ArXiv:2603 | Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights

- 标题:Neural Thickets: Diverse Task Experts Are Dense Around Pretrained Weights
- 作者:Yulu Gan, Phillip Isola
- 单位:MIT CSAIL
- 论文链接:https://arxiv.org/abs/2603.12228
- 代码链接:https://github.com/sunrainyg/RandOpt
- 详细解读:https://mp.weixin.qq.com/s/9K90nM7WWJHgHav5Ec2WZw
摘要直译
Pretraining produces a learned parameter vector that is typically treated as a starting point for further iterative adaptation. In this work, we instead view the outcome of pretraining as a distribution over parameter vectors, whose support already contains task-specific experts. We show that in small models such expert solutions occupy a negligible fraction of the volume of this distribution, making their discovery reliant on structured optimization methods such as gradient descent. In contrast, in large, well-pretrained models the density of task-experts increases dramatically, so that diverse, task-improving specialists populate a substantial fraction of the neighborhood around the pretrained weights. Motivated by this perspective, we explore a simple, fully parallel post-training method that samples K parameter perturbations at random, selects the top , and ensembles predictions via majority vote. Despite its simplicity, this approach is competitive with standard post-training methods such as PPO, GRPO, and ES for contemporary large-scale models.
预训练(Pretraining)产生了一个学习到的参数向量,该向量通常被视为进一步迭代自适应(iterative adaptation)的起点。这项工作转而将预训练的结果视为参数向量的分布(distribution over parameter vectors),该分布的支撑集(support)中已经包含了特定任务的专家(task-specific experts)。我们证明,在小型模型中,此类专家解决方案在分布体积中所占的比例微乎其微,因此发现它们需要依赖诸如梯度下降等结构化优化方法。相比之下,在经过良好预训练的大型模型中,任务专家的密度急剧增加,因此多样化、能提升任务性能的专家占据了预训练权重周围邻域的很大一部分。受此视角的启发,我们探索了一种简单、完全并行的后训练方法,该方法随机采样 N N N 个参数微扰,选择前 K K K 个,并通过多数投票(majority vote)对预测进行集成。
尽管这种方法非常简单,但对于当代大规模模型,它在竞争力上与 PPO、GRPO 和 ES 等标准后训练方法相当。
研究背景
在机器学习的早期阶段(如 2001 年 Schmidhuber 等人的研究 Evaluating benchmark problems by random guessing),随机猜测(Random guessing)在解决当时的基准测试时偶尔有效,但对于拥有数十亿参数的现代大语言模型(LLMs),从头开始随机猜测出一个 ChatGPT 级别的模型概率微乎其微,因此这种方法长期以来被认为是毫无希望的。
然而,现有的共识主要集中在从头训练或依赖梯度优化的微调上。很少有研究去系统性地探讨:在经历了庞大计算量的大规模预训练之后,模型权重周围的局部损失地形(loss landscape)到底发生了怎样的根本性拓扑偏移。
研究动机
既然预训练极大程度地改变了参数空间,那么是否能在不使用任何结构化多步搜索(如梯度下降)的情况下,仅通过简单的“猜测与检验(guess and check)”来提升模型能力?
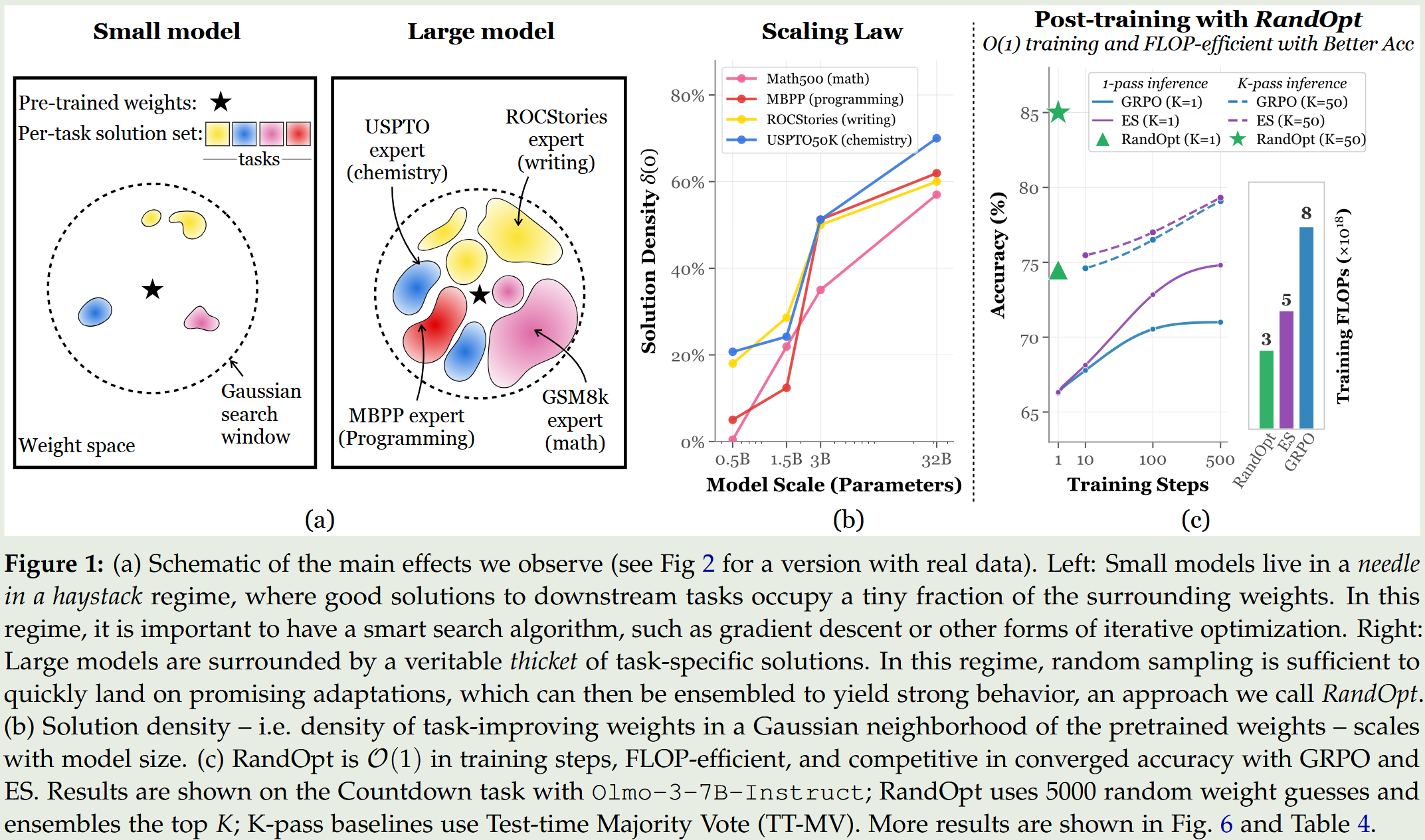
作者希望通过测量预训练权重周围高斯邻域内“任务提升解的密度(Solution Density)”和“解的多样性(Solution Diversity)”,来验证大型模型是否从小型模型的“大海捞针(needle in a haystack)”状态跨越到了一个充满专家的“灌木丛(thicket)”状态。如果存在这种高密度的 Thicket 区域,那么一种完全并行、无需梯度的后训练算法就有可能以 O ( 1 ) \mathcal{O}(1) O(1) 的时间复杂度媲美目前主流的顺序更新 RL 方法。
研究内容
本研究提出了一种名为 RandOpt(Random Guessing & Ensembling)的完全并行后训练算法框架。该方法摒弃了顺序优化步骤和梯度计算,转而在权重空间中直接采样多个微扰,并利用集成策略来融合多位“专家”的能力。

具体技术细节包括:
- 参数微扰生成(Perturbation Generation):令基础模型为 f θ : X → Y f_{\theta}:\mathcal{X}\rightarrow\mathcal{Y} fθ:X→Y,其权重为 θ ∈ R d \theta\in\mathbb{R}^{d} θ∈Rd。RandOpt 通过标准高斯分布 ϵ ∼ N ( 0 , I d ) \epsilon\sim\mathcal{N}(0,I_{d}) ϵ∼N(0,Id) 引入噪声向量,并通过噪声尺度 σ ∈ Σ = { σ 1 , … , σ M } \sigma\in\Sigma=\{\sigma_{1},…,\sigma_{M}\} σ∈Σ={σ1,…,σM} 控制微扰幅度。针对每一个随机种子 s s s,生成微扰后的模型实例: θ ′ = θ + σ ⋅ ϵ ( s ) \theta^{\prime}=\theta+\sigma\cdot\epsilon(s) θ′=θ+σ⋅ϵ(s)。
- 随机猜测与检验(Training: Random Guessing and Checking):在训练阶段,算法采样 N N N 个随机种子 { s 1 , … , s N } \{s_{1},…,s_{N}\} {s1,…,sN} 并分配相应的噪声尺度 { σ 1 , … , σ N } \{\sigma_{1},…,\sigma_{N}\} {σ1,…,σN}。由此产生 N N N 个参数向量 θ i = θ + σ i ϵ ( s i ) \theta_{i}=\theta+\sigma_{i}\epsilon(s_{i}) θi=θ+σiϵ(si)。这 N N N 个模型在小的训练集或验证集 D t r a i n \mathcal{D}_{train} Dtrain 上进行评估,获得性能得分 v i v_{i} vi。随后挑选出得分最高的 K K K 个模型构成顶级集合: I t o p = argtopK i ∈ [ N ] ( v i ) \mathcal{I}_{top}=\text{argtopK}_{i\in[N]}(v_{i}) Itop=argtopKi∈[N](vi)。
- 推理与预测集成(Inference: Ensembling of Predictions):在测试阶段,针对输入 x x x,仅使用所选的集合 I t o p \mathcal{I}_{top} Itop 生成预测。最终输出 y ^ \hat{y} y^ 通过多数投票(majority voting)进行聚合: y ^ = mode ( { arg max y f θ i ( y ∣ x ) ∣ i ∈ I t o p } ) \hat{y}=\text{mode}(\{\arg\max_{y}f_{\theta_{i}}(y|x)|i\in\mathcal{I}_{top}\}) y^=mode({argmaxyfθi(y∣x)∣i∈Itop})。
- 模型知识蒸馏(Distillation - 可选机制):为了缓解推理阶段 K K K 次前向传播带来的计算开销,作者提出通过有监督微调(SFT)将 Top-K 集成的能力蒸馏到单一模型中。该过程针对困难样本进行训练,优化目标为最小化推理轨迹(reasoning trace)和最终答案的负对数似然: L D i s t i l l ( θ ) = − ∑ t = T x + 1 T log p θ ( s t ∣ x , s < t ) \mathcal{L}_{Distill}(\theta)=-\sum_{t=T_{x}+1}^{T}\log~p_{\theta}(s_{t}|x,s_{<t}) LDistill(θ)=−∑t=Tx+1Tlog pθ(st∣x,s<t)。
研究价值
这项工作挑战了“预训练模型是一个固定起点”的传统观念,转而提出将其视为“涵盖多样化专家的参数分布”的全新范式。它证明了在具备足够好的预训练表示后,后训练可以极其简单且高效,不需要复杂的 RLHF 框架也能取得 SOTA 级别的性能。由于 RandOpt 工作节点完全并行且互不通信,仅在推理时聚合,它为受限带宽环境或重视挂钟时间(wall-clock time)的场景(如分布式联邦学习)提供了一种极具潜力的去中心化替代方案。
重要论点
- 小型模型处于“大海捞针(needle in a haystack regime)”的状态中,下游任务的良好解决方案仅占周围权重的极小部分,发现它们需要依赖梯度下降等迭代优化算法。
- 大型且经过充分预训练的模型被大量特定任务的解决方案所包围(thicket regime),其局部高斯邻域内的任务提升解密度(Solution Density)随模型规模增加而单调上升。
- 在大型模型周围采样到的良好微扰向量并非全能型模型(generalists),而是具有明显分化的专家(specialists),它们在提升某个任务性能的同时往往会损害其他任务的性能。
- 衡量解多样性的谱不一致性(Spectral Discordance D \mathcal{D} D)指标随着模型规模的增加而单调递增,表明大模型周围的解在能力上变得越来越不重叠。
- 在完全并行、无需梯度的设置下,采用随机猜测与集成的 RandOpt 算法在相同后训练 FLOPs 下,能够取得与 PPO、GRPO 和 ES 等标准且复杂的强化学习微调方法相媲美的竞争性准确率。
- RandOpt 算法在训练步骤上需要 O ( 1 ) \mathcal{O}(1) O(1) 的时间,显著优于需要 T T T 步顺序更新的传统基准方法 O ( T ) \mathcal{O}(T) O(T)。
- 集成机制(Ensembling)不仅对 RandOpt 至关重要( K = 50 K=50 K=50 显著优于 K = 1 K=1 K=1),它同样也能一致地提升传统后训练基准方法(如 PPO, GRPO, ES)的准确率。
- RandOpt 所带来的性能提升无法被单纯的“模型沙袋效应(Sandbagging,即模型故意隐瞒能力)”所解释,因为该算法在透明且无沙袋效应的 OLMo3-7B Base 模型上同样表现出了显著提升。
- RandOpt 找到的灌木丛(Thickets)并非仅由深层逻辑推理能力构成,有相当一部分性能收益来自于表面格式的修正(Format Thicket),同时也有确实修复了原模型错误推理的推理灌木丛(Reasoning Thicket),甚至在视觉生成模型中还存在颜色灌木丛(Color Thickets)”。
重要结果

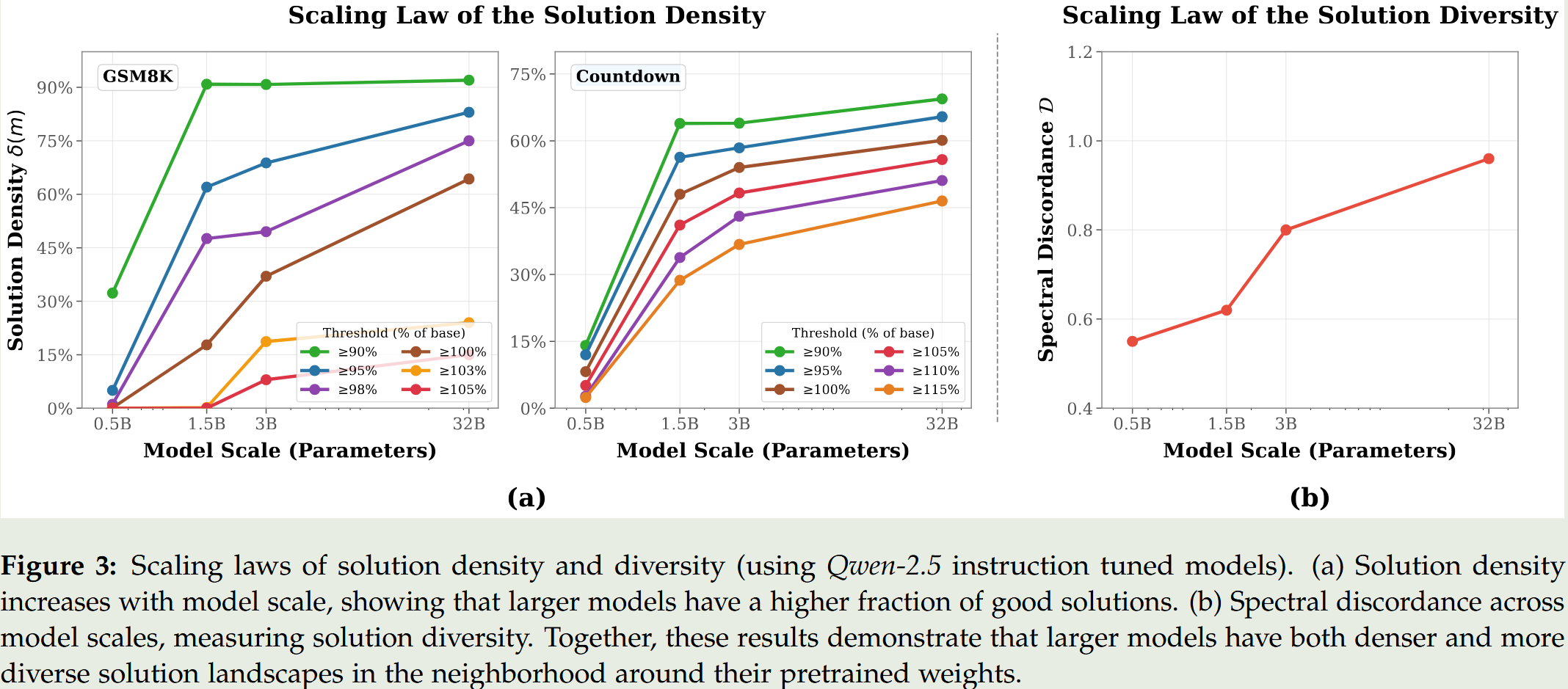
- 大模型的预训练彻底改变了损失空间的局部拓扑,从稀疏分布转变为特定任务专家的密集分布(Solution Density 随规模缩放)。实验表明,对 Qwen2.5 家族(0.5B 至 32B)进行 1000 次随机权重微扰后,小模型位于准确率景观的局部最高点,而大模型位于一个“山谷”中,周围有许多更高准确率的“山峰”。测量不同裕度 m m m 的解密度 δ ( m ) \delta(m) δ(m) 发现,能带来 5% 性能提升的微扰密度随着模型参数规模的扩大呈现单调递增趋势(文中图 2 和图 3)。

2. 在预训练权重周围的高质量微扰呈现出高度的专业化和能力互斥性(Solution Diversity 与专家倾向)。在涉及数学、代码、写作和化学等七个任务的评估中,作者计算了谱不一致性(Spectral Discordance D \mathcal{D} D)。结果显示 D \mathcal{D} D 值随模型规模变大而上升,且通过对 100 个随机种子的性能向量进行 PCA 降维,明显观察到具有相似行为的种子聚类成不同组(如图 4 所示),表明它们具备互补而非重叠的专业领域。

3. 完全并行的 RandOpt 算法在挂钟时间极具优势的前提下,推理性能足以匹敌 SOTA 的后训练方法。在相同计算量(FLOPs)下,RandOpt( K = 50 K=50 K=50)在 0.5B 到 8B 的多个模型和任务上匹配或超越了 PPO、GRPO 和 ES 的表现。特别是在一台部署了 200 张 GH200 的集群上,使用 N = 2000 N=2000 N=2000 训练 OLMo-3-7B 的 Countdown 任务仅需 3.2 分钟便达到了 70% 的准确率,展现出了免梯度算法在极端并行下的潜力。

4. 模型能力的提升是推理能力增强与输出格式修正共同作用的结果(多种类型 Thickets 混合)。在 GSM8K 测试集的 1319 个样本上对性能增益进行分解分析发现,RandOpt 提升至 86.7% 的准确率中,有 19.0% 来自于格式修复(即基础模型算对了但格式不合规),而有 12.3% 是基础模型算错但被新模型正确解答的真正推理提升,这证明“Thicket”概念包涵了从表面风格到深层技能的多个维度。

局限与扩展
- 局限性:
- 对强预训练的高度依赖:RandOpt 绝对不适用于从头开始训练庞大的神经网络架构(如 GPT-2 0.1B 表现极差),它在小型预训练模型上也十分挣扎。它只在已经具备极高表征能力的模型上生效。
- 获取全新技能的瓶颈:随着搜索预算 N N N 的扩大,性能扩展曲线呈现饱和趋势。这表明仅靠局部“灌木丛”采样可能无法赋予模型远超其基础水平的全新技能,寻找突破仍可能需要回到结构化搜索方法。
- 推理时的计算成本高昂:由于必须前向传播 K K K 次(通常 K > 1 K>1 K>1 才能取得好成绩),其推理代价极大。虽然通过知识蒸馏能缓解此问题,但这会带来额外训练开销且打破完全并行性。
- 对复杂结构化预测任务的不适配:基于多数投票(Majority-Vote)的集成在解决离散类别或整数预测(如数学选择题)时很直接,但很难直接平移到长篇故事生成或分子设计等结构化预测任务中。
- 现象成因尚未完全清晰:目前研究测量了预训练景观的特征,但并未完全从机理上解释预训练目标或学习动态是如何具体形成这些“Thickets”的。
- 未来扩展:作者希望未来的研究能够深入探究预训练进入“Thicket Regime”的具体时机和机理条件,以及针对图像或结构化生成任务开发更优的集成机制。
相关工作
本文在探讨参数损失景观和随机搜索时,与以下几项前沿工作有着深刻的传承和对比关系:
- 平缓极小值与局部崎岖景观 (Flat Minima vs. Spiky Local Landscapes)
- 相关论文:On large-batch training for deep learning: Generalization gap and sharp minima, ICLR 2017
- 联系与差异:深度学习界的传统共识认为,神经网络在训练中倾向于收敛在平滑、宽广的极小值区域(Flat Minima),这通常代表着良好的泛化能力。本文指出,这种表面的“平缓”实际上是一种多任务聚合后的宏观错觉。如果把视角拉近,单独审视某一个特定下游任务的局部损失景观,它其实是高度崎岖(Spiky)的。预训练权重往往正处于一个精度“山谷”之中,被周围众多代表特定任务专家的“崎岖山峰”(更高的精度峰值)所包围。
- 演化策略与随机搜索(Evolution Strategies at Scale)
- 相关论文:
- Evolution strategies as a scalable alternative to reinforcement learning
- Evolution strategies at scale: Llm fine-tuning beyond reinforcement learning
- 联系与差异:这些工作证明了顺序随机搜索方法(如 ES)可以作为强化学习的有力替代品进行 LLM 微调。本文与它们的本质区别在于,RandOpt 实现的是在参数空间的完全并行(parallel)“Best-of-N”猜测,而彻底去除了顺序迭代的包袱。
- 相关论文:

- 权重空间微调内在大维数(Intrinsic Dimension & LoRA)
- 相关论文:
- Intrinsic dimensionality explains the effectiveness of language model fine-tuning
- LoRA: Low-rank adaptation of large language models
- 联系与差异:这些研究提出参数的高效微调之所以可行,是因为大模型的适应过程本质上是低维的。本文与之不谋而合,且将“Thickets”现象解释为一个由于过度参数化引起的宽广盆地与一个低秩但存在于完整参数空间中的任务相关方向集合的交集。
- 相关论文:
- 虚假奖励奏效的底层解释 (Spurious Rewards)
- 相关论文:Spurious rewards: Rethinking training signals in rlvr (Shao et al., 2025) [cite: 573, 735]
- 联系与差异:近期 RL 领域发现了一个反常现象:在后训练中,即使给予模型随机的、错误的或虚假的奖励信号(Spurious Rewards),有时也能出人意料地提升模型表现。本文从“解密度(Solution Density)”的全新视角为这一现象提供了解释。对于某些特定任务,大型预训练模型周围的专家解密度极其高,以至于绝大多数的高斯微扰无论如何都能提高任务准确率。在如此高密度的“灌木丛”中,即便虚假奖励提供了一个方向错误的梯度,但在“闭着眼睛走都能撞上好解”的区域,这个错误方向碰巧也能带来足够的性能增益。
重要概念清单
- 模型沙袋效应 (Sandbagging)
- 相关论文:Noise injection reveals hidden capabilities of sandbagging language models
- 相关背景:沙袋效应指大模型可能因为安全对齐或指令微调的副作用,故意隐藏或未充分发挥其实际能力。如果模型存在这种效应,随机微扰可能只是打破了封印限制,而非真正发掘了更好的表征潜力。
- 本文作者通过实验强有力地反驳了这一假设。他们在完全开源、透明且未经过意图隐藏或复杂安全对齐的 OLMo3-7B Base 模型上应用 RandOpt,依然取得了显著的性能提升。此外,RandOpt 的表现一致优于单纯旨在提取已有答案的测试时多数投票(TT-MV)机制,证明随机微扰是真的在参数空间中找到了更优的任务专家。
- 神经灌木丛的多样性 (Neural Thickets & Mixed Types)
- 相关论文:本文
- 相关背景:预训练大模型的参数周围密集分布着能提升任务性能的“专家网络”,这些高密度解的聚集区被称为“灌木丛(Thickets)” 。
- 研究拆解发现,“专家”能力的提升是多维度因素的混合体。在文本推理任务(如 GSM8K)中,既有真正修复基础模型错误推理的“推理灌木丛(Reasoning Thicket)”,也有占据相当比例、仅修正表面输出格式的“格式灌木丛(Format Thicket)”。在视觉生成模型(如 SDXL)中,甚至存在固执偏好特定色调或风格的“颜色灌木丛(Color Thickets)” 。
- 彩票假设 (Lottery Ticket Hypothesis)
- 相关论文:The lottery ticket hypothesis: Finding sparse, trainable neural networks, ICLR 2019
- 相关背景:彩票假设提出,在随机初始化的网络中,从头开始寻找好的初始化权重(中奖彩票)就像中彩票一样罕见和困难。
- 本文为彩票假设补充了关键的时间维度视角:在经过庞大计算量的预训练之后(即迁移阶段),参数空间的拓扑性质发生了质变。预训练将权重拉入了一个充满高质量解决方案的密集盆地,此时在初始权重(预训练权重)周围,原本极其罕见的“中奖彩票”变得无比密集丰富,随机微扰即可轻易命中。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)