RAG系统深度解析
RAG系统深度解析
RAG 的具体流程 | 为什么你的RAG效果不好 | 怎么评估一个RAG系统的好坏
1. RAG是什么
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索和大语言模型的架构。它的核心思想是:在模型生成答案之前,先从外部知识库中检索相关文档,将这些文档作为上下文提供给模型,最后生成基于事实的答案。
简单来说,RAG = 检索器(Retriever)+ 生成器(Generator)的协同工作。它不是让模型"凭空想象",而是让模型"带着资料回答"。
2. RAG有什么用
RAG的出现解决了大语言模型的几个核心痛点:
| 痛点 | RAG的解决方案 |
|---|---|
| 知识截止日期 | 模型只知道训练数据截止前的知识,RAG可以接入最新数据 |
| 幻觉问题 | 模型可能编造事实,RAG提供真实资料作为依据 |
| 私有数据接入 | 模型没训练过你的企业数据,RAG可以检索内部文档 |
| 长文本处理成本 | 把所有文档塞进prompt成本太高,RAG只检索相关片段 |
| 知识更新成本 | 重新训练模型成本极高,RAG只需要更新知识库 |
适用场景:智能客服、企业知识库问答、法律文书辅助、医疗诊断支持、教育辅导等。
3. RAG的具体流程
一个完整的RAG流程包含5个核心模块,下图展示了完整的工作流:
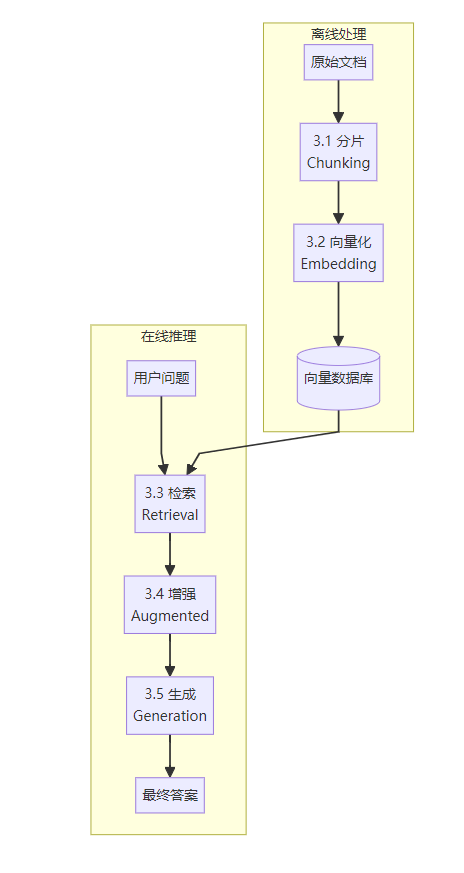
3.1 分片(Chunking)
目的:将长文档切成适合检索的小块,避免上下文超限,同时保证每个块包含完整的语义信息。
常见方式:
| 分片策略 | 方法 | 优点 | 缺点 |
|---|---|---|---|
| 固定长度切分 | 按300字/500token硬切 | 实现简单,长度可控 | 可能切断句子,语义不完整 |
| 自然结构切分 | 按段落、小标题、句号切 | 语义完整性强 | 长度不均,可能超长 |
| 滑动窗口 | 带重叠的切分 | 避免在关键处切断 | 数据冗余,存储成本高 |
| 递归切分 | 先切段落,再切句子 | 层次化语义保留 | 实现复杂 |
3.2 向量化(Embedding)
过程:通过embedding模型将每个chunk转换为向量。以BERT base Chinese为例:
-
词表大小:21128
-
输出维度:768
-
处理流程:chunk经词向量查找 → Transformer自注意机制 → 池化(取[CLS]向量或平均) → 得到一维向量
这个向量的神奇之处在于:语义相近的文本,在向量空间中的距离也相近。
3.3 检索
3.3.1 相似度计算
常见计算方式:
| 方法 | 公式 | 特点 |
|---|---|---|
| 点积 | ( \text{similarity} = q \cdot v = \sum_{i=1}^{n} q_i v_i ) | 值越大越相似,受向量长度影响 |
| 欧式距离 | ( \text{distance} = \sqrt{\sum_{i=1}^{n} (q_i - v_i)^2} ) | 值越小越相似,对尺度敏感 |
| 余弦相似度 | ( \cos\theta = \frac{q \cdot v}{|q| \cdot |v|} ) | 值越接近1越相似,不受向量长度影响,最常用 |
3.3.2 高效检索
当知识库达到百万甚至亿级规模时,暴力计算所有向量相似度不可行,需要ANN(Approximate Nearest Neighbor,近似最近邻搜索):
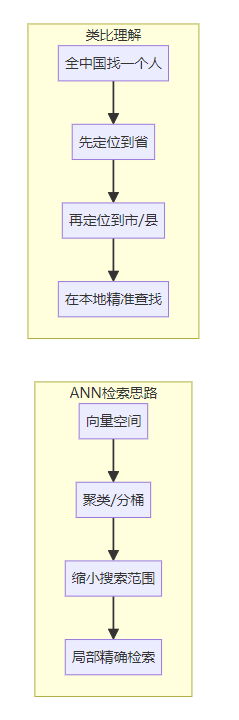
常见ANN算法:
-
HNSW:基于图的导航式搜索
-
IVF:倒排索引+聚类
-
PQ:乘积量化压缩向量
3.3.3 Rerank重排
ANN检索后可能返回几十个候选,需要用更精确的模型重新排序:
-
特点:精度高但速度慢
-
作用:将最相关的3-5个排在前面
-
常用模型:Cross-encoder类(如bge-reranker-base)
3.3.4 向量数据库
专门为向量检索优化的数据库,核心功能:
-
存储向量+原始文本
-
建立ANN索引
-
支持top-k检索
-
支持元数据过滤
-
解决普通数据库不擅长高维近邻搜索的问题
常见选择:Milvus、Qdrant、Weaviate、Chroma、Pinecone
3.4 增强(Augmented)模块
将检索到的top-k相关chunk与用户问题拼接成新的prompt:
请基于以下资料回答问题: [资料1]:xxxxxx [资料2]:xxxxxx [资料3]:xxxxxx 用户问题:xxxxxx 回答:
这一步的关键是prompt工程:如何告诉模型"优先使用资料,不要自己编造"。
3.5 生成(Generation)模块
增强后的prompt输入大模型,模型基于上下文生成答案。与普通生成过程一致,但因为有了相关资料的支撑,幻觉大大减少。
4. 联合概率解释为什么RAG会失效
用数学语言理解RAG的局限性:
普通大模型生成概率: P(y|x)(x为用户问题,y为输出)
RAG生成概率: P(y|x) = \sum_{z \in Z} P(z|x) \cdot P(y|x,z)
其中:
-
(P(z|x)) 为检索到证据z的概率
-
(P(y|x,z)) 为基于问题x和证据z生成答案y的概率
关键洞察:RAG是一条完整的链路,整个过程的联合概率是各环节概率的乘积:
P_{RAG} = P_{chunk} \cdot P_{embed} \cdot P_{retrieve} \cdot P_{rerank} \cdot P_{generate}
只要中间任何一步出错,最终结果就可能失败。这解释了为什么RAG系统调优如此复杂。
5. RAG常见失败点及解决方案
问题1:分片问题
表现:
-
chunk过大:一个块包含多个主题,检索时引入噪声
-
chunk过小:完整语义被切断,单个块信息不足
-
关键信息正好在切分边界上
解决方案:多层级分片策略
层级结构: ├── 文档级 (Document):整个文档,适合"总结全文"类问题 ├── 章节级 (Section):按标题/章节划分,适合概念理解 ├── 段落级 (Paragraph):默认检索层级,平衡长度和语义 └── 句子级 (Sentence):细粒度检索,适合精确事实查询
参数配置建议:
# 英文配置(token为单位) chunk_sizes_en = [2048, 1024, 512, 128] # 中文配置(中文字符为单位) chunk_sizes_zh = [3000, 1500, 600, 150] # 中文信息密度更高
注意:这里的大小是近似值,实际切分时会保持语义边界完整,不会硬切。
问题2:向量表示问题
表现:语义相近的文本在向量空间中距离很远,导致相似度计算不准。
原因:
-
embedding模型选型不当
-
领域术语不在模型预训练范围内
-
未针对业务数据进行微调
解决方案:
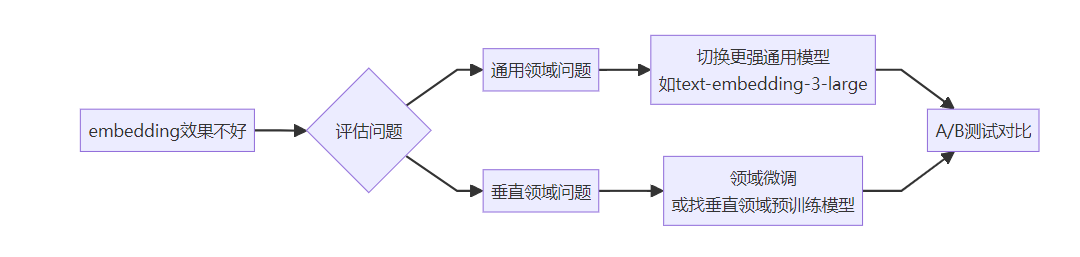
A/B测试对比
常用embedding模型对比:
| 模型 | 维度 | 特点 | 适用场景 |
|---|---|---|---|
| BGE系列 | 768/1024 | 中文效果好 | 中文通用 |
| text-embedding-3 | 1536 | OpenAI出品 | 多语言 |
| m3e | 768 | 开源中英双语 | 通用 |
| bce-embedding | 768 | 中文商用 | 高精度需求 |
问题3:召回问题 - 未召回关键文本片段
这是RAG系统最常见也最难调试的问题。我们把它细分为两类:
3.1 查询问题
表现:用户查询表述模糊,或者查询意图需要不同粒度的信息。
解决方案:智能查询路由
def query_router(query): """根据查询特征选择检索层级""" # 规则1:精确关键词触发句子级检索 if any(keyword in query for keyword in ['table', 'figure', '第X章', '定义']): return 'sentence' # 规则2:长查询(>15词)可能是复杂概念问题,用章节级 if len(query.split()) > 15: return 'section' # 规则3:查询很短(1-2词)可能是主题检索,用文档级 if len(query.split()) <= 2: return 'document' # 默认:段落级 return 'paragraph'
层级存储在metadata中:
{
"text": "xxxxxx",
"metadata": {
"layer": "paragraph", // document/section/paragraph/sentence
"doc_id": "doc_001",
"title": "xxx"
}
}
检索时过滤:
# 只在指定层级搜索
results = vector_store.search(
query_vector,
filter={"layer": {"$eq": "paragraph"}}
)
实际使用技巧:
-
80%的场景用paragraph层就够了
-
可以在paragraph层检索,如果置信度低(如top1得分<阈值),自动下钻到sentence层二次检索
-
document层主要用于"总结全文"类问题
3.2 语义问题
表现:用户查询中的关键词在知识库中存在,但因为语义匹配问题没被召回。
案例:
用户问题:美国总统住在哪里? 知识库中有:"白宫是美国总统的官邸和主要办公场所"
-
embedding可能因为"住"和"官邸"的语义差异没匹配上
-
但如果有关键词匹配(关键词:美国+总统+住 → 匹配白宫),就能召回
解决方案:混合检索架构
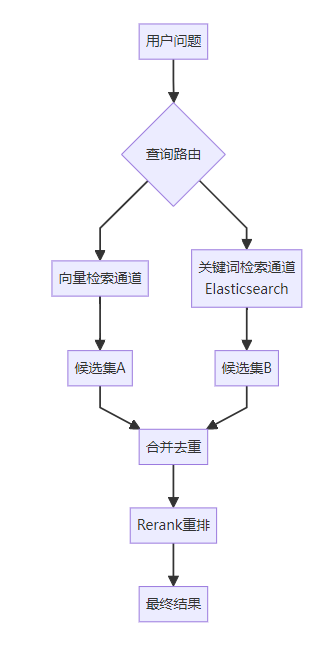
Elasticsearch配置示例:
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word", // 中文分词
"search_analyzer": "ik_smart"
}
}
}
}
查询改写:解决多轮对话中的指代问题
用户:John是谁? 助手:John是公司的技术总监... 用户:他喜欢看什么书? 问题:第二个问题只有"他",无法关键词匹配 解决方案:多轮对话查询改写 输入:["John是谁?", "他喜欢看什么书?"] 输出:"John喜欢看什么书?"
问题4:重排问题
表现:rerank模型将本应排在前面的证据排到了后面。
原因:
-
rerank模型本身精度不足
-
跨语言问题(查询中文,文档英文)
-
查询和文档长度差异过大
解决方案:
-
rerank模型选型:
-
bge-reranker-base(中文)
-
cross-encoder/ms-marco-MiniLM(英文)
-
多语言:xlm-roberta-based
-
-
两阶段rerank:
# 第一阶段:轻量级rerank,筛出top50 candidates = light_rerank(initial_results[:200]) # 第二阶段:重量级rerank,精排top20 final_results = heavy_rerank(candidates[:50])
-
融合分数:
final_score = 0.3 * vector_score + 0.3 * keyword_score + 0.4 * rerank_score
问题5:生成问题
表现:即使检索到了正确资料,模型还是回答错误。
原因:
-
prompt设计不合理
-
模型被资料中的噪声干扰
-
模型不擅长多文档推理
-
指令微调不足
解决方案:
-
Prompt工程:
prompt_template = """ 请严格基于以下资料回答问题。如果资料中没有相关信息,请直接说"资料中未提及"。 资料: {context} 问题:{question} 回答要求: 1. 只使用资料中的信息 2. 如果资料矛盾,请指出并说明不同来源的差异 3. 简明扼要,不要添加额外信息 回答: """ -
上下文压缩:去除检索结果中的冗余信息
# 只保留与问题最相关的2-3句 compressed_context = extract_relevant_sentences(context, question)
-
多文档推理优化:
-
让模型先逐条分析每个文档
-
再综合给出答案
-
标注每个信息点的来源
-
6. 如何评估RAG系统的好坏
6.1 核心指标详解
检索质量指标
| 指标 | 公式 | 含义 | 理想值 |
|---|---|---|---|
| Hit Rate@k | 有相关文档在topk中的查询比例 | 召回能力 | >0.8 |
| MRR | (\frac{1}{Q}\sum_{i=1}^{Q}\frac{1}{rank_i}) | 第一个正确答案的位置 | >0.7 |
| NDCG@k | 考虑排序位置的加权指标 | 排序质量 | >0.75 |
生成质量指标
| 指标 | 评估方法 | 含义 |
|---|---|---|
| 忠实度 | 答案中的每个陈述都能在资料中找到依据 | 防止幻觉 |
| 相关度 | 答案直接回答了问题,没有偏题 | 用户体验 |
| 完整性 | 答案覆盖了问题的所有方面 | 信息全面 |
自动化评估方法
# 使用LLM评估答案质量
eval_prompt = """
请评估AI助手的回答质量:
问题:{question}
标准答案:{ground_truth}
AI回答:{ai_answer}
检索到的资料:{context}
请从以下维度评分(1-5分):
1. 忠实度:回答是否严格基于资料
2. 准确性:与标准答案的匹配程度
3. 完整性:是否遗漏重要信息
输出格式:
{{
"faithfulness": x,
"accuracy": x,
"completeness": x,
"explanation": "简要说明"
}}
"""
6.2 离线测试集构建
好的评估需要高质量测试集:
# 测试集格式示例
test_cases = [
{
"question": "美国总统住在哪里?",
"ground_truth": "白宫",
"relevant_docs": ["doc_001_chunk_3", "doc_002_chunk_5"],
"difficulty": "easy", # easy/medium/hard
"category": "factual" # factual/reasoning/summary
}
]
构建方法:
-
人工标注:成本高但质量最好
-
LLM生成+人工校验:效率高
-
用户日志回放:真实场景
7. 未来展望
RAG技术正在快速演进,值得关注的方向:
| 方向 | 核心思想 | 优势 |
|---|---|---|
| Self-RAG | 模型自己决定何时检索、检索什么 | 更智能,减少无用检索(模型更清楚自己需要什么信息) |
| Corrective RAG | 验证检索结果,必要时重检索 | 提高可靠性 |
| Graph RAG | 利用知识图谱结构增强检索 | 更好处理多跳问题 |
| Agentic RAG | 多轮检索、推理、工具调用 | 解决复杂任务 |
结语:RAG不是银弹,但它是当前落地大模型最实用的架构。理解每个环节的原理和可能的失败点,建立完善的评估体系,持续迭代优化,才能构建出真正好用的RAG系统。记住:没有最好的RAG,只有最适合你业务的RAG。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)