LSTM长短期记忆神经网络多输入多输出预测(Matlab) 所有程序经过验证,保证有效运行。 ...
·
LSTM长短期记忆神经网络多输入多输出预测(Matlab) 所有程序经过验证,保证有效运行。 1.data为数据集,10个输入特征,3个输出变量。 2.MainLSTMNM.m为主程序文件。 3.命令窗口输出MAE和R2,
一、模型概述
本技术方案基于长短期记忆神经网络(LSTM)构建多输入多输出预测模型,通过Matlab实现端到端的数据处理、模型训练与预测分析。模型支持10个输入特征维度与3个输出预测维度的映射关系,适用于时间序列预测、多变量关联预测等场景,具备数据自动划分、归一化处理、模型可视化训练、多维度评估等完整功能模块,可快速落地多变量预测类业务需求。
二、核心功能模块解析
(一)环境初始化与数据导入模块
- 环境清理机制:启动时自动执行环境变量重置操作,包括关闭系统报警信息、关闭所有已开启的图窗窗口、清空内存变量与命令行窗口,避免历史数据残留对模型训练产生干扰,确保每次运行均处于干净的计算环境。
- 数据导入方式:通过读取Excel格式的数据文件(data.xlsx)实现数据源接入,支持批量加载结构化数据,数据文件需遵循"前N列输入特征+后M列输出目标"的格式规范,本方案中默认输入特征列10列、输出目标列3列,可通过参数调整适配不同数据结构。
(二)数据预处理模块
- 训练集与测试集划分
- 采用随机置换(randperm)算法实现数据样本的随机分割,避免因数据顺序导致的模型偏倚。
- 固定划分比例为训练集83.3%(500个样本)、测试集16.7%(100个样本),支持通过修改索引范围调整划分比例,满足不同数据量场景需求。
- 自动转换数据维度为模型适配格式,将输入特征与输出目标数据转换为行表示特征/目标、列表示样本的矩阵结构,符合LSTM网络输入要求。 - 数据归一化处理
- 采用mapminmax函数实现数据线性归一化,将输入输出数据统一映射到[0,1]区间,消除不同特征量纲差异对模型训练的影响。
- 建立输入输出双归一化参数存储机制(psinput、psoutput),分别记录输入特征与输出目标的归一化系数,确保后续预测数据的归一化与反归一化使用相同尺度,避免误差传递。
- 提供归一化应用(apply)与反归一化(reverse)接口,实现训练数据、测试数据、预测结果的统一尺度处理。
(三)LSTM模型构建模块
- 网络结构设计
- 输入层:采用sequenceInputLayer构建序列输入层,自动匹配输入特征维度,支持动态调整输入特征数量。
- 核心层:设置LSTM隐藏层与dropout层组合,隐藏层单元数量可配置(默认180个),通过dropout层(丢弃率0.2)减少模型过拟合,提升泛化能力。
- 输出层:采用全连接层(fullyConnectedLayer)映射到指定输出维度(默认3个),配合回归层(regressionLayer)实现连续值预测,适用于回归类预测场景。 - 关键参数配置
- 优化器:选用Adam梯度下降算法,具备自适应学习率特性,相比传统SGD算法收敛速度更快,对初始学习率敏感度更低。
- 训练批次:设置批处理大小(MiniBatchSize)为30,平衡内存占用与训练效率,减少单次迭代计算量的同时保证梯度估计的稳定性。
- 学习率策略:采用分段衰减(piecewise)学习率,初始学习率0.01,每训练250个epoch后学习率乘以0.5,实现前期快速收敛、后期精细优化。
- 训练控制:最大训练轮次(MaxEpochs)设为500,支持训练过程中自动打乱数据(every-epoch),避免模型记忆训练数据顺序。
(四)模型训练与预测模块
- 训练过程可视化:启动训练后自动生成训练进度图,实时展示训练损失(Loss)的变化趋势,支持直观观察模型收敛过程,便于判断训练是否提前收敛或出现过拟合。
- 模型预测机制:训练完成后自动对训练集与测试集分别执行预测计算,生成预测结果矩阵,预测过程复用训练阶段的归一化参数,确保输入数据尺度一致性。
- 结果反归一化:将预测得到的[0,1]区间结果通过反归一化操作转换为原始数据尺度,还原真实业务场景下的预测值,保证结果的业务可读性。
(五)模型评估与可视化模块
- 多维度评估指标计算
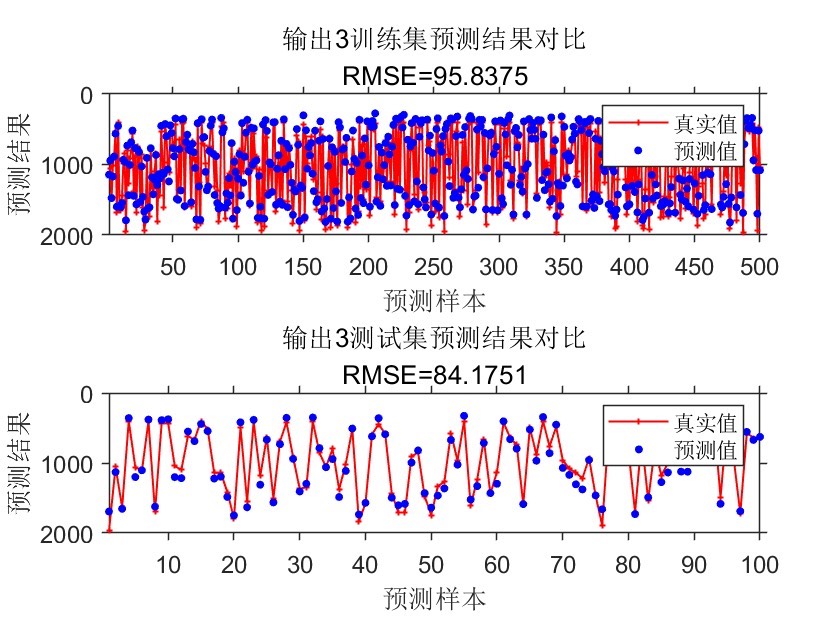
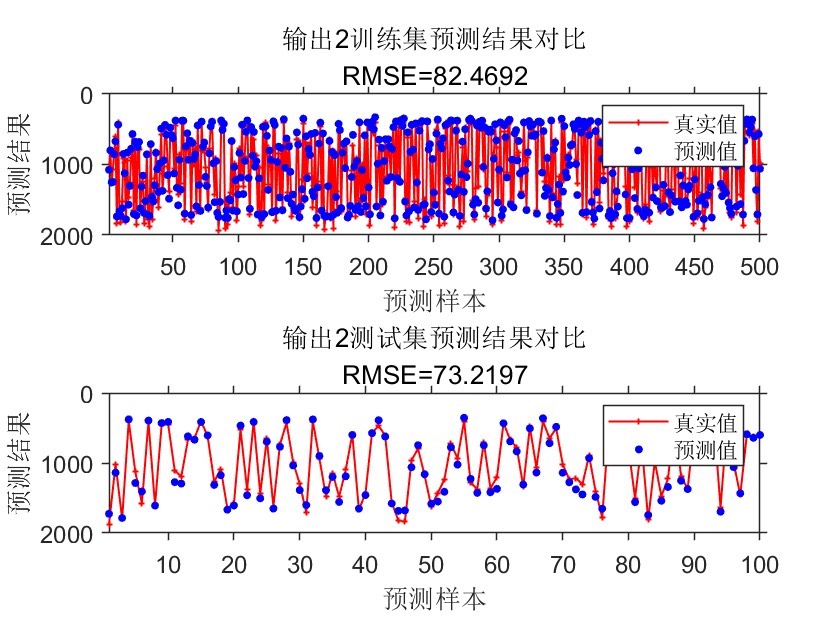
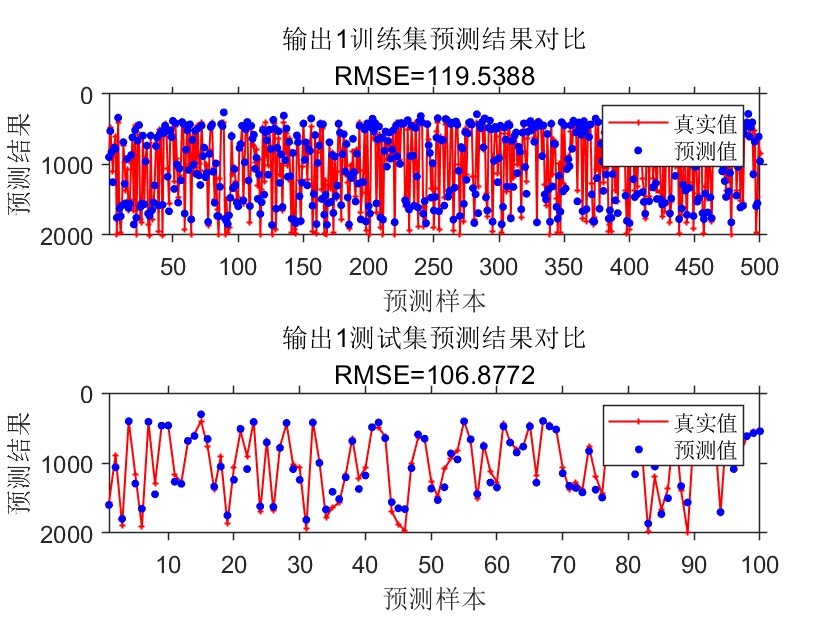
- 均方根误差(RMSE):衡量预测值与真实值的整体偏差程度,计算每个输出维度的RMSE,量化模型预测精度。
- 决定系数(R²):评估模型解释数据变异的能力,R²越接近1表示模型拟合效果越好,支持判断模型对数据规律的捕捉能力。
- 平均绝对误差(MAE):反映预测值与真实值的平均绝对偏差,避免极端值对误差评估的过度影响,更贴近实际业务中的误差感知。
- 平均偏差误差(MBE):衡量预测结果的整体偏移方向,判断模型是否存在系统性高估或低估趋势。 - 结果可视化展示
- 针对3个输出维度分别生成对比图表,每个维度包含训练集与测试集两个子图,采用红色实线+加号标记真实值、蓝色圆点标记预测值,直观展示两者的吻合程度。
- 图表自动标注RMSE数值、维度编号,设置坐标轴范围适配样本数量,优化图表字体、线条宽度、标记大小等视觉参数,提升结果可读性。
- 支持图表实时刷新(drawnow),确保训练与评估过程中图表同步更新,便于实时监控模型效果。
三、模型优势与适用场景
- 核心优势
- 多输入多输出架构:支持同时处理多个输入特征与多个预测目标,适用于复杂多变量关联场景。
- 自动化流程:从数据导入到结果输出全程自动化,无需人工干预数据处理环节,降低使用门槛。
- 鲁棒性设计:通过随机数据划分、dropout正则化、分段学习率等机制,提升模型泛化能力,减少过拟合风险。
- 全面评估体系:多维度评估指标与可视化图表结合,提供量化与定性双重评估结果,便于模型效果验证。 - 适用场景
- 工业过程预测:如设备多参数状态预测、生产指标关联预测等。
- 环境监测预测:如基于多气象因子的空气质量多指标预测。
- 经济数据预测:如基于多宏观指标的GDP、CPI等多维度经济数据预测。
- 能源消耗预测:如建筑多区域、多时段的能源消耗同步预测。
四、使用注意事项
- 数据格式要求:输入Excel文件需确保无缺失值、异常值,建议先进行数据清洗;输入特征与输出目标的列数需与模型参数匹配,修改数据结构后需同步调整输入输出维度参数。
- 参数调优建议:隐藏层单元数量(numhidden_units)、批处理大小、学习率等关键参数需根据数据量大小与复杂度调整,可通过控制变量法进行对照实验,选择最优参数组合。
- 结果解读要点:评估时需综合关注RMSE、R²、MAE、MBE四个指标,避免单一指标误导;若MBE绝对值较大,需检查数据归一化是否异常或模型是否存在结构偏差。
- 性能优化方向:当数据量较大时,可适当减少批处理大小或降低最大训练轮次;若模型过拟合,可提高dropout丢弃率或增加训练样本数量。
LSTM长短期记忆神经网络多输入多输出预测(Matlab) 所有程序经过验证,保证有效运行。 1.data为数据集,10个输入特征,3个输出变量。 2.MainLSTMNM.m为主程序文件。 3.命令窗口输出MAE和R2,

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)