大语言模型(LLM)的底层原理竟然如此简单!3个小游戏让你秒懂,轻松成为科技达人!
目前,不管你是干什么的,你要是还没使用过甚至不知道语言大模型(Large Language Model,简称LLM),别人一定会对你“另眼相看”。不过大多数人只会感觉大模型很聪明,但不能够对这种现象的原因说出个一二三。其实大模型底层原理并不复杂,任何人都能够理解它,本篇文章尽量用外行也能懂的文字阐述大模型的底层原理,以后你也可以上桌讨论了。
我们用三个小游戏学习大模型基本原理:
(一)完形填空
用你的直觉,在括号中填上你觉得合适的字/词
1.三国演()
2.唱,跳,()
3.今天天气()
4.中华人民()
(二)划重点
逐字划出对决定完形填空答案重要的内容
1.打南边来了个喇嘛,手里提拉着五斤鳎目。打北边来了个哑巴,腰里别着个喇叭。 南边提拉着()
2.太阳当空照,花儿对我笑,小鸟说,早早早,你为什么()
3.从前有座山,山里有座庙,庙里有个和尚,和尚说,在数轴上任取一点,它是有理数的概()
(三)语义地图
把下面词汇写到一张纸上,使得意思或者感觉更近的词汇距离更短,更远的词汇反之。
逗比,音乐,数学,扬声器,电脑,复平面,疑问句,假设,娱乐,5,硫酸铜,万有引力
完成上述三个游戏,恭喜你现在已经是一个LLM了!
完形填空小游戏,叫做“predict the next token”(预测下一个字/词)。
划重点小游戏,叫注意力机制
语义地图小游戏,叫词向量嵌入。
我们先来总结一下上面三个游戏的技术要领:
1.完形填空中,我们永远都在填最后一个字/词。并且我们是依赖直觉填空的,不进行任何思考和逻辑推理。本质上,我们是在自己的巨大的字词库中,找到概率最大的候选字词。
2.划重点中,我们给已有的文本内容赋予了“注意力”权重,依它们权重的大小来寻找候选字词的概率。注意力 = 给不同东西 “打分”,比如你读一句话:我今天在学校吃了一个很好吃的苹果。你做阅读理解时,会自动关注:吃了、好吃、苹果。不太关注:我、今天、在学校。
注意力就是:给关键词打高分,不重要的打低分。让模型学会 “哪里重要看哪里”,而不是全都一样看。
3.语义地图中,我们给每个短词赋予一个坐标(即向量),让关系更近的词语挨得更近。
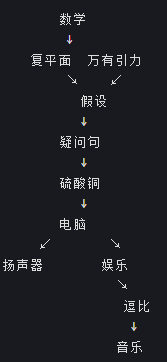
数学、复平面、万有引力、假设、疑问句:偏理性、理科、思考,放一起
硫酸铜:理科实验,靠近数学但单独一点
电脑:工具,一边连理科,一边连娱乐
扬声器、音乐、娱乐、逗比:偏好玩、声音、休闲,放一起
好了!
我们现在来完整地梳理LLM的基本工作原理。当你问完问题,LLM开始回答时,它会利用‘注意力机制’——像一个聚光灯——同时照亮你的问题和它已经写出的回答。每写下一个新词,这束光就会移动,重新计算哪些词对‘接下来写什么’最重要,这样不断取最高的概率的词,直到一个特定的终止符为止。
而LLM的训练过程,就包含用海量数据学习上述几个关键计算过程:
词向量嵌入:学习每个字词对应的向量位置
注意力函数:学习根据所有当前文本的状态+词向量赋予注意力权重
预测函数:学习根据注意力权重+当前文本的词向量状态预测下一个字词的概率
所以LLM本质上是个统计模型,给出的是一个基于训练数据“概率最高”的答案。
那么 LLM 是怎么工作的?
第一步:给词语画一张“关系地图”。我们要训练一个模型,使其能够根据单词在类似环境中出现的频率,理解单词间的关系。可以这么说:“一个单词的特征,取决于它周围的单词。” 我们需要将大量人类撰写的数据输入给它(这里的 “大量”,基本涵盖了整个互联网的范围),然后模型会适时地调整单词之间的位置关系。
这就是所谓的向量空间(vector-space),系统并不真正理解任何一个单词的含义。它仅仅能够理解每个单词在向量空间中与其他单词的相互关系。
想象一下,我们让一个外星人(不懂人类语言的计算机)学习英语。我们不告诉它“苹果”是什么,也不告诉它“吃”是什么意思。我们只是把全互联网的文字像洪水一样倒给它。这个外星人非常擅长做统计。它发现:“苹果”这个词旁边总是出现“红”、“脆”、“削皮”、“吃”;而“吃”这个词旁边总是出现“嘴”、“食物”、“咀嚼”、“苹果”。于是,这个外星人在它的脑海里建了一个巨大的、无限维度的星座图(也就是向量空间)。它把“苹果”和“红”这两个星星放得很近,把“苹果”和“汽车”放得很远。在这个宇宙里,词语没有“灵魂”,只有“邻居”。一个词的含义,就是它所有邻居的总和。
第二步:词语接龙。
有了这张星座图,这个外星人开始玩一个游戏——超级词语接龙。它读过的所有文章,其实都是接龙的范例。它发现了一些规律:如果一句话里出现了“粉丝”、“五月天”、“抢”,那么这段话的“星星坐标”就会聚集在一个叫“演唱会”的星区。在这个星区里,下一个最可能出现的高频词是“票”。所以,LLM 本质上是一个“赌神”。它不看懂你的问题,它只是根据当前这几个词的“星座位置”,去计算:在它读过的那万亿篇文章里,此刻哪个词最该冒出来。
对于 LLM,它们实际上做的就是 “下一个单词预测”,比如说,你向一个 LLM 提出这样的指令:“Tell me you love me.” 它会通过所有已掌握的模式寻找来回答一个问题:这串单词之后,最可能跟随的单词是什么?换个方式表达就是:基于这个句子中单词在向量空间的坐标,我在其他句子中观察到的模式告诉我,下一个单词应该在哪里寻找?LLM 找到的答案是 “I”。确定了这一点后,它会将 “I” 附加到你的原始指令之后,并将整个句子重新输入系统。那么,接下来最可能出现的单词是什么?“Tell me you love me. I” 之后呢?显然是 “love”!将其附加上,再将整个句子投入系统。接下来可能的是:“Tell me you love me. I love”……
AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献62条内容
已为社区贡献62条内容

所有评论(0)