模型评估的“照妖镜”:准确率、混淆矩阵与四大核心指标深度拆解
📖 导读:
在上一篇《逻辑回归预测癌症》中,我们只用了一个简单的“准确率”来给模型打分。但你可能隐隐觉得不对劲:如果100个人里只有1个癌症患者,模型全部预测“没病”,准确率高达99%,但这模型有用吗?完全没用!本篇指南将带你进入模型评估战区的核心。我们将通过
03_混淆矩阵_准确率_精确率_召回率_F1分数.py这份代码,彻底搞懂为什么准确率会骗人,以及准确率、混淆矩阵、精确率、召回率、F1分数这“五大金刚”如何联手揭穿模型的伪装。本章目标:学会用多维度的眼光审视模型,特别是在样本不平衡(如癌症检测、欺诈识别)的场景下,找到真正靠谱的评估指标。
🗺️ 一、本章定位:为什么需要这把“尺子”?
在之前的《章节全景指南》中,我们提到模型评估是机器学习的“裁判”。
- 前情提要:逻辑回归模型已经训练好了,它说自己的准确率是 96%。
- 核心痛点:在医疗、金融风控等领域,“漏报”(把病人当健康人)和**“误报”**(把健康人当病人)的代价是完全不同的。
- 本文件作用:
- 重新审视准确率 (Accuracy) 的局限性。
- 引入混淆矩阵 (Confusion Matrix),将错误的类型细分。
- 计算更精准的精确率 (Precision)、召回率 (Recall) 和 F1分数。

📦 第二部分:导包与数据准备(复习与预热)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# 新增:评估工具包
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
💡 新增工具详解
除了之前熟悉的 LogisticRegression 等,这里引入了评估全家桶:
accuracy_score:准确率计算器。最基础的整体得分。confusion_matrix:混淆矩阵生成器。它能画出一张表,清晰地展示“猜对的”和“猜错的”具体分布。precision_score:精确率计算器。关注“预测为正的里面,有多少是真的正”。recall_score:召回率计算器。关注“真正的正例里面,有多少被找出来了”。f1_score:F1分数计算器。精确率和召回率的调和平均数,综合指标。classification_report:全能报告生成器。一键输出所有指标,懒人必备。
(注:数据读取、清洗、划分、标准化、训练部分的代码与前一篇完全一致,此处不再赘述,我们直接跳到核心的评估环节)
🔍 第三部分:获取预测结果(考试交卷)
# 假设模型已经训练好 (lr_model)
y_pred = lr_model.predict(new_x_test) # 模型给出的预测结果
y_test = y_test # 真实答案
🧐 变量状态
y_test:真实的诊断结果(例如:[2, 4, 2, 2, 4, ...],其中2=良性,4=恶性)。y_pred:模型猜的结果(例如:[2, 2, 2, 2, 4, ...])。- 现状:这两个数组长度一样,逐个对比就能看出模型哪里对了,哪里错了。但光看数组太累,我们需要工具来统计。
🎯 第四部分:混淆矩阵(核心中的核心)⭐
# 1. 生成混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", cm)
❓ 灵魂拷问:什么是混淆矩阵?
很多初学者看到矩阵里的数字就晕了。别怕,我们把它拆解成四个格子的故事。
1. 矩阵长什么样?
假设我们的任务是**“找出恶性肿瘤 (4)”(即把 4 看作正例 Positive**,2 看作负例 Negative)。
输出的 cm 通常是一个 2x2 的表格(注意:sklearn 默认顺序可能是 [负, 正] 或 [正, 负],需根据实际标签确认,通常行是真实值,列是预测值):
| 预测:良性 (Neg) | 预测:恶性 (Pos) | |
|---|---|---|
| 真实:良性 (Neg) | TN (真负) | FP (假正) |
| 真实:恶性 (Pos) | FN (假负) | TP (真正) |
2. 四个格子的通俗解读
- TP (True Positive, 真正例):
- 含义:真的是恶性,模型也预测是恶性。
- 评价:🎉 完美! 抓住了坏人。
- TN (True Negative, 真负例):
- 含义:真的是良性,模型也预测是良性。
- 评价:🎉 完美! 放走了好人。
- FP (False Positive, 假正例) -> 误报 (Type I Error):
- 含义:其实是良性,模型却瞎说是恶性。
- 评价:😨 虚惊一场。好人被冤枉了。
- 后果:病人被吓坏,还要多做检查,浪费医疗资源。
- FN (False Negative, 假负例) -> 漏报 (Type II Error):
- 含义:其实是恶性,模型却说是良性。
- 评价:☠️ 致命错误! 坏人逍遥法外。
- 后果:癌症患者被误诊为健康,延误治疗,可能危及生命。
3. 代码中的 cm 变量
- 是什么:一个二维数组(NumPy Array)。
- 内容示例:
(注:具体行列顺序取决于[[80 5] <-- 第一行:真实是良性的。80个猜对(TN),5个猜错(FP) [ 3 49]] <-- 第二行:真实是恶性的。3个漏掉(FN),49个抓对(TP)y_test中标签的排序,通常是从小到大) - 价值:它是计算后面所有高级指标的基石。没有它,就无法区分“误报”和“漏报”。
📈 第五部分:五大核心指标全解析
有了混淆矩阵的 TP, FP, TN, FN,我们就可以计算所有关键指标了。
0. 准确率 (Accuracy) —— “整体及格率”
acc = accuracy_score(y_test, y_pred)
print(f"准确率: {acc}")
- 公式:

(所有猜对的总数 / 总人数) - 通俗理解:“全班考试中,及格的人数比例是多少?”
- 优点:直观,容易理解。
- 致命缺点:在样本不平衡时极具欺骗性。
- 案例:100个病人,99个良性,1个恶性。模型全部预测“良性”。

- 适用场景:样本分布非常均匀(正负例各占50%左右),且误报和漏报代价相当时。
1. 精确率 (Precision) —— “宁缺毋滥”
precision = precision_score(y_test, y_pred, pos_label=4) # 指定 4 为正例
print(f"精确率: {precision}")
- 公式:
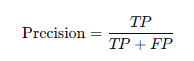
- (预测为恶性的总数中,真正是恶性的比例)
- 通俗理解:“模型说他是坏人,他真的是坏人的概率有多大?”
- 场景:
- 如果你很讨厌误报(比如垃圾邮件过滤,你不想让重要邮件被当成垃圾邮件),你就追求高精确率。
- 口诀:查得准不准?
2. 召回率 (Recall) —— “宁可错杀,不可放过”
recall = recall_score(y_test, y_pred, pos_label=4)
print(f"召回率: {recall}")
- 公式:
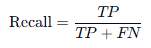
- (所有真正的恶性中,被模型找出来的比例)
- 通俗理解:“所有的坏人里,有多少被模型抓出来了?”
- 场景:
- 癌症检测、地震预警、反恐。这些场景下,漏报 (FN) 的代价极大。哪怕把100个健康人抓来检查(FP高),也不能漏掉1个癌症患者(FN必须低)。
- 口诀:查得全不全?
3. F1 分数 (F1-Score) —— “综合平衡大师”
f1 = f1_score(y_test, y_pred, pos_label=4)
print(f"F1分数: {f1}")
- 公式:
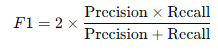
- (精确率和召回率的调和平均数)
- 为什么要用它?
- 有时候精确率高了,召回率就低了(为了准,不敢多猜)。
- 有时候召回率高了,精确率就低了(为了全,乱猜一通)。
- F1 就是要在两者之间找一个平衡点。如果 F1 高,说明模型既准又全。
- 场景:当你需要同时兼顾“误报”和“漏报”,或者两个指标同等重要时。
📝 第六部分:全能报告(一键输出)
# 一行代码搞定所有
report = classification_report(y_test, y_pred, target_names=['良性', '恶性'])
print(report)
💡 输出解读
这会打印出一个漂亮的表格:
precision recall f1-score support
良性 0.94 0.96 0.95 85
恶性 0.91 0.88 0.89 52
accuracy 0.93 137
macro avg 0.92 0.92 0.92 137
weighted avg 0.93 0.93 0.93 137
- support:测试集中该类样本的真实数量(如 52 个恶性)。
- accuracy (底部):整体准确率((80+49)/137 ≈ 0.94)。注意:这里再次出现了准确率,作为参考基准。
- macro avg:算术平均。把良性和恶性的指标简单相加除以2,不关心样本数量差异。
- weighted avg:加权平均。考虑了样本数量(支持度)。如果恶性样本很少,它的权重就小。在样本不平衡时,这个指标更有参考价值。
⚔️ 第七部分:深度对比与决策(什么时候用哪个?)
这是初学者最容易混淆的地方,我们用癌症检测作为终极案例来总结:
| 指标 | 关注点 | 癌症检测场景下的含义 | 适用场景 |
|---|---|---|---|
| 准确率 (Accuracy) | 整体对错比例 | “100个人里猜对了95个”。陷阱:如果只有1个癌症,全猜“没病”也有99%准确率,但毫无意义。 | 样本分布均匀,且误报漏报代价差不多时(如识别猫狗图片)。 |
| 精确率 (Precision) | 预测为正的准确性 | “模型说是癌症的10个人里,真的有9个是癌症”。代价:可能会漏掉一些真正的癌症患者。 | 垃圾邮件过滤(不想误删重要邮件)、推荐系统(不想推用户不喜欢的商品)。 |
| 召回率 (Recall) | 覆盖真实正例的能力 | “真正的10个癌症患者里,模型找出了9个”。代价:可能会把很多健康人误判为癌症,造成恐慌。 | 癌症筛查、地震预警、金融反欺诈(宁可多查,不可漏网)。 |
| F1 分数 | 综合平衡 | 在“不漏诊”和“不误诊”之间取得最佳平衡。 | 需要兼顾两者,或者作为模型调优的统一目标。 |
💡 针对本代码的思考
在癌症预测中,召回率 (Recall) 往往比精确率更重要!
- 因为漏诊 (FN) 的代价是生命。
- 即使误诊 (FP) 导致一些健康人多跑了一趟医院,这也是可以接受的代价。
- 策略:如果在调参时发现 Recall 太低,即使 Accuracy 很高,也要调整模型(如降低分类阈值),优先保证把病人找出来。
🎯 全文数据流向总结图
让我们看看评估指标是如何从预测结果中诞生的:
- 真实标签 (
y_test) + 预测标签 (y_pred)
⬇️ 对比 - 混淆矩阵 (
cm)- 提取出 TP, FP, TN, FN 四个关键数值
⬇️ 代入公式
- 提取出 TP, FP, TN, FN 四个关键数值
- 准确率 = (TP + TN) / 总和 (整体及格率)
精确率 = TP / (TP + FP) (查得准不准?)
召回率 = TP / (TP + FN) (查得全不全?)
F1 分数 = 2 * (P * R) / (P + R) (综合得分)
⬇️ 汇总 - Classification Report
- 生成最终体检报告,指导模型优化方向
🚀 下一步行动建议
恭喜你!你现在已经掌握了超越 90% 初学者的评估能力。你不再会被单一的“准确率”忽悠了,能够根据业务场景选择正确的指标。
- 复习重点:
- 背诵 TP, FP, FN 的定义。
- 记住公式:
- 准确率看整体。
- 精确率分母是预测为正的总和。
- 召回率分母是真实为正的总和。
- 理解场景:癌症选召回率,垃圾邮件选精确率,样本不均慎选准确率。
- 动手实验:
- 尝试修改逻辑回归的参数(如
class_weight='balanced'),看看召回率会不会提高? - 思考:如果我想让模型更激进一点(宁可错杀),我该怎么做?(提示:涉及预测概率阈值的调整,这是进阶内容)。
- 尝试修改逻辑回归的参数(如
- 继续前进:
体。
* 精确率分母是预测为正的总和。
* 召回率分母是真实为正的总和。- 理解场景:癌症选召回率,垃圾邮件选精确率,样本不均慎选准确率。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)