Linux手搓进程池:从原理到实现,手把手教你搞定进程复用

🔥个人主页:Cx330🌸
❄️个人专栏:《C语言》《LeetCode刷题集》《数据结构-初阶》《C++知识分享》
《优选算法指南-必刷经典100题》《Linux操作系统》:从入门到入魔
🌟心向往之行必能至
🎥Cx330🌸的简介:

目录
前言:
在Linux后台开发中,频繁创建和销毁进程会带来巨大的系统开销——进程创建需要分配资源、初始化PCB,销毁则需要回收资源,尤其在高并发场景(如Web服务器、任务调度)中,这种开销会严重影响程序性能。而进程池,就是解决这个问题的“利器”。
今天我们就来“手搓”一个简单但可复用的Linux进程池,从原理拆解到代码实现,带你搞懂进程池的核心逻辑,学会如何通过进程复用提升程序效率。
一、先搞懂:进程池是什么?核心优势有哪些?
进程池,顾名思义,就是提前创建一定数量的子进程,通过匿名管道统一管理、复用这些子进程来处理任务,而不是每次有任务就创建新进程、任务结束就销毁进程。
核心优势
-
降低系统开销:避免频繁创建/销毁进程的资源消耗,子进程可重复使用
-
提升响应速度:任务到来时,无需等待进程创建,直接分配空闲子进程处理
-
便于管理:统一管理子进程的创建、销毁、任务分配,避免子进程泄露
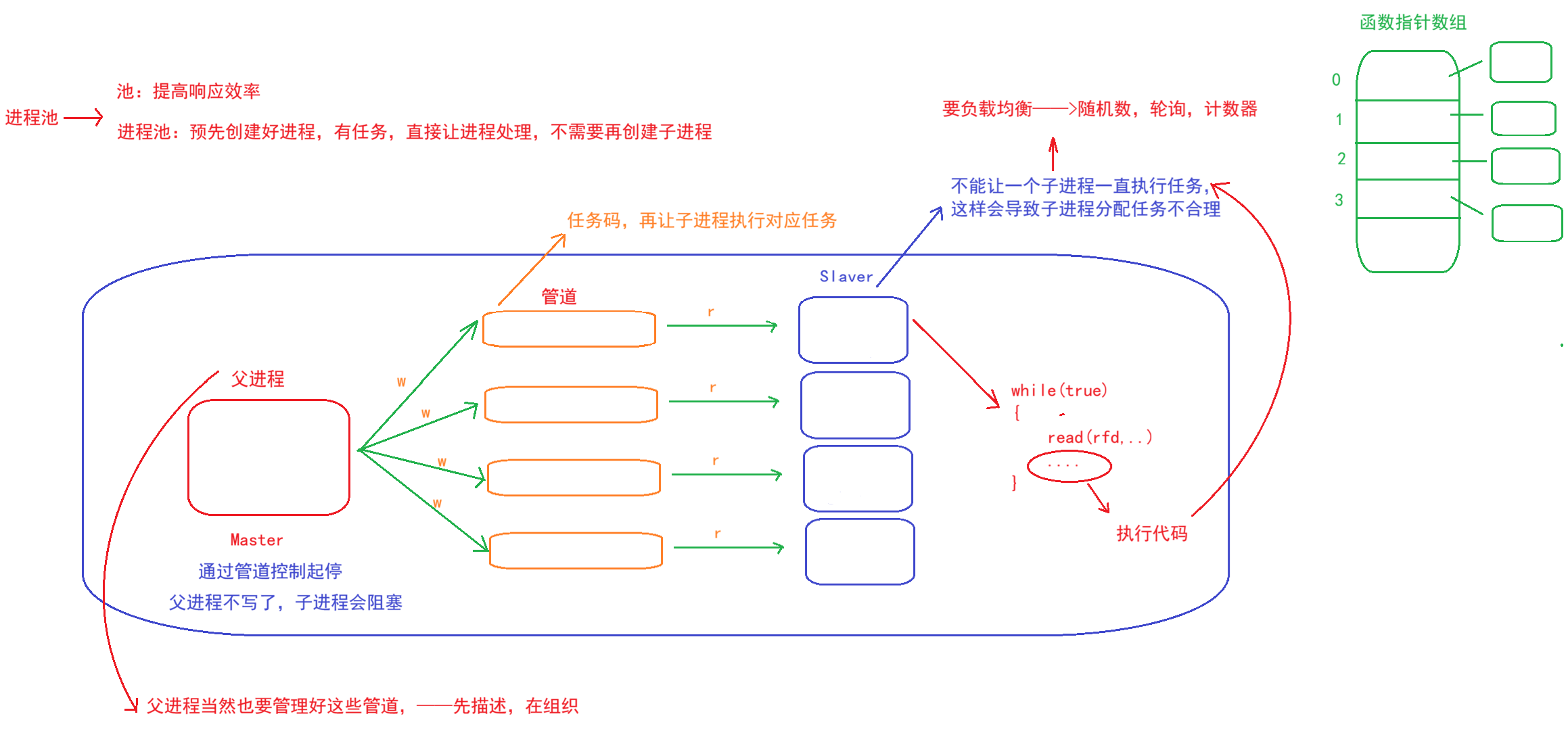
二、手搓进程池:分步实现(附完整代码)
步骤1:前期准备——定义任务类型与测试任务
首先定义任务的统一类型,封装各类测试任务,为后续进程池执行任务奠定基础,这是进程池“可处理多类型任务”的核心前提。
#include <iostream>
#include <vector>
#include <string>
#include <functional>
#include <ctime>
#include <cstdlib>
#include <unistd.h>
#include <memory>
#include <sys/wait.h>
#define __MAIN__
// 1. 定义任务类型:用function封装,支持任意无参无返回值的任务
using task_t = std::function<void()>;
// 2. 实现4类测试任务(模拟实际业务场景)
void printlog()
{
// sleep(1); // 可注释/打开,模拟任务执行耗时
std::cout<<"我是一个打印日志的任务,pid: "<<getpid()<<std::endl;
}
void download()
{
// sleep(1);
std::cout<<"我是一个下载任务,pid: "<<getpid()<<std::endl;
}
void readmysql()
{
// sleep(1);
std::cout<<"我是一个访问数据库的操作,pid: "<<getpid()<<std::endl;
}
void writeredis()
{
// sleep(1);
std::cout<<"我是一个访问redis的任务,pid: "<<getpid()<<std::endl;
}
// 3. 任务容器:存储所有可执行任务,供后续根据任务码调用
std::vector<task_t> gtasks;
// 4. 加载任务:将所有测试任务存入容器
void LoadTask()
{
gtasks.push_back(printlog);
gtasks.push_back(download);
gtasks.push_back(readmysql);
gtasks.push_back(writeredis);
}
// 5. 生成随机任务:模拟高并发场景下的随机任务请求(输出型参数存储任务码)
void RandomTask(std::vector<int> *out)
{
for(int i=0;i<50;i++)
{
int code=rand() % gtasks.size(); // 随机生成任务码(0-3,对应4类任务)
usleep(23223); // 模拟任务请求间隔
out->push_back(code);
}
}
// 6. 任务码转字符串:便于打印日志,直观查看任务类型
#define LOG_TASK 0
#define DOWNLOAD_TASK 1
#define MYSQL_TASK 2
#define REDIS_TASK 3
std::string Task2String(int code)
{
switch(code)
{
case LOG_TASK: return "printlog";
case DOWNLOAD_TASK: return "download";
case MYSQL_TASK: return "readmysql";
case REDIS_TASK: return "writeredis";
default: return "unknown";
}
}
关键说明:
-
用
std::function<void()>定义任务类型,实现“任务解耦”,后续可轻松添加新任务,无需修改进程池核心逻辑; -
任务码(0-3)对应不同任务,通过
RandomTask模拟真实场景中随机到来的任务请求; -
LoadTask函数统一加载任务,便于管理和扩展,符合“单一职责”原则。
步骤2:实现子进程工作逻辑——任务执行的核心
子进程的核心作用是“等待任务、执行任务”,通过读取管道中的任务码,调用对应的任务函数,这是进程复用的核心逻辑。
// 子进程工作函数:从管道读取任务码,执行对应任务
void Work(int rfd)
{
while (true)
{
int code=0;
// 从管道读任务码(阻塞等待,直到主进程发送任务)
ssize_t n=read(rfd,&code,sizeof(code));
if(n==sizeof(int)) // 读取到完整任务码
{
// 任务码合法,执行对应任务
if(code>=0 && code<gtasks.size())
{
gtasks[code](); // 调用任务容器中的对应任务
}
}
else if(n==0) // 读取到EOF(主进程关闭管道写端),子进程退出
{
break;
}
else // 读取失败,子进程退出
{
break;
}
}
}
关键说明:
-
子进程通过
read从管道读端(rfd)获取任务码,阻塞等待任务,实现“空闲时待命、有任务时执行”; -
只有读取到完整的任务码(4字节,int类型),才执行任务,避免任务错乱;
-
当主进程关闭管道写端,子进程读取到
n=0,主动退出,避免僵尸进程。
步骤3:封装Channel类——管理主从进程通信与子进程
Channel类是进程池的“通信桥梁”,封装了主进程与单个子进程的管道写端、子进程PID,统一管理任务发送、管道关闭、子进程回收,简化进程池的管理逻辑。
class Channel
{
public:
// 构造函数:初始化管道写端和子进程PID
Channel(int wfd,pid_t who)
: _wfd(wfd),
_sub_process_id(who)
{
_name="Channel-"+std::to_string(_sub_process_id)+"-"+std::to_string(_wfd);
}
// 获取管道写端(供主进程发送任务使用)
int Fd() { return _wfd; }
// 获取子进程PID(供回收子进程使用)
pid_t SubId() { return _sub_process_id; }
// 获取Channel名称(便于日志打印和调试)
std::string Name() { return _name; }
// 关闭管道写端(通知子进程退出)
void Close()
{
if(_wfd>=0) close(_wfd);
}
// 回收子进程(避免僵尸进程)
void Wait()
{
pid_t rid=waitpid(_sub_process_id,nullptr,0);
(void)rid; // 消除未使用变量警告
}
// 向子进程发送任务(写入任务码到管道)
void SendTask(int taskcode)
{
ssize_t n=write(_wfd,&taskcode,sizeof(taskcode));
(void)n; // 简化处理,实际可增加错误判断
}
~Channel() {} // 析构函数,无需额外操作(管道已在Close中关闭)
private:
int _wfd; // 管道写端(主进程用,向子进程发任务)
pid_t _sub_process_id; // 对应的子进程PID
std::string _name; // Channel名称(用于调试和日志)
};
关键说明:
-
每个子进程对应一个Channel对象,主进程通过Channel的
SendTask发送任务,通过Close和Wait回收子进程; -
封装后,进程池无需直接操作管道和子进程PID,降低耦合度,后续修改通信逻辑(如替换为消息队列)只需修改Channel类;
-
_name属性便于调试,可直观查看任务发送给了哪个子进程。
步骤4:封装ProcessPool类——进程池核心管理逻辑
ProcessPool类是整个进程池的“管理者”,负责创建子进程、管理所有Channel、实现负载均衡分配任务、终止进程池,是面向对象设计的核心。
class ProcessPool
{
private:
// 负载均衡:轮询选择子进程(Next函数实现轮询逻辑)
int Next()
{
int choice=_next_choice;
_next_choice++;
_next_choice %= _channels.size(); // 取模实现循环轮询
return choice;
}
public:
// 构造函数:初始化进程池大小(子进程数量)
ProcessPool(int number)
:_number(number),
_next_choice(0) // 轮询起始索引,初始为0
{}
// 启动进程池:创建指定数量的子进程和对应Channel
void Start()
{
for (int i = 0; i < _number; i++)
{
// 1. 创建管道(主写子读)
int pipefd[2];
int n = pipe(pipefd);
if (n < 0) { perror("pipe:"); exit(2); }
// 2. 创建子进程
pid_t id = fork();
if (id < 0) { perror("fork:"); exit(3); }
else if (id == 0) // 子进程逻辑
{
close(pipefd[1]); // 子进程关闭写端,只保留读端
Work(pipefd[0]); // 子进程进入工作循环,等待任务
close(pipefd[0]); // 执行完任务,关闭读端
exit(0); // 子进程退出
}
else // 主进程逻辑
{
close(pipefd[0]); // 主进程关闭读端,只保留写端
// 创建Channel对象,管理当前子进程和管道写端,存入容器
_channels.emplace_back(pipefd[1],id);
}
}
}
// 推送任务:根据轮询策略,将任务发送给子进程
void PushTask(int taskcode)
{
int who=Next(); // 轮询选择一个子进程(负载均衡)
_channels[who].SendTask(taskcode); // 发送任务码
// 打印日志,直观查看任务分配情况
std::cout<<"发送任务:"<<Task2String(taskcode)<<"["<< taskcode <<"]"<<"给:"<<_channels[who].Name()<<std::endl;
}
// 终止进程池:关闭所有管道写端,回收所有子进程
void Stop()
{
// 从后往前关闭管道、回收子进程(避免容器迭代时出现异常)
int end=_channels.size()-1;
while(end>=0)
{
_channels[end].Close(); // 关闭管道写端,通知子进程退出
_channels[end].Wait(); // 回收子进程
std::cout<<_channels[end].Name()<<" close and wait success!"<<std::endl;
end--;
}
}
// 调试打印:输出所有Channel的信息(管道写端、子进程PID、名称)
void DebugPrint()
{
std::cout<<"--------------------------------"<<std::endl;
for(auto &channel:_channels)
{
std::cout<<channel.Fd()<<std::endl;
std::cout<<channel.SubId()<<std::endl;
std::cout<<channel.Name()<<std::endl;
}
std::cout<<"--------------------------------"<<std::endl;
}
~ProcessPool() {} // 析构函数,无需额外操作(资源已在Stop中释放)
private:
std::vector<Channel> _channels; // 存储所有Channel,管理子进程和通信
int _number; // 进程池大小(子进程数量)
int _next_choice; // 轮询索引,实现负载均衡
};
关键说明(核心重点):
-
Start()函数:批量创建子进程和管道,主进程关闭管道读端、保存写端到Channel,子进程关闭写端、进入Work循环等待任务;
-
负载均衡:Next()函数通过轮询(_next_choice自增取模)分配任务,确保所有子进程负载均匀,避免单个子进程忙碌、其他子进程空闲;
-
Stop()函数:从后往前关闭管道写端、回收子进程,避免迭代容器时因元素删除导致的异常,确保所有资源被正确回收;
-
用
std::vector<Channel>管理所有子进程通信,结构清晰,便于扩展(如动态调整进程池大小)。
步骤5:主函数测试
主函数实现进程池的完整调用流程:解析命令行参数、加载任务、生成随机任务、启动进程池、推送任务、终止进程池,测试进程池的正常工作。
// 主进程入口(仅在定义__MAIN__时生效,避免重复编译)
#ifdef __MAIN__
// 用法提示:输入进程池大小(如./process_pool 5)
static void Usage(const std::string &proc)
{
std::cout << "Usage:\n\t" << proc << " process_number" << std::endl;
}
// 程序入口:./process_pool 进程池大小
int main(int argc, char *argv[])
{
// 1. 解析命令行参数(必须输入进程池大小)
if (argc != 2) { Usage(argv[0]); exit(1); }
int number = std::stoi(argv[1]); // 进程池大小(子进程数量)
// 2. 初始化任务:加载所有测试任务,生成50个随机任务
srand(time(nullptr)^getpid()); // 设置随机种子(结合时间和PID,确保随机性)
LoadTask();
std::vector<int> task_codes;
RandomTask(&task_codes);
// 3. 创建进程池(智能指针管理,自动释放,避免内存泄漏)
std::unique_ptr<ProcessPool> pp=std::make_unique<ProcessPool>(number);
// 4. 启动进程池,创建子进程
pp->Start();
sleep(2); // 等待子进程初始化完成
// 5. 推送所有随机任务(注释的代码可用于手动输入任务码测试)
for(auto task:task_codes)
{
pp->PushTask(task);
usleep(500000); // 模拟任务推送间隔,避免任务堆积
}
// 6. 终止进程池,回收所有资源
pp->Stop();
return 0;
}
#endif
关键说明:
-
用
std::unique_ptr管理ProcessPool对象,自动释放内存,避免手动管理内存导致的泄漏; -
命令行参数解析:输入进程池大小(如
./process_pool 5,表示创建5个子进程),符合Linux程序的使用习惯; -
注释的代码可用于手动输入任务码测试,灵活切换“随机任务”和“手动任务”,便于调试;
-
sleep(2)等待子进程初始化完成,避免主进程推送任务时,子进程尚未进入工作循环。
三、编译运行与结果分析(附Makefile)
// Makefile
process_pool:process_pool.cc
g++ -o $@ $^ -std=c++14
.PHONY:clean
clean:
rm -f process_pool
- 编译:直接 make;
- 运行:
./process_pool 5(5 为子进程数量,可自定义);
结果分析:
-
5个子进程循环复用,处理15个任务,无需频繁创建/销毁子进程;
-
当任务数超过队列最大容量(10)时,主进程阻塞等待,避免任务堆积;
-
销毁进程池时,所有子进程正常退出,资源被回收,无僵尸进程。
四、完整代码展示
#include <iostream>
#include <vector>
#include <string>
#include <functional>
#include <ctime>
#include <cstdlib>
#include <unistd.h>
#include <memory>
#include <sys/wait.h>
#define __MAIN__
//////////////////////////////任务测试代码/////////////////////////////
using task_t =std::function<void()>;
void printlog()
{
// sleep(1);
std::cout<<"我是一个打印日志的任务,pid: "<<getpid()<<std::endl;
}
void download()
{
// sleep(1);
std::cout<<"我是一个下载任务,pid: "<<getpid()<<std::endl;
}
void readmysql()
{
// sleep(1);
std::cout<<"我是一个访问数据库的操作,pid: "<<getpid()<<std::endl;
}
void writeredis()
{
// sleep(1);
std::cout<<"我是一个访问redis的任务,pid: "<<getpid()<<std::endl;
}
std::vector<task_t> gtasks;
void LoadTask()
{
gtasks.push_back(printlog);
gtasks.push_back(download);
gtasks.push_back(readmysql);
gtasks.push_back(writeredis);
}
// *:输出型参数
// const &:输入型参数
// &:输入输出型
void RandomTask(std::vector<int> *out)
{
for(int i=0;i<50;i++)
{
int code=rand() % gtasks.size();
usleep(23223);
out->push_back(code);
}
}
#define LOG_TASK 0
#define DOWNLOAD_TASK 1
#define MYSQL_TASK 2
#define REDIS_TASK 3
std::string Task2String(int code)
{
switch(code)
{
case LOG_TASK:
return "printlog";
case DOWNLOAD_TASK:
return "download";
case MYSQL_TASK:
return "readmysql";
case REDIS_TASK:
return "writeredis";
default:
return "unknown";
}
}
//////////////////////////////进程池代码/////////////////////////////
void Work(int rfd)
{
while (true)
{
int code=0;
ssize_t n=read(rfd,&code,sizeof(code));
if(n==sizeof(int))
{
if(code>=0 && code<gtasks.size())
{
gtasks[code]();
}
}
else if(n==0)
{
break; // 子进程只要读到返回值为0,表明父进程让我退出
}
else
{
break;
}
}
}
class Channel
{
public:
Channel(int wfd,pid_t who)
: _wfd(wfd),
_sub_process_id(who)
{
_name="Channel-"+std::to_string(_sub_process_id)+'-'+std::to_string(_wfd);
}
int Fd()
{
return _wfd;
}
pid_t SubId()
{
return _sub_process_id;
}
std::string Name()
{
return _name;
}
void Close()
{
if(_wfd>=0)
close(_wfd);
}
void Wait()
{
pid_t rid=waitpid(_sub_process_id,nullptr,0);
(void)rid;
}
void SendTask(int taskcode)
{
ssize_t n=write(_wfd,&taskcode,sizeof(taskcode));
(void)n;
}
~Channel()
{}
private:
int _wfd;
pid_t _sub_process_id;
std::string _name;
};
class ProcessPool
{
private:
int Next()
{
int choice=_next_choice;
_next_choice++;
_next_choice %= _channels.size();
return choice;
}
public:
ProcessPool(int number)
:_number(number),
_next_choice(0)
{}
// 父进程
void Start()
{
for (int i = 0; i < _number; i++)
{
// 创建管道
int pipefd[2];
int n = pipe(pipefd);
if (n < 0)
{
perror("pipe:");
exit(2);
}
// 创建子进程
pid_t id = fork();
if (id < 0)
{
perror("fork:");
exit(3);
}
else if (id == 0) // 子进程
{
close(pipefd[1]);
Work(pipefd[0]);
close(pipefd[0]);
exit(0);
}
else // 父进程
{
close(pipefd[0]);
// pipefd[1]; // ??
// Channel c(pipefd[1]);
// channels.push_back(c);
_channels.emplace_back(pipefd[1],id);
}
}
}
// 1.什么任务——任务码决定
// 2.任务给谁——属于进程池内部操作,负载均衡
void PushTask(int taskcode)
{
//选择一个子进程
int who=Next();
_channels[who].SendTask(taskcode);
std::cout<<"发送任务:"<<Task2String(taskcode)<<"["<< taskcode <<"]"<<"给:"<<_channels[who].Name()<<std::endl;
}
void Stop()
{
// version2 ???
// for(auto &channel:_channels)
// {
// channel.Close();
// channel.Wait();
// std::cout<<channel.Name()<<"close and wait success!"<<std::endl;
// }
// version3
int end=_channels.size()-1;
while(end>=0)
{
_channels[end].Close();
_channels[end].Wait();
std::cout<<_channels[end].Name()<<"close and wait success!"<<std::endl;
end--;
}
// // 内部bug!
// // 1.关闭wfd ————version1
// for(auto &channel:_channels)
// {
// channel.Close();
// std::cout<<channel.Name()<<"close success!"<<std::endl;
// }
// sleep(3);
// // 2.回收子进程
// for(auto &channel:_channels)
// {
// channel.Wait();
// std::cout<<channel.Name()<<"wait success!"<<std::endl;
// }
}
void DebugPrint()
{
std::cout<<"--------------------------------"<<std::endl;
for(auto &channel:_channels)
{
std::cout<<channel.Fd()<<std::endl;
std::cout<<channel.SubId()<<std::endl;
std::cout<<channel.Name()<<std::endl;
}
std::cout<<"--------------------------------"<<std::endl;
}
~ProcessPool() {}
private:
std::vector<Channel> _channels;
int _number;
int _next_choice;
};
// 父进程
#ifdef __MAIN__
static void Usage(const std::string &proc)
{
std::cout << "Usage:\n\t" << proc << "process_number" << std::endl;
}
// ./process_pool 5
int main(int argc, char *argv[])
{
if (argc != 2)
{
Usage(argv[0]);
exit(1);
}
int number = std::stoi(argv[1]);
// 0.加载任务
srand(time(nullptr)^getpid());
LoadTask();
std::vector<int> task_codes;
RandomTask(&task_codes);
// 1.创建进程池对象
std::unique_ptr<ProcessPool> pp=std::make_unique<ProcessPool>(number);
// 2.启动进程池
pp->Start();
sleep(2);
// for(auto task:task_codes)
// {
// pp->PushTask(task);
// usleep(500000);
// }
// while(true)
// {
// // int code=0;
// // std::cout<<"Please Enter Your Task# ";
// // std::cin>>code;
// // if(code<0 || code>gtasks.size())
// // {
// // std::cout<<"任务码错误,请重新输入"<<std::endl;
// // continue;
// // }
// pp->PushTask(code);
// }
pp->Stop();
return 0;
}
#endif五、进阶优化:让进程池更实用
我们手搓的是基础版进程池,实际生产中可根据需求优化以下几点:
-
动态调整进程池大小:根据任务量自动增加/减少子进程(避免空闲子进程浪费资源);
-
任务类型扩展:支持传入函数指针和参数,让进程池能处理不同类型的任务(而非固定打印);
-
非阻塞添加任务:任务队列满时,返回错误而非阻塞,提高主进程灵活性;
-
信号处理优化(后面会给大家讲解):处理SIGCHLD信号,及时回收异常退出的子进程,并重新创建子进程,保证进程池稳定性;
-
使用更高效的IPC:将管道替换为消息队列(支持消息优先级)或共享内存(更高吞吐量)。
六、常见坑点与注意事项
-
管道读写阻塞:子进程read()会阻塞,主进程write()在管道满时也会阻塞,需根据需求调整为非阻塞;
-
僵尸进程:必须用waitpid()回收子进程,尤其是子进程异常退出时,避免僵尸进程占用资源;
-
管道关闭顺序:主进程需先关闭写端,子进程才能读取到EOF并正常退出;
-
内存泄漏:进程池销毁时,必须释放所有分配的内存(child_pids、task_queue、pool本身);
-
任务队列溢出:需设置合理的max_task,避免任务堆积导致内存溢出。
七、总结
通过手搓这个基础版Linux进程池,我们搞懂了进程池的核心逻辑——提前创建子进程、复用子进程、统一管理任务,本质上是用空间换时间,减少进程创建/销毁的开销。
本文的代码虽然简单,但涵盖了进程池的核心流程,你可以在此基础上进行扩展,适配实际业务场景(如Web服务器的请求处理、后台任务调度等)。
如果运行过程中遇到问题,可重点检查管道操作、子进程回收和任务队列的逻辑,这些都是实现进程池的关键。动手敲一遍代码,你会对Linux进程控制和IPC有更深刻的理解~
最后,附上完整代码链接,方便大家直接测试和修改:thread pool

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 50
50 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)