【原创】基于Spec驱动的AI工程化开发指南
作者:黑夜路人
时间:2026 年 3 月
背景与目标
AI 编程 Agent 正在彻底改变软件构建的方式。现在的模型不仅能运行数小时,完成庞大的多文件重构,还能不断迭代直到测试通过。但要充分发挥 Agent 的潜力,不仅需要了解它们的工作原理,还需要掌握新的协作模式。
本指南的目标是:将 AI Agent 从"聪明的代码补全工具"升级为"可靠的开发协作伙伴",通过系统化的流程约束,让 Agent 输出的代码达到生产级质量。
📌 术语说明: 本指南中所说的 "Agent" 是对当前 AI 辅助编程工具的泛称,包括但不限于:Cursor、Claude Code、Codex、Augment Code、KiloCode、Antigravity、OpenCode 等。无论你使用哪款工具,本指南的流程和原则均适用。
为什么需要工程化方案?
当前多 Agent 协作模式(无论是多实例并行、Agent Team、还是按角色分工的团队 Agent)的核心价值在于提升效率——多个 Agent 同时处理不同任务,缩短整体交付周期。但本质上,它们只是不同角色在并行运转:上下游有依赖的任务仍然需要串行执行,无法跳过。
更关键的问题在于编码环节的可靠性。目前没有任何 AI 工具能彻底保证多 Agent 并行修改代码时不出问题——代码合并可能冲突,一个 Agent 的修改可能无意中破坏另一个 Agent 的产出,单个 Agent 也可能写出"看起来对但逻辑有坑"的代码。仅仅打开一个 AI 编程工具、写几句 Prompt,是远远不够的。 要在生产环境中真正依赖 Agent 的产出,就必须有一套工业级的研发工程化方案——从规范约束、需求规划、TDD 驱动到多维 Review 和自动化测试——层层把关,才能将 Agent 的效率优势转化为可靠的交付质量。
⚠️ 适用范围说明
本指南是一套面向工业级软件的工程化方案,并非所有项目都需要。 以下场景建议酌情简化或跳过部分环节:
- 个人项目 / 个人 Side Project:直接让 Agent 写代码即可,无需完整复杂的流程,只需要进行跟ai反复沟通方案即可。
- 纯客户端应用(H5、小程序、桌面或者独立CLI):业务逻辑简单,测试策略可大幅精简。
- MVP / 快速原型验证:追求速度而非质量,先跑通再说,本指南的重流程会拖慢节奏。
- 小作坊团队(1-3 人)/ 简单 CRUD 业务:流程的管理成本可能超过收益。
适合使用本指南的场景:
- 多人协作的中大型项目(10+ 人团队)
- 核心业务系统——如电商、金融、交易支付、电信 BOSS、医疗、教育、供应链、工控制造、酒旅 OTA 等对正确性和稳定性要求高的领域。教育业务虽然不涉及到钱,但是各种层叠依赖的业务策略非常多,以及多并发性能的要求。
- 各类复杂企业级软件——ERP、SaaS 服务平台、底层基础软件与基础设施
- 多服务/微服务架构,模块间有复杂依赖
- 软件规模和复杂度已超出小团队凭经验 Cover 的范围,需要流程化保障
- 长期维护的产品(非一次性交付)
成本提醒: 按照本指南的完整流程,一个中等复杂度的需求可能需要与 LLM 交互几十轮,消耗几十万上百万 Token。请根据项目的实际价值和复杂度,选择性地采用其中的环节——核心原则是"关键路径上严格执行,非关键路径灵活裁剪"。
核心理念:人是领航员,AI 是驾驶员
当前阶段的 AI Agent 并非全自动化的"AI 程序员"。它们在有明确目标、充分上下文和严格约束时表现出色,但在需要全局判断、架构决策和模糊需求理解时仍然依赖人类。最佳协作模式是 Human-in-the-Loop(人机协同闭环)的结对编程——你负责思考"做什么"和"为什么",Agent 负责高效执行"怎么做"。
核心链路概览
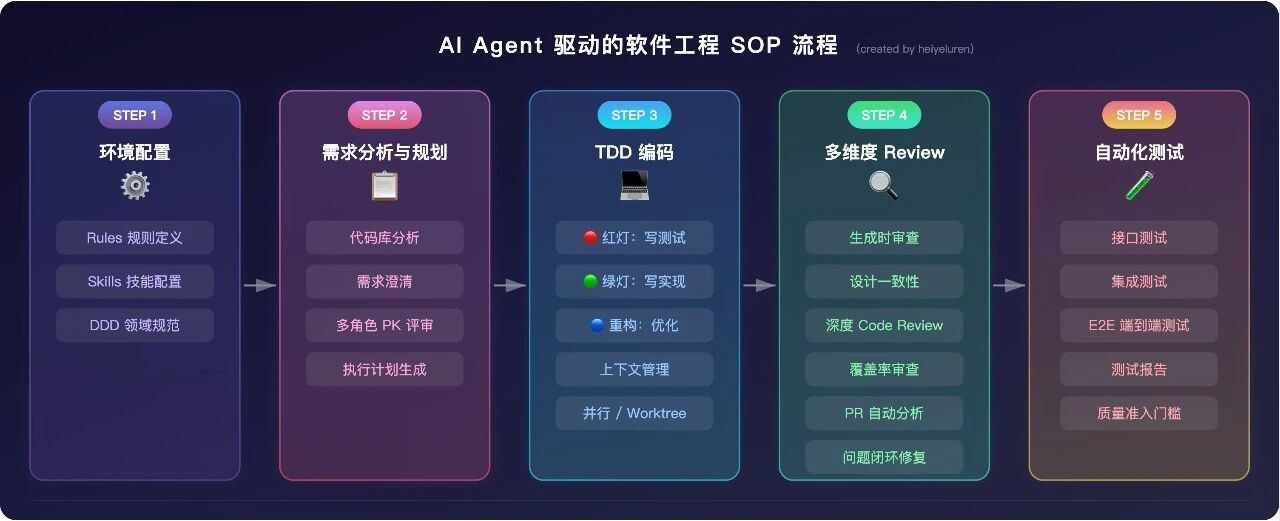
细节:
| 阶段 | 核心动作 | 解决的问题 |
| 环境配置 | Rules 规范 + Skills 技能 | Agent 不了解项目约束,输出不合规 |
| 需求规划 | 代码库分析 → 需求澄清 → 多角色 PK → 执行计划 | 理解不充分导致返工 |
| TDD 编码 | 红灯 → 绿灯 → 重构,精准上下文,多 Agent 并行 | 代码写完才发现逻辑错误 |
| 多维 Review | 设计一致性 + Code Review + 覆盖率审查 + 问题闭环 | AI 代码"看着对但有坑" |
| 自动化测试 | 接口测试 → 集成测试 → E2E 测试 → 准入门槛 | 单元通过但系统级失败 |
每个阶段都产出可追溯的文档(设计文档、执行计划、Review 报告、测试报告),形成完整的质量证据链。那些从 Agent 中获益最多的开发者,往往具备以下特质:编写具体的提示词、提供可验证的目标(如测试)、并且像对待有能力的同事一样,要求 Agent 提供计划和解释。
一、开发前:定制你的 Agent 环境
在开始任何开发任务之前,先配置好 Agent 的行为基线,让每次对话都站在正确的起点上。
1. Rules(规则)—— 静态常驻指令
适用于所有对话的全局约束,以 Markdown 文件形式维护在项目中,Agent 每次启动时自动加载。
(我们后端现有很多通用规则可以直接引用,在 ai-conmon-rules 中)
技术栈声明
明确告诉 Agent 项目的技术边界,避免它"自由发挥"引入不兼容的技术。
# 技术栈规范(概要版)
- 后端:Go 1.24+,标准库优先,gin 框架+kratos框架
- 前端:TypeScript + React 18 + Next 14
- 数据库:PostgreSQL 17 主库,Redis 7 缓存
- 消息队列:Kafka
- 部署:阿里云 K8S
- 禁止引入未经审批的第三方依赖编码约束("八荣八耻"式规则)
将团队的编码红线写成 Agent 必须遵守的铁律。
# 编码八荣八耻
以编写单元测试为荣,以跳过测试为耻
以清晰命名为荣,以缩写命名为耻
以接口抽象为荣,以硬编码实现为耻
以幂等设计为荣,以重复执行出错为耻
以显式错误处理为荣,以忽略 error 为耻
以小函数单一职责为荣,以上帝函数为耻
以数据库迁移脚本为荣,以手动改表为耻
以配置外部化为荣,以代码写死配置为耻数据库设计规范
# 数据库设计规范
- 所有表必须包含:id(bigint主键)、created_at、updated_at、deleted_at(软删除)
- 字段命名:snake_case,禁止拼音,禁止缩写(除公认缩写如 id、url)
- 索引命名:idx_{表名}_{字段名},唯一索引:uk_{表名}_{字段名}
- 枚举值使用 smallint + 注释,不使用字符串枚举
- 单表字段不超过 30 个,超过则拆分
- 所有外键关系通过应用层维护,不使用数据库外键约束
- 大文本字段(如 JSON)使用独立扩展表存储
- 必须提供完整的 migration 脚本,禁止手动 DDLDDD 分层架构规范
# 项目分层架构(DDD 风格,我们项目约束)
## 请求流转链路
Request -> Controller (DTO解析) -> Service (业务编排) -> Domain (接口定义) -> DAO (数据读写) -> DB/Cache
## 各层职责边界
- controller/:HTTP 入参解析、DTO 校验、调用 Service,禁止包含业务逻辑
- service/:业务流程编排,调用 Domain 接口,处理事务,禁止直接访问 DAO
- domain/:核心业务规则和接口定义,不依赖任何基础设施
- dao/:数据库读写实现,实现 Domain 层定义的接口
- dto/:请求/响应数据结构,仅用于 Controller 与外部的数据交换
- model/:数据库实体映射,与表结构一一对应
## 依赖方向(严格单向)
controller → service → domain ← dao
禁止反向依赖,禁止跨层调用(如 controller 直接调用 dao)其他建议写入的内容:
- 常用的构建命令(如 go build、npm run dev)
- 代码风格偏好(如"使用 ES modules"、"函数优先于类")
- 项目特定的目录结构规范
- 日志规范(级别、格式、敏感信息脱敏)
- API 设计规范(RESTful 路径、响应码、分页约定,符合我们rules 要求的规范)
- Git 提交信息格式(如 Conventional Commits)
不应该写什么:
- 不要复制整个风格指南(用 Linter 代替自动检查的部分)
- 不要试图用 Rules 覆盖所有边缘情况(那是代码逻辑该做的事)
2. Skills(技能)—— 按需加载的动态能力
与 Rules 不同,Skills 是按需触发的,定义在 SKILL.md 文件中。与始终加载的 Rules 不同,Skills 是按需加载的,适合封装可复用的、有固定流程的开发动作。
代码生成技能 —— 按 DDD 分层生成
# SKILL: generate-dao
## 触发命令: /gen-dao {实体名}
## 执行步骤:
1. 读取 app/model/{实体名}.go 获取数据库实体定义
2. 读取 app/domain/ 下对应的接口定义
3. 在 app/dao/ 目录生成 DAO 实现,包含:
- Create、GetByID、Update、Delete、List(带分页)
- 所有数据库操作使用事务包装
4. 生成对应的 dao_test.go 文件
5. 遵循项目 Rules 中的数据库设计规范和编码约束类似地,可以定义 /gen-domain(生成 Domain 层接口)、/gen-service(生成 Service 层编排逻辑)、/gen-controller(生成 Controller 层 HTTP 处理)、/gen-dto(生成数据传输对象)等技能,形成从模型到接口的完整代码生成链。
测试生成技能
# SKILL: generate-unit-test
## 触发命令: /gen-test {文件路径}
## 执行步骤:
1. 分析目标文件的所有公开函数和方法
2. 为每个函数生成 Table-Driven 测试用例,覆盖:
- 正常路径(至少 2 个用例)
- 边界条件(空值、零值、最大值)
- 错误路径(参数非法、依赖失败)
3. 使用 testify/assert 断言
4. Mock 外部依赖(使用 mockery 生成的 mock)
5. 运行测试确认全部通过
6. 输出覆盖率报告# SKILL: generate-api-test
## 触发命令: /gen-api-test {接口路径}
## 执行步骤:
1. 读取 app/controller/ 中的路由定义和 Handler 实现
2. 生成 HTTP 集成测试用例,覆盖:
- 正常请求和响应校验
- 参数校验失败(缺少必填项、类型错误)
- 认证和权限校验
- 并发请求幂等性验证
3. 使用 httptest 构建测试服务器
4. 断言响应状态码、Body 结构、Header工作流自动化技能
# SKILL: submit-pr
## 触发命令: /pr
## 执行步骤:
1. 执行 git diff --stat 汇总变更
2. 运行全量测试套件,确认通过
3. 运行 linter 检查
4. 基于 diff 生成 Conventional Commits 格式的提交信息
5. Push 到远程分支
6. 创建 Pull Request,自动填写描述模板Hook 脚本
除了命令式 Skills,还可以创建循环脚本,让 Agent 持续修改代码直到所有测试通过——这在 TDD 阶段的"绿灯"环节尤其有用。
二、需求分析与规划:谋定而后动
拿到需求后,绝不允许 Agent 直接写代码。这个阶段的目标是让 Agent 充分理解现有系统,产出经过验证的实施计划。
第一步:深入理解现有代码库
在讨论任何需求之前,先让 Agent 建立对项目的全局认知。Agent 拥有强大的搜索工具(grep + 语义搜索),能通过代码库自动定位相关文件——但首次接触项目时,需要系统性地建立全景视图。
⚠️ 局限性提醒: 对于中大型项目(数十万行代码以上),目前的模型无法一次性读取所有代码来构建完美的"全景图"。基于 RAG(检索增强)的工具在回答局部问题时很强,但在总结"全局架构"时往往会遗漏细节或产生幻觉。建议的做法是:由人类架构师提供架构框架和核心模块说明,让 Agent 在此基础上填充细节并补全文档,而非期望 Agent 从零生成。
示例提示词:
请深入分析当前项目代码库,生成一份项目全景文档(保存为 docs/project-overview.md),包含:
1. 项目整体架构(DDD 分层结构、各层模块及职责)
2. 核心数据模型及其关系(基于 app/model/ 目录分析 ER 关系)
3. 关键业务流程(梳理 controller → service → domain → dao 的调用链路)
4. 外部依赖和集成点(第三方 API、消息队列、缓存)
5. 各入口服务差异(main/teacher-api、main/teacher-admin、main/teacher-job 的职责划分)
6. 现有测试覆盖情况
不要猜测,只基于代码库中实际存在的内容进行分析。如果某个模块无法确认,请标注"待人工确认"。产出后务必人工审查: Agent 生成的全景文档需要架构师或资深开发者逐项校对(如果非常熟悉模块可以设计可靠通用skills校对人类检查校对结果),修正遗漏和幻觉,才能作为后续规划的可靠基础。这份文档也可以作为新成员的学习资料。
第二步:需求理解与澄清
让 Agent 以产品经理的视角审视需求,主动发现模糊地带。
示例提示词:
以下是本次迭代的需求文档:[粘贴或引用 PRD]
请完成以下工作:
1. 用你自己的话复述这个需求的核心目标和用户价值
2. 列出所有你认为不够明确、可能导致返工的问题
3. 识别与现有系统的交互点和潜在冲突
4. 将分析结果保存为 docs/requirements/{需求名}-analysis.mdAgent 可能产出的澄清问题示例:
- "需求提到'支持批量导入用户',但未定义:单次最大导入量是多少?导入失败的记录如何处理?是否需要异步处理?"
- "新增的'学习报告'模块需要读取历史答题数据,但现有 answer_record 表没有索引支持按用户+时间范围查询,是否需要同步规划索引优化?"
第三步:多角色 PK 评审设计方案
这是防止返工的关键环节。让 Agent 扮演不同角色对设计方案进行挑战。
💡 效果增强技巧: 多角色 PK 在同一个对话上下文中进行时,Agent 可能倾向于"自我一致"而非真正的对抗性审查。建议以下优化方式:(1)每个角色在独立的新对话中进行评审,避免上下文污染;(2)如果条件允许,可以用不同的模型扮演不同角色(如 Claude 做架构评审、GPT 做安全评审),利用模型差异性发现更多问题。
示例提示词:
基于需求分析文档,请先产出一份技术设计方案,然后依次从以下角色视角进行评审 PK:
【架构师视角】
- 方案是否符合现有 DDD 分层架构?各层职责是否清晰?
- 是否引入了不必要的复杂度?是否有跨层调用?
- 扩展性如何?如果用户量增长 10 倍,哪里会成为瓶颈?
【DBA 视角】
- 新增的表结构是否符合数据库规范?索引设计是否合理?
- 数据量预估多少?是否需要分表策略?
- 有没有慢查询风险?
【安全工程师视角】
- 是否存在注入、越权、数据泄露风险?
- 敏感数据是否加密存储?接口是否有鉴权?
【QA 视角】
- 哪些场景难以测试?是否需要特殊的测试数据构造?
- 边界条件和异常路径是否在设计中考虑到了?
每个角色给出具体的修改建议。最终输出修订后的设计方案,保存为 docs/design/{需求名}-design.md。第四步:生成执行计划
设计方案通过后,产出可执行的任务分解和实施计划。计划应创建包含文件路径和代码引用的详细实施方案。
示例提示词:
基于已审批的设计方案,生成详细的执行计划(保存为 docs/plans/{需求名}-plan.md),包含:
1. 任务分解(按 DDD 分层自底向上,标注依赖关系)
- 每个任务包含:涉及的文件、预估工作量、验收标准
2. 开发顺序(识别关键路径,标注哪些任务可以并行)
- 推荐顺序:model → migration → domain 接口 → dao 实现 → service 编排 → controller → dto
3. 数据库变更清单(migration 脚本顺序)
4. 测试策略(每个模块的测试类型和覆盖目标)
5. 风险清单及应对方案
格式示例:
## Task 1: 创建 learning_report 表和 Model
- 文件: migrations/202502_create_learning_report.sql, app/model/learning_report.go
- 依赖: 无
- 验收: migration 可正向/反向执行,model 结构体与表结构一致
- 预估: 0.5h
## Task 2: 定义 Domain 层接口
- 文件: app/domain/learning_report.go
- 依赖: Task 1(需要 model 定义)
- 验收: 接口覆盖所有业务操作,无基础设施依赖
- 预估: 0.5h关键实践
- 保存计划:将计划持久化保存。这不仅是团队文档,也能帮助你在工作中断后快速恢复上下文。
- 从计划重来:如果 Agent 写偏了,不要试图通过对话修修补补。更好的做法是:回滚更改 → 修改计划文件 → 让 Agent 重新执行。这通常比修正"正在进行中"的 Agent 更快,代码也更干净。
- 计划即文档:计划文件本身就是开发过程的文档记录,方便团队协作和后续追溯。
三、编码阶段:上下文管理与 TDD 驱动
1. 上下文管理:少即是多
随着你对 Agent 越来越熟悉,你的核心工作将转变为提供精准的上下文。不要手动 Tag 所有文件——Agent 拥有强大的搜索工具,当你问"认证流程"时,它能通过 grep 和语义搜索找到相关文件,哪怕你的提示词里没有精确的文件名。你要做的是帮它"聚焦"。
应该引用的上下文:
| 类型 | 示例 | 原因 |
| 执行计划 | @docs/plans/learning-report-plan.md | Agent 需要知道当前任务在整体中的位置 |
| 设计文档 | @docs/design/learning-report-design.md | 确保实现不偏离设计 |
| Domain 接口 | @app/domain/learning_report.go | 明确实现契约 |
| 相关数据模型 | @app/model/student.go | 理解关联实体的结构 |
| 已有的类似实现 | @app/service/homework_service.go | 作为编码风格和模式的参考 |
| 当前分支变动 | 让 Agent 了解分支上的改动 | 保持对变更全貌的感知 |
| 过去的工作记录 | 引用过去的对话而非复制粘贴 | 减少上下文中的"噪音" |
| Rules 规则文件 | 自动加载 | 全局约束始终生效 |
不应该引用的内容:
| 类型 | 原因 |
| 整个 app/ 目录 | 噪音太多,Agent 会注意力分散 |
| 过期的设计文档 | 误导 Agent,产出与当前设计矛盾的代码 |
| 无关模块的代码 | 占用上下文窗口,挤掉真正需要的信息 |
| 完整的聊天历史 | 累积的试错过程会干扰 Agent 判断 |
提示词构建模板:
## 当前任务
执行计划 Task 4:实现 LearningReport 的 Service 层
## 上下文
- 执行计划:@docs/plans/learning-report-plan.md(关注 Task 4)
- 设计文档:@docs/design/learning-report-design.md(关注"Service 层设计"章节)
- Domain 接口:@app/domain/learning_report.go
- DAO 实现:@app/dao/learning_report_dao.go
- 数据模型:@app/model/learning_report.go
- 参考实现:@app/service/homework_service.go(参考其编排模式和错误处理)
## 要求
1. 在 app/service/ 目录下实现,严格按照 Domain 接口编排业务逻辑
2. 所有公开方法必须有完整的错误处理
3. 业务日志使用 structured logging
4. 禁止在 Service 层直接操作数据库,必须通过 DAO 接口
5. 先不要写测试,我们下一步用 TDD 方式补充何时开启新对话:
当 Agent 开始感到困惑、重复犯错,或者你已经完成了一个逻辑单元的工作时,果断开启新对话。过长的对话会积累干扰信息,导致 Agent 注意力分散。具体判断标准:
- Agent 开始重复犯同样的错误(上下文已被"污染")
- 当前任务完成,要进入下一个独立任务
- 对话已超过 15-20 轮(注意力衰减)
- 需要切换到完全不同的模块或技术领域
开启新对话时,引用过去的工作记录,而不是复制粘贴整个聊天记录,这样能减少上下文中的"噪音"。
2. TDD 红-绿-重构循环
Agent 在有明确、可验证的目标时表现最佳。TDD 提供了这种"目标感"——用测试定义"完成",让 Agent 有明确的迭代方向。
🔴 红灯阶段:编写失败的测试
请为 app/service/learning_report_service.go 的 GenerateReport 方法编写测试用例:
要求:
- 这是 TDD 流程,现在只写测试,不写任何实现代码
- 不要生成 Mock 实现来让测试"假通过"
- 使用 Table-Driven 风格,覆盖以下场景:
1. 正常生成报告(有完整答题数据的用户)
2. 用户无答题记录时返回空报告
3. 时间范围参数非法时返回错误
4. 用户 ID 不存在时返回 NotFound 错误
5. DAO 层查询超时时的错误处理
运行测试,确认所有用例都是 FAIL 状态(红灯)。
如果有任何用例意外通过了,说明测试写得不够严格,请修正。验证点: 所有测试必须失败,且失败原因是"功能未实现"而非"编译错误"。
🟢 绿灯阶段:用最简代码通过测试
现在请编写 LearningReportService.GenerateReport 的实现代码。
要求:
- 目标是让所有测试通过(变绿灯),不要过度设计
- 每实现一个场景后立即运行测试,逐步从红变绿
- 如果某个测试持续失败,分析失败原因并修复,不要跳过
- 遇到设计文档未覆盖的边界情况,先记录到 TODO 注释,稍后讨论验证点: 所有测试通过。Agent 应逐个用例报告从 FAIL → PASS 的过程。可以利用 Hook 脚本让 Agent 不断迭代直到所有测试通过。
🔵 重构阶段:在测试保护下优化代码
所有测试已通过。现在请对实现代码进行重构:
检查并优化:
1. 是否有重复代码可以提取为私有方法?
2. 函数是否过长(超过 50 行)?是否可以拆分?
3. 命名是否清晰准确?
4. 错误处理是否符合项目规范?
5. 是否有性能优化空间(如 N+1 查询)?
6. 是否严格遵循 DDD 分层,没有跨层调用?
约束:
- 每次重构后必须运行测试,确认全部通过(绿灯不能变红)
- 如果重构导致测试失败,立即回退该次修改验证点: 代码质量提升,所有测试仍然通过。
TDD 循环示意
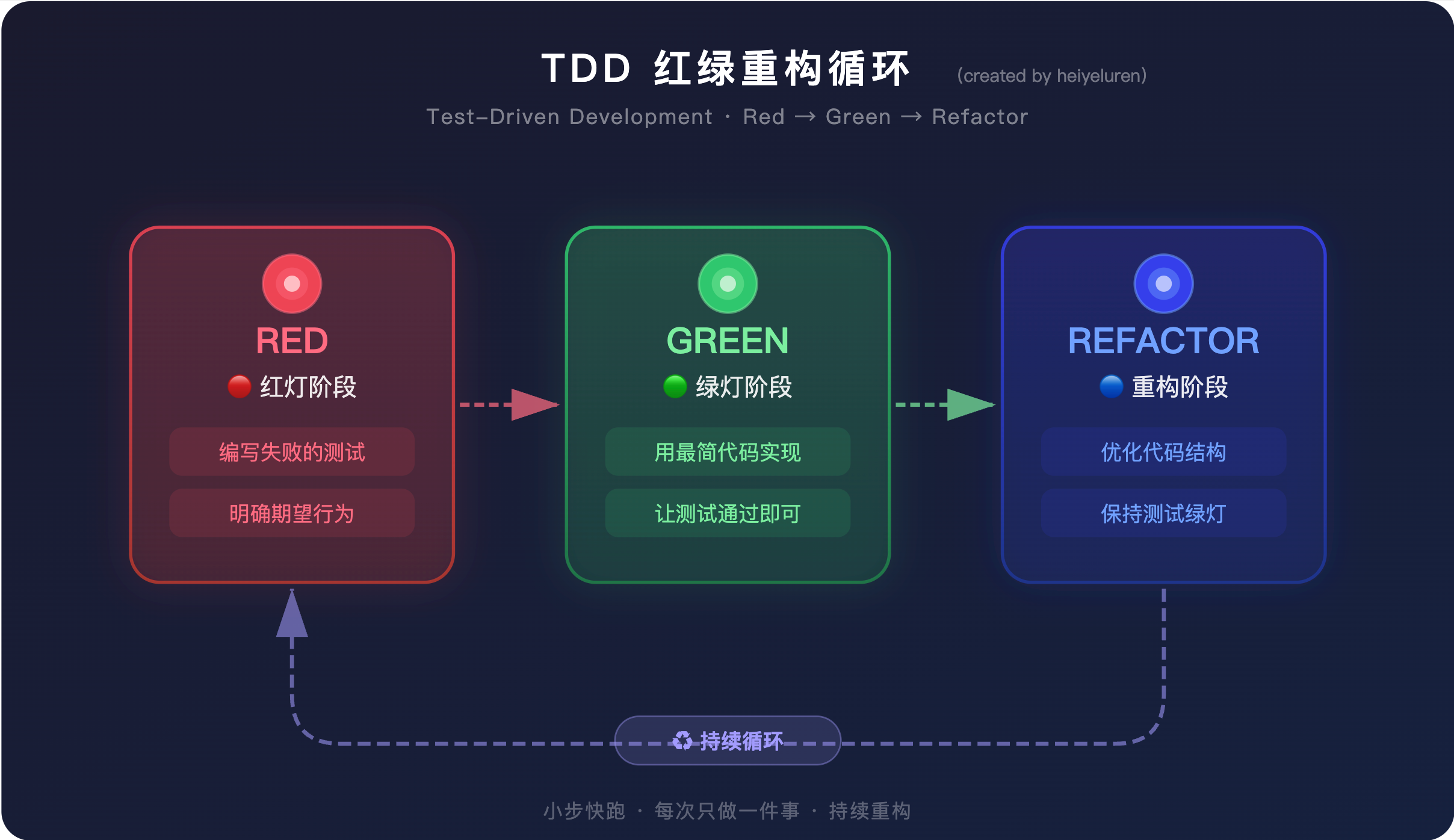
┌─────────────────────────────────────────┐
│ │
│ 🔴 红灯 🟢 绿灯 🔵 重构 │
│ ┌──────┐ ┌──────┐ ┌──────────┐ │
│ │ RED │───→│ GREEN│───→│ REFACTOR │──┘
│ └──────┘ └──────┘ └──────────┘
│ 写失败测试 最简实现 优化代码
│ 通过测试 保持绿灯每完成一个功能点,重复这个循环。积累的测试套件就是代码质量的安全网。
3. 并行开发与多 Agent 协作
当执行计划中存在多个任务时,可以通过并行方式加速开发。根据任务间的关系,选择不同的并行策略。
⚠️ 现实提醒:人是单线程的。 虽然技术上可以同时运行多个 Agent,但你作为"领航员"需要频繁审查和纠偏每个 Agent 的输出。同时管理 3 个以上的 Agent 会导致认知负荷过载,在不同上下文之间频繁切换反而比串行更慢。推荐的实际并行度是:1 个主力任务(你深度参与)+ 1-2 个简单的后台任务(如文档、测试补充、代码清理等可以"拿起放下"的工作)。
场景一:任务完全隔离 —— 直接多终端并行
当多个任务修改的文件完全不重叠时,最简单的方式是在不同终端或 IDE 窗口中直接启动多个 Agent,无需额外的隔离机制。
# 终端 1:Agent A 在 app/dao/ 下实现 LearningReportDAO
cd ~/projects/teacher-api
claude # 或在 IDE 中打开 Agent
# 终端 2:Agent B 在前端项目中实现报告展示组件
cd ~/projects/teacher-web
claude # 完全不同的项目,天然隔离适用条件:
- 两个任务修改的文件集合完全不重叠
- 或者分别在不同的子项目/仓库中工作
- 任务相对简短(10-30 分钟可完成)
场景二:任务涉及同仓库不同模块 —— 使用 Git Worktree
⚠️ 重要提示: Git worktree + 多 Agent 并行是一种高级工作模式,操作不当可能导致代码丢失或合并混乱。在实际使用前,请务必深入学习理解多 Agent 协作原理和 Git worktree 的工作机制(特别是分支锁定、共享 .git 目录、rebase/merge 策略等概念)。如果你对 Git worktree 还不熟悉,建议先在个人测试仓库中练习完整的 创建 → 开发 → rebase → 合并 → 清理 流程,确认理解后再用于生产项目。否则请优先使用"场景一:直接多终端并行"的简单模式。
当多个 Agent 需要在同一仓库中工作,即使修改不同文件,也推荐使用 Git worktree 进行隔离。Worktree 让同一个仓库在磁盘上拥有多个独立的工作目录,每个目录对应不同的分支,共享同一个 .git 数据库但文件系统完全隔离。
为什么用 worktree 而不是多次 clone:
- 共享 .git 目录,节省磁盘空间,git fetch 一次所有 worktree 都可见
- 分支锁定保护:同一个分支不能在两个 worktree 中同时 checkout,天然避免并行冲突
- 清理方便:git worktree remove 一键移除,不留残留
创建 worktree 并启动 Agent:
# 推荐将所有 worktree 放在统一的目录下,并加入 .gitignore
mkdir -p .trees
# 为不同任务创建隔离的工作空间
git worktree add .trees/task-3-dao -b feature/task-3-dao origin/main
git worktree add .trees/task-5-service -b feature/task-5-service origin/main
git worktree add .trees/task-7-controller -b feature/task-7-controller origin/main
# 每个 worktree 需要独立初始化环境
cd .trees/task-3-dao && go mod download && cd ../..
cd .trees/task-5-service && go mod download && cd ../..# 终端 1:Agent A 在 worktree 中实现 DAO 层
cd .trees/task-3-dao
claude # 或 cursor 打开此目录
# 终端 2:Agent B 在另一个 worktree 中实现 Service 层
cd .trees/task-5-service
claude
# 主工作目录:你继续在 main 上做其他工作或 Review
cd ~/projects/teacher-api目录结构示意:
teacher-api/ # 主 worktree(main 分支)
├── .trees/ # 所有并行 worktree(已加入 .gitignore)
│ ├── task-3-dao/ # Agent A 的工作空间
│ ├── task-5-service/ # Agent B 的工作空间
│ └── task-7-controller/ # Agent C 的工作空间
├── app/
├── main/
└── ...单个 Agent 完成后的合并流程
Agent 完成任务后,需要经过验证、合并、清理三个步骤,确保最终代码可靠。
第一步:worktree 内自验证
cd .trees/task-3-dao
# 运行全量测试,确保本任务的代码自身没问题
go test ./... -v -count=1
go vet ./...
golangci-lint run第二步:同步最新主分支并解决冲突
这是防止 worktree 与主分支"漂移"过远的关键——实践中建议每完成一个逻辑检查点就同步一次,而不是等到最后。
git fetch origin
git rebase origin/main
# 如果有冲突:解决冲突 → git add . → git rebase --continue
# rebase 后必须重新运行全量测试
go test ./... -v -count=1第三步:合并入主分支
# 切回主 worktree
cd ~/projects/teacher-api
# 方式一:本地合并(适合个人开发)
git merge --no-ff feature/task-3-dao -m "feat: implement LearningReport DAO (#task-3)"
# 方式二:推送并创建 PR(适合团队协作,推荐)
cd .trees/task-3-dao
git push -u origin feature/task-3-dao
# 然后在 GitHub/GitLab 上创建 Pull Request 进行 Review
# 合并后运行全量测试(关键!确认与其他已合并任务没有冲突)
go test ./... -v -count=1第四步:清理 worktree
git worktree remove .trees/task-3-dao
git branch -d feature/task-3-dao # 删除本地分支
git push origin --delete feature/task-3-dao # 删除远程分支(如已推送)
git worktree list # 确认清理干净多 Agent 合并顺序策略
当多个 Agent 同时完成时,合并顺序至关重要,应遵循 DDD 分层的依赖方向:
推荐合并顺序:底层 → 上层,无依赖 → 有依赖
1. 先合并:migration 脚本 + model(数据库层,最底层)
2. 再合并:domain 接口定义(领域层)
3. 然后合并:dao 实现(依赖 model 和 domain 接口)
4. 然后合并:service 编排(依赖 domain 和 dao)
5. 最后合并:controller + dto(依赖 service)
每次合并后都运行全量测试,确认不会破坏已合并的代码。冲突预防最佳实践
- 在执行计划阶段就规划好任务边界,尽量让每个 Agent 修改不同的文件
- 共享的文件(如路由注册、依赖注入配置)约定由最后合并的 Agent 统一处理
- Domain 层接口先在主分支定义好,各 Agent 只实现不修改接口
- 不要两个复杂功能并行——并行的核心是"非对称复杂度":主力任务用你的深度思考,并行任务应该是可以随时拿起放下的工作(清理、文档、测试补充)
- 如果两个 Agent 触碰相同文件,会产生和两个开发者同时改同一个文件一样的合并难题
实用提示
- 每个 worktree 需要独立初始化:go mod download、安装依赖、复制不在版本控制中的配置文件(如 .env)
- 用描述性的目录名:与执行计划的 Task 编号对应(如 task-3-dao),方便追溯
- 定期清理:完成并合并后立即 git worktree remove,不要积累过多 worktree
- 及时同步:长时间运行的 worktree 要定期 rebase 主分支,防止最终合并时冲突堆积
- 可以让 Agent 帮你管理 Git:Agent 可以执行 rebase、解决冲突、提交代码,减少你的操作负担
4. 后台委托(Cloud / Remote Agent)
对于重构、修 Bug、写文档、补测试等后台任务,可以委托给云端远程 Agent。它们在远程沙箱环境中运行,即使你合上电脑也会继续工作,完成后通知你审查结果。
⚠️ 成熟度提醒: 后台/云端 Agent 是 AI 编程领域的前沿功能,目前仍在快速迭代中。对于"大规模重构"或"全量补测"这类复杂任务,无人值守的 Agent 可能会陷入死循环、破坏现有逻辑或卡在环境报错上。建议仅将后台 Agent 用于范围明确、风险可控的中小型任务,并将其产出视为 "Draft PR"——必须人工审查后才能合并。
目前支持后台/远程 Agent 的主流工具:
| 工具 | 后台 Agent 名称 | 运行环境 | 说明 |
| Cursor | Background Agent | 远程云端沙箱 | 在 cursor.com/agents 或 IDE 内发起,Agent 在云端 VM 中独立工作,完成后生成 PR。需要 Pro 订阅($20/月)并连接 GitHub 仓库。注意:代码会上传至云端沙箱,需评估安全策略 |
| OpenAI Codex | Codex Agent | 本地终端(后台) | 通过 Codex CLI 在本地终端后台运行,结合 Git worktree 实现多任务并行。适合对代码安全性要求高、不希望代码离开本地环境的场景 |
| Claude Code | 后台执行模式 | 本地终端(后台) | 通过 |
后台委托的最佳使用场景:
- 范围明确、可独立完成的小型任务(如"为 app/dao/learning_report_dao.go 补充单元测试")
- 耗时较长但逻辑清晰的工作(如依赖升级、代码风格统一)
- 低风险的改进型任务(如文档补全、注释完善)
不适合后台委托的任务:
- 涉及多模块联动的大规模重构(Agent 容易迷失方向)
- 需要理解复杂业务上下文的功能开发(缺乏人工即时纠偏)
- 涉及生产环境配置或敏感数据的操作
四、Review 阶段:多维度严格审查
AI 生成的代码看起来正确,但可能包含细微错误。仔细审查是高效使用 Agent 的关键一环。Review 必须多维度、系统化地执行。
⚠️ 关于"自我审查"的局限性: LLM 对自己生成的代码通常有"自信偏差"——如果它在生成时认为某个逻辑是对的,在同一个上下文中让它 Review,它大概率仍然认为是对的。为了提高 Review 的有效性,建议:(1)在新对话中进行 Review,切断生成时的上下文惯性;(2)如条件允许,使用不同的模型进行 Review(如用 Claude 写代码,用 GPT 来 Review),利用模型差异性发现更多问题;(3)人工 Review 不可省略,Agent 的自查只是辅助手段,不能替代人的最终判断。
1. 生成时审查(实时监控)
在 Diff 视图中实时观察 Agent 写代码。如果发现方向不对,及时打断(如按 Escape 键),不要等到整个文件写完再回头改。越早介入,成本越低。
2. 规划设计一致性 Review
验证实现是否忠于设计方案。
请对比以下两份文档,逐项检查实现与设计的一致性:
- 设计文档:@docs/design/learning-report-design.md
- 实际代码:@app/service/learning_report_service.go, @app/dao/learning_report_dao.go, @app/controller/learning_report_controller.go
检查项:
1. 设计中定义的每个 Domain 接口是否都已实现?
2. 数据模型字段是否与设计一致?
3. 请求链路是否符合 Controller → Service → Domain → DAO 的分层规范?
4. 是否有设计中未提及的额外实现(可能是过度设计)?
5. 是否有设计中要求但被遗漏的功能?
输出差异报告,标注每项为:✅ 一致 / ⚠️ 偏差 / ❌ 缺失3. 深度 Code Review
逐文件、逐函数的代码质量审查。 建议在新对话中进行,让 Agent 以"审查者"而非"作者"的身份审视代码。
请对本次变更的所有文件进行深度 Code Review,逐文件分析:
## 正确性
- 业务逻辑是否正确?是否有遗漏的边界条件?
- 并发场景下是否安全(竞态条件、死锁)?
- 错误处理是否完整?是否有被吞掉的 error?
## 架构合规
- 是否严格遵循 DDD 分层?是否有跨层调用(如 controller 直接调用 dao)?
- Service 层是否只做编排,没有包含数据访问逻辑?
- Domain 层是否保持纯净,不依赖基础设施?
## 安全性
- 是否存在 SQL 注入风险?
- 用户输入是否经过校验和清洗?
- 是否有越权访问的可能?
## 性能
- 是否存在 N+1 查询?
- 大数据量场景下是否有性能隐患?
- 是否合理使用了缓存?
## 可维护性
- 命名是否清晰?注释是否充分?
- 函数职责是否单一?
- 是否符合项目 Rules 中的编码规范?
对每个问题标注严重级别:🔴 必须修复 / 🟡 建议优化 / 🟢 微小建议4. 测试覆盖率 Review(Code Coverage)
确保测试不只是"有",而是"够"。 在 AI 辅助编程中,代码覆盖率(Code Coverage)是防止 Agent "偷懒"或"瞎写"的最重要防线之一。
什么是代码覆盖率?
代码覆盖率是衡量测试完整性的量化指标——你的测试用例在运行时实际执行了多少比例的代码。打个比方:如果代码是一栋有许多房间的楼房,测试就是拿着手电筒巡逻的保安。覆盖率就是手电筒照到了多少个房间。
覆盖率被测试执行过的代码行数总代码行数
如果覆盖率只有 80%,意味着还有 20% 的代码从未被测试运行过。如果那 20% 里藏着 Bug(比如 Agent 写了一个错误的 else 分支),上线前是发现不了的。
为什么 AI 编程要特别强调覆盖率?
人类编程中,少写测试通常是因为"偷懒"。但在 AI 编程中,覆盖率承担着更关键的角色——防止 Agent 的"虚假通过":
- Agent 的通病: Agent 知道你要"测试通过"。它有时会写出没有实质断言(Assertion)的测试,或者只测"快乐路径"(Happy Path),完全跳过错误分支。
- 典型场景: 代码逻辑是 if (a > 10) { ... } else { ... },Agent 只写了 a = 11 的测试用例。测试结果是全绿,但 else 分支从未执行过——里面如果有 Bug,谁也不知道。
- 覆盖率的作用: 你不需要逐行审读 Agent 写的每个测试,只需看覆盖率报告。如果某个模块覆盖率不达标,直接打回让 Agent 补齐,直到达标为止。
分层覆盖率红线
不能只看"总分",要看"单科成绩"。不同架构层级承载的职责不同,覆盖率要求也不同:
| 代码层级(DDD 架构) | 覆盖率红线 | 原因 |
| Domain(领域层) | >= 90% | 核心业务规则(如"订单金额不能为负"),纯逻辑,必须几乎全覆盖 |
| Utils/Libs(工具库) | >= 90% | 工具函数被全系统复用,出错影响全局 |
| Service(服务层) | >= 85% | 业务流程编排,逻辑复杂,容易出 Bug |
| DAO(数据层) | >= 80% | 涉及数据库读写,SQL 拼写错误或事务问题需要测试拦截 |
| Controller(接口层) | >= 75% | 主要是参数解析和转发,逻辑相对较少 |
审查执行
请分析当前测试覆盖情况:
1. 运行测试并生成覆盖率报告(如 go test -coverprofile=coverage.out ./...)
2. 逐模块分析覆盖率,对照分层红线逐项检查:
- Domain 层是否 >= 90%?Service 层是否 >= 85%?
- DAO 层是否 >= 80%?Controller 层是否 >= 75%?
- Utils/Libs 是否 >= 90%?
- 哪些函数/分支未被覆盖?
- 未覆盖的部分是否包含关键业务逻辑?
3. 测试质量评估(防止 Agent 的"虚假通过"):
- 是否存在没有实质断言的空壳测试?
- 是否只覆盖了 Happy Path,忽略了错误路径和异常场景?
- 测试数据是否具有代表性?
4. 补充建议:列出需要新增的测试用例,标注优先级
覆盖率不达标的模块必须打回,要求 Agent 补齐测试后重新提交。5. PR 自动分析
提交 PR 后,自动进行高级分析,在合并前拦截潜在问题。这是人工 Review 之外的自动化安全网。
6. 问题闭环:迭代修复
Review 发现的问题必须闭环处理,不允许"已知问题"带入合并。
以下是 Code Review 发现的问题清单:[粘贴或引用 Review 报告中的 🔴 和 🟡 项]
请逐项修复:
1. 每修复一个问题,运行相关测试确认不引入新问题
2. 如果修复涉及设计变更,更新设计文档
3. 修复完成后重新运行完整测试套件
4. 输出修复报告:每个问题的修复方式和验证结果五、测试验证阶段:自动化保障交付质量
代码通过 Review 后,进入系统级的自动化测试验证,确保功能在真实环境中可靠运行。
💡 成本与收益平衡: 以下四层测试(接口 → 集成 → E2E → 报告)是完整方案。对于非核心功能或时间紧迫的迭代,可以根据风险等级裁剪——但核心业务链路的接口测试和集成测试不应省略。
1. 接口测试(API Testing)
验证每个 API 端点的契约正确性。
请为以下 API 端点生成完整的接口测试(基于 main/teacher-api 服务):
POST /api/v1/learning-reports/generate
GET /api/v1/learning-reports/{id}
GET /api/v1/learning-reports?student_id={sid}&start_date={date}&end_date={date}
每个端点覆盖:
- 正常请求:验证响应状态码、Body 结构、字段类型
- 参数校验:缺少必填项、类型错误、超出范围
- 认证鉴权:无 Token、过期 Token、无权限用户
- 幂等性:POST 重复调用的行为是否符合预期
- 响应格式:分页参数、排序、空结果集
- 性能基线:单次请求响应时间 < 500ms2. 集成测试(Integration Testing)
验证多个模块协同工作的正确性。
请编写集成测试,验证"生成学习报告"的完整业务链路(controller → service → domain → dao → DB):
测试场景:
1. 完整链路:创建用户 → 录入答题记录 → 生成报告 → 查询报告
- 验证报告数据与答题记录的一致性
2. 跨模块交互:报告生成时触发的消息通知是否正确发送
3. 数据一致性:并发生成同一用户的报告,结果是否一致
4. 故障恢复:数据库短暂不可用后恢复,未完成的报告是否能正确重试
要求:
- 使用真实数据库(测试专用 schema),不使用 Mock
- 每个测试用例独立,测试前后自动清理数据
- 集成测试与单元测试分离,可独立运行3. E2E 测试(End-to-End Testing)
从用户视角验证完整功能流程。
请编写 E2E 测试(使用 Playwright / Cypress),模拟用户操作验证完整流程:
场景 1:教师生成班级学习报告
1. 教师登录系统
2. 进入"学习报告"页面
3. 选择班级、时间范围
4. 点击"生成报告"
5. 等待生成完成(验证 loading 状态)
6. 验证报告内容正确显示(图表、数据、排名)
7. 点击"导出 PDF",验证下载成功
场景 2:异常路径
1. 未选择班级直接点击生成 → 验证错误提示
2. 选择无数据的时间范围 → 验证空状态展示
3. 网络断开时的降级展示
要求:
- 测试数据通过 API 预置,不依赖手动准备
- 每个场景截图关键步骤,失败时自动保存截图用于排查4. 测试报告与准入门槛
所有测试执行完毕后,请生成测试验收报告(保存为 docs/test-report/{需求名}-report.md):
报告内容:
1. 测试概览:各层测试用例数、通过率
2. 覆盖率数据:行覆盖率、分支覆盖率、函数覆盖率
3. 失败用例分析:失败原因、影响范围、是否阻塞发布
4. 性能数据:核心接口的响应时间 P50/P90/P99
5. 发布建议:是否满足上线条件
上线准入门槛:
- 单元测试通过率:100%
- 集成测试通过率:100%
- E2E 测试通过率:>= 95%(允许非核心场景的 flaky test)
- 核心模块覆盖率:>= 80%
- 无 🔴 级别的 Code Review 问题遗留总结:全链路质量保障体系
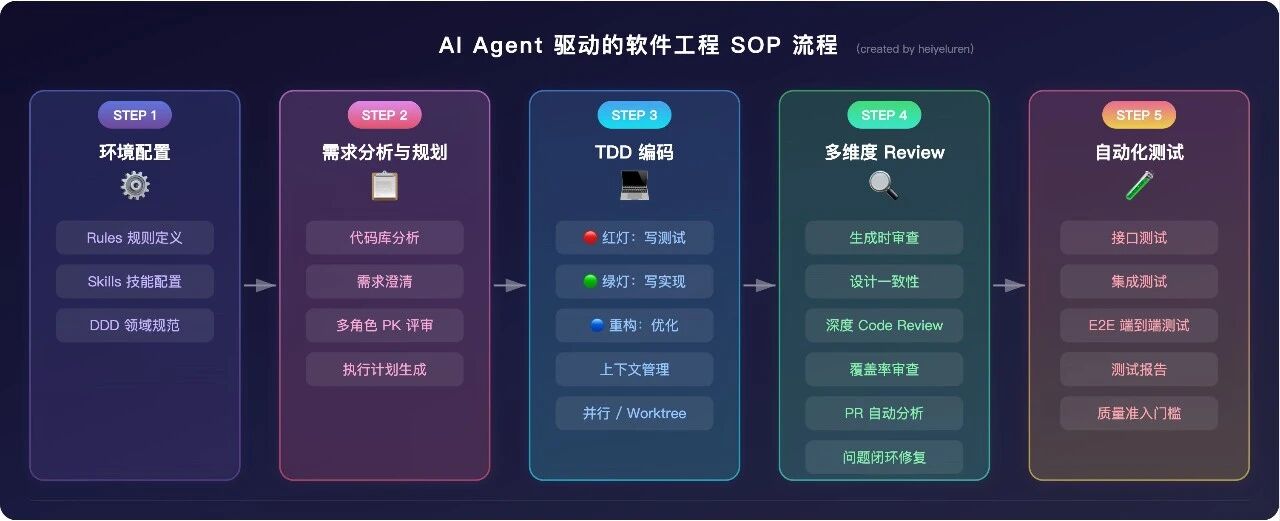
┌─────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ 环境配置 │──→│ 需求分析与规划 │──→│ TDD 编码 │──→│ 多维度 Review │──→│ 自动化测试 │
│ │ │ │ │ │ │ │ │ │
│ Rules │ │ 代码库分析 │ │🔴红灯:写测试 │ │ 生成时审查 │ │ 接口测试 │
│ Skills │ │ 需求澄清 │ │🟢绿灯:写实现 │ │ 设计一致性 │ │ 集成测试 │
│ DDD规范 │ │ 多角色PK评审 │ │🔵重构:优化 │ │ 深度Code Review│ │ E2E测试 │
│ │ │ 执行计划生成 │ │ 上下文管理 │ │ 覆盖率审查 │ │ 测试报告 │
│ │ │ │ │ 并行开发 │ │ PR自动分析 │ │ 准入门槛 │
│ │ │ │ │ Worktree协作 │ │ 问题闭环修复 │ │ │
└─────────┘ └──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘| 原则 | 说明 |
| 人在回路 | AI 是驾驶员,人是领航员,关键决策始终由人做出 |
| 规范先行 | Rules + Skills 定义行为基线,所有 Agent 输出自动合规 |
| 充分规划 | 多角色 PK 评审设计方案,在写代码前消灭返工风险 |
| 精准上下文 | 少即是多,让 Agent 自己搜索,你只补充关键信息 |
| TDD 驱动 | 红-绿-重构循环,每一行代码都有测试保护 |
| 设定可验证目标 | 用测试定义"完成",让 Agent 有明确的迭代方向 |
| 并行推进任务 | Worktree 隔离环境中多 Agent 同时工作,但控制并行度 |
| 多维 Review | 新对话审查 + 不同模型交叉审查 + 人工最终判断 |
| 自动化验证 | 接口 → 集成 → E2E,从单元到全链路层层把关 |
| 问题闭环 | 发现问题必修复,修复后必验证,不留技术债 |
| 果断重来 | 偏离计划时回滚重来,优于在错误基础上修补 |
| 按需裁剪 | 核心路径严格执行,非关键路径灵活裁剪,避免过度流程化 |
提示词沉淀为 Skill
本指南中的许多提示词模板(需求澄清、多角色 PK、TDD 红绿灯、深度 Code Review、覆盖率审查等)如果在项目中反复使用且验证有效,强烈建议将它们封装为正式的 Skill 文件。久经考验的流程值得沉淀——从"每次手动输入提示词"进化为"一个命令触发标准化流程",这不仅减少遗漏,也让团队中的每个人都能复用最佳实践。
# 示例:将 Code Review 提示词封装为 Skill
# SKILL: deep-code-review
## 触发命令: /review
## 执行步骤:
1. 获取当前分支相对于 main 的所有变更文件
2. 逐文件执行正确性、架构合规、安全性、性能、可维护性五维审查
3. 对每个问题标注严重级别(🔴/🟡/🟢)
4. 生成 Review 报告保存到 docs/review/{分支名}-review.md
5. 汇总 🔴 项数量,如果 > 0 则明确提示"不可合并"适合封装为 Skill 的提示词特征:
- 在多个需求迭代中重复使用
- 包含固定的步骤和检查项
- 产出有标准化格式的文档
- 团队多人需要使用同一套流程
【想要讨论AI编程和AI技术加群】访问 WX 公众号后后面有码

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)