REAL-MM-RAG: A Real-World Multi-Modal Retrieval Benchmark
核心聚焦多模态检索增强生成(mRAG)系统的真实场景评估与优化。针对现有基准数据集缺乏真实世界代表性、查询设计不贴合实际使用场景等问题,论文提出了满足四大核心属性的 REAL-MM-RAG 基准数据集,并配套推出两类针对性训练数据集,系统揭示了当前模型在表格密集文档处理与查询重述鲁棒性上的关键缺陷,为多模态检索模型的实用化优化提供了标准化工具与实证方案。
一、研究背景与核心问题
1.1 研究动机
多模态 RAG 系统需从包含文本、表格、图表、图像的文档中精准检索相关信息,已广泛应用于企业报告分析、技术文档查询等真实场景。但现有研究存在显著局限:
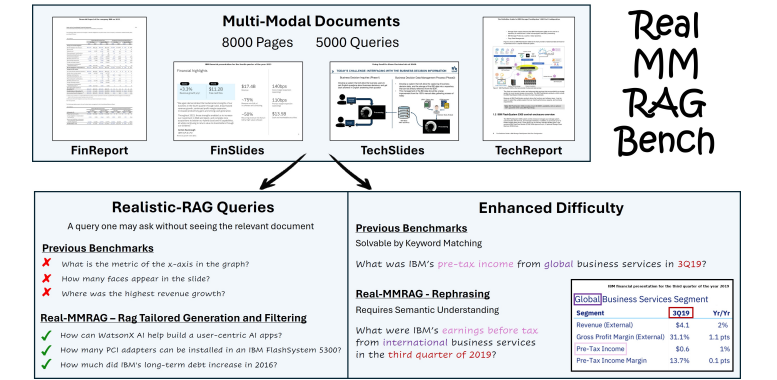
- 基准数据集缺陷:现有数据集多存在模态单一、查询设计贴近文档原文(依赖关键词匹配而非语义理解)、标注错误率高(尤其是假阴性标注)、场景难度不足等问题,无法反映真实世界中 “用户无文档先验知识”“查询表述多样”“相似内容区分” 等核心挑战;
- 模型评估片面:缺乏对 “查询重述鲁棒性”“表格密集文档处理能力” 等实用维度的评估,导致模型优化方向偏离实际需求;
- 优化方案缺失:针对真实场景核心痛点的靶向训练数据与优化策略不足,模型在实际应用中性能衰减严重。
1.2 核心问题
- 如何构建具备 “多模态文档、高难度场景、真实 RAG 查询、精准标注” 四大属性的基准数据集,填补真实场景评估空白?
- 当前主流多模态检索模型在真实场景中存在哪些关键性能短板?
- 如何通过针对性训练数据设计与微调,有效弥补模型在表格处理与查询重述鲁棒性上的缺陷?
1.3 研究贡献
- 定义真实世界多模态检索基准的四大核心属性,明确现有数据集的关键短板;
- 提出REAL-MM-RAG 基准数据集:通过自动化生成与验证 pipeline,构建包含 8000 页多模态文档、5000 个真实查询的高质量基准,支持查询重述鲁棒性与表格密集场景评估;
- 建立三级查询重述评估框架:首次标准化多模态检索模型的语义理解能力评估,突破关键词匹配依赖;
- 提供两类靶向训练数据集:重述训练集与金融表格密集训练集,微调后模型在 REAL-MM-RAG 上实现 SOTA 性能,验证了针对性优化的有效性。
二、REAL-MM-RAG 基准数据集构建
数据集通过 “文档收集 - 查询生成 - 查询验证 - 查询重述 - 标注验证” 五阶段自动化 pipeline 构建,确保四大核心属性的同时,兼顾规模与质量。
2.1 核心设计原则(四大属性)
表格
| 核心属性 | 定义与实现方式 |
|---|---|
| 多模态文档(Multi-modal documents) | 涵盖文本、表格、图表、图像等多种元素,文档类型包括财务报告、技术文档、演示幻灯片等 |
| 增强难度(Enhanced difficulty) | 聚焦同一领域(IBM)的长文档,包含大量语义相似页面,需模型区分细节差异;通过查询重述避免关键词匹配依赖 |
| 真实 RAG 查询(Realistic-RAG queries) | 查询自然表述,无页面编号、图表引用等文档结构关联信息,贴合用户无先验知识的信息检索场景 |
| 精准标注(Accurate labeling) | 通过 VLM 自动化验证所有文档与查询的相关性,大幅降低假阴性标注率,确保评估可靠性 |
2.2 数据集核心构成
(1)文档集
聚焦 IBM 单一企业的四大专业领域,确保内容语义关联性与场景真实性:
表格
| 文档类型 | 描述 | 页数 | 核心模态特征 |
|---|---|---|---|
| FinReport(财务报告) | 2005-2023 年年度财务报告(19 份) | 2687 | 文本 + 表格混合(表格占比 24%) |
| FinSlides(财务幻灯片) | 2008-2024 年季度财务演示幻灯片(65 份) | 2280 | 表格密集(表格占比 83%) |
| TechReport(技术报告) | FlashSystem 相关技术文档(17 份) | 1674 | 文本密集 + 少量视觉元素(文本占比 81%) |
| TechSlides(技术幻灯片) | 业务与 IT 自动化演示幻灯片(62 份) | 1963 | 多模态均衡(视觉元素占比 28%) |
(2)查询集
通过 “VLM 生成 + LLM 过滤” 的两阶段流程构建,最终保留 5000 个高质量查询:
- 生成阶段:使用 Pixtral-12B VLM 对每页文档生成 10 个 “无文档先验” 的检索式查询,要求聚焦表格 / 图表等多模态元素,避免直接引用文档内容;
- 过滤阶段:使用 Mixtral-8x22B LLM 筛选,剔除包含页面引用、表述模糊(如无具体公司 / 年份)的查询,确保查询自然性与针对性;
- 重述扩展:对每个查询进行三级重述(保持语义不变),形成 4 种表述版本:
- 1 级:轻微词汇替换(如 “what is” 改为 “what's”);
- 2 级:词汇替换 + 句式调整(如调整语序);
- 3 级:大幅重述 + 句式重构(如 “IBM 2020 年净利润是多少” 改为 “2020 年 IBM 公司的净收益金额为多少”)。
(3)标注验证
采用 Pixtral-12B VLM 对每个查询与所有文档页面进行相关性验证,仅保留 “唯一页面可回答” 的查询 - 页面对,最终假阴性标注率仅 31.9%,远低于 ViDoRe(86.9%)与 MMLongBench(77.8%)。
2.3 数据集质量优势
- 真实查询占比:88.0% 的查询被标注为 “符合真实用户检索习惯”,远超 ViDoRe(32.9%)与 MMLongBench(35.8%);
- 难度适配:同一领域内大量语义相似页面,模型需依赖细粒度语义区分,而非简单关键词匹配;
- 模态覆盖:表格、文本、视觉元素分布贴合真实文档特征,尤其强化了表格密集场景(FinSlides 表格占比 83%)。
三、模型评估与核心发现
3.1 评估设置
(1)评估模型
覆盖文本驱动与视觉驱动两类主流多模态检索模型:
- 文本驱动:BM25(稀疏检索基线)、BGE-M3(多向量稠密检索),包含 OCR 文本转化与 VLM 描述生成两种视觉元素处理方式;
- 视觉驱动:ColPali(基于 PaliGemma 的多向量检索)、ColQwen(基于 Qwen2-VL 的视觉检索)。
(2)评估指标
核心指标为 NDCG@5(评估 Top-5 检索结果的排序质量),辅助指标包括 Recall@1、Recall@5,全面衡量检索准确性与排序合理性。
3.2 核心评估结果与发现
(1)模型性能整体对比(查询重述 3 级场景)
表格
| 模型类型 | 模型名称 | FinReport(NDCG@5) | FinSlides(NDCG@5) | TechReport(NDCG@5) | TechSlides(NDCG@5) |
|---|---|---|---|---|---|
| 文本驱动 | BM25(OCR) | 21.7 | 5.9 | 35.1 | 31.2 |
| 文本驱动 | BGE-M3(Captioning) | 35.9 | 13.8 | 37.5 | 51.7 |
| 视觉驱动 | ColPali | 34.5 | 27.6 | 62.0 | 75.8 |
| 视觉驱动 | ColQwen | 41.8 | 31.1 | 66.9 | 78.1 |
| 微调模型 | RobTabColQwen(本文) | 67.1 | 61.6 | 73.2 | 85.0 |
关键发现:
- 视觉驱动模型显著优于文本驱动模型:尤其在表格密集场景(FinSlides)中,ColQwen 比 BGE-M3(Captioning)性能提升 125%,证明直接利用视觉信息对表格理解的重要性;
- 表格密集场景难度最高:所有模型在 FinSlides(表格占比 83%)上性能最差,基准模型平均 NDCG@5 仅 20 左右,凸显当前模型表格处理能力的短板;
- 查询重述导致性能显著下降:以 ColPali 为例,查询从 0 级重述(原文表述)到 3 级重述(大幅重构),NDCG@5 从 71.3 降至 50.6,下降幅度达 29%,验证模型对查询表述变化的敏感性。
(2)模型核心短板量化
- 表格处理能力不足:基准模型在表格类证据查询上的 NDCG@5 仅 58.6-59.9,远低于文本类(75.8-79.2)与视觉类(84.5-86.8);
- 查询重述鲁棒性差:词汇匹配型模型(如 BM25)受重述影响最大,3 级重述场景下 NDCG@5 从 52.7 降至 27.1,下降幅度达 48.6%;
- 语义相似页面区分困难:同一领域内内容高度相似的页面中,模型易混淆相关与无关信息,假阳性检索率较高。
四、靶向优化方案:训练数据集与微调策略
针对评估发现的核心短板,论文设计两类靶向训练数据集,并通过微调验证优化效果。
4.1 靶向训练数据集构建
(1)重述训练集(Rephrased Training Set)
- 构建方式:基于 ColPali 训练集,使用 LLaMA-3-70B 对 50% 的查询进行三级随机重述,通过 LLM 验证语义一致性,确保重述后查询与原查询意图一致;
- 核心目标:提升模型对查询表述变化的鲁棒性,摆脱关键词匹配依赖。
(2)金融表格密集训练集(Finance-Table-Heavy Training Set)
- 构建方式:基于 FinTabNet 数据集(S&P 500 公司年度报告中的复杂表格),通过 REAL-MM-RAG 的查询生成 pipeline 生成 46000 个 “表格 - 查询 - 答案” 三元组,聚焦表格数据提取与理解;
- 核心目标:强化模型对表格结构、数值信息的检索与理解能力。
4.2 微调策略与优化效果
采用 LoRA 微调策略,基于 ColPali 与 ColQwen 基线模型,分别构建三类微调模型:
- RobCol:仅使用重述训练集微调;
- TabCol:仅使用金融表格密集训练集微调;
- RobTabCol:结合两类训练集微调。
(1)微调模型性能提升(3 级重述场景)
表格
| 模型变体 | ColPali 基准 | RobCol | TabCol | RobTabCol | ColQwen 基准 | RobColQwen | TabColQwen | RobTabColQwen |
|---|---|---|---|---|---|---|---|---|
| 平均 NDCG@5 | 50.6 | 61.2 | 56.0 | 68.9 | 54.5 | 61.1 | 59.8 | 71.7 |
| FinSlides NDCG@5 | 27.6 | 48.4 | 41.5 | 58.3 | 31.1 | 44.3 | 49.6 | 61.6 |
关键结论:
- RobTabCol 综合微调效果最优:平均 NDCG@5 比 ColPali 基准提升 36.2%,比 ColQwen 基准提升 31.6%;
- 表格场景提升最显著:RobTabColQwen 在 FinSlides 上性能提升 98.1%,彻底弥补表格处理短板;
- 重述鲁棒性大幅增强:RobTabCol 在 3 级重述场景下的 NDCG@5(68.9-71.7)接近基准模型在 0 级重述场景的性能(71.3-73.9)。
(2)泛化能力验证
微调模型在新发布的 ViDoRe V2 基准上同样表现优异:
- 英语场景:RobTabColQwen 平均 NDCG@5 达 63.2,比 ColQwen 基准提升 3.1%;
- 多语言场景:平均 NDCG@5 达 59.1,比 ColQwen 基准提升 6.3%,证明训练策略的领域泛化性。
五、相关工作对比
表格
| 研究方向 | 代表工作 | 核心差异 |
|---|---|---|
| 多模态检索基准 | ViDoRe、MMLongBench-Doc | 缺乏真实 RAG 查询设计,假阴性标注率高,无查询重述鲁棒性评估 |
| 文本检索基准 | WIKI-SS-NQ | 模态单一(以文本为主),场景覆盖窄,难度不足 |
| 查询重述研究 | Query Variability Dataset | 仅针对文本检索,无多模态场景支持,未形成标准化评估框架 |
| 表格检索研究 | FinTabNet | 仅提供表格数据,无配套检索查询与评估体系,无法直接用于模型优化 |
| 本研究(REAL-MM-RAG) | - | 首次整合 “真实查询、多模态、高难度、精准标注” 四大属性,配套靶向训练数据集,支持表格处理与查询重述鲁棒性双维度评估与优化 |
六、局限性与未来方向
6.1 局限性
- 查询生成依赖 VLM:查询多样性受限于 VLM 的生成能力,可能未完全覆盖真实用户的查询表述习惯;
- 标注仍受模型能力限制:尽管假阴性率已显著降低,但 VLM 的相关性判断仍可能存在误差;
- 缺乏多页推理评估:当前基准聚焦单页检索,未涉及需要跨页整合证据的复杂检索场景。
6.2 未来方向
- 扩展查询多样性:结合人类标注与 VLM 生成,进一步丰富查询表述类型与场景覆盖;
- 新增多页推理任务:设计需要跨页整合多模态证据的检索场景,提升基准的复杂度与全面性;
- 轻量化优化方案:探索更高效的训练策略,降低靶向微调的计算成本,适配低资源场景;
- 多语言扩展:将基准与训练数据集扩展至多语言场景,满足全球化应用需求。
七、结论
REAL-MM-RAG 基准数据集通过严格的四大核心属性设计,填补了多模态检索真实场景评估的空白,其自动化构建 pipeline 确保了数据质量与可扩展性。评估结果明确了当前模型在表格密集文档处理与查询重述鲁棒性上的关键短板,而配套的两类靶向训练数据集与微调策略,有效实现了模型性能的突破性提升。
论文的核心价值在于:建立了 “真实场景评估 - 核心短板识别 - 靶向优化验证” 的完整闭环,不仅为多模态检索模型提供了贴近实际应用的标准化评估工具,也为模型的实用化优化提供了可直接落地的训练方案,推动多模态 RAG 系统从 “实验室高性能” 向 “真实场景可靠” 演进。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)