OpenAI推出GPT-5.4 mini/nano;MiniMax发布M2.7;小米发布MiMo-V2系列模型
OpenAI、MiniMax、小米前后陆续发布新模型,从轻量高效的编程助手到具备自我演化能力的智能体,再到全模态理解与情感语音合成,三条技术路线在这一周交汇。
OpenAI推出GPT-5.4 mini与nano两款小型模型,MiniMax发布具备自我演化能力的M2.7,小米则一口气发布MiMo-V2系列三款模型,覆盖智能体核心、全模态理解和情感语音合成。
OpenAI的轻量化战略
OpenAI正式发布GPT-5.4 mini与GPT-5.4 nano两款小型模型。

两款模型延续了GPT-5.4的核心能力,却在速度和成本上做出了针对性优化,专为高吞吐量工作负载设计。
GPT-5.4 mini在代码编写、推理、多模态理解以及工具使用方面较前代GPT-5 mini有显著提升,运行速度提高两倍以上。
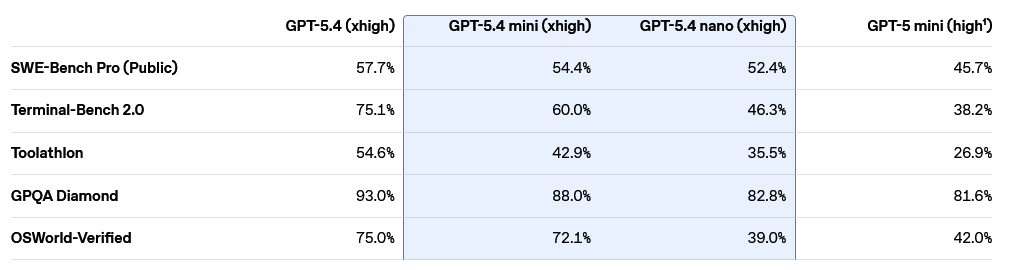
SWE-Bench Pro基准测试中,GPT-5.4 mini取得54.4%的成绩,接近体积更大的GPT-5.4模型的57.7%。Terminal-Bench 2.0测试中,GPT-5.4 mini得分60.0%,远超前代GPT-5 mini的38.2%。这种性能提升并非以牺牲速度为代价,相反,模型在延迟敏感场景中表现更加出色。
GPT-5.4 nano定位更加极致,成为GPT-5.4家族中最轻量、最经济的版本。
它专为分类、数据提取、排序以及简单辅助任务的编程子智能体设计。SWE-Bench Pro测试中,nano取得52.4%的成绩,与mini的差距仅2个百分点,成本却进一步降低。
API定价方面,mini每100万输入Token收费0.75美元,nano仅需0.20美元。
两款模型的目标场景非常明确:即时响应的代码助手、快速完成辅助任务的子智能体、解析截图的计算机使用系统、实时推理图像的多模态应用。
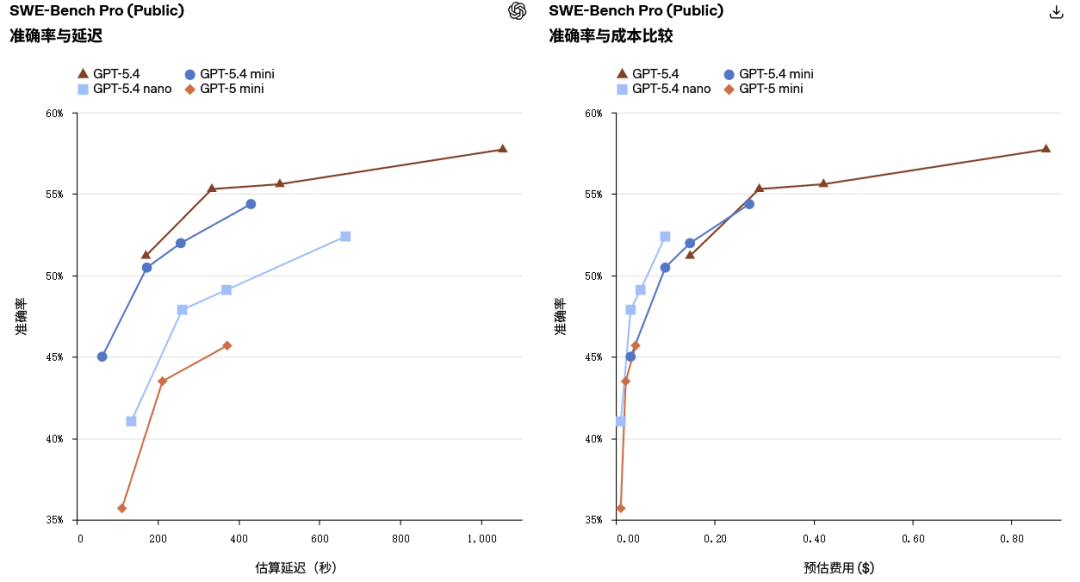
这些场景有一个共同特点,响应速度直接关系到产品体验,最好的模型往往不是体积最大的那个,而是能够快速响应、可靠调用工具、在复杂专业任务中保持出色表现的模型。
子智能体架构是这两款小型模型的典型应用模式。
以Codex为例,体量较大的GPT-5.4负责处理规划、协作和最终判定,同时将具体子任务并行分配给GPT-5.4 mini子智能体,比如搜索代码库、审阅大文件或处理辅助文档。这种组合系统让开发者无需用单一模型处理所有事务,大模型决定任务方向,小模型进行大规模快速执行。
计算机使用能力是另一大亮点。
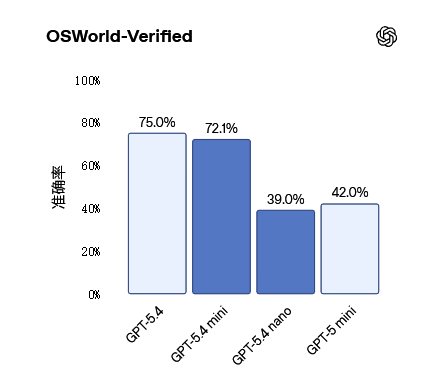
OSWorld-Verified基准测试中,GPT-5.4 mini得分72.1%,接近GPT-5.4的75.0%,大幅超越GPT-5 mini的42.0%。多模态任务不再是大型模型的专属,小型模型同样可以在视觉理解领域有所作为。
GPT-5.4 mini已全面上线API、Codex及ChatGPT。API版本支持文本与图像输入、工具使用、函数调用、网页搜索、文件搜索、计算机使用以及技能功能,具备400K上下文窗口。
在Codex中,mini仅消耗GPT-5.4配额的30%,开发者能以约三分之一的成本快速处理简单代码任务。GPT-5.4 nano仅在API中提供,定位更加纯粹,服务于对成本和速度要求极高的轻量任务。
MiniMax的自我演化探索
MiniMax发布M2.7模型,标题简洁有力:自我演化的早期回响。

M2.7的核心卖点在于它能够深度参与自身的演化过程。
模型可以构建复杂的智能体工具包,完成高度精细的生产力任务,利用Agent Teams、复杂技能以及动态工具搜索等能力。
开发过程中,MiniMax让模型更新自己的记忆,在工具包中构建数十个复杂技能来辅助强化学习实验,让模型根据实验结果改进学习过程和工具包,由此开启模型自我演化的循环。
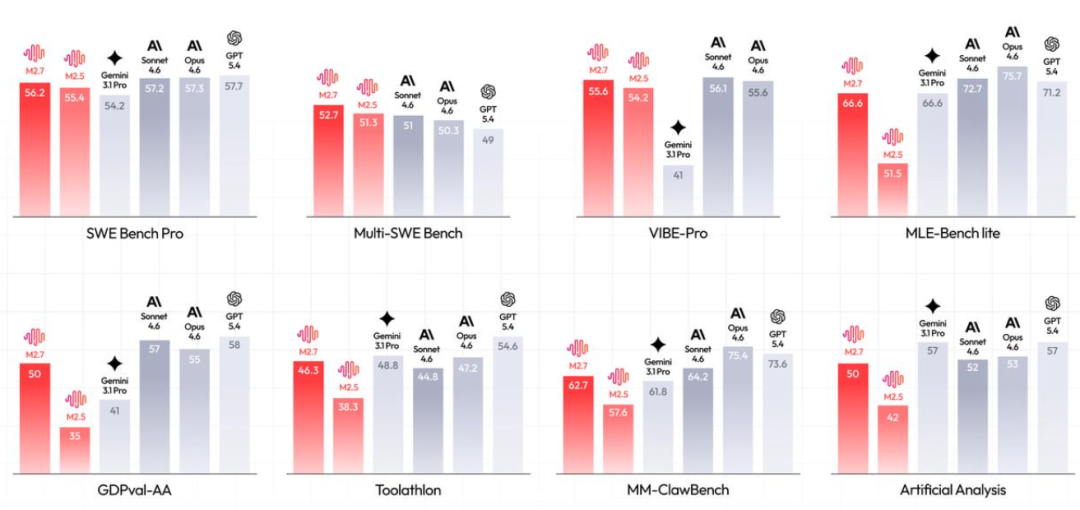
软件工程能力是M2.7的强项。SWE-Pro基准测试中,M2.7得分56.22%,接近Opus的最佳水平。
能力延伸到端到端全项目交付场景,VIBE-Pro得分55.6%。
Terminal Bench 2测试中,模型展现出对复杂工程系统的深度理解,得分57.0%。
GDPval-AA的ELO分数达到1495,在开源模型中排名第一。
M2.7在Excel、PPT、Word等Office套件中的复杂编辑能力显著提升,能够更好地处理多轮修订和高保真编辑。
技能执行方面,M2.7在与超过40个复杂技能协作时保持97%的技能遵守率,每个技能超过2000个Token。
模型展现出优秀的角色一致性和情商表现,为产品创新打开了更多空间。MiniMax内部正在利用这些能力加速向AI原生组织演化。
现代智能体工具包结合复杂技能、记忆和其他外部模块,提高在不同工作环境中的适应性。MiniMax的智能体日常面对跨越多个部门的复杂异构环境。
为此,团队让M2.7的内部版本构建研究智能体工具包,与不同研究项目组交互协作。工具包支持数据管道、训练环境、基础设施、跨团队协作和持久记忆,研究人员可以驱动它交付更好的模型。
研究智能体工具包驱动迭代周期,在研究人员设定的指导下生产下一代模型。
典型的日常工作流发生在强化学习团队:研究员与智能体讨论实验想法,智能体帮助进行文献综述,跟踪预设实验规格,管道化数据和其他工件,启动实验。
这些工作以前需要来自不同团队的多个研究员协作,现在人类研究员只需参与关键决策和讨论。M2.7能够处理30%到50%的工作流程。
模型递归演化自身工具包的能力同样关键。内部工具包自主收集反馈,为内部任务构建评估集,基于此持续迭代自身的架构、技能实现和记忆机制,以更好更高效地完成任务。
团队让M2.7优化模型在内部支架上的编程性能。M2.7完全自主运行,执行分析失败轨迹、规划变更、修改支架代码、运行评估、比较结果、决定保留或回滚变更的迭代循环,持续超过100轮。
过程中,M2.7发现了有效的优化方案:系统搜索温度、频率惩罚和存在惩罚等采样参数的最优组合;为模型设计更具体的工作流指南,比如修复后自动在其他文件中搜索相同错误模式;在支架的智能体循环中添加循环检测等优化。最终在内部评估集上实现了30%的性能提升。

MiniMax认为,未来AI自我演化将逐步向完全自主过渡,协调数据构建、模型训练、推理架构、评估等阶段,无需人类参与。
为此,团队在低资源场景进行了初步探索性测试。让M2.7参与OpenAI开源的MLE Bench Lite级别的22个机器学习竞赛。这些竞赛可以在单张A30 GPU上运行,却覆盖机器学习工作流的几乎所有阶段。
团队设计并实现了一个简单的支架来引导智能体自主优化,核心模块包括短期记忆、自我反馈和自我优化三个组件。
每轮迭代后,智能体生成短期记忆Markdown文件,同时对当前轮结果进行自我批评,为下一轮提供潜在优化方向。
下一轮则基于所有之前轮次的记忆和自我反馈链进行进一步自我优化。总共运行三次试验,每次24小时迭代演化。最终,最好的一次运行获得9枚金牌、5枚银牌、1枚铜牌。
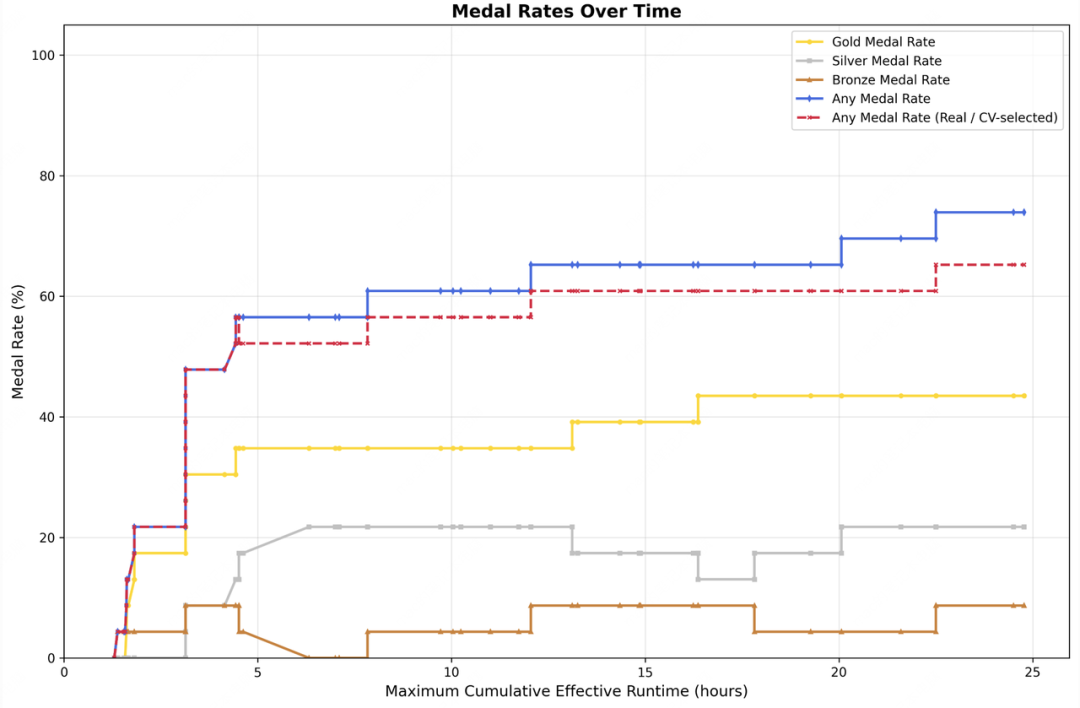
三次运行的平均获奖率为66.6%,仅次于Opus-4.6的75.7%和GPT-5.4的71.2%,与Gemini-3.1并列。
小米的智能体全家桶
小米发布MiMo-V2系列三款模型:MiMo-V2-Pro、MiMo-V2-Omni和MiMo-V2-TTS,分别定位于智能体核心、全模态理解和情感语音合成。

MiMo-V2-Pro是旗舰基础模型,专为真实世界智能体工作负载构建。
模型定位非常明确,作为智能体系统的大脑,编排复杂工作流,驱动生产工程任务,可靠地交付结果。
总参数超过1T,活跃参数42B,约为MiMo-V2-Flash的3倍。
模型继承前代的混合注意力机制,混合比例从5:1提升至7:1,在显著扩大规模的同时保持高推理效率。支持最高1M Token上下文,轻量级多Token预测层实现快速生成。
Artificial Analysis Intelligence Index是全球模型综合智能评估的权威基准,MiMo-V2-Pro排名全球第8,中国大模型第2。
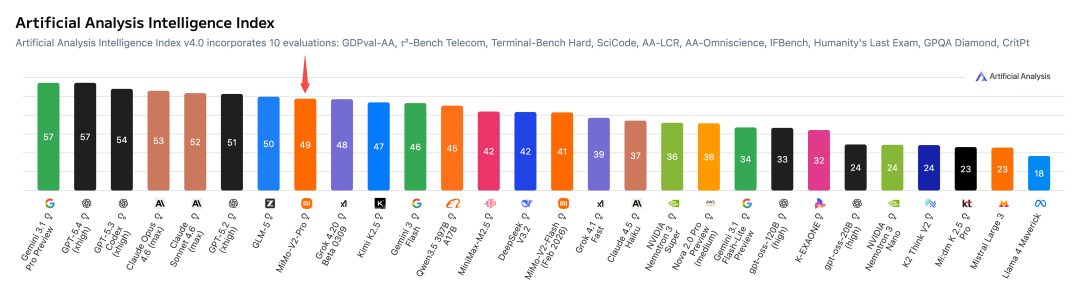
ClawEval基准测试中,MiMo-V2-Pro得分61.5%,全球第3,接近Opus 4.6的66.3%。
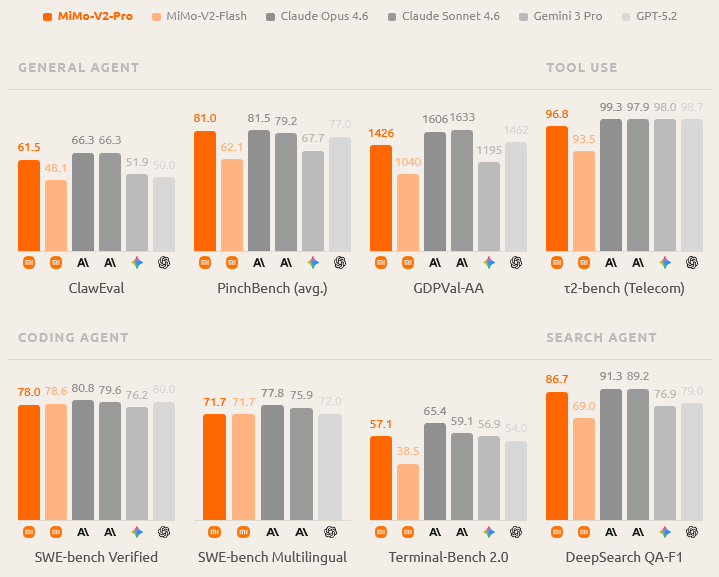
PinchBench平均分81.0%,同样全球第3。

工具调用方面,τ2-bench电信测试得分96.8%,与Claude Opus 4.6的99.3%和Gemini 3 Pro的98.0%处于同一梯队。
一个有趣的插曲是,发布前一周,代号为Hunter Alpha的匿名模型在OpenRouter上架。
OpenRouter是全球最大的API聚合平台。上架期间,调用量稳步增长,多次登顶日榜,总使用量超过1T Token。
Hunter Alpha正是MiMo-V2-Pro的早期内部测试版本。经过一周持续迭代优化,MiMo-V2-Pro在长上下文能力和智能体场景稳定性上有了显著提升。
MiMo-V2-Omni则走的是全模态路线。
模型将专用图像、视频和音频编码器融合到单一共享骨干中,不是作为独立能力的简单叠加,而是作为统一的感知流。
模型同时看、听、读,就像真实世界中操作的智能体必须做到的那样。感知之外,智能体必须将感知与下一步行动连接。小米的做法很直接,训练模型预测未来,而不仅是描述现在。场景中有什么、接下来会发生什么、现在应该做什么,模型从训练的第一步就学习这三件事。感知和行动从未分离,它们作为一个连续的推理过程共同涌现。
输出端,MiMo-V2-Omni原生支持结构化工具调用、函数执行和UI定位,无需额外适配层即可接入真实的智能体框架和编排系统。
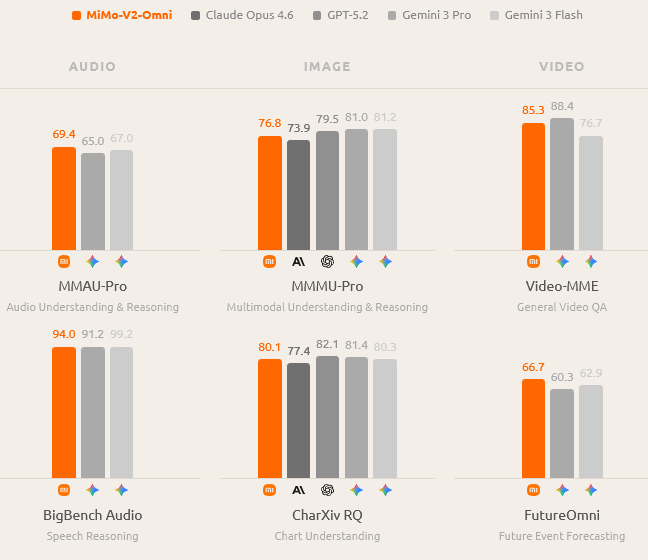
音频理解方面,MMAU-Pro测试得分69.4%,BigBench Audio得分94.0%,超越Gemini 3 Pro。
能力远远超越转录,延伸到环境声音分类、多说话人分离、音视频联合推理,以及超过10小时连续音频的深度理解。
图像理解方面,MMMU-Pro得分76.8%,CharXiv RQ得分80.1%,超越Claude Opus 4.6,接近Gemini 3等顶级闭源模型水平。
视频理解方面,Video-MME得分85.3%,支持原生音视频联合输入,实现真正的多模态视频理解。通过创新的视频预训练,模型发展出强大的情境感知和未来推理能力,不只是感知正在发生什么,还能预测接下来会发生什么。
MiMo-V2-TTS是小米自研的大规模语音合成模型。
基于专有音频分词器和多码本联合语音文本建模架构,在超过1亿小时语音数据上预训练,并通过多维强化学习进一步优化。
模型提供高度可控的多粒度风格控制,从设定话语整体基调到微调局部情感细微差别,包括句中情绪转变和短语内的渐进情感过渡。自然韵律再现、唱歌能力一应俱全。
传统TTS系统给你一个情绪下拉菜单,快乐、悲伤、愤怒、中性,选一个。MiMo-V2-TTS给你一个文本框。用自然语言描述你想要的声音,任何语言、任何详细程度,模型生成匹配描述的语音。
没有预定义标签,没有固定词汇表。想要睡意朦胧、刚醒来、略带沙哑?想要可爱婴儿音、有点撒娇?想要深情款款、慢慢说、几乎是耳语?想要慷慨激昂、像对人群演讲?用自然语言描述即可。
模型解析风格描述的语义内容,在生成过程中映射到相应的声学特征。组合描述自然有效,愤怒但努力保持冷静,产生的输出与单纯的愤怒或冷静都有可测量的差异。
模型还支持方言和角色声音。真人语音不是干净的词汇序列,充满咳嗽、叹息、犹豫、急促呼吸、紧张笑声等副语言事件,这些事件承载的意义与词汇本身一样多。MiMo-V2-TTS将这些事件作为语音输出的自然集成组件生成,而非事后拼接的音频片段。模型理解这些事件在上下文中的位置以及它们在周围文本下应该听起来如何。
当人类朗读你太离谱了!这句话时,不会以相同方式发音每个字。大写字母、连字符、感叹号都是如何说话的指令。
OpenAI向下渗透,让大型模型的能力在小型模型中延续,以更低成本更高效率服务高吞吐场景。
MiniMax向内深化,让模型参与自身演化,开启智能体自我迭代的循环。
小米横向扩展,Pro定位智能体核心,Omni打通全模态理解,TTS注入情感表达,三条产品线形成智能体能力的完整闭环。
参考资料:
https://openai.com/zh-Hans-CN/index/introducing-gpt-5-4-mini-and-nano/
https://www.minimax.io/news/minimax-m27-en
https://mimo.xiaomi.com/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)