Matlab语音识别:基于GMM和MFCC的模型训练与测试集解析
Matlab语音识别,使用GMM和MFCC,有训练集和测试集,带说明,带轮文解析等。
引言
随着生物识别技术在身份认证、智能安防、人机交互等领域的广泛应用,说话人识别(Speaker Recognition)作为语音信号处理的重要分支,因其非接触性、便捷性和低成本等优势,成为研究热点。本文基于上传的 MATLAB 实现代码,系统解析一个完整的说话人识别系统架构,重点围绕梅尔频率倒谱系数(MFCC)特征提取、端点检测(Voice Activity Detection, VAD)、高斯混合模型(Gaussian Mixture Model, GMM)建模与匹配等核心模块,深入阐述其功能设计与实现逻辑。
系统整体架构
该系统采用典型的两阶段结构:训练阶段与识别阶段。
- 训练阶段:对多个说话人的语音样本进行预处理、特征提取,并为每位说话人独立训练一个 GMM 模型,形成说话人模型库。
- 识别阶段:对待识别语音执行相同的预处理与特征提取流程,随后将其 MFCC 特征与所有 GMM 模型进行似然度匹配,选择得分最高的模型对应说话人作为识别结果。
整个系统以模块化方式组织,各功能组件职责清晰,便于调试与扩展。
语音预处理模块
语音信号在采集过程中不可避免地包含静音段与环境噪声,因此预处理是提升识别准确率的关键前置步骤。系统实现了以下核心预处理功能:
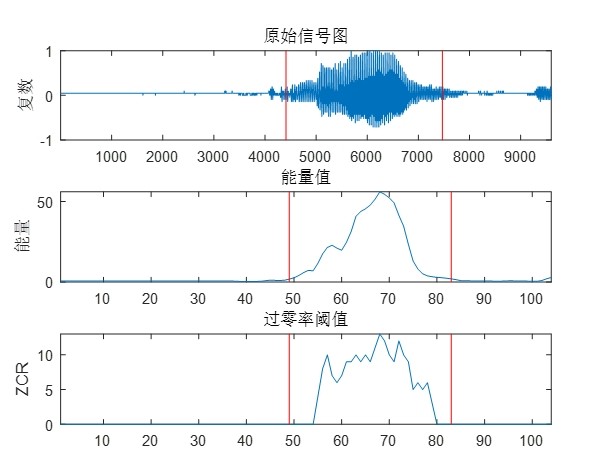
1. 端点检测(VAD)
系统采用基于能量的端点检测方法 epdByVol,其核心思想是通过分析语音帧的能量变化,自动定位有效语音的起始与结束位置。具体流程包括:
- 分帧加窗:使用自定义函数
buffer2对语音信号进行无重叠或低重叠分帧; - 零均值化:通过
frameZeroMean消除每帧中的直流分量,提升能量计算的鲁棒性; - 能量计算:利用
frame2volume计算每帧的绝对值和作为能量指标; - 阈值判定:动态设定能量阈值,结合最小语音段长度约束,识别并截取有效语音片段。
该方法有效剔除了静音与噪声干扰,显著提升了后续特征提取的质量。
2. 幅度归一化
在读取 .wav 文件后,系统对语音信号进行幅度归一化(y = y / max(abs(y))),确保不同录音设备或音量水平下的语音具有可比性。
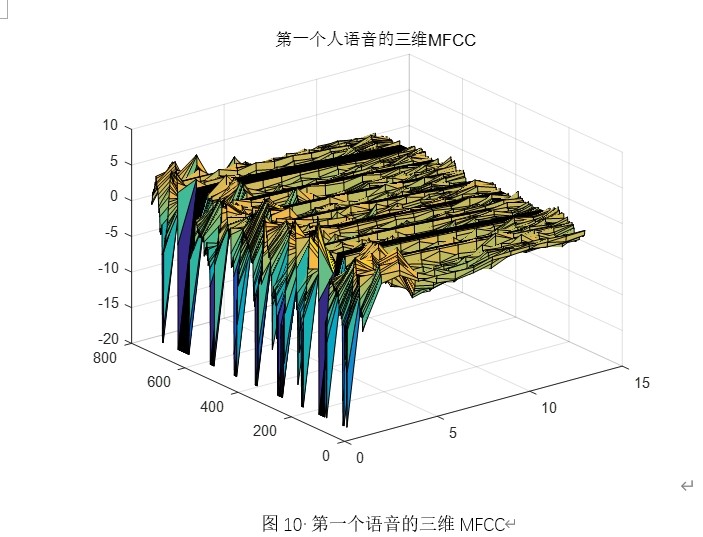
特征提取模块:MFCC
梅尔频率倒谱系数(MFCC)模拟人耳对频率的非线性感知特性,是说话人识别中最经典且有效的声学特征之一。系统通过 melcepst 函数实现完整的 MFCC 提取流程:
- 预加重:增强高频成分,补偿语音信号在高频段的自然衰减;
- 分帧加窗:采用汉明窗对语音进行短时平稳化处理;
- FFT 与能量谱计算:对每帧信号进行快速傅里叶变换,并计算功率谱;
- Mel 滤波器组映射:通过
melbankm构建三角形 Mel 滤波器组,将线性频谱映射到 Mel 频域; - 对数压缩与 DCT:对 Mel 频谱取对数后进行离散余弦变换(DCT),最终输出 12 维 MFCC 系数。
值得注意的是,系统在 GMM 训练时仅使用第 5 至第 12 维 MFCC(即 mfcc(:,5:12)),这是因为在说话人识别任务中,低维系数(如第 1–4 维)通常包含较多与发音内容相关的信息,而高维系数更能反映说话人的声道特性,有助于提升模型的说话人区分能力。
建模与识别模块:高斯混合模型(GMM)
GMM 是一种强大的概率密度估计工具,能够灵活拟合复杂的数据分布。在说话人识别中,每个说话人的语音特征分布被建模为一个 GMM。
1. GMM 训练
系统通过 gmm_estimate 函数实现 GMM 参数估计,采用经典的 期望最大化(EM)算法:
- 初始化:从训练数据中随机选取初始均值,协方差设为数据方差的缩放形式,权重均匀分配;
- E 步:计算每个数据点属于各高斯分量的后验概率;
- M 步:基于后验概率重新估计均值、协方差和混合权重;
- 收敛判断:当对数似然函数变化小于阈值或达到最大迭代次数时停止。
系统默认使用 12 个高斯分量(gaussianNum = 12),在模型复杂度与数据量之间取得平衡。
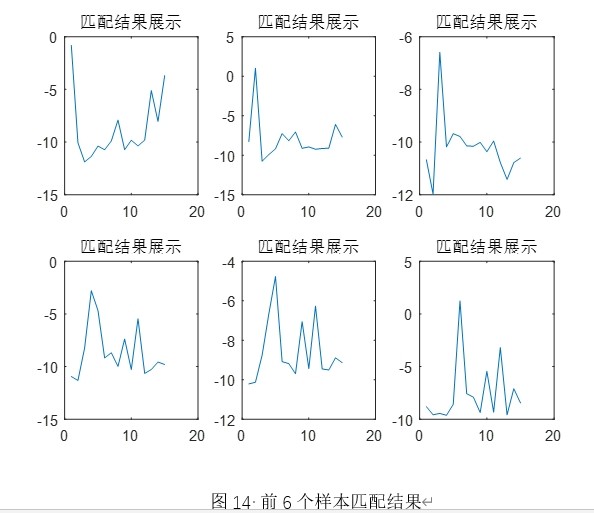
2. 说话人匹配与识别
识别阶段调用 MFCCfeaturecompare 函数,其核心逻辑如下:
- 对测试语音提取 MFCC 特征;
- 遍历所有说话人的 GMM 模型,计算测试特征在各模型下的平均对数似然得分;
- 选择得分最高的模型对应的说话人作为识别结果。
该方法本质上是一种最大似然分类器,充分利用了 GMM 对说话人声学特征的概率建模能力。
系统评估与可视化
系统在识别过程中自动统计识别正确率,并通过多种可视化手段辅助分析:
- MFCC 三维/二维图:直观展示语音特征的时频结构;
- 匹配得分曲线:显示测试样本与各说话人模型的相似度分布;
- 时域/频域/功率谱图:用于信号质量与预处理效果评估。
这些可视化不仅有助于调试,也为理解系统行为提供了直观依据。
总结
本系统完整实现了基于 MFCC 与 GMM 的说话人辨认流程,涵盖了从原始语音输入到最终身份输出的全链路处理。其模块化设计、合理的特征选择、稳健的端点检测以及成熟的 GMM 建模策略,共同构成了一个高效、可复现的说话人识别原型。尽管现代系统已逐步引入深度学习方法(如 DNN、x-vector),但 GMM-MFCC 作为经典基线,仍具有重要的教学与工程参考价值。该实现代码结构清晰、注释详实,为语音识别初学者提供了极佳的学习范例。

Matlab语音识别,使用GMM和MFCC,有训练集和测试集,带说明,带轮文解析等。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)