收藏必备!小白程序员必看:从向量库到知识图谱,解锁大模型学习秘籍
文章探讨了向量库在RAG系统中的局限性,如断章取义和信息淹没问题,并引出知识图谱作为更优解决方案。知识图谱通过实体、关系和属性的结构化表示,能够更好地呈现知识内在联系,解决传统知识库的缺陷。文章还讨论了知识图谱与大模型的结合,如何通过图谱推理提升医疗领域大模型的置信度和可解释性,并提出了未来AI知识系统的可能发展方向。
在最初做RAG系统的时候有个几乎绑定的名词:向量库。所以他是什么呢?
应该说向量库是一个理论上很美好的名词,他是一类用于存储和检索向量的数据系统,这里有两点要注意:
- 向量(embedding),可以将一段文本、图片、音频等内容,通过embedding模型编码成一个高维数组;
- 检索,现在拿着一个查询向量,理想情况下向量库可以快速找到最相似的Top-K条类目,这里可以带上原文片段等信息;
所以,向量库找的是语义相近,而不是关键词查询。比如你去搜苹果,系统不可能给到你iPhone手机的,当向量库可以将他搜出来,于是大家就开始兴奋了。这似乎意味着:我们从关键词查询进入了语义查询了!
另一方面,早期模型能力不行,单词上下文也就几千Token,而主流的文本embedding模型最佳编码长度也就500左右(256-768 tokens,最近也有提升到了8000左右Tokens的):
- 太短了,可能信息不足,embedding表达不完整,匹配不上;
- 太长,单个向量需要概括的信息过多,可能稀释核心语义,难以在相似性搜索中被选择,这是“信息淹没”;
这还正好跟模型上下文还对上了,于是乎向量库在早期的RAG系统几乎是标配,并且Coze、Dify、N8N等Agent低代码平台都是默认带上了向量库的,这进一步给很多不明真相群众造成了烟雾弹效应;
但真正使用过程中,大家又发现了好像玩不转,最主要的问题就是断章取义,要明白这是什么,就需要简单做展开:
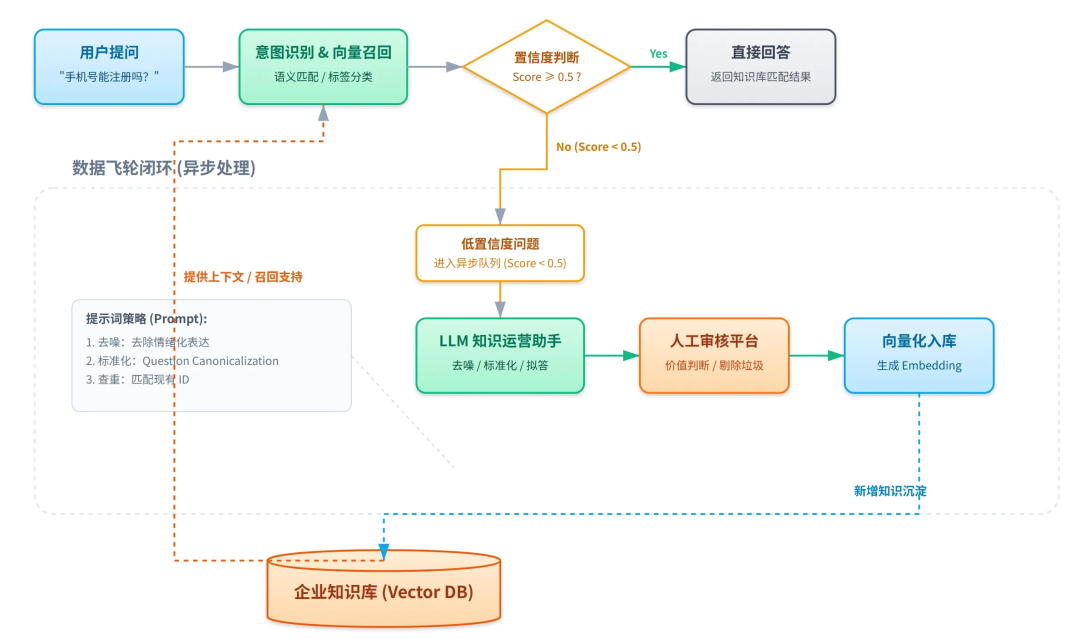
传统RAG
传统向量库构建知识库的底层逻辑,是很粗糙的:
- 切分(Chunking): 把一整段文档直接丢给向量库,然后开始无脑分块;
- 向量化(Embedding): 把这些块映射成高维空间里的坐标;
- 检索(Retrieval): 当用户问问题时,去找空间里距离最近的几个chunk;
- 拼凑(Prompting): 把这几个chunk塞给大模型,说:“来,信息都给你了,把完整文档该给我了”;
如果原始文档过长,而每段分块内容又是不可控的,这里就会导致很多问题,最经典的就是上下文割裂:
文档分块的时候对原文的完整性进行了破坏,比如表格阶段、论证逻辑切断,最终结果是信息丢失,比如以下案例:
电商“退款助手”场景,用户问“多久到账”。RAG 只召回主条款“T+1”,把下一块的“黑名单/已发货订单除外”没带进来,助手回答“一律T+1”,这可能导致高风险订单被误退款。
更恐怖的是医疗或者法律场景,比如将临床指南按段落切分,导致降压药“适用症”与关键的“妊娠期禁用”提示被分隔在不同向量块。
医生在审方时询问:“孕妇高血压能否使用某某地平?”系统如果仅检索到并返回了“适用症”信息块,生成的结果显示“该药可用于治疗高血压”,这存在严重安全隐患。
于是乎,大家逐渐发现一个问题:什么JB语义检索,还是关键词检索靠谱!,于是乎,向量库其实在后来模型进步后(上下文越来越长),一直是个非常尴尬的存在。
但如果非要把这些锅丢全部给向量库,也不大合适,因为RAG效果不行多半是大家想偷懒,数据处理(包括切分)没做好的缘故…
因为大家最后终于发现了:语义相似也只能解决部分问题,我们需要完整的数据关系来表征真实的世界,说人话就是:我们不止要数据,我们还要关系,比如你说到苹果,我们要根据上下文自动带出iPhone,还需要连带带出乔布斯等数据;
到这里才引出今天的主角知识图谱,其实复杂的AI知识库,用的多办事伪知识图谱技术,这里会同时涉及到关键词、向量库检索等。
知识图谱
知识图谱和知识库非常相似,可以说**知识图谱是知识库的一种有机表现形式。**在逻辑上,知识库通过关系链的建立也能够形成图谱结构。
具体来说,知识库是对各种知识的组织、存储和管理,而知识图谱则是在此基础上通过图的结构(实体、关系和属性)来呈现知识的内在联系和结构。
知识图谱通常包括三大元素:
- **实体(Entities):**即图中的节点,代表真实世界中的事物、概念等(如人、地点、物品、概念、类别)。
- **关系(Relations):**实体之间的连接或联系,描述实体之间的互动。
- **属性(Attributes):**描述实体或关系的特征信息,如一个实体的具体属性值。
通过这种标准化的表示形式,知识图谱不仅能够展示实体之间的关联,还能够进行语义分析,帮助计算机理解和推理这些关系。
它为我们提供了一种更加直观、结构化的方式来管理和呈现知识库中的信息。
更粗暴的理解可以是:图谱就是强制将知识库按照实体、关系、属性的标准做结构化,两者间界限很模糊
为方便理解给一个案例,首先是没有关系的知识库:
疾病: { 名称: "糖尿病", 类型: "慢性疾病", 并发症: ["心血管疾病", "肾脏病", "神经损伤"]}症状: [ { 名称: "口渴", 常见疾病: "糖尿病" }, { 名称: "频繁排尿", 常见疾病: "糖尿病" }, { 名称: "体重下降", 常见疾病: "糖尿病" }, { 名称: "疲劳", 常见疾病: "糖尿病" }]药物: { 名称: "胰岛素", 类型: "药物", 用途: "控制血糖", 使用方法: "注射"}
然后是有关系的知识图谱:
实体: [ 疾病("糖尿病"): { 类型: "慢性疾病" }, 并发症("心血管疾病"): {}, 并发症("肾脏病"): {}, 并发症("神经损伤"): {}, 症状("口渴"): { 常见疾病: "糖尿病" }, 症状("频繁排尿"): { 常见疾病: "糖尿病" }, 症状("体重下降"): { 常见疾病: "糖尿病" }, 症状("疲劳"): { 常见疾病: "糖尿病" }, 药物("胰岛素"): { 类型: "药物", 用途: "控制血糖", 使用方法: "注射" }]关系: [ (疾病("糖尿病") - 表现为 -> 症状("口渴")), (疾病("糖尿病") - 表现为 -> 症状("频繁排尿")), (疾病("糖尿病") - 表现为 -> 症状("体重下降")), (疾病("糖尿病") - 表现为 -> 症状("疲劳")), (疾病("糖尿病") - 引发 -> 并发症("心血管疾病")), (疾病("糖尿病") - 引发 -> 并发症("肾脏病")), (疾病("糖尿病") - 引发 -> 并发症("神经损伤")), (疾病("糖尿病") - 治疗 -> 药物("胰岛素"))]
PS:上述只是为了便于各位理解图谱是什么,真实的情况会更复杂,但大体是这么个意思
比如常见的贝叶斯预测:P(糖尿病|多饮+多尿) = P(多饮|糖尿病) x P(多尿|糖尿病) x P(糖尿病) / P(多饮+多尿)
在大模型时代,当前模型对于根据症状推导常见疾病已经非常擅长,但是依旧会由于幻觉有各种问题,这里知识图谱的意义就来了:
输入:咳嗽 + 呼吸急促 + 发热 + 胸痛图谱推理路径:症状 → 咳嗽、呼吸急促、发热、胸痛症状 → [常见疾病类别] → 呼吸系统疾病可能的疾病:肺炎、支气管炎、慢性阻塞性肺疾病(COPD)进一步筛查 → [检查指标] → 血氧饱和度、白细胞计数、胸部影像如果胸部影像显示肺部浸润阴影,高度怀疑肺炎或肺结核影像学特征差异 → [不同疾病影像学差异] → 肺炎(浸润阴影) vs 肺结核(钙化灶)若影像学表现为浸润阴影,进一步考虑细菌性肺炎最终诊断 → [关联知识库] → 确定细菌性肺炎可能性若有相关临床史(如吸烟史、基础疾病),可能进一步确定为慢性阻塞性肺疾病合并肺炎。
综上,大模型其实就是我们所谓的快思考而知识图谱(知识库)就是我们所谓的慢思考了,在快慢结合下,医疗AI的答案将更为靠谱。
知识图谱 → CDSS
医疗是知识图谱最经典的场景,而大模型出现之前最经典的图谱类产品是CDSS(Clinical Decision Support System):临床决策支持系统,是一种为辅助医疗专业人员做出临床决策的AI技术产品。
因为AI辅助诊断的需求一直存在,所以前些年一直有机构在做CDSS的尝试,比如IBM Watson就投入了大量资源,但最终却以失败告终,现在回过头来看看其价值和失败的原因,可能为后续的AI应用研发提供一些中肯的建议。
CDSS的核心原理
CDSS的核心原理之一是基于规则的推理,这种方法依赖于大量由领域专家(医生)手工输入的规则和知识库。
每条规则通常以“如果…则…”的形式存在,系统通过这些规则对患者的症状、检查结果等信息进行分析,给出相应的建议。例如:
- 如果患者有发热、咳嗽和气促的症状,那么该患者可能感染了呼吸道疾病;
- 如果患者的血糖水平持续超过某个阈值,可能需要调整糖尿病治疗方案;
以上的所有规则便形成了CDSS最核心的知识库,他是CDSS最重要的组件:存储着关于各种疾病、症状、治疗方法等的信息。
这些信息通常来自医学文献、临床经验以及专家的知识,通过不断更新知识库,CDSS可以适应最新的医学研究成果和临床实践。
最终CDSS利用知识库中的信息结合患者的临床数据,进行诊断和治疗推理。它可以根据患者的病史、体征、实验室检查结果等信息,自动生成诊断建议,并根据既有的治疗方案推荐治疗方法。
只不过这里有两个核心的问题也就暴露出来了:
第一,知识库不全
CDSS的效果依赖于知识库的完整性,而知识库的完整性依赖于专业人员的不断录入。
且不论ICD11上的几万个疾病信息一次完整录入何其之高,一旦知识库中出现任何错误整个系统就会受到质疑,由此CDSS失败的罪魁祸首出现:
完整的知识库总是难以达成,包括知识的校准以及信息不断的更新,专业医生的时间成本极高。
第二,泛化能力不足
CDSS之所以是辅助系统,是因为其泛化能力不足,他无法从海量的患者语言中抽取出他需要的医学关键词,换句话说:真实世界的患者描述是很宽的,而CDSS的入口是很窄的,这导致了CDSS的适应性极差。
比如患者的描述是:我感觉到胸口很沉,有时候呼吸急促,特别是晚上躺下时。
CDSS通常需要将这些信息转化为结构化的数据,如**“胸痛”、“呼吸急促”**等,才能对症下药。
但**“胸口很沉”**这样的描述是非标准化的,且没有精确到医学术语,CDSS难以直接识别并匹配相关的疾病(如心脏病或呼吸系统问题)。
这里还产生了另一个问题,一旦CDSS的理解(关键词抽取)是错误的,那么整个诊断建议都是不可逆的错误。
这里虽然有些排除算法,但并不能从根本解决问题,因为没办法解决关键术语抽取能力的缺陷。
下图应该能让大家直观的感受到泛化能力中宽窄的情况:
| 术语 | 可能描述 | 难以解释 |
|---|---|---|
| 头痛 | “太阳穴一跳一跳地疼” “后脑勺像被锤子砸” “一吹风就头胀” “看电脑久了眼眶连着疼” | 无法区分偏头痛/紧张性头痛/青光眼 |
| 胸痛 | “心脏位置像针扎” “左胸有东西压着喘不过气” “胸口火辣辣地烧” “深呼吸肋骨下刺痛” | 可能混淆心绞痛/胃食管反流/肋间神经痛 |
| 呼吸困难 | “喉咙被掐住的感觉” “吸气吸不到底” “睡觉躺不平会憋醒” “走两步就要大喘气” | 无法区分哮喘/心衰/COPD/焦虑症 |
| 铁摄入过量 | “最近补铁片后大便发黑” “每天吃半斤菠菜+猪肝” “孕期补铁后恶心加重” | 可能忽略铁剂中毒风险 |
无法跨越这个泛化能力不足的问题,所以CDSS只能是辅助系统,由医生输入真实的症状信息,比如医生根据用户描述进行症状输入。
者就显得CDSS很鸡肋了:好的医生不需要CDSS,水平不行的医生本身也抽取不准,一时之间,CDSS竟有鸡肋之感受!
所以,结论就是:CDSS没用咯?这可能也不至于,特别是大模型的AI时代。
CDSS的本质是医学知识库,更进一步可以衍生出一套医学知识图谱,这套图谱在之前由于泛化能力不足所以不好用,但在大模型时代技术鸿沟的问题被弥合了,所以知识图谱也就开始焕发新生了。
图谱 VS 知识库
从存储方式来说图谱区别于知识库的差异在于图结构 VS 表结构,其实更深一步来说,其差异是认知的差异,或者说点状或网状。
传统的知识库以表分类知识: 传统知识库如同中药房的百子柜,每个抽屉(数据库表)存放着严格分类的知识:
- **疾病表:**ICD-11编码、标准名称、所属科室;
- **药品表:**化学名、适应症、禁忌证;
- **症状表:**标准化描述、关联器官;
这种结构的致命缺陷在2020年新冠疫情中暴露无遗:当患者同时出现发热、腹泻、味觉丧失时,系统无法自主发现这些跨科室症状的新型关联模式。
其实这里疾病和症状表之间可以通过多重关系表(如症状与疾病的“表现为”关系)建立更多动态的联接,这能更好地发现症状之间的组合关联模式。
但即便如此,这种关系依然是预先定义好的。这里的意思是:知识库 + 关系表在已知关系的场景中可以满足大部分需求,尤其是在数据结构比较明确且稳定的情况下。
而知识图谱的核心优势是**开放系统的可扩展性,以及它能够应对更加动态、复杂和未知的情况。**这里举个例子:
二甲双胍的案例
二甲双胍是治疗2型糖尿病的一线药物,但临床观察和部分研究显示:
- 患者长期服用后体重可能下降;
- 可能通过抑制肝糖异生、改善胰岛素敏感性间接影响脂肪代谢;
- 在非糖尿病人群中也可能产生代谢调节作用;
这类跨领域、非直接的关联关系在传统医学知识库中往往缺失,但知识图谱可以低成本扩展。
假设某医学数据库的结构如下:
药物表(ID, 名称, 适应症, 副作用...)疾病表(ID, 名称, 治疗方法...)
当需要添加"二甲双胍→减肥"关系时:
- 需要修改数据库模式(新增字段或关联表);
- 需临床指南明确认可该用途才能入库;
- 无法表达间接作用机制(如通过AMPK通路影响代谢);
但以上问题在知识图谱规则中就比较简单了:
(二甲双胍, 治疗疾病, 2型糖尿病)(二甲双胍, 可能影响, 体重)(二甲双胍, 作用机制, AMPK通路激活)(AMPK通路激活, 调节过程, 脂肪分解)(体重减轻, 证据等级, IIb级临床证据)二甲双胍 → 激活AMPK → 促进脂肪分解 → 导致体重下降
当新研究发现时,只需添加三元组:
(二甲双胍, 抑制, mTOR信号通路)(mTOR信号通路抑制, 关联, 寿命延长)
以上算是产品视角层面图谱与知识库的核心差异。
生成手段
传统知识库通常由**权威专家(至少会有专家校验)**手工录入数据,所有信息都经过严格审核,确保每条记录都能追溯到权威文献或临床指南。
这种方式使得数据具有高度的准确性和权威性,便于医生查证数据的来源,提高医疗决策时的信心。
知识图谱的话除了从结构化的数据(比如知识图谱)生成外,还会从非结构化数据(比如文章、文献、网页甚至影像等)提取关系和实体。
意思是他可以通过一套程序自动生成,比如之前我们研究的阿里KAG框架,可以直接提取我文章形成图谱:
PS:实际提取的还不太好…
医疗置信度
在当前医疗大模型产品中,溯源(可追溯性)和医疗置信度是至关重要的,因为它们直接关系到诊断决策的安全性和可靠性。
指能够追踪每一条信息的来源,从原始文献、临床指南、专家共识到数据采集的具体过程。
溯源性越高,医生越能确信系统给出的结论有明确的依据,从而在临床决策中更有信心使用这些数据。
只要医疗信息可溯源,加之算法清晰合理,其医疗置信度自然就高了。
综上,图谱与知识库各有优劣但大家也不必纠结,一起使用就好,其实可以看出,图谱会更适应于大模型时代的搜索使用。
至此进入今天的正题:知识图谱+大模型提升解决医疗幻觉问题
图谱+LLM
如上所述,AI1.0时代的CDSS根本无法满足医生的基本使用,而大模型时代的DeepSeek依旧在模型幻觉等问题上让医疗人员犹豫不决,比如以下案例:
输入:65岁男性,持续胸痛伴随呼吸困难,症状加重,10分钟内没有缓解,既往有高血压和糖尿病病史,急诊就诊。错误诊断:急性支气管炎依据:胸痛和呼吸困难可能由气道感染引起,尤其是在有慢性呼吸道症状的患者中。实际病因:急性心肌梗死风险后果:延误紧急冠脉介入治疗,可能导致心脏骤停或大面积心肌坏死。
在急诊分诊、手术抢救等情境下,错误的诊断不仅会延误治疗,还可能使患者失去最佳抢救时机,极大地危及生命。
因此,降低大模型幻觉风险、提高生成答案的可信度成为关键任务。
而知识图谱结合大模型的使用会是解决模型幻觉乃至增强医疗置信度的有效手段
PS:这类应用其实有很多,比如前面所述的KAG乃至GraphRAG(由微软研究院开发的一种新型检索增强生成框架,它旨在利用知识图谱和大型语言模型来提升信息处理和问答能力)。
医疗置信度的四个维度
为了保证诊断建议的准确性和临床安全性,我们需要考虑四个维度:
- 数据溯源。 每条诊断结论都应能追溯到权威指南、临床文献和历史病历数据。只有明确溯源,医生才能信任系统的判断。
- 多模态一致性。 综合患者的主诉、检查数据、影像资料等多方面信息,确保不同数据源之间推理结果的一致性。多模态一致性有助于消除单一数据带来的偏差。
- 动态规则适配。 系统必须能够实时更新,根据最新的医学研究和临床指南动态调整诊疗路径。动态适配确保了诊断建议始终反映最新临床证据。
- 可解释推理链。 生成的答案应附带详细的推理链和证据来源,让医生了解每一步判断的依据,从而对系统的决策过程有充分信任。
医学知识结构化范式
医疗知识图谱可以形成一张庞大的知识网络。例如,对于2型糖尿病:
{ "实体": "2型糖尿病", "属性": { "诊断标准": ["空腹血糖≥7mmol/L", "HbA1c≥6.5%"], "治疗路径": ["一线用药: 二甲双胍", "二线加用: SGLT2抑制剂"] }, "关系": [ {"source": "糖尿病", "target": "视网膜病变", "type": "并发症"}, {"source": "二甲双胍", "target": "维生素B12缺乏", "type": "副作用"} ]}
通过这种结构化方式,系统可以明确展示各医学实体之间的因果和关联关系,形成完整的知识链条。
这样,在实际诊断过程中,知识图谱不仅能提供丰富的背景知识,还能对大模型的生成过程进行实时约束和验证,从而大幅降低幻觉风险。
并且,图谱的更新速度可以很快,一般3天就能做一次更新,以进一步保障医疗的及时性。
图谱+RAG
在实际应用中,将知识图谱与RAG技术结合,可以构建一个多层次的智能诊断体系。
该系统通过智能路由、查询规划和多模态整合,形成了一个自上而下的三层防御体系,确保生成答案具有高医疗置信度和充分可解释性:
A[用户输入] --> B{简单查询?}B -->|是| C[RAG基础层]B -->|否| D[图谱推理层]C --> E[置信度验证]D --> EE -->|≥90%| F[直接输出]E -->|<90%| G[专家复核]subgraph 知识中枢 H[症状库] --> I[疾病-症状矩阵] J[检查库] --> K[诊断决策树] L[治疗库] --> M[指南规则引擎]endD -->|实时调用| HD -->|动态关联| J
在此架构中,系统首先对输入问题进行初步判断:对于简单、标准的查询直接由RAG基础层处理;
而对于复杂、多模态或涉及实体关系的问题,则交由图谱推理层进一步分析。
无论哪种路径,最终结果都经过置信度验证,当系统置信度超过预设阈值(如90%)时直接输出,否则提交专家复核。
以下是通过知识图谱实现对复杂问题的结构化推理案例:
步骤1: 症状解析 → 解析腹痛位置(上腹)、放射特征(向背部); 步骤2: 图谱触发 → 根据症状匹配胰腺炎和胆囊炎的鉴别路径; 步骤3: 检查建议 → 推荐淀粉酶检测(强制项)和腹部CT; 步骤4: 动态排除 → 根据Murphy征结果,若阴性则排除胆囊炎; 步骤5: 治疗规划 → 根据体重计算液体复苏方案及禁食时间;
为了更直观展示知识图谱+LLM对提高医疗置信度的效果,下面通过三个层次的案例进行对比分析,以下是基本输入:
{ "主诉": "突发撕裂样胸痛放射至背部,伴呼吸困难", "病史": "高血压10年", "生命体征": "血压180/110mmHg,双侧脉搏不对称", "实验室检查": "D-二聚体 5.2mg/L", "心电图": "无ST段抬高"}
一、大模型(无RAG技术)
# 原始输入直接传递prompt = f"""患者信息:{input_data} 请给出诊断建议:"""{ "诊断": "高血压危象(置信度88%)", "建议": ["硝苯地平舌下含服", "监测血压"], "遗漏风险": ["未识别主动脉夹层特征", "忽视D-二聚体异常"]}
二、大模型+RAG
# 向量检索结果retrieved_context = ["文献1:D-二聚体>0.5mg/L需考虑血栓性疾病(NEJM 2023)","文献2:双侧脉搏不对称提示主动脉病变(Circulation 2022)"]# 提示词组装prompt = f"""临床数据:{input_data} 相关医学证据:{retrieved_context} 请结合证据生成诊断:"""# 模型输出{"诊断": ["肺栓塞(概率45%)", "主动脉夹层(概率38%)"],"建议": ["CT肺动脉造影", "静脉肝素治疗"],"冲突项": "肝素可能加重主动脉夹层出血"}
这里的输出其实已经不错了,只不过组装的信息缺少逻辑性。
二、大模型+图谱+RAG
# 最终提示词prompt = f"""【严格遵循临床推理规则】患者数据:{input_data} 图谱诊断路径:主动脉夹层(Stanford A型) 必要检查:急诊主动脉CTA(依据:2023 ESC指南第8.2章) 药物禁忌:β受体阻滞剂优先于硝普钠(心率>60次/分) 请生成结构化诊断报告:"""# 模型输出{"诊断": "急性主动脉夹层(DeBakey I型)","置信度": 97.3%,"核心证据链": [ "高血压病史→血管内皮损伤风险↑", "撕裂痛+脉搏不对称→夹层特异性征象", "D-二聚体>5mg/L排除心梗(敏感性92%)" ],"处置方案": [ "立即控制血压:艾司洛尔静脉泵入", "15分钟内完成主动脉CTA", "心血管外科急会诊" ],"绝对禁忌": [ "禁用抗凝/抗血小板药物", "避免剧烈搬动患者" ]}
这种在输出前结合CoT的功能,再集合溯源的功能,医生还不被“迷得死死的”…
结语
最后总结一下:向量库从来都不是RAG必须的选择,他的问题很大,它将知识压缩为孤立的“点”,这种所谓语义检索是很脆弱的。
相应的,知识图谱的“回归”,则是对知识本质的回应:**它不满足于点与线的偶然关联,而是着力构建实体、属性和关系的确定网络。**它带来的不是“更像”,而是“更相关”与“更可信”,通过可解释的逻辑链,将检索从概率匹配提升到关系推理。
事实上做过复杂AI知识库业务的同学会理解:伪知识图谱就是CoT本身了。
最后,工程实践也正在走向务实与融合,但依旧有很多问题需要处理,其中最大的问题是人们很“懒惰”,他们并不想去处理烦躁的数据。于是乎市面上也出了很多自动数据处理的框架,比如PageIndex:
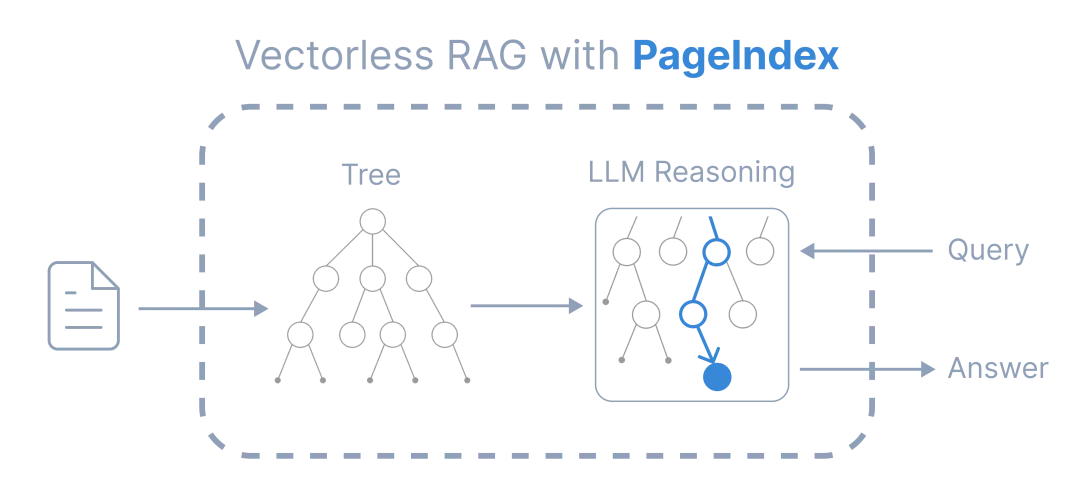
他通过层级化、结构化的索引,检索可以变为先定位、后精读的“规划-取证”流程。
向量库在此体系中,作用是处理模糊问法的补充工具,这可能才是他真正需要去到的角色。真实的系统,往往是关键词、规则路由、向量检索与图谱查询的混合体。
这里再说下下阶段的可能:未来的AI知识系统,或许将不再显式区分这些组件,而是将其内化为自主规划、多步推理、自我校验的Agent能力。从“检索增强”走向“推理增强”,让机器不仅找到片段,更能理解因果,最终交付确信的答案。
我反正看进来Google的NoteBookLLM表现是很不错的,他的技术路径可能是个方向。
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。

👇👇扫码免费领取全部内容👇👇

最后
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献222条内容
已为社区贡献222条内容

所有评论(0)