Kimi这篇论文动了AI的“地基“。统治十年的残差连接,被中国团队三刀改写了。
文章目录
🍃作者介绍:25届双非本科网络工程专业,阿里云专家博主,深耕 AI 原理 / 应用开发 / 产品设计。前几年深耕Java技术体系,现专注把 AI 能力落地到实际产品与业务场景。
🦅个人主页:@逐梦苍穹
🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、前言
在深度学习的世界里,有一项技术默默统治了整整十年,从2015年一直到今天——它就是残差连接(Residual Connection)。
几乎你能叫得上名字的AI模型——GPT、BERT、LLaMA、Kimi……它们的底层架构里,都离不开残差连接。它就像深度学习大厦里的"钢筋",虽然看不见,但没它整个楼就会塌。
然而,2026年3月,Kimi背后的公司**月之暗面(Moonshot AI)**发了一篇论文,提出了一种叫做 Attention Residuals(AttnRes) 的新技术,直接对这个统治了十年的"钢筋"动了手术。
更让人兴奋的是,如果我们回顾过去两年在残差连接领域的重大突破,会发现一个惊人的事实:
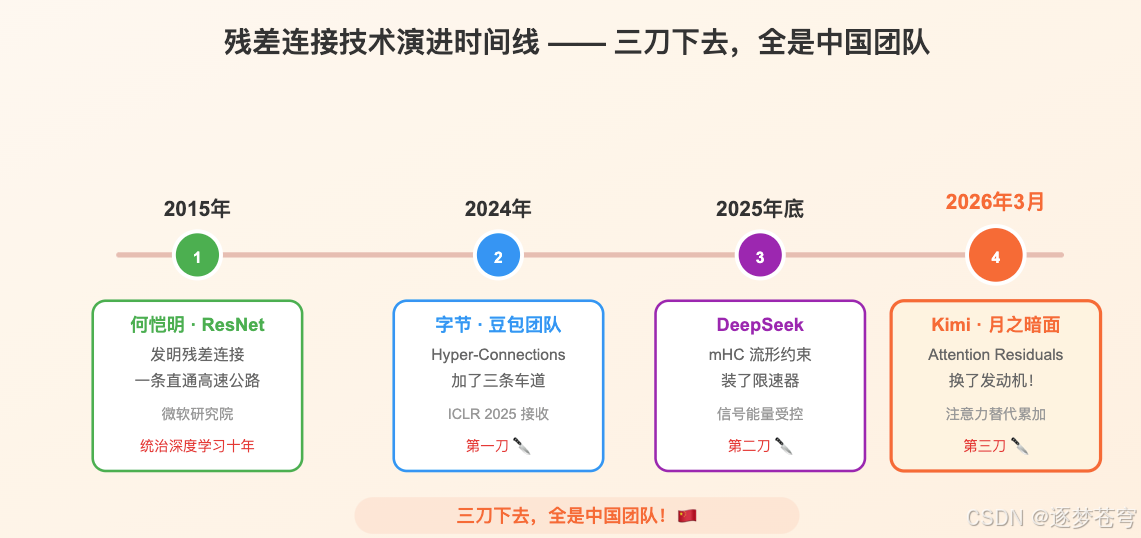
三刀下去,全是中国团队!
- 2024年,字节跳动豆包团队:第一刀
- 2025年底,DeepSeek:第二刀
- 2026年3月,Kimi月之暗面:第三刀
这篇文章,就带你从零开始,用最通俗的方式,搞懂这三刀到底砍在了哪里。
2、一个比喻:信息在神经网络里怎么"走路"
在正式讲技术之前,我们先搞明白一个最基本的问题:深度神经网络到底在干什么?
你可以把一个深度神经网络想象成一条流水线工厂。一张图片、一段文字进去,经过一道道"工序"(也就是网络的每一层),最后输出一个结果——可能是"这是一只猫",也可能是"下一个词应该是什么"。
这条流水线有个特点:它非常长。
现在的大模型动不动就几十层、上百层。信息从第一层出发,一路走到最后一层,中间要经过很多道加工。
问题来了:信息在传递的过程中,会丢失。
这就好比你玩过"传话游戏"——第一个人说"今天天气真好",传到第十个人可能就变成了"今天有鬼来搞"。每传一次,信息就扭曲一点、丢失一点。
在神经网络里,这个问题叫做梯度消失——网络越深,前面层的信息就越难传到后面,训练也就越困难。
在2015年之前,这个问题一直是深度学习的"拦路虎"。网络不是不想做深,而是做深了就没法训练。
3、2015年:何恺明的"直通车"—— 残差连接
3.1 问题有多严重?
2014年的 ImageNet 图像分类大赛(相当于 AI 界的奥运会),获胜的 VGG 网络只有 19层。大家都知道理论上更深的网络应该更强,但一旦网络超过20多层,训练就开始崩溃——准确率反而下降了。
注意,这不是"过拟合"(学得太好导致泛化差),而是连训练集上的成绩都变差了。就好比一个学生,给他更多的学习时间,成绩反而更低了——这不科学。
3.2 何恺明的天才想法
2015年,在微软研究院工作的何恺明(Kaiming He)和他的团队想出了一个极其简洁的办法:
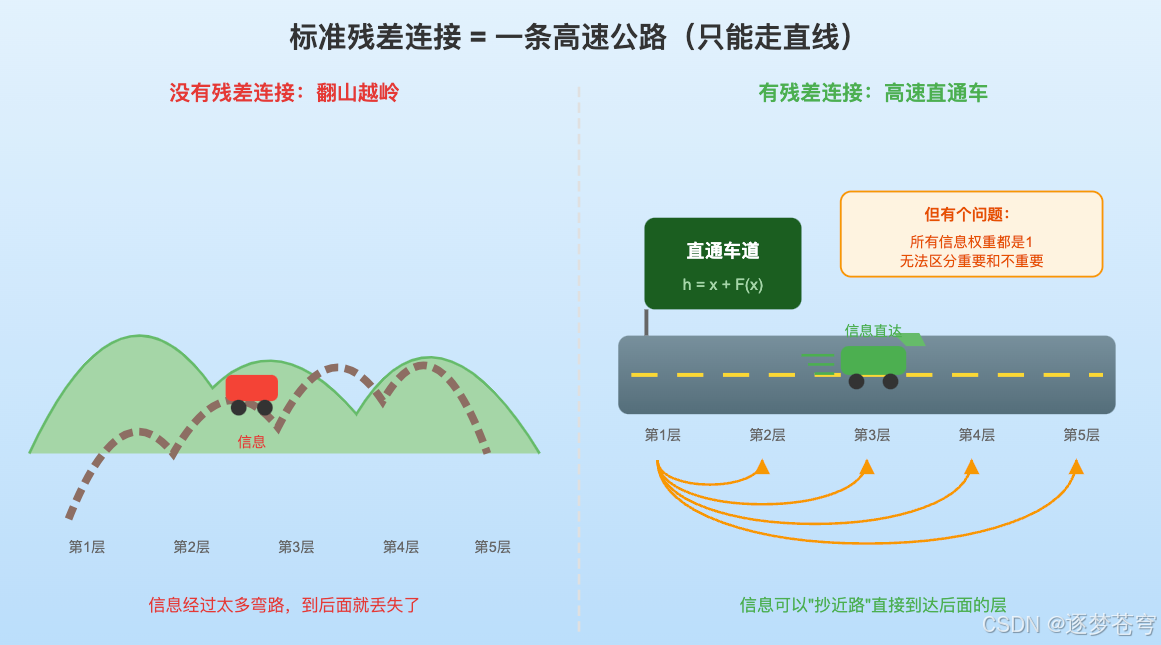
给信息修一条高速公路,让它可以"抄近路"直接到达后面的层,不用每一层都加工一次。
具体怎么做呢?每一层的输出,不再只是"这一层加工后的结果",而是"这一层加工后的结果 加上 原来没加工的输入"。
用生活中的话说:
- 之前:原料 → 第1道工序 → 半成品 → 第2道工序 → 半成品 → ……(原料的样子越来越看不出来了)
- 之后:每道工序完成后,把一份原料的副本也混进去。这样即使中间的工序出了问题,原料的信息也不会完全丢失。
这就是残差连接,也叫跳跃连接。
3.3 效果有多炸裂?
有了残差连接,何恺明团队直接把网络深度拉到了 152层——上一年冠军才 19 层!
这篇论文后来成了21世纪学术引用量最高的论文之一,何恺明也被誉为深度学习领域最有影响力的研究者之一。
从那以后,残差连接就成了深度学习的"标配"。几乎所有的深度网络都在用它,一用就是十年。
4、十年进化:从一条路到三条车道
残差连接虽好,但它也不是没有问题。十年来,研究者们一直在琢磨:这条高速公路还能不能再优化一下?
4.1 残差连接的隐患
残差连接的做法很简单:每一层的输出 = 这一层的加工结果 + 原来的输入。
注意这里的**"+"号**——它意味着所有层的贡献都是等权重的。不管哪一层输出了什么,都是用"1"的权重直接加上去。
这就好比你在做一道菜,盐巴、糖、酱油、味精……每种调料都放一勺,不管菜是什么。层数少的时候还凑合,但当网络有几十层、上百层的时候,问题就来了:
- 信息被稀释:每层的贡献都是1,但总共有100层,那每层的信息在最终输出里就只占1/100。越到后面,越被稀释。
- 无法区分重要和不重要:有些层对某个任务特别关键,有些层贡献很小。但残差连接不管这些,一律按"1"来加。
- 隐藏状态越来越大:每层都往里加东西,信息"包袱"越来越重。
这些问题在学术上叫做**“PreNorm稀释问题”**——每一层的输出占整体的比例,会随着深度增加而越来越小。
4.2 2024年:字节跳动的"第一刀"——加车道
2024年9月,字节跳动的豆包(Seed)团队提出了一个新方案:Hyper-Connections(超连接)。
回到高速公路的比喻:残差连接是一条单车道的高速公路,所有信息都挤在同一条道上。字节的做法是——
把一条车道拓宽成多条并行车道!
原来信息只有一条通道(一个残差流),现在变成了多条通道(多个并行残差流)。不同的信息可以走不同的车道,还能在车道之间切换。
这就像把单车道高速公路升级成了三车道甚至四车道,通行效率大大提升。
这个工作后来被 ICLR 2025(人工智能领域的顶级会议之一)接收,得到了学术界的认可。
4.3 2025年底:DeepSeek的"第二刀"——装限速器
但字节的多车道方案有个问题:车道多了,交通反而容易失控。
在实际大规模训练中,多个并行的残差流会导致信号能量指数级放大——本来应该传1份信号,实际上被放大了3000倍!这会导致训练不稳定、模型崩溃。
2025年底,DeepSeek(深度求索)团队在字节的基础上,提出了一个关键改进:mHC(流形约束超连接)。
用高速公路的比喻来说:
给多车道高速公路装上了"限速器"和"流量管控系统"。
通过一种叫"双随机矩阵"的数学约束,确保无论网络有多深,信号的能量始终在可控范围内。原来字节方案会让信号放大到3000倍,DeepSeek的方案把放大倍数控制在了1.6倍。
这就好比:多车道是好事,但你得给每个车道设定限速,不然大家都飙车,整条高速就全堵死了。
DeepSeek的这一改进,让多车道残差连接真正变得可以在大规模训练中使用了。
4.4 小结:两刀切了什么?
| 团队 | 时间 | 做了什么 | 比喻 |
|---|---|---|---|
| 字节豆包 | 2024年 | 加多条并行车道 | 单车道 → 多车道 |
| DeepSeek | 2025年底 | 加限速器和流量管控 | 防止多车道飙车失控 |
这两刀,本质上都是在**“修路”**——在残差连接这条高速公路上做各种优化。路拓宽了、交通管制好了,确实更好用了。
但它们没有改变一个根本事实:这条路的"发动机"还是那个固定权重的"+"号。
5、2026年:Kimi说,别修路了,换发动机
5.1 问题的本质
前面说的残差连接,不管怎么修路、加车道、装限速器,本质上都逃不开一个核心操作:把所有层的输出用固定的权重加在一起。
Kimi团队(月之暗面)在论文中指出了一个深刻的类比:
这就像早期的循环神经网络(RNN)——RNN在时间维度上,也是把每个时间步的信息不断累加。结果怎样?信息一多就记不住了,早期的内容被不断覆盖和遗忘。
后来Transformer出现了,用注意力机制替代了RNN的固定累加,让模型可以智能地选择要关注序列中哪些位置的信息。这就是AI领域最重要的革命之一。
Kimi团队的核心洞察是:
残差连接在"深度维度"上做的事情,和RNN在"时间维度"上做的事情,本质上是一样的——都是用固定权重把信息堆在一起。
既然Transformer用注意力机制解决了"时间维度"的问题,我们为什么不能用同样的思路,解决"深度维度"的问题呢?
这就是 Attention Residuals(AttnRes) 的核心思想。
5.2 从"傻加"到"智选"
用一个生活中的比喻来理解AttnRes:
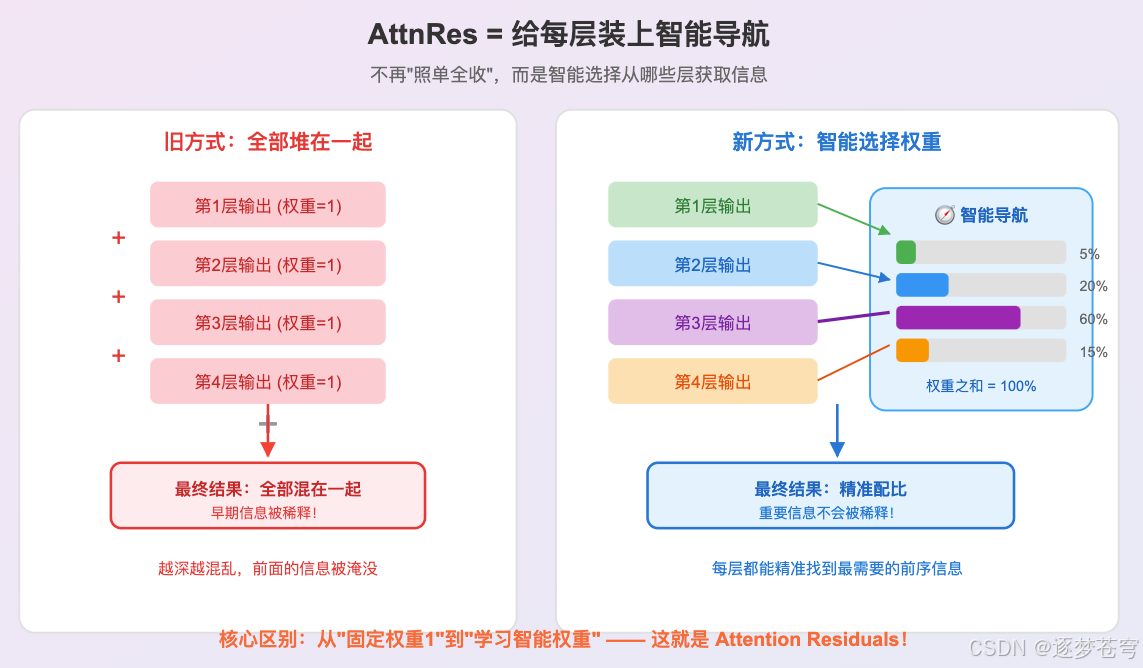
旧方式(标准残差连接)= 自助餐的"全拿"策略
你去吃自助餐,面前有100道菜(100层网络的输出)。标准残差连接的做法是:每道菜都拿一勺,不管你喜不喜欢、需不需要,全部堆到你的盘子里。结果盘子堆成山,每道菜都只能尝到一丁点。
新方式(AttnRes)= 有经验的美食家
同样面对100道菜,AttnRes的做法是:先看看你现在"需要什么口味"(这就是注意力机制中的"查询"),然后有选择地挑几道最合适的菜,多拿一些;不太需要的菜,少拿或不拿。最后你盘子里的菜不多,但每一样都是你真正需要的。
更关键的是,每层的"口味偏好"可以不一样。第20层可能特别需要第3层的信息(因为那里有基础特征),而第50层可能更需要第45层的信息(因为那里有高级语义)。AttnRes让每一层都能根据自己的需求,智能地从前面所有层里"挑选"信息。
这就是用注意力机制替代固定的"+“号——从"傻加"升级为"智选”。
5.3 为什么说是"换发动机"?
之前字节的"加车道"和DeepSeek的"装限速器",都是在残差连接的框架内做优化——路还是那条路,信息传递的方式没有本质改变。
而Kimi的AttnRes是从根本上改变了信息传递的方式:
- 旧方式:所有层的信息像坐公交车一样,到每一站都上人,但永远不下人,车越来越挤。
- 新方式:每一站都有一个"智能调度员",根据当前的需求,从前面所有站点的乘客中,精准挑选几个最需要的乘客上车。
这不是在修路、加车道、装限速器——这是把公交车换成了智能出租车。
6、怎么落地?Block AttnRes的工程智慧
6.1 理想很丰满,现实有挑战
AttnRes的思想虽好,但在工程实现上有个问题:
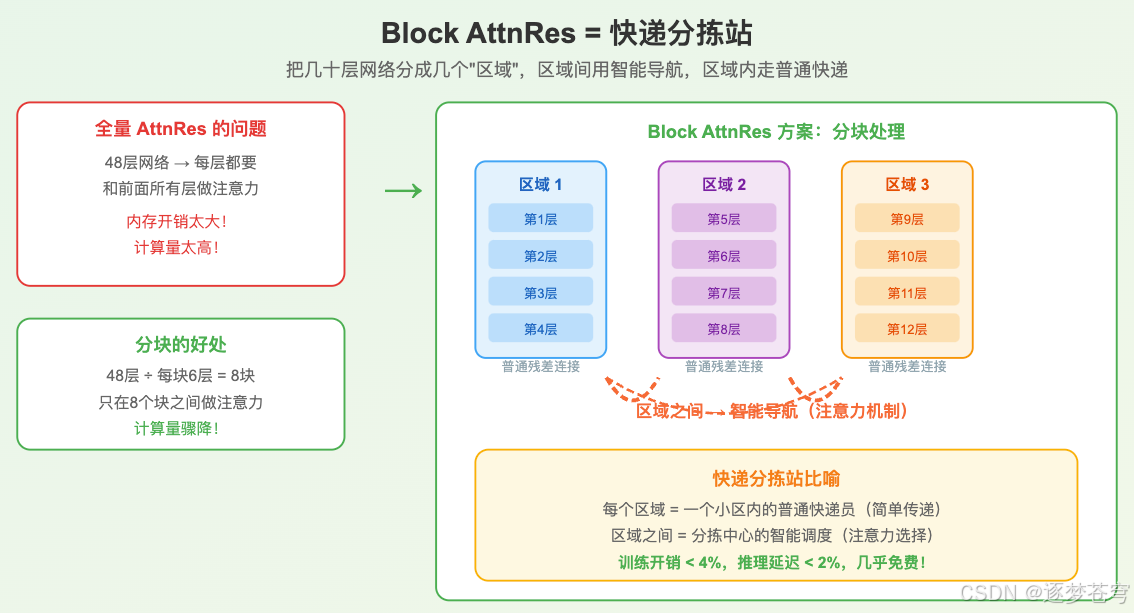
如果网络有48层,那第48层需要对前面所有47层做注意力计算——它需要"看"前面每一层的输出,然后做出选择。这意味着需要把前面所有层的输出都存在内存里,内存开销和计算量都很大。
6.2 快递分拣站的灵感
Kimi团队提出了一个非常聪明的工程方案:Block AttnRes(分块注意力残差)。
这个方案的思路,可以用"快递分拣站"来比喻:
想象一个全国性的快递网络。如果每个快递员都要记住全国所有其他快递员手上有什么包裹,那这个系统马上就崩溃了。
实际的做法是:
- 小区内:快递员直接送货,简单高效(不需要复杂调度)
- 区域间:通过分拣站来中转,分拣站负责智能调度(决定哪些包裹送到哪个区域)
Block AttnRes 的做法完全一样:
- 把48层网络分成8个"块"(每块约6层)
- 块内:用传统的残差连接(简单的"+"号),高效快速
- 块间:用注意力机制做智能选择,精准调度
这样做的好处是:
- 注意力计算只发生在8个块之间,而不是48层之间,计算量大大减少
- 内存占用从存储48层的信息变成只存储8个块的信息
- 训练额外开销不到4%,推理延迟增加不到2%——几乎是"免费午餐"!
7、效果如何?
说了这么多,AttnRes到底有没有用?让数据说话。
7.1 Scaling Law 优势
在大语言模型的训练中,有一条被广泛验证的规律叫 Scaling Law(缩放定律)——模型越大、数据越多、算力越强,模型就越聪明。
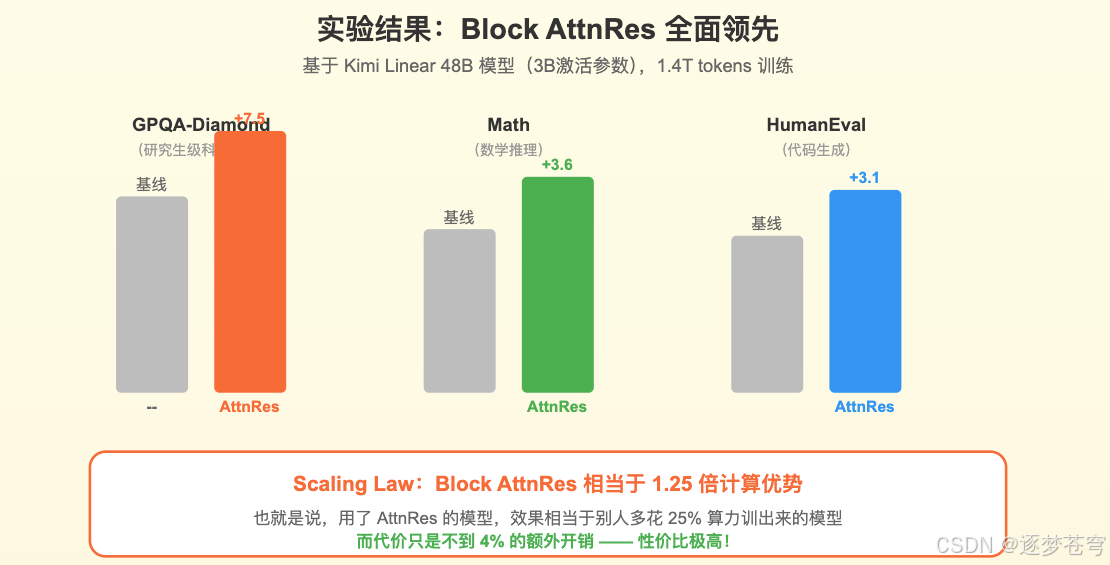
Kimi团队发现,使用 Block AttnRes 的模型,在同等算力下的表现,相当于没用AttnRes的模型多花了25%的算力。
换句话说:别人花100块钱训出来的效果,你用了AttnRes只需要花80块就能达到——而AttnRes本身的额外成本还不到4块钱。这笔账,怎么算都划算。
7.2 实际任务表现
Kimi团队把AttnRes应用到了他们的 Kimi Linear 48B 模型(一个拥有48B参数但只需激活3B参数的高效模型),用1.4万亿个tokens训练,在多个权威评测上都取得了提升:
- GPQA-Diamond(研究生级科学问答):提升 +7.5 分
- Math(数学推理):提升 +3.6 分
- HumanEval(代码生成):提升 +3.1 分
所有评测任务都有提升,没有一项退步。
7.3 解决了老问题
还记得我们前面提到的"PreNorm稀释问题"吗?每一层的贡献被越来越多的层稀释,到后来就像一杯不断兑水的咖啡,几乎没味道了。
AttnRes因为用了注意力机制来分配权重,重要的层可以获得更高的权重,不重要的层权重接近于零。这样一来:
- 输出的幅度被控制在合理范围内(不会无限膨胀)
- 梯度分布更均匀(训练更稳定)
- 前面层的信息不会被后面层淹没
8、总结
让我们回顾一下这十年的技术演进:
2015年,何恺明发明了残差连接——给深度网络修了一条高速公路,解决了"网络太深训练不了"的难题。这条高速公路用的是最简单的规则:每一层的输出,固定地加上前一层的输入。这个简单的"+"号,统治了整个深度学习十年。
2024年,字节跳动豆包团队的第一刀——既然一条车道不够用,那就加多条并行车道(Hyper-Connections)。
2025年底,DeepSeek的第二刀——多车道容易失控,那就装上限速器和流量管控(mHC流形约束)。
2026年3月,Kimi月之暗面的第三刀——别修路了,换发动机吧!用注意力机制替代那个固定的"+"号,让每一层都能智能地选择信息(Attention Residuals)。
三刀下去,全是中国团队。
从"修路"到"换发动机",这是思维层次的跃迁。正如Kimi团队在论文中指出的那个精妙类比:Transformer用注意力机制替代了RNN在时间维度上的固定累加,成就了AI领域最伟大的革命之一。而AttnRes用同样的思路,替代了残差连接在深度维度上的固定累加——这或许是深度建模领域下一个重要的革命。
深度学习的这条高速公路,终于不再只是"修修补补"了。它正在迎来一台全新的发动机。
🚀 持续探索 AI 与前沿技术 分享大模型应用、软件开发实战与行业洞察。 欢迎关注公众号 【龙哥AI】,加入 7000+ 技术同行的交流圈! 🌟 探索技术边界,让开发更有效率 |
 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)