[大模型医疗专利]CN 121354772 A 基于大模型的医疗数据质量闭环控制方法及系统 发明人:李旭 曾仔健
发明人:李旭 曾仔健
摘要
本发明涉及一种基于大模型的医疗数据质 量闭环控制系统及方法,属于肿瘤医疗与人工智 能技术领域,解决了现有肿瘤病历质控缺乏肿瘤 专科知识、多模态整合能力和时序逻辑建模,无 法有效专科质控的问题。包括实时交互接口模块 用于获取书写界面的患者ID及诊疗数据,实时捕 获该界面的输入文本内容;用于将最终建议显示 并记录操作信息;安全护栏模块用于对捕获的输 入文本内容进行安全校验,若通过,则将数据传 输至肿瘤循证知识增强大模型模块;用于对初步 建议及其置信度评分进行安全校验及安全过滤 得到最终建议;肿瘤循证知识增强大模型模块用 于基于接收的数据生成任务指令提示词,进而生 成初步建议及其置信度评分。实现了肿瘤医疗数 据质量闭环控制。
技术领域
本发明涉及肿瘤医疗信息技术与人工智能技术领域,尤其涉及一种基于大模型的医疗数据质量闭环控制系统及方法。
背景技术
肿瘤临床病历具有显著的特殊性,其诊疗过程是由初诊、分子检测、治疗、评估、进展等一系列特定临床事件构成的动态序列。这一过程高度依赖跨模态信息(如影像、病理、基因)的整合,并且随着靶向和免疫治疗的发展,病历需要精准记录分子诊断信息、用药依据及疗效评估标准等专科核心要素,对病历的质量和内涵提出了极高要求。
目前,部分医疗机构已尝试将大模型技术应用于病历质控,实现了基础的形式审核和部分内涵质控。然而,这些方案本质上是基于通用医疗大模型构建的,其知识体系(如ICD-O、SNOMED-CT)更新缓慢,且分析模式单一,通常仅处理文本病历,未能有效整合影像、病理、分子检测等多模态数据,也缺乏对肿瘤专科诊疗特有逻辑的深入理解。
现有技术主要存在四大核心缺陷:一是专科深度不足,通用模型无法精准捕捉肿瘤领域快速演进的细粒度知识(如基因变异与药物的匹配关系);二是多模态分析能力缺失,导致信息孤岛问题无法解决,难以发现跨模态矛盾;三是缺乏肿瘤专属的时序建模,无法校验诊疗事件(如确诊、治疗、评估)间严格的时序逻辑;四是反馈机制低效,未针对肿瘤领域的高价值、前沿场景进行定向优化。这些缺陷导致现有系统在处理肿瘤专科病历时,在长上下文推理和复杂规则校验方面存在显著瓶颈。
发明内容
鉴于上述的分析,本发明实施例旨在提供一种基于大模型的医疗数据质量闭环控制系统及方法,用以解决现有肿瘤病历质控缺乏肿瘤专科知识、多模态整合能力和时序逻辑建模,导致无法有效专科质控的问题。
与现有技术相比,本发明至少可实现如下有益效果之一:
1、融合肿瘤循证知识图谱、具备多模态一致性校验、实现时序里程碑建模的专科质控系统,实现对病历书写的实时、智能、闭环式质量控制和规范化引导;
2、构建覆盖"基因-病理-影像-药物-疗效"全链条的肿瘤循证知识图谱,实现专科知识的深度增强;
3、实时校验病历文本与影像、病理、分子检测等多模态报告的一致性;
4、建立肿瘤诊疗里程碑时间轴模型,检测专科特有的时序逻辑冲突;
5、设计高效的闭环反馈机制,使系统持续学习肿瘤领域的边界知识和新兴证据。
本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
附图说明
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
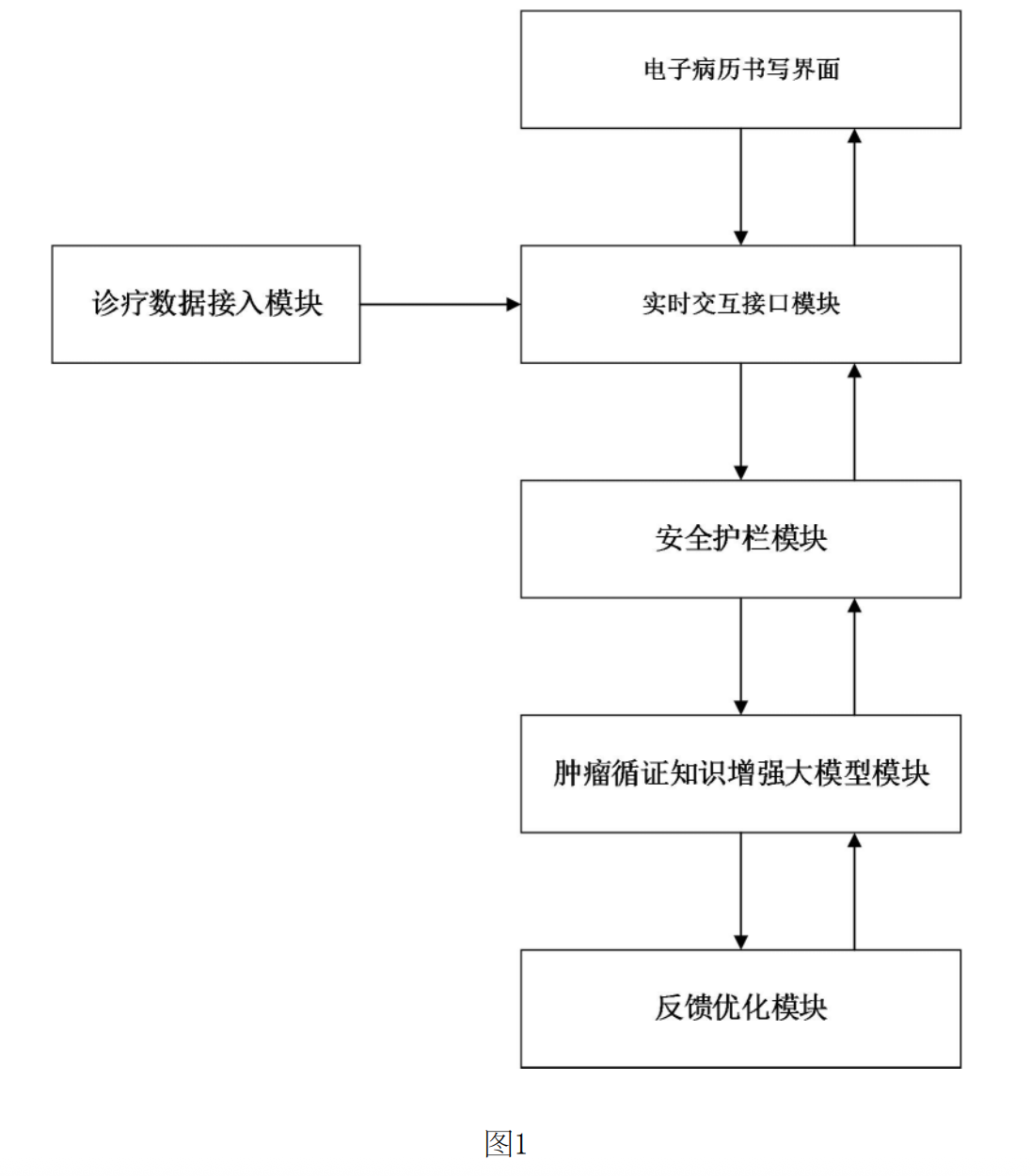
图1为本发明实施例提供的基于大模型的医疗数据质量闭环控制系统的整体架构示意图;
图2为本发明实施例提供的肿瘤循证知识图谱结构示意图;
图3为本发明实施例提供的七大里程碑时间轴模型示意图。
具体实施方式
下面结合附图来具体描述本发明的优选实施例,其中,附图构成本申请一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
实施例1
本发明的一个具体实施例,公开了一种基于大模型的医疗数据质量闭环控制系统,如图1所示,包括:
(1)实时交互接口模块
用于嵌入肿瘤专科电子病历(EMR)书写界面,在医师撰写入院记录、病程记录、治疗记录、疗效评估记录等肿瘤病历时,逐句或逐段实时捕获文本内容,并将捕获的文本及关联的多模态数据发送至后续的肿瘤循证知识增强大模型模块和安全护栏模块进行处理。本模块接收上述模块处理后返回的质控结果,并以高亮提示、侧边栏建议、浮窗警告等形式向医师实时展示。
其中,所述质控结果具体表现为根据风险和重要性等级划分的、包含以下至少一种的分层建议:
a) 强制性建议:针对存在严重错误的场景,如时序逻辑冲突、多模态数据严重矛盾、用药禁忌症等;
b) 推荐性建议:针对内容不规范或欠佳的场景,如医学术语不标准、缺失关键临床信息、诊疗方案与临床指南符合性欠佳等;
c) 优化性建议:针对可进一步提升质量的场景,如病历描述可优化、可补充相关的循证医学依据等。
(2)多模态数据接入模块
当医师通过实时交互接口模块打开特定患者的电子病历时,本模块被触发, 用于根据当前患者的唯一标识(如住院号或患者ID),实时或准实时地从医院信息系统(HIS)、影像归档和通信系统(PACS)、实验室信息系统(LIS)及分子诊断信息系统中,自动获取预设时间窗口内(例如,最近30天内) 的与该患者关联的影像AI结构化报告、病理结构化报告和分子检测报告。
其中,所述报告在从源系统获取时已为结构化或半结构化格式,本模块对其进行解析和标准化,以提取后续处理所需的关键字段信息:影像AI结构化报告包含肿瘤病灶位置、大小(长径×短径)、密度/信号特征、淋巴结状态、远处转移灶分布等DICOM影像的AI自动分析结果;
病理结构化报告包含组织学类型(依据WHO 2021版肺癌分类或WHO 2019版消化系统肿瘤分类等最新标准)、分化程度、浸润深度、脉管侵犯、神经侵犯、切缘状态等;
分子检测报告包含驱动基因突变(如EGFR L858R、KRAS G12C、ALK-EML4融合)、免疫标志物(PD-L1 TPS、TMB、MSI/MMR状态)、拷贝数变异等,变异命名符合HGVS标准。
该模块通过HL7 FHIR、DICOM、自定义API等接口与PACS、LIS、分子诊断系统对接。
(3)肿瘤循证知识增强大模型模块
基座模型:采用LLaMA-3.1-8B或GLM-4-9B等开源大语言模型作为基座。
专科知识增强:
训练语料(总规模>5000万条记录):
中文肿瘤脱敏病历文本180万段(覆盖肺癌、胃癌、乳腺癌、结直肠癌、肝癌等12个常见瘤种);
英文PubMed肿瘤相关摘要420万篇;
NCCN、ESMO、CSCO三大权威指南2020-2024年各版本PDF共1,247份。在本发明的实施过程中,通过光学字符识别(OCR)技术提取PDF中的文本内容,再利用自然语言处理技术(如命名实体识别和关系抽取)对文本进行结构化处理, 形成包含“疾病分期-推荐方案-证据等级”的结构化三元组数据,作为训练本发明所述大模型的核心语料之一。
WHO 2021版肺癌病理分类、WHO 2019版消化系统肿瘤分类等最新病理分型标准;
SNOMED CT Oncology子集(包含肿瘤专科术语);
国家药品编码库、FDA药物标签、ClinicalTrials.gov临床试验数据库(抗肿瘤药物部分);
自建“基因-药物-适应证”知识图谱,包含18万条三元组(如<EGFR 19-del, 敏感, 奥希替尼>、<KRAS G12C, 敏感, 索托拉西布>)。该知识图谱是下文所述的肿瘤循证知识图谱的核心组成部分。
肿瘤循证知识图谱构建:
本发明中,肿瘤循证知识图谱的构建采用半自动化的方法,具体包括:
1. 自动抽取:利用自然语言处理技术(如关系抽取模型)从上述训练语料(尤其是临床指南、药物说明书、PubMed摘要)中自动抽取候选的“实体-关系-实体”三元组。
2. 人工校验:组织肿瘤专科医师团队对自动抽取的候选三元组进行审核、校验和补充,确保其医学准确性。
3. 融合构建:将校验后的三元组与外部标准知识库(如SNOMED CT、国家药品编码库)进行融合,最终形成如下“实体-关系-属性”三层架构的知识图谱:
实体层:基因变异(如EGFR L858R、BRAF V600E)、病理分型(依据WHO最新标准)、影像组学特征(如瘤周毛刺征、空泡征)、TNM分期(第八版)、抗肿瘤药物(通用名+商品名+NCT编号)、疗效评估标准(RECIST 1.1、iRECIST)、不良反应(CTCAE 5.0分级);
关系层:基因-药物敏感性关系、病理-预后关联、分期-治疗模式对应、药物-不良反应因果关系等;
属性层: 证据等级(NCCN 1类/2A类/2B类、CSCO I级/II级/III级、ESMO I/II/III/IV级)、推荐强度、临床试验编号、发表年份等。
指令微调任务(Supervised Fine-Tuning):
本步骤是基于上述专科知识增强语料对基座大模型进行微调的核心过程。通过构建一系列指令微调任务,使模型学习并掌握肿瘤专科领域的特定能力。这些任务既是模型训练的目标,也对应了模型在实际应用中需要执行的核心功能。
训练过程中,采用多任务混合微调(Multi-task Mixed Fine-tuning)策略,即将所有任务的指令数据混合在一起,在每个训练批次中随机采样不同任务的数据进行同步训练。
在实际应用过程中,系统会根据需要执行的任务,将实时捕获的病历文本和关联的多模态数据,自动处理并格式化成与训练时一致的指令格式(即prompt),再输入给微调后的大模型以获取结果。
具体的指令微调任务、所用语料及预处理方式如下:
实体识别与标准化任务:
所用语料: 经过人工标注的中文肿瘤脱敏病历文本。
预处理: 将病历文本片段作为输入(instruction),将其中的医学实体(如疾病、症状、药物、基因变异)及对应的标准编码(ICD-10/ICD-O-3/SNOMED CT)作为输出(output),构建成指令-响应对。例如:{"instruction": "识别并标准化以下文本中的实体:患者诊断为肺腺癌,EGFR 19del突变。", "output": "[{\"text\": \"肺腺癌\", \"label\": \"诊断\", \"code\": \"C34.901\"}, {\"text\": \"EGFR 19del\", \"label\": \"基因变异\", \"code\": \"EGFR:p.E746_A750del\"}]"}。
模型功能: 输入原始病历片段,输出标准化实体及其编码。
分子-药物匹配一致性任务:
所用语料: “基因-药物-适应证”知识图谱、NCCN/ESMO/CSCO指南中的“疾病分期-推荐方案-证据等级”三元组。
预处理: 构建包含“患者基因检测结果+当前用药方案”的输入,并以“一致性判断+指南依据”作为输出。例如:{"instruction": "判断用药一致性:患者基因检测为EGFR 19-del,当前用药为吉非替尼。", "output": "一致。NCCN指南对EGFR 19-del突变非小细胞肺癌患者一线推荐使用EGFR-TKI,吉非替尼为其中之一。"}。
模型功能: 判断用药方案是否符合分子分型,并提供证据。
多模态一致性任务:
所用语料: 成对的“病历文本片段+影像/病理结构化报告”数据,并由专家标注其一致性。
预处理: 将文本描述和结构化报告的关键字段拼接为输入,以一致性校验结果(如“一致”、“矛盾-尺寸差异”、“矛盾-位置差异”)作为输出。例如:{"instruction": "校验一致性:病历描述为'右肺上叶结节约3cm',CT报告显示'病灶长径4.2cm'。", "output": "矛盾-尺寸差异。病历描述尺寸3cm与CT报告尺寸4.2cm差异超过10%阈值。"}。
模型功能: 校验文本与多模态报告间的一致性。
时序里程碑任务:
所用语料: 包含时间戳的诊疗事件序列,并由专家标注其时序是否合理。
预处理: 将事件序列作为输入,以时序合理性判断及理由作为输出。例如:{"instruction": "判断时序合理性:事件A(病理确诊, 2024-03-15),事件B(首次化疗, 2024-03-10)。", "output": "时序冲突。首次系统治疗日期早于病理确诊日期。"}。
模型功能: 判断诊疗事件序列的时序逻辑。
疗效评估规范性任务:
所用语料: 病历中的疗效评估描述,并由专家依据RECIST 1.1等标准标注其是否规范。
预处理: 将疗效描述作为输入,以规范性判断和改进建议作为输出。例如:{"instruction": "判断疗效评估是否规范:'复查CT示病灶较前缩小'。", "output": "不规范。未明确靶病灶直径和及基线对比的百分比变化,不符合RECIST 1.1标准。"}。
模型功能: 判断疗效评估描述是否符合标准。
模型训练:
采用LoRA(Low-Rank Adaptation)高效微调,秩r=64,α=128;
训练轮次:3 epochs;
学习率:2e-4,采用cosine退火策略;
批次大小:32(梯度累积4步);
最大输入长度:4096 tokens(覆盖完整入院记录);
训练硬件:8×NVIDIA A100 80GB GPU,训练时长约120小时。
内部功能单元:
a) 肿瘤医学实体识别与标准化单元:
识别病历文本中的肿瘤专科实体(诊断、分期、病理类型、基因变异、靶向/化疗/免疫药物、检查、症状、疗效评估指标等),并与内置的标准术语库(ICD-10、ICD-O-3、SNOMED CT Oncology子集、HGVS基因命名标准、国家药品编码)进行比对和映射。
技术创新点:针对肿瘤领域,特别处理:
基因变异的多种表述(如"EGFR 19外显子缺失""EGFR exon 19 del""19-del"统一映射为HGVS标准表述);
病理亚型的跨版本映射(如"腺泡型腺癌"在WHO 2015与2021版分类中的对应关系);
抗肿瘤药物的通用名-商品名-临床试验代码三向映射(如"奥希替尼=泰瑞沙=AZD9291")。
b) 肿瘤诊疗时间轴逻辑校验单元:
基于Transformer-CRF联合模型,对肿瘤患者的诊疗事件进行时序建模:
首先,预定义七大里程碑事件:①初诊/症状发现 → ②影像学检查 → ③病理确诊 → ④分子检测 → ⑤首次系统治疗(手术/放疗/化疗/靶向/免疫) → ⑥疗效评估 → ⑦疾病进展/复发/死亡;
然后,设定时序约束规则:
"首次系统治疗"必须晚于"病理确诊"(特殊情况如新辅助治疗需备注);
"疗效评估"须在"首次系统治疗"后4-8周(依据RECIST 1.1);
分子检测报告日期应在病理确诊之后、靶向治疗之前;
最后,冲突检测:若时间戳违反上述约束,生成高优先级警告(如"疗效评估日期2024-03-10早于首次用药日期2024-03-15,请核实")。
c) 多模态图文一致性校验单元:
实时比对病历文本与多模态报告:
影像一致性:提取病历中的病灶描述(位置、大小、数量、性质),与影像AI结构化报告进行NER+数值比对,容差阈值设为±10%(如病历写"3cm"、CT报告"3.2cm"判定一致;但"3cm" vs "4.5cm"判定冲突);
病理一致性:核对病历诊断与病理报告的组织学类型、分化程度是否匹配(如病历写"低分化腺癌"但病理为"高-中分化",则判定冲突);
分子-药物一致性:基于肿瘤循证知识图谱,判断当前用药是否与分子检测结果匹配(如检出"EGFR 20外显子插入"却使用一代EGFR-TKI,生成警告"EGFR 20-ins对一代TKI耐药,推荐使用阿美替尼或铂类化疗")。
d) 指南符合性与证据追溯单元
将当前诊疗方案与NCCN/ESMO/CSCO最新指南进行实时比对:
输入:患者分期+分子标志物状态+当前用药方案;
输出:指南推荐等级(如"NCCN 2A类推荐:EGFR突变晚期NSCLC一线奥希替尼")、证据来源(如"FLAURA研究,NEJM 2018")、偏离警告(如"当前方案为III级推荐,存在I级推荐替代方案")。
e) 规范化建议生成单元
本单元用于综合上述各校验单元的输出结果,生成结构化的分层建议,并通过实时交互接口模块,实时地反馈到医师的电子病历书写界面。
• 强制性建议(红色高亮):时序冲突、多模态严重矛盾、用药禁忌症;
• 推荐性建议(橙色提示):术语不规范、缺失关键信息(如未记录PD-L1表达)、指南符合性欠佳;
• 优化性建议(蓝色浮窗):描述可优化、可补充的循证依据。
建议格式示例:
[强制性]时序冲突:疗效评估记录日期(2024-03-10)早于首次化疗日期(2024-03-15),不符合RECIST 1.1时间窗要求,请核实。
[推荐性]分子-药物不匹配:检测EGFR L858R突变,当前使用培美曲塞+顺铂化疗,NCCN指南I类推荐一线使用奥希替尼(PFS 18.9个月 vs 化疗10.2个月,FLAURA研究),建议调整方案或补充说明。
[优化性]术语标准化:建议将"心梗"修正为"急性心肌梗死(ICD-10:I21.9)"。
(4)安全护栏模块
针对大模型可能产生的幻觉或误判,设置多层安全机制:
a) 高风险硬规则二次验证:
对于药物禁忌、剂量超标、配伍禁忌等高风险场景,采用确定性规则引擎进行二次校验。
其中,所述确定性规则引擎是一种基于预设逻辑规则进行判断的非学习型计算引擎,其输出结果对于相同的输入是固定且可预测的,用以对大模型可能存在的幻觉提供一道硬性安全防线。
具体的实现方式包括:
1. 构建规则库:预先编译和维护一个包含2,300+条肿瘤用药规则的结构化规则库。每条规则以“IF-THEN”逻辑形式存储,规则来源于药品说明书、NCCN化疗指南、临床药师审方经验等权威来源。例如,一条规则可表示为:IF (药物 = '甲氨蝶呤' AND 肌酐清除率 < 30ml/min) THEN (风险 = '禁忌', 建议 = '严重肾功能不全者禁用')。
2. 设计执行器:开发一个规则执行器,该执行器首先从大模型初步处理后的病历文本中提取出结构化信息(如用药名称、剂量、患者肾功能指标等),然后将这些信息作为事实(Facts)输入。执行器遍历规则库,将事实与每条规则的“IF”条件进行匹配,一旦匹配成功,则触发“THEN”部分定义的动作,如生成高风险警报。
b) 置信度评分机制:
针对由肿瘤循证知识增强大模型模块生成的每一条建议(不包括由确定性规则引擎生成的建议), 系统会附带一个量化其可靠性的置信度评分(0-1)。
该置信度评分是基于大模型在生成建议内容时内部输出的概率分布计算得出的。具体的计算方法可以为以下至少一种:
对于生成式任务(如生成建议文本),置信度可以由构成输出序列的所有词元(token)的条件概率的平均值或几何平均值来确定。
对于分类式任务(如判断一致性),置信度可以直接采用模型输出层对最终选定类别(如“一致”或“矛盾”)的Softmax概率值。
一个较高的置信度评分(如0.95)表示模型对其输出有很强的把握,而较低的评分则表示模型对结果不确定,可能存在多个合理的备选项。
每条建议附带置信度评分(0-1):
≥0.9: 直接展示;
0.7-0.9: 展示但标注"建议人工复核";
<0.7: 不展示, 进入专家审核队列。c) 证据溯源:
所有建议强制附带证据来源(如"NCCN NSCLC指南2024.V3,第MS-15页"、"FLAURA研究,DOI:10.1056/NEJMoa1713137"),支持一键跳转原文。
(5)闭环反馈与模型优化模块
a) 反馈数据采集单元:
记录每次交互的完整信息:
• 原始病历文本;
• 系统建议内容及置信度;
• 医师操作(采纳/忽略/修改);
• 多模态报告快照;
• 时间戳与操作医师ID(匿名化)。
b) 智能采样策略(核心创新):
本策略并非对所有病患进行采样,而是对每一次系统生成建议并与医师发生交互的事件记录进行筛选, 以高效地挑选出对模型优化最有价值的样本。采用"不确定性+冲突度+临床价值"三维混合采样:
不确定性: 衡量模型自身对所生成建议的“困惑”程度。具体地,在模型生成建议的每一步(或关键步骤),计算其在词汇表上输出的Softmax概率分布的熵(Softmax Entropy)。 高熵表示模型在多个候选词元间难以抉择,即不确定性高。若一次交互中,模型输出的平均或最大熵值 ≥ 预设阈值Hₜ(例如1.5),则认为该样本具有高不确定性。
冲突度: 衡量医师行为与模型建议之间的差异程度。具体地,通过计算医师最终采纳或修改后的文本与模型原始建议文本之间的莱文斯坦距离(Levenshtein Distance),若编辑距离 ≥ 预设阈值Dₜ(例如15),则认为该样本具有高冲突度,表明模型建议可能存在较大偏差。
临床价值: 衡量当前交互所涉及的病历场景对于推动肿瘤医学知识前沿的重要性。 具体的判定方法是:系统维护一个由肿瘤专科高级医师团队预先定义和持续更新的“高价值临床场景列表”,该列表包含三类场景并定义了其价值等级(如高、中、低)。
高价值场景示例: 罕见驱动基因突变(如HER2外显子20插入)、新上市抗肿瘤药物(上市<2年)的使用、超适应证用药、临床指南中的边界病例(如患者特征跨越两个不同推荐等级的条件)。
判定过程: 肿瘤医学实体识别与标准化单元从当前病历上下文中识别出实体,系统将这些实体与“高价值临床场景列表”进行匹配。若匹配成功,则将该样本的临床价值标记为相应等级。
仅当满足以下条件之一时进入专家标注池:
• 不确定性 AND 冲突度均在top 5%;
• 临床价值=高(由肿瘤专科医师预设的75种高价值场景);
• 医师主动标记"疑难病例"。
效果:相比随机采样,标注量减少约70%,但模型在边界病例上的F1值提升18%。
c) 专家审核与数据标注单元:
采集到的数据推送至肿瘤专科高级医师(副主任及以上职称,或5年以上肿瘤科工作经验):
• 判断系统建议的准确性(正确/部分正确/错误);
• 修正或补充标准答案;
• 标注依据(引用指南章节、文献DOI、临床共识)。
d) 增量LoRA微调单元:
每季度(或累积标注样本≥5,000例时)触发一次增量微调:
• 采用LoRA适配器叠加策略,保留基座模型参数不变;
• 新LoRA秩r=32(低于初始训练以防过拟合);
• 学习率:5e-5(低于初始训练);
• 验证集:保留20%专家标注数据用于评估;
• 上线策略:A/B测试,新模型在验证集F1 ≥旧模型+2%时方可替换。
e) 模型版本管理:
• 所有历史版本保留90天;
• 支持快速回滚;
• 生成版本对比报告(各指标差异、badcase分析)。
与现有技术相比,本实施例具有以下显著有益效果:
智能化与精准度高:基于医疗知识增强的大模型,能够深度理解病历上下文和医学逻辑,显著提高了质控的准确性和智能化水平,避免了传统规则引擎的僵化和局限性;
实时交互性强:将质量控制从事后审查前置到事中干预,通过实时引导,帮助医师在第一时间写出高质量、标准化的病历,提升工作效率,培养规范书写习惯。
闭环自优化能力:独创的“医师交互-专家审核-模型微调”闭环反馈机制,使系统能够从临床实践中持续学习,自我迭代和进化,不断适应新的医学知识和诊疗场景,保证了系统的长期有效性和先进性。
提升数据价值:通过源头上的数据规范化,极大提升了医疗数据的同质性和可用性,为后续的临床科研、医院精细化管理、以及人工智能应用奠定了坚实的数据基础。
实施例2
本发明的一个具体实施例,公开了一种基于大模型的医疗数据质量闭环控制方法,包括以下步骤:
步骤S1:实时文本获取与多模态数据关联
• 实时交互接口模块逐句捕获病历文本;
• 多模态数据接入模块根据患者ID调取最近7天内的影像、病理、分子检测报告;
• 若存在新报告未被引用,生成提示"检测到新报告, 建议补充至病历"。其中,“新报告未被引用”的判定逻辑为:系统将多模态数据接入模块获取的在预设时间窗口内(例如过去7天)生成的所有报告,与医师当前正在撰写以及历史已归档的病历文本进行比对。如果系统发现某一份报告(例如一份新的病理报告)的关键信息,如报告编号、检查日期、或其核心结论(如“肺腺癌”),在所有相关病历文本中均未被提及或引述,则判定该报告为“未被引用”。
步骤S2:多维度并行校验
肿瘤知识增强大模型模块调用5个功能单元并行执行:
• 实体识别与标准化(耗时<0.3s);
• 时间轴逻辑校验(耗时<0.5s);
• 多模态一致性校验(耗时<0.8s);
• 指南符合性判断(耗时<1.0s);
• 安全护栏硬规则验证(耗时<0.2s)。
总响应时间<2s(满足临床实时性要求)。
步骤S3: 分层建议生成与展示
规范化建议生成单元整合各单元输出,并根据预设的优先级进行排序。三种建议的优先级由高到低依次为:强制性建议 > 推荐性建议 > 优化性建议。
通过交互接口以差异化方式展示:高优先级的强制性建议以模态对话框(弹窗)形式呈现,可能需要医师确认后才能继续操作;中等优先级的推荐性建议显示在病历编辑区侧边栏;低优先级的优化性建议则以不打扰操作的浮窗或下划线形式提示。
医师可点击"查看依据"跳转至指南原文或文献。
• 通过交互接口以差异化方式展示:强制性建议弹窗拦截,推荐性建议侧边栏,优化性建议浮窗;
步骤S4:用户反馈自动收集
• 闭环反馈模块记录医师的每次操作;
• 计算不确定性、冲突度、临床价值三个维度得分;
• 满足采样条件的样本自动进入专家审核队列,其他仅做统计分析。
步骤S5:专家标注与质量控制
• 专家通过标注平台审核待标注样本;
标注结果经双人盲审,一致性κ值需≥0.85。该一致性κ值通过以下标准化流程获得:
1. 样本选取:从待审核的样本池中随机抽取一定数量(例如100例)的样本。
2. 独立标注(盲审):将选取的样本分别分发给两名背景相似的肿瘤专科医师(审核员A和审核员B)。两位审核员在互不知晓对方标注结果的情况下,独立对每个样本的系统建议进行判断(例如,标注为“正确”、“部分正确”、“错误”三类之一)。
3. 计算观测一致性(Pₒ):统计两位审核员标注结果完全一致的样本数量,除以总样本数,得到观测一致性比例。
4. 计算期望一致性(Pₑ):分别统计两位审核员将样本标注为各个类别的比例,然后计算在随机情况下他们达成一致的概率。例如,Pₑ = P(A判正确)×P(B判正确) + P(A判部分正确)×P(B判部分正确) + P(A判错误)×P(B判错误)。
5. 计算Kappa值:应用科恩卡帕系数(Cohen's Kappa)公式 κ = (Pₒ - Pₑ) / (1 - Pₑ) 进行计算。该值衡量了超越机遇的真实一致性水平。κ值≥0.85通常被认为达到了非常高的一致性。
争议样本由科主任仲裁。步骤S6:季度增量微调与上线
• 累积足够标注样本后触发增量LoRA微调;
• 在验证集上评估,计算实体识别F1、一致性检测Accuracy、指南符合性Recall@K等指标;
• A/B测试通过后灰度上线(先10%用户,逐步扩大至100%)。
步骤S7:效果评估与持续监控
• 每月生成质控报告:病历平均缺陷数下降率、医师采纳率、专家标注一致性等KPI;
• 监控模型输出分布,检测concept drift(如新药大量上市导致知识过时);
• 触发条件时重启完整训练流程。
实施例3
为说明实施例1和实施例2所提系统和方法的有效性,在实际场景中进行使用和验证,能够得到显著的显著效果,具体为:
肿瘤专科深度显著优于通用方案:通过5000万条肿瘤专科语料、18万条基因-药物知识图谱的深度训练,在肿瘤实体识别F1值达0.932(通用模型约0.78),药物-基因冲突检测准确率96.4%(通用模型约82%);覆盖WHO 2021最新病理分类、NCCN/ESMO/CSCO 2024版指南等最新知识,知识更新速度比传统规则系统快6-12个月。
多模态一致性校验填补行业空白:首次实现病历文本与影像、病理、分子检测三类报告的实时一致性核对;影像基因组学研究表明肿瘤异质性可通过影像特征预测基因表达模式,本系统通过图文一致性校验,间接提升了病理-影像-分子信息的整合质量,人机一致性κ值达0.89(vs中级职称医师双评)。
时间轴里程碑建模解决专科特有问题:针对肿瘤诊疗的严格时序依赖,创新性构建七大里程碑事件模型,时序冲突检出率98.1%,假阳性率<3%;在某三甲医院肿瘤科试点中,发现并纠正127例"疗效评估时间不符合RECIST 1.1"的错误,避免了潜在的临床试验数据质量问题。
智能采样策略大幅提升闭环效率:"不确定性+冲突度+临床价值"三维采样使标注量减少70%,但模型在罕见突变、新药使用等高价值场景的F1提升18%;季度微调周期使系统快速适应新上市药物(如2024年批准的ADC类药物)和指南更新,保持持续先进性。
安全护栏机制保障临床安全: 高风险场景硬规则二次验证,5个月试点期间拦截药物禁忌11例、剂量错误23例,零漏报;证据溯源功能使每条建议可追溯至指南章节或文献DOI,提升医师信任度,,建议采纳率从初期的58%提升至82%。
数据质量提升带来显著临床价值:试点医院肿瘤科病历平均缺陷数从3.2条/份下降至0.8条/份,下降75%;病历书写时间减少约20%(从平均45分钟降至36分钟);规范化后的数据可直接用于真实世界研究(RWS)、DRG/DIP支付,数据二次利用率提升60%。
本领域技术人员可以理解,实现上述实施例方法的全部或部分流程,可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读存储介质中。其中,所述计算机可读存储介质为磁盘、光盘、只读存储记忆体或随机存储记忆体等。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)