[特殊字符] 当 AI 拥有「过目不忘」:OpenClaw 记忆系统完全指南
📢 从「上下文爆炸」到「精准召回」——一场 AI 记忆的范式革命
📌 先说结论
| 维度 | 传统方式 | QMD |
|---|---|---|
| Token 削减 | 0%(全文塞入) | 60-97%(平均95%+) |
| 响应速度 | 5-120秒 | 1-3秒(快5-50倍) |
| 精准度 | ~59% | 93% |
| API成本 | $0.05-8/次 | 降低90-99% |
一、背景:AI 记忆的「阿喀琉斯之踵」
1.1 传统记忆系统的困境
当你让 AI「记住一些事情」时,业界通常做法是:传统方案:把整个 MEMORY.md 塞进上下文用户说:"帮我写个函数",AI 会收到一个包含 5000 tokens 的 MEMORY.md 文件,里面记录了:
- ●五哥喜欢简洁的回答
- ●老家在江西赣州石城
- ●项目A:XXX
- ●项目B:YYY
- ●2024年1月的讨论:ZZZ
- ●...(与当前需求无关的噪音)
- ●当前需求:帮我写个函数 ← 关键信息在这里!
结果:90% 内容与当前问题无关,AI 被噪音淹没三大痛点:
- 上下文膨胀:Token 随会话指数增长
- 成本爆炸:10K tokens → $0.5,100K tokens → $6-8
- 精准度下降:噪音越多,AI 越容易「跑偏」
1.2 OpenClaw 的记忆演进
OpenClaw 的记忆系统经历了三代进化:
| 时代 | 方案 | 特点 |
|---|---|---|
| 第一代 | 纯文件存储 | Markdown 文件简单读取,无索引 |
| 第二代 | SQLite向量 | 向量语义搜索,需要 Ollama |
| 第三代 | QMD混合引擎 | BM25 + 向量 + 重排序,本地 LLM 重排序,完全离线 |
二、lossless-claw:会话级「无损记忆」
2.1 核心定位
lossless-claw 解决的是「单次会话内的长对话连续性」问题。场景:和 AI 讨论 3 小时的代码优化项目
- ●10:00 —— 讨论了 Redis 缓存策略
- ●10:30 —— 讨论了数据库索引优化
- ●11:00 —— 讨论了 API 速率限制
- ●11:30 —— 讨论了负载均衡方案
- ●12:00 —— "我们最初定的缓存策略是什么?"
❌ 没有 lossless-claw:AI 忘得一干二净✅ 有 lossless-claw:可以通过 lcm_expand 回溯原始对话
2.2 技术原理:DAG 摘要图谱
lossless-claw 的核心创新是有向无环图(DAG)摘要:Step 1: 全量存储
- ●所有消息原始存储到 SQLite,永不删除
Step 2: 分层摘要
- ●每8条消息压缩成1个叶子节点摘要
- ●例如:"讨论了 Redis 缓存,定了 1 小时 TTL"
Step 3: 构建 DAG
- ●根摘要:汇总所有叶子摘要
- ●叶子摘要:保留原始消息指针,可回溯
2.3 动态组装「工作记忆」
每次对话时,lossless-claw 精心组装上下文:发送给 AI 的上下文包含三个部分:
- [系统提示] - 系统级指令
- [DAG 摘要] - 提供宏观对话脉络
- ●"今天讨论了:
- ●Redis 缓存策略 (TTL=1h)
- ●数据库索引优化
- ●API 速率限制 (100req/s)"
- [最近 N 条原始消息] - 保证当前任务细节
- ●"User: 帮我优化缓存策略
AI: 建议使用 Redis,设置 TTL..."总 Token: 30K-100K(可控)
2.4 按需回溯工具
AI 可以主动「回忆」:
| 工具 | 功能 |
|---|---|
lcm_grep |
在历史中搜索关键词 |
lcm_describe |
查看某个摘要节点详情 |
lcm_expand |
展开摘要,回溯原始消息 |
三、QMD:跨会话「知识沉淀」
3.1 核心定位
QMD (Query Markup Documents) 解决的是「跨会话的知识库」问题。场景:三个月前讨论的项目方案,新会话中需要调用
- ●Day 1: 讨论项目方案
- ●AI: "我们确定了 API 路由:/users,GET/POST 方法..."
- ●Day 90: 写前端代码
- ●User: "帮我写个调用用户 API 的 fetch"
❌ 没有 QMD: AI: "抱歉我不知道 API 格式"✅ 有 QMD: AI: "根据之前保存的规范,API 是..."
3.2 技术原理:三层混合检索
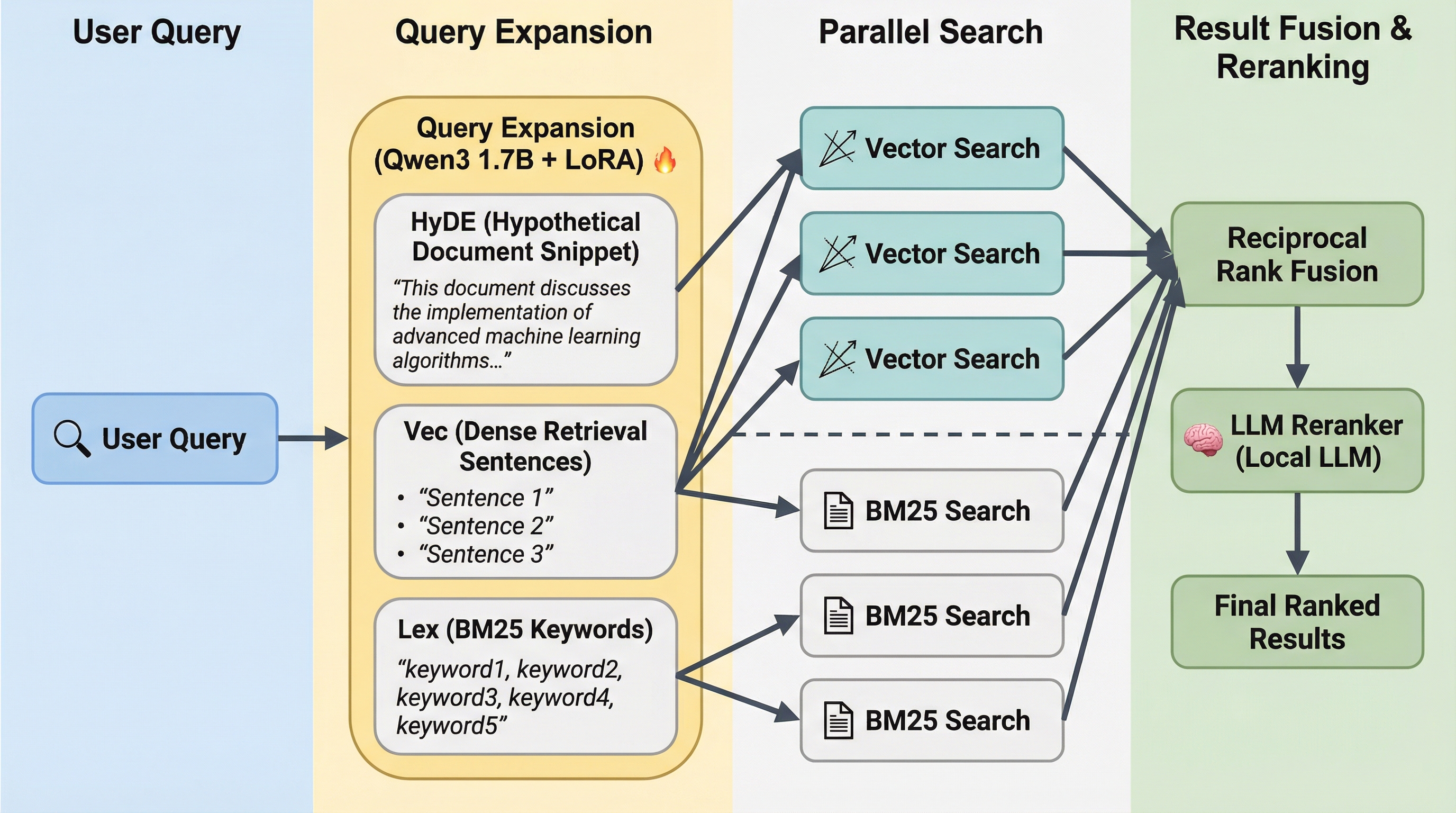
QMD 是本文重点,它的架构非常精妙:查询流程:
- Query Expansion(查询扩展)
- ●输入: "authentication"
- ●LLM 生成变体: ["user login process", "authentication flow"]
- 并行检索
- ●原始查询 + 扩展查询 同时在 BM25 和向量索引中搜索
- ●多个搜索结果并行获取
- RRF 融合 (Reciprocal Rank Fusion)
- ●score = Σ(1 / (k + rank)),k = 60
- ●加上排名奖励: #1 → +0.05, #2-3 → +0.02
- Top 30 候选 → LLM 重排序
- ●Prompt: "Does this document answer the query?"
- ●Yes/No + logprob confidence
- Position-Aware Blend(位置感知融合)
- ●Rank 1-3: 75% RRF + 25% Reranker ← 保留精确匹配
- ●Rank 4-10: 60% RRF + 40% Reranker
- ●Rank 11+: 40% RRF + 60% Reranker ← 信任重排序
3.3 核心技术细节
3.3.1 Query Expansion(查询扩展)
输入: "authentication"↓LLM (1.7B GGUF 模型) 处理↓输出: ["user login process", // LLM 生成的变体"authentication flow" // 语义等价变体]
3.3.2 智能分块(Smart Chunking)
QMD 不是粗暴地按 token 切分,而是语义感知分块:分块边界得分规则:
- ●# Heading → 100 分 (最强边界)
- ●## Heading → 90 分
- ●代码块 → 80 分
- ●--- 分割线 → 60 分
- ●空白行 → 20 分
- ●普通换行 → 1 分 (最弱)
目标: ~900 tokens,搜索 200-token 窗口内最高得分的边界代码块保护: 代码块内的内容永不被分割!
3.3.3 本地 LLM 模型
QMD 依赖三个本地 GGUF 模型(自动下载):
| 模型 | 用途 | 大小 |
|---|---|---|
| embeddinggemma-300M-Q8_0 | 向量化 | ~300MB |
| qwen3-reranker-0.6b-q8_0 | 重排序 | ~640MB |
| qmd-query-expansion-1.7B-q4_k_m | 查询扩展 | ~1.1GB |
总计约 2GB,完全本地运行,无需联网(首次下载后)使用Qwen3-Embeding模型对中文更友好
# Use Qwen3-Embedding-0.6B for better multilingual (CJK) support
export QMD_EMBED_MODEL="hf:Qwen/Qwen3-Embedding-0.6B-GGUF/Qwen3-Embedding-0.6B-Q8_0.gguf"
# After changing the model, re-embed all collections:
qmd embed -f
3.4 实测数据对比
场景一:长期会话记忆查询
| 指标 | 传统方式 | QMD | 提升 |
|---|---|---|---|
| 上下文大小 | 80,000+ tokens | 4,000 tokens | 削减 95%+ |
| 响应时间 | 45秒(超时失败) | 2秒 | 快 20+ 倍 |
| API 成本 | $2.4 | $0.01 | 降低 200+ 倍 |
| 成功率 | 失败 | 成功 | ✅ |
场景二:跨文件知识检索
| 指标 | 传统方式 | QMD | 提升 |
|---|---|---|---|
| 上下文大小 | 15,000+ tokens | 1,500 tokens | 削减 90%+ |
| 响应时间 | 25-30秒 | 3秒 | 快 10 倍 |
| 稳定性 | 容易触发 rate limit | 从不卡死 | ✅ |
场景三:日常对话
| 指标 | 传统方式 | QMD | 提升 |
|---|---|---|---|
| 上下文大小 | 5,000+ tokens | 250 tokens | 削减 95%+ |
| 响应时间 | 8-10秒 | 1秒 | 快 8-10 倍 |
3.5 精准度分析
精准度对比:
- ●混合搜索 (BM25 + 向量 + 重排序): 93% ████████████████████░░
- ●纯向量搜索: 59% ██████████░░░░░░░
为什么混合搜索更强?
- ●BM25: 精确匹配关键词(如代码、ID、术语)
- ●向量: 语义理解("登录" ≈ "authentication")
- ●重排序: LLM 二次把关,筛选真正相关的结果
四、两者联合:1 + 1 > 2
4.1 职责互补
| 维度 | lossless-claw | QMD |
|---|---|---|
| 核心目标 | 会话内长对话连续性 | 跨会话知识沉淀 |
| 数据形态 | 原始消息 + DAG 摘要 | Markdown + 向量索引 |
| 生命周期 | 会话级 | 永久跨会话 |
| 召回方式 | 主动回溯 (lcm_expand) | 自动语义搜索 |
| 本质 | 「过程」记忆 | 「结果」记忆 |
4.2 联合 workflow
完整工作流:
- Step 1: 对话进行中 (lossless-claw 工作)
- ●User ↔ AI ↔ User ↔ AI ...
- ●原始消息存入 SQLite + 构建 DAG 摘要
- Step 2: 知识沉淀 (QMD 介入)
- ●"把确定的 API 规范保存下来"
- ●AI → 生成 API-规范.md → QMD 索引
- Step 3: 新会话开始
- ●QMD: "根据之前保存的规范,API 是..." → 自动注入
- ●+ lossless-claw: 管理当前新会话的上下文
五、安装指南
5.1 前提条件
✅ OpenClaw ≥ 2026.2.2
✅ Bun 或 Node.js ≥ 22
✅ SQLite ≥ 3.40.0 (带扩展)
5.2 安装 Lossless-claw
# 安装Lossless-claw
openclaw plugins install @martian-engineering/lossless-claw
# 配置 openclaw
5.3 安装步骤
# 1. 安装 QMD (推荐 Bun)
bun install -g @tobilu/qmd
# or
npm install -g @tobilu/qmd
# 2. 安装支持扩展的 SQLite
# macOS
brew install sqlite
# Linux
sudo apt install sqlite3
# Windows: 访问 SQLite 官网下载页面 https://www.sqlite.org/download.html
# 下载 "Precompiled Binaries for Windows" 中的 sqlite-tools-win-x64-*.zip
# 解压到任意目录(例如 C:\sqlite)
# 将该目录添加到系统 PATH 环境变量
# 3. 验证
sqlite3 --version
qmd --version
# 4. 配置 OpenClaw
# 在 openclaw.json 中添加:
{
"memory": {
"backend": "qmd",
"qmd": {
"limits": {
"timeoutMs": 8000
}
}
}
}
# 5. 重启
openclaw gateway restart
六、结论与建议
6.1 何时开启 QMD?
| 场景 | 推荐 |
|---|---|
| 会话历史超过 10K tokens | 🔴 必须 |
| 经常遇到响应慢/卡死 | 🔴 必须 |
| 单次请求成本超过 $1 | 🔴 必须 |
| 日常简单对话 | 🟡 可选 |
6.2 最终建议
最佳实践路径:
- ●当前配置 (够用):
- ●lossless-claw (会话级) + Builtin SQLite (基础搜索)
- ●升级配置 (更强):
- ●lossless-claw (会话级) + QMD (混合搜索)
- ●= 过目不忘 + 精准知识召回
📚 参考资料

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)