RAG综述解读
https://arxiv.org/pdf/2312.10997
一段话总结
这篇综述聚焦大语言模型(LLMs)面临的幻觉、知识过时、推理不透明问题,系统阐述了检索增强生成(RAG) 技术的发展脉络、核心框架、评估体系及未来方向,将 RAG 研究范式划分为Naive RAG、Advanced RAG、Modular RAG 三个阶段,深入剖析了检索、生成、增强三大核心组件的关键技术,梳理了覆盖26 类下游任务、近 50 个数据集 的 RAG 评估体系,指出 RAG 通过融合 LLMs 固有知识与外部动态知识库,有效提升了生成的准确性和可信度,同时探讨了其在长上下文适配、鲁棒性、与微调融合等方面的挑战,以及多模态、工程化落地等未来研究方向。
详细总结
本文是一篇关于检索增强生成(RAG) 技术的综合性综述,针对大语言模型(LLMs)的固有缺陷,系统梳理了 RAG 的发展历程、核心技术、评估体系,并分析了其现存挑战与未来研究方向,核心内容如下:
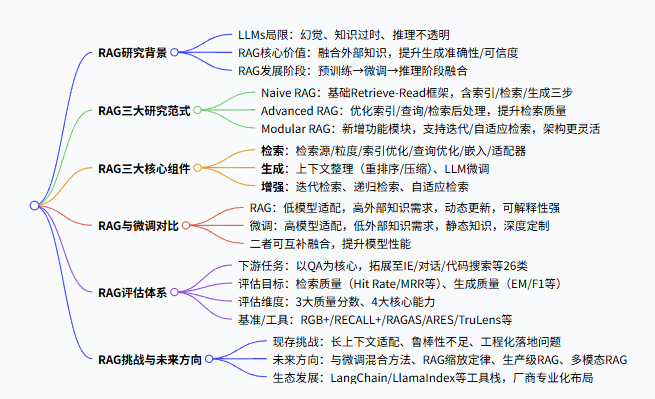
一、研究背景与核心价值
- LLMs 的核心局限:存在幻觉、知识更新不及时、推理过程非透明 / 不可追溯,在知识密集型任务中表现不佳。
- RAG 的解决思路:通过语义相似度计算从外部知识库检索相关文档片段,将外部知识与 LLMs 固有知识融合,弥补其知识缺陷。
- RAG 的发展轨迹:随 Transformer 架构兴起,初期聚焦预训练阶段知识融合;ChatGPT 出现后,转向推理阶段为 LLMs 提供信息;后续逐步与 LLM 微调技术深度结合。
- 本文核心贡献:梳理 RAG 三大范式、剖析三大核心组件技术、总结覆盖26 类任务、近 50 个数据集 的评估体系、展望未来研究方向。
二、RAG 三大研究范式
RAG 的范式发展是对前序范式缺陷的针对性优化,三者的核心特征与差异如下表:
表格
| 范式类型 | 核心架构 | 关键步骤 / 优化 | 主要缺陷 |
|---|---|---|---|
| Naive RAG | 经典 Retrieve-Read 框架 | 索引(数据清洗→分块→向量化)、检索(语义相似度匹配 Top K)、生成(融合查询 + 检索内容生成答案) | 检索精度 / 召回率低、生成易幻觉、增强过程易冗余 / 不连贯 |
| Advanced RAG | 链式结构,优化检索全流程 | 检索前:索引精细化、查询重写 / 扩展;检索后:片段重排序、上下文压缩 | 仍为固定链式流程,灵活性不足 |
| Modular RAG | 模块化架构,支持灵活重组 | 新增 Search/Memory/Routing 等模块;支持迭代 / 自适应 / 递归检索,模块可替换 / 重排 | 架构复杂度提升,模块协同要求高 |
三、RAG 三大核心技术组件
RAG 的核心由检索、生成、增强 三部分构成,各部分的关键优化技术如下:
- 检索组件:决定外部知识获取的准确性,核心优化方向包括
- 检索源:从非结构化文本拓展至半结构化(PDF)、结构化数据(知识图谱)、LLM 生成内容;
- 检索粒度:从细到粗含 Token / 短语 / 句子 / Chunk / 文档等,知识图谱粒度为实体 / 三元组 / 子图;
- 索引优化:优化分块策略(滑动窗口 / 递归分割)、附加元数据、构建层级 / 知识图谱索引;
- 查询优化:查询扩展(多查询 / 子查询)、转换(重写 / HyDE)、路由(元数据 / 语义路由);
- 嵌入:融合稀疏 / 稠密检索,针对领域数据微调嵌入模型,通过 LLM 提供监督信号;
- 适配器:引入轻量级适配器,适配多任务 / 特定任务,降低微调成本。
- 生成组件:解决检索内容与 LLM 的高效融合,核心优化包括
- 上下文整理:通过模型 / 规则重排序提升相关片段优先级,通过压缩 / 筛选解决 “Lost in the middle” 问题,去除冗余信息;
- LLM 微调:针对特定领域 / 任务微调,适配输入输出格式;通过强化学习对齐人类 / 检索器偏好;与检索器协同微调。
- 增强组件:针对复杂问题优化检索方式,突破单次检索的局限,包含
- 迭代检索:交替进行检索与生成,为复杂任务提供更全面的上下文;
- 递归检索:将复杂查询拆解为子查询,逐步收敛至核心信息,适配多跳推理;
- 自适应检索:由 LLM 自主判断是否需要检索、何时停止检索,通过特殊令牌 / 置信度阈值控制,提升效率。
四、RAG 与其他 LLM 优化方法的对比
RAG、微调(FT)、提示工程是 LLM 三大核心优化方法,核心差异体现在外部知识需求和模型适配需求两个维度:
- 提示工程:低外部知识需求、低模型适配需求,仅挖掘 LLMs 固有能力;
- RAG:高外部知识需求、低(早期)→高(模块化阶段)模型适配需求,可动态更新知识,可解释性强,推理延迟较高;
- 微调:低外部知识需求、高模型适配需求,知识静态化,需重新训练更新,可深度定制模型行为。
- 二者互补:RAG 在知识密集型任务中表现优于无监督微调,且 RAG 与微调可融合使用(如先检索再微调、协同微调),实现性能最优。
五、RAG 评估体系
目前 RAG 评估已形成覆盖任务、目标、维度、工具 的完整体系,核心内容如下:
- 下游任务:以问答(QA) 为核心(单跳 / 多跳 / 长文本 / 领域 QA),拓展至信息抽取(IE)、对话生成、代码搜索、文本摘要等26 类任务,对应近 50 个数据集;
- 评估目标:分为检索质量(Hit Rate、MRR、NDCG 等)和生成质量(EM、F1、Accuracy、BLEU/ROUGE 等);
- 核心评估维度:
- 3 大质量分数:上下文相关性、答案忠实性、答案相关性;
- 4 大核心能力:噪声鲁棒性、否定拒绝能力、信息整合能力、反事实鲁棒性;
- 评估基准与工具:基准包括 RGB+、RECALL+、CRUD+;自动化工具包括 RAGAS、ARES、TruLens,部分工具采用定制化量化指标。
六、RAG 现存挑战与未来研究方向
- 核心挑战
- 长上下文适配:LLMs 上下文长度突破 20 万 Token 后,RAG 的必要性与优化方式需重新探索;
- 鲁棒性不足:检索中的噪声 / 矛盾信息会严重影响生成质量,甚至出现 “误信息不如无信息” 的情况;
- 工程化落地:大知识库中检索效率 / 召回率低、数据安全(如元数据泄露)、工具栈整合难度大。
- 未来研究方向
- 混合方法:探索 RAG 与微调的最优融合方式(序贯 / 交替 / 端到端训练);
- RAG 缩放定律:研究 RAG 模型参数与性能的关系,验证逆缩放定律的适用性;
- 生产级 RAG:提升检索效率、保障数据安全,推动 RAG 工具栈的定制化 / 简化 / 专业化;
- 多模态 RAG:将 RAG 从文本拓展至图像、音频、视频、代码等多模态数据,适配多模态任务;
- 生态发展:LangChain、LlamaIndex 等工具栈成为基础,传统软件 / 云厂商布局 RAG 专属服务,形成专业化生态。
七、结论
RAG 通过融合 LLMs 的参数化知识与外部非参数化知识库,有效解决了 LLMs 的核心缺陷,成为提升其知识密集型任务性能的关键技术;其范式从 Naive RAG 逐步发展为更灵活的 Modular RAG,核心技术不断优化,评估体系日趋完善;未来 RAG 将向长上下文适配、高鲁棒性、多模态、工程化落地 方向发展,同时与微调等技术深度融合,其工具栈与生态也将持续丰富,成为 AI 学术与工业界的研究重点。
关键问题
问题 1:RAG 的三大研究范式分别是什么,核心差异体现在哪里?
答案:RAG 的三大研究范式为Naive RAG、Advanced RAG、Modular RAG,核心差异体现在架构设计与优化方向:①Naive RAG 是基础的 Retrieve-Read 链式框架,仅包含索引、检索、生成三步,未做额外优化,存在检索精度低、生成易幻觉等问题;②Advanced RAG 在 Naive RAG 基础上,针对检索全流程做优化,包括检索前的索引 / 查询优化、检索后的重排序 / 上下文压缩,仍为链式结构,灵活性不足;③Modular RAG 是模块化架构,新增 Search/Memory/Routing 等功能模块,支持模块替换 / 重排,可实现迭代、自适应、递归检索,架构灵活性与适配性大幅提升,是目前的主流研究方向。
问题 2:RAG 在检索组件中针对 “查询优化” 提出了哪些核心方法,解决了什么问题?
答案:查询优化是为了解决 Naive RAG 直接使用用户原始查询导致的检索效果差、语言歧义 / 专业词汇理解困难等问题,核心方法分为三类:①查询扩展:将单查询拓展为多查询 / 子查询,通过 Chain-of-Verification 验证扩展查询,丰富查询上下文,提升检索相关性;②查询转换:通过 LLM / 专用小模型重写查询,或通过 HyDE 生成假设文档、Step-back Prompting 生成抽象问题,以转换后的内容为检索依据,降低查询与文档的语义鸿沟;③查询路由:基于元数据 / 语义信息将不同查询路由至专属 RAG 流水线,适配多场景的通用 RAG 系统,缩小检索范围。
问题 3:RAG 与微调(FT)作为 LLM 的核心优化方法,各有何优劣,二者该如何结合使用?
答案:①优势与劣势:RAG 的优势是可动态更新外部知识、可解释性强、无需大量计算资源重新训练,适合知识密集型 / 动态知识任务,劣势是推理延迟较高、对检索质量依赖大;微调的优势是可深度定制模型行为 / 风格、降低幻觉,适合固定结构 / 风格的任务,劣势是知识静态化、需重新训练更新、数据集准备与训练成本高。②结合方式:二者并非互斥,而是互补关系,核心结合方式包括:先通过 RAG 为 LLM 提供外部知识,再针对特定任务微调 LLM;对 RAG 的检索器与生成器进行协同微调,通过 KL 散度等方式对齐二者的评分函数;在 Modular RAG 中引入微调模块,针对特定任务微调检索器 / 生成器,提升模块性能;通过强化学习将人类 / 检索器偏好融入微调,实现 RAG 与微调的端到端融合,最终达到性能最优。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)