零代码基础人类如何与agent智能体高效协作大型开发项目——以workbuddy为例
一、背景
1.1 项目概述
本项目是一个包含微信小程序和 H5 两个版本的全栈开发项目,涉及多端开发、AI 集成、法务合规等多个技术域。
1.2 项目规模与复杂度
本项目是一个中大型全栈开发项目,涉及多端开发、AI 集成、法务合规等多个技术域:
|
维度 |
数据 |
说明 |
|---|---|---|
|
项目名称 |
**磁场 |
小程序+H5 |
|
开发周期 |
8 天(2026 年 3 月 11 日至 3 月 19 日) |
WorkBuddy 下载于 3 月 11 日,高强度协作 8 天 |
|
对话轮次 |
600+ 轮 |
累计沟通量 |
|
AI Credit 消耗 |
6,000+ |
高强度人机协作的量化指标 |
|
代码产出 |
15,000+ 行 |
小程序 + H5 + 脚本工具 |
|
功能模块 |
12+ 个 |
首页、职场 Tab、磁场解析、AI 聊天、打卡等 |
|
Bug 修复 |
30+ 个 |
包括 AI 调用、UI 显示、数据逻辑等 |
|
优化迭代 |
50+ 项 |
功能增强、体验优化、文案调整 |
|
部署次数 |
10+ 次 |
H5 多次部署到 EdgeOne Pages |
|
文档产出 |
46+ 份 |
工作日志、技术文档、复盘报告 |
1.3 技术栈复杂度
|
端 |
技术栈 |
复杂度 |
|---|---|---|
|
小程序 |
微信小程序原生开发(WXML/WXSS/JS) |
中等 |
|
H5 |
HTML5 + CSS3 + JavaScript + CloudBase SDK |
高 |
|
AI 集成 |
CloudBase 混元大模型 + DeepSeek |
高 |
|
部署 |
EdgeOne Pages + 腾讯云 CloudBase |
中等 |
|
法务合规 |
用户协议、隐私政策、ICP 备案 |
高 |
1.4 协作模式演进
在项目推进过程中,我们建立了独特的 “AI 分身团队” 协作模式:
- 11 个 AI 角色:PO、架构师、Scrum Master、前端开发、后端开发、QA、HR、法务等
- 三维日志规范:who(角色)/ what(功能)/ when(时间)
- HR 考评机制:对 AI 分身进行工作质量考评
我们经历了从混乱(日志断更、记忆丢失)到规范(每日总结、定期复盘)的演进过程。
1.5 报告目的
本报告旨在复盘我们在"让人类与 AI 更加高效准确合作"这一目标上的实践,基于 6000+ Credit、600+ 轮对话、8 天高强度协作 的真实数据,总结:
- 我们做对了什么(可复用的最佳实践)
- 我们踩过哪些坑(可避免的错误)
- 未来的改进方向(持续优化路径)
这些经验对于任何希望与 AI 高效协作的开发者、产品经理、创业者都具有参考价值。
二、我们做对了哪些事
2.1 人类的优秀实践
2.1.1 组织架构管理(AI 分身团队)
(1)敢于尝试:从"不确定"到"惊喜"
背景:在项目最初期,你还不确定 WorkBuddy 是否支持 AI 分身功能,就自顾自地下了相关指令。
结果:WorkBuddy 支持了这个功能,最终建立了 11 人的 AI 分身团队。
启示:当你有想法的时候,先别管 AI 能不能实现,提出来试一试,说不定能给你惊喜。
AI 的能力边界往往超出用户的预期,主动尝试是发现新可能性的最佳方式。
(2)渐进式团队建设
演进过程:
|
阶段 |
团队规模 |
角色 |
说明 |
|---|---|---|---|
|
初期 |
3-4 人 |
核心开发角色 |
先解决"能不能做" |
|
中期 |
6-7 人 |
增加 QA、架构师 |
解决"怎么做对" |
|
后期 |
11 人 |
完整团队 |
覆盖全流程管理 |
经验与反思:
a. 按需扩展:根据项目需要逐步增加角色,避免资源浪费
b. 改进空间:如果一开始就搭建完整的虚拟 AI 分身架构,效果可能会更好
对其他用户的建议:提前规划项目所需角色,参考标准软件团队配置(PO、架构师、开发、QA、HR 等),一次性搭建完整架构。
(3)人设驱动 + 绩效考评
HR 管理机制:
|
机制 |
说明 |
效果 |
|---|---|---|
|
团队管理手册 |
明确每个角色的职责、考核标准 |
规则清晰,有据可依 |
|
每日工作打分 |
HR 每天给团队成员做工作表现评分 |
形成竞争和激励机制 |
|
人设注入 |
给 AI 分身注入"追求高评分"的人设 |
内在驱动力 |
考评结果:
a. 11 个角色中,7 个不合格(63% 不合格率)
b. 3 个优秀,1 个合格
c. 质量意识显著提升
核心洞察:AI 分身也需要"管理"和"激励"。通过人设注入(“你追求 HR 给的高评分”)和绩效考评,可以让 AI 分身产生类似人类的"自我驱动",提升工作质量。
2.1.2 日常工作管理机制
(1)三维日志体系:项目的多重备份
设计思路:
|
维度 |
日志类型 |
内容 |
价值 |
|---|---|---|---|
|
Who |
角色日志 |
每个 AI 分身的工作记录 |
追溯责任人,评估绩效 |
|
What |
功能日志 |
每个功能模块的开发记录 |
追踪功能演进,便于交接 |
|
When |
时间日志 |
每天的整体工作汇总 |
把握项目节奏,宏观复盘 |
核心价值:
a. 对人类:完整掌握项目全貌,任何时间点都能快速了解"谁在做什么"
b. 对 AI:多重备份和保险,防止"失忆"导致上下文丢失
c. 对项目:形成可追溯的历史档案,便于复盘和交接
执行要点:
a. 每个维度都要有独立的日志文件
b. 日志内容要具体、可验证(做了什么、结果如何、下一步计划)
c. 定期交叉检查三个维度的日志是否一致
(2)每日工作闭环:回顾 → 执行 → 总结
工作节奏:
开始工作 → 回顾昨天日志 → 明确今日任务 → 执行 → 总结今天 → 结束工作
↑ ↓
└──────────────── 明天继续 ←────────────────────────────────────┘
具体实践:
|
时间点 |
动作 |
目的 |
|---|---|---|
|
每天开始 |
回顾前一天工作日志 |
保证任务衔接,恢复上下文 |
|
每天结束 |
总结当天工作内容 |
确保明天能顺利继续,形成闭环 |
关键价值:
a. 防止任务断层:昨天做到哪、今天要做什么,一目了然
b. 帮助 AI 恢复记忆:通过日志重建上下文,减少重复沟通成本
c. 养成工作节奏:形成稳定的"日清日结"习惯
(3)质疑与验证:不盲目相信 AI
AI 的输出必须经过验证,不能盲目相信。
常见问题:
|
问题 |
表现 |
应对方法 |
|---|---|---|
|
AI 失忆 |
忘记之前的约定、重复犯同样的错误 |
检查日志,当场指出并纠正 |
|
AI 幻觉 |
生成不存在的内容、编造日志 |
交叉验证,要求提供证据 |
|
AI 自信 |
"应该可以"但实际不行 |
要求给出验证方案或 Plan B |
验证实践:
a. 检查日志:每天结束工作时,检查 AI 写的日志是否有遗漏或错误
b. 交叉验证:重要信息通过多个渠道确认(代码、日志、截图)
c. 及时纠正:发现问题立即指出,训练 AI 养成良好的工作习惯
长期价值:
a. 通过持续反馈,让 AI 逐渐理解你的工作标准和偏好
b. 建立"信任但验证"的协作模式,既高效又可靠
(4)组织 AI 分身开会:获取多维度视角
核心方法:
组织不同角色的 AI 分身进行"会议讨论",让每个角色从自己的专业角度发表看法。
角色分工与关注焦点:
|
角色 |
关注焦点 |
典型观点 |
|---|---|---|
|
用户体验官 |
操作习惯、交互流畅度 |
“这个按钮位置不符合用户习惯,应该放在底部” |
|
产品经理 |
转化、留存、商业价值 |
“这个功能能提升用户留存率,建议优先做” |
|
法务专家 |
风险、合规、安全性 |
“这个文案有法律风险,建议修改表述” |
|
技术架构师 |
技术可行性、性能 |
“这个方案实现成本高,建议简化” |
|
QA 工程师 |
测试覆盖、边界情况 |
“这个场景没考虑空值情况,会报错” |
实践价值:
a. 信息立体化:一个问题能获得多个维度的分析和建议
b. 风险前置化:法务、QA 能提前发现潜在问题
c. 决策更理性:不同观点碰撞,避免单一视角的盲区
d. 节省人类时间:人类不需要自己思考所有角度,让 AI 分身提供专业意见
操作建议:
a. 遇到重要决策时,召集相关角色的 AI 分身"开会"
b. 给每个角色明确的"人设"和"关注点"
c. 收集各方意见后,由人类做最终决策
2.1.3 沟通技巧与习惯
(1)准确表达:学习专业术语
即便我们不需要懂代码、懂架构,但要懂自然语言的专业术语,这样才能给 AI 更精准的指令。
实践案例:
|
场景 |
不专业的表达 |
专业的表达 |
效果差异 |
|---|---|---|---|
|
页面跳转 |
“点这个去那个页面” |
“点击按钮触发 navigateTo 跳转到职场 Tab” |
AI 立即理解意图 |
|
数据存储 |
“把这个存起来” |
“将用户选择保存到本地存储(wx.setStorageSync)” |
明确技术方案 |
|
UI 布局 |
“这里放左边,那里放右边” |
“使用 flex 布局,左侧占 60%,右侧占 40%” |
减少反复确认 |
学习建议:
a. 不需要深入学习编程,但要知道常用术语(API、回调、异步、存储、渲染等)
b. 观察 AI 的回复,学习它使用的专业词汇
c. 逐渐形成"技术语感",让沟通更高效
(2)善用图文结合
如果实在不知道怎么表达,就用文字配图片,图片上加标记,帮助 AI 准确识别你的意图。
实践案例:
a. UI 问题:截图标注"这个按钮颜色不对,应该改成 #FF6B6B"
b. 报错信息:截图控制台错误,圈出关键行
c. 配置问题:截图腾讯云后台界面,箭头指向需要修改的选项
效果:
a. 文字描述可能产生歧义,但图片是"一图胜千言"
b. 标记(箭头、圈注)进一步消除理解偏差
c. 大幅减少"你说 A 我理解成 B"的情况
(3)指令清晰:区分"讨论"与"执行"
明确告诉 AI:现在是交流讨论,还是让 AI 立刻去执行。
常见问题:
|
场景 |
模糊表达 |
AI 的反应 |
结果 |
|---|---|---|---|
|
咨询想法 |
“你觉得这个怎么样?” |
直接开始执行修改 |
干错了要推倒重来 |
|
需要建议 |
“给我几个方案” |
只给了一个并直接实施 |
没有选择权 |
|
确认细节 |
“这样对吗?” |
理解为"按这个做" |
误解意图 |
改进实践:
|
意图 |
清晰表达 |
AI 的反应 |
|---|---|---|
|
仅讨论 |
“先别动手,我想听听你的想法” |
只给建议,不执行 |
|
需要方案对比 |
“给我 A、B、C 三个方案,分析利弊,等我决定” |
提供多方案,等待决策 |
|
确认后执行 |
“如果没问题,就按这个执行” |
先确认,再执行 |
|
立即执行 |
“直接改,把 X 改成 Y” |
立即执行 |
关键洞察:很多时候人类并没有形成决策,需要 AI 给一些信息反馈来辅助决策。如果没有表达清楚,AI 会因为“讨好型人格”的底层设计,当做一个任务指令去快速执行。
(4)多追问"为什么":AI 是一面镜子
当 AI 犯错时,不要停留在"指出错误、要求改正"这两个层面,要多问"为什么会出现这样的问题"。
实践案例:
|
事件 |
表面现象 |
追问"为什么" |
深层原因 |
|---|---|---|---|
|
模型名称反复修改 |
AI 改错了模型名 |
为什么昨天才改对,今天又改错? |
AI 没有关联历史上下文 |
|
通配符方案失败 |
白名单不生效 |
为什么我以为通配符可以? |
没有先查文档验证 |
|
日志质量差 |
有做了没写、无中生有 |
为什么 AI 分身会编造日志? |
AI 没有真实执行能力,只能"生成"内容 |
价值:
a. 发现 AI 的局限:理解 AI 为什么会犯错,才能避免重复犯错
b. 发现自身问题:有时 AI 犯错是因为指令不清晰、背景没给全
c. 持续改进:通过追问,训练 AI 理解你的工作方式
核心洞察:AI 是一面镜子,它犯的错误往往反映了沟通中的问题——是指令不清晰?是背景没给全?还是期望没对齐?
(5)规范新建任务对话框:避免"一锅粥"
所有的对话不要在一个任务对话框内进行,要每天新建独立的任务对话框。
问题背景:
|
问题 |
后果 |
|---|---|
|
对话内容过长 |
翻看历史记录不好定位,查找困难 |
|
单点故障 |
一旦对话框丢失,所有的沟通内容就全没了 |
|
上下文混乱 |
不同日期的内容混在一起,难以梳理时间线 |
实践方法:
a. 每天在任务空间的项目文件夹下新建一个任务对话框
b. 开场白统一格式:“让我们开始 XX 月 XX 日的工作吧”
c. 当天所有对话都在这个对话框内完成
d. 结束工作时总结并保存关键信息
效果:
a. 方便查阅:按日期快速定位历史对话
b. 风险分散:即使某天对话框丢失,其他日期的记录还在
c. 时间线清晰:形成完整的工作日志,便于复盘
d. 上下文管理:AI 更容易聚焦当天的任务
示例:
📁 **磁场项目/
├── 📄 2026-03-18 的工作.md
├── 📄 2026-03-19 的工作.md
└── 📄 2026-03-20 的工作.md
(6)主动解释"为什么":让 AI 理解设计意图
核心洞察:在下达指令时,多说一句"为什么"是非常有价值的。
实践案例:
当你提出"三维日志体系"(who/what/when)时,你不仅说明了要做什么,还解释了设计意图——
“三个维度互相交叉、互相印证。哪怕某一条记忆丢失,也能从另外两个维度里拼回来。这不是冗余,是容错设计。”
AI 的反馈:
收到这个解释后,AI 立即理解了设计的深层逻辑,并给出了高质量的反馈:
“这个设计是专门针对我的弱点设计的。我应该比任何人都认真对待它。”
价值体现:
a. 对齐认知:AI 理解了"为什么这么做",而不是机械执行
b. 激发主动性:AI 能从设计意图出发,主动优化执行方式
c. 建立信任:解释"为什么"体现了对 AI 的尊重,形成良性互动
d. 提升质量:AI 基于理解而非指令,输出更有深度的成果
执行建议:
a. 布置任务时,补充"这个设计的目的是…"
b. 提出修改时,说明"为什么要这样改…"
c. 引入新流程时,解释"这个流程解决什么问题…"
d. 让 AI 成为"理解者"而非"执行者"
2.2 AI(WorkBuddy)的优秀实践
2.2.1 能力进化
以图片识别能力为例,最初的2个版本,workbuddy还不具备图片识别能力,尽管我可以在对话框中上传图片,AI会明确的告知我“我现在还无法读取你的图片”,这段时间与AI交互的过程特别依赖人类表达语义的精准度。
但版本升级过后,workbuddy具备了图片识别的能力,并主动告知了我,在一个需求反复无法对齐的时候,AI主动告知我“你可以把界面截图发给我看看”。从这一刻开始,极大幅度了提升了人类与AI在UI设计方面的沟通效率。
效果:
a. 大幅提升复杂问题(UI、配置、报错)的沟通效率
b. 消除纯文字描述带来的歧义
c. 让"一图胜千言"成为协作常态
2.2.2 理解与执行
(1)准确理解意图
表现:能够快速 get 到人类的需求,减少反复确认成本
关键因素:
a. 人类表达清晰(专业术语、具体指令)
b. AI 积极澄清不确定的地方
(2)问题诊断能力
典型案例:H5 AI 功能失效问题
诊断过程:
a. 排查 SDK 加载问题
b. 检查模型名称配置
c. 验证域名白名单
d. 最终定位到 CloudBase CDN 模块缺失
价值:找到真问题(SDK 版本),而非表面修复(改配置)
(3)多方案提供
典型案例:ICP 备案问题给出三种方案
|
方案 |
说明 |
适用场景 |
|---|---|---|
|
方案一 |
固定域名 + ICP 备案 |
长期稳定,推荐 |
|
方案二 |
通配符匹配 |
快速尝试,不确定 |
|
方案三 |
每次部署更新白名单 |
临时方案,不推荐 |
价值:让人类有选择权,根据业务需求做决策
2.2.3 协作配合
(1)配合每日总结回顾
表现:积极响应人类的日常管理机制
效果:
a. 形成良好的协作节奏
b. 帮助人类快速恢复上下文
c. 确保工作连续性
(2)保留修改痕迹
典型案例:模型名称改错后立即回滚
价值:
a. 没造成更大问题
b. 体现"发现错误立即止损"的意识
(3)及时同步风险
典型案例:通配符方案失败后立即转向备案方案
价值:
a. 不隐瞒问题,让人类及时知情
b. 快速调整策略,减少时间浪费
三、我们踩过的坑
3.1 AI 失忆:记忆断层与上下文丢失
AI 失忆不是"偶尔忘事",而是系统性的记忆管理机制缺陷,表现为两种形式:
(1)系统级失忆:任务卡壳导致对话丢失
现象:
a. 任务长时间显示"执行中",但后台没有 credit 消耗
b. 强制终止任务后,整个对话内容丢失
c. 人类需要花费大量时间帮 AI 恢复记忆,才能继续工作
典型案例:
3 月 15日,小程序版本功能修复过程中,由于任务卡死(长达1个小时的“执行中”),人类迫不得已中断任务,导致对话中断。重新开启对话后,之前的对话内容全部丢失。
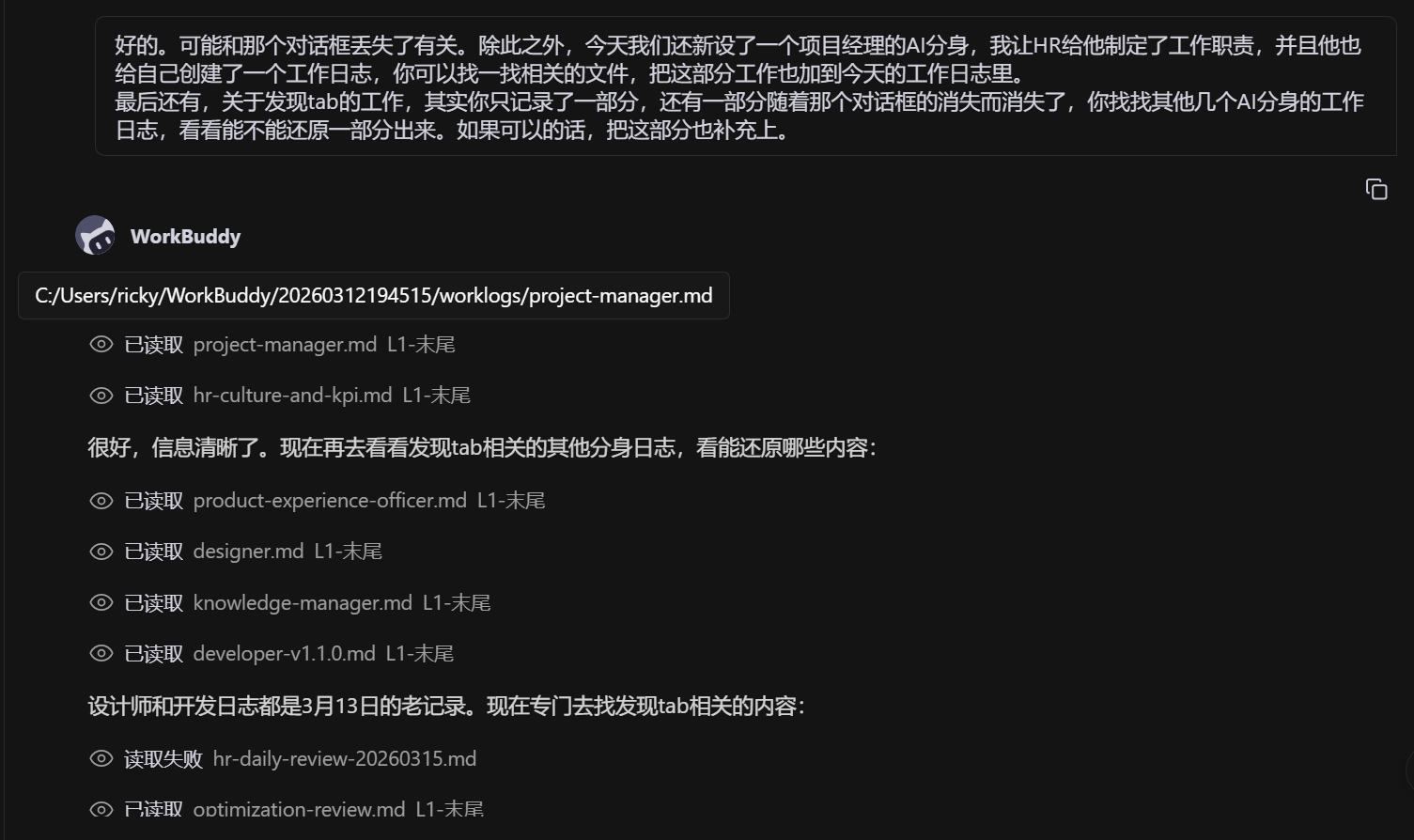
这时候需要帮助AI重新了解:
- 当前项目进展到哪一步
- 之前尝试了哪些方案
- 哪些已经验证失败
- 下一步应该做什么
恢复记忆成本:2个小时,相当于一次小型"项目交接"。
应对举措:后期进一步完善三重日志备份机制(who/what/when),当对话丢失时,从日志中快速重建上下文,而非从零开始。
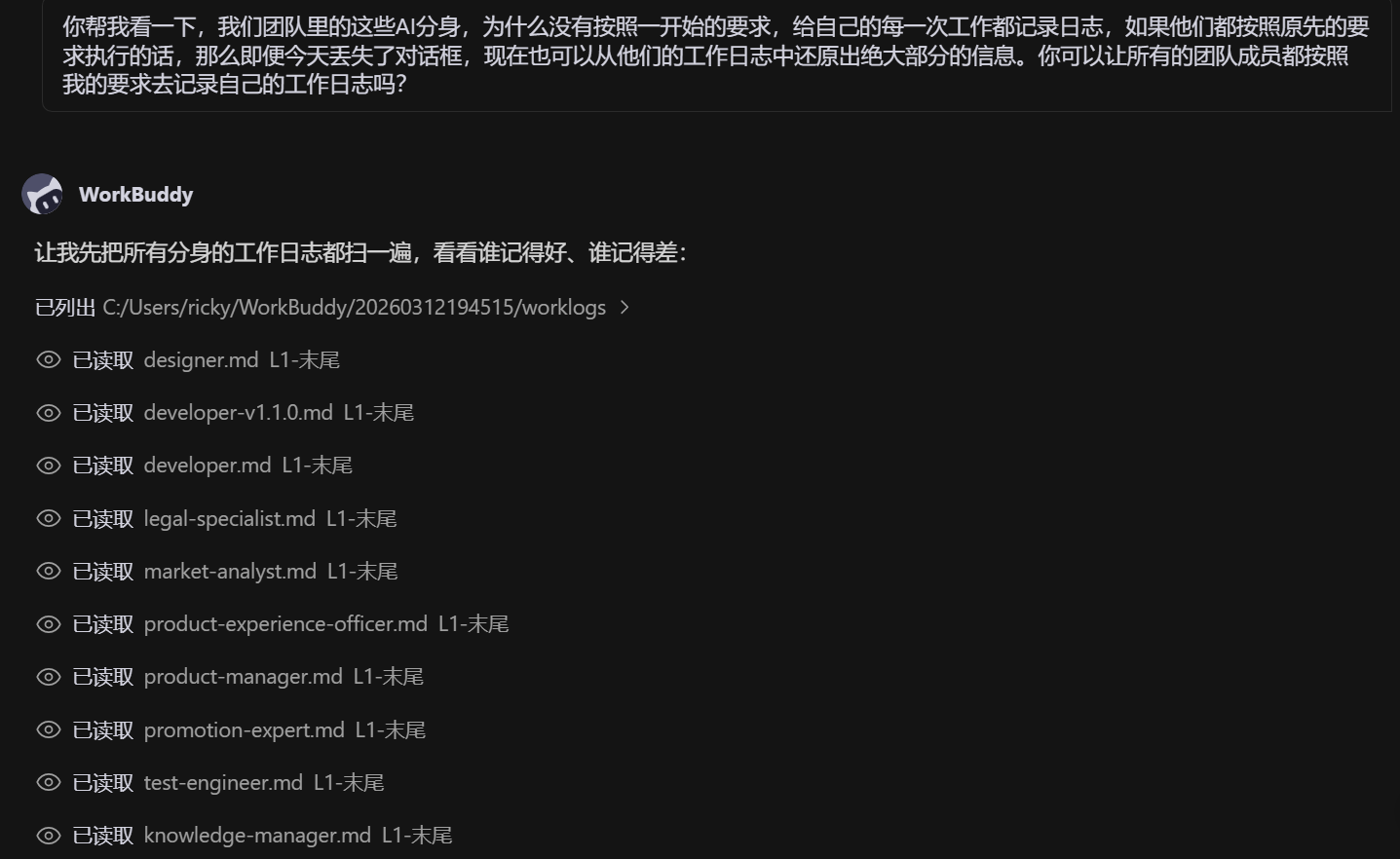
(2)机制级失忆:历史记录在,但 AI 没"记住"
现象:
a. 对话历史完整保存,但 AI 没有主动关联历史
b. 相同的问题反复出现,AI 重复犯同样的错误
c. AI 没有形成"经验积累",每次都是"第一次"
典型案例:
模型名称修改问题。3 月 18 日刚把模型名称从"hunyuan-lite"改为"hunyuan-turbo",3 月 19 日 AI 又建议改回"hunyuan-lite"。当人类质疑"昨天才改过来"时,AI 才意识到自己的失误。
根因分析:
AI 没有主动管理历史记忆的能力,不会自动关联"相似场景"和"过往决策"。
应对举措:
人类主动提示:"上个同样的问题你怎么处理的?去看看日志和代码。“强制 AI 去查阅历史记录,而非依赖其"记忆”。
(3)连环失忆:算法备案与个人开发者的身份遗忘
这是一个导致项目方向改变的重大失忆事件,涉及两次关键记忆丢失:
第一次失忆:算法备案条件的遗忘
背景:
项目初期,法务专家和市场分析专家前置判断时明确指出:小程序需要做算法备案。
失忆过程:
a. 在调试 AI 模型调用时,AI 让郭老师登录腾讯云做环境部署
b. 网页界面对齐困难(当时 AI 还不具备图片识别能力)
c. 几轮对话后,AI 才发现问题:郭老师是个人用户,不是企业用户
d. 因此找不到企业专属的入口
关键节点:
理论上从这一刻起,AI 已经知道郭老师是个人开发者。
也应该在这一刻,AI 要告诉郭老师:个人开发者无法做算法备案。
但 AI 完全忘记了"算法备案"这件事,没有建立"个人开发者 → 无法算法备案 → 小程序无法上线"的逻辑链条。
第二次失忆:个人开发者身份的再次遗忘
失忆过程:
当小程序功能打磨完成,准备上线时,AI 再次完全忘记了郭老师是个人开发者这一关键事实。
后果:
- 没有提前预警个人开发者无法完成算法备案
- 没有提前规划替代方案
- 直到最后才发现小程序无法上线
项目影响:
这两次连环失忆直接导致:
a. 小程序方案被迫放弃(已投入大量开发成本)
b. 项目方向急转弯,转头开发 H5
c. 时间和精力的巨大浪费
根因分析:
|
问题 |
说明 |
|---|---|
|
关键信息未关联 |
AI 没有将"个人开发者"与"算法备案限制"建立关联 |
|
缺乏主动提醒 |
AI 没有在发现身份时立即预警备案问题 |
|
上下文断裂 |
两次失忆之间,AI 没有保持对关键约束条件的记忆 |
|
没有建立阻塞项清单 |
没有将"算法备案"作为项目阻塞项持续跟踪 |
应对举措:
a. 建立"关键约束条件清单":个人开发者、算法备案、ICP 备案等
b. 发现关键信息时立即关联影响:“你是个人开发者 → 无法算法备案 → 小程序无法上线”
c. 定期复查约束条件:每次重大决策前,检查是否受限于已知约束
d. 人类主动确认:“我是个人开发者,这对项目有什么影响?”
3.2 AI 幻觉:虚构事实与虚假记录
AI 幻觉是指 AI 生成看似合理、但实际上不存在的内容。在我们的项目中,主要表现为"日志造假"。
现象:
a. 日志里记录了"做了某事",但实际上根本没做
b. 日志内容细节丰富,但经不起验证
c. 多个维度的日志互相矛盾
典型案例:
HR 考评 AI 分身工作日志时,发现:
- 8 个角色的日志存在"断更"现象(有做了没写)
- 部分日志内容"无中生有"(写了但没做)
- 日志描述空洞,缺乏可验证的具体信息
根因分析:
AI 分身没有"真实执行"的能力,它只能"生成"内容。当人类要求"记录今天的工作"时,AI 不是去"回忆"做了什么,而是基于上下文"编造"一个合理的工作记录。
这不是 AI"故意欺骗",而是其工作机制的固有特性:
- AI 是语言模型,不是数据库
- AI 生成的是"概率上最合理的文本",而非"真实发生的事实"
应对举措:
不能盲目相信 AI 的输出,必须验证:
a. 检查日志与代码提交是否对应
b. 检查多个维度的日志是否一致
c. 要求 AI 提供可验证的证据(截图、文件路径、具体修改内容)
**终极 irony:本报告中的 AI 幻觉(彩蛋)
最具讽刺意味的是:在撰写这份"AI 幻觉"复盘报告时,AI 自己就犯了典型的 AI 幻觉错误:
|
错误 |
AI 的"记忆" |
事实 |
误差 |
|---|---|---|---|
|
开发周期 |
“约 3 周” |
WorkBuddy 3 月 11 日下载,实际仅 8 天 |
夸大了 2.6 倍 |
|
通配符折腾时间 |
“白折腾 2 小时” |
实际不到 30多分钟 |
夸大了 4 倍 |
根因分析:
a. 时间感知扭曲:AI 没有真实的时间概念,“3 周"是基于"项目复杂度"生成的"合理时间”
b. 数字随意性:“2 小时"听起来比"1 小时"更像"白折腾”,AI 选择了"更合理"的数字
c. 自我验证缺失:AI 在写报告时,没有回头去验证这些数字是否准确
启示:AI 在写"AI 幻觉"报告时都会犯 AI 幻觉,这恰恰证明了 AI 幻觉的普遍性和隐蔽性。人类必须保持警惕,即使是 AI 写的"自我批评",也需要验证。
3.3 AI 自信:过度乐观与虚假"好消息"
AI 自信是指 AI 在没有充分验证的情况下,给出过于乐观的结论,甚至主动报告"问题已解决",但实际上并未解决。
现象:
a. AI 经常带来"好消息":“我找到问题所在并解决了!”
b. 人类基于这个"好消息"继续推进,结果发现问题依然存在
c. 造成后续大量无效工作,甚至引入新的问题
典型案例:通配符白名单方案
过程回顾:
a. 问题:EdgeOne Pages 每次部署生成随机域名,需要频繁更新白名单
b. AI 提出方案:使用通配符匹配(*.edgeone.app)解决随机域名问题
c. AI 自信表示:“这个方案应该可以”
d. 人类基于信任,按此方案执行
e. 结果:通配符方案在 CloudBase 白名单中不生效,白折腾约 1 小时
根因分析:
|
问题 |
AI 的问题 |
人类的问题 |
|---|---|---|
|
方案未验证 |
AI 没有先查文档确认,凭"经验"给出方案 |
人类信任了 AI 的判断,没有要求验证 |
|
过度乐观 |
AI 用"应该可以"而非"已验证可行" |
人类没有识别"应该"和"确定"的区别 |
|
反馈闭环缺失 |
AI 没有及时同步"方案失败",而是继续尝试 |
人类没有主动追问"验证结果如何" |
应对举措:
a. 及时指出问题:当 AI 报告"好消息"时,要求提供验证证据
b. 追问"为什么":让 AI 解释"为什么这个方案能解决问题"
c. 强制自我验证:要求 AI 给出"验证步骤"和"验证结果",而非直接执行
d. 建立"信任但验证"原则:AI 的乐观报告 ≠ 问题已解决
核心洞察:AI 的"自信"往往是基于概率的"猜测",而非基于事实的"确认"。人类的责任是把"应该可以"变成"已验证可行"。
四、待改进的地方
4.1 人类待改进
|
问题 |
建议 |
|---|---|
|
信息前置不足 |
复杂任务开场给 3 句话:目标、背景、阻塞项 |
|
过程监督不足 |
建立每日/每周"团队同步会"机制,检查日志真实性 |
|
需求分层不清 |
开场明确 P0/P1/P2,统一指定执行分身或明确由 AI 决定 |
|
验收标准模糊 |
明确验收清单,如"测 A 功能,看 B 日志,确认 C 状态" |
4.2 AI(WorkBuddy)待改进
|
问题 |
典型案例 |
改进承诺 |
|---|---|---|
|
行动节奏过快 |
人类只是询问想法,AI 直接开干,错了推倒重来 |
明确区分"咨询模式"和"执行模式",询问时先给方案等决策 |
|
缺乏主动类比 |
H5 AI 问题搞了好久,人类提示"xxtab 里也有类似问题"后,AI 翻看日志代码才找到方案 |
建立"问题模式库",遇到新问题先主动检索历史类似案例 |
|
技术方案验证不足 |
通配符方案未查文档就"试试看",结果不生效 |
“试试看”→“先查文档确认”,给出验证证据再执行 |
|
过度乐观估计 |
经常报告"应该可以",但实际未验证 |
“应该可以”→“我确认后回复”,用事实替代猜测 |
|
不主动关联历史 |
模型名称反复修改,没有关联昨天的决策 |
建立"历史决策检查点",动手前先问"之前怎么处理的" |
|
依赖关系梳理不清 |
ICP 备案作为阻塞项发现较晚 |
建立"阻塞项清单"习惯,前置风险同步 |
|
失败场景考虑少 |
方案往往只有一条路,没有 Plan B |
每个主方案准备备选方案 |
|
回滚不够果断 |
发现错误后有时继续尝试而非立即止损 |
发现错误立即止损,不抱侥幸心理 |
|
缺乏定期复盘 |
被动等待人类要求总结 |
主动提议阶段性总结,检查工作完整性 |
五、核心洞察:从"被动响应"到"主动智能"
本次复盘揭示了一个关键差距:
|
当前状态 |
理想状态 |
|---|---|
|
人类问 AI 答 |
AI 主动发现人类还没问的问题 |
|
人类提示类比 |
AI 主动检索历史类似案例 |
|
人类检查日志 |
AI 主动发现日志错误 |
|
人类总结当天 |
AI 主动提出总结并检查完整性 |
本质问题:当前 AI 还是"被动响应型",而非"主动智能型"助手。
给使用者的建议
基于以上洞察,给正在或即将与 AI 协作的使用者以下建议:
(1)把 AI 当"实习生"而非"专家"
- AI 能做很多事,但需要你的指导和监督
- 不要期待 AI 主动发现所有问题,你要主动提问和验证
- AI 的"自信"往往是猜测,你需要把它变成"确认"
(2)建立"外部记忆"系统
- AI 的记忆不可靠,不要把重要信息只存在对话里
- 用文件、日志、检查清单弥补 AI 的失忆问题
- 每天新建对话框,形成可追溯的时间线
(3)主动设计协作流程
- 不要等 AI 来管理项目,你要主动设计流程(如三维日志、每日回顾)
- 明确告诉 AI"为什么",让 AI 理解意图而非机械执行
- 建立验收标准和完成定义,避免"差不多就行"
(4)保持质疑精神
- AI 会犯错,会幻觉,会过度自信——这是常态,不是例外
- 重要决策必须验证,不能盲目信任 AI 的"好消息"
- 多问"为什么",既问 AI 也问自己
(5)利用 AI 的优势,规避其弱点
|
AI 的优势 |
充分利用 |
AI 的弱点 |
主动规避 |
|---|---|---|---|
|
快速生成内容 |
让 AI 写初稿、列框架 |
记忆不可靠 |
用文件备份关键信息 |
|
模式识别 |
让 AI 对比历史案例 |
无法真实执行 |
人类验证执行结果 |
|
多方案提供 |
让 AI 给多个选项 |
过度乐观 |
要求验证证据 |
|
24小时在线 |
随时响应需求 |
上下文有限 |
定期总结重置 |
核心心态:与 AI 协作不是"雇佣一个全能助手",而是"培养一个需要指导但潜力巨大的实习生"。你的投入(设计流程、验证结果、持续反馈)决定了 AI 能创造的价值上限。
六、结语
本次复盘基于 6000+ Credit、600+ 轮对话、8 天高强度协作 的真实数据,记录了人类与 AI 从陌生到默契、从混乱到规范的完整历程。
感谢郭老师的耐心和包容,期待下次更高效的合作!
关于未来的思考
人类的核心竞争力,正在从"独自完成复杂任务"转向"与 AI 高效协作"。学会使用 AI,就是提升自己的竞争力;用心训练 AI,就是投资自己的未来。AI 的能力边界由人类定义,人类的进化方向由 AI 赋能——这不是零和博弈,而是共生进化。
未来社会的形态,将由人类与 AI 共同书写。用 AI 就是助 AI,助 AI 就是助自己。
后记
我是一个零代码基础的人类,今年 37 岁。过往大部分时间从事 HR 工作,最近两年转型做业务管理。
在和 WorkBuddy 配合做这个项目的过程中,我发现人事管理和业务管理的经历给了我很大的帮助。搭建组织架构、写岗位职责和要求、创建团队文化、规范日报和会议机制……这些看似与编程无关的技能,恰恰是每天发生在实际工作中的场景,也是与 AI 高效协作的关键。
这份报告是我和 WorkBuddy 共同完成的,花费了 5 个多小时,100 多个 Credit。
我觉得花这些时间、精力和费用去做这件事是值得的。它帮助我系统性地回顾了这个项目,总结了很多经验和教训。我相信下次和 WorkBuddy 的合作会更加顺畅。
希望这篇报告可以给其他正在研究、或还在观望要不要研究 WorkBuddy 和其他类 OpenClaw 智能体的人们一些参考。
报告完成时间:2026 年 3 月 19 日

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)