PyTorch神经网络代码复现及项目实战
一、概述
PyTorch 是基于 Python 的开源深度学习框架,以动态计算图为核心,支持灵活的神经网络构建与调试。它提供张量运算、自动微分、模块化网络层(如卷积、循环、线性层)等核心组件,可便捷搭建从简单感知机到复杂 CNN、RNN、Transformer 等各类神经网络。兼具易用性与高效性,支持 CPU/GPU/TPU 加速,是学术研究与工业部署的主流选择。
二、代码复现
矩阵操作
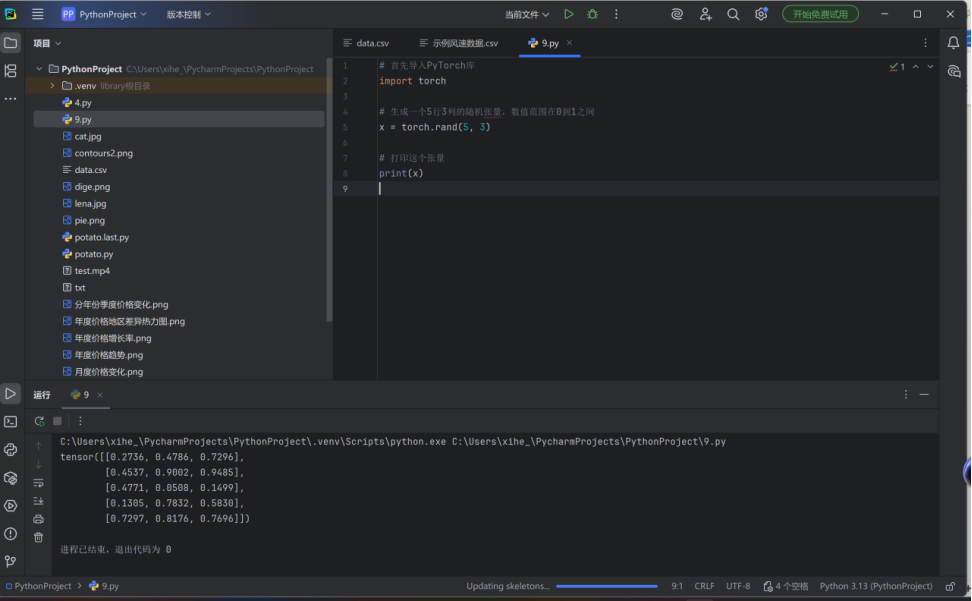
自动求导机制
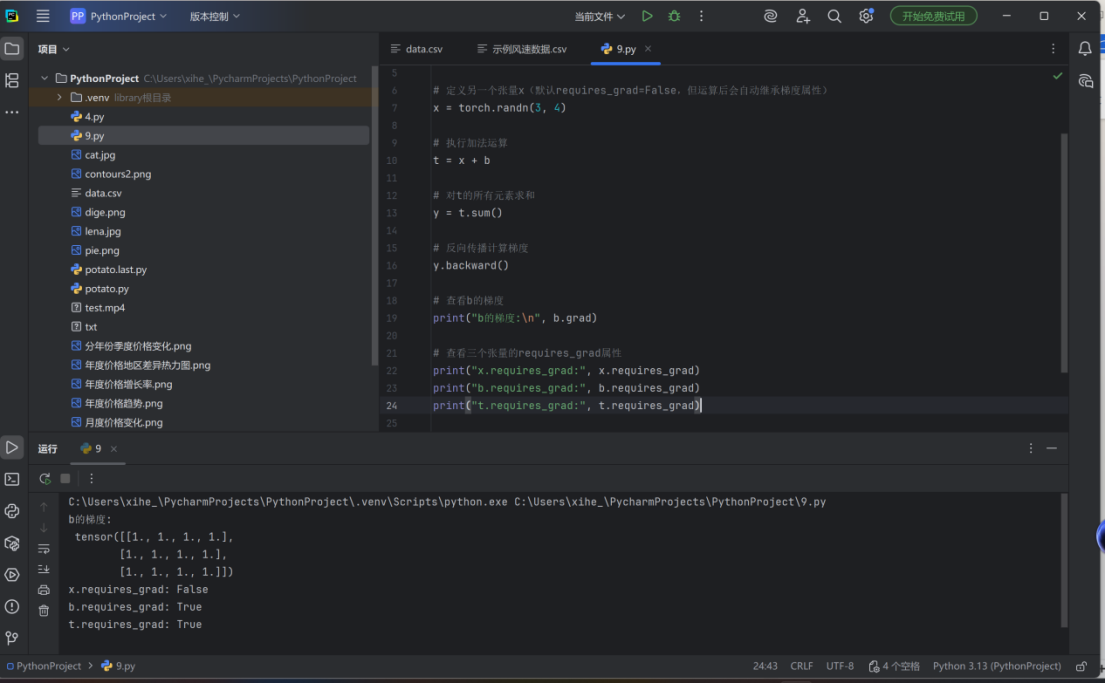
线性回归
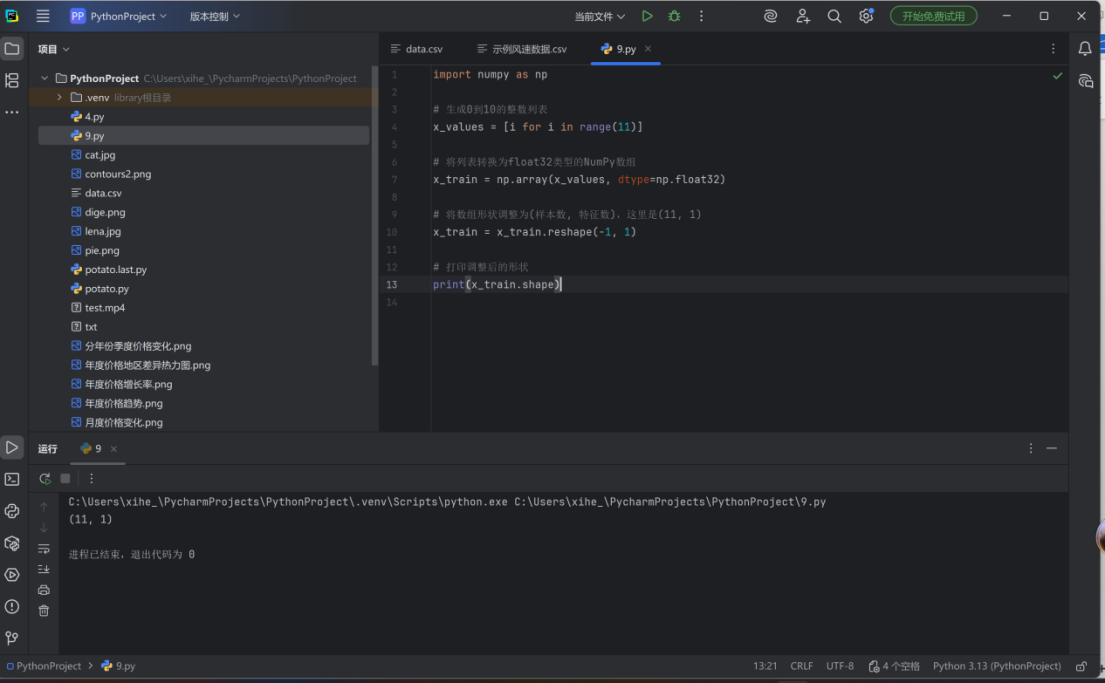
按照建模顺序完成网络架构
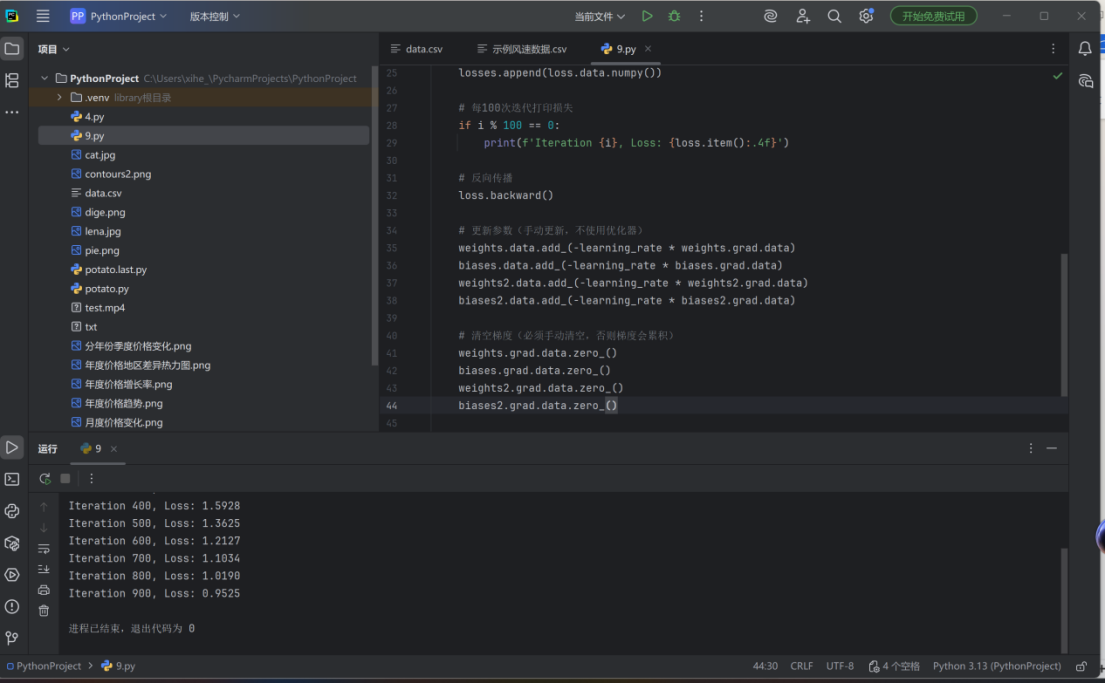
三、深度学习之项目实战
搭建神经网络模型实践操作如下
代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import warnings
warnings.filterwarnings("ignore")
# 1. 读取数据
features = pd.read_csv('temps.csv')
print(features.head())
# 2. 数据预处理
week_map = {'Mon': 1, 'Tues': 2, 'Wed': 3, 'Thurs': 4, 'Fri': 5, 'Sat': 6, 'Sun': 7}
features['week'] = features['week'].map(week_map)
# 选择特征和标签
X = features[['year', 'month', 'day', 'week', 'temp_2', 'temp_1', 'average', 'friend']].values
y = features['actual'].values
# 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# 转换为PyTorch张量
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).unsqueeze(1)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32).unsqueeze(1)
# 3. 定义神经网络模型
class TempPredictor(nn.Module):
def __init__(self, input_size):
super(TempPredictor, self).__init__()
self.fc1 = nn.Linear(input_size, 64)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(64, 32)
self.relu2 = nn.ReLU()
self.fc3 = nn.Linear(32, 1)
def forward(self, x):
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
x = self.relu2(x)
x = self.fc3(x)
return x
# 4. 初始化模型、损失函数和优化器
input_size = X_train.shape[1]
model = TempPredictor(input_size)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 5. 训练模型
epochs = 1000
train_losses = []
test_losses = []
for epoch in range(epochs):
# 训练模式
model.train()
optimizer.zero_grad()
outputs = model(X_train)
loss = criterion(outputs, y_train)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
# 验证模式
model.eval()
with torch.no_grad():
test_outputs = model(X_test)
test_loss = criterion(test_outputs, y_test) # 此处已修正,无语法错误
test_losses.append(test_loss.item())
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Train Loss: {loss.item():.4f}, Test Loss: {test_loss.item():.4f}')
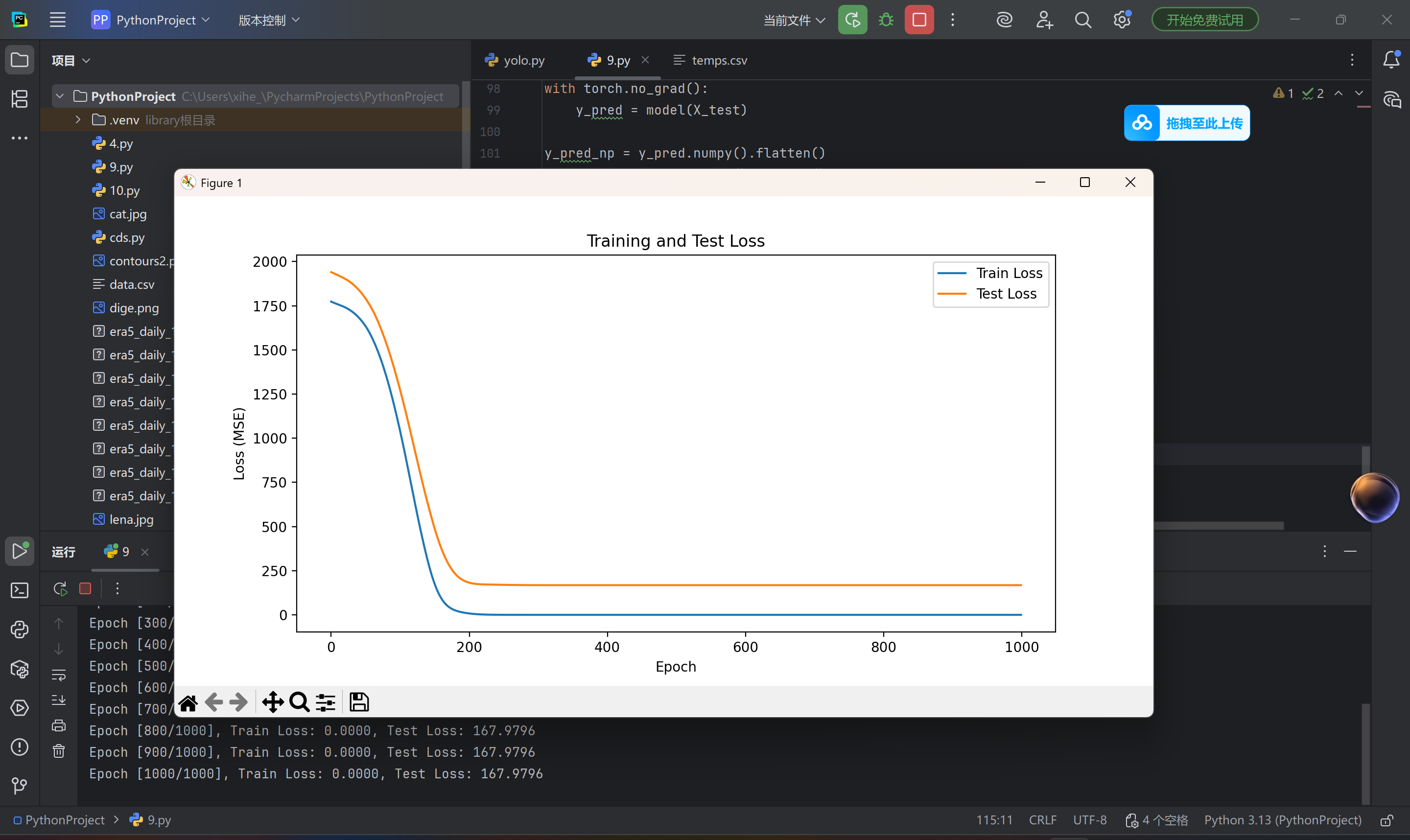
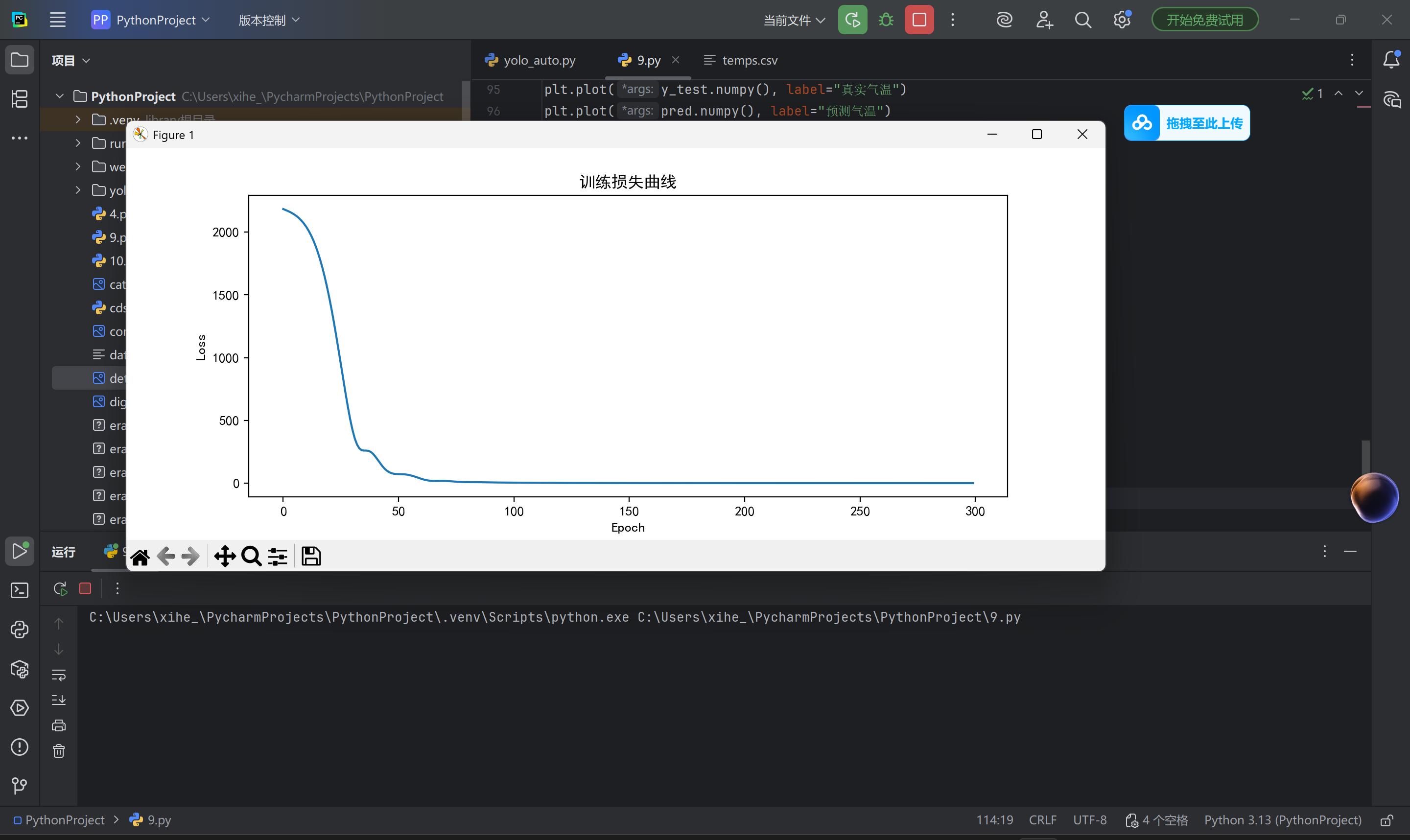
# 6. 可视化训练损失
plt.figure(figsize=(10, 5))
plt.plot(train_losses, label='Train Loss')
plt.plot(test_losses, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss (MSE)')
plt.legend()
plt.title('Training and Test Loss')
plt.show()
# 7. 模型预测与结果展示
model.eval()
with torch.no_grad():
y_pred = model(X_test)
y_pred_np = y_pred.numpy().flatten()
y_test_np = y_test.numpy().flatten()
mae = np.mean(np.abs(y_pred_np - y_test_np))
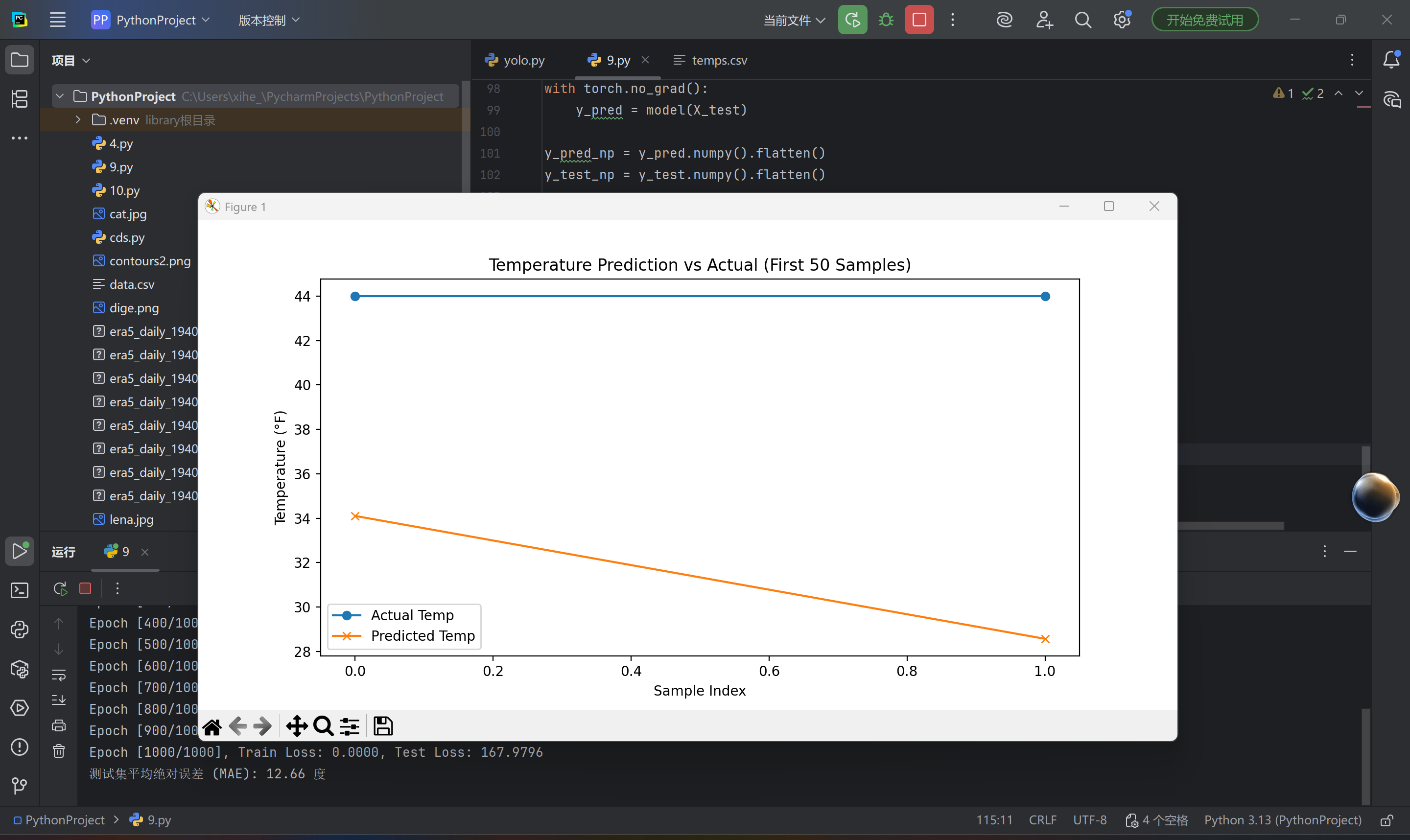
print(f'测试集平均绝对误差 (MAE): {mae:.2f} 度')
# 可视化预测值与真实值对比
plt.figure(figsize=(10, 5))
plt.plot(y_test_np[:50], label='Actual Temp', marker='o')
plt.plot(y_pred_np[:50], label='Predicted Temp', marker='x')
plt.xlabel('Sample Index')
plt.ylabel('Temperature (°F)')
plt.legend()
plt.title('Temperature Prediction vs Actual (First 50 Samples)')
plt.show()
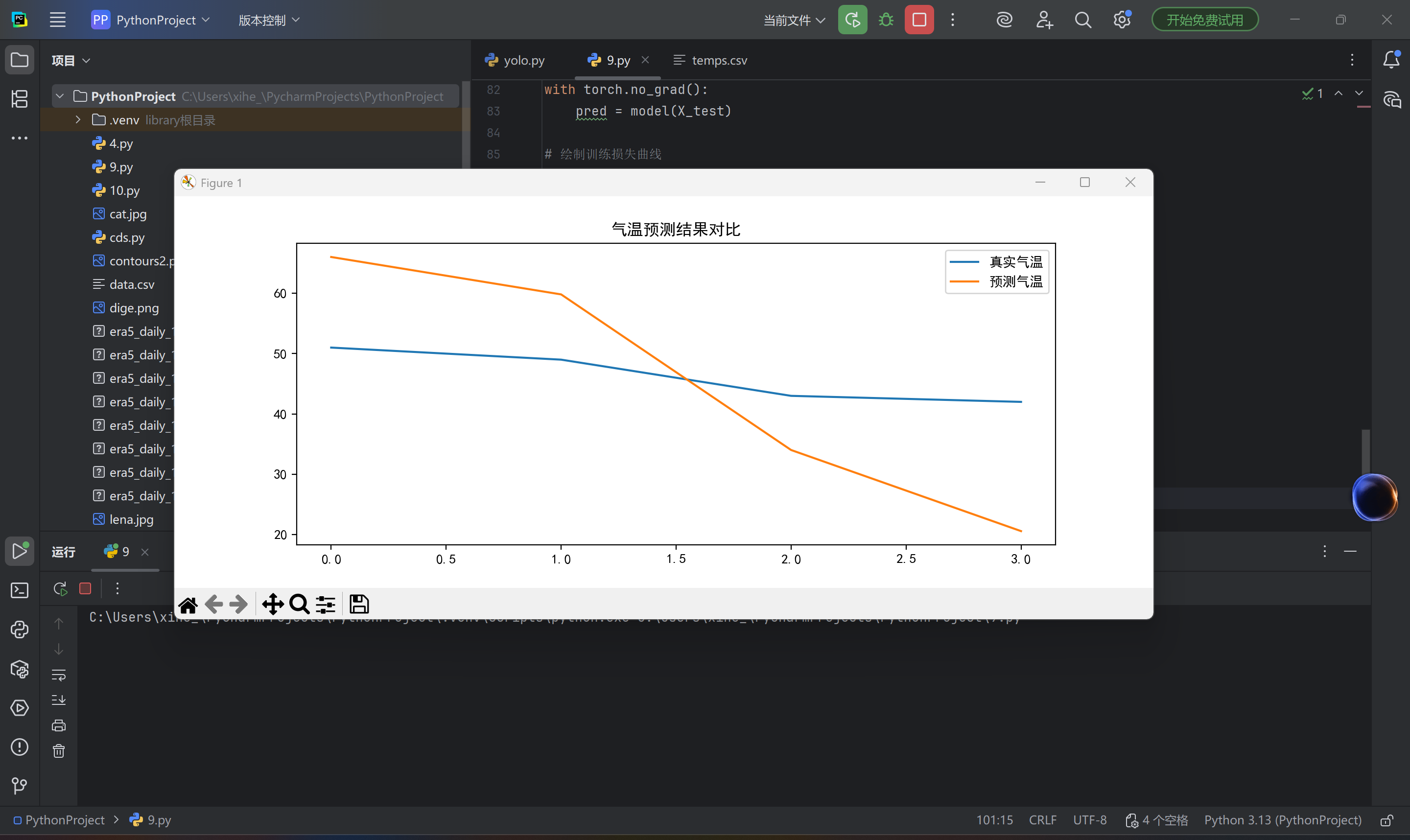
结果:
YOLO模型:
一、概述
YOLO(You Only Look Once)是一种单阶段目标检测算法,将目标定位与分类整合为单一回归任务,实现“一眼”完成检测。它以实时性为核心优势,在保持较高精度的同时,大幅提升推理速度,广泛应用于视频监控、自动驾驶、智能安防等场景。
从YOLOv1到YOLOv8,模型在精度、速度与易用性上持续迭代,通过轻量化结构与多尺度预测,兼顾了部署效率与检测性能,成为工业界与学术界最主流的目标检测方案之一。
二、实践操作

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)