【独家原创】基于HBA(蜜獾)-Transformer多特征分类预测 (多输入单输出)Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。
🍎 往期回顾关注个人主页:Matlab科研工作室
👇 关注我领取海量matlab电子书和数学建模资料
🍊个人信条:格物致知,完整Matlab代码获取及仿真咨询内容私信。
🔥 内容介绍
一、引言
在当今的数据分析与机器学习领域,多特征分类预测是一项关键任务,广泛应用于众多行业,如医疗诊断、金融风险评估、图像识别等。从大量具有复杂关系的多特征数据中准确预测单一输出类别,对于决策制定和问题解决至关重要。传统方法在处理此类复杂任务时往往面临挑战,而基于 HBA(蜜獾算法) - Transformer 的模型结合了两者的优势,为多特征分类预测提供了一种强大的解决方案。
二、多特征分类预测的挑战
(一)特征复杂性
- 高维度与相关性
:实际应用中的多特征数据集通常具有高维度,包含大量的特征变量。例如,在医疗诊断中,可能涉及患者的各种生理指标、病史记录、基因数据等,维度可能达到成百上千。这些特征之间还可能存在复杂的相关性,有些特征可能是冗余的,而有些特征之间的相互作用对分类结果起着关键作用,但难以通过简单方法识别和利用。
- 特征类型多样性
:多特征数据可能包含不同类型的特征,如数值型、类别型、文本型等。不同类型的特征需要不同的处理方式,将它们有效地整合到一个分类模型中具有一定难度。例如,数值型特征可以直接进行数值计算和统计分析,而文本型特征则需要进行向量化等预处理操作才能用于模型训练。
(二)传统方法的局限性
- 特征提取与选择困难
:传统的机器学习算法,如决策树、支持向量机等,在处理高维度多特征数据时,往往依赖人工进行特征提取和选择。这不仅耗时费力,而且人工选择的特征可能无法充分捕捉数据中的潜在信息,导致分类性能受限。例如,人工可能遗漏一些对分类结果有重要影响的特征组合。
- 模型适应性与泛化能力不足
:传统模型在面对复杂多变的多特征数据时,其模型结构和参数设置往往难以适应不同数据集的特点。这可能导致模型在训练集上表现良好,但在测试集或新的实际数据上泛化能力较差,无法准确地进行分类预测。
三、蜜獾算法(HBA)原理
(一)生物学启发
蜜獾算法受蜜獾独特的觅食行为启发。蜜獾在寻找食物过程中,表现出强大的探索和挖掘能力。它具有两种主要行为模式:探索模式,类似于随机搜索,蜜獾会在较大范围内随机寻找食物源;挖掘模式,当蜜獾接近食物源时,会进行局部的精细搜索,以获取食物。这种行为模式反映在算法中,就是在解空间中同时进行全局搜索和局部开发。
(二)算法核心机制
- 初始化与种群生成
:算法开始时,在解空间中随机生成一组初始解,这些解构成种群,每个解可以看作是蜜獾在解空间中的初始位置。例如,在多特征分类预测问题中,一个解可能代表一组分类模型的参数设置。
- 适应度评估
:定义适应度函数来衡量每个解的优劣。在多特征分类预测场景下,适应度函数通常基于分类模型在训练数据集上的性能指标,如准确率、召回率、F1 值等。通过计算每个解对应的适应度值,来评估该解在解决当前分类问题上的有效性。
- 搜索策略
:蜜獾算法通过模拟蜜獾的探索和挖掘行为进行搜索。在探索阶段,蜜獾以一定概率进行随机移动,扩大搜索范围,寻找潜在的更好解。在挖掘阶段,蜜獾根据当前位置和历史最优位置的信息,进行局部搜索,尝试改进当前解。例如,通过对当前解的某些参数进行微调,看是否能提高适应度值。
- 更新与迭代
:根据搜索结果,更新种群中的解。将适应度值更好的解保留下来,并逐渐淘汰较差的解。通过不断迭代,种群中的解逐渐向最优解靠近,最终找到适应度值最优的解,即对应多特征分类预测问题中的最优模型参数或特征组合。
四、Transformer 架构原理
(一)自注意力机制(Self - Attention)
-

-

-
五、基于 HBA - Transformer 多特征分类预测原理
(一)模型架构融合
(二)多特征处理与分类
- 多特征输入与处理
:将多特征数据进行预处理,使其转化为适合 Transformer 输入的序列格式。对于不同类型的特征,采用相应的预处理方法,如数值型特征进行归一化处理,类别型特征进行独热编码等。然后将预处理后的特征序列输入到 Transformer 中,利用其自注意力机制和多头自注意力机制,捕捉特征之间的复杂关系,挖掘出深层次的特征表示。
- 分类决策
:经过 Transformer 多层的特征提取后,得到的特征表示被输入到一个分类器中,通常是一个全连接层(FC)。全连接层根据学习到的权重,将特征向量映射到不同的类别空间,输出每个类别对应的概率值。通过 softmax 函数对这些概率值进行归一化处理,得到最终的分类结果。例如,在一个多类别分类任务中,softmax 函数输出每个类别标签的概率,概率最高的类别即为预测类别。
- 整体框架
:基于 HBA - Transformer 的多特征分类预测模型将蜜獾算法的优化能力与 Transformer 的特征提取和处理能力有机结合。在整体框架上,首先利用 Transformer 架构对多特征数据进行特征提取和建模。Transformer 的输入是经过预处理的多特征数据,这些数据被转换为适合模型输入的序列形式。通过多头自注意力机制、位置编码和前馈神经网络层,Transformer 能够自动学习多特征数据中的复杂模式和相互关系,将输入特征映射到一个高维特征空间,得到更具代表性的特征表示。
- HBA 优化过程
:在 Transformer 模型训练的过程中,引入蜜獾算法对模型的参数进行优化。将 Transformer 模型的参数看作是蜜獾在解空间中的位置,通过蜜獾算法的搜索策略,引导模型参数朝着使分类性能最优的方向调整。具体来说,在每次训练迭代中,计算模型在训练数据集上的适应度值(如分类准确率),根据适应度值更新蜜獾的位置(即模型参数),按照蜜獾算法的探索和挖掘模式调整参数。通过不断的迭代优化,使得模型能够跳出局部最优解,更快地收敛到全局最优或近似全局最优的参数配置,从而提高模型的分类性能。
- 多特征输入与处理
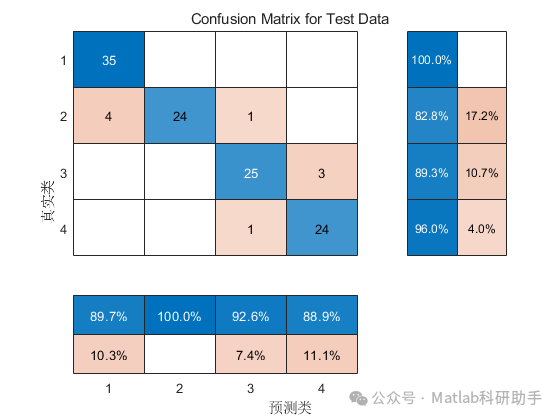
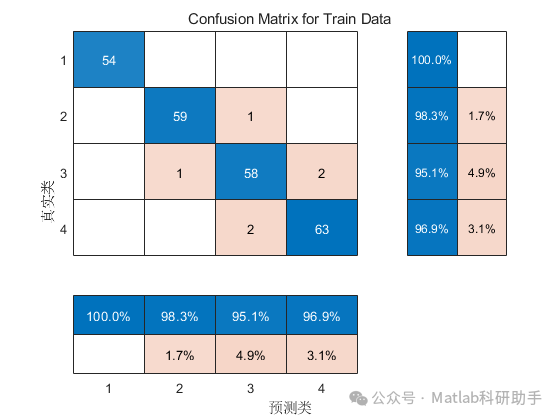
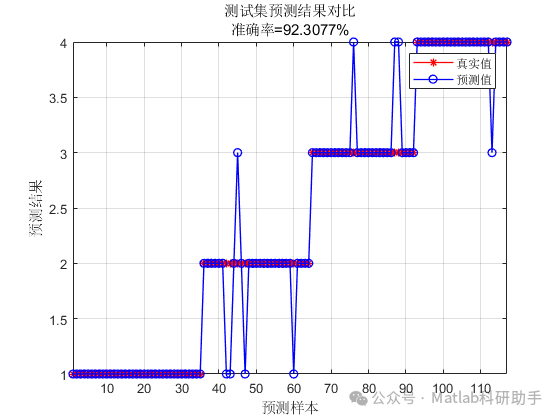
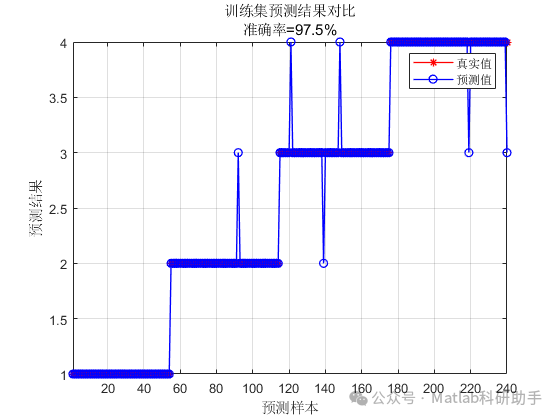
⛳️ 运行结果
📣 部分代码
function [R,rmse,biaozhuncha,mae,mape]=calc_error(x1,x2)
%此函数用于计算预测值和实际(期望)值的各项误差指标
% 参数说明
%----函数的输入值-------
% x1:真实值
% x2:预测值
%----函数的返回值-------
% mae:平均绝对误差(是绝对误差的平均值,反映预测值误差的实际情况.)
% mse:均方误差(是预测值与实际值偏差的平方和与样本总数的比值)
% rmse:均方误差根(是预测值与实际值偏差的平方和与样本总数的比值的平方根,也就是mse开根号,
% 用来衡量预测值同实际值之间的偏差)
% mape:平均绝对百分比误差(是预测值与实际值偏差绝对值与实际值的比值,取平均值的结果,可以消除量纲的影响,用于客观的评价偏差)
% error:误差
% errorPercent:相对误差
if nargin==2
if size(x1,2)==1
x1=x1'; %将列向量转换为行向量
end
if size(x2,2)==1
x2=x2'; %将列向量转换为行向量
end
num=size(x1,2);%统计样本总数
error=x2-x1; %计算误差
x1(find(x1==0))=inf;
errorPercent=abs(error)./x1; %计算每个样本的绝对百分比误差
mae=sum(abs(error))/num; %计算平均绝对误差
mse=sum(error.*error)/num; %计算均方误差
rmse=sqrt(mse); %计算均方误差根
mape=mean(errorPercent); %计算平均绝对百分比误差
biaozhuncha=std(x2);
%结果输出
for i=1:size(x1,1)
tempdata=(x1(i,:)-x2(i,:)).^2;
tempdata2=(x1(i,:)-mean(x1(i,:))).^2;
R(i)=1 - ( sum(tempdata)/sum(tempdata2) );
% disp(['决定系数R为: ',num2str(R(i))])
end
disp(['标准差为: ',num2str(biaozhuncha)])
disp(['均方误差根rmse为: ',num2str(rmse)])
disp(['平均绝对误差mae为: ',num2str(mae)])
disp(['平均绝对百分比误差mape为: ',num2str(mape*100),' %'])
else
disp('函数调用方法有误,请检查输入参数的个数')
end
end
🔗 参考文献
🍅往期回顾扫扫下方二维码

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)