Harness Engineering: 为 AI 搭建可持续迭代环境的实践
在公司内部一个 AIGC页面 Verify 项目(下面代号 HelixVerify )中,我们经历了 114 次版本迭代, 将相对benchmark 的风险样本召回率从 最初的 8% 提升至 98.86%,无风险样本通过率从 36.11% 提升至 54.93%。
**整个 114 次迭代中,基本没有代码是我手写的。**从第一个版本开始,所有代码都是我指导 AI 完成的——包括搭建闭环环境本身的代码。早期 AI 没有闭环,效率很低:每轮迭代都需要我指出方向、审查结果、告诉 AI 下一步做什么。但 AI 在我的指导下逐步搭建出端到端测试、标准化评测、自动诊断等基础设施——每搭建一个模块,AI 就减少一项对人的依赖。
这是一个自举(bootstrapping)过程:AI 用自己写的代码,逐步把自己迭代到能够自主闭环运行。当闭环完成后,AI 可以 7×24 小时自主运行:分析问题、生成策略、修改代码、验证效果、进入下一轮——整个过程无需人工介入。
工程师的角色从"编写代码"转向"设计环境、明确意图和构建反馈回路"。我们在HelixVerify项目中的实践与 OpenAI 在 2026 年 2 月分享的理念不谋而合:人类掌舵,智能体执行(Humans steer. Agents execute.)。
一、HelixVerify: Agent 产出检测系统
HelixVerify 是一个 Agent 产出质量验证系统,核心通过后置verify系统反馈,消除 LLM 生成页面内容时的幻觉与低质量问题。
1.1 整体架构
HelixVerify 采用三层分离架构:
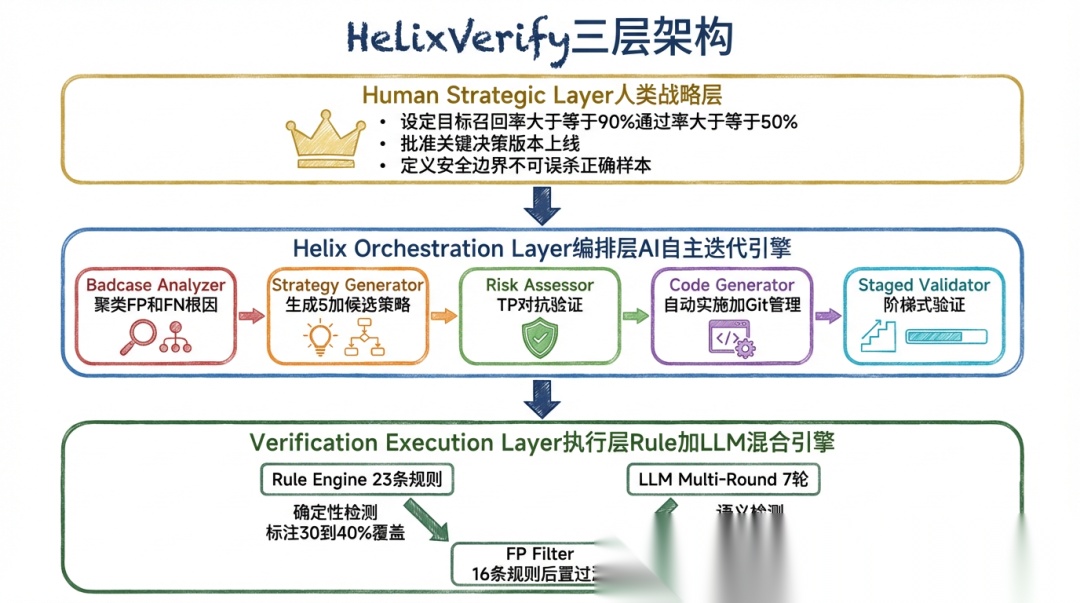
- 首先人类设定目标(召回率≥90%)和安全边界(不可误杀正确样本)
- 然后就让 AI 自主迭代,完成诊断→策略→实施→验证的闭环
- 其中我作为“架构师” 指出应该执行的架构,即下面的混合验证引擎
1.2 混合验证-Rule + LLM
这个架构是我作为人类对 AI 最大的输入。刚开始我让模型持续自迭代,但发现模型(Opus-4.5)做不到自己迭代出一个合理的架构——模型更多是在自己的一亩三分地反复优化。而当我指出”Rule 引擎 + LLM 多轮检测可以优势互补”时,模型就在关键指标上持续取得很大进步。
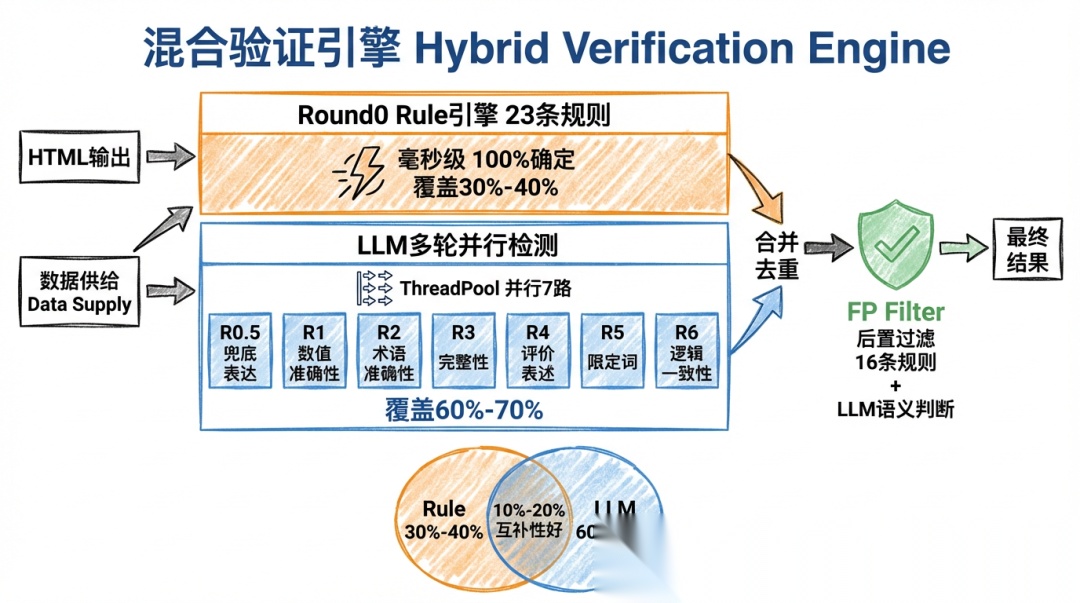
设计思路: Rule 引擎和 LLM 各有所长,让它们各司其职:
- Rule 引擎(23 条规则): 处理确定性错误——HTML 注释残留、JSON 空数据、格式异常等。毫秒级响应,100% 确定,覆盖 30-40% 的错误。
- LLM 多轮检测(7 个维度并行): 处理语义错误——数值不准确、术语误用、逻辑矛盾、信息遗漏等。需要语义理解,覆盖 60-70% 的错误。
- FP Filter(后置过滤): 16 条规则 + LLM 语义判断,过滤两层检测产生的误报。
两者重叠约 10-20%,说明互补性好。
二、如何搭建让 AI 自主迭代的闭环环境
有了验证引擎还不够——AI 需要一个完整的闭环环境才能自主迭代优化这个引擎。本节是这篇文章的核心:搭建闭环所需的 5 个能力模块,以及让闭环 7×24 持续运行的 Loop 基础设施。
需要强调的是:这些模块本身也是 AI 写的代码。 整个过程是一个自举:早期我指导 AI 搭建端到端测试 → AI 有了"看"的能力 → 我指导 AI 搭建评测工具 → AI 有了"量"的能力 → ……每搭建一个模块,AI 对人的依赖就减少一层,直到闭环完全合上。
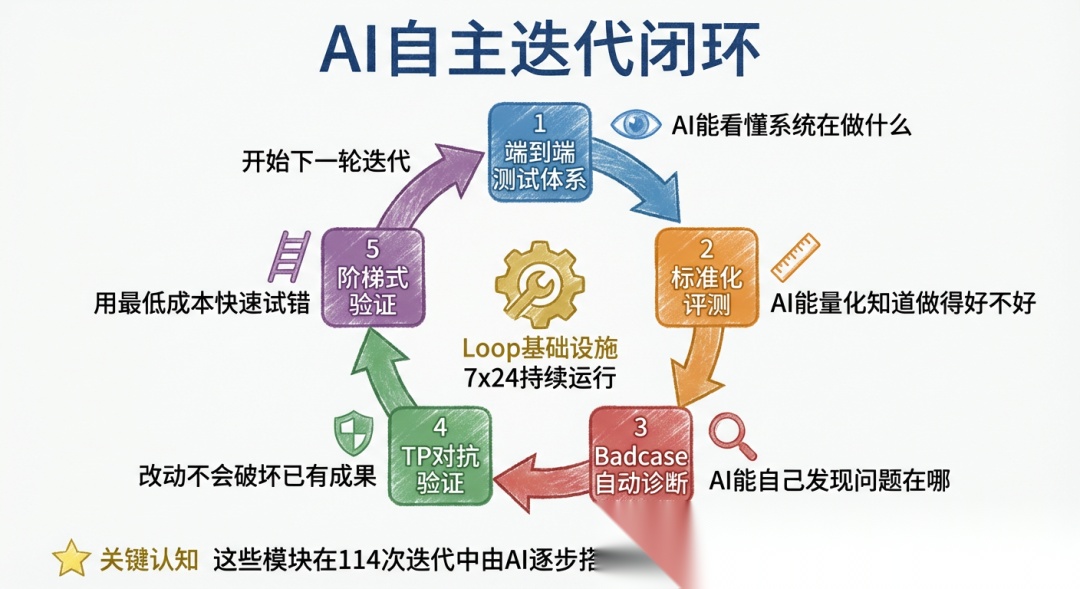
这些模块不是一次性搭完的,而是在 114 次迭代中由 AI 逐步搭建的。每个模块的出现,都是因为闭环在某个环节断了,AI 跑不下去了——然后我指出问题方向,AI 来实现解决方案。
2.1 端到端测试体系:让 AI”看懂”系统
AI 只能改代码,但看不懂改完之后系统内部发生了什么——这就像让一个工程师蒙着眼睛 debug。所以我们要搭建完整的端到端测试框架,让 AI 像人类工程师一样 debug:
- 模拟人类分析 case: AI 发请求、看响应、分析日志,就像人类工程师 debug 一样
- 理解 LLM 的思考过程: 通过日志中的 traceId 追踪每个请求的完整链路,包括 LLM 内部的推理过程——这让 AI 不仅知道”结果不对”,还能理解”哪一步思考出了问题”
- 自主设计测试用例: AI 根据代码变更自己设计测试,不需要人工指定
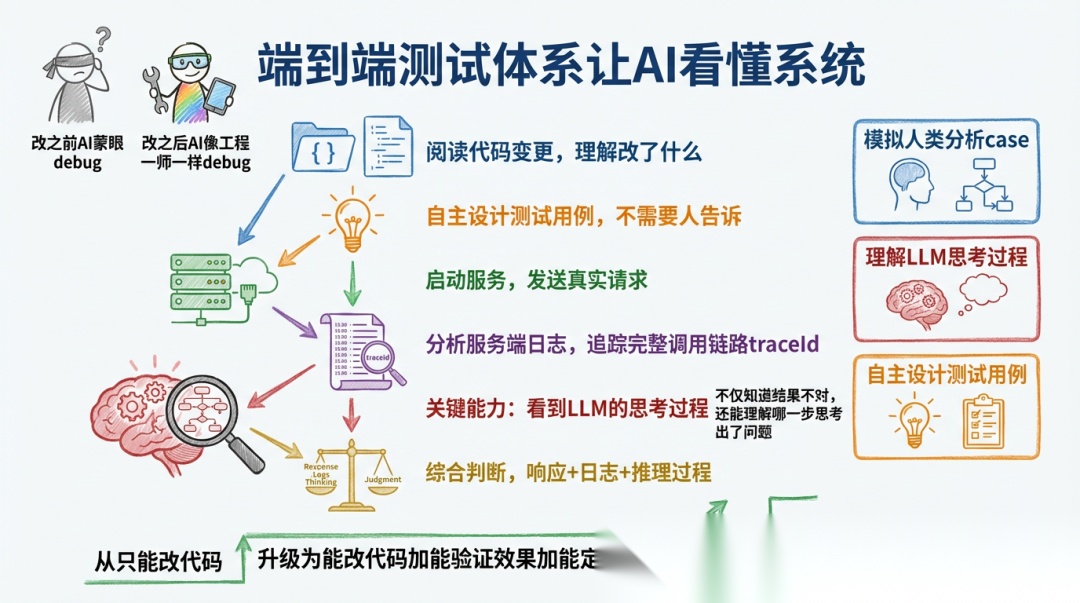
于是 AI 从”只能改代码”升级为”能改代码 + 能验证效果 + 能定位问题”。这是闭环的起点——没有这个能力,后面所有模块都无从谈起。
2.2 标准化评测(verify_bench):给 AI 一把统一的尺子
解决的问题: AI 改完代码后不知道是进步了还是退步了。没有统一标准,AI 无法自主判断迭代结果,闭环在”评估”环节断裂。
我的做法: 构建 verify_bench 评测工具,输出结构化的两份文件:
verify_bench 评测输出├── metric.txt → 量化指标,AI 用来判断”好不好”└── detail.txt → 逐条明细,AI 用来分析”哪里不好”
metric.txt(指标结果):
# AI 可以直接解读的结构化指标{ “total_samples”: 202, “tp”: 85, # 真阳性: 正确检出的错误 “fp”: 234, # 假阳性: 误报 “fn”: 1, # 假阴性: 漏报 “tn”: 345, # 真阴性: 正确通过 “recall”: 0.9886, “pass_rate”: 0.5493}
detail.txt(逐条明细):包含每个样本的完整日志、人工标注的 Ground Truth 结果、以及 HelixVerify 产出的实验过程目录。三者并列,AI 可以逐条对比,发现”人觉得对但机器判错”或”人觉得错但机器漏掉”的具体 case。
为什么这件事对闭环至关重要? 如果 AI 没有一个可程序化调用的评测工具,它就无法自主判断迭代结果。每次改完代码都需要人来看结果、告诉 AI 好不好——闭环就断了。
于是AI 每次改完代码后能自动跑评测、自动解读 metric.txt 判断方向、自动分析 detail.txt 定位问题,自主决定下一步。
detail.txt 如何构建
detail.txt 本身是一个集合,指导 AI 去对应地方查看日志、GT 以及 实验过程目录。我这里附录下具体的实验目录构建步骤:
# ============================================================# Step 1: 设置环境变量# ============================================================...# ============================================================# Step 2: 创建实验目录(带版本号和时间戳)# ============================================================EXPERIMENT_DIR="experiments/v101_stage1_test_$(date +%Y%m%d_%H%M%S)"mkdir -p $EXPERIMENT_DIRecho"📁 实验目录: $EXPERIMENT_DIR"# ============================================================# Step 3: 运行验证# ============================================================echo"🚀 开始验证 Stage 1..."$VENV_PYTHON run_stage_validation_direct.py \ --stage 1 \ --output-dir $EXPERIMENT_DIR# 验证输出示例:# ============================================================# 🚀 Stage 1 | Samples: 10# Data: stage1.xlsx# Temperature: 0.0 (Fixed)# ============================================================# [1/10] BIZ_2026011600000005289480 ✅ BC=2# [2/10] BIZ_2026010500000004072882 ✅ BC=1# ...# [10/10] BIZ_2026011600000005248951 ✅ BC=2# 💾 Results saved: experiments/v101_stage1_test_20260210_104139/stage1_results.xlsx# ============================================================# Step 4: 运行verify_bench评测# ============================================================echo"📊 运行verify_bench评测..."cd ../../../verify_bench....# verify_bench会输出结果目录,例如:# results/20260210_104510_stage1_results_eqfn_v1/# ============================================================# Step 5: 查看评测结果# ============================================================echo"📈 查看指标..."# 找到最新的results目录LATEST_RESULT=$(ls -td results/*stage1* | head -1)echo"最新结果目录: $LATEST_RESULT"# 查看核心指标cat $LATEST_RESULT/metric.txt# 示例输出:# MetricPRF(# tp = 3,# fp = 13,# fn = 1,# p = 0.1875, # Precision: 18.75%# r = 0.75, # Recall: 75%# f1 = 0.3, # F1: 30%# )# MetricRecallPass(# (风险样本)全召回率 = 66.67 %,# (无风险样本)通过率 = 28.57 %, # )# 查看详细case分析(查看前30行)head -30 $LATEST_RESULT/detail.txt# ============================================================# Step 6: 复制verify_bench结果到实验目录# ============================================================cd$VERIFY_V2_ROOTcp -r ../../../verify_bench/$LATEST_RESULT$EXPERIMENT_DIR/verify_bench_resultsecho"✅ verify_bench结果已复制到实验目录"# ============================================================# Step 7: 创建配置快照(推荐)# ============================================================.....# ============================================================# Step 8: 创建分析报告(模板)# ============================================================.....# ============================================================# Step 9: 查看实验目录结构# ============================================================echo"📁 实验目录结构:"tree -L 2 $EXPERIMENT_DIR 2>/dev/null || ls -lR $EXPERIMENT_DIR# 期望输出:# experiments/v101_stage1_test_20260210_104139/# ├── config.json# ├── stage1_results.xlsx# ├── analysis_report.md# └── verify_bench_results/# ├── metric.txt# ├── detail.txt# └── evaluation_results.jsonecho"✅ 完成!现在可以编辑 $EXPERIMENT_DIR/analysis_report.md 进行详细分析"
2.3 Badcase 自动诊断:让 AI 自己发现问题
解决的问题: 以前每轮迭代,都需要我人工分析 badcase,告诉 AI”这批误报的共同特征是 XXX,你试试从这个方向优化”。我是 AI 迭代的瓶颈。
我的做法: 让 AI 直接消费 verify_bench 的两份输出,自动完成诊断:
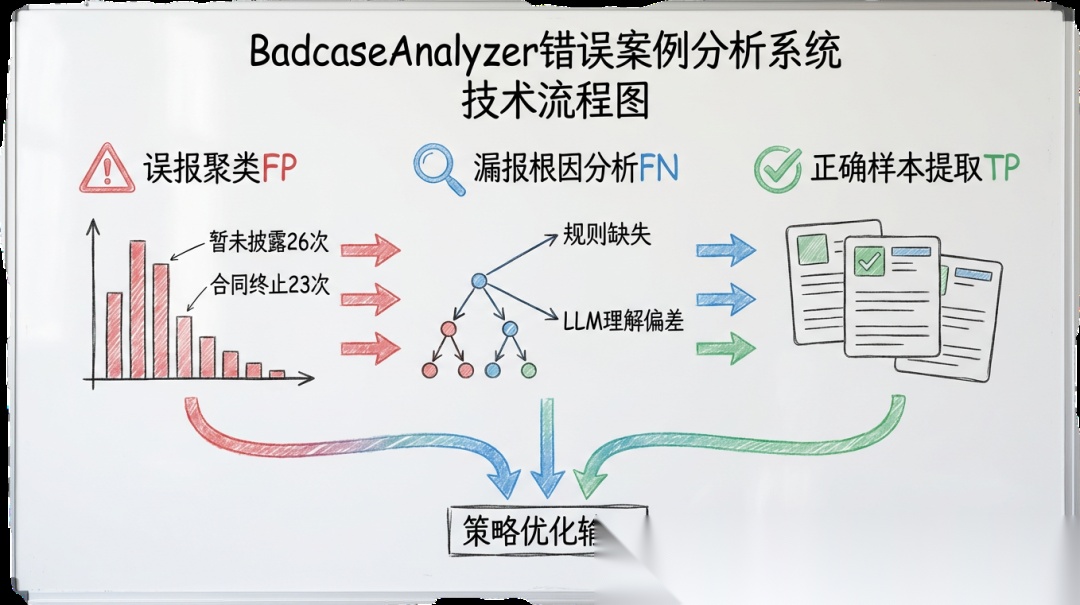
AI 读取 metric.txt 判断当前瓶颈在哪(是召回率不够还是误报太多),然后读取 detail.txt 聚类分析具体 case,自动生成候选优化策略并按预估收益排序。
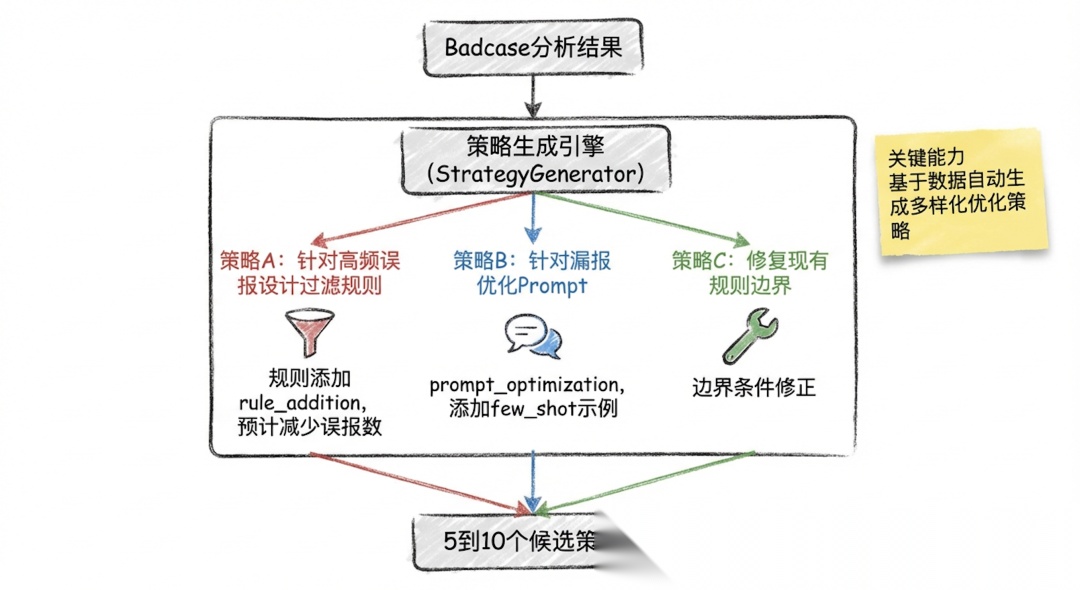
关键设计: AI 的诊断是数据驱动的——它从 detail.txt 的逐条对比中发现规律,而不是凭”直觉”猜测。这比人工分析更系统、更不容易遗漏。
解锁的能力: 人类不再需要参与”分析问题”这个环节。AI 自己跑评测、自己分析结果、自己生成策略。
2.4 TP 对抗验证:让 AI 的改动安全
在当前的指标优化场景汇总,AI 自主迭代往往会出现“按下葫芦起了瓢”的情况,即优化了一个指标,另一个指标反而下降了。 比如在 v105 中, AI 统计了高频误报的 case ,直接设计过滤规则和 prompt 。对于正确样本误报确实减少了 23 个,使得无风险样本召回率上升了,但是讲原有的风险样本错误也误杀了,风险样本召回率从 90% 暴跌至 40%。
之所以有这种”优化一个指标、破坏另一个指标”的困境,根因在于 AI 只看了误报数据,没有交叉验证正确样本。所以我们需要TP(True Positive)对抗验证——任何过滤规则上线前,必须验证它不会误杀正确样本:
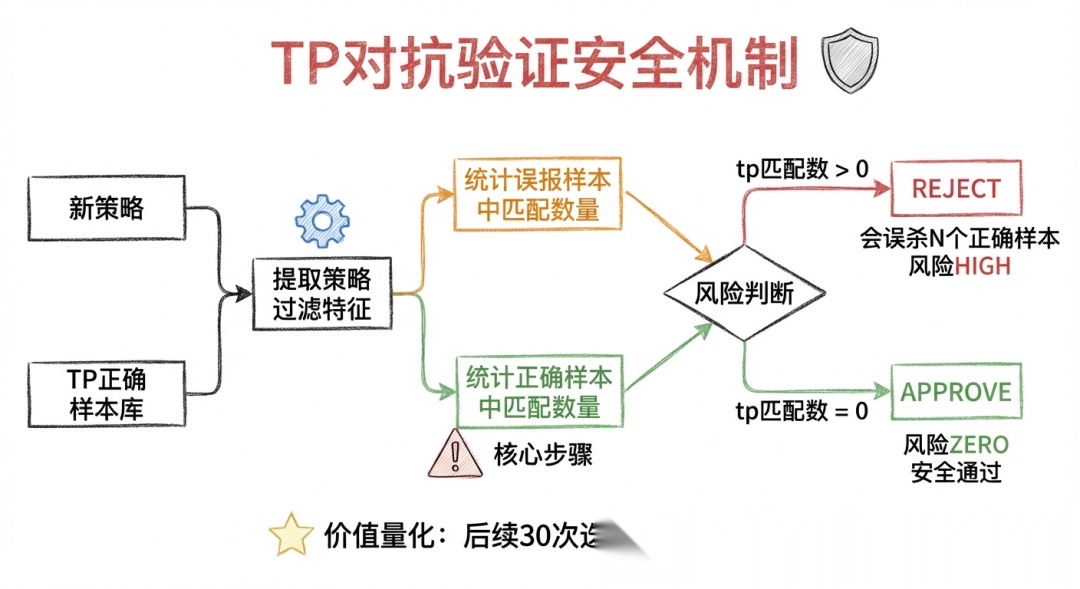
实现 TP 对抗验证后,后续 30 次迭代无一次召回率下降。AI 终于可以放心地优化误报,不用担心破坏已有成果。
我们需要有手段保证AI 的迭代从”可能破坏”变为”保证不破坏”。使用代码围栏、Lint、对抗测试与模块等。
2.5 阶梯式验证:让 AI 用最低成本试错
全量评测(202 样本) 需要 60 分钟。如果每次试错都跑全量,AI 一天只能迭代几次,效率太低。
于是我从小样本到大样本逐层验证,90% 的问题在前 3 分钟暴露:
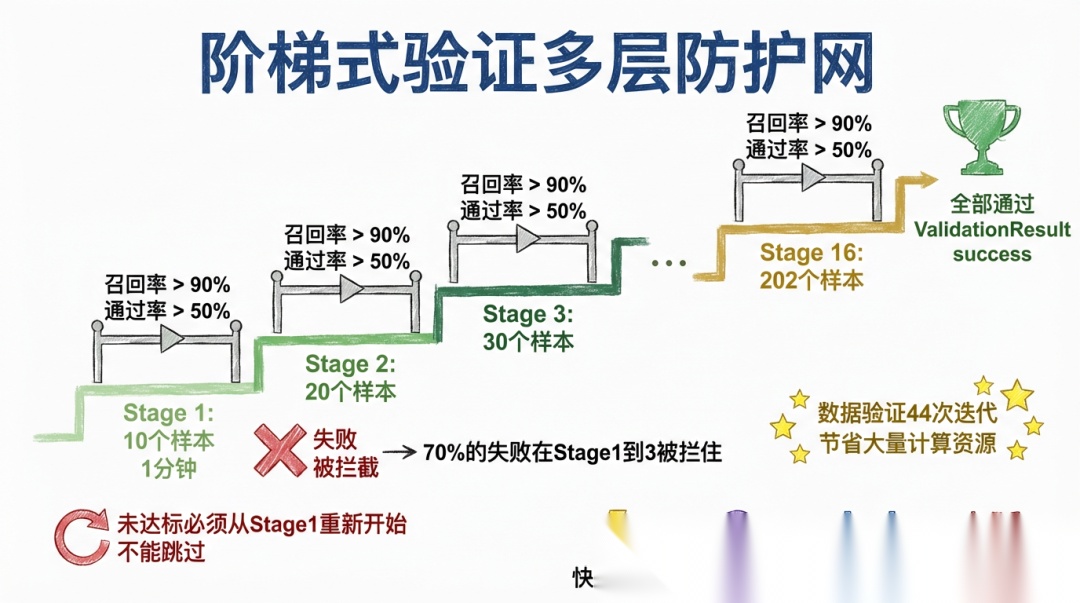
为什么不直接跑全量? 因为 AI 的大部分尝试会失败——114 次迭代中 70% 是失败或部分达标。让失败在 3 分钟内暴露,比在 60 分钟后暴露,节省了巨大的时间成本。
于是AI 一天可以迭代十几次(而非几次),大幅加速”试错-学习”循环。
2.6 Loop 基础设施:让 AI 7×24 持续运行
前面 5 个模块解决了”AI 能做什么”的问题,但还有一个关键问题:谁来驱动 AI 不停地跑下去?
人类不可能 24 小时盯着屏幕按回车。我们需要 Loop 基础设施。
Ralph-Loop:让 AI 自己决定”做没做完”
Claude Code 本身是 Loop 组成的智能体,而人类使用 Claude Code 的过程(提需求→规划→实现→review→再提需求)本身也是一个 Loop。Ralph-Loop 借助 Stop Hook,强制 AI 每次自然停下时反思任务是否完成,没完成就继续:
/ralph-loop “Fix xxx” --max-iterations 10 --completion-promise “FIXED”
这个命令让模型修复 xxx,一直到 AI 认为自己修复完成并显式输出 “FIXED” 才会停止,最大迭代 10 次。
上下文窗口不会爆掉吗? 不会。Ralph-Loop 在每轮任务结束后彻底关闭当前 AI 进程并重新启动,模型将进度和状态存储在本地文件中,剥离”短期记忆”。
实际体验: 我跑通了持续运行 6 小时以上的任务。不过也得承认没有很稳定能有效运行这么久——模型会反思进入自身的”无进度循环”中,也可能触发上下文溢出(比如模型突然读了一个很大的日志文件)。保持任务原子化和可验证是关键。
之所以我要求是整个流程要做到连续跑 6h 以上–是希望至少人睡觉前启动下,睡觉后可以看结果。 这个主要依赖两个,一个是 Ralph Loop 本身会不停 save session 再 resume ; 第二个是需要调试到模型每次工作都有完好的实验记录,保证每一次迭代是在上一次基础上前进。让模型每次在新的 session 可以看到之前的实验记录,包括benchmark 、评测结果以及评测细节等。
Supervisor:给 AI 加一个”AI 主管”
Ralph-Loop 的缺点很明显——单纯让 AI 自己反思,不能给 AI 指导性意见,不能像人类一样 review AI 每次停下来的输出,或者在 AI 问你选 A 还是 B 方案时给出判断。
解决办法:在最外层 Loop 加一个 Supervisor Agent,它扮演人类的角色:
| 方面 | Ralph-Loop | Supervisor |
|---|---|---|
| 检测方式 | AI 输出结构化状态 + 规则解析 | Supervisor AI 直接审查 |
| 评估方式 | 基于信号和规则 | Fork 会话上下文,评估实际质量 |
| 灵活性 | 需要更新规则代码 | 更新 Prompt 即可 |
Supervisor 会判断:AI 是否在等待确认?是否做了该做的事?代码质量是否达标?用户需求是否全部满足?
不过复杂场景下 AI 归根结底不能代替人做判断。当 AI 给出选项 A、B、C 时,Supervisor 或许能根据当下情况选择,但目前还不能像人一样提出 D 选项。比如下面这个场景:AI 自己给出了几个选项并选了 A,但我明显不同意它妥协的做法——这个判断就是人的核心价值所在。
下面是 AI 在 Loop 中 “Aha Monent” 的时候: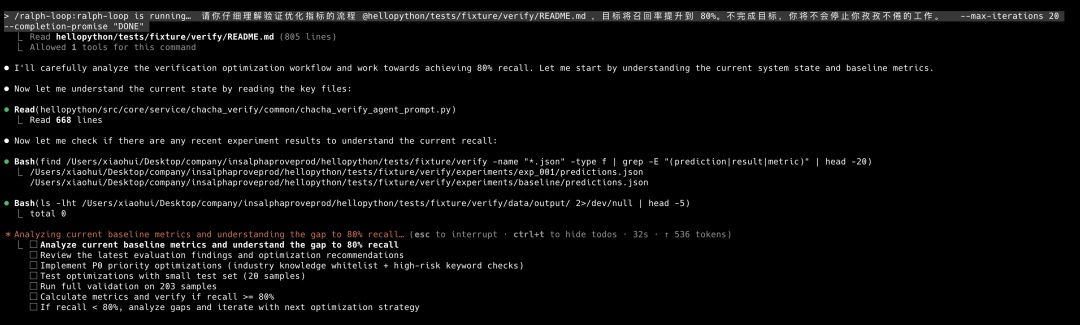
⚠️ Loop 过程中我们要避免上下文的无关消耗 虽然每次新的 Loop 会开启新窗口。但是单次 Loop 上下文窗口依然是非常有限的资源。不珍惜的话不仅仅是效果问题,当次 Loop 也可能被中断。 比如实验日志动辄数千行,多次轮询会快速耗尽上下文,导致 AI"失忆"。需要主动避免 AI 无效轮询评测过程。
# ❌ 不要多次非阻塞读取检查进度(每次重新加载全部日志)while True: result = TaskOutput(task_id, block=False) # ✅ 阻塞等待,一次性获取结果result = TaskOutput(task_id, block=True)
闭环 + Loop = 基于测试的应用级”强化学习”
当 AI 有了闭环的 5 个能力模块,又有了 Loop 基础设施持续运行,整个系统就构成了一个类似强化学习的过程:
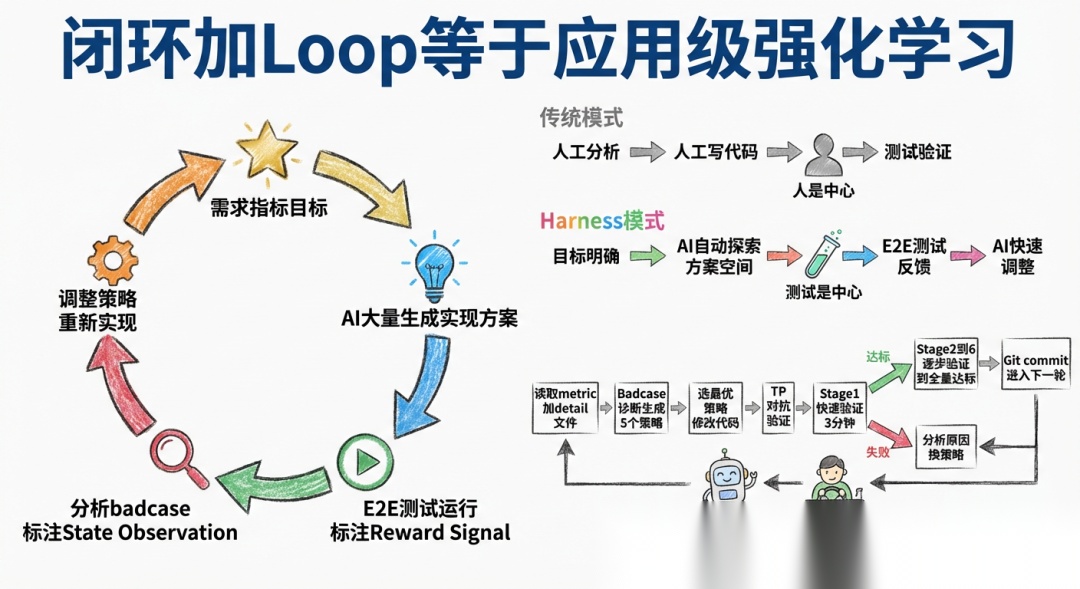
闭环合上前后的对比:
| 闭环前(v1-v70) | 闭环后(v71-v114) | |
|---|---|---|
| 人的角色 | 指导 AI 分析 badcase、指定方向、审查每次改动 | 设定目标、审批上线 |
| AI 的角色 | 执行人的指令写代码,同时搭建环境模块 | 自主完成诊断→策略→实施→验证全流程 |
| 迭代周期 | 5-7 天/轮 | 3-4 小时/轮 |
| 迭代成功率 | ~60% | ~75% |
| 召回率进展 | 0% → ~80%(70 个版本,~4 周) | 87% → 98.86%(44 个版本,~2 周) |
114 次迭代最终成果:
| 指标 | v71 基线 | v114 最终 | 提升幅度 |
|---|---|---|---|
| 召回率(Recall) | 87.42% | 98.86% | +11.44pp |
| 通过率(Pass Rate) | 36.11% | 54.93% | +18.82pp |
| 误报数(FP) | 346 | 234 | -112 (-32.4%) |
| 漏报数(FN) | 19 | 1 | -18 (-94.7%) |
三、Harness Engineering:从实践中提炼的方法论
前两节讲了我们做了什么、怎么搭建闭环。本节提炼背后的方法论——让这些经验可以复用到其他场景。
OpenAI 在 2026 年 2 月分享了类似的理念:用 Codex 智能体完成产品开发,接近 100 万行代码没有一行是人工编写的。他们总结的核心是:人类掌舵,智能体执行(Humans steer. Agents execute.)。工程师的角色从”编写代码”转向”设计环境、明确意图和构建反馈回路”。 OpenAI. 将其提炼为 Harness Engineering:
Harness Engineering = 工程师的主要工作不再是编写代码,而是设计环境、明确意图和构建反馈回路,从而使 AI 智能体能够可靠地工作并交付成果。
我们在 HelixVerify 中实践了同样的理念。这里我还想提出基于自身实践的四条核心原则:
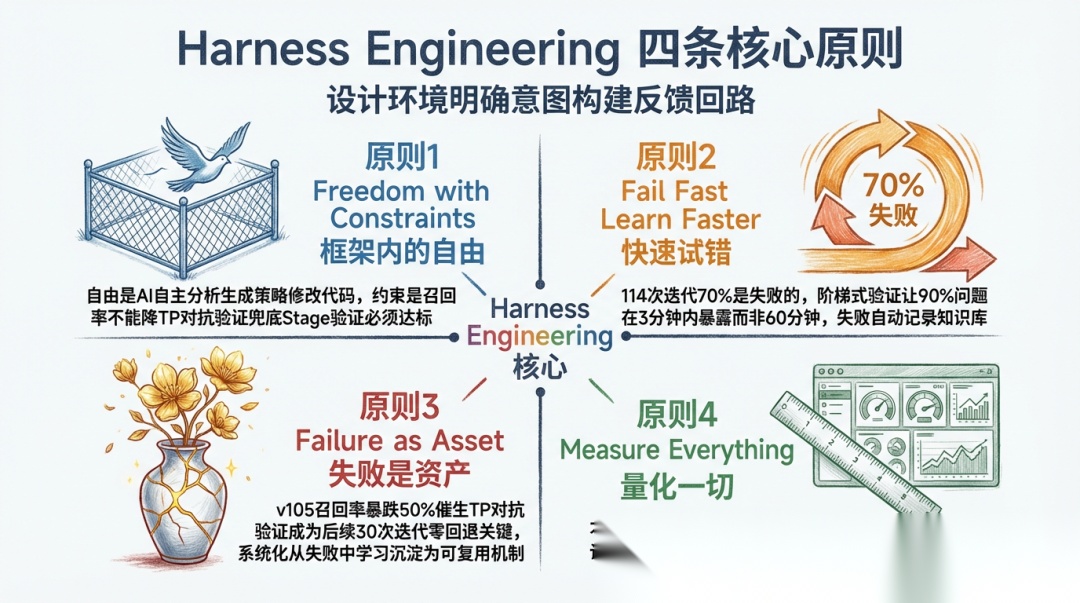
可复制的实施路径
如果你想为自己的场景搭建类似的闭环,建议按以下顺序:
Phase 1: 让 AI 能”看”和”量”
- 搭建端到端测试体系:让 AI 能发请求、看日志、追踪调用链路
- 对接标准化评测工具:让 AI 有统一的量化指标
- 建立 Git 版本管理:每次迭代自动 commit,全程可追溯、可回滚
Phase 2: 让 AI 能”诊”和”治”
- 实现 Badcase 自动诊断:让 AI 能从评测结果中自动发现问题
- 实现 TP 对抗验证:让 AI 的每次改动都安全可控
- 实现阶梯式验证:让 AI 能用最低成本快速试错
Phase 3: 让 AI 7×24 自主运行
- 配置 Ralph-Loop 或 Supervisor,让 AI 持续迭代(现在 Claude Code 自带了原生 Loop)
- 失败案例自动记录到知识库,避免重复犯错
- 人类只需设定目标和审批上线
结语
Harness Engineering 的核心很简单:为 AI 搭闭环,让 AI 自举到自主运行。
HelixVerify 的 114 次迭代,基本没有代码是我手写的。AI 在人的指导下,逐步搭建出让自己能够自主迭代的闭环环境——端到端测试、标准化评测、Badcase 诊断、TP 对抗验证、阶梯式验证、Loop 基础设施。每搭建一个模块,AI 对人的依赖就减少一层,直到闭环完全合上,AI 可以 7×24 自主运行。
HelixVerify 在质量验证领域验证了这个理念:
- 效率: 迭代周期从 5-7 天缩短至 3-4 小时(30-40 倍)
- 质量: Recall 8% → 98.86%, Pass Rate 36.11% → 54.93%
- 成本: 原本需要很多人标注、看 Case,现在只需要开发者为 AI 建立 Harness 的环境
当你需要 AI 来完成长流程闭环任务时, 先问自己几个问题,如果哪个环节的答案是”不能”,那就是你需要搭建环境中的下一个模块。
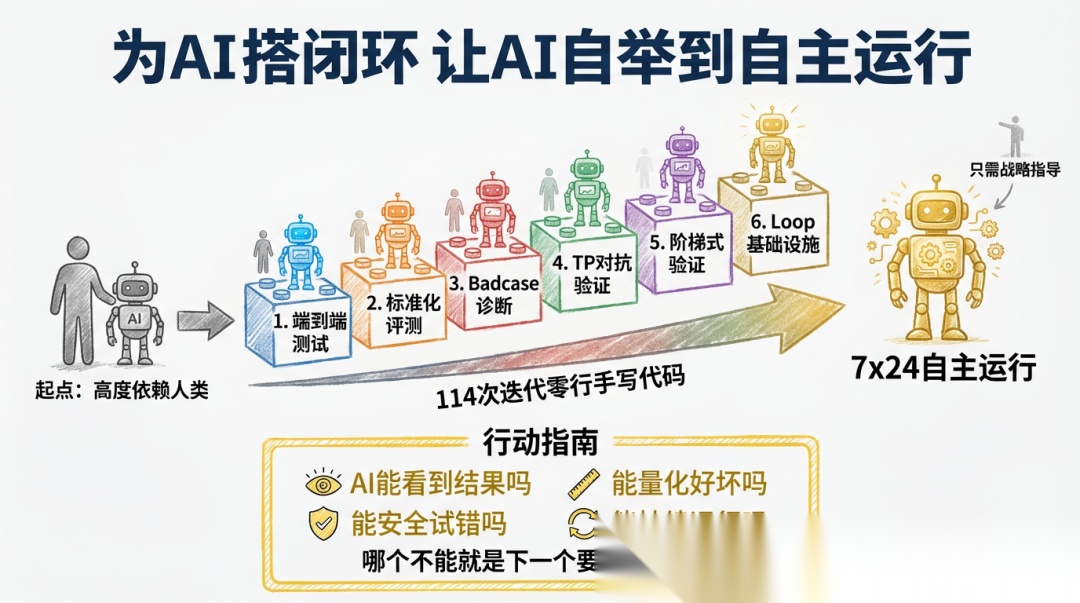
希望这些经验能对后 OpenClaw 时代,开发者有效管理 AI 交付需求有所启发。
术语表
为了方便非算法背景的读者理解,这里列出文章中使用的核心术语:
质量验证指标
| 术语 | 英文 | 解释 | 场景示例 |
|---|---|---|---|
| 召回率 | Recall | 所有真实错误中被成功检测出的比例 | 100个真实错误,检出90个,召回率=90% |
| 通过率 | Pass Rate | 没有误报的样本占总样本的比例 | 100个样本,60个完全正确(无误报),通过率=60% |
| 真阳性 | TP (True Positive) | 正确检出的错误样本 | 检测出的错误确实是错误 |
| 假阳性 | FP (False Positive) | 误报,把正确的判断为错误 | 把正确内容误判为错误 |
| 假阴性 | FN (False Negative) | 漏报,把错误的判断为正确 | 错误内容未被检测出 |
| 真阴性 | TN (True Negative) | 正确判断为正确的样本 | 正确内容被正确识别 |
核心机制
| 术语 | 解释 | 价值 |
|---|---|---|
| TP 对抗验证 | 在设计过滤规则前,验证该规则是否会误杀正确样本 | 防止召回率下降 |
| 阶梯式验证 | 从小样本到大样本逐层验证,快速暴露问题 | 节省验证时间 |
| Rule+LLM 混合 | 规则引擎处理确定性错误,LLM 处理语义错误 | 优势互补,提升覆盖率 |
工程术语
| 术语 | 解释 |
|---|---|
| Badcase | 错误案例,包括误报(FP)和漏报(FN) |
| Ground Truth (GT) | 人工标注的正确答案 |
| Benchmark | 用于评测的标准数据集 |
| Stage | 阶梯式验证中的一个阶段 |
注: Recall 和 Pass Rate 指标均相对于当前 benchmark
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献201条内容
已为社区贡献201条内容

所有评论(0)