AgentScope
1. AgentScope整体架构
1.1 架构概览与设计原则
AgentScope采用了模块化、分层的架构设计,整体架构分为以下几个核心层次:
- 核心层:包含Agent、Environment、Memory等基础组件
- 服务层:提供模型管理、工具调用、消息传递等服务
- 应用层:面向开发者的API和开发工具
- 部署层:包含监控、部署、运维等功能
设计原则:
- 模块化:各组件职责明确,边界清晰
- 可扩展性:支持自定义组件和插件
- 可靠性:内置错误处理和容错机制
- 性能优先:针对多智能体场景优化
- 开发者友好:提供简洁易用的API
1.2 核心层次划分
| 层次 | 主要职责 | 核心组件 |
|---|---|---|
| 核心层 | 智能体定义与管理 | Agent、Environment、Memory |
| 服务层 | 提供核心服务 | Model、Tool、Message、Event |
| 应用层 | 开发者接口 | API、SDK、CLI工具 |
| 部署层 | 系统运维 | Monitoring、Deployment、Security |
1.3 模块间的依赖关系
AgentScope的模块间采用了松耦合的设计,主要依赖关系如下:
- Agent 依赖 Environment 提供运行环境
- Agent 依赖 Memory 管理状态和记忆
- Agent 依赖 Model 进行决策和推理
- Agent 依赖 Tool 执行外部操作
- Agent 依赖 Message 进行通信
- 应用层 依赖 核心层 和 服务层 提供功能
- 部署层 监控和管理所有其他层
2. 核心组件详解
2.1 Agent组件
Agent是AgentScope的核心概念,代表一个具有自主决策能力的智能实体。
2.1.1 智能体的定义
class Agent:
def __init__(self, name, model, memory=None, tools=None):
self.name = name
self.model = model
self.memory = memory or Memory()
self.tools = tools or []
self.state = {}
def act(self, observation):
# 基于观察进行决策
pass
def learn(self, experience):
# 从经验中学习
pass
2.1.2 智能体的类型
- 基础智能体:具备基本的观察-决策-行动能力
- 工具使用智能体:能够调用外部工具执行任务
- 协作智能体:能够与其他智能体进行协作
- 领域专家智能体:针对特定领域优化的智能体
- 元智能体:管理其他智能体的智能体
2.1.3 智能体的生命周期
- 初始化:创建智能体实例,配置模型、记忆和工具
- 启动:智能体进入就绪状态,准备接收任务
- 执行:智能体处理任务,与环境和其他智能体交互
- 暂停:智能体暂时停止执行,但保持状态
- 恢复:智能体从暂停状态恢复执行
- 终止:智能体停止执行,释放资源
2.2 Environment组件
Environment为智能体提供运行环境,管理智能体的交互和状态。
2.2.1 环境的概念
Environment是智能体活动的场所,它提供了以下功能:
- 状态管理:维护环境的当前状态
- 交互管理:处理智能体与环境的交互
- 事件触发:生成和处理环境事件
- 资源管理:管理环境中的资源
2.2.2 环境的作用
- 为智能体提供统一的交互接口
- 隔离智能体与外部系统的直接交互
- 管理智能体间的通信
- 提供环境状态的持久化
3.2.3 环境的实现
class Environment:
def __init__(self, name):
self.name = name
self.state = {}
self.agents = {}
self.events = []
def add_agent(self, agent):
# 添加智能体到环境
pass
def step(self):
# 环境步进,处理智能体动作
pass
def reset(self):
# 重置环境状态
pass
2.3 Memory组件
Memory组件管理智能体的记忆系统,包括短期记忆和长期记忆。
2.3.1 记忆系统的设计
- 短期记忆:存储最近的交互和状态
- 长期记忆:存储重要的信息和经验
- 记忆检索:基于相似度或关键词检索记忆
- 记忆更新:根据新经验更新记忆
3.3.2 记忆的类型
| 记忆类型 | 存储内容 | 特点 |
|---|---|---|
| 短期记忆 | 最近的交互、状态 | 容量小,访问快 |
| 长期记忆 | 重要经验、知识 | 容量大,持久化 |
| 语义记忆 | 概念、规则、关系 | 结构化存储 |
| 情景记忆 | 具体事件、经历 | 时间序列存储 |
2.3.3 记忆的管理
class Memory:
def __init__(self):
self.short_term = []
self.long_term = []
self.embeddings = {}
def add(self, content, importance=0.5):
# 添加记忆内容
pass
def retrieve(self, query, k=5):
# 检索相关记忆
pass
def forget(self, criteria):
# 遗忘不重要的记忆
pass
2.4 Model组件
Model组件负责模型的管理和调用,为智能体提供推理能力。
2.4.1 模型抽象
- 统一接口:为不同模型提供统一的调用接口
- 模型管理:处理模型的加载、切换和释放
- 参数配置:管理模型的参数和配置
- 性能优化:优化模型调用性能
2.4.2 多模型支持
- OpenAI模型:GPT系列模型
- 阿里云模型:通义千问系列
- 百度模型:文心一言系列
- 其他模型:支持自定义模型集成
2.5 Tool组件
Tool组件提供工具系统,使智能体能够调用外部工具执行任务。
2.5.1 工具系统的设计
- 工具注册:注册和管理可用工具
- 工具调用:执行工具并处理结果
- 工具参数:管理工具的输入参数
- 工具结果:处理工具的输出结果
2.5.2 工具的使用
class Tool:
def __init__(self, name, func, description):
self.name = name
self.func = func
self.description = description
def run(self, **kwargs):
# 执行工具
return self.func(**kwargs)
class ToolManager:
def __init__(self):
self.tools = {}
def register_tool(self, tool):
# 注册工具
self.tools[tool.name] = tool
def call_tool(self, tool_name, **kwargs):
# 调用工具
if tool_name in self.tools:
return self.tools[tool_name].run(**kwargs)
raise ValueError(f"Tool {tool_name} not found")
2.6 Message组件
Message组件负责智能体间的消息传递,是多智能体协作的基础。
2.6.1 消息系统的设计
- 消息类型:支持不同类型的消息(文本、结构化数据等)
- 消息路由:根据目标智能体路由消息
- 消息队列:处理消息的异步传递
- 消息持久化:存储消息历史
2.6.2 消息传递机制
- 直接消息:智能体间的点对点通信
- 广播消息:向所有智能体发送消息
- 组消息:向特定组的智能体发送消息
- 事件消息:基于事件的消息传递
3. 交互机制与数据流
3.1 组件间的交互方式
AgentScope采用了多种交互方式来支持组件间的通信:
- 同步调用:直接函数调用,适用于实时性要求高的场景
- 异步消息:基于消息队列的异步通信,适用于非实时场景
- 事件驱动:基于事件的发布-订阅模式,适用于松耦合场景
- 共享状态:通过共享内存或数据库的方式共享状态
3.2 数据流分析
智能体系统的典型数据流如下:
- 输入数据:用户输入、环境状态、外部系统数据
- 智能体处理:智能体接收输入,进行决策
- 工具调用:智能体调用工具执行任务
- 状态更新:根据执行结果更新智能体和环境状态
- 输出数据:生成响应、触发事件、更新外部系统
3.3 控制流分析
控制流主要包括:
- 智能体生命周期管理:创建、启动、执行、暂停、终止
- 任务执行流程:任务接收、分配、执行、完成
- 协作流程:智能体间的协商、协调、执行
- 错误处理流程:错误检测、处理、恢复
3.4 交互时序图
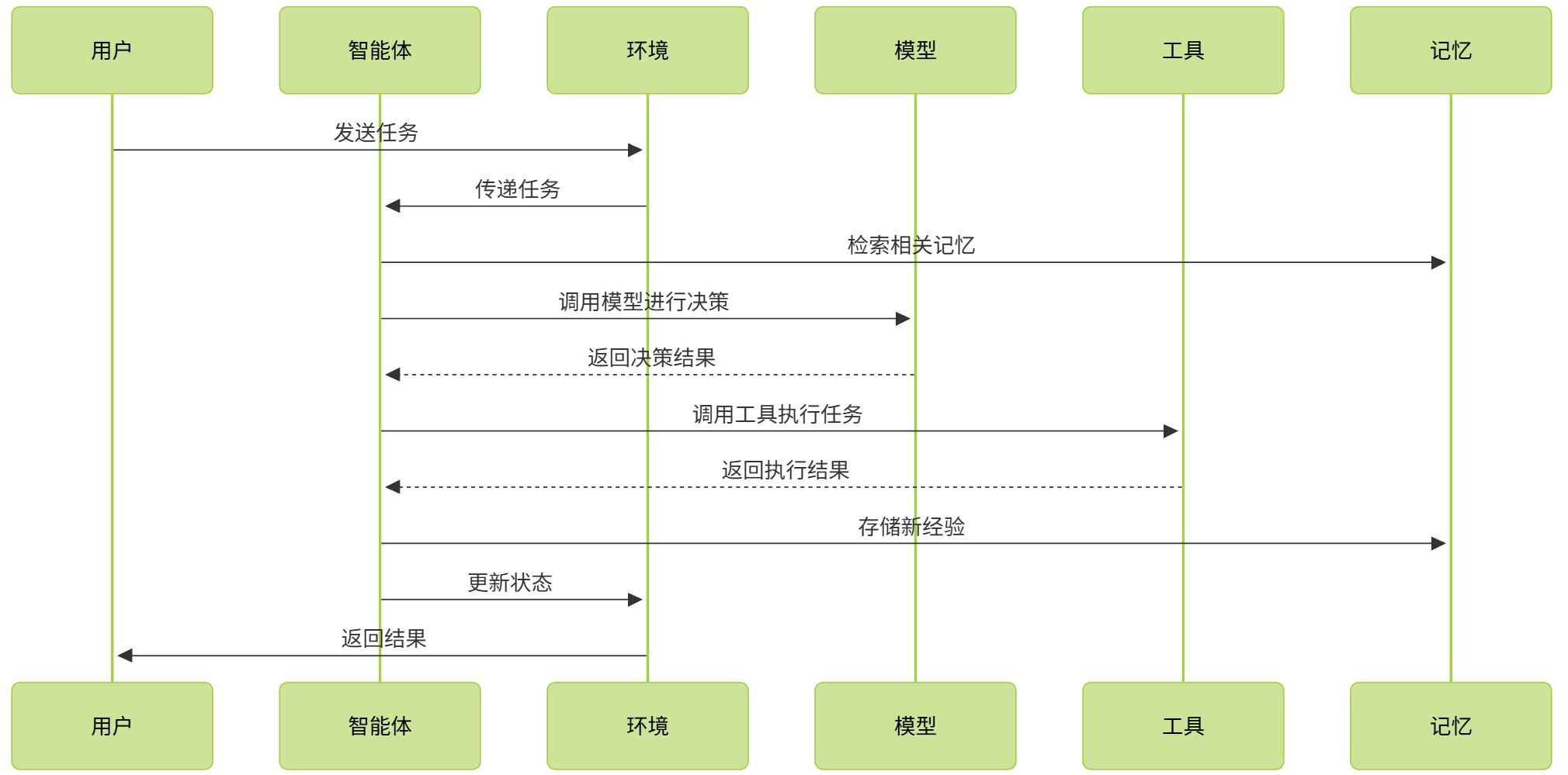
4. 扩展与定制能力
4.1 插件系统
AgentScope提供了灵活的插件系统,支持开发者扩展框架功能:
- 插件注册:通过注册机制添加新插件
- 插件加载:动态加载和卸载插件
- 插件依赖:管理插件间的依赖关系
- 插件配置:为插件提供配置选项
4.2 自定义组件
开发者可以自定义以下组件:
- 自定义智能体:继承基础Agent类,实现特定功能
- 自定义环境:创建特定领域的环境
- 自定义记忆:实现特殊的记忆管理策略
- 自定义工具:添加新的工具类型
- 自定义模型:集成新的模型后端
4.3 集成第三方服务
- API集成:与外部API服务集成
- 数据库集成:与各种数据库系统集成
- 消息队列集成:与消息队列系统集成
- 监控系统集成:与监控工具集成
5. 环境搭建
5.1 系统要求
在开始搭建AgentScope环境之前,确保你的系统满足以下要求:
- 操作系统:Windows 10/11、macOS 10.15+、Linux (Ubuntu 18.04+)
- Python版本:Python 3.8+(推荐Python 3.10+)
- 内存:至少4GB RAM(推荐8GB+)
- 磁盘空间:至少10GB可用空间
- 网络连接:需要网络连接以下载依赖和调用模型API
5.2 依赖安装
5.2.1 使用pip安装
# 创建并激活虚拟环境
python -m venv agentscope-env
source agentscope-env/bin/activate # Linux/macOS
# 或
agentscope-env\Scripts\activate # Windows
# 安装AgentScope
pip install agentscope
# 安装可选依赖(根据需要)
pip install agentscope[all] # 安装所有可选依赖
# 或
pip install agentscope[model] # 安装模型相关依赖
pip install agentscope[tool] # 安装工具相关依赖
pip install agentscope[monitor] # 安装监控相关依赖
5.2.2 使用conda安装
# 创建conda环境
conda create -n agentscope-env python=3.10
conda activate agentscope-env
# 安装AgentScope
pip install agentscope
5.3 配置方法
5.3.1 环境变量配置
AgentScope需要配置一些环境变量来连接模型和服务:
-
OpenAI模型配置:
export OPENAI_API_KEY=your_openai_api_key -
阿里云通义千问配置:
export DASHSCOPE_API_KEY=your_dashscope_api_key -
百度文心一言配置:
export ERNIE_API_KEY=your_ernie_api_key export ERNIE_SECRET_KEY=your_ernie_secret_key
5.3.2 配置文件
你也可以创建一个配置文件来管理这些设置:
# config.yaml
models:
openai:
api_key: your_openai_api_key
dashscope:
api_key: your_dashscope_api_key
ernie:
api_key: your_ernie_api_key
secret_key: your_ernie_secret_key
environment:
log_level: INFO
cache_dir: ./cache
timeout: 30
5.4 验证流程
安装完成后,运行以下命令验证环境是否配置正确:
# 验证AgentScope安装
python -c "import agentscope; print('AgentScope version:', agentscope.__version__)"
# 验证模型配置(以OpenAI为例)
python -c "
import agentscope
from agentscope.models import OpenAIModel
# 创建模型实例
model = OpenAIModel(model='gpt-3.5-turbo')
# 测试模型调用
response = model('Hello, AgentScope!')
print('Model response:', response)
"
6. 第一个Agent应用
6.1 项目结构搭建
创建一个简单的项目结构:
my-first-agent/
├── config.yaml # 配置文件
├── main.py # 主脚本
└── requirements.txt # 依赖文件
6.2 基础代码实现
创建main.py文件,实现一个简单的对话智能体:
import agentscope
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
# 初始化AgentScope
agentscope.init(config="config.yaml")
# 创建模型实例
model = OpenAIModel(
model="gpt-3.5-turbo",
temperature=0.7,
max_tokens=500
)
# 创建对话智能体
agent = DialogAgent(
name="Assistant",
model=model,
system_prompt="你是一个 helpful 的人工智能助手,善于回答各种问题。"
)
# 与智能体交互
print("AgentScope对话智能体示例")
print("输入'quit'退出对话")
print("=" * 50)
while True:
user_input = input("用户: ")
if user_input.lower() == "quit":
break
# 智能体处理输入并生成响应
response = agent(user_input)
print(f"助手: {response}")
print("=" * 50)
6.3 运行与验证
运行应用:
cd my-first-agent
python main.py
预期输出:
AgentScope对话智能体示例
输入'quit'退出对话
==================================================
用户: 你好,介绍一下你自己
助手: 你好!我是一个基于大语言模型的人工智能助手,由AgentScope框架驱动。我可以回答你的问题、提供信息、协助完成各种任务,并且不断学习以提升我的能力。请问有什么我可以帮助你的吗?
==================================================
用户: 什么是AgentScope
助手: AgentScope是阿里巴巴通义实验室推出的新一代智能体开发框架,专注于多智能体开发。它提供了高易用、高可靠的编程体验,支持多种大语言模型,并且内置了完善的智能体管理、状态管理、工具调用等功能。通过AgentScope,开发者可以更加高效地构建复杂的智能体系统,实现多智能体协作完成各种任务。
==================================================
用户: quit
6.4 代码解析与说明
- 初始化AgentScope:
agentscope.init()函数初始化框架,加载配置文件。 - 创建模型实例:
OpenAIModel类创建一个使用OpenAI GPT模型的实例。 - 创建对话智能体:
DialogAgent类创建一个简单的对话智能体,设置名称、模型和系统提示。 - 智能体交互:通过调用智能体实例并传入用户输入,获取智能体的响应。
7. 核心概念实践
7.1 Agent创建与配置
7.1.1 基础智能体
from agentscope.agents import BaseAgent
from agentscope.models import OpenAIModel
# 创建模型
model = OpenAIModel(model="gpt-3.5-turbo")
# 创建基础智能体
agent = BaseAgent(
name="BaseAgent",
model=model,
memory=None, # 不使用记忆
tools=None # 不使用工具
)
# 使用智能体
result = agent("请解释什么是机器学习")
print(result)
7.1.2 工具使用智能体
from agentscope.agents import ToolAgent
from agentscope.models import OpenAIModel
from agentscope.tools import CalculatorTool, SearchTool
# 创建模型
model = OpenAIModel(model="gpt-3.5-turbo")
# 创建工具
calculator_tool = CalculatorTool()
search_tool = SearchTool()
tools = [calculator_tool, search_tool]
# 创建工具使用智能体
agent = ToolAgent(
name="ToolAgent",
model=model,
tools=tools
)
# 使用智能体(工具调用示例)
result = agent("345乘以678等于多少?")
print(result)
result = agent("今天北京的天气怎么样?")
print(result)
7.2 基本交互模式
AgentScope支持多种交互模式:
7.2.1 同步交互
# 同步调用智能体
response = agent("你好,AgentScope!")
print(response)
7.2.2 异步交互
import asyncio
async def async_interaction():
# 异步调用智能体
response = await agent.ainvoke("你好,AgentScope!")
print(response)
# 运行异步函数
asyncio.run(async_interaction())
7.2.3 批量交互
# 批量调用智能体
inputs = ["你好", "什么是AI", "今天天气如何"]
responses = agent.batch_invoke(inputs)
for i, response in enumerate(responses):
print(f"输入: {inputs[i]}")
print(f"输出: {response}")
print("=" * 30)
7.3 简单工具调用
7.3.1 内置工具
AgentScope提供了一些内置工具:
- CalculatorTool:计算器工具,用于执行数学计算
- SearchTool:搜索工具,用于获取网络信息
- FileTool:文件工具,用于读写文件
- CodeTool:代码工具,用于执行代码
7.3.2 工具调用示例
from agentscope.agents import ToolAgent
from agentscope.models import OpenAIModel
from agentscope.tools import CalculatorTool, FileTool
# 创建模型
model = OpenAIModel(model="gpt-3.5-turbo")
# 创建工具
calculator = CalculatorTool()
file_tool = FileTool()
tools = [calculator, file_tool]
# 创建工具智能体
agent = ToolAgent(
name="ToolAgent",
model=model,
tools=tools
)
# 测试计算器工具
result = agent("计算123的平方")
print("计算器测试结果:", result)
# 测试文件工具
result = agent("创建一个文件,内容为'Hello AgentScope!',文件名为test.txt")
print("文件创建结果:", result)
result = agent("读取test.txt文件的内容")
print("文件读取结果:", result)
7.4 消息传递实践
7.4.1 单智能体消息处理
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
from agentscope.message import Message
# 创建模型
model = OpenAIModel(model="gpt-3.5-turbo")
# 创建智能体
agent = DialogAgent(
name="Assistant",
model=model
)
# 创建消息对象
message = Message(
content="你好,如何使用消息传递功能?",
role="user",
sender="User"
)
# 处理消息
response = agent.handle_message(message)
print(f"智能体响应: {response.content}")
7.4.2 多智能体消息传递
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
from agentscope.environment import Environment
# 创建模型
model1 = OpenAIModel(model="gpt-3.5-turbo")
model2 = OpenAIModel(model="gpt-3.5-turbo")
# 创建智能体
agent1 = DialogAgent(
name="Alice",
model=model1,
system_prompt="你是Alice,一个友好的助手。"
)
agent2 = DialogAgent(
name="Bob",
model=model2,
system_prompt="你是Bob,一个技术专家。"
)
# 创建环境
env = Environment(name="ChatRoom")
# 添加智能体到环境
env.add_agent(agent1)
env.add_agent(agent2)
# 智能体间消息传递
env.send_message(
content="Bob,你好!我是Alice。",
sender="Alice",
receiver="Bob"
)
# 查看环境中的消息
messages = env.get_messages()
for msg in messages:
print(f"{msg.sender}: {msg.content}")
8. 常见问题与解决方案
8.1 环境配置问题
8.1.1 依赖安装失败
问题:pip install agentscope 失败
解决方案:
- 确保Python版本符合要求(3.8+)
- 升级pip:
pip install --upgrade pip - 尝试使用镜像源:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple agentscope - 检查网络连接是否正常
8.1.2 模型API密钥配置错误
问题:运行时出现模型API密钥错误
解决方案:
- 确保正确设置了环境变量
- 检查API密钥是否有效
- 确认网络连接可以访问模型服务
- 对于中国用户,考虑使用国内模型如通义千问
8.2 依赖冲突问题
8.2.1 与其他库版本冲突
问题:安装AgentScope后,其他库无法正常工作
解决方案:
- 使用虚拟环境隔离依赖
- 检查冲突的依赖版本
- 尝试安装特定版本的依赖:
pip install package==version - 参考AgentScope的兼容性文档
8.2.2 版本不兼容
问题:AgentScope版本与Python版本不兼容
解决方案:
- 查看AgentScope的官方文档,确认支持的Python版本
- 安装兼容的Python版本
- 或安装兼容的AgentScope版本
8.3 运行时错误
8.3.1 模型调用超时
问题:模型调用时出现超时错误
解决方案:
- 检查网络连接
- 增加超时设置:
model = OpenAIModel(model="gpt-3.5-turbo", timeout=60) - 尝试使用响应速度更快的模型
- 减少请求的复杂度和长度
8.3.2 内存不足
问题:运行时出现内存不足错误
解决方案:
- 增加系统内存
- 减少批量处理的大小
- 优化代码,减少内存使用
- 关闭不必要的应用程序
8.4 调试技巧
8.4.1 启用详细日志
import agentscope
# 启用详细日志
agentscope.init(log_level="DEBUG")
8.4.2 检查模型配置
from agentscope.models import OpenAIModel
# 检查模型配置
model = OpenAIModel(model="gpt-3.5-turbo")
print("模型配置:", model.config)
# 测试模型连接
try:
response = model("测试连接")
print("模型连接成功:", response)
except Exception as e:
print("模型连接失败:", str(e))
9. 多智能体协作
9.1 协作模式设计
AgentScope支持多种智能体协作模式,以适应不同的应用场景:
9.1.1 顺序协作模式
顺序协作模式是指智能体按照预定的顺序依次执行任务,每个智能体完成自己的任务后将结果传递给下一个智能体:
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
from agentscope.environment import Environment
# 创建模型
model1 = OpenAIModel(model="gpt-3.5-turbo")
model2 = OpenAIModel(model="gpt-3.5-turbo")
model3 = OpenAIModel(model="gpt-3.5-turbo")
# 创建智能体
planner = DialogAgent(
name="Planner",
model=model1,
system_prompt="你是一个任务规划师,负责将复杂任务分解为简单步骤。"
)
executor = DialogAgent(
name="Executor",
model=model2,
system_prompt="你是一个任务执行者,负责按照步骤执行具体任务。"
)
reviewer = DialogAgent(
name="Reviewer",
model=model3,
system_prompt="你是一个任务评审者,负责检查任务执行结果并提供改进建议。"
)
# 创建环境
env = Environment(name="SequentialCooperation")
env.add_agent(planner)
env.add_agent(executor)
env.add_agent(reviewer)
# 顺序协作流程
def sequential_cooperation(task):
# 1. 规划任务
plan = planner(f"请将以下任务分解为具体步骤:{task}")
print(f"规划结果: {plan}")
# 2. 执行任务
execution = executor(f"请按照以下步骤执行任务:{plan}")
print(f"执行结果: {execution}")
# 3. 评审结果
review = reviewer(f"请评审以下任务执行结果:{execution}")
print(f"评审结果: {review}")
return review
# 测试顺序协作
result = sequential_cooperation("为一个新的Python项目创建项目结构和基础文件")
print(f"最终结果: {result}")
9.1.2 并行协作模式
并行协作模式是指多个智能体同时执行不同的子任务,然后汇总结果:
import asyncio
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
# 创建模型
model1 = OpenAIModel(model="gpt-3.5-turbo")
model2 = OpenAIModel(model="gpt-3.5-turbo")
model3 = OpenAIModel(model="gpt-3.5-turbo")
# 创建智能体
data_analyst = DialogAgent(
name="DataAnalyst",
model=model1,
system_prompt="你是一个数据分析师,负责分析数据并提供见解。"
)
visualization_expert = DialogAgent(
name="VisualizationExpert",
model=model2,
system_prompt="你是一个数据可视化专家,负责创建数据可视化图表。"
)
report_writer = DialogAgent(
name="ReportWriter",
model=model3,
system_prompt="你是一个报告撰写者,负责将分析结果和可视化整合为完整报告。"
)
# 并行协作流程
async def parallel_cooperation(data):
# 并行执行任务
task1 = data_analyst.ainvoke(f"请分析以下数据:{data}")
task2 = visualization_expert.ainvoke(f"请为以下数据创建可视化方案:{data}")
# 等待所有任务完成
analysis, visualization = await asyncio.gather(task1, task2)
print(f"数据分析结果: {analysis}")
print(f"可视化方案: {visualization}")
# 生成最终报告
report = await report_writer.ainvoke(
f"请基于以下分析结果和可视化方案生成完整报告:\n"
f"分析结果:{analysis}\n"
f"可视化方案:{visualization}"
)
print(f"最终报告: {report}")
return report
# 测试并行协作
asyncio.run(parallel_cooperation("2023年Q1-Q4的销售额分别为100万、120万、150万、180万"))
9.1.3 层次协作模式
层次协作模式是指智能体按照层次结构组织,上层智能体负责协调下层智能体:
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
from agentscope.environment import Environment
# 创建模型
model_manager = OpenAIModel(model="gpt-3.5-turbo")
model_expert1 = OpenAIModel(model="gpt-3.5-turbo")
model_expert2 = OpenAIModel(model="gpt-3.5-turbo")
model_expert3 = OpenAIModel(model="gpt-3.5-turbo")
# 创建智能体
project_manager = DialogAgent(
name="ProjectManager",
model=model_manager,
system_prompt="你是一个项目管理器,负责协调多个专家完成复杂项目。"
)
expert1 = DialogAgent(
name="Expert1",
model=model_expert1,
system_prompt="你是一个前端开发专家,负责网页前端开发。"
)
expert2 = DialogAgent(
name="Expert2",
model=model_expert2,
system_prompt="你是一个后端开发专家,负责服务器端开发。"
)
expert3 = DialogAgent(
name="Expert3",
model=model_expert3,
system_prompt="你是一个数据库专家,负责数据库设计和优化。"
)
# 创建环境
env = Environment(name="HierarchicalCooperation")
env.add_agent(project_manager)
env.add_agent(expert1)
env.add_agent(expert2)
env.add_agent(expert3)
# 层次协作流程
def hierarchical_cooperation(project):
# 项目管理器分解任务
task_assignment = project_manager(
f"请将以下项目分解为具体任务,并分配给前端、后端和数据库专家:{project}"
)
print(f"任务分配: {task_assignment}")
# 各专家执行任务
frontend_work = expert1(f"请完成以下前端任务:{task_assignment}")
backend_work = expert2(f"请完成以下后端任务:{task_assignment}")
db_work = expert3(f"请完成以下数据库任务:{task_assignment}")
print(f"前端工作: {frontend_work}")
print(f"后端工作: {backend_work}")
print(f"数据库工作: {db_work}")
# 项目管理器整合结果
final_result = project_manager(
f"请整合以下各专家的工作成果:\n"
f"前端工作:{frontend_work}\n"
f"后端工作:{backend_work}\n"
f"数据库工作:{db_work}"
)
print(f"最终结果: {final_result}")
return final_result
# 测试层次协作
hierarchical_cooperation("开发一个电商网站,包括用户注册登录、商品浏览、购物车、订单管理等功能")
9.2 通信机制
AgentScope提供了多种智能体间的通信机制:
9.2.1 直接通信
智能体之间直接发送消息:
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
from agentscope.environment import Environment
# 创建模型
model1 = OpenAIModel(model="gpt-3.5-turbo")
model2 = OpenAIModel(model="gpt-3.5-turbo")
# 创建智能体
alice = DialogAgent(
name="Alice",
model=model1,
system_prompt="你是Alice,一个友好的助手。"
)
bob = DialogAgent(
name="Bob",
model=model2,
system_prompt="你是Bob,一个技术专家。"
)
# 创建环境
env = Environment(name="DirectCommunication")
env.add_agent(alice)
env.add_agent(bob)
# 直接通信
env.send_message(
content="Bob,你好!我是Alice。我有一个技术问题想请教你。",
sender="Alice",
receiver="Bob"
)
# 查看消息
messages = env.get_messages()
for msg in messages:
print(f"{msg.sender} -> {msg.receiver}: {msg.content}")
9.2.2 广播通信
一个智能体向所有其他智能体发送消息:
# 广播通信
env.broadcast_message(
content="大家好!我是新加入的智能体Charlie。",
sender="Charlie"
)
# 查看消息
messages = env.get_messages()
for msg in messages:
print(f"{msg.sender} -> {msg.receiver}: {msg.content}")
9.2.3 组通信
智能体向特定组的智能体发送消息:
# 创建智能体组
env.create_group("developers", ["Alice", "Bob", "Charlie"])
# 组通信
env.send_group_message(
content="开发团队请注意:明天上午10点召开技术会议。",
sender="Manager",
group="developers"
)
# 查看消息
messages = env.get_messages()
for msg in messages:
print(f"{msg.sender} -> {msg.receiver}: {msg.content}")
9.3 任务分配与协调
9.3.1 动态任务分配
根据智能体的能力和当前负载动态分配任务:
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
from agentscope.environment import Environment
# 创建模型
model1 = OpenAIModel(model="gpt-3.5-turbo")
model2 = OpenAIModel(model="gpt-3.5-turbo")
model3 = OpenAIModel(model="gpt-3.5-turbo")
# 创建智能体
agent1 = DialogAgent(
name="Agent1",
model=model1,
system_prompt="你是一个通用助手,擅长处理各种任务。"
)
agent2 = DialogAgent(
name="Agent2",
model=model2,
system_prompt="你是一个技术专家,擅长处理技术相关任务。"
)
agent3 = DialogAgent(
name="Agent3",
model=model3,
system_prompt="你是一个创意专家,擅长处理创意相关任务。"
)
### 2.3.1 动态任务分配
根据智能体的能力和当前负载动态分配任务:
```python
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
from agentscope.environment import Environment
# 创建模型
model1 = OpenAIModel(model="gpt-3.5-turbo")
model2 = OpenAIModel(model="gpt-3.5-turbo")
model3 = OpenAIModel(model="gpt-3.5-turbo")
# 创建智能体
agent1 = DialogAgent(
name="Agent1",
model=model1,
system_prompt="你是一个通用助手,擅长处理各种任务。"
)
agent2 = DialogAgent(
name="Agent2",
model=model2,
system_prompt="你是一个技术专家,擅长处理技术相关任务。"
)
agent3 = DialogAgent(
name="Agent3",
model=model3,
system_prompt="你是一个创意专家,擅长处理创意相关任务。"
)
# 创建环境
env = Environment(name="DynamicTaskAssignment")
env.add_agent(agent1)
env.add_agent(agent2)
env.add_agent(agent3)
# 动态任务分配函数
def dynamic_task_assignment(task):
# 分析任务类型
task_type = analyze_task_type(task)
# 根据任务类型和智能体状态分配任务
if task_type == "technical":
# 技术任务分配给技术专家
return agent2(task)
elif task_type == "creative":
# 创意任务分配给创意专家
return agent3(task)
else:
# 其他任务分配给通用助手
return agent1(task)
# 分析任务类型的简单实现
def analyze_task_type(task):
technical_keywords = ["技术", "代码", "系统", "网络", "软件"]
creative_keywords = ["创意", "设计", "策划", "文案", "艺术"]
task_lower = task.lower()
for keyword in technical_keywords:
if keyword in task_lower:
return "technical"
for keyword in creative_keywords:
if keyword in task_lower:
return "creative"
return "general"
# 测试动态任务分配
print(dynamic_task_assignment("请帮我解决一个Python代码问题"))
print(dynamic_task_assignment("请为我们的产品设计一个创意营销方案"))
print(dynamic_task_assignment("请帮我安排明天的日程"))
9.4 冲突解决策略
在多智能体系统中,冲突是不可避免的,AgentScope提供了多种冲突解决策略:
9.4.1 基于规则的冲突解决
def rule_based_conflict_resolution(agents, conflict):
# 基于预定义规则解决冲突
rules = {
"priority": "任务优先级高的智能体优先",
"expertise": "领域专家智能体优先",
"availability": "当前负载低的智能体优先"
}
# 应用规则解决冲突
if conflict.type == "resource":
# 资源冲突:优先分配给优先级高的任务
return sorted(agents, key=lambda x: x.task_priority, reverse=True)[0]
elif conflict.type == "task":
# 任务冲突:优先分配给领域专家
return get_expert_agent(agents, conflict.task_type)
else:
# 其他冲突:优先分配给当前空闲的智能体
return sorted(agents, key=lambda x: x.current_load)[0]
9.4.2 基于协商的冲突解决
async def negotiation_based_conflict_resolution(agents, conflict):
# 智能体之间通过协商解决冲突
negotiation_results = []
# 每个智能体提出解决方案
for agent in agents:
proposal = await agent.ainvoke(
f"请针对以下冲突提出解决方案:{conflict.description}\n"
f"你的角色:{agent.name}\n"
f"当前状态:{agent.state}\n"
f"请提出一个公平合理的解决方案。"
)
negotiation_results.append((agent, proposal))
# 评估所有提案
best_proposal = evaluate_proposals(negotiation_results, conflict)
return best_proposal
10. 工具调用系统
10.1 工具定义与注册
AgentScope的工具系统允许智能体调用外部工具执行任务:
from agentscope.tools import BaseTool, ToolManager
# 自定义工具类
class WeatherTool(BaseTool):
def __init__(self):
super().__init__(
name="weather_tool",
description="获取指定城市的天气信息",
parameters={
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称"
},
"date": {
"type": "string",
"description": "日期,格式:YYYY-MM-DD,可选"
}
},
"required": ["city"]
}
)
def run(self, city, date=None):
# 模拟获取天气信息
if not date:
date = "今天"
return f"{date} {city}的天气晴朗,温度25℃,微风。"
# 创建工具管理器
tool_manager = ToolManager()
# 注册工具
weather_tool = WeatherTool()
tool_manager.register_tool(weather_tool)
# 查看已注册的工具
print("已注册的工具:", tool_manager.list_tools())
10.2 工具调用机制
智能体调用工具的过程如下:
- 工具发现:智能体发现可用的工具
- 参数构建:智能体构建工具调用参数
- 工具执行:执行工具并获取结果
- 结果处理:处理工具执行结果
from agentscope.agents import ToolAgent
from agentscope.models import OpenAIModel
# 创建模型
model = OpenAIModel(model="gpt-3.5-turbo")
# 创建工具
weather_tool = WeatherTool()
tools = [weather_tool]
# 创建工具智能体
agent = ToolAgent(
name="ToolAgent",
model=model,
tools=tools
)
# 使用智能体调用工具
result = agent("请帮我查询北京今天的天气")
print(result)
result = agent("请帮我查询上海明天的天气")
print(result)
10.3 工具结果处理
智能体需要能够理解和处理工具执行的结果:
def process_tool_result(agent, tool_name, result):
# 处理工具执行结果
if tool_name == "weather_tool":
# 天气工具结果处理
return f"天气信息:{result}"
elif tool_name == "search_tool":
# 搜索工具结果处理
return f"搜索结果:{result[:500]}..."
elif tool_name == "calculator_tool":
# 计算器工具结果处理
return f"计算结果:{result}"
else:
# 默认处理
return f"工具执行结果:{result}"
10.4 自定义工具开发
开发自定义工具的最佳实践:
- 继承BaseTool类:实现run方法
- 定义清晰的参数:使用JSON Schema定义参数
- 提供详细的描述:帮助智能体理解工具功能
- 处理异常情况:确保工具执行的可靠性
- 返回结构化结果:便于智能体处理
class DatabaseTool(BaseTool):
def __init__(self):
super().__init__(
name="database_tool",
description="执行数据库查询",
parameters={
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "SQL查询语句"
}
},
"required": ["query"]
}
)
def run(self, query):
try:
# 模拟数据库查询
if "SELECT" in query.upper():
return "查询结果:[{\"id\": 1, \"name\": \"Alice\"}, {\"id\": 2, \"name\": \"Bob\"}]"
else:
return "操作成功"
except Exception as e:
return f"错误:{str(e)}"
11. 状态管理系统
11.1 状态表示与存储
AgentScope使用多种方式表示和存储智能体状态:
11.1.1 内存状态
class MemoryState:
def __init__(self):
self.short_term_memory = [] # 短期记忆
self.long_term_memory = [] # 长期记忆
self.current_state = {} # 当前状态
def add_memory(self, content, importance=0.5):
# 添加记忆
if importance > 0.7:
self.long_term_memory.append(content)
else:
self.short_term_memory.append(content)
# 限制短期记忆大小
if len(self.short_term_memory) > 100:
self.short_term_memory = self.short_term_memory[-50:]
def get_state(self):
# 获取当前状态
return {
"short_term_memory": self.short_term_memory,
"long_term_memory": self.long_term_memory,
"current_state": self.current_state
}
def update_state(self, new_state):
# 更新状态
self.current_state.update(new_state)
11.1.2 持久化状态
import json
class PersistentState:
def __init__(self, storage_path):
self.storage_path = storage_path
self.state = self.load_state()
def load_state(self):
# 从文件加载状态
try:
with open(self.storage_path, 'r', encoding='utf-8') as f:
return json.load(f)
except FileNotFoundError:
return {}
def save_state(self):
# 保存状态到文件
with open(self.storage_path, 'w', encoding='utf-8') as f:
json.dump(self.state, f, ensure_ascii=False, indent=2)
def update(self, key, value):
# 更新状态
self.state[key] = value
self.save_state()
def get(self, key, default=None):
# 获取状态值
return self.state.get(key, default)
11.2 状态更新机制
状态更新的几种方式:
11.2.1 事件驱动的状态更新
def event_driven_state_update(agent, event):
# 基于事件更新状态
if event.type == "task_completed":
agent.state["completed_tasks"] = agent.state.get("completed_tasks", 0) + 1
agent.state["last_task"] = event.task
elif event.type == "error":
agent.state["error_count"] = agent.state.get("error_count", 0) + 1
agent.state["last_error"] = event.error
elif event.type == "user_interaction":
agent.state["last_interaction"] = event.timestamp
agent.state["interaction_count"] = agent.state.get("interaction_count", 0) + 1
11.2.2 定期状态更新
import time
def periodic_state_update(agent, interval=60):
# 定期更新状态
while True:
agent.state["last_updated"] = time.time()
agent.state["uptime"] = agent.state.get("uptime", 0) + interval
agent.save_state()
time.sleep(interval)
11.3 状态持久化
AgentScope支持多种状态持久化方式:
- 文件存储:将状态保存到本地文件
- 数据库存储:将状态保存到数据库
- 缓存存储:使用Redis等缓存系统存储状态
- 云存储:将状态保存到云存储服务
class StatePersistence:
def __init__(self, storage_type="file", **kwargs):
self.storage_type = storage_type
if storage_type == "file":
self.storage = FileStorage(kwargs.get("path", "./state.json"))
elif storage_type == "redis":
self.storage = RedisStorage(kwargs.get("redis_url"))
elif storage_type == "database":
self.storage = DatabaseStorage(kwargs.get("db_url"))
else:
raise ValueError(f"Unsupported storage type: {storage_type}")
def save(self, agent_id, state):
# 保存状态
self.storage.save(agent_id, state)
def load(self, agent_id):
# 加载状态
return self.storage.load(agent_id)
def delete(self, agent_id):
# 删除状态
self.storage.delete(agent_id)
11.4 状态恢复策略
系统重启或故障后如何恢复状态:
def state_recovery_strategy(agent, persistence):
# 状态恢复策略
try:
# 尝试从持久化存储加载状态
saved_state = persistence.load(agent.id)
if saved_state:
agent.state.update(saved_state)
print(f"Successfully recovered state for agent {agent.id}")
else:
# 初始化新状态
agent.state = {"initialized": True, "start_time": time.time()}
print(f"Initialized new state for agent {agent.id}")
except Exception as e:
# 恢复失败,使用默认状态
agent.state = {"initialized": True, "start_time": time.time(), "recovery_error": str(e)}
print(f"Failed to recover state: {str(e)}. Using default state.")
12. 消息传递机制
12.1 消息类型与格式
AgentScope支持多种消息类型:
| 消息类型 | 描述 | 格式 |
|---|---|---|
| 文本消息 | 普通文本消息 | {"type": "text", "content": "消息内容"} |
| 工具调用 | 调用工具的消息 | {"type": "tool_call", "tool_name": "工具名称", "params": {...}} |
| 工具响应 | 工具执行的响应 | {"type": "tool_response", "tool_name": "工具名称", "result": "执行结果"} |
| 事件消息 | 系统事件通知 | {"type": "event", "event_type": "事件类型", "data": {...}} |
| 状态消息 | 状态更新通知 | {"type": "state", "state": {...}} |
12.2 消息路由与分发
消息路由的实现方式:
class MessageRouter:
def __init__(self):
self.routes = {}
def register_route(self, agent_id, handler):
# 注册消息路由
self.routes[agent_id] = handler
def route_message(self, message):
# 路由消息到目标智能体
receiver = message.get("receiver")
if receiver in self.routes:
# 路由到指定智能体
self.routes[receiver](message)
elif receiver == "broadcast":
# 广播消息
for handler in self.routes.values():
handler(message)
else:
# 未知接收者
print(f"Unknown receiver: {receiver}")
12.3 消息处理流程
消息处理的完整流程:
- 消息接收:接收来自其他智能体或系统的消息
- 消息解析:解析消息内容和类型
- 消息路由:根据接收者路由消息
- 消息处理:根据消息类型处理消息
- 结果返回:返回处理结果
def message_processing_flow(agent, message):
# 消息处理流程
print(f"Agent {agent.name} received message: {message}")
# 解析消息
message_type = message.get("type", "text")
content = message.get("content")
# 根据消息类型处理
if message_type == "text":
# 处理文本消息
return agent.handle_text_message(content)
elif message_type == "tool_call":
# 处理工具调用
return agent.handle_tool_call(message)
elif message_type == "tool_response":
# 处理工具响应
return agent.handle_tool_response(message)
elif message_type == "event":
# 处理事件消息
return agent.handle_event(message)
elif message_type == "state":
# 处理状态消息
return agent.handle_state_message(message)
else:
# 处理未知类型消息
return f"Unknown message type: {message_type}"
12.4 消息安全与可靠性
确保消息传递的安全与可靠:
12.4.1 消息加密
import hashlib
import json
def encrypt_message(message, secret_key):
# 加密消息
message_str = json.dumps(message)
hash_obj = hashlib.sha256((message_str + secret_key).encode())
signature = hash_obj.hexdigest()
return {
"message": message,
"signature": signature,
"timestamp": time.time()
}
def verify_message(encrypted_message, secret_key):
# 验证消息
message = encrypted_message["message"]
signature = encrypted_message["signature"]
message_str = json.dumps(message)
expected_signature = hashlib.sha256((message_str + secret_key).encode()).hexdigest()
return signature == expected_signature
12.4.2 消息重试机制
import time
def reliable_message_delivery(sender, receiver, message, max_retries=3, retry_delay=1):
# 可靠消息传递
retries = 0
while retries < max_retries:
try:
# 发送消息
result = sender.send_message(receiver, message)
if result.success:
return True
except Exception as e:
print(f"Error sending message: {str(e)}")
# 重试
retries += 1
if retries < max_retries:
print(f"Retrying ({retries}/{max_retries})...")
time.sleep(retry_delay)
print(f"Failed to send message after {max_retries} retries")
return False
13. 记忆系统
13.1 短期记忆与长期记忆
AgentScope的记忆系统分为短期记忆和长期记忆:
13.1.1 短期记忆
- 存储内容:最近的交互、临时信息
- 特点:容量小,访问速度快
- 管理策略:FIFO(先进先出)
class ShortTermMemory:
def __init__(self, capacity=100):
self.capacity = capacity
self.memories = []
def add(self, memory):
# 添加短期记忆
self.memories.append({
"content": memory,
"timestamp": time.time()
})
# 保持容量限制
if len(self.memories) > self.capacity:
self.memories.pop(0)
def get_recent(self, n=10):
# 获取最近的n条记忆
return self.memories[-n:]
def clear(self):
# 清空短期记忆
self.memories = []
13.1.2 长期记忆
- 存储内容:重要的信息、经验、知识
- 特点:容量大,持久化存储
- 管理策略:基于重要性和使用频率
class LongTermMemory:
def __init__(self, storage_path=None):
self.memories = []
self.storage_path = storage_path
if storage_path:
self.load()
def add(self, memory, importance=0.5):
# 添加长期记忆
self.memories.append({
"content": memory,
"importance": importance,
"timestamp": time.time(),
"access_count": 0
})
if self.storage_path:
self.save()
def retrieve(self, query, k=5):
# 检索相关记忆
# 简单的基于关键词匹配
relevant = []
for memory in self.memories:
if query.lower() in memory["content"].lower():
relevant.append(memory)
# 按重要性和时间排序
relevant.sort(key=lambda x: (x["importance"], x["timestamp"]), reverse=True)
# 更新访问计数
for memory in relevant[:k]:
memory["access_count"] += 1
if self.storage_path:
self.save()
return [m["content"] for m in relevant[:k]]
def save(self):
# 保存到文件
if self.storage_path:
with open(self.storage_path, 'w', encoding='utf-8') as f:
json.dump(self.memories, f, ensure_ascii=False, indent=2)
def load(self):
# 从文件加载
if self.storage_path and os.path.exists(self.storage_path):
with open(self.storage_path, 'r', encoding='utf-8') as f:
self.memories = json.load(f)
13.2 记忆检索与管理
13.2.1 基于相似度的记忆检索
from sentence_transformers import SentenceTransformer
class SimilarityMemory:
def __init__(self):
self.model = SentenceTransformer('all-MiniLM-L6-v2')
self.memories = []
self.embeddings = []
def add(self, memory):
# 添加记忆并生成嵌入
self.memories.append(memory)
embedding = self.model.encode(memory)
self.embeddings.append(embedding)
def retrieve(self, query, k=5):
# 基于相似度检索记忆
query_embedding = self.model.encode(query)
similarities = cosine_similarity([query_embedding], self.embeddings)[0]
# 获取最相似的记忆
indices = similarities.argsort()[-k:][::-1]
return [self.memories[i] for i in indices]
# 余弦相似度计算
def cosine_similarity(a, b):
import numpy as np
from numpy.linalg import norm
return np.dot(a, b.T) / (norm(a) * norm(b, axis=1))
13.2.2 记忆管理策略
def memory_management_strategy(long_term_memory, max_size=1000):
# 记忆管理策略
if len(long_term_memory.memories) > max_size:
# 按重要性和访问频率排序
sorted_memories = sorted(
long_term_memory.memories,
key=lambda x: (x["importance"] * 0.7 + x["access_count"] * 0.3),
reverse=True
)
# 保留重要的记忆
long_term_memory.memories = sorted_memories[:max_size]
if long_term_memory.storage_path:
long_term_memory.save()
print(f"Memory pruned to {max_size} items")
13.3 记忆更新策略
如何有效地更新智能体的记忆:
13.3.1 增量记忆更新
def incremental_memory_update(agent, new_information):
# 增量更新记忆
# 1. 分析新信息的重要性
importance = assess_importance(new_information)
# 2. 根据重要性决定存储位置
if importance > 0.7:
# 重要信息存入长期记忆
agent.long_term_memory.add(new_information, importance)
else:
# 一般信息存入短期记忆
agent.short_term_memory.add(new_information)
# 3. 更新相关记忆
update_related_memories(agent, new_information)
13.3.2 记忆融合
def memory_integration(agent, new_memory):
# 记忆融合:将新记忆与现有记忆融合
# 1. 查找相关记忆
related_memories = agent.long_term_memory.retrieve(new_memory, k=3)
# 2. 融合相关记忆
if related_memories:
fused_memory = fuse_memories(related_memories + [new_memory])
# 替换旧记忆
for old_memory in related_memories:
agent.long_term_memory.remove(old_memory)
# 添加融合后的记忆
agent.long_term_memory.add(fused_memory, importance=0.8)
else:
# 没有相关记忆,直接添加
agent.long_term_memory.add(new_memory, importance=0.5)
# 融合多个记忆
def fuse_memories(memories):
# 简单的记忆融合实现
return " ".join(memories)
13.4 记忆优化技巧
记忆系统的优化技巧:
- 记忆压缩:压缩不重要的记忆,节省存储空间
- 记忆索引:为记忆建立索引,提高检索速度
- 记忆分层:根据不同类型的信息使用不同的记忆存储策略
- 记忆过滤:过滤掉无关或错误的信息
- 记忆组织:将相关记忆组织成结构化的知识体系
def optimize_memory(agent):
# 优化记忆系统
# 1. 压缩长期记忆
compress_long_term_memory(agent.long_term_memory)
# 2. 建立记忆索引
build_memory_index(agent.long_term_memory)
# 3. 过滤短期记忆
filter_short_term_memory(agent.short_term_memory)
# 4. 组织相关记忆
organize_related_memories(agent.long_term_memory)
14. 模型管理
14.1 多模型支持
AgentScope支持多种大语言模型:
| 模型类型 | 支持的模型 | 特点 |
|---|---|---|
| OpenAI | GPT-3.5, GPT-4, GPT-4o | 通用能力强,响应质量高 |
| 阿里云 | 通义千问系列 | 中文支持好,国内访问快 |
| 百度 | 文心一言系列 | 中文理解能力强 |
| Gemini系列 | 多模态能力强 | |
| Anthropic | Claude系列 | 上下文理解能力强 |
14.2 模型切换与选择
智能地切换和选择模型:
def model_selection_strategy(task, available_models):
# 根据任务选择合适的模型
if "代码" in task or "编程" in task:
# 代码相关任务:选择编程能力强的模型
return select_model_by_capability(available_models, "coding")
elif "中文" in task or "翻译" in task:
# 中文相关任务:选择中文能力强的模型
return select_model_by_capability(available_models, "chinese")
elif "图像" in task or "视频" in task:
# 多模态任务:选择多模态能力强的模型
return select_model_by_capability(available_models, "multimodal")
elif len(task) > 2000:
# 长文本任务:选择上下文窗口大的模型
return select_model_by_context_window(available_models)
else:
# 一般任务:选择性价比高的模型
return select_model_by_cost(available_models)
# 根据能力选择模型
def select_model_by_capability(models, capability):
capability_scores = {
"coding": {"gpt-4": 95, "claude-3": 90, "gemini-pro": 85, "qwen-plus": 80},
"chinese": {"qwen-plus": 95, "ernie-4": 90, "gpt-4": 80, "claude-3": 75},
"multimodal": {"gemini-pro-vision": 95, "gpt-4v": 90, "qwen-vl": 85, "claude-3-opus": 80}
}
scores = capability_scores.get(capability, {})
for model in models:
if model in scores:
return model
return models[0] # 默认返回第一个模型
14.3 模型参数配置
优化模型参数以获得最佳性能:
| 参数 | 描述 | 推荐值 |
|---|---|---|
| temperature | 控制输出的随机性 | 0.7(创意任务)- 0.2(确定性任务) |
| max_tokens | 最大输出 tokens | 根据任务长度设置 |
| top_p | 控制输出的多样性 | 0.95 |
| frequency_penalty | 减少重复内容 | 0.0 |
| presence_penalty | 鼓励新内容 | 0.0 |
def optimize_model_parameters(task_type):
# 根据任务类型优化模型参数
if task_type == "creative":
# 创意任务:更高的随机性
return {
"temperature": 0.9,
"top_p": 0.95,
"frequency_penalty": 0.0,
"presence_penalty": 0.1
}
elif task_type == "technical":
# 技术任务:更低的随机性
return {
"temperature": 0.2,
"top_p": 0.9,
"frequency_penalty": 0.1,
"presence_penalty": 0.0
}
elif task_type == "conversational":
# 对话任务:平衡的参数
return {
"temperature": 0.7,
"top_p": 0.95,
"frequency_penalty": 0.0,
"presence_penalty": 0.0
}
else:
# 默认参数
return {
"temperature": 0.7,
"top_p": 0.95,
"frequency_penalty": 0.0,
"presence_penalty": 0.0
}
14.4 模型性能评估
如何评估模型的性能:
14.4.1 任务型评估
def evaluate_model_performance(model, test_tasks):
# 评估模型在特定任务上的性能
results = {}
for task_type, tasks in test_tasks.items():
correct_count = 0
total_count = len(tasks)
for task in tasks:
response = model(task["prompt"])
if task["evaluation"](response):
correct_count += 1
accuracy = correct_count / total_count
results[task_type] = accuracy
print(f"{task_type}: {accuracy:.2f}")
# 计算总体性能
overall_accuracy = sum(results.values()) / len(results)
results["overall"] = overall_accuracy
print(f"Overall: {overall_accuracy:.2f}")
return results
14.4.2 性能指标评估
def evaluate_model_metrics(model, test_prompts):
# 评估模型的性能指标
metrics = {
"response_times": [],
"token_counts": [],
"success_rate": 0,
"consistency": 0
}
for prompt in test_prompts:
start_time = time.time()
try:
response = model(prompt)
end_time = time.time()
# 计算响应时间
response_time = end_time - start_time
metrics["response_times"].append(response_time)
# 计算token数
token_count = len(response.split()) # 简单估算
metrics["token_counts"].append(token_count)
# 成功计数
metrics["success_rate"] += 1
except Exception as e:
print(f"Error: {str(e)}")
# 计算平均值
metrics["avg_response_time"] = sum(metrics["response_times"]) / len(metrics["response_times"])
metrics["avg_token_count"] = sum(metrics["token_counts"]) / len(metrics["token_counts"])
metrics["success_rate"] /= len(test_prompts)
# 计算一致性(对相同提示的响应相似度)
if len(test_prompts) > 0:
prompt = test_prompts[0]
responses = [model(prompt) for _ in range(3)]
metrics["consistency"] = calculate_consistency(responses)
return metrics
# 计算响应一致性
def calculate_consistency(responses):
# 简单的一致性计算:响应长度的变异系数
lengths = [len(r) for r in responses]
mean_length = sum(lengths) / len(lengths)
std_dev = (sum((l - mean_length)**2 for l in lengths) / len(lengths))**0.5
return 1 - (std_dev / mean_length) if mean_length > 0 else 0
15. 智能客服系统
2.1 系统架构设计
一个完整的智能客服系统通常包含以下组件:
- 用户接口层:负责接收用户输入,展示系统响应
- 智能体层:包含多个专业智能体,处理不同类型的问题
- 知识库层:存储产品信息、常见问题等知识
- 工具层:提供查询、操作等功能
- 集成层:与企业现有系统集成
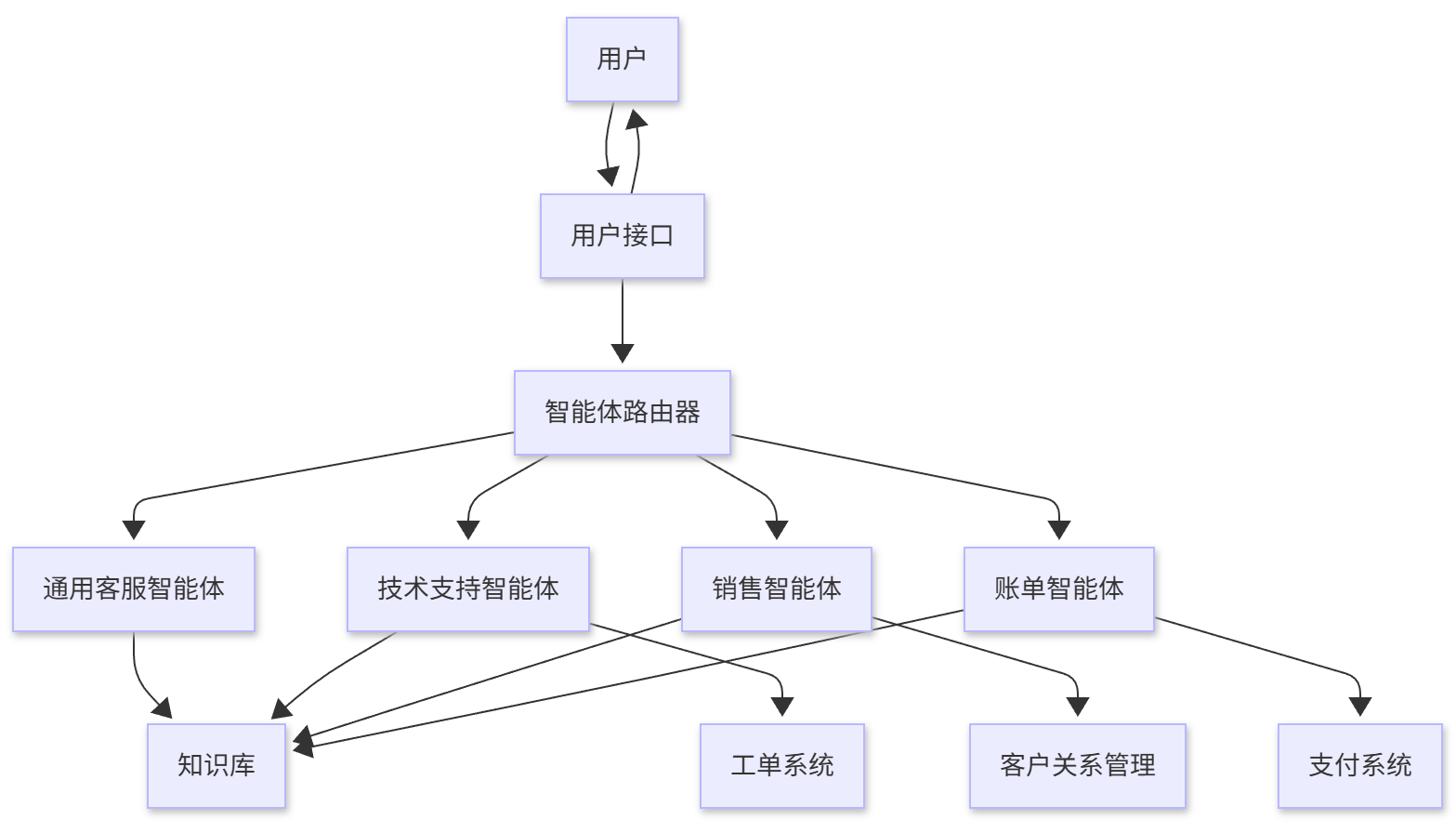
15.2 核心功能实现
15.2.1 智能体路由器
智能体路由器负责根据用户问题的类型,将请求路由到合适的专业智能体:
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
class AgentRouter:
def __init__(self):
# 创建模型
model = OpenAIModel(model="gpt-3.5-turbo")
# 创建专业智能体
self.agents = {
"general": DialogAgent(
name="GeneralAgent",
model=model,
system_prompt="你是一个通用客服智能体,负责回答一般性问题。"
),
"technical": DialogAgent(
name="TechnicalAgent",
model=model,
system_prompt="你是一个技术支持智能体,负责解决技术问题。"
),
"sales": DialogAgent(
name="SalesAgent",
model=model,
system_prompt="你是一个销售智能体,负责产品销售相关问题。"
),
"billing": DialogAgent(
name="BillingAgent",
model=model,
system_prompt="你是一个账单智能体,负责处理账单和支付问题。"
)
}
def route(self, user_input):
# 分析用户输入,确定需要的智能体类型
agent_type = self._analyze_input(user_input)
# 路由到对应的智能体
if agent_type in self.agents:
return agent_type, self.agents[agent_type](user_input)
else:
# 默认使用通用智能体
return "general", self.agents["general"](user_input)
def _analyze_input(self, user_input):
# 简单的输入分析逻辑
technical_keywords = ["问题", "错误", "故障", "技术", "设置", "配置"]
sales_keywords = ["价格", "购买", "销售", "优惠", "折扣", "产品"]
billing_keywords = ["账单", "支付", "费用", "发票", "退款", "收费"]
user_input_lower = user_input.lower()
for keyword in technical_keywords:
if keyword in user_input_lower:
return "technical"
for keyword in sales_keywords:
if keyword in user_input_lower:
return "sales"
for keyword in billing_keywords:
if keyword in user_input_lower:
return "billing"
return "general"
15.2.2 知识库集成
智能客服系统需要与知识库集成,以获取最新的产品信息和常见问题答案:
from agentscope.tools import BaseTool
class KnowledgeBaseTool(BaseTool):
def __init__(self, knowledge_base):
super().__init__(
name="knowledge_base_tool",
description="查询知识库,获取产品信息和常见问题答案",
parameters={
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "查询关键词"
}
},
"required": ["query"]
}
)
self.knowledge_base = knowledge_base
def run(self, query):
# 从知识库查询信息
results = self.knowledge_base.search(query)
if results:
return "\n".join(results)
else:
return "知识库中未找到相关信息"
# 知识库实现
class KnowledgeBase:
def __init__(self):
# 模拟知识库数据
self.data = {
"产品": ["我们的产品包括智能音箱、智能灯具和智能门锁", "我们的最新产品是智能摄像头,具有人脸识别功能"],
"价格": ["智能音箱价格为299元", "智能灯具价格为199元", "智能门锁价格为899元", "智能摄像头价格为599元"],
"保修": ["我们的产品提供1年保修服务", "保修范围包括产品本身的质量问题,不包括人为损坏"],
"安装": ["智能音箱和智能灯具可以自行安装,智能门锁建议请专业人员安装"],
"连接": ["我们的产品支持WiFi和蓝牙连接", "连接步骤:1. 下载APP 2. 打开设备 3. 按照APP提示操作"]
}
def search(self, query):
# 简单的关键词匹配
results = []
for keyword, information in self.data.items():
if keyword in query:
results.extend(information)
return results
15.2.3 工单系统集成
对于复杂的技术问题,智能客服系统需要能够创建工单:
class TicketTool(BaseTool):
def __init__(self):
super().__init__(
name="ticket_tool",
description="创建技术支持工单",
parameters={
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "工单标题"
},
"description": {
"type": "string",
"description": "问题描述"
},
"priority": {
"type": "string",
"description": "优先级:low, medium, high"
}
},
"required": ["title", "description"]
}
)
self.tickets = []
def run(self, title, description, priority="medium"):
# 创建工单
ticket_id = len(self.tickets) + 1
ticket = {
"id": ticket_id,
"title": title,
"description": description,
"priority": priority,
"status": "open",
"created_at": "2023-07-01 10:00:00"
}
self.tickets.append(ticket)
return f"工单创建成功!工单ID:{ticket_id},状态:{ticket['status']}"
15.3 多智能体协作策略
智能客服系统中的多个智能体需要协作处理复杂问题:
from agentscope.agents import ToolAgent
from agentscope.models import OpenAIModel
from agentscope.environment import Environment
# 创建模型
model = OpenAIModel(model="gpt-3.5-turbo")
# 创建知识库和工具
knowledge_base = KnowledgeBase()
knowledge_tool = KnowledgeBaseTool(knowledge_base)
ticket_tool = TicketTool()
# 创建智能体
router_agent = AgentRouter()
technical_agent = ToolAgent(
name="TechnicalAgent",
model=model,
tools=[knowledge_tool, ticket_tool],
system_prompt="你是一个技术支持智能体,负责解决技术问题,必要时创建工单。"
)
sales_agent = ToolAgent(
name="SalesAgent",
model=model,
tools=[knowledge_tool],
system_prompt="你是一个销售智能体,负责产品销售相关问题。"
)
billing_agent = ToolAgent(
name="BillingAgent",
model=model,
tools=[knowledge_tool],
system_prompt="你是一个账单智能体,负责处理账单和支付问题。"
)
# 创建环境
env = Environment(name="CustomerServiceSystem")
env.add_agent(technical_agent)
env.add_agent(sales_agent)
env.add_agent(billing_agent)
# 协作处理问题
def handle_customer_query(query):
# 1. 路由到合适的智能体
agent_type, initial_response = router_agent.route(query)
# 2. 如果需要,其他智能体提供辅助
if agent_type == "technical":
# 技术问题可能需要销售智能体提供产品信息
sales_input = f"用户问了关于技术问题:{query},请提供相关产品信息"
sales_response = sales_agent(sales_input)
return f"技术支持:{initial_response}\n产品信息:{sales_response}"
elif agent_type == "sales":
# 销售问题可能需要技术智能体提供技术细节
technical_input = f"用户问了关于销售问题:{query},请提供相关技术细节"
technical_response = technical_agent(technical_input)
return f"销售支持:{initial_response}\n技术细节:{technical_response}"
else:
return initial_response
# 测试智能客服系统
print(handle_customer_query("智能音箱的价格是多少?"))
print(handle_customer_query("我的智能门锁连接不上WiFi,怎么办?"))
print(handle_customer_query("我想退款,怎么操作?"))
16. 自动化工作流系统
16.1 工作流定义与编排
自动化工作流系统允许用户定义和编排复杂的工作流程,由智能体自动执行:
class Workflow:
def __init__(self, name):
self.name = name
self.steps = []
def add_step(self, step):
"""添加工作流步骤"""
self.steps.append(step)
def execute(self, context):
"""执行工作流"""
result = {}
for step in self.steps:
step_result = step.execute(context)
result[step.name] = step_result
context.update(step_result)
return result
class WorkflowStep:
def __init__(self, name, agent, input_template, output_mapping):
self.name = name
self.agent = agent
self.input_template = input_template
self.output_mapping = output_mapping
def execute(self, context):
"""执行工作流步骤"""
# 根据模板生成输入
input_data = self.input_template.format(**context)
# 执行智能体
agent_output = self.agent(input_data)
# 映射输出
output = {}
for key, pattern in self.output_mapping.items():
# 简单的输出提取(实际应用中可能需要更复杂的NLP处理)
output[key] = agent_output
return output
16.2 智能体任务分配
根据工作流步骤的特点,智能体任务分配系统会选择合适的智能体执行任务:
class TaskAllocator:
def __init__(self, agents):
self.agents = agents
def allocate(self, task_type, task_description):
"""根据任务类型分配智能体"""
# 分析任务类型
if "research" in task_type.lower():
return self.agents.get("research", self.agents["general"])
elif "write" in task_type.lower():
return self.agents.get("writer", self.agents["general"])
elif "analyze" in task_type.lower():
return self.agents.get("analyst", self.agents["general"])
elif "code" in task_type.lower():
return self.agents.get("developer", self.agents["general"])
else:
return self.agents["general"]
16.3 状态管理与监控
工作流系统需要管理和监控工作流的执行状态:
class WorkflowMonitor:
def __init__(self):
self.workflows = {}
def register_workflow(self, workflow):
"""注册工作流"""
self.workflows[workflow.name] = {
"workflow": workflow,
"status": "registered",
"executions": []
}
def start_workflow(self, workflow_name, context):
"""启动工作流"""
if workflow_name not in self.workflows:
return {"error": "Workflow not found"}
# 更新状态
self.workflows[workflow_name]["status"] = "running"
# 执行工作流
try:
result = self.workflows[workflow_name]["workflow"].execute(context)
self.workflows[workflow_name]["status"] = "completed"
self.workflows[workflow_name]["executions"].append({
"timestamp": time.time(),
"context": context,
"result": result,
"status": "success"
})
return result
except Exception as e:
self.workflows[workflow_name]["status"] = "failed"
self.workflows[workflow_name]["executions"].append({
"timestamp": time.time(),
"context": context,
"error": str(e),
"status": "failed"
})
return {"error": str(e)}
def get_status(self, workflow_name):
"""获取工作流状态"""
if workflow_name not in self.workflows:
return {"error": "Workflow not found"}
return {
"status": self.workflows[workflow_name]["status"],
"executions": self.workflows[workflow_name]["executions"]
}
16.4 异常处理机制
工作流执行过程中的异常处理:
class ExceptionHandler:
def __init__(self):
self.handlers = {
"timeout": self.handle_timeout,
"api_error": self.handle_api_error,
"validation_error": self.handle_validation_error
}
def handle(self, exception_type, exception, context):
"""处理异常"""
handler = self.handlers.get(exception_type, self.handle_generic)
return handler(exception, context)
def handle_timeout(self, exception, context):
"""处理超时异常"""
return {"error": "操作超时", "retry": True, "retry_delay": 5}
def handle_api_error(self, exception, context):
"""处理API错误"""
return {"error": "API错误", "retry": True, "retry_delay": 10}
def handle_validation_error(self, exception, context):
"""处理验证错误"""
return {"error": "输入验证错误", "retry": False, "fix_suggestion": "检查输入数据"}
def handle_generic(self, exception, context):
"""处理通用异常"""
return {"error": str(exception), "retry": False}
16.5 实际应用案例
16.5.1 市场调研工作流
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
# 创建模型
model = OpenAIModel(model="gpt-3.5-turbo")
# 创建智能体
research_agent = DialogAgent(
name="ResearchAgent",
model=model,
system_prompt="你是一个市场调研智能体,负责收集和分析市场信息。"
)
analyst_agent = DialogAgent(
name="AnalystAgent",
model=model,
system_prompt="你是一个数据分析智能体,负责分析市场数据并提供见解。"
)
writer_agent = DialogAgent(
name="WriterAgent",
model=model,
system_prompt="你是一个报告撰写智能体,负责根据分析结果撰写市场调研报告。"
)
# 创建工作流步骤
research_step = WorkflowStep(
name="research",
agent=research_agent,
input_template="请调研{topic}的市场情况,包括主要玩家、市场规模和增长趋势",
output_mapping={"research_result": "调研结果"}
)
analysis_step = WorkflowStep(
name="analysis",
agent=analyst_agent,
input_template="请分析以下市场调研结果:{research_result},并提供关键见解",
output_mapping={"analysis_result": "分析结果"}
)
writing_step = WorkflowStep(
name="writing",
agent=writer_agent,
input_template="请根据以下分析结果撰写一份市场调研报告:{analysis_result}",
output_mapping={"report": "调研报告"}
)
# 创建工作流
market_research_workflow = Workflow("MarketResearch")
market_research_workflow.add_step(research_step)
market_research_workflow.add_step(analysis_step)
market_research_workflow.add_step(writing_step)
# 执行工作流
context = {"topic": "人工智能在医疗领域的应用"}
result = market_research_workflow.execute(context)
print("调研报告:", result["report"])
16.5.2 内容创作工作流
# 创建内容创作工作流
content_workflow = Workflow("ContentCreation")
# 创建步骤
topic_generation_step = WorkflowStep(
name="topic_generation",
agent=research_agent,
input_template="请为{domain}领域生成5个内容主题",
output_mapping={"topics": "主题列表"}
)
content_creation_step = WorkflowStep(
name="content_creation",
agent=writer_agent,
input_template="请为主题 '{topic}' 创建一篇详细的内容",
output_mapping={"content": "创建的内容"}
)
# 添加步骤
content_workflow.add_step(topic_generation_step)
content_workflow.add_step(content_creation_step)
# 执行工作流
context = {"domain": "机器学习", "topic": "深度学习基础"}
result = content_workflow.execute(context)
print("生成的内容:", result["content"])
17. 多模态交互系统
17.1 多模态能力集成
多模态交互系统需要集成多种模态的处理能力:
from agentscope.agents import ToolAgent
from agentscope.models import OpenAIModel
class ImageAnalysisTool(BaseTool):
def __init__(self):
super().__init__(
name="image_analysis_tool",
description="分析图片内容",
parameters={
"type": "object",
"properties": {
"image_url": {
"type": "string",
"description": "图片URL"
}
},
"required": ["image_url"]
}
)
def run(self, image_url):
# 模拟图片分析
return f"图片分析结果:这是一张关于{image_url.split('/')[-1].split('.')[0]}的图片"
class SpeechRecognitionTool(BaseTool):
def __init__(self):
super().__init__(
name="speech_recognition_tool",
description="识别语音内容",
parameters={
"type": "object",
"properties": {
"audio_url": {
"type": "string",
"description": "音频URL"
}
},
"required": ["audio_url"]
}
)
def run(self, audio_url):
# 模拟语音识别
return f"语音识别结果:这是一段关于{audio_url.split('/')[-1].split('.')[0]}的音频"
# 创建多模态智能体
model = OpenAIModel(model="gpt-4o") # 假设使用支持多模态的模型
image_tool = ImageAnalysisTool()
speech_tool = SpeechRecognitionTool()
multimodal_agent = ToolAgent(
name="MultimodalAgent",
model=model,
tools=[image_tool, speech_tool],
system_prompt="你是一个多模态智能体,能够理解和处理文本、图片和语音等多种模态的信息。"
)
17.2 跨模态信息处理
多模态智能体需要能够处理和整合来自不同模态的信息:
class CrossModalProcessor:
def __init__(self, multimodal_agent):
self.agent = multimodal_agent
def process(self, inputs):
"""处理多模态输入"""
# 构建输入
input_text = "请分析以下信息:\n"
for input_type, input_data in inputs.items():
if input_type == "text":
input_text += f"文本:{input_data}\n"
elif input_type == "image":
# 使用图片分析工具
image_result = self.agent.tools[0].run(input_data)
input_text += f"图片分析:{image_result}\n"
elif input_type == "audio":
# 使用语音识别工具
audio_result = self.agent.tools[1].run(input_data)
input_text += f"语音识别:{audio_result}\n"
# 执行智能体
return self.agent(input_text)
17.3 智能体协同工作
多个专业智能体协同处理多模态信息:
from agentscope.agents import DialogAgent
from agentscope.models import OpenAIModel
from agentscope.environment import Environment
# 创建模型
model = OpenAIModel(model="gpt-4o")
# 创建智能体
image_agent = DialogAgent(
name="ImageAgent",
model=model,
system_prompt="你是一个图像理解专家,擅长分析图片内容。"
)
speech_agent = DialogAgent(
name="SpeechAgent",
model=model,
system_prompt="你是一个语音理解专家,擅长识别和分析语音内容。"
)
text_agent = DialogAgent(
name="TextAgent",
model=model,
system_prompt="你是一个文本理解专家,擅长分析文本内容。"
)
integrator_agent = DialogAgent(
name="IntegratorAgent",
model=model,
system_prompt="你是一个多模态信息整合专家,擅长整合来自不同模态的信息。"
)
# 创建环境
env = Environment(name="MultimodalSystem")
env.add_agent(image_agent)
env.add_agent(speech_agent)
env.add_agent(text_agent)
env.add_agent(integrator_agent)
# 协同处理多模态信息
def process_multimodal_inputs(text_input, image_url=None, audio_url=None):
# 1. 各专业智能体处理各自模态的信息
text_result = text_agent(text_input)
image_result = ""
if image_url:
image_result = image_agent(f"请分析这张图片:{image_url}")
audio_result = ""
if audio_url:
audio_result = speech_agent(f"请分析这段音频:{audio_url}")
# 2. 整合智能体整合信息
integrator_input = f"请整合以下信息:\n文本分析:{text_result}\n"
if image_result:
integrator_input += f"图片分析:{image_result}\n"
if audio_result:
integrator_input += f"音频分析:{audio_result}\n"
final_result = integrator_agent(integrator_input)
return final_result
# 测试多模态处理
result = process_multimodal_inputs(
"这是什么产品?",
image_url="https://example.com/smartphone.jpg",
audio_url="https://example.com/product_demo.mp3"
)
print("多模态分析结果:", result)
17.4 用户体验优化
多模态交互系统的用户体验优化:
- 响应速度:优化模型调用和处理流程,减少响应时间
- 准确性:提高多模态信息处理的准确性
- 一致性:确保不同模态处理结果的一致性
- 自然交互:支持更自然的多模态交互方式
- 个性化:根据用户偏好调整多模态处理策略
17.5 实现方案详解
多模态交互系统的完整实现方案:
class MultimodalInteractionSystem:
def __init__(self):
# 初始化各组件
self.cross_modal_processor = CrossModalProcessor(multimodal_agent)
self.environment = Environment(name="MultimodalSystem")
self.setup_agents()
def setup_agents(self):
"""设置智能体"""
# 创建模型
model = OpenAIModel(model="gpt-4o")
# 创建智能体
self.image_agent = DialogAgent(
name="ImageAgent",
model=model,
system_prompt="你是一个图像理解专家。"
)
self.speech_agent = DialogAgent(
name="SpeechAgent",
model=model,
system_prompt="你是一个语音理解专家。"
)
self.text_agent = DialogAgent(
name="TextAgent",
model=model,
system_prompt="你是一个文本理解专家。"
)
self.integrator_agent = DialogAgent(
name="IntegratorAgent",
model=model,
system_prompt="你是一个多模态信息整合专家。"
)
# 添加到环境
self.environment.add_agent(self.image_agent)
self.environment.add_agent(self.speech_agent)
self.environment.add_agent(self.text_agent)
self.environment.add_agent(self.integrator_agent)
def process_input(self, inputs):
"""处理多模态输入"""
# 处理不同类型的输入
if "text" in inputs:
text_input = inputs["text"]
else:
text_input = "请分析提供的信息"
image_url = inputs.get("image")
audio_url = inputs.get("audio")
# 调用多模态处理
return process_multimodal_inputs(text_input, image_url, audio_url)
# 测试系统
system = MultimodalInteractionSystem()
result = system.process_input({
"text": "这是什么产品?",
"image": "https://example.com/smartphone.jpg"
})
print("处理结果:", result)
18. 知识图谱与智能体结合
18.1 知识图谱构建与管理
知识图谱是智能体系统的重要知识来源:
class KnowledgeGraph:
def __init__(self):
self.nodes = {}
self.edges = {}
def add_node(self, node_id, node_type, properties):
"""添加节点"""
self.nodes[node_id] = {
"type": node_type,
"properties": properties
}
def add_edge(self, source_id, target_id, relationship_type, properties=None):
"""添加边"""
if source_id not in self.edges:
self.edges[source_id] = {}
self.edges[source_id][target_id] = {
"type": relationship_type,
"properties": properties or {}
}
def search(self, query):
"""搜索知识图谱"""
results = []
# 简单的关键词搜索(实际应用中可能需要更复杂的查询语言)
for node_id, node_data in self.nodes.items():
for key, value in node_data["properties"].items():
if query.lower() in str(value).lower():
results.append({
"node_id": node_id,
"node_type": node_data["type"],
"properties": node_data["properties"]
})
return results
def get_related_nodes(self, node_id, relationship_type=None):
"""获取相关节点"""
results = []
if node_id in self.edges:
for target_id, edge_data in self.edges[node_id].items():
if not relationship_type or edge_data["type"] == relationship_type:
if target_id in self.nodes:
results.append({
"node_id": target_id,
"node_type": self.nodes[target_id]["type"],
"relationship": edge_data["type"],
"properties": self.nodes[target_id]["properties"]
})
return results
18.2 智能体知识获取与利用
智能体如何从知识图谱中获取和利用知识:
class KnowledgeAgent:
def __init__(self, model, knowledge_graph):
self.model = model
self.knowledge_graph = knowledge_graph
def query_knowledge(self, query):
"""查询知识"""
# 从知识图谱搜索
search_results = self.knowledge_graph.search(query)
if search_results:
# 整合搜索结果
knowledge_text = "根据知识图谱,找到以下相关信息:\n"
for result in search_results:
knowledge_text += f"- {result['node_type']}: {result['properties'].get('name', result['node_id'])} - {result['properties'].get('description', '')}\n"
# 相关节点
if search_results:
related_nodes = self.knowledge_graph.get_related_nodes(search_results[0]['node_id'])
if related_nodes:
knowledge_text += "\n相关信息:\n"
for node in related_nodes[:3]: # 限制数量
knowledge_text += f"- {node['relationship']}: {node['properties'].get('name', node['node_id'])} - {node['properties'].get('description', '')}\n"
return knowledge_text
else:
return "知识图谱中未找到相关信息"
def answer_question(self, question):
"""回答问题"""
# 获取知识
knowledge = self.query_knowledge(question)
# 生成答案
prompt = f"基于以下知识回答问题:\n{knowledge}\n\n问题:{question}\n\n答案:"
return self.model(prompt)
18.3 问答与推理能力
结合知识图谱的智能体具有更强的问答和推理能力:
class ReasoningAgent:
def __init__(self, model, knowledge_agent):
self.model = model
self.knowledge_agent = knowledge_agent
def reason(self, question, context=None):
"""基于知识进行推理"""
# 获取相关知识
knowledge = self.knowledge_agent.query_knowledge(question)
# 构建推理 prompt
prompt = f"请基于以下知识回答问题,并详细说明推理过程:\n"
prompt += f"知识:{knowledge}\n"
if context:
prompt += f"上下文:{context}\n"
prompt += f"问题:{question}\n\n推理过程:"
# 生成推理
reasoning = self.model(prompt)
# 提取答案
answer_prompt = f"基于以下推理过程,提供一个简洁的答案:\n{reasoning}\n\n答案:"
answer = self.model(answer_prompt)
return {
"question": question,
"reasoning": reasoning,
"answer": answer
}
18.4 实际应用案例
18.4.1 医疗知识问答系统
from agentscope.models import OpenAIModel
# 创建模型
model = OpenAIModel(model="gpt-4")
# 创建知识图谱
medical_kg = KnowledgeGraph()
# 添加医疗知识
medical_kg.add_node("disease1", "Disease", {
"name": "高血压",
"description": "高血压是一种常见的慢性疾病,特征是血压持续升高。",
"symptoms": ["头痛", "头晕", "视力模糊", "心悸"],
"causes": ["遗传因素", "生活方式", "饮食不当", "缺乏运动"],
"treatments": ["药物治疗", "饮食调整", "运动", "减轻压力"]
})
medical_kg.add_node("medicine1", "Medicine", {
"name": "降压药",
"description": "用于降低血压的药物",
"types": ["ACE抑制剂", "β受体阻滞剂", "钙通道阻滞剂", "利尿剂"]
})
medical_kg.add_edge("disease1", "medicine1", "treated_by", {
"effectiveness": "高",
"side_effects": "可能引起头晕、疲劳"
})
# 创建智能体
knowledge_agent = KnowledgeAgent(model, medical_kg)
reasoning_agent = ReasoningAgent(model, knowledge_agent)
# 测试医疗知识问答
result = reasoning_agent.reason("高血压的治疗方法有哪些?")
print("问题:", result["question"])
print("推理过程:", result["reasoning"])
print("答案:", result["answer"])
result = reasoning_agent.reason("降压药可以治疗什么疾病?")
print("问题:", result["question"])
print("推理过程:", result["reasoning"])
print("答案:", result["answer"])
18.4.2 产品推荐系统
# 创建产品知识图谱
product_kg = KnowledgeGraph()
# 添加产品知识
product_kg.add_node("product1", "Product", {
"name": "智能手表",
"description": "一款具有健康监测功能的智能手表",
"price": "1999元",
"features": ["心率监测", "睡眠监测", "运动追踪", "智能通知"]
})
product_kg.add_node("brand1", "Brand", {
"name": "TechWatch",
"description": "知名智能穿戴设备品牌",
"country": "中国"
})
product_kg.add_node("category1", "Category", {
"name": "智能穿戴",
"description": "可穿戴的智能设备"
})
product_kg.add_edge("product1", "brand1", "produced_by")
product_kg.add_edge("product1", "category1", "belongs_to")
# 创建智能体
product_knowledge_agent = KnowledgeAgent(model, product_kg)
product_recommendation_agent = ReasoningAgent(model, product_knowledge_agent)
# 测试产品推荐
result = product_recommendation_agent.reason("推荐一款具有健康监测功能的智能设备")
print("问题:", result["question"])
print("推理过程:", result["reasoning"])
print("答案:", result["answer"])
19. 大规模智能体系统
19.1 系统架构设计
大规模智能体系统需要更复杂的架构设计:
- 分层架构:前端层、API层、智能体层、服务层、数据层
- 微服务设计:将不同功能拆分为独立的微服务
- 消息总线:使用消息总线实现组件间通信
- 负载均衡:在多个智能体实例间分配负载
- 容错设计:处理智能体故障和服务不可用的情况
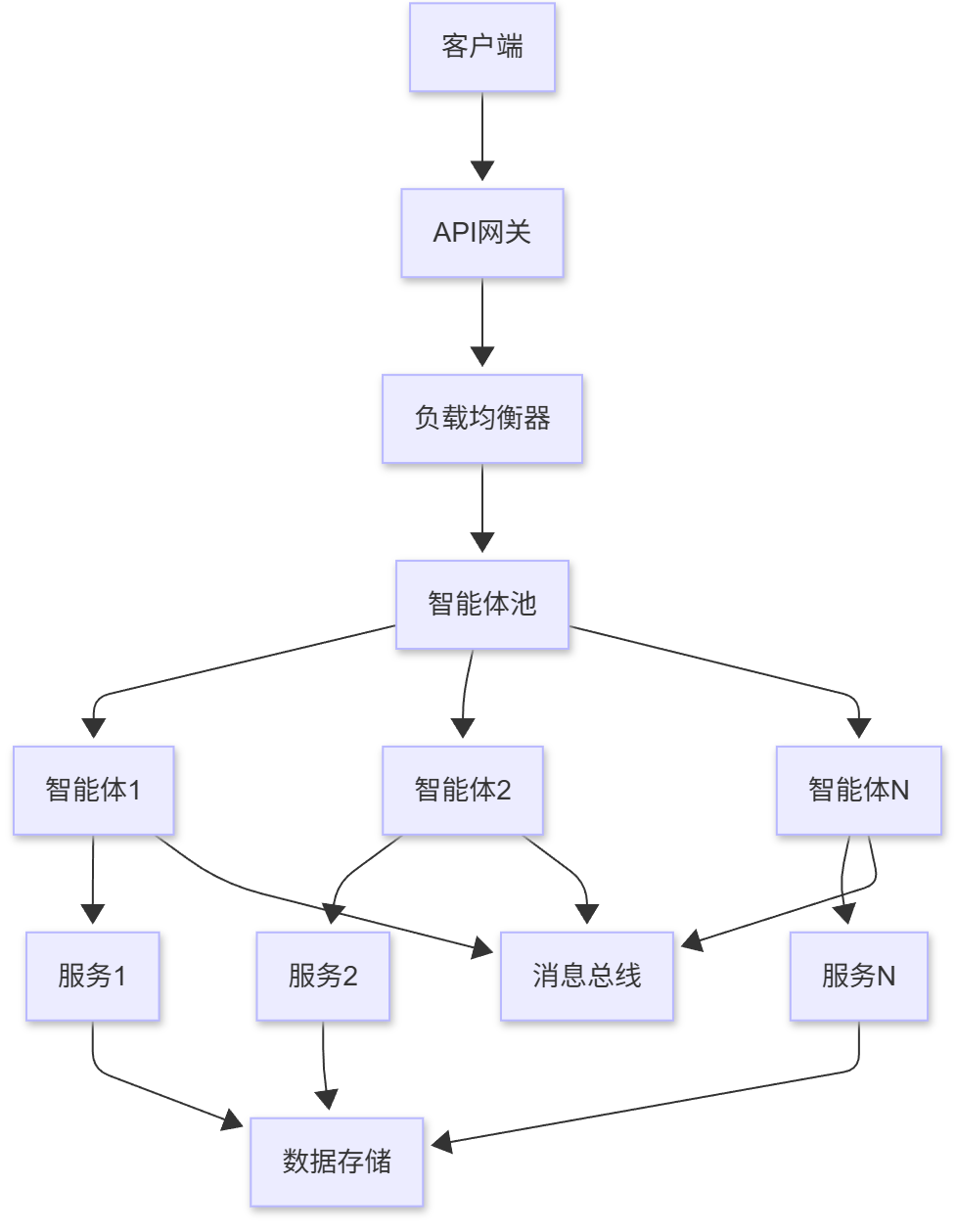
19.2 负载均衡与容错
大规模智能体系统的负载均衡和容错机制:
class AgentLoadBalancer:
def __init__(self, agents):
self.agents = agents
self.current_index = 0
self.health_status = {agent.id: True for agent in agents}
def get_agent(self):
"""获取可用的智能体"""
# 轮询选择健康的智能体
for _ in range(len(self.agents)):
agent = self.agents[self.current_index]
self.current_index = (self.current_index + 1) % len(self.agents)
if self.health_status[agent.id]:
return agent
# 没有健康的智能体
raise Exception("No healthy agents available")
def update_health_status(self, agent_id, status):
"""更新智能体健康状态"""
if agent_id in self.health_status:
self.health_status[agent_id] = status
def check_health(self):
"""检查所有智能体的健康状态"""
for agent in self.agents:
try:
# 简单的健康检查
response = agent("健康检查")
self.update_health_status(agent.id, True)
except Exception:
self.update_health_status(agent.id, False)
19.3 性能优化策略
大规模智能体系统的性能优化策略:
- 缓存策略:缓存常见请求的响应
- 批量处理:批量处理相似请求
- 异步处理:使用异步API提高并发能力
- 资源分配:根据任务类型分配适当的资源
- 自动扩缩容:根据负载自动调整智能体数量
class PerformanceOptimizer:
def __init__(self, cache_size=1000):
self.cache = {}
self.cache_size = cache_size
self.hit_count = 0
self.miss_count = 0
def get_from_cache(self, key):
"""从缓存获取"""
if key in self.cache:
self.hit_count += 1
return self.cache[key]
else:
self.miss_count += 1
return None
def add_to_cache(self, key, value):
"""添加到缓存"""
if len(self.cache) >= self.cache_size:
# 简单的LRU缓存淘汰
oldest_key = next(iter(self.cache))
del self.cache[oldest_key]
self.cache[key] = value
def get_stats(self):
"""获取缓存统计信息"""
total = self.hit_count + self.miss_count
hit_rate = self.hit_count / total if total > 0 else 0
return {
"hit_count": self.hit_count,
"miss_count": self.miss_count,
"hit_rate": hit_rate,
"cache_size": len(self.cache)
}
19.4 部署与运维
大规模智能体系统的部署与运维:
- 容器化部署:使用Docker容器化智能体服务
- 编排系统:使用Kubernetes编排容器
- CI/CD流程:自动化部署和测试
- 监控系统:监控智能体性能和健康状态
- 日志管理:集中管理和分析日志
- 配置管理:集中管理配置
# docker-compose.yml 示例
version: '3'
services:
agent-service:
build: .
ports:
- "8000:8000"
environment:
- MODEL_API_KEY=${MODEL_API_KEY}
- CACHE_SIZE=1000
deploy:
replicas: 3
depends_on:
- redis
- mongodb
redis:
image: redis:latest
ports:
- "6379:6379"
mongodb:
image: mongo:latest
ports:
- "27017:27017"
volumes:
- mongo_data:/data/db
volumes:
mongo_data:
20. 性能瓶颈分析
20.1 代码级优化策略
20.1.1 异步编程优化
优化方案:使用Python的asyncio库实现异步编程,提高I/O密集型操作的性能。
示例代码:
import asyncio
from agentscope import Agent, Environment
class AsyncAgent(Agent):
async def async_think(self, message):
# 异步思考逻辑
await asyncio.sleep(0.1) # 模拟异步操作
return f"Processed: {message}"
def think(self, message):
# 同步接口调用异步方法
return asyncio.run(self.async_think(message))
# 使用异步Agent
async def main():
agent = AsyncAgent(name="async_agent")
env = Environment()
# 并发处理多个任务
tasks = [agent.think(f"Task {i}") for i in range(10)]
results = await asyncio.gather(*tasks)
print(results)
if __name__ == "__main__":
asyncio.run(main())
20.1.2 缓存机制优化
优化方案:实现多级缓存策略,减少重复计算和I/O操作。
示例代码:
from agentscope import Agent
from functools import lru_cache
import time
class CachedAgent(Agent):
def __init__(self, name):
super().__init__(name)
self.cache = {}
@lru_cache(maxsize=1000)
def cached_calculation(self, input_data):
# 模拟耗时计算
time.sleep(1)
return f"Result for {input_data}"
def think(self, message):
# 检查缓存
if message in self.cache:
return f"Cached: {self.cache[message]}"
# 计算结果
result = self.cached_calculation(message)
self.cache[message] = result
return result
2.0.1.3 批处理优化
优化方案:将多个小任务合并为批处理,减少往返开销。
示例代码:
from agentscope import Agent
import time
class BatchAgent(Agent):
def __init__(self, name):
super().__init__(name)
self.task_queue = []
self.batch_size = 5
self.batch_interval = 0.5
self.last_batch_time = time.time()
def think(self, message):
self.task_queue.append(message)
current_time = time.time()
# 检查是否达到批处理条件
if len(self.task_queue) >= self.batch_size or \
current_time - self.last_batch_time >= self.batch_interval:
results = self.process_batch()
return results.get(message, "No result")
# 等待批处理
time.sleep(0.1)
return self.think(message)
def process_batch(self):
tasks = self.task_queue.copy()
self.task_queue.clear()
self.last_batch_time = time.time()
# 批量处理任务
results = {}
for task in tasks:
results[task] = f"Processed: {task}"
print(f"Batch processed {len(tasks)} tasks")
return results
20.1..4 内存管理优化
优化方案:实现内存使用监控和优化,避免内存泄漏。
示例代码:
from agentscope import Agent
import gc
import psutil
import os
class MemoryOptimizedAgent(Agent):
def __init__(self, name):
super().__init__(name)
self.memory_threshold = 80 # 内存使用阈值(百分比)
def check_memory_usage(self):
process = psutil.Process(os.getpid())
memory_percent = process.memory_percent()
return memory_percent
def optimize_memory(self):
# 手动触发垃圾回收
gc.collect()
# 清理临时变量
if hasattr(self, 'temp_data'):
del self.temp_data
self.temp_data = {}
def think(self, message):
# 检查内存使用
memory_usage = self.check_memory_usage()
if memory_usage > self.memory_threshold:
self.optimize_memory()
print(f"Memory optimized, usage: {memory_usage:.2f}%")
# 处理消息
return f"Processed: {message}"
20.2 配置级优化策略
20.2.1 线程池配置
优化方案:根据系统硬件资源和任务特性,合理配置线程池大小。
配置示例:
import concurrent.futures
from agentscope import Agent, Environment
# 配置线程池
def configure_thread_pool(max_workers=None):
if max_workers is None:
# 根据CPU核心数自动配置
import os
max_workers = os.cpu_count() * 2
return concurrent.futures.ThreadPoolExecutor(max_workers=max_workers)
# 使用线程池处理任务
class ThreadPoolAgent(Agent):
def __init__(self, name):
super().__init__(name)
self.executor = configure_thread_pool()
def think(self, message):
# 提交任务到线程池
future = self.executor.submit(self.process_message, message)
return future.result()
def process_message(self, message):
# 处理消息的逻辑
return f"Processed: {message}"
20.2.2 模型配置优化
优化方案:根据实际需求选择合适的模型大小和配置,平衡性能和效果。
配置示例:
from agentscope import Agent, ModelConfig
# 模型配置优化
def get_optimized_model_config():
return ModelConfig(
model="gpt-3.5-turbo", # 选择适合的模型
temperature=0.7, # 适当的温度参数
max_tokens=1000, # 合理的最大token数
timeout=30, # 设置超时时间
retry_count=3, # 配置重试次数
batch_size=10, # 批处理大小
caching=True, # 启用缓存
)
# 使用优化的模型配置
class OptimizedAgent(Agent):
def __init__(self, name):
model_config = get_optimized_model_config()
super().__init__(name, model_config=model_config)
def think(self, message):
return super().think(message)
20.2.3 通信协议优化
优化方案:选择高效的通信协议,减少序列化和反序列化开销。
配置示例:
import msgpack # 更高效的序列化库
from agentscope import Agent, Environment
class EfficientCommunicationAgent(Agent):
def __init__(self, name):
super().__init__(name)
def send_message(self, recipient, message):
# 使用msgpack进行序列化
serialized_message = msgpack.packb(message)
# 模拟发送消息
print(f"Sent {len(serialized_message)} bytes to {recipient}")
return True
def receive_message(self, sender, serialized_message):
# 使用msgpack进行反序列化
message = msgpack.unpackb(serialized_message)
print(f"Received message from {sender}: {message}")
return message
20.3 系统级优化策略
20.3.1 负载均衡
优化方案:实现智能负载均衡,合理分配任务到不同的处理节点。
实现示例:
from agentscope import Agent, Environment
import random
class LoadBalancer:
def __init__(self, agents):
self.agents = agents
self.agent_loads = {agent.name: 0 for agent in agents}
def get_least_loaded_agent(self):
# 选择负载最小的智能体
return min(self.agent_loads, key=self.agent_loads.get)
def assign_task(self, task):
# 分配任务
agent_name = self.get_least_loaded_agent()
self.agent_loads[agent_name] += 1
print(f"Assigned task to {agent_name}, current load: {self.agent_loads[agent_name]}")
return agent_name
def complete_task(self, agent_name):
# 完成任务,减少负载
if agent_name in self.agent_loads:
self.agent_loads[agent_name] = max(0, self.agent_loads[agent_name] - 1)
print(f"Task completed by {agent_name}, current load: {self.agent_loads[agent_name]}")
# 使用负载均衡器
class LoadBalancedEnvironment(Environment):
def __init__(self, agents):
super().__init__()
self.agents = {agent.name: agent for agent in agents}
self.load_balancer = LoadBalancer(agents)
def submit_task(self, task):
agent_name = self.load_balancer.assign_task(task)
agent = self.agents[agent_name]
result = agent.think(task)
self.load_balancer.complete_task(agent_name)
return result
20.3.2 资源监控与自动扩缩容
优化方案:实现系统资源监控,根据负载自动调整资源分配。
实现示例:
import psutil
import time
from agentscope import Agent, Environment
class ResourceMonitor:
def __init__(self):
self.cpu_threshold = 70 # CPU使用率阈值
self.memory_threshold = 80 # 内存使用率阈值
def check_resources(self):
cpu_usage = psutil.cpu_percent()
memory_usage = psutil.virtual_memory().percent
return {
"cpu": cpu_usage,
"memory": memory_usage,
"timestamp": time.time()
}
def should_scale_up(self, resource_status):
return resource_status["cpu"] > self.cpu_threshold or \
resource_status["memory"] > self.memory_threshold
def should_scale_down(self, resource_status):
return resource_status["cpu"] < 30 and \
resource_status["memory"] < 40
class AutoScalingEnvironment(Environment):
def __init__(self):
super().__init__()
self.agents = []
self.resource_monitor = ResourceMonitor()
self.min_agents = 2
self.max_agents = 10
def monitor_and_scale(self):
resource_status = self.resource_monitor.check_resources()
print(f"Resource status: {resource_status}")
if self.resource_monitor.should_scale_up(resource_status) and len(self.agents) < self.max_agents:
# 扩容
new_agent = Agent(name=f"agent_{len(self.agents) + 1}")
self.agents.append(new_agent)
print(f"Scaled up: {len(self.agents)} agents now")
elif self.resource_monitor.should_scale_down(resource_status) and len(self.agents) > self.min_agents:
# 缩容
self.agents.pop()
print(f"Scaled down: {len(self.agents)} agents now")
def run(self):
while True:
self.monitor_and_scale()
time.sleep(10) # 每10秒检查一次
20.3.3 缓存策略优化
优化方案:实现多级缓存策略,减少重复计算和I/O操作。
实现示例:
from agentscope import Agent
from functools import lru_cache
import redis
class MultiLevelCacheAgent(Agent):
def __init__(self, name):
super().__init__(name)
# 初始化Redis客户端(远程缓存)
try:
self.redis_client = redis.Redis(host='localhost', port=6379, db=0)
self.redis_available = True
except:
self.redis_available = False
# 本地内存缓存
self.local_cache = {}
@lru_cache(maxsize=1000)
def cached_operation(self, key):
# 先检查本地缓存
if key in self.local_cache:
print(f"Cache hit (local): {key}")
return self.local_cache[key]
# 再检查Redis缓存
if self.redis_available:
try:
value = self.redis_client.get(key)
if value:
print(f"Cache hit (Redis): {key}")
value = value.decode('utf-8')
self.local_cache[key] = value
return value
except:
pass
# 缓存未命中,执行计算
print(f"Cache miss: {key}")
value = self.expensive_operation(key)
# 更新缓存
self.local_cache[key] = value
if self.redis_available:
try:
self.redis_client.set(key, value, ex=3600) # 1小时过期
except:
pass
return value
def expensive_operation(self, key):
# 模拟耗时操作
import time
time.sleep(0.5)
return f"Result for {key}"
def think(self, message):
return self.cached_operation(message)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)