大模型&Agent相关资料
大模型&Agent资料
大模型已从“参数竞赛”转向效率、推理、多模态。不再拼谁参数最多,而是谁能真正用好。
关键技术趋势
| 关键技术 | 通俗解释 | 为什么现在最火 | 代表模型/例子 |
|---|---|---|---|
| 多模态 | 能看图、听声、看视频 | 更接近真实世界 | Gemini 3, GPT-5 |
| Agent / Agentic | AI自己做事、规划任务 | 从聊天 → 干活 | Grok、OpenAI o系列 |
| 多智能体 | AI组队合作、互相辩论 | 解决超复杂问题,准确率高 | Grok 4.20 的4-Agent |
| MoE | 只用需要的专家,省电省钱 | 性能强 + 成本低 | DeepSeek, Mistral |
| 领域专用/小模型 | 专攻某个行业,小巧高效 | 企业实用、隐私好 | IBM Granite, SLM |
| 长上下文+记忆 | 记住超多内容、不容易忘 | 处理真实长文档/项目 | Claude 4, Gemini |
Mixture-of-Experts (MoE):动态路由,只激活专家子模块,推理成本大幅降低,同时保持高性能(Mistral、DeepSeek、Grok都在用)。
长上下文 + 分层记忆:上下文窗口轻松百万token + 终身记忆系统,能记住整个项目历史,不用反复喂资料。
多模态(Multimodal):一模型处理文本+图像+视频+音频(GPT-5系列、Gemini 3最强)。
测试时计算(Test-time Compute)+ Chain-of-Thought:推理时额外“思考”几步,准确率暴增(类似OpenAI o系列)。
RAG + 参数高效微调(LoRA):结合外部知识库,减少幻觉,快速适配企业场景。
2026主流Top模型一览表:
| 模型 | 开发者 | 核心优势 | 典型应用场景 |
|---|---|---|---|
| GPT-5.5 / o系列 | OpenAI | 最强推理 + 多模态 | 研究、法律、复杂决策 |
| Gemini 3 | 搜索集成 + 多模态速度快 | 总结、翻译、实时分析 | |
| Claude 4 | Anthropic | 安全对齐 + 长上下文 | 医疗、合规、代码审查 |
| Grok 4 / 4.20 | xAI | 原生多智能体 + 实时辩论 | 复杂工程、策略、科研 |
| Llama 4 / DeepSeek V3 | Meta / 深求 | 开源 + MoE高效 | 企业私有化部署 |
数据来源 Top LLMs and AI Trends for 2026 | Clarifai Industry Guide
Agent 与多智能体
25年“单Agent” ==》26年“多Agent协作“ 趋势
单Agent容易“单打独斗”出问题(重复逻辑、幻觉),多Agent像一支团队:分工、辩论、共识,效率和准确率指数级提升。
为什么多Agent是趋势
-
单Agent适合简单任务,多Agent能端到端处理复杂工作流(营销、HR、产品研发全覆盖)。
-
超过80%的Fortune 500公司正在使用活跃的AI Agent”(基于2025年11月的遥测数据)
-
流行多Agent框架
- LangGraph:一个专为构建长期运行、有状态的智能体 (Agent) 和多智能体系统而设计的底层编排框架。它以“图”的方式定义工作流,尤其适合处理复杂的、需要循环和条件分支的任务
- CrewAI:一个专为构建多智能体协作系统而设计的 Python 开源框架。它让多个 AI 智能体像真实团队一样,通过角色分工和流程编排,自动化处理复杂任务
- AutoGen(Microsoft):开源多智能体 AI 应用框架,用于构建由多个 LLM 智能体、工具和人协同工作的复杂应用。
案例
xAI Grok 4.20 原生4-Agent系统(2026年2月上线,已在Beta中广泛使用)
每次复杂问题自动启动4个专业Agent并行工作:
- Captain Grok:总指挥,拆任务、汇总最终答案
- Harper:研究员,实时查X数据(每天6800万条)+事实核查
- Benjamin:逻辑/数学/代码专家,步步推理、严谨验证
- Lucas:创意+反驳专家,找盲点、提出新假设(故意唱反调)
流程:并行思考 → 多轮内部辩论 → 共识合成。
效果:幻觉降低65%+,复杂推理能力提升2-4倍(数学、工程、策略任务特别明显)。成本仅单次推理的1.5-2.5倍。
Gork4
| 版本阶段 | 多智能体形式 | 主要特点 | 能耗/延迟 | 适用场景 |
|---|---|---|---|---|
| Grok 4 (2025.7) | Grok 4 Heavy 多 agent 并行 | 多个假设并行 → 交叉验证 → 选优 | 高(几分钟) | 极难推理、学术级题目 |
| Grok 4.1 Fast | 原生工具调用 + agent 倾向 | 更偏向单体,但支持长上下文 agent 任务 | 低 | 日常工具型 agent |
| Grok 4.20 (2026.2~) | 原生 4-agent 协作系统 | 固定角色分工 + 实时辩论 + 共识合成 | 中等 | 工程、创作、研究综合任务 |
MoE(Mixture of Experts,专家混合) —— 聪明又省钱
MoE 的核心思想是:一个大模型内部有很多“专家”(子网络),每次推理只激活其中一小部分专家,而不是全部参数都参与计算。
结构上:
- 一个 MoE 层里有若干“专家”(通常是前馈网络 FFN)。
- 配一个“路由器”(Router/Gating Network),根据输入决定激活哪些专家。
效果上:
- 总参数量可以非常大(看起来像“超大模型”),
- 但每次推理只用到其中一部分参数,计算量接近小模型。
为什么:传统大模型每次都全开,太费电费钱。MoE让模型又强又高效,推理成本降很多。用相对可控的成本,争取接近“巨无霸模型”的能力。
例子:问法律问题,只激活“法律专家”;问代码,只激活“编程专家”。速度快、便宜,还准。
2026现状:DeepSeek、通义千问、GPT-4等主流模型都在用MoE。
长上下文+记忆
大模型的核心是Transformer架构,它用自注意力(Self-Attention)机制来理解每个词跟其他所有词的关系。
2024-2026年主流技术
长上下文
高效注意力机制(让计算不爆炸):
- FlashAttention / Ring Attention:重写注意力计算方式,把内存访问优化到极致,速度快几倍,内存用得少。Google、IBM、xAI 等都在用这个。
- Sparse Attention 或 局部注意力:不是每个词都看全部上下文,只关注“附近”和“重要”的部分(像人脑不记所有细节,只记关键点)。
- 相对位置编码(Relative Positional Encoding):取代绝对位置,让模型更容易泛化到超长序列。
训练数据和方法升级:
- 用超长文档数据集预训练:比如几百万token的长文章、代码库、书籍全塞进去反复练,让模型学会“长距离依赖”。
- 合成长上下文数据:模型自己生成超长训练样本,再压缩/扩展训练,专门治“中间忘事”问题(needle-in-haystack 测试里表现好很多)。
硬件 + 推理优化:
- 大量GPU/TPU集群 + 上下文并行(context parallelism):把超长序列切分到多张卡上计算。
- KV Cache 优化:注意力计算的中间结果缓存起来,重用时不重复算。
从2023年的几千token,到2026年Gemini 3/Claude 4/Grok 4 轻松上百万token(Gemini 3 甚至宣称10M,但实际有效长度通常1-2M左右)。不过有个小问题叫“context rot”(上下文衰减):超长时模型对中间内容的注意力会变弱,厂商还在持续优化。
持久记忆(跨对话、跨天记住你)
长上下文是“本次对话的超大工作台”,但关掉聊天就全忘了。持久记忆相当于给AI加个“硬盘”或“记事本”。
实现方式主要有两种(2025-2026年普及):
- 内置记忆模块(模型原生支持):
- 向量数据库 + 检索:把你之前的对话/偏好转成向量,存到外部数据库(像Pinecone、Weaviate)。下次对话时,AI自动检索最相关的记忆插进上下文。
- 专用记忆层:像Google的“Titans + MIRAS”或DeepSeek的条件记忆模块,用神经网络学“什么该记、什么该忘”,优先存“惊喜/重要”的信息(模仿人类记忆偏向异常事件)。
- 厂商例子:
- Grok:从2025年4月起内置持久记忆,能记住你的风格、项目偏好、跨会话调用(在xAI平台内)。
- Claude:2026年全用户开放“persistent memory”,还能从ChatGPT/Gemini导入记忆。
- Gemini/ChatGPT:类似,用外部存储 + 自动召回。
- 外部工具/平台增强(企业/开发者常用):
- 用LangChain、CrewAI 等框架加“记忆缓冲区”:短期用上下文,长期存数据库。
- CLAUDE.md 文件或类似:Claude Code里自动加载用户自定义记忆文件。
总结:长上下文靠架构+训练+硬件硬扛长度;持久记忆靠外部存储 + 智能检索 + 神经记忆模块“记住你”。
DSLMs(Domain-Specific Language Model 领域特定语言模型)
DSLMs:针对特定行业(vertical)、职能(function) 或 任务(task) 优化训练或微调的模型。
- 训练数据:专业数据集(如法规文件、内部知识库、行业报告、专利文献)。
- 目标:嵌入“领域专家知识”,输出更准、更可靠、更符合合规。
趋势分析
企业痛点解决:通用模型幻觉多、隐私泄露风险高、成本贵;DSLMs更安全、更省钱、更精准。
相比通用LLM,DSLMs开发成本可降50%,部署更快,准确率更高(尤其在受监管行业如金融、医疗、制造)。
趋势结合:DSLMs常和Agentic AI(智能体AI)搭配用,让Agent在专业场景下决策更靠谱。
实现(一般方法)
从小模型起步(SLM + 领域微调):用7B-70B参数的小模型(比GPT-5小100倍),再用企业私有数据微调。
方法:
-
Fine-Tuning:在通用模型基础上,用领域数据继续训练。
-
Retrieval-Augmented:结合RAG(Retrieval-Augmented Generation检索增强生成),但数据源只限领域内。
GAG:先从外部知识库里找出相关内容,再把这些内容喂给大模型,让它基于检索到的信息生成回答,而不是直接靠模型“凭记忆”回答。
-
从头训练(少数):用纯领域数据从零训(成本高,但最纯)。
| 领域 | DSLMs 优势示例 | 对比通用LLM的具体提升 | 数据来源(2025-2026) & 代表厂商/案例 |
|---|---|---|---|
| 医疗 | 临床事实性、诊断准确率更高;减少医疗错误 | • John Snow Labs MedS(8B参数DSLMs):事实性优于GPT-4o 5-10% • DocOA(骨关节炎专用):基准准确率 88% vs GPT-4 24%(巨大领域差距) | Nature Medicine (Med-PaLM 2研究)、John Snow Labs专家评测 (2025)、JMIR研究 (DocOA 2024/2025更新) 代表:Epic In-basket ART(已生成百万级草稿,医生偏好更高)、Google Med-PaLM系列、John Snow Labs MedS/MedM |
| 金融 | 合规性、隐私保护、输出一致性更强;幻觉显著减少 | • IBM Granite系列:在金融RAG任务中faithfulness(忠实度)领先,幻觉率低至 ~5%(Vectara榜单) • 小型DSLMs在监管金融任务中输出一致性100%(大模型仅12.5%) | Gartner《DSLMs Reduce Risks for GenAI in Financial Services》(2025)、arXiv金融漂移研究 (2025)、Vectara Hallucination Leaderboard (2026更新) 代表:IBM Granite 3.0/3.3系列(企业首选) |
| 制造 | 理解技术手册、预测维护更高效;响应更快、成本更低 | • SLM/DSLMs整体AI总成本降低 85-95%(训练+推理) • 预测维护场景:非计划停机时间可减少 56% | Harvard Business Review AI成本分析 (2026)、NIST制造研究引用、SLM企业案例 (2025-2026) 代表:IBM Granite制造变体、DeepSeek等开源领域微调小模型 |
| 法律/合规 | 精确解读法规、合同审查更可靠;可解释性强 | • 合同智能基准:专用模型可靠初稿率 73.3%(与资深律师相当或略胜) • 通用LLM在法律任务中幻觉率可高达 75%+(专用模型显著降低) | Harvey AI Contract Intelligence Benchmark (2025)、Stanford Legal RAG Hallucinations研究 (2025) 代表:Harvey AI、Contractzlab等法律专用模型 |
微调方式
1. 全参数微调(Full Fine-Tuning)
- 把整个基础模型的参数都放开,用领域数据继续训练一轮或多轮。
- 优点:领域能力提升最大,能充分“改写”模型行为。
- 缺点: 需要大量显存/算力(比如 7B 模型至少多张 A100); 容易“忘掉”一部分通用能力(灾难性遗忘)。
2. 参数高效微调(PEFT,更常用)
只训练少量新增或少量可训练参数,原模型大部分不动,例如:
- LoRA:在注意力层等位置加低秩矩阵,只训练这些矩阵。
- Adapter:在模型各层插入小型“插件”模块,只训练插件。
- Prefix/Prompt Tuning:在输入或某些层加可学习的“前缀向量”,只训练这些向量。
优点:
- 显存/算力要求低,可以用单卡甚至消费级 GPU 做 7B/13B 模型;
- 保留原模型通用能力,只“加领域能力”。
缺点:
- 对极深、极复杂的领域适应,可能略弱于全参数微调(视数据量和任务难度而定)。
3. 持续预训练(Continual Pre-Training)
- 在通用预训练之后,用大规模、持续不断的领域语料再预训练一段时间。
- 介于“预训练”和“微调”之间,数据量通常比普通微调大很多。
- 适合: 行业语料极其丰富(如几十年金融数据、海量代码); 希望模型在领域语言理解上更“底层”地变强。
- 缺点是:成本更高,对算力和数据工程要求都很大。
Agent or Agentic
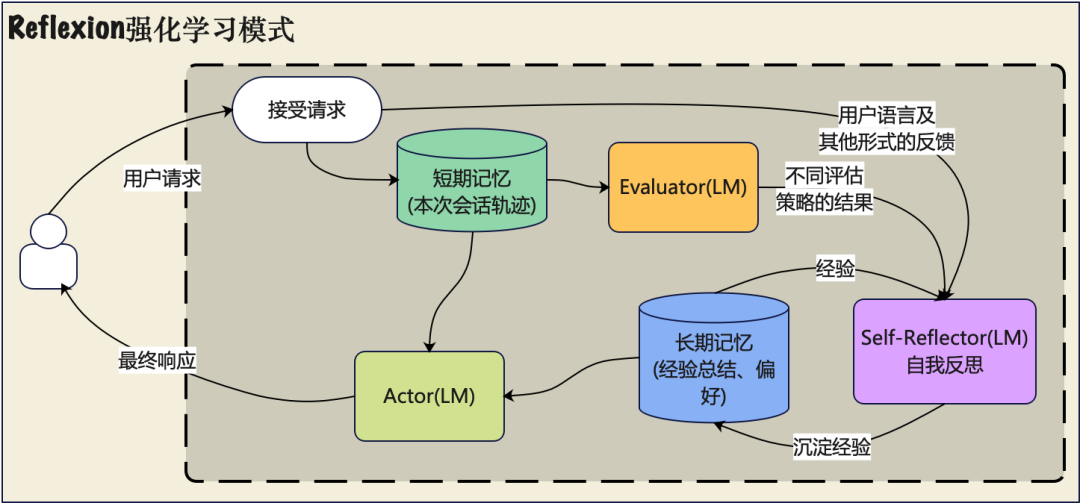
定义:Agentic AI = AI系统通过迭代、多步工作流自主完成复杂任务(而非一次性回答)。
| 维度 | 传统 Agent | Agentic AI |
|---|---|---|
| 任务形态 | 单轮或短任务 | 长任务、链式任务 |
| 目标处理 | 被动执行指令 | 主动拆解与推进 |
| 记忆 | 上下文短、静态配置 | 短期+长期记忆+检索 |
| 工具使用 | 固定少量工具 | 动态选择多工具 |
| 自我反思 | 基本没有 | 计划-执行-评估-反思循环 |
| 协作 | 单体为主 | 多智能体协同 |
| 安全与观测 | 轻量 | 权限、审计、回放、红队化 |
Eg:
写一篇论文 ==》LLM(网页搜索 or 查询)==》网页搜索 ==》网页抓取 ==》LLM(写论文)==》 论文
上面是低自主性的
下面更具有自主性的
写一篇论文 ==》LLM(Tools,自主 比如:网页搜索 or 查询)==》网页搜索 ==》LLM(Tools,自主 比如:pdf to text) ==》 网页抓取 ==》LLM(写论文)==》 论文 ==》LLM(再抓取网页等 改进论文)==> 论文
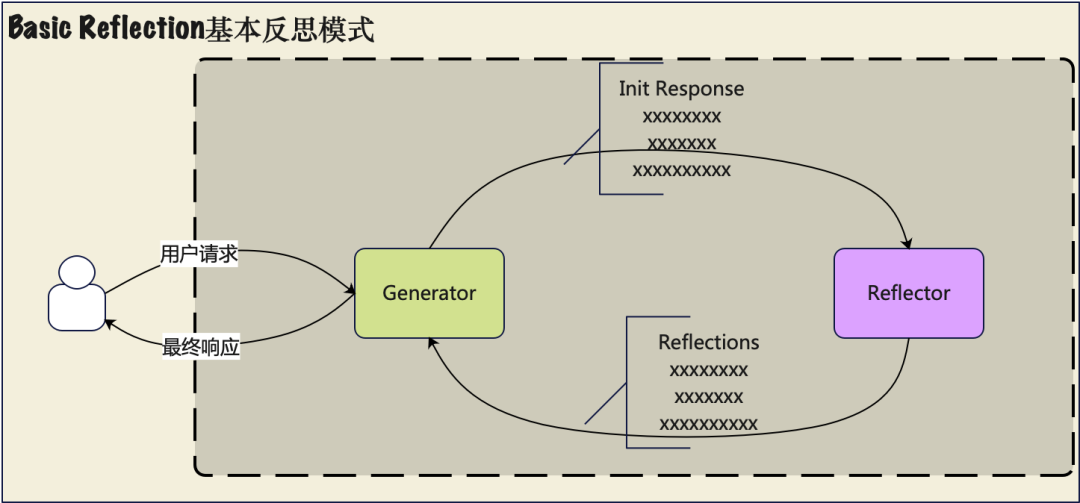
Reflection(反思/自省)
- 机制:AI生成初稿 → 自己/另一个AI审阅 → 找出问题 → 改进输出(类似人类修改作文)。
- 效果:显著降低错误、提升质量(小循环就能带来明显进步)。
- 汇报示例:用在报告生成、代码调试场景——“让AI自己批改自己,比单次输出准得多”。
Tool Use(工具使用)
- 机制:LLM决定调用哪些外部工具(web搜索、数据库查询、API、日历、邮件、代码执行器等)。
- 关键:不是硬编码,而是让模型自主选择和调用。
- 汇报价值:企业最实用——“AI不再局限于知识截止日期,能实时查最新数据、运行代码、发邮件”。
Planning(规划)
- 机制:LLM把大任务拆分成子任务(task decomposition),再逐一执行。
- 强调:任务分解是人类工程师思维的核心,AI也要学会“先规划再行动”。
- 汇报示例:复杂项目如“安排出差”→ 拆成查机票、订酒店、加日程、发邀请。
代理式流程
优势:可以让某些任务并行处理从而比人类快得多
- 拆分任务,哪些可以用LLM or Tools来解决,不能解决的先思考人类是如何处理的。
- refection
- 让LLM可以访问工具
- 文本告知 ==》LLM
- AISuite开源库 LLM直接调用Tools
- MCP
高度自主Agent的模式
关键词:工具、步骤方案、LLM按步执行
总结:让LLM写出方案的多个步骤然后依次执行每一步并结合适当的上下文信息(任务是什么,可以用的工具有哪些、等等)
主要应用在Coding
生成步骤方案
- 使用Json(推荐)、XML 格式输出计划
- 通过代码(用代码表达每一步,推荐)
多智能体工作流
Multi-agent Collaboration(多智能体协作)
- 机制:构建多个专精Agent(如研究员、逻辑专家、创意专家),它们分工、沟通、辩论、共识。
- 模式:线性通信 vs 并行协作 vs 层次结构。
- 效果:处理超复杂任务,准确率和鲁棒性指数级提升(类似公司团队)。
优势:
- 可以专注于某一项任务 ==》 打造最优 ∗ ^{*} ∗Agent。
- 分工合作专注自己的Agent,最后串联起来 ==》 完整多Agent系统
更自主的设计:OM具有选择权可以调用不同的Agent
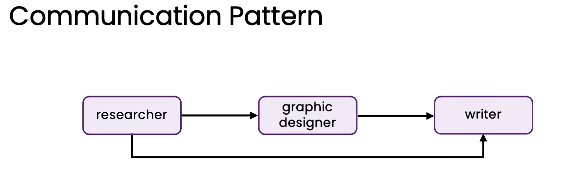
Agent之间沟通模式
-
常用:线性、层级沟通模式
-
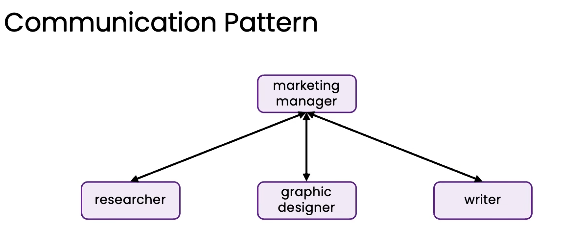
高级但是不常用:更深层次的层级结构
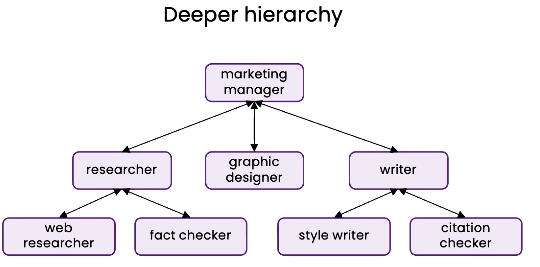
-
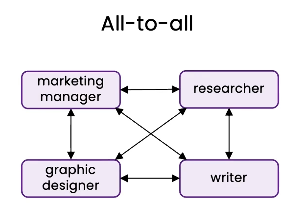
ALL-to-all 全员互联沟通模式(任何人都可以随时与其他人交流,难以预测,目前不推荐)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)