线
架构整体分为4 层:观测输入 → 多模态目标编码 → 共享令牌融合 → LLM 主干 → 动作输出。
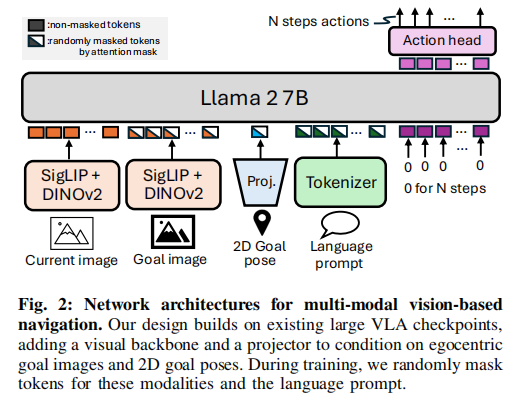
(1)当前观测编码(Robot Current Observation)
- 输入:机器人自中心单目 RGB 图像
- 处理:视觉编码器(OpenVLA 用 DINOv2+SigLIP;OmniVLA-edge 用 EfficientNet-B0)
- 输出:固定维度的视觉观测特征,送入 LLM/Transformer
(2)三大目标模态编码(核心创新)
论文支持三种原生目标模态,将每种模态独立编码后投影到共享空间:
① 自中心目标图像模态(Egocentric Goal Image)
- 输入:目标位置的自中心图像
- 处理:目标图像编码器 + 线性投影器
- 作用:让机器人 “看目标去哪”,适合室内近距离、无 GPS 场景
② 2D 目标位姿模态(2D Goal Pose)
- 输入:2D 目标坐标
(GPS / 局部坐标系)
- 处理:专用位姿投影器(Pose Projector)
- 作用:将坐标映射为与视觉 / 语言兼容的特征向量,适合室外远距离导航
③ 自然语言指令模态(Language Prompt)
- 输入:文本指令
(如 “move along the wall”)
- 处理:语言编码器 / Tokenizer(OpenVLA 用 LLaMA-2 Tokenizer;edge 用 CLIP 文本编码器)
- 作用:提供语义约束,实现 “怎么去” 的行为控制
(3)共享Token空间与模态融合
- 所有模态编码后,统一投影到相同维度的Token空间
- Token拼接后,作为条件输入送入 LLM 主干
- 关键:不区分模态类型,让模型学习统一的目标表示
(4)模态 Dropout / Mask 机制(论文核心技术)
这是 OmniVLA 能处理任意模态组合、缺失模态的关键:
- 训练阶段:Modality Dropout(随机模态丢弃)
- 对每个训练样本,独立随机采样可用的目标模态
- 未被采样的模态:输入置空 / 随机值,并生成注意力掩码屏蔽
- 效果:强制模型不依赖某一种模态,学习跨模态通用表示
- 推理阶段:Modality Mask(模态掩码)
- 用户提供哪些模态,就只启用哪些模态的通路
- 缺失模态直接被掩码屏蔽,不影响推理
- 效果:支持单模态、双模态、三模态任意组合输入
(5)动作输出头(Action Head)
- 结构:LLM 输出后接线性层动作头(遵循 OpenVLA-OFT 设计)
- 输出:N 步连续动作序列
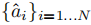
- 动作定义:线速度
+ 角速度
,直接驱动机器人底盘
3.3 OmniVLA-edge 轻量化架构
为满足边缘部署,论文专门设计OmniVLA-edge,完全基于 ViNT 改造:
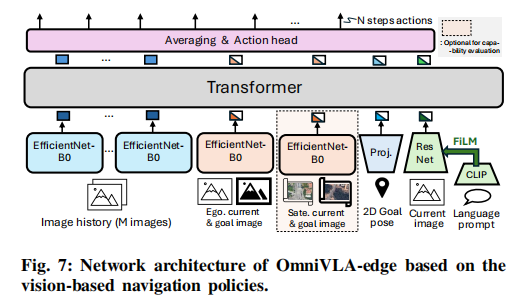
- 早期融合(Early Fusion):模态令牌在送入 Transformer 前完成融合
- 时序输入:输入最近 M=5 帧 图像特征,保持运动时序一致性
- 多模态适配:
- 添加位姿投影器支持 2D Pose
- 用 ResNet+CLIP+FiLM 实现语言条件
- Token 聚合:对 Transformer 输出取均值,送入动作头
- 参数规模:仅50M 参数,算力受限场景首选
3.4 训练方案
3.4.1 训练数据集
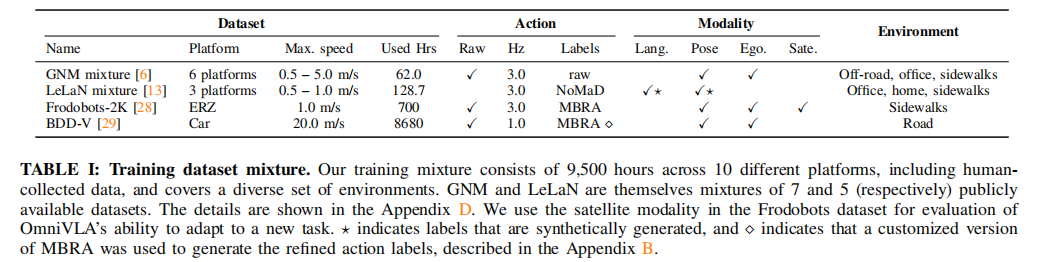
OmniVLA 使用迄今最大规模的导航预训练数据集:
- 总时长:9,500 小时
- 机器人平台:10 种(轮式、四足、无人车)
- 数据集:13 个公开数据集,合并为 4 大混合集:
- GNM mixture(6 平台,62h):越野、办公室、人行道
- LeLaN mixture(3 平台,128.7h):家庭、办公室、人行道
- Frodobots-2K(1 平台,700h):人行道
- BDD-V(1 平台,8,680h):城市道路(汽车数据)
3.4.2 数据重标注(解决 Embodiment Gap)
BDD-V 是汽车采集数据,与小型机器人存在巨大差异:速度快 40 倍、帧率 1Hz(其他 3Hz)、GPS 噪声大、画面含仪表盘等。论文通过如下方式进行数据重标注来匹配机器人训练场景:
- 基于MBRA训练专用重标注模型
- 仅在 GNM 数据上学习避障,BDD-V 只学习视觉分布
- 约束动作空间:线速度 0–0.5m/s,角速度 ±1.0rad/s
- 遵循双轴同轴机器人运动学模型,保证动作可执行
3.4.3 训练流程
- 批次构建
- 采样比例:LeLaN : GNM : Frodobots : BDD-V = 4:1:1:1
- 目的:平衡语言、位姿、图像三种模态的数据分布
- 模态随机选择
- 对每个样本,从可用模态中随机选取组合作为条件 tm
- 示例:GNM 可选择 Pose、Image、Pose+Image
- 注意力掩码生成
- 未选中模态被掩码,模型仅关注有效输入
- 梯度累积
- 8×H100,单卡 batch=7,累积 4 步 → 有效 batch=224
- LoRA 微调
- 仅对 OpenVLA 主干使用,可训练参数≈5%
- 目的:增大有效 batch,稳定训练
3.5 损失函数
OmniVLA 使用多目标联合损失,目标函数为:
![]()
(1)主损失:动作模仿损失 
- 作用:让模型输出动作逼近专家动作
- 公式:
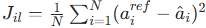
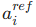 :专家动作(人工 / 重标注)
:专家动作(人工 / 重标注)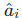 :模型预测动作
:模型预测动作:动作 chunk 长度(论文固定 N=8)
(2)语言任务辅助损失 
- 作用:让语言导航任务最终动作靠近目标物体
- 公式:
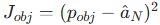
:目标物体位姿
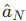 :模型第 N 步(最后一步)预测动作
:模型第 N 步(最后一步)预测动作:掩码系数 → LeLaN 数据为 1,其余为 0
(3)动作平滑损失 
- 作用:正则化,让动作序列更平滑、抖动更小
- 公式:
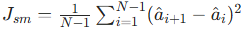
3.6 全模态条件推理机制
模型最终策略函数为:
![]()
各参数含义:
:当前自中心图像
:目标图像
:2D 目标位姿
:当前启用的模态组合
:全模态导航策略
策略支持的输入组合如下:
- 仅语言
- 仅 2D 位姿
- 仅目标图像
- 语言 + 2D 位姿
- 语言 + 目标图像
- 2D 位姿 + 目标图像
- 语言 + 2D 位姿 + 目标图像
3.7 核心技术创新总结
- 首次统一导航三大模态:语言、2D 位姿、自中心图像在一个 VLA 模型内
- 模态随机融合策略:用 Dropout/Mask 实现模态鲁棒性
- 最大规模导航预训练:9,500 小时跨具身数据
- 共享令牌空间:跨模态表示学习,提升泛化
- 双架构设计:7B 高性能版 + 50M 边缘版
- 可扩展基础模型:支持新模态、新环境、新机器人小数据微调
4. 实验设置
4.1 三大导航任务
- 语言指令导航
- 场景:40 个室内外环境,目标距离 5-30 米
- 测试:常规指令 + OOD 行为指令(如「沿墙走」)+ 障碍物场景
- 自中心图像导航
- 近距离:直接目标图像导航
- 远距离:拓扑记忆图扩展到远程目标
- 2D 位姿导航
- 室外 GPS 场景,目标距离 25-100 米,抗 GPS 抖动
4.2 机器人平台

- 主平台:FrodoBots ERZ(带 GPS、相机、IMU)
- 跨机型测试:VizBot 轮式机器人、Unitree Go1 四足机器人
4.3 对比基线
7 个 SOTA 基线:
- 单模态专用:CoW、LeLaN、MBRA-pose/image、NoMaD、ViNT
- VLA 模型:CounterfactualVLA、MiniVLA、SmolVLA
5. 实验结果与分析
5.1 核心研究问题
论文围绕 3 个核心问题展开实验:
- 全模态预训练是否优于单模态专用模型?
- 模型能否处理多模态组合指令?
- 能否快速适配新模态、环境、机型?
5.2 单模态性能对比(表 II)
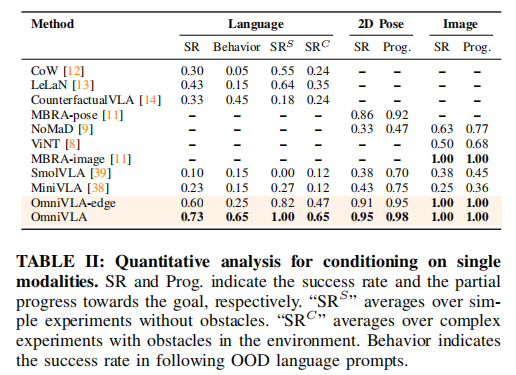
关键结论:
- OmniVLA 全面超越所有单模态基线
- 语言任务:成功率 73%,OOD 行为遵循 65%,远超 LeLaN(43%/15%)
- 2D 位姿:成功率 95%,比 MBRA-pose 提升 9%
- 图像任务:100% 成功率,追平最优专用模型
- 模型规模至关重要
- 7B OmniVLA >> 50M OmniVLA-edge >> 小 VLA(Mini/SmolVLA)
- 大模型继承的视觉 - 语言先验是语言任务提升核心
- 轻量版性价比极高
- OmniVLA-edge 仅 50M 参数,图像 / 位姿性能接近大模型,适合边缘部署
5.3 多模态训练消融(表 III)
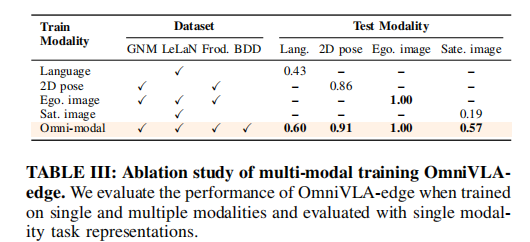
关键结论:
- 全模态训练远优于单模态训练
- 语言:60% vs 单模态 43%
- 卫星图像:57% vs 单模态 19%
- 位姿 / 图像:保持最优性能
- 跨模态知识迁移:模型从多模态数据中学习通用导航表示,泛化到未见过的卫星模态
5.4 多模态组合导航(表 IV)
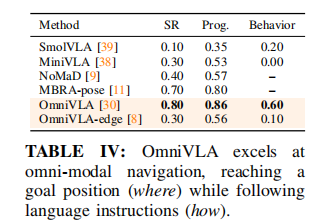
任务定义:同时输入2D 目标位姿(去哪)+ 语言行为指令(怎么去),如「去 GPS 目标点,同时沿草地走」。
关键结论:
- OmniVLA 唯一能完成复合任务
- 成功率 80%,行为遵循 60%
- 基线仅能完成位姿导航,无法遵循语言约束
- 模型能同时关注多模态信息,实现「目标位置 + 行为约束」的复杂导航
可视化结果:

5.5 新模态 / 环境 / 机型适配
5.5.1 新模态适配(卫星图像)
- 预训练无卫星模态,仅替换编码器微调
- 成功率从 19% 提升至 62%,快速适配新模态
5.5.2 新环境微调(表 V)
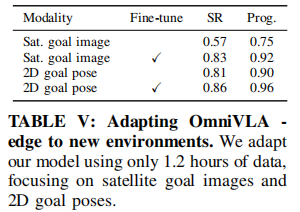
- 仅用 1.2 小时小数据微调
- 卫星图像:57%→83%;2D 位姿:81%→86%
- 小数据快速适配新环境
5.5.3 跨机型迁移
- 零样本部署到 VizBot 轮式、Go1 四足机器人
- 直接完成语言指令导航,能进行跨机型泛化

6. 结论与展望
6.1 核心贡献
- 首个全模态 VLA 导航模型:统一语言、位姿、图像三大模态
- 最大规模导航预训练:9500 小时跨平台数据,强泛化
- 优异性能:全面超越单模态基线,支持多模态组合
- 基础模型特性:快速适配新模态、环境、机器人
6.2 未来方向
- 扩大语言导航数据集,提升复杂指令遵循能力
- 扩展更多模态(如卫星图像、点云)
- 进一步优化轻量版,适配更低算力边缘设备
7. 全文总结
OmniVLA 是机器人导航领域的里程碑工作,首次将全模态 VLA 架构引入导航,打破了单模态模型的局限。
它证明了:用统一模型学习多模态导航表示,能获得比专用模型更强的泛化性与灵活性,为通用机器人导航基础模型提供了可复制的技术路线。
无论是学术研究还是工业落地,OmniVLA 的全模态设计、大规模训练、跨域迁移思路,都将成为未来机器人导航的核心范式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)