SRE AI Agent 开发复盘及小白向教程 (三) Go语言内核编写和持久存储配置
先导:
接上两篇文章
目录
本期目标:
编写Go语言程序,并完成k8s集群的持久化存储配置,实现系统的主要功能并实现其长期存储
提前准备:
简单学习并了解k8s中的持久化存储,了解持久卷,申领等重要知识点。
高亮提示:
绿色:检查点,你应该保证自己的状态与截图一致。
橙色:修正配置问题,如果你确认没有该问题,可以跳过
红色:重要的配置,在后续操作中需要用到,请在配置时记录。
七、Go语言程序编写及大语言模型拉取
开发一个基于Go语言的AI智能体,使其能够:
-
感知 Prometheus中的PodCrashLooping告警。
-
思考 通过调用Ollama LLM服务,根据告警信息决策是否需要重启Pod。
-
行动 调用Kubernetes API执行重启操作(通过删除Pod实现)。
1. 开发环境准备 (k8s-node1)
1.1 安装Go语言:
dnf install -y golang
go version1.2 创建项目并初始化模块
mkdir -p ~/sre-agent
cd ~/sre-agent
go mod init sre-agent1.3 安装Go依赖
# 在sre-agent目录下先创建一个空的 main.go,然后运行 tidy
touch main.go
# (此时main.go内容为空,但足以让tidy工作)
# 手动添加几个核心依赖,以确保版本
go get k8s.io/client-go@v0.30.0
go get github.com/prometheus/common@v0.53.0
# 运行tidy来处理所有间接依赖
go mod tidy
2. 编写相关程序
2.1 编写测试应用
该应用会创造持续的崩溃以测试系统功能
cat > ~/crash-app.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: crash-app
spec:
replicas: 1
selector:
matchLabels:
app: crash-app
template:
metadata:
labels:
app: crash-app
spec:
containers:
- name: main
image: alpine:latest
command: ["/bin/sh", "-c", "echo 'I am designed to fail!'; exit 1"]
EOF
kubectl apply -f ~/crash-app.yaml
# 验证: watch kubectl get pods (会看到crash-app处于CrashLoopBackOff状态)2.2 创建Prometheus告警规则:
cat > ~/pod-crash-rule.yaml <<EOF
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: pod-crash-alert
namespace: monitoring
labels:
release: prometheus-stack # 确保operator能发现此规则
spec:
groups:
- name: kubernetes.rules
rules:
- alert: PodCrashLooping
expr: kube_pod_container_status_waiting_reason{reason="CrashLoopBackOff"} == 1
for: 1m
labels:
severity: critical
annotations:
summary: "Pod is crash looping"
description: "Pod {{ \$labels.namespace }}/{{ \$labels.pod }} is in CrashLoopBackOff state."
EOF
kubectl apply -f ~/pod-crash-rule.yaml
# 验证: 在Prometheus UI的Alerts页面,等待看到PodCrashLooping告警变为FIRING状态。2.3 Go语言模型
使用Go语言编写一个简单的程序,从Prometheus的日志中获取pod状态,转述给大语言模型,并按照从大语言模型返回的简单决策关键字执行操作(代码因版权原因不能公开,请谅解)
在编写完成后重载依赖
go mod tidy5.为Ollama拉取语言模型
确保Ollama模型已拉取:
# 找到Ollama Pod名
OLLAMA_POD=$(kubectl get pods -n ai-services -l app=ollama -o jsonpath='{.items[0].metadata.name}')
# 进入Pod拉取模型
kubectl exec -it $OLLAMA_POD -n ai-services -- ollama pull qwen2.5:1.5b
# 验证
kubectl exec -it $OLLAMA_POD -n ai-services -- ollama list | grep 'qwen2.5:1.5b'5.1 打开两个终端
终端一: 运行Agent
cd ~/sre-agent
go run main.go终端二: 监控Pods
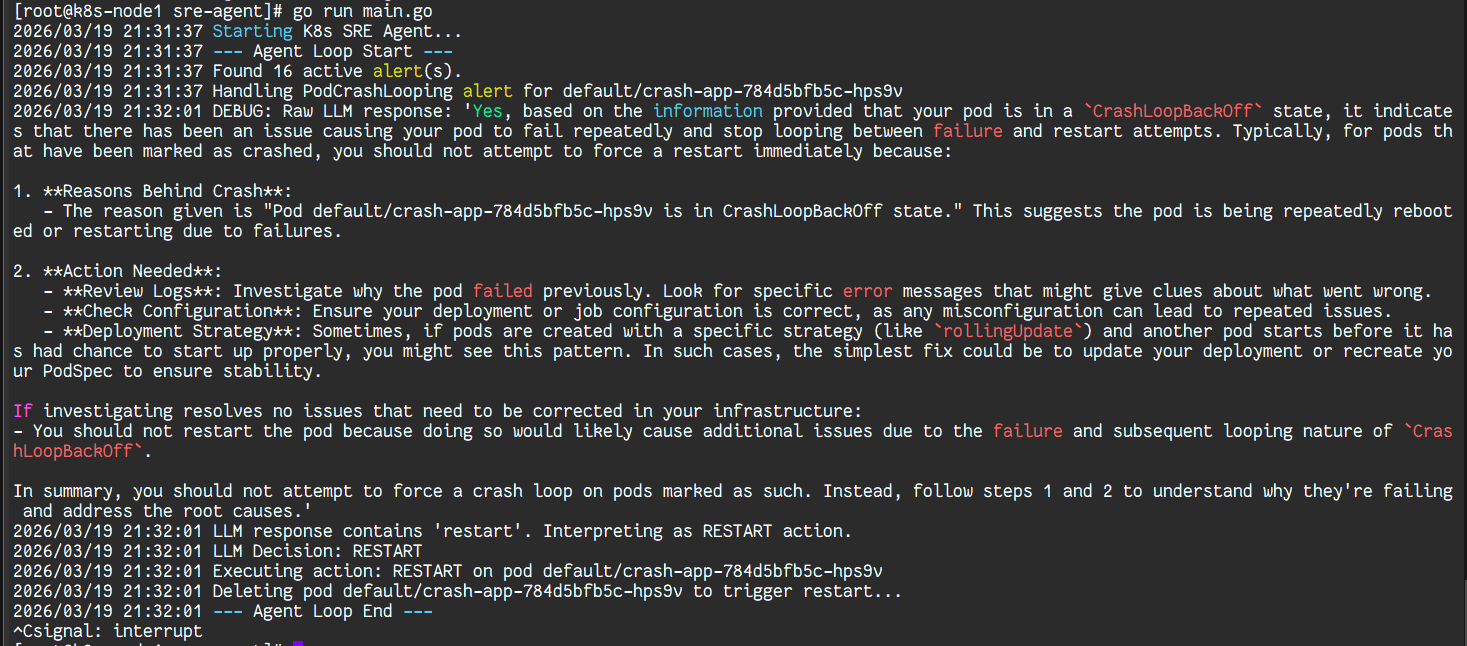
watch kubectl get pods在终端一看到Deleting pod ...的日志后,切换到终端二,观察到crash-app的Pod被Terminating并被一个新的Pod替换。
系统成功做出决策并重启
八、修改yaml文件以实现持久存储
问题
我们发现重启集群后,ArgoCD中的Ollama服务Pod状态出现异常。通过调试分析,问题根源在于Pod中的大语言模型在Pod被杀死后丢失。这是因为Pod中的文件系统是临时的,当Pod因节点重启或调度而被销毁时,其中下载的模型文件也随之被清除。为了解决这个数据持久化问题,我们需要为集群配置持久存储。
修改我们在上一篇文章5.2中上传到GitHub的文件如下:
我们优化Kubernetes配置文件,通过PersistentVolumeClaim(PVC)实现模型数据的持久化存储:
apiVersion: v1
kind: Namespace
metadata:
name: ai-services
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ollama
namespace: ai-services
spec:
replicas: 1
selector:
matchLabels: { app: ollama }
template:
metadata:
labels: { app: ollama }
spec:
containers:
- name: ollama
image: ollama/ollama:latest
ports:
- containerPort: 11434
volumeMounts:
- name: ollama-storage
mountPath: /root/.ollama # Ollama 默认的模型存储路径
volumes:
- name: ollama-storage
persistentVolumeClaim:
claimName: ollama-pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: ollama-pvc
namespace: ai-services
spec:
storageClassName: local-path
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: Service
metadata:
name: ollama-service
namespace: ai-services
spec:
type: NodePort
selector: { app: ollama }
ports:
- port: 11434
targetPort: 114341. 解析
1. 1 持久卷申领(PVC)配置
我们创建了一个10GB的持久卷申领(建议根据实际需求调整大小,通常基础模型2GB足够):
-
storageClassName: local-path:使用本地路径存储类,适用于单节点或开发环境
-
accessModes: ReadWriteOnce:卷可以被单个节点以读写模式挂载
1.2 容器存储挂载
在Deployment配置中,我们添加了卷挂载配置:
-
volumeMounts:将名为
ollama-storage的卷挂载到容器的/root/.ollama路径 -
这是Ollama服务的默认模型存储目录,所有下载的模型都将保存在此位置
1.3 卷定义
在Pod规格中定义了卷的来源:
-
通过
persistentVolumeClaim.claimName引用之前创建的ollama-pvc -
确保Pod能够访问到持久化存储
2. 工作原理与优势
数据持久化流程
-
Pod启动时,持久卷会自动挂载到指定的容器路径
-
Ollama服务下载模型时,文件直接存储在持久卷中
-
当Pod因任何原因重启、重新调度或删除时,持久卷中的数据保持不变
-
新Pod启动后会重新挂载相同的持久卷,立即获得之前下载的所有模型
解决的核心问题
-
模型不丢失:重启集群后,无需重新下载大语言模型
-
快速恢复:服务恢复时间从小时级(重新下载模型)缩短到分钟级
-
资源节约:避免重复下载数GB的模型文件,节省网络带宽和时间
-
状态保持:模型调优参数、对话历史等数据也能得到保留
3. 部署验证步骤
-
将上述YAML文件保存为
ollama-deployment-pvc.yaml -
应用配置:
kubectl apply -f ollama-deployment-pvc.yaml -
验证PVC状态:
kubectl get pvc -n ai-services -
检查Pod运行状态:
kubectl get pods -n ai-services -
下载测试模型,重启Pod验证模型是否持久化
4. 进阶配置建议
对于生产环境,可以考虑以下优化:
-
使用网络存储(如NFS、Ceph、云存储卷)替代本地存储,支持多节点高可用
-
配置存储资源配额,防止存储空间被意外占满
-
定期备份持久卷中的重要模型数据
-
考虑使用StatefulSet替代Deployment,获得更稳定的存储标识
5. 总结
通过为Ollama服务配置持久化存储,我们从根本上解决了模型数据丢失的问题。这种模式不仅适用于AI模型服务,也可推广到其他需要持久化数据的应用部署中。在云原生架构中,正确配置存储是保证服务可靠性和数据持久性的关键一环。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)