计算机毕业设计源码:Python 二手房源数据智能分析预测平台 Flask框架 scikit-learn机器学习 可视化 爬虫 SVR算法 房子 房屋 大数据(建议收藏)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
Python语言、Flask框架、scikit-learn机器学习、房价预测模型采用SVR算法(支持向量回归)、DrissionPage网络爬虫库、ECharts可视化工具、二手房数据源
功能模块
· 用户登录
· 房源数据分析系统首页
· 项目界面
· 数据中心
· 价格分析
· 面积分析
· 房源标签分析
· 房屋特征分析
· 房价预测
· 爬虫管理
项目介绍
房源数据分析系统是一个基于Python与Flask框架构建的综合性二手房数据可视化平台。系统通过DrissionPage爬虫库自动采集二手房信息,并提供数据总量与爬虫进度等监控功能。平台围绕房源核心维度展开分析,包括价格、面积、户型、朝向、楼层及标签等,借助ECharts实现柱状图、环形图、词云图及3D动态球形图等多种可视化形式,直观展示房源分布与特征关系。系统还集成了基于SVR算法的房价预测模型,支持用户输入房屋特征进行价格预估。从用户登录到数据检索、从统计分析到智能预测,平台为二手房研究提供了完整的数据支持与分析工具。
2、项目界面
房源数据分析仪表盘
该页面为房源数据分析仪表盘,展示房源总数、平均总价、平均单价与平均面积等核心统计数据,并通过环形图呈现户型分布与朝向分布,借助柱状图分别展示楼层分布和房源标签分布,为用户提供直观的房源数据可视化分析功能。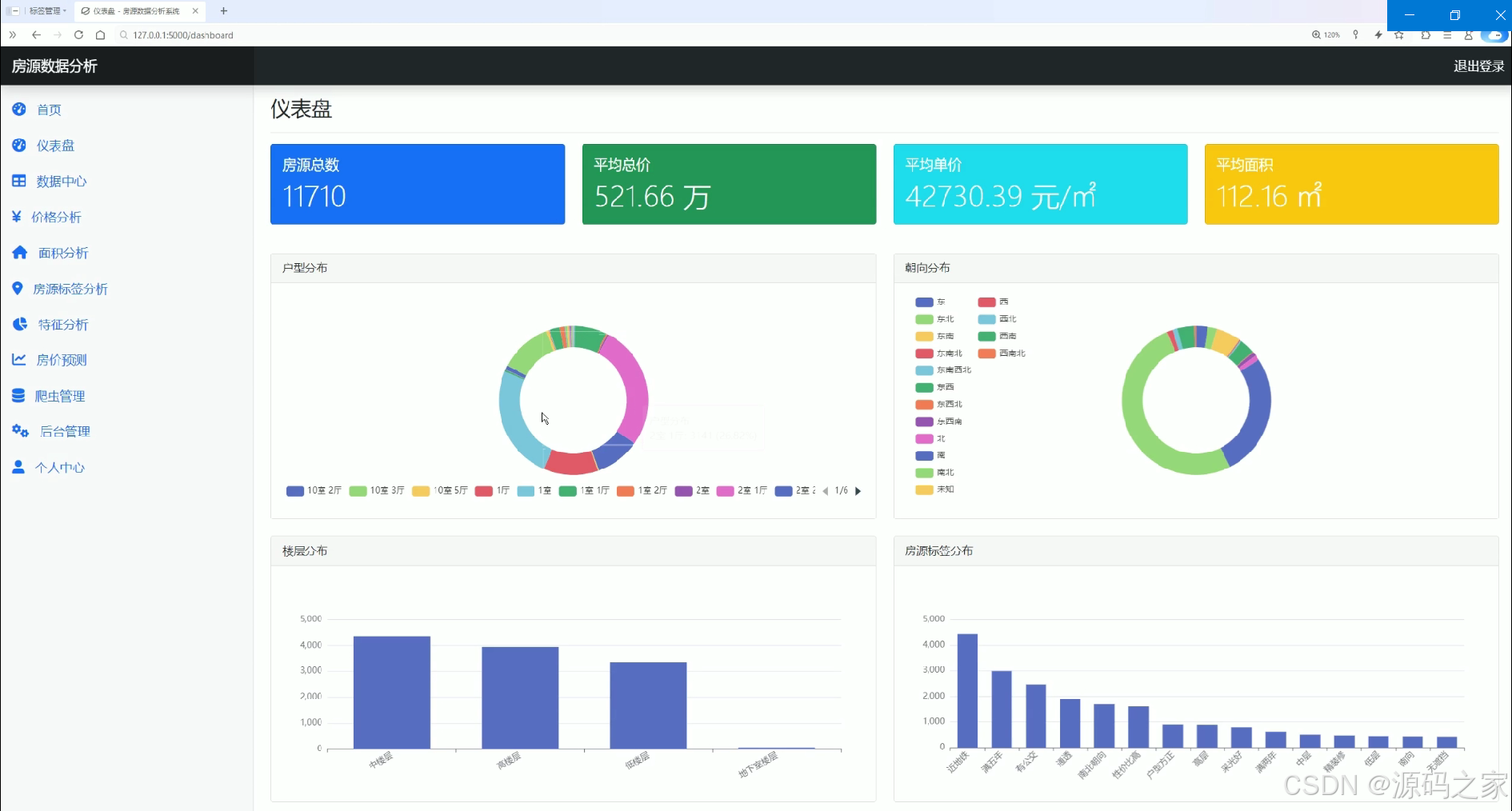
数据中心
该页面为房源数据分析系统的数据中心,设有城市、楼层、户型、朝向等筛选条件及关键词搜索功能,以表格形式展示房源ID、名称、城市、地址、楼层、户型、面积、朝向、总价和单价等详细数据,支持房源信息的检索与查看。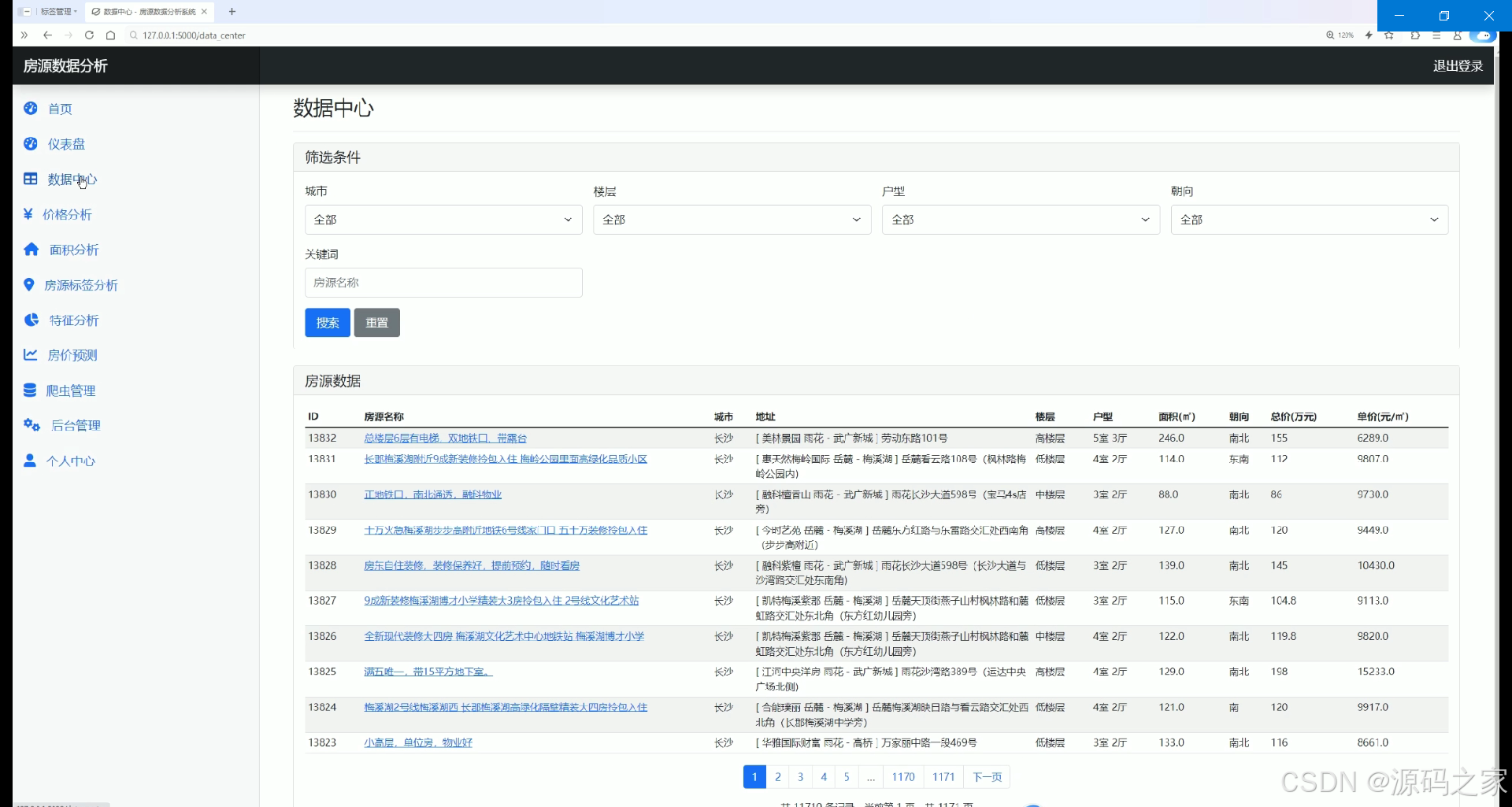
价格分析
该页面为房源数据分析系统的价格分析模块,展示平均总价、平均单价、最高总价和最低总价等核心价格指标,通过柱状图分别呈现房源总价分布与单价分布情况,直观反映不同价格区间的房源数量占比,为用户提供房源价格维度的可视化分析功能。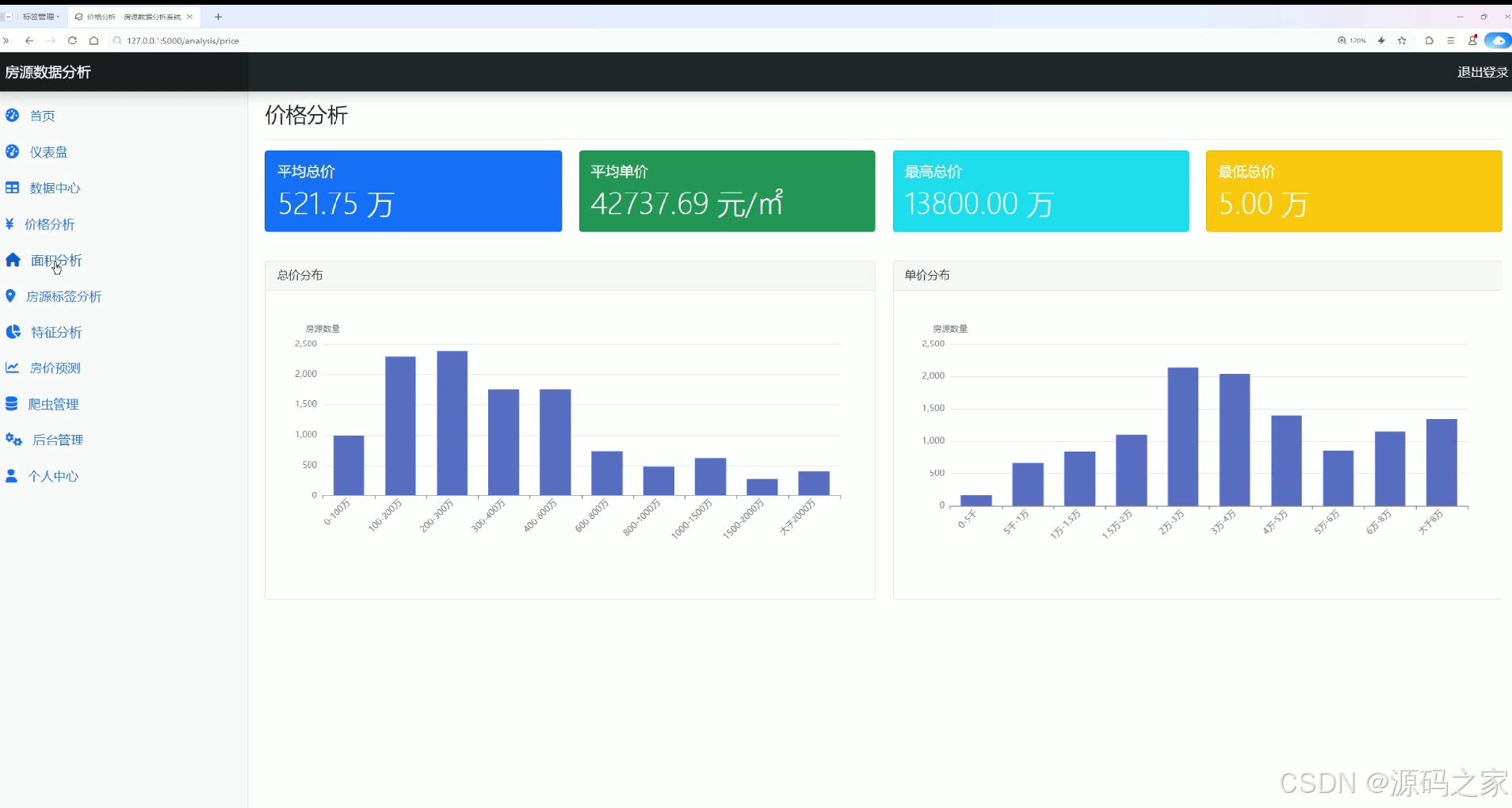
房源数据分析系统首页
该页面为房源数据分析系统的首页,设有进入仪表盘和查看数据的快捷入口,介绍了智能爬虫、深度分析、智能预测的系统特色,同时展示价格分析、面积分析、位置分析、标签分析等核心功能模块,向用户呈现系统的整体功能框架与核心价值。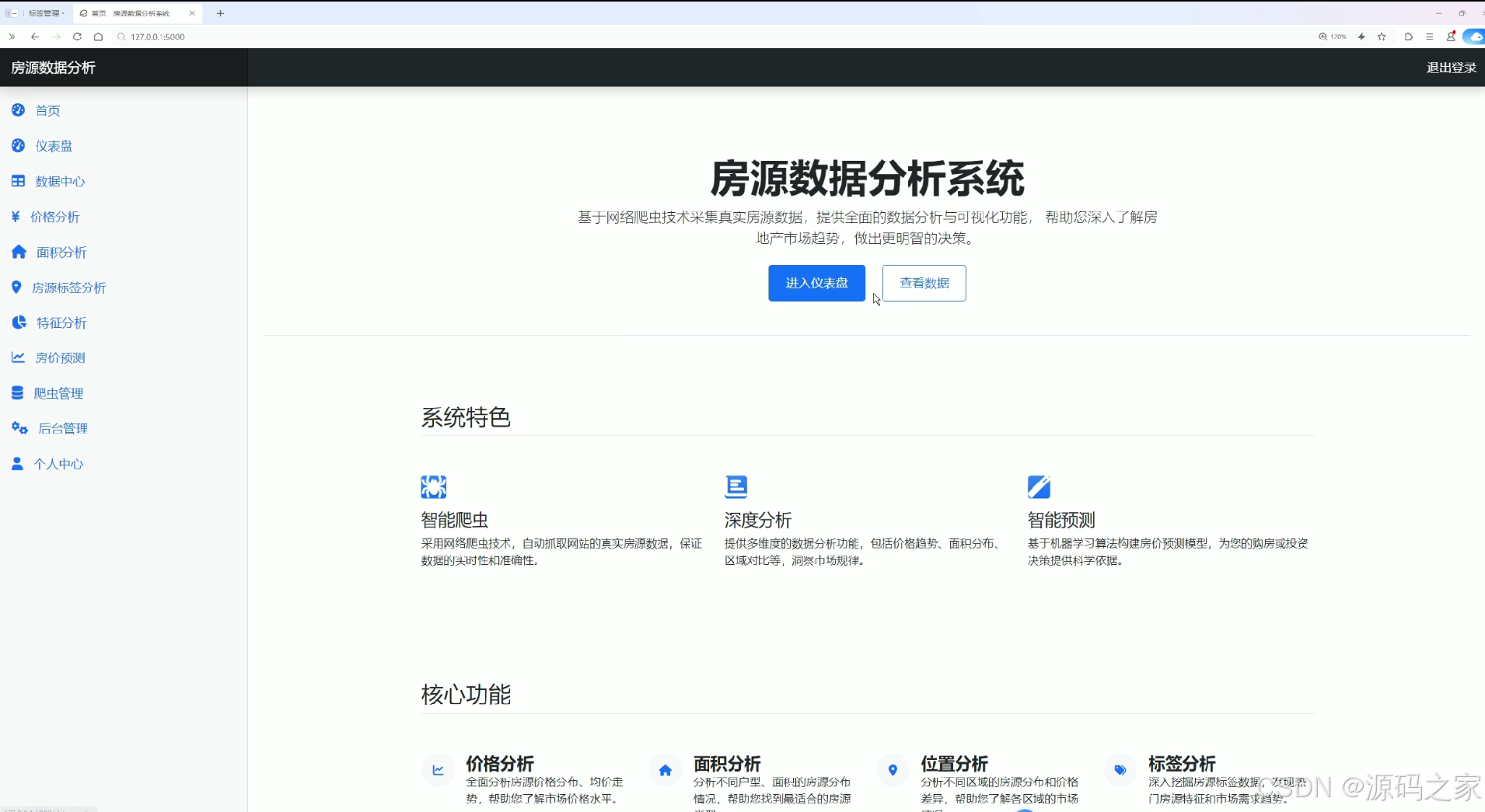
面积分析
该页面为房源数据分析系统的面积分析模块,展示平均面积、最大面积、最小面积等核心面积指标,通过柱状图呈现房源面积分布情况,利用环形图展示户型分布,直观呈现不同面积区间房源数量及不同户型的占比情况。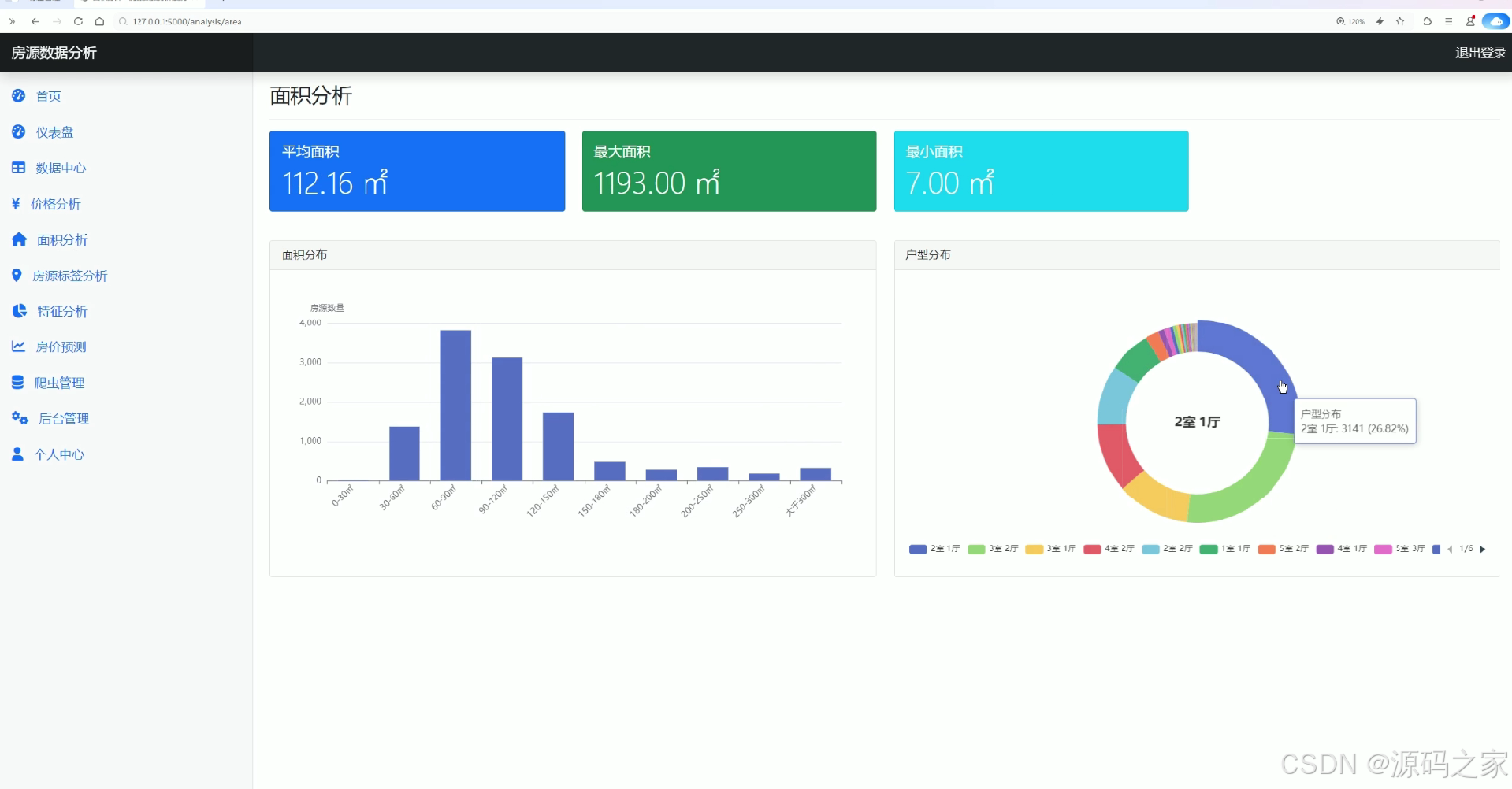
房源标签分析
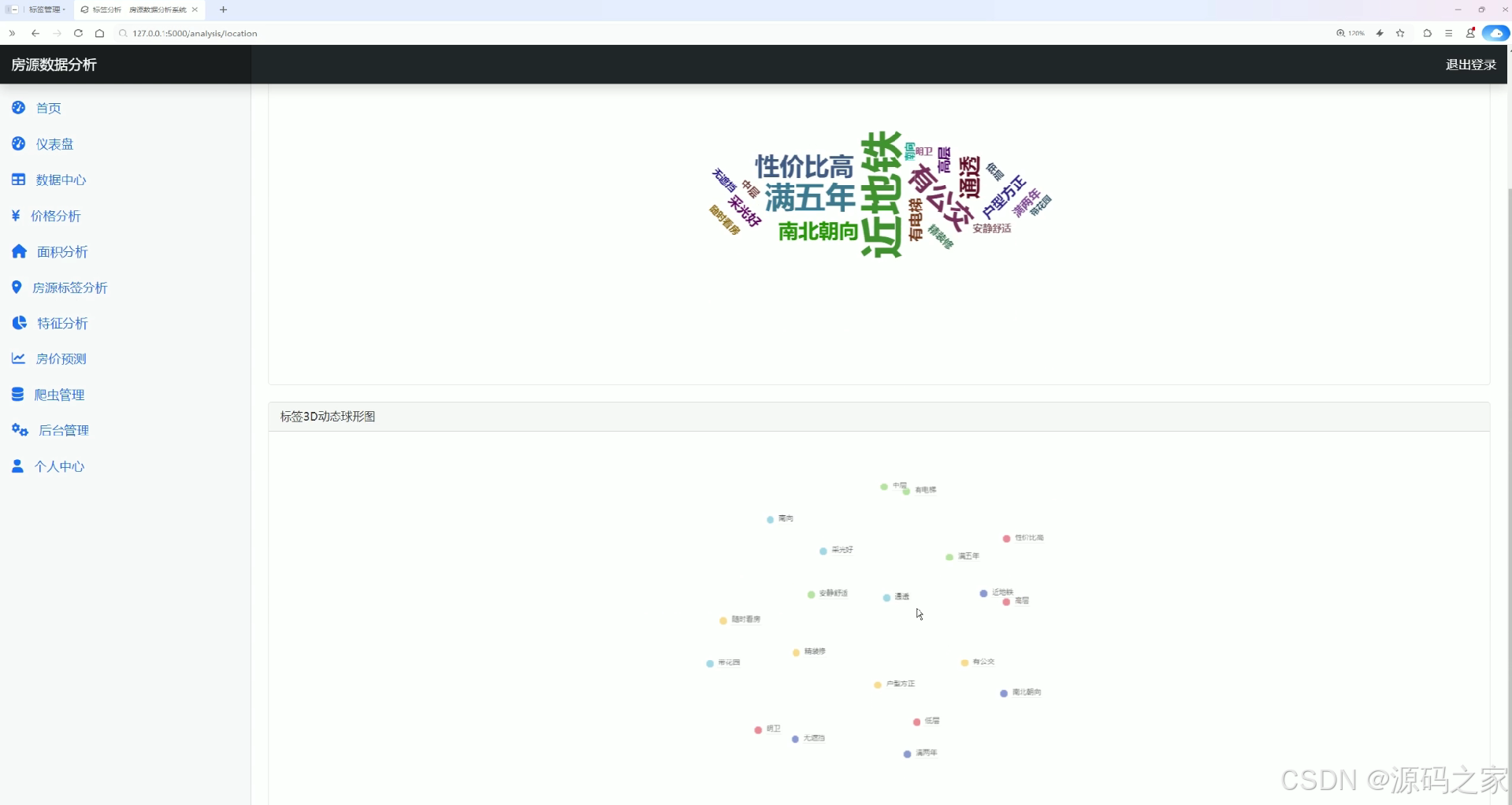
该页面为房源数据分析系统的房源标签分析模块,通过词云图直观展示高频房源标签,同时借助3D动态球形图呈现各标签间的关联分布,帮助用户清晰了解房源标签的热度与关联特征,实现房源标签维度的可视化分析。
房屋特征分析
该页面为房源数据分析系统的房屋特征分析模块,通过多组组合图表分别呈现房型与价格关系、朝向与价格关系,同时还包含楼层与价格关系、面积区间与价格关系的分析模块,直观展示不同房屋特征对房源价格的影响,为用户提供房屋特征维度的可视化分析功能。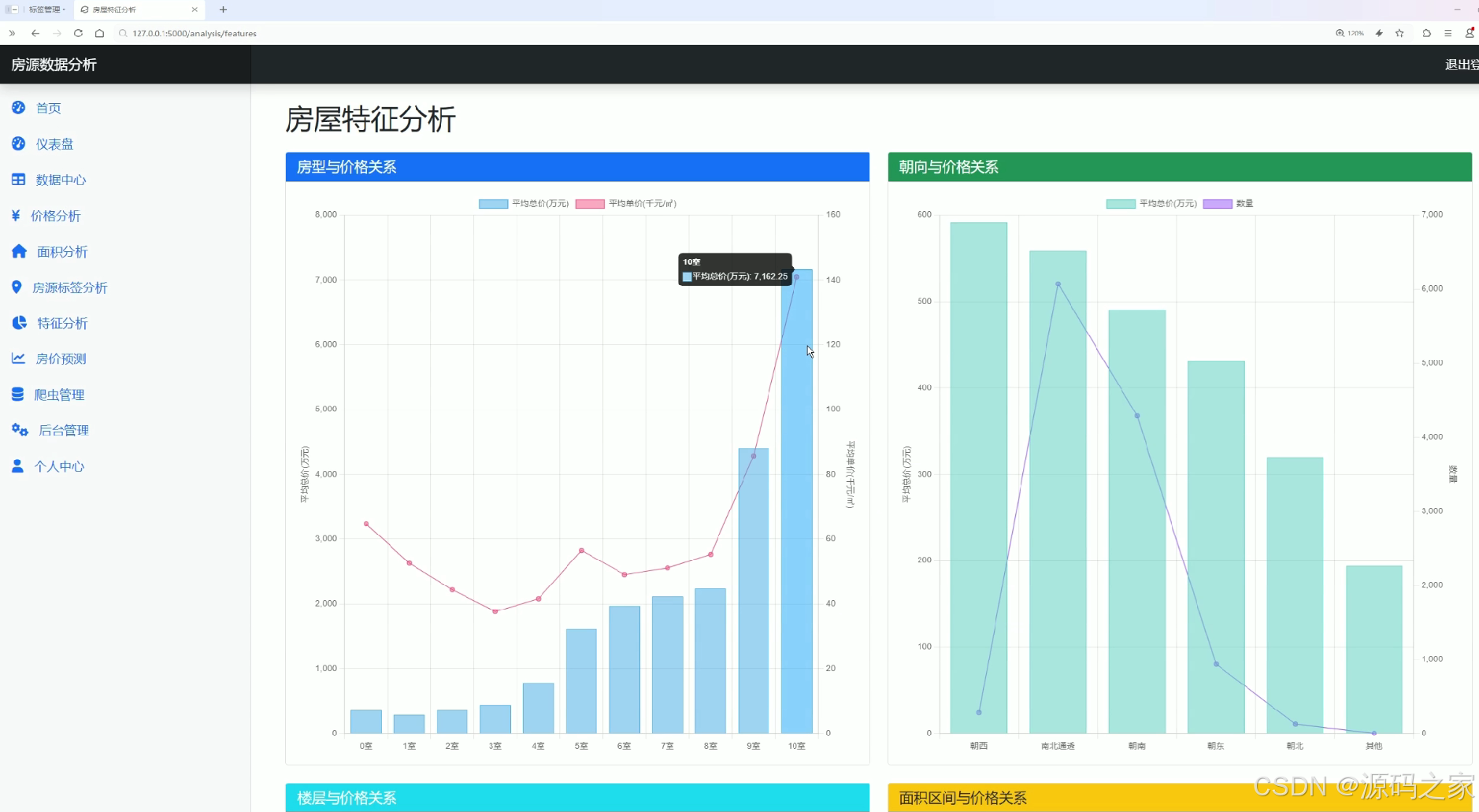
房价预测
该页面为房源数据分析系统的房价预测模块,展示面积、户型、朝向、楼层等房源特征的数据参考信息,提供面积、房间数量、朝向、楼层等参数的自定义输入选项,支持用户通过点击预测按钮获取房源价格预测结果。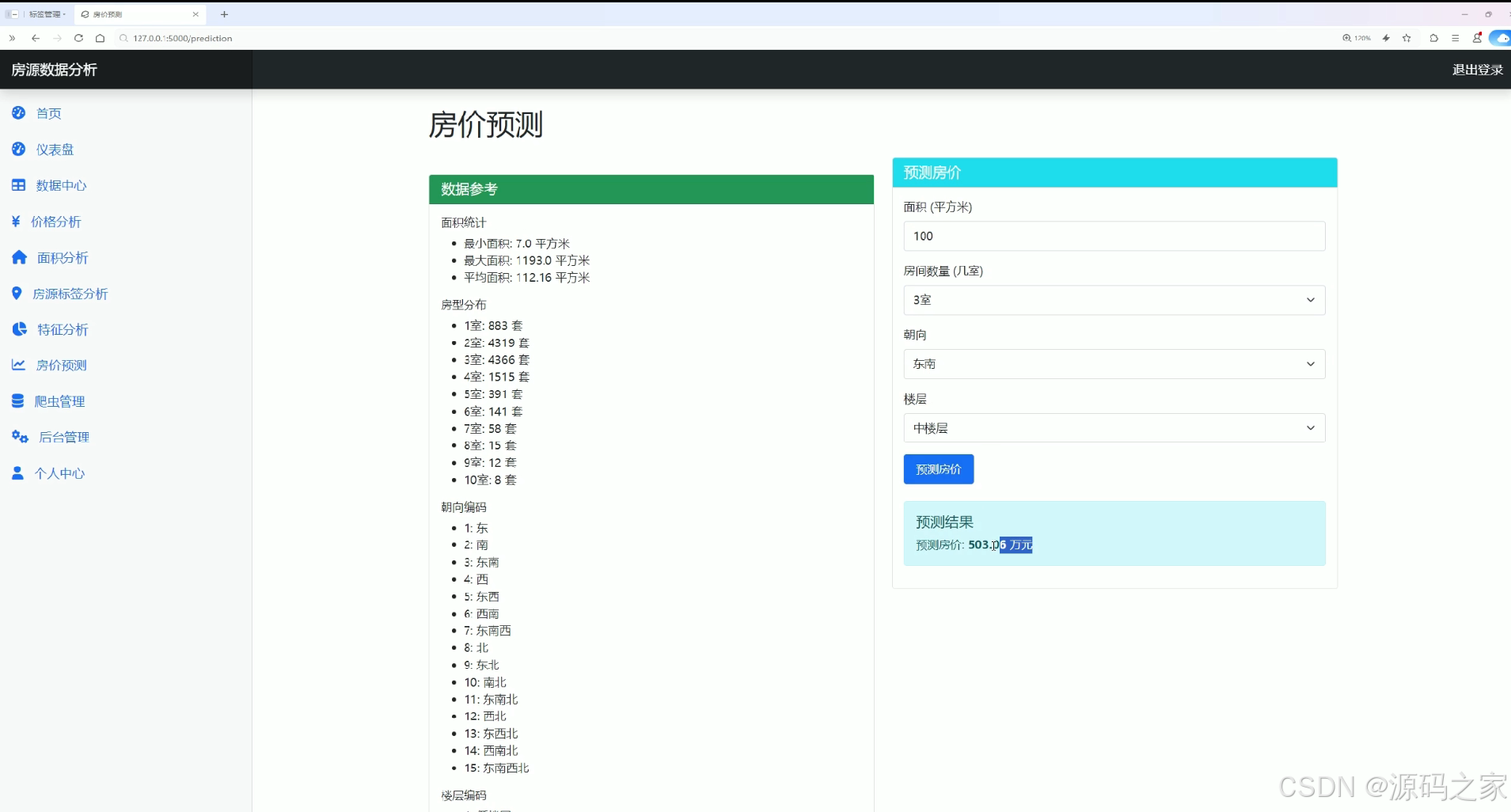
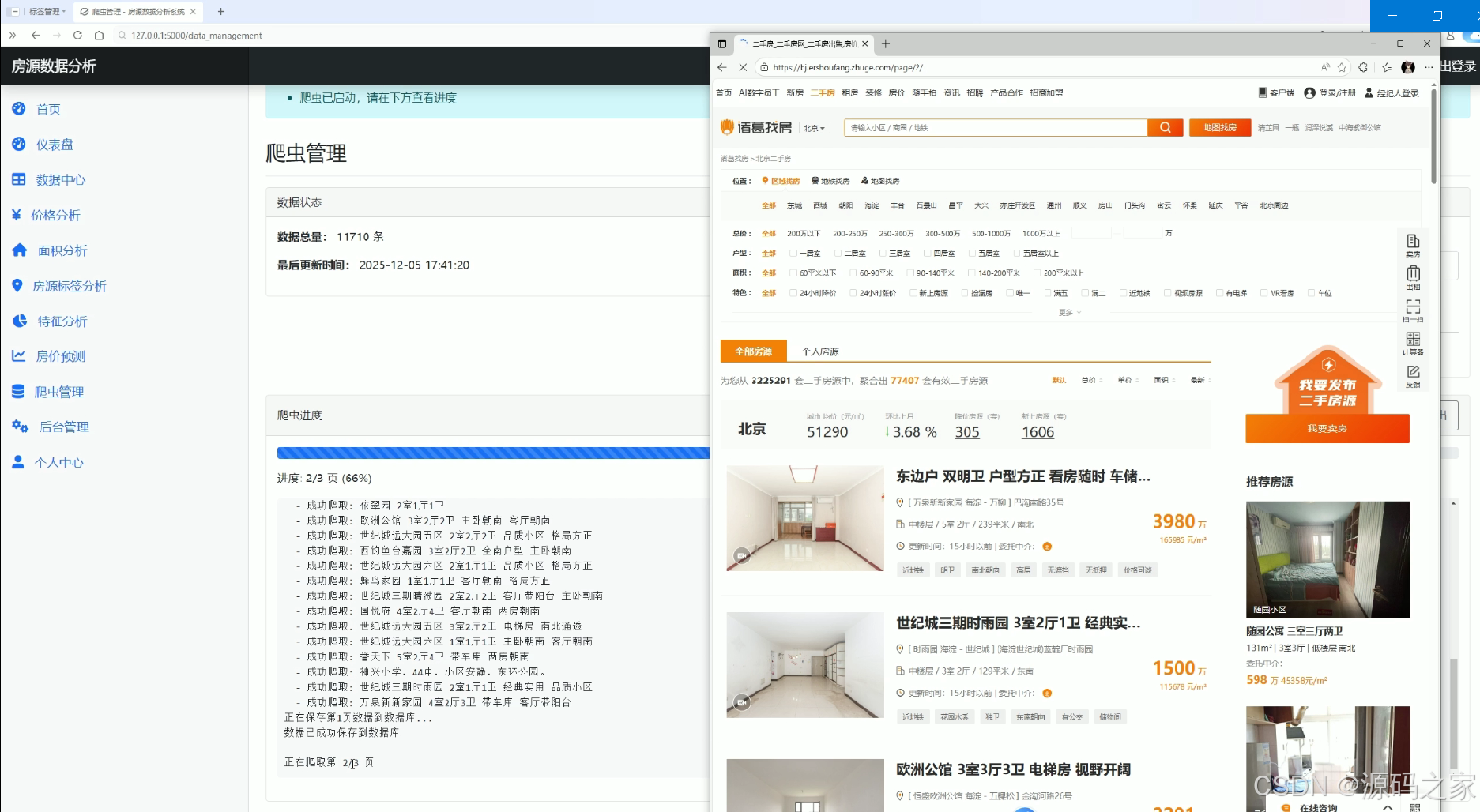
爬虫管理
该页面为房源数据分析系统的爬虫管理模块,展示数据总量与最后更新时间等数据状态信息,呈现爬虫进度及成功爬取的房源信息,同时关联显示爬虫目标网站的房源页面,实现房源数据的爬取监控与状态展示功能。
用户登录
该页面为房源数据分析系统的用户登录模块,提供用户名与密码输入框,设有记住我、忘记密码、登录按钮及立即注册入口,实现系统用户的身份验证与账号注册引导功能。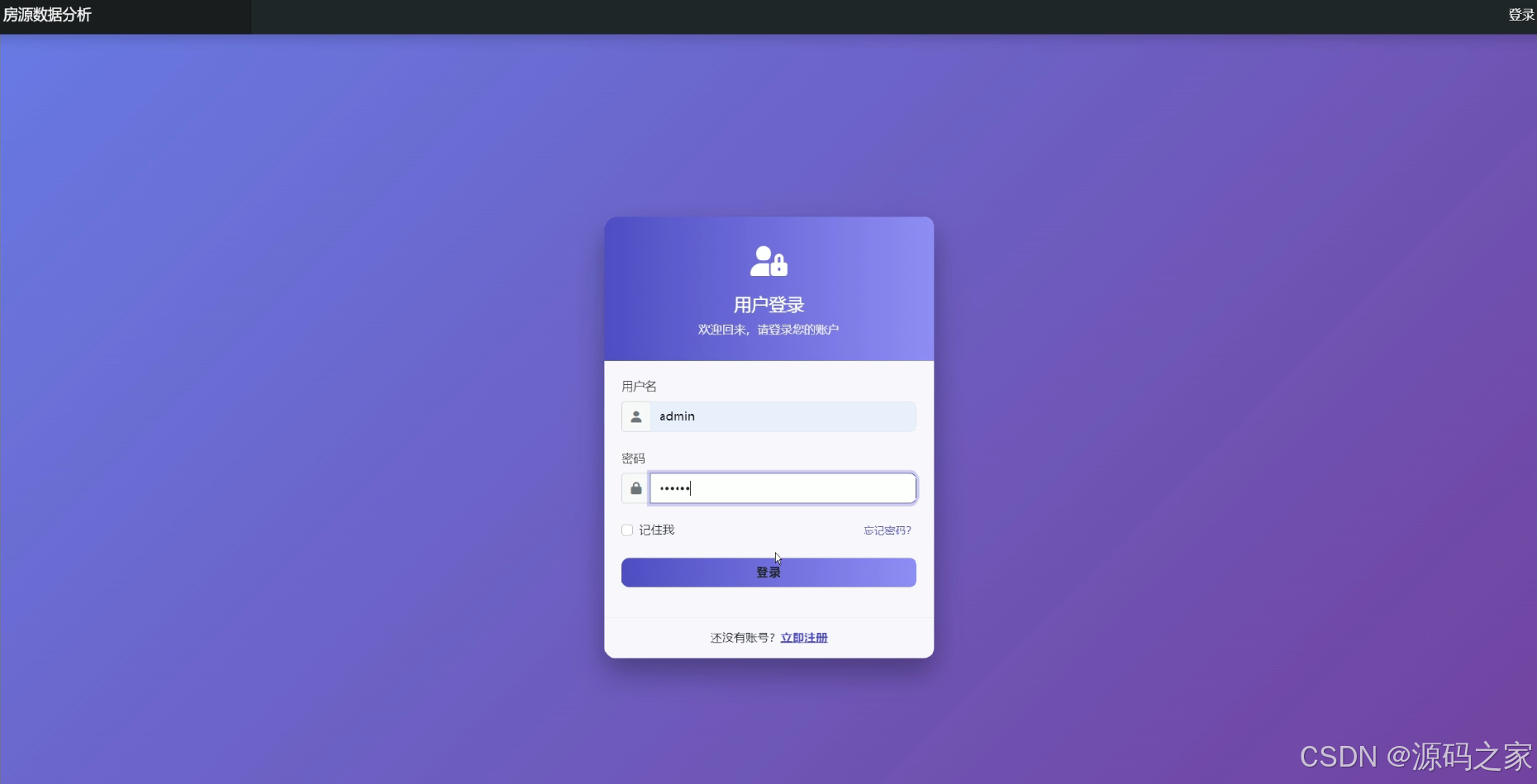
3、项目说明
一、技术栈
本系统后端基于Python语言开发,采用轻量级Flask框架构建Web应用。数据采集环节使用DrissionPage网络爬虫库,该库整合了浏览器自动化与HTTP请求功能,能够高效获取二手房信息。机器学习方面,系统集成了scikit-learn库,房价预测模块采用支持向量回归(SVR)算法构建预测模型。前端可视化使用ECharts工具库,实现各类交互式图表的展示。系统所有数据均来源于真实的二手房源信息。
二、功能模块详解
· 用户登录
该模块为系统的入口页面,提供完整的用户身份验证功能。界面包含用户名与密码输入框,配套设置有记住我选项、忘记密码链接、登录按钮以及立即注册入口。用户通过输入正确的凭证后方可进入系统,确保数据访问的安全性,同时也为新用户提供了账号注册的引导通道。
· 房源数据分析系统首页
作为系统的主导航页面,该模块集中展示了平台的核心价值与功能框架。首页设有进入仪表盘和查看数据的快捷入口,同时介绍了智能爬虫、深度分析、智能预测三大系统特色。页面下方呈现价格分析、面积分析、位置分析、标签分析等核心功能模块的概览,帮助用户快速了解系统能够提供的各项分析能力。
· 项目界面
该模块实际为房源数据分析仪表盘,是系统数据可视化的核心展示区域。页面顶部展示房源总数、平均总价、平均单价与平均面积四项关键统计指标。中部通过环形图分别呈现房源户型分布与朝向分布,让用户直观了解不同户型与朝向的占比情况。底部借助柱状图展示楼层分布和房源标签分布,从多个维度描绘房源的整体特征。
· 数据中心
该模块承担房源原始数据的检索与查看功能。页面设有城市、楼层、户型、朝向等多维度筛选条件,同时提供关键词搜索框,方便用户快速定位目标房源。数据展示采用表格形式,列明房源ID、名称、城市、地址、楼层、户型、面积、朝向、总价和单价等详细信息,为用户提供了全面的数据查询能力。
· 价格分析
该模块专注于房源价格维度的深度分析。页面展示平均总价、平均单价、最高总价和最低总价四个核心价格指标,让用户快速把握整体价格水平。主体部分通过两组柱状图分别呈现房源总价分布与单价分布情况,清晰反映不同价格区间内的房源数量占比,为价格趋势研究提供直观依据。
· 面积分析
该模块围绕房源面积特征展开分析。页面展示平均面积、最大面积、最小面积三项核心指标,帮助用户了解面积的总体情况。分析部分采用柱状图呈现房源面积分布,展示不同面积区间的房源数量;同时利用环形图展示户型分布情况,将面积与户型两个关联维度结合起来,为用户提供更全面的面积分析视角。
· 房源标签分析
该模块聚焦于房源的标签信息挖掘。页面通过词云图直观展示高频出现的房源标签,标签字号大小直接反映其出现频率,让用户一目了然地掌握房源的热点描述词。同时借助3D动态球形图呈现各标签之间的关联分布,通过空间位置与连线关系展示标签的共现特征,帮助用户深入理解不同房源属性之间的内在联系。
· 房屋特征分析
该模块探究不同房屋特征对价格的影响关系。页面采用多组组合图表的形式,分别呈现房型与价格关系、朝向与价格关系、楼层与价格关系以及面积区间与价格关系。每组分析都将特征维度与价格进行关联对比,直观展示哪些户型更受欢迎、哪种朝向均价更高、不同楼层的价格差异以及面积大小如何影响房价,为用户提供多维度的交叉分析能力。
· 房价预测
该模块为用户提供房源价格的智能预估功能。页面首先展示面积、户型、朝向、楼层等特征的统计数据作为输入参考。下方设有面积、房间数量、朝向、楼层等参数的自定义输入选项,用户可以根据实际需求组合选择各项特征,点击预测按钮后系统将基于SVR算法模型计算出预估价格,实现从数据分析到智能预测的功能延伸。
· 爬虫管理
该模块负责监控数据采集状态。页面展示当前数据总量与最后更新时间,让用户了解数据的时效性与规模。同时呈现爬虫进度条及成功爬取的房源信息列表,并关联显示爬虫目标网站的原始房源页面,实现对数据采集过程的实时监控与状态展示,确保数据源的持续更新与可追溯。
三、项目总结
二手房数据分析可视化系统是一个集数据采集、存储、分析、预测于一体的综合性平台。系统以Flask为框架基础,整合DrissionPage爬虫实现自动化数据获取,通过ECharts构建丰富的可视化图表,并引入SVR机器学习算法提供房价预测能力。平台覆盖了从用户登录、数据检索、多维度统计分析到智能预测的完整业务链条,为二手房研究提供了从原始数据到深度洞察的全流程支持。无论是价格、面积、户型等基础维度的分析,还是标签挖掘、特征关联、价格预测等进阶功能,系统都提供了直观易用的交互界面,有效帮助用户理解二手房市场的内在规律与价值特征。
4、核心代码
from app.models import House
from app import db
import pandas as pd
import numpy as np
import re
def clean_price(price_str):
"""清洗价格数据,提取数字部分"""
if not price_str or price_str == '未知':
return None
match = re.search(r'(\d+(\.\d+)?)', price_str)
if match:
return float(match.group(1))
return None
def clean_area(area_str):
"""清洗面积数据,提取数字部分"""
if not area_str or area_str == '未知':
return None
match = re.search(r'(\d+(\.\d+)?)', area_str)
if match:
return float(match.group(1))
return None
def get_price_stats():
"""获取价格统计数据"""
houses = House.query.all()
# 转换为DataFrame进行数据分析
df = pd.DataFrame([{
'total_price': clean_price(h.total_price),
'unit_price': clean_price(h.unit_price),
'area': clean_area(h.area),
'room_type': h.room_type,
'direction': h.direction,
'floor': h.floor,
'address': h.address
} for h in houses])
# 过滤掉无效数据
df = df.dropna(subset=['total_price', 'unit_price'])
# 自定义总价区间划分:总共10个区间,其中0-1000万之间划分为7个区间
total_price_bins = [0, 100, 200, 300, 400, 600, 800, 1000, 1500, 2000, float('inf')]
total_price_labels = [
'0-100万', '100-200万', '200-300万', '300-400万',
'400-600万', '600-800万', '800-1000万', '1000-1500万',
'1500-2000万', '大于2000万'
]
# 计算总价分布
df['total_price_range'] = pd.cut(df['total_price'], bins=total_price_bins, labels=total_price_labels, right=False)
total_price_distribution = df['total_price_range'].value_counts().to_dict()
# 确保所有总价区间都在结果中(即使计数为0)
full_total_price_distribution = {label: total_price_distribution.get(label, 0) for label in total_price_labels}
# 自定义单价区间划分:总共10个区间,其中0-50000之间划分为7个区间
unit_price_bins = [0, 5000, 10000, 15000, 20000, 30000, 40000, 50000, 60000, 80000, float('inf')]
unit_price_labels = [
'0-5千', '5千-1万', '1万-1.5万', '1.5万-2万',
'2万-3万', '3万-4万', '4万-5万', '5万-6万',
'6万-8万', '大于8万'
]
# 计算单价分布
df['unit_price_range'] = pd.cut(df['unit_price'], bins=unit_price_bins, labels=unit_price_labels, right=False)
unit_price_distribution = df['unit_price_range'].value_counts().to_dict()
# 确保所有单价区间都在结果中(即使计数为0)
full_unit_price_distribution = {label: unit_price_distribution.get(label, 0) for label in unit_price_labels}
# 计算统计数据
stats = {
'avg_total_price': df['total_price'].mean(),
'avg_unit_price': df['unit_price'].mean(),
'max_total_price': df['total_price'].max(),
'min_total_price': df['total_price'].min(),
'price_distribution': full_total_price_distribution,
'unit_price_distribution': full_unit_price_distribution
}
return stats
def get_area_stats():
"""获取面积统计数据"""
houses = House.query.all()
# 转换为DataFrame进行数据分析
df = pd.DataFrame([{
'area': clean_area(h.area),
'room_type': h.room_type
} for h in houses])
# 过滤掉无效数据
df = df.dropna(subset=['area'])
# 自定义区间划分:总共10个区间,其中0-200之间划分为7个区间
bins = [0, 30, 60, 90, 120, 150, 180, 200, 250, 300, float('inf')]
labels = ['0-30㎡', '30-60㎡', '60-90㎡', '90-120㎡', '120-150㎡', '150-180㎡', '180-200㎡', '200-250㎡', '250-300㎡', '大于300㎡']
# 计算面积分布
df['area_range'] = pd.cut(df['area'], bins=bins, labels=labels, right=False)
area_distribution = df['area_range'].value_counts().to_dict()
# 确保所有区间都在结果中(即使计数为0)
full_area_distribution = {label: area_distribution.get(label, 0) for label in labels}
# 计算统计数据
stats = {
'avg_area': df['area'].mean(),
'max_area': df['area'].max(),
'min_area': df['area'].min(),
'area_distribution': full_area_distribution,
'room_type_distribution': df['room_type'].value_counts().to_dict()
}
return stats
5、项目列表



6、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)