大模型时代,向量嵌入才是真正的“认知底盘”:从Word2Vec到Transformer
向量嵌入(Vector Embedding)是大型语言模型(LLM)和人工智能(AI)应用的核心技术,它将文本、图片、音频等人类内容翻译成机器能计算的数字坐标,从而实现更精准的语义理解和知识检索。本文深入探讨了向量嵌入的技术演进、应用场景、主流模型对比以及RAG(检索增强生成)的完整链路,并分析了向量嵌入在产业化的趋势和风险,强调向量嵌入在大模型时代的重要性,它不仅是模型推理的基础,更是构建下一代AI产品的“认知底盘”。
很多人第一次接触大模型,会把注意力放在“生成”上:它为什么能写方案、改代码、做客服、答法律问题。
但如果把大模型比作一家大型咨询公司,真正决定它“看懂了什么、记住了什么、能不能在海量资料里找到答案”的,不是嘴巴,而是它的“坐标系统”——Vector Embedding(向量嵌入,简单说,就是把文字、图片、音频这些人类内容,翻译成机器能计算的数字坐标)。
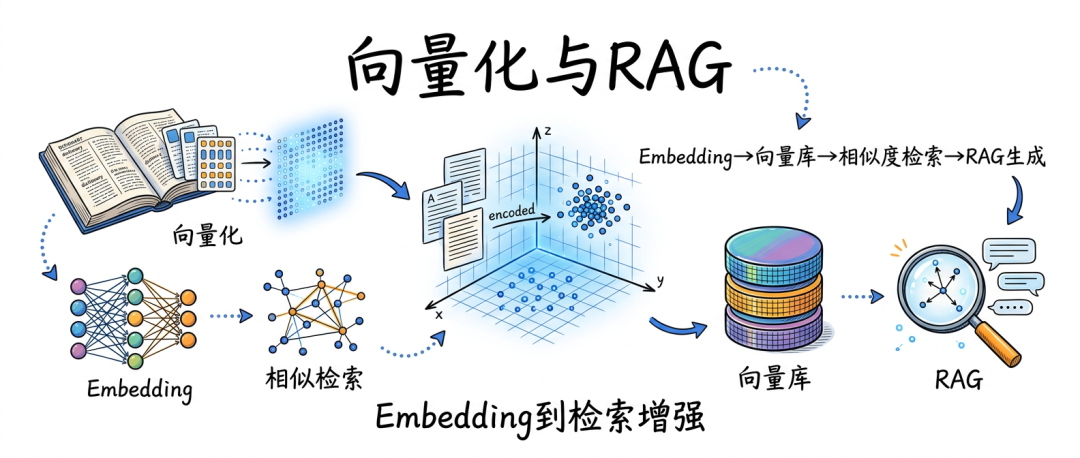
今天的 AI 应用,尤其是 RAG(Retrieval-Augmented Generation,检索增强生成,可以理解成“先查资料,再带着资料回答”),本质上都建立在这套坐标系统上。没有向量,模型只能“会说”;有了向量,它才开始“会找、会比、会联想”。
更重要的是,这已经不是实验室话题,而是一个快速变成基础设施的产业:
- Vector Database(向量数据库,专门用来存储和检索这些“语义坐标”的数据库)市场在 2024–2025 年约为 22–25.8 亿美元;
- 2026 年预计到 32 亿美元;
- 到 2032 年可能到 100–110 亿美元,年复合增长率约 21%–22%。
来源:Fortune Business Insights,Vector Database Market
链接:https://www.fortunebusinessinsights.com/vector-database-market-112428
来源:Actian Dev,What’s Changing in Vector Databases in 2026
链接:https://dev.to/actiandev/whats-changing-in-vector-databases-in-2026-3pbo
这篇文章,我想把几个问题一次讲透:
- 向量到底是什么,为什么它比关键词更接近“理解”?
- Embedding(把内容变成数字坐标)为什么从 Word2Vec(早期词向量方法,可理解为“让机器通过词和词经常一起出现的关系来认识意义”)一路演进到 Transformer(当前主流大模型架构,像一个会前后文一起看的阅读系统),再到多模态统一空间(让文字、图片、音频进入同一张“意义地图”)?
- OpenAI、Gemini、Cohere、Voyage 这些主流 embedding 模型/服务提供商,差别到底在哪里?
- RAG 的完整链路究竟怎么工作,为什么很多项目“看起来做了 RAG,实际效果却很一般”?
- 向量化的边界是什么,哪些坑是产品经理和技术负责人最容易踩的?
一、什么是向量化:机器如何给“意义”定位
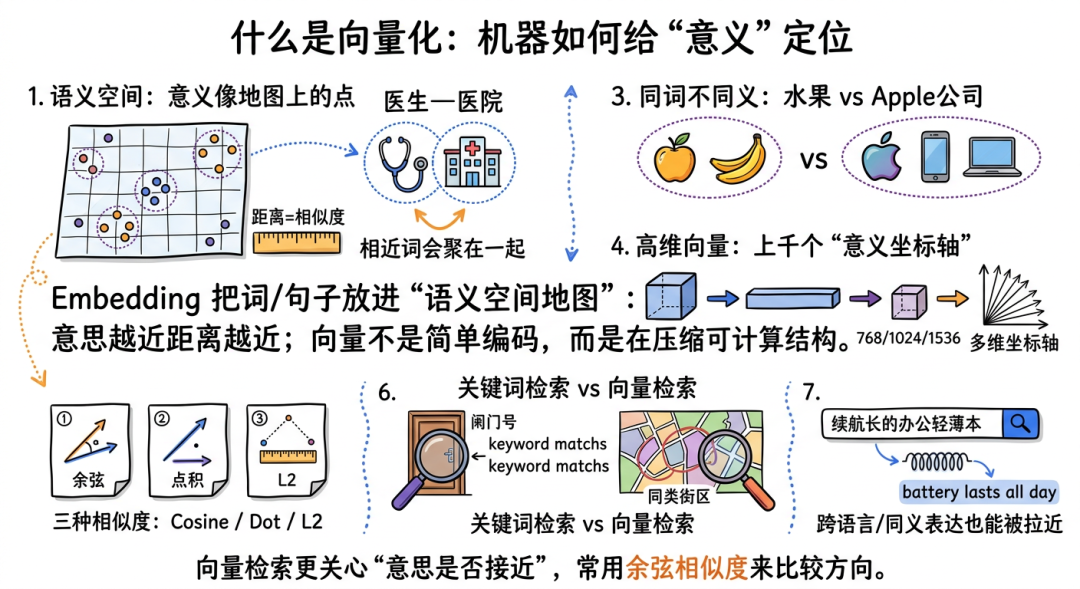
如果你把每个词都当成地图上的一个点,Embedding 做的事,就是把“意义相近”的词放得更近,把“意义相反或无关”的词放得更远。
比如:
- “医生”和“医院”应该靠近;
- “苹果(水果)”和“香蕉”应该靠近;
- “苹果(Apple 公司)”又可能和“iPhone”“MacBook”更近。
这就是语义空间(semantic space,像一张看不见的地图)。
在这张地图里,文字不再是字符串,而是一串浮点数(带小数的数字坐标),比如 768 维、1024 维、1536 维。你可以把它理解成:不是用经纬度 2 个数字定位,而是用上千个“意义坐标轴”同时定位。
一个最常见的误解是:向量就是“给文本编码”。
不完全对。更准确地说,向量是在压缩“意义结构”。
就像外卖平台不会真的理解“这家店温暖治愈、适合下雨天吃”,但它可以通过海量行为数据,知道“搜索番茄牛腩的人也常点罗宋汤”。Embedding 也类似:它并不“像人一样思考”,但它能把语义相关性变成可计算的距离。
常见的相似度计算方式有三种:
- Cosine Similarity(余弦相似度,比较两个方向是否接近,像看两支箭头是否指向同一边)
- Dot Product(点积,同时比较方向和“劲儿”的大小)
- L2 Distance(欧氏距离,直接比较两点物理距离)
在文本检索里,最常用的是 Cosine Similarity,因为我们通常更关心“意思是否接近”,而不是数值本身有多大。
一个非常直观的比喻是:
关键词搜索像“按字面找门牌号”;
向量搜索像“按你想去的那类街区找地方”。
所以用户搜“续航长的办公轻薄本”,即便文档里没写“续航长”,但写了“battery lasts all day”,向量也可能把它们拉近。
来源:IBM,What is Vector Embedding?
链接:https://www.ibm.com/think/topics/vector-embedding
来源:The New Stack,The Building Blocks of LLMs: Vectors, Tokens and Embeddings
链接:https://thenewstack.io/the-building-blocks-of-llms-vectors-tokens-and-embeddings/
来源:Stack Overflow Blog,An intuitive introduction to text embeddings
链接:https://stackoverflow.blog/2023/11/09/an-intuitive-introduction-to-text-embeddings/
补充一:为什么会有向量化:从"字面匹配"到"意义匹配"
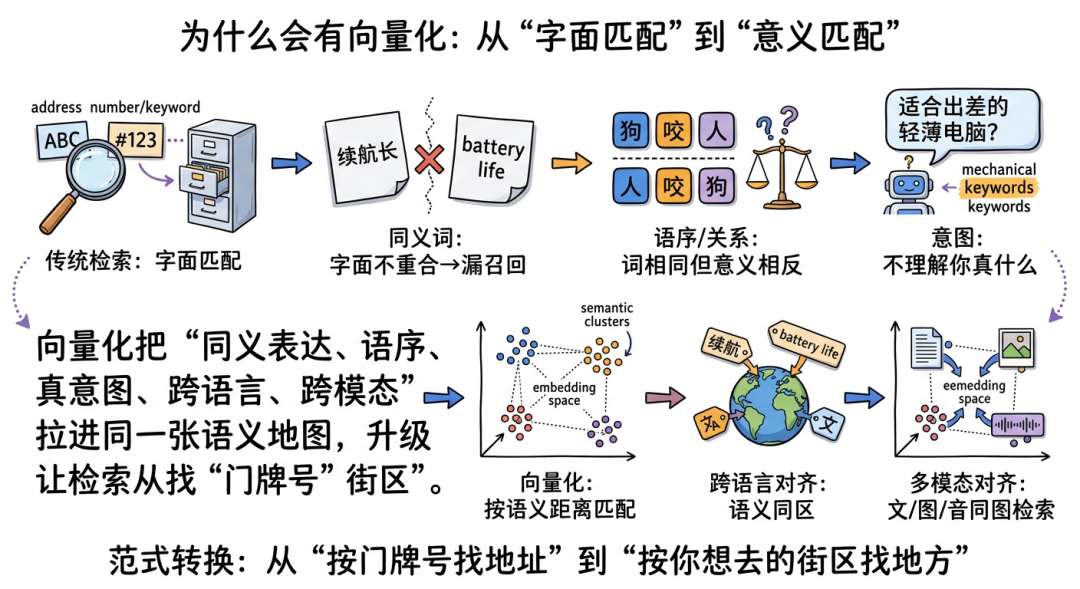
如果把传统关键词搜索想成“拿着一串门牌号找地址”,它的优点是简单、快、可控;但一旦用户的问题开始接近自然语言,它的天花板也会立刻暴露。
第一,同义词经常搜不到。用户搜“续航长”,文档里写的是 “battery life”;用户搜“裁员”,材料里写的是“组织优化”;字面不重合,系统就容易漏掉真正相关的内容。第二,很多传统检索对语序并不敏感,或者说敏感度远低于语义本身。“狗咬人”和“人咬狗”包含相同的词,但意义完全相反;如果系统主要按词频和命中率算分,就很难稳定区分。第三,它不理解查询意图。用户问“适合出差用的轻薄电脑”,真正想找的可能是轻、稳、续航长、开会方便,而不是网页里机械出现过“出差”“轻薄”四个字的内容。
这正是向量化出现的背景。它先解决的是语义理解:不是看你有没有用同一个词,而是看你是不是在说同一件事。于是“续航长”和 “battery life lasts all day” 会被拉到更近的位置;“退款规则”和“退货政策”也更容易互相召回。
再往前一步,向量空间天然适合做跨语言对齐。中文里的“续航”、英文里的 “battery life”、其他语言里的相近表达,只要语义接近,就可以被压到同一片区域。对全球化产品、跨境电商、跨语言知识库来说,这意味着搜索不再被语言边界硬切开。
更重要的是,向量化最终把多模态也带进了同一张地图。文字可以变向量,图片可以变向量,音频也可以变向量;只要模型把它们对齐到同一语义空间里,系统就能做到“用一句话找图片”“上传一张图找说明文档”“根据一段语音找相关会议纪要”。这已经不是单纯的搜索优化,而是在重写机器理解信息的接口。
所以,向量化真正带来的,不只是“搜索更聪明了一点”,而是一种范式转换:
从“按门牌号找地址”,变成“按你想去的街区找地方”。
来源:IBM,What is Vector Embedding?
链接:https://www.ibm.com/think/topics/vector-embedding
来源:Stack Overflow Blog,An intuitive introduction to text embeddings
链接:https://stackoverflow.blog/2023/11/09/an-intuitive-introduction-to-text-embeddings/
补充二:向量化在哪里用:5 个最能赚钱的应用场景
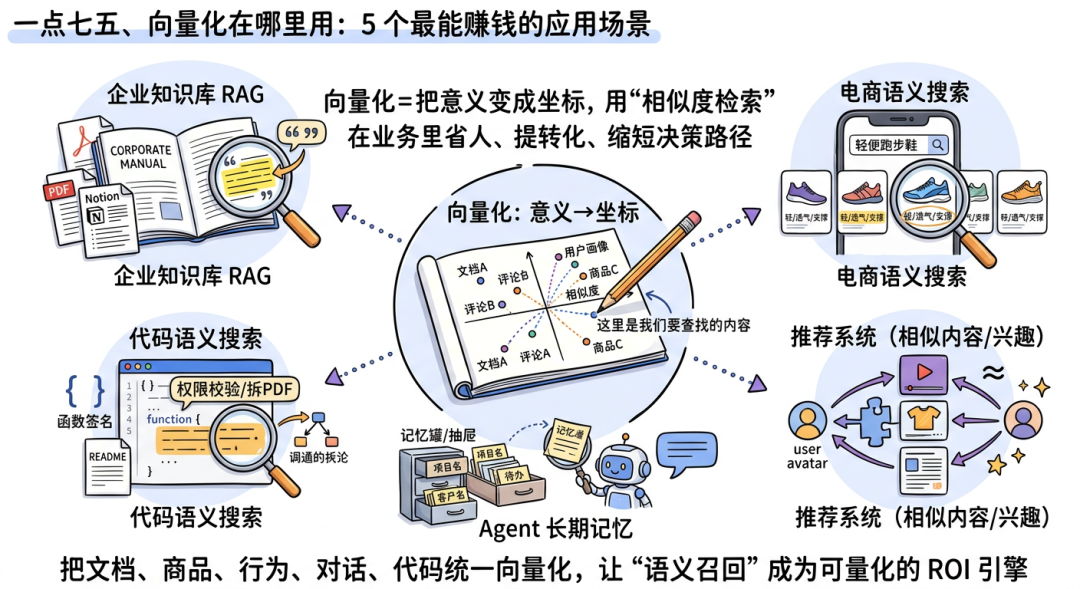
如果说向量化是“把意义变成坐标”,那它最有商业价值的地方,往往不是论文里,而是那些每天都在帮企业省人、提转化、缩短决策路径的业务环节。下面这 5 类,是今天最常见、也最容易直接看到 ROI 的场景。
1. 企业知识库 RAG
这是很多公司最先落地的方向:把制度、SOP、产品文档、客服话术向量化,让 AI 助手先查资料再回答。它的价值不只是“回答更像人”,而是把原本分散在 PDF、Notion、工单系统里的知识,变成一个可检索、可引用、可持续更新的统一入口。
2. 电商语义搜索
用户搜“适合跑步的轻便鞋”,真正想找的是轻、透气、支撑好、适合运动,而不一定是标题里正好出现“跑步”“轻便鞋”这几个词。向量搜索能把商品描述、评论、标签和用户意图拉到一起,因此更容易把“不写这些词、但确实符合需求”的商品找出来。
3. 推荐系统
“看过这个的人也喜欢”背后,很多时候本质就是向量相似度:内容像不像、用户兴趣像不像、行为轨迹像不像。无论是短视频、资讯、电商还是音乐平台,只要要做“相似内容推荐”,向量几乎都是底层标配。
4. Agent 长期记忆
AI 助手如果每次对话都像“失忆”,就很难真的成为工作助手。把对话历史、用户偏好、任务上下文向量化后,系统就能在下一次对话里按语义召回关键记忆,像“回忆起”你上次提过的项目、客户和待办事项。
5. 代码搜索
开发者不一定记得函数名,但往往记得“我要找一个做权限校验的模块”或“一个把 PDF 拆页的工具函数”。把代码注释、函数签名、README 和调用关系一起向量化后,团队就可以用自然语言找代码,而不是靠记忆翻仓库。
二、为什么 Embedding 是大模型的“入口层”
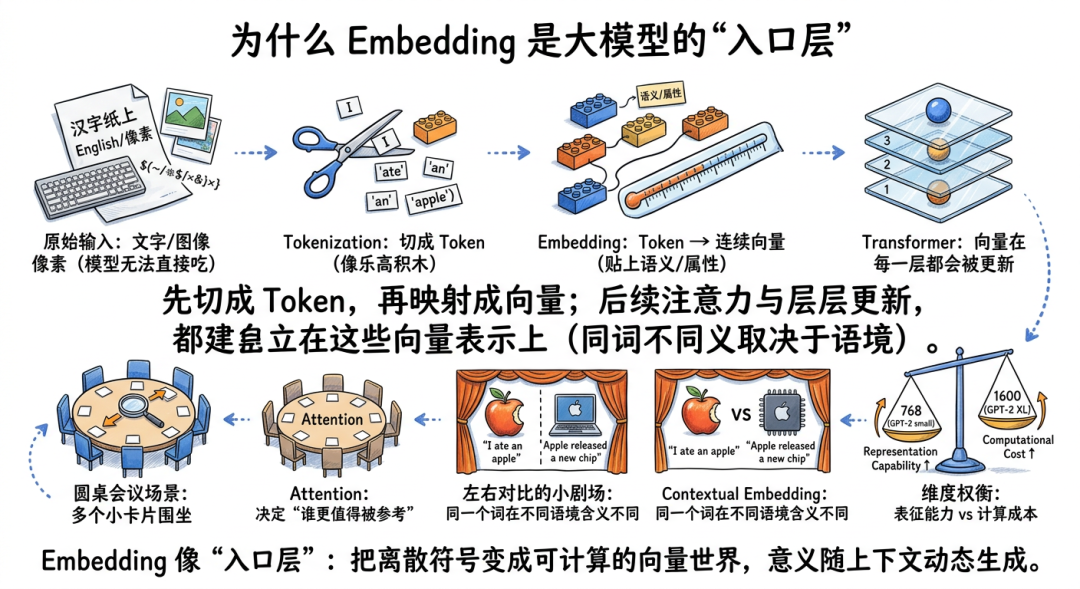
大模型不能直接处理汉字、英文单词、图片像素。
它首先要做两步:
- Tokenization(分词/切词,把输入拆成更小的处理单元)
- Embedding(嵌入,把这些离散单元变成连续向量)
你可以把 Token 想成“乐高积木块”,把 Embedding 想成“给每块积木贴上物理属性和语义属性标签”。
模型后面所有的注意力机制(Attention,像团队开会时决定“谁更值得被重点参考”)都建立在这些向量之上。
在早期模型里,一个 token 对应一个相对固定的向量。
但在 Transformer(当前主流大模型架构)里,向量不只是“入场券”,它还会在每一层网络里被不断更新。也就是说,同一个词在不同上下文中,最终形成的表示会不同。
最经典的例子是“Apple”:
- 在 “I ate an apple” 里,它更接近水果;
- 在 “Apple released a new chip” 里,它更接近科技公司。
这就是 Contextual Embedding(上下文化嵌入,意思是“词的意义要看语境”)。
如果说 Word2Vec 时代的词向量像“给每个人发一张静态身份证”,那 Transformer Embedding 更像“根据今天所处场景,动态生成的一张身份画像”。
关于维度,一个公开常被引用的例子是 GPT-2 small 的 embedding 维度为 768,GPT-2 XL 为 1600。这个数字本身不是“越大越强”,但它大致反映了模型表征能力和计算成本之间的平衡。
来源:Mike X Cohen,LLM breakdown #36: Embeddings
链接:https://mikexcohen.substack.com/p/llm-breakdown-36-embeddings
来源:HatchWorks,Large Language Models Guide
链接:https://hatchworks.com/blog/gen-ai/large-language-models-guide/
三、技术演进:Word2Vec 为什么不够,Transformer 为什么接管一切
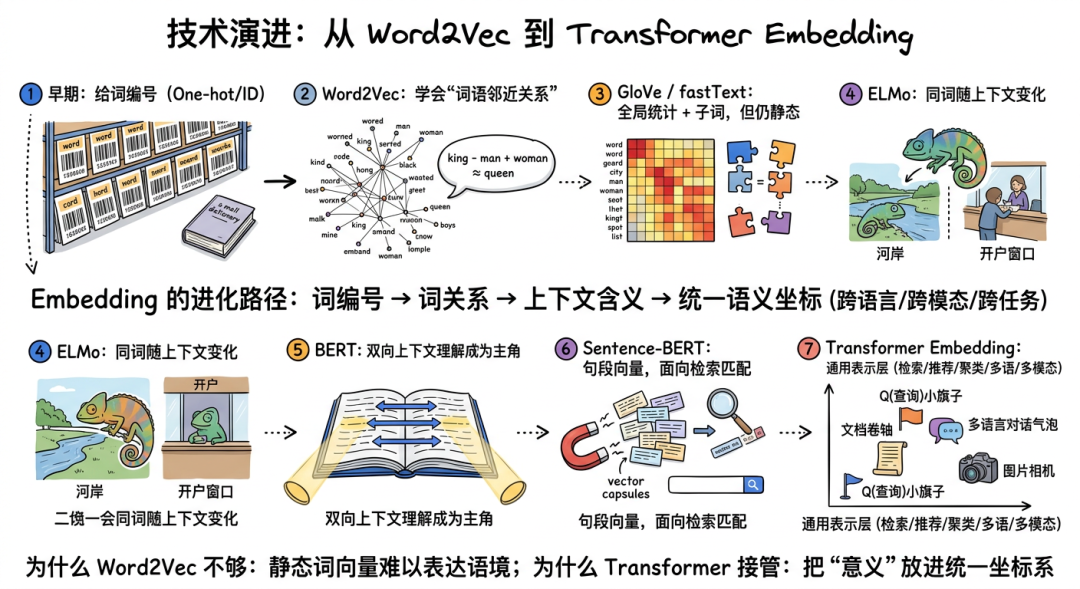
如果把 Embedding 的历史压缩成一句话,就是:
从“给词编号”,到“给词建模”,再到“给上下文建模”,最后走向“给世界建统一坐标”。
1. Word2Vec:第一次让机器学会“词语邻近关系”
Word2Vec(早期词向量方法,像让机器根据“谁经常和谁一起出现”来画关系图)的重要性,不在于今天还在不在用,而在于它第一次证明:
只要喂给模型足够多上下文,它就能学出“国王 - 男 + 女 ≈ 女王”这种结构化关系。
它的核心思想很朴素:
- CBOW(Continuous Bag of Words,连续词袋,可以理解成“看周围词,猜中间这个词是什么”)根据上下文猜中心词;
- Skip-gram(跳字模型,可以理解成“给你中心词,反过来猜它常和谁一起出现”)根据中心词猜上下文。
白话说,像让一个新员工通过同事关系图,慢慢学会“谁和谁是一个部门、谁和谁经常一起出现”。
但它的问题也很明显:
- 一个词只有一个向量;
- 不理解上下文;
- 对长句子、段落、文档的表达能力有限。
2. GloVe / fastText:补结构、补子词,但还是“静态世界”
GloVe(基于全局共现统计的词向量方法,像先看整张城市热力图,再决定词和词该离多近)更强调全局共现统计;
fastText(把词拆成更小的字片段来学习的词向量方法,像不只认识整词,还认识词的“零件”)引入子词信息,对拼写变化、低频词和多语言更友好。
但它们本质上仍然属于 Static Embedding(静态嵌入):
“银行”不管出现在“河岸边的银行”还是“去银行开户”,向量基本是同一个。
3. ELMo / BERT / Sentence-BERT:上下文成为主角
ELMo(早期上下文化词表示模型,意思是“同一个词会随句子环境变化”)、BERT(Bidirectional Encoder Representations from Transformers,双向编码器表征模型)和 Sentence-BERT(专门把整句、整段压成更适合检索的向量模型)代表了一个关键转折点。
它们不再只问“这个词通常是什么意思”,而是问“这个词在这句话里是什么意思”。
再往后,Sentence-BERT 这类模型开始专门优化句子级和段落级向量,让它更适合 search(搜索)、matching(匹配)、retrieval(检索)这些真实业务。
4. Transformer Embedding:从“词向量”变成“通用表示层”
今天主流 Embedding 模型几乎都建立在 Transformer 家族之上。
它们的特点不是只会做词表示,而是能做:
- query embedding(查询向量,把用户问题变成坐标)
- document embedding(文档向量,把资料内容变成坐标)
- instruction-tuned embedding(带任务偏好的向量,像“先告诉模型这次是做检索,再去编码”)
- multilingual embedding(多语言向量,让不同语言的相近意思落到相近位置)
- multimodal embedding(多模态向量,让文字、图片、音频等内容进入同一张地图)
这意味着 Embedding 已经不是语言模型的附属品,而是 Retrieval(检索)、Recommendation(推荐)、Clustering(聚类,也就是把相似内容自动分堆)、Reranking(重排,把候选结果再排一次)甚至 Agent memory(智能体记忆,可以理解成给 AI 建一个可检索的外部笔记本)的基础层。
来源:OpenLayer,What are Embedding Models? Complete Guide
链接:https://www.openlayer.com/blog/post/what-are-embedding-models-complete-guide
来源:BentoML,A Guide to Open-Source Embedding Models
链接:https://www.bentoml.com/blog/a-guide-to-open-source-embedding-models
四、维度不是越大越好:向量化里的“甜蜜点”
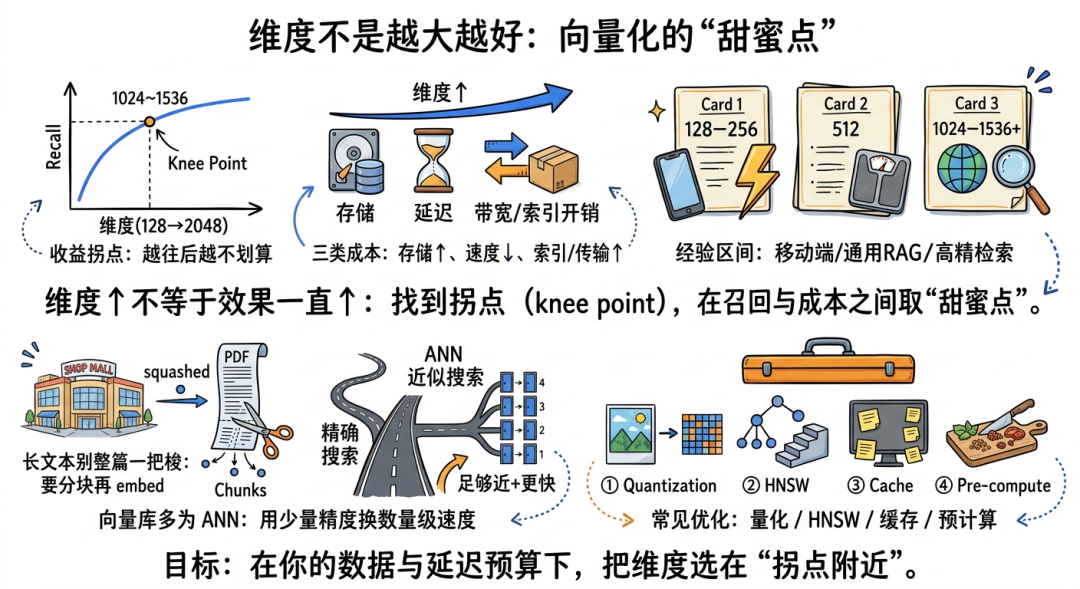
很多团队第一次做向量检索,特别容易陷入一个直觉:
维度越大,信息越丰富,效果一定越好。
这句话只对了一半。
维度(dimension,向量长度,可以理解成“描述一个对象用了多少个特征刻度”)越大,确实有机会容纳更细腻的语义差异;但同时也会带来三类成本:
- 存储成本上升
- 检索速度下降
- 索引和网络传输开销增加
公开实践里,经常会提到一个“knee point”(拐点,意思是投入继续增加,但收益开始明显变小)。
也就是当维度从 512 提升到 1024 时,Recall(召回率,能不能把相关结果找回来)可能提升明显;但从 1536 再到更高,收益可能开始趋缓。
一个常见经验区间是:
- 向量维度: 128–256,典型场景: 移动端、实时 API(程序调用接口,像系统之间的标准插座),优点: 延迟低、索引小,代价: 语义容易“糊”
- 向量维度: 512,典型场景: 通用 RAG,优点: 精度/成本平衡较好,代价: 复杂语境略吃亏
- 向量维度: 1024–1536+,典型场景: 多语言、多模态、高精度检索,优点: 召回高、上下文表达更强,代价: 存储贵、检索慢
还有两个经常被忽略的现实问题:
第一,长文本不是“整篇一把梭”就能 embed
Embedding 模型即便支持长上下文,也不意味着你应该把几十页 PDF 整体编码成一个向量。
因为一个向量只能代表一个“综合语义中心”,内容越长,主题越混杂,就越像“把整栋商场压缩成一个坐标”,最后什么都不够精准。
第二,向量数据库不是“精确搜索”,而是“近似搜索”
生产环境里,大家用的通常是 ANN(Approximate Nearest Neighbor,近似最近邻搜索,意思是“不求 100% 找到最接近的点,但求足够快地找到非常接近的点”)。
这是一个典型工程妥协:用极少量精度损失,换取数量级的性能提升。
常见优化手段包括:
- Quantization(量化,把浮点数压缩成 int8/fp16,像把高清照片压缩到肉眼几乎看不出差异的程度)
- HNSW(分层近邻图索引,像先走高速路定位大概区域,再走小路找具体门牌)
- Cache(缓存高频查询,相当于把常被问的问题先放到手边)
- Pre-computation(预计算,提前把热门内容向量化,像先把常用食材切好备菜)
来源:Artsmart,Top Embedding Models in 2025
链接:https://artsmart.ai/blog/top-embedding-models-in-2025/
来源:Milvus,We Benchmarked 20 Embedding APIs with Milvus
链接:https://milvus.io/blog/we-benchmarked-20-embedding-apis-with-milvus-7-insights-that-will-surprise-you.md
五、主流 Embedding 模型横评:OpenAI、Gemini、Cohere、Voyage 怎么选
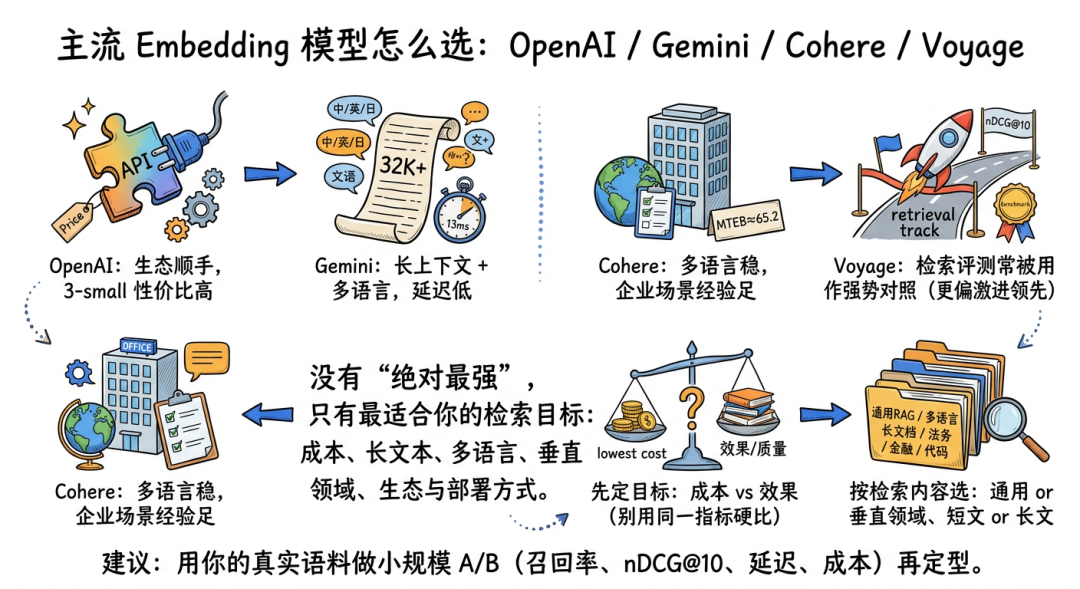
说结论之前,先说一句最重要的话:
没有“绝对最强”的 embedding model,只有“最适合你的 retrieval target(检索目标,也就是你到底想把什么内容找回来)”。
因为你真正优化的,可能不是同一个指标:
- 有的人要 lowest cost(最低成本)
- 有的人要 long context(长文本支持)
- 有的人要 multilingual(多语言)
- 有的人要 legal / finance / code 这类垂直领域效果
- 有的人要 self-hosted(私有部署,自己掌控运行环境)
但如果只看 2025 年公开 benchmark(基准测试,可以理解成统一考场里的公开成绩单)和对比数据,四家商业模型大概可以这样理解。
1. OpenAI:生态友好,text-embedding-3-small 性价比极高
OpenAI 的优势不是“所有榜单第一”,而是“整体够强 + 生态最顺手”。
公开数据里:
| text-embedding-3-small | 1536 维 | 可降维,最大输入 8191 tokens | 约 $0.02 / 1M tokens |
| text-embedding-3-large | 3072 维 | 可降维,最大输入 8191 tokens | 约 $0.13 / 1M tokens |
- 在一些公开对比中,
text-embedding-3-large的 MTEB(Massive Text Embedding Benchmark,文本向量综合评测基准,可以理解成 embedding 界的“高考总分榜”)约 64.6
如果你的目标是:
- 英文或中英混合知识库
- 成本敏感的通用 RAG
- 已经在 OpenAI 生态里开发应用
那 3-small 反而常常比 3-large 更值得先试。
来源:Dataa.dev,Embedding Models Compared: OpenAI vs Cohere vs Voyage vs Open Source
链接:https://dataa.dev/2025/01/17/embedding-models-compared-openai-vs-cohere-vs-voyage-vs-open-source/
来源:AIlog,Choosing Embedding Models
链接:https://app.ailog.fr/en/blog/guides/choosing-embedding-models
2. Gemini:长上下文和多语言是亮点,延迟也很漂亮
Google Gemini 的 embedding 路线,最大的吸引力在于:
- context length(上下文长度)更长,公开资料中可到 32K+
- multilingual(多语言)表现强
- 在一些对比中平均延迟可低至 13ms
如果你的文档有明显的跨语言特性,比如中文、英文、日文混合知识库,或者企业搜索场景里资料非常长,Gemini 很值得重点测试。
但从某些公开 ELO(原本用于棋手强弱排名的积分法,这里可理解为“模型对战积分”)和 nDCG@10(归一化折损累计增益,简单理解为“排在前面的结果到底准不准”)对比看,Gemini 在部分 retrieval 评测上并不总是领先。
来源:Agentset,voyage-3-large vs gemini-text-embedding-004
链接:https://agentset.ai/embeddings/compare/voyage-3-large-vs-gemini-text-embedding-004
来源:Slashdot Compare,Gemini Embedding vs voyage-3-large
链接:https://slashdot.org/software/comparison/Gemini-Embedding-vs-voyage-3-large/
3. Cohere:多语言传统强项明显,企业场景一直有存在感
Cohere 一直是 embedding 赛道的老牌选手。
公开比较里,embed-v4 在多语言任务上表现稳定,MTEB 约 65.2,在某些统计里甚至略高于 OpenAI text-embedding-3-large 的 64.6。
它的特点更像“均衡型选手”:
- 多语言覆盖广
- 企业搜索场景经验足
- 对文本理解任务比较稳
短板也比较现实:
- 在一些 retrieval benchmark 上,不如 Voyage 那么激进领先
- 上下文长度和成本表现,视具体版本和套餐而变化较大
来源:AIlog,Choosing Embedding Models
链接:https://app.ailog.fr/en/blog/guides/choosing-embedding-models
来源:ZenML,Best Embedding Models for RAG
链接:https://www.zenml.io/blog/best-embedding-models-for-rag
4. Voyage:如果你要“检索精度优先”,它经常会进入第一候选
在很多 2025 年公开对比里,Voyage 的 voyage-3-large 是 retrieval 场景的“明星选手”。
公开数据大致包括:
- 1024 维
- 最大输入 32K tokens
- 价格约 $0.18 / 1M tokens
- ELO 约 1528
- nDCG@10 约 0.837
- 某些平均域任务上比 OpenAI v3-large 高约 9.74%
- 相比 Cohere v3 平均高约 20.71%
- 在 law、finance、code 等场景表现突出
如果你做的是“文档检索质量直接决定业务价值”的系统,比如:
- 法律检索
- 金融研究助手
- 代码知识库
- 企业内部复杂 SOP(Standard Operating Procedure,标准操作流程,可理解为公司内部“照着做就不会错”的步骤文档)检索
Voyage 往往值得把预算倾斜过去。
但代价也明显:
- 单价更高
- 延迟通常高于 Gemini
- 你需要确认 ROI(投入产出比)是否真能覆盖成本
来源:Agentset,voyage-3-large vs gemini-text-embedding-004
链接:https://agentset.ai/embeddings/compare/voyage-3-large-vs-gemini-text-embedding-004
来源:SourceForge Compare,Gemini Embedding vs voyage-3-large
链接:https://sourceforge.net/software/compare/Gemini-Embedding-vs-voyage-3-large/
一张表看懂四家主流模型
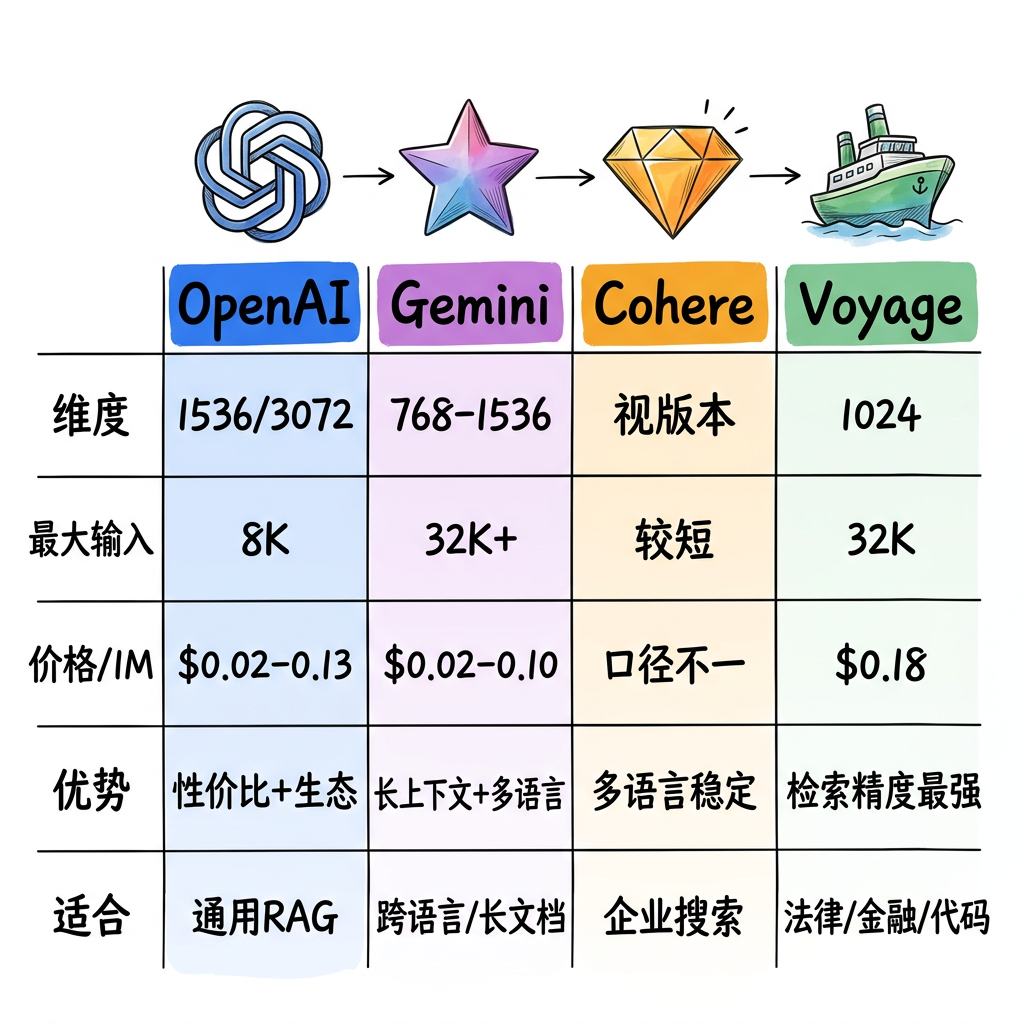
数据来源:OpenAI/Google/Cohere/Voyage 官方文档 + MTEB 基准测试 + Dataa.dev 对比报告(2025)
那开源呢?
如果你对成本、隐私和可控性更敏感,开源 embedding 已经非常能打。
2025 年公开讨论里,Qwen3-Embedding-8B、BGE-M3 等都被频繁提及,特别适合:
- 本地部署
- 数据不出域
- 大规模离线向量化
- 对 API 成本敏感的 SaaS 产品
但要提醒一句:
开源不是“免费午餐”。你省下 API 账单,可能会换成 GPU、运维、评测、模型升级和量化部署成本。
来源:Tavily Search Snippet,Best Embedding Models for 2025
链接:https://www.baseten.co/blog/the-best-open-source-embedding-models/
来源:Towards AI,Building a Modern RAG Pipeline in 2026: Qwen3 Embeddings and Vector Database in Qdrant
链接:https://pub.towardsai.net/building-a-modern-rag-pipeline-in-2026-qwen3-embeddings-and-vector-database-in-qdrant-ebeca2bbe338
六、从 Embedding 到 RAG:真正的完整链路长什么样
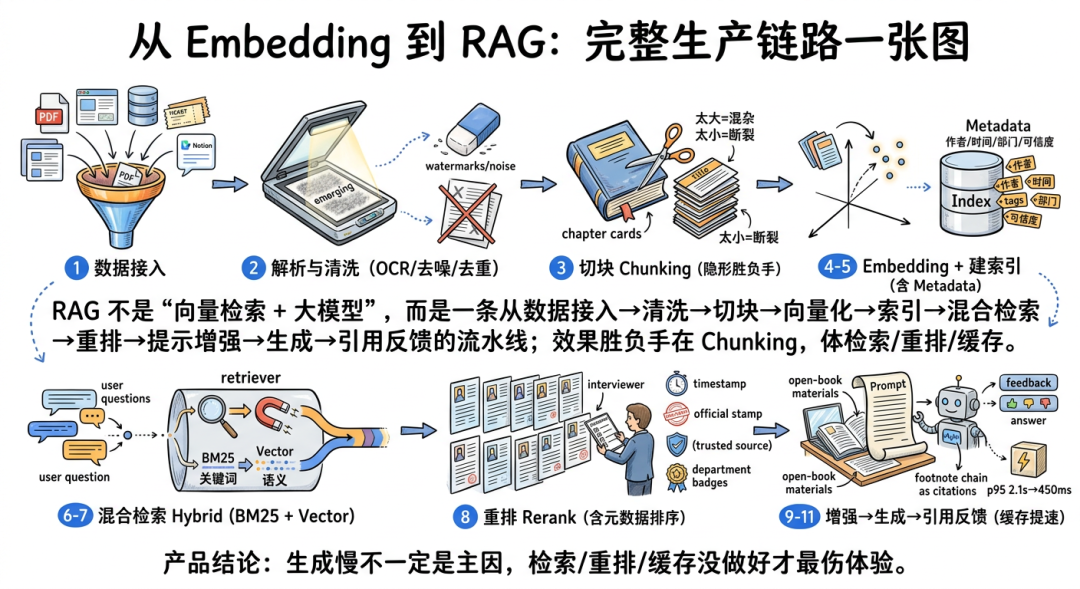
如果只用一句话定义 RAG,它就是:
“先把企业知识变成可检索的向量,再把检索结果喂给生成模型回答。”
但真正上线过的人都知道,RAG 从来不只是“向量检索 + 大模型”这么简单。
它是一条完整的生产流水线。
RAG 完整链路
步骤1 → 数据接入(PDF、网页、数据库、工单、飞书/Notion 文档进入系统)
步骤2 → 解析与清洗(OCR,光学字符识别,像把扫描图片里的字重新“抄”成可编辑文本;再做去噪、去模板页、去重复)
步骤3 → 切块 Chunking(把长文档切成可检索的小段,就像把一本书拆成便于查找的章节卡片)
步骤4 → 向量化 Embedding(每个 chunk 变成语义坐标)
步骤5 → 建索引(写入向量数据库,并附 metadata 元数据,也就是“文档的说明标签”,如作者、时间、部门、可信度)
步骤6 → 用户提问(query 查询也被向量化,变成同一套坐标里的一个点)
步骤7 → 检索 Retrieval(按向量相似度,或 BM25 + Vector hybrid 混合检索;BM25 是经典关键词检索算法,可以理解成“按关键词命中率和重要性打分”)
步骤8 → 重排 Rerank(第二轮“复审”,让更相关、更权威、更新的内容排前面)
步骤9 → 增强 Augmentation(把检索片段拼进 prompt 提示词;prompt 就是你给模型的指令和上下文,这一步很像“开卷考试前,把参考资料摊到桌上”)
步骤10 → 生成 Generation(LLM 基于外部资料回答)
步骤11 → 引用与反馈(附来源、记录点击、用户纠错、进入评估闭环)
为什么切块是 RAG 的“隐形胜负手”
Chunking(切块)最像“把一本书拆成便于检索的章节卡片”。
- 切得太大,语义太混;
- 切得太小,上下文断裂。
这就是很多团队 RAG 效果差的根源:
不是模型不够强,而是块切坏了。
例如:
- FAQ(Frequently Asked Questions,常见问题清单)适合小块、精确匹配
- 法律合同适合按条款/章节切
- 技术文档适合按标题层级切
- 代码知识库适合按函数、类、模块切
为什么混合检索比纯向量更稳
BM25 擅长找精确字面匹配;
向量检索擅长找语义相近内容。
两者混合,像“一个实习生负责找关键词,一个资深顾问负责找意思相近的材料”,组合起来更稳。
2025 年很多 RAG 最佳实践都在强调 Hybrid Retrieval(混合检索),常见权重如 0.3 的 BM25 + 0.7 的 Vector。
这对客服、知识库、企业文档搜索特别有效。
为什么重排是“第二次拯救结果”的机会
向量检索通常负责粗召回:先找一批“可能相关”的文档。
但最终给 LLM 的上下文窗口很有限,所以你还需要 Reranker(重排模型,像二面面试官,负责从候选人里挑出最该上场的几个)。
尤其在多主题知识库里,加入 metadata-aware ranking(基于元数据的排序,也就是参考作者、时间、部门、来源等“说明标签”来排结果)很关键,比如:
- 时间新的优先
- 官方文档优先
- 可信来源优先
- 当前用户部门相关内容优先
一个经常被忽略的数据现实
公开实践数据显示:
- retrieval 阶段常见延迟大约 50–200ms
- generation 阶段常见为 1–5s
- 对高频问题做缓存和预热,可以把 p95 latency(95 分位延迟,理解成“绝大多数用户体感到的慢”)从 2.1s 降到 450ms
这说明一个非常关键的产品结论:
RAG 的用户体验,往往不是败在“模型思考太慢”,而是败在“检索、重排、缓存没做好”。
来源:Google Cloud,Optimizing RAG Retrieval
链接:https://cloud.google.com/blog/products/ai-machine-learning/optimizing-rag-retrieval
来源:Morphik,Retrieval-Augmented Generation Strategies
链接:https://www.morphik.ai/blog/retrieval-augmented-generation-strategies
来源:Tomoro AI,Retrieval-Augmented Generation in 2025
链接:https://tomoro.ai/insights/retrieval-augmented-generation-in-2025
来源:Towards AI,RAG Techniques You Must Know in 2025
链接:https://towardsai.net/p/machine-learning/rag-techniques-you-must-know-in-2025
七、实战上手:一个能跑通的 RAG 配置长什么样
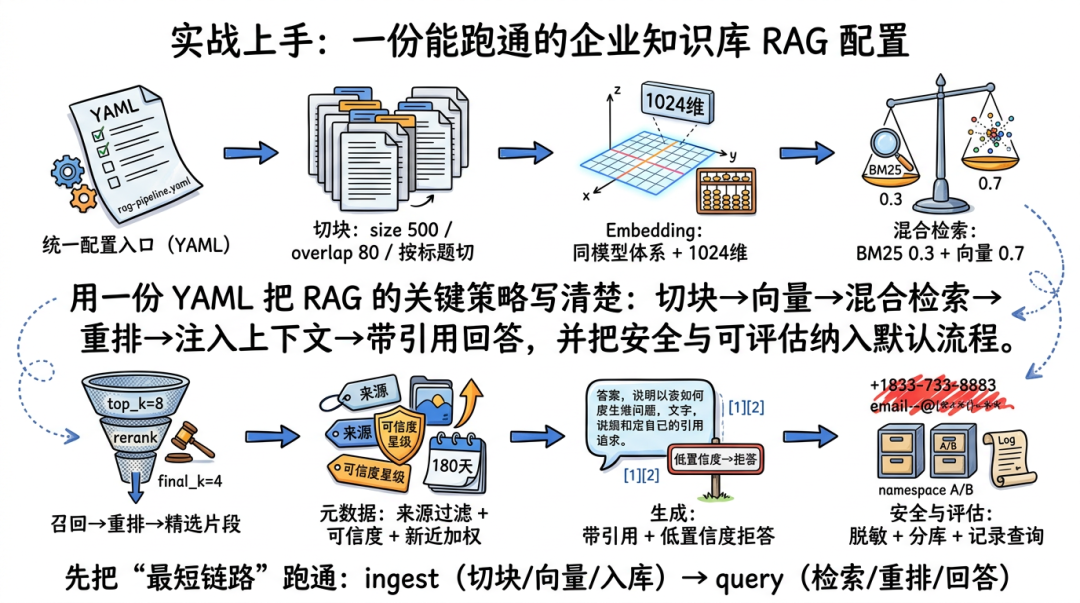
很多人读完理论,最大的问题其实是:
“所以我到底该怎么配置?”
下面给一个非常实用的“通用企业知识库 RAG”思路。
这里用到 Qdrant(开源向量数据库,专门用来存储和过滤高维向量,像一个特别擅长按“意思相近”找资料的仓库)作为向量库;用 OpenAI embedding 作为示例模型。你也可以替换成 Gemini、Voyage 或开源模型。
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献43条内容
已为社区贡献43条内容

所有评论(0)