嵌入式视觉落地:从 DeepPCB 数据处理到 YOLOv8 轻量化模型开发实战(mAP 98.5%)
Markdown 博客正文草稿
大家好!最近在筹备一个工业互联网相关的比赛,平时咱们搞惯了单片机底层(比如对着 STM32 的数据手册撸寄存器、写驱动),面对自己画出来的 PCB 板子,往往只关注电气特性。但这次赛题涉及到产线后端的工业质检场景,也就是怎么用机器视觉把有瑕疵的坏板子挑出来。
今天就把我这套基于 YOLOv8n + PyQt5 构建的 PCB 缺陷智能检测系统 开源并拆解给大家。项目涵盖了从数据集格式转换、模型训练调优到最终桌面端 GUI 闭环演示的全流程。模型最终 mAP50 达到了 98.5%,权重仅 6.3MB,非常适合后续往边缘计算板卡上移植!
一、 核心痛点与技术选型
做工业质检,最大的痛点往往不是模型有多复杂,而是数据非标和落地难。
-
算法侧:我选用了 YOLOv8n。带个 "n" (nano) 的原因很简单,工业现场最终是要上边缘端部署的,轻量化是第一要义。单图推理约 59.8ms,能保证检测的实时性。
-
数据侧:采用了 DeepPCB 公开数据集,包含开路、短路、鼠咬、毛刺、针孔、伪铜共 6 类典型缺陷。
-
交互侧:采用 PyQt5 开发了桌面端可视化界面,方便做 Demo 演示,也为后续工业通信联动打底。
二、 数据预处理实战:DeepPCB 转 YOLO 格式
网上的开源数据集格式五花八门,DeepPCB 默认的 txt 标注给的是 [x1, y1, x2, y2, cls](左上角和右下角坐标)。而咱们 YOLO 训练需要的是归一化后的中心点坐标及宽高 [cls, cx, cy, w, h]。
这里必须手写脚本转换,非常容易踩坑的地方在于坐标的除法归一化。以下是我的 convert.py 中的核心解析逻辑:
Python
def parse_annotation(txt_path, img_w=640, img_h=640):
yolo_lines = []
try:
with open(txt_path, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split()
if len(parts) < 5:
continue
# 解析原始数据:x1, y1 (左上角), x2, y2 (右下角)
x1,y1,x2,y2,cls = int(parts[0]),int(parts[1]),int(parts[2]),int(parts[3]),int(parts[4])
# 容错处理:剔除异常坐标
if x2<=x1 or y2<=y1:
continue
# 核心转换逻辑:计算中心点坐标并除以图像宽高进行归一化
cx = ((x1+x2)/2)/img_w
cy = ((y1+y2)/2)/img_h
w = (x2-x1)/img_w
h = (y2-y1)/img_h
# 注意:YOLO类别索引从0开始,DeepPCB可能从1开始,记得 cls-1
yolo_lines.append(f"{cls-1} {cx:.6f} {cy:.6f} {w:.6f} {h:.6f}")
except Exception as e:
print(f"read error: {txt_path} -> {e}")
return yolo_lines
💡 开发者避坑指南: > 很多小伙伴做视觉检测时,训练出来的框满天飞,90% 都是因为没有针对图片真实分辨率做正确归一化。本例中我统一将输入图像重置为 640x640。
三、 YOLOv8 模型训练与性能验证
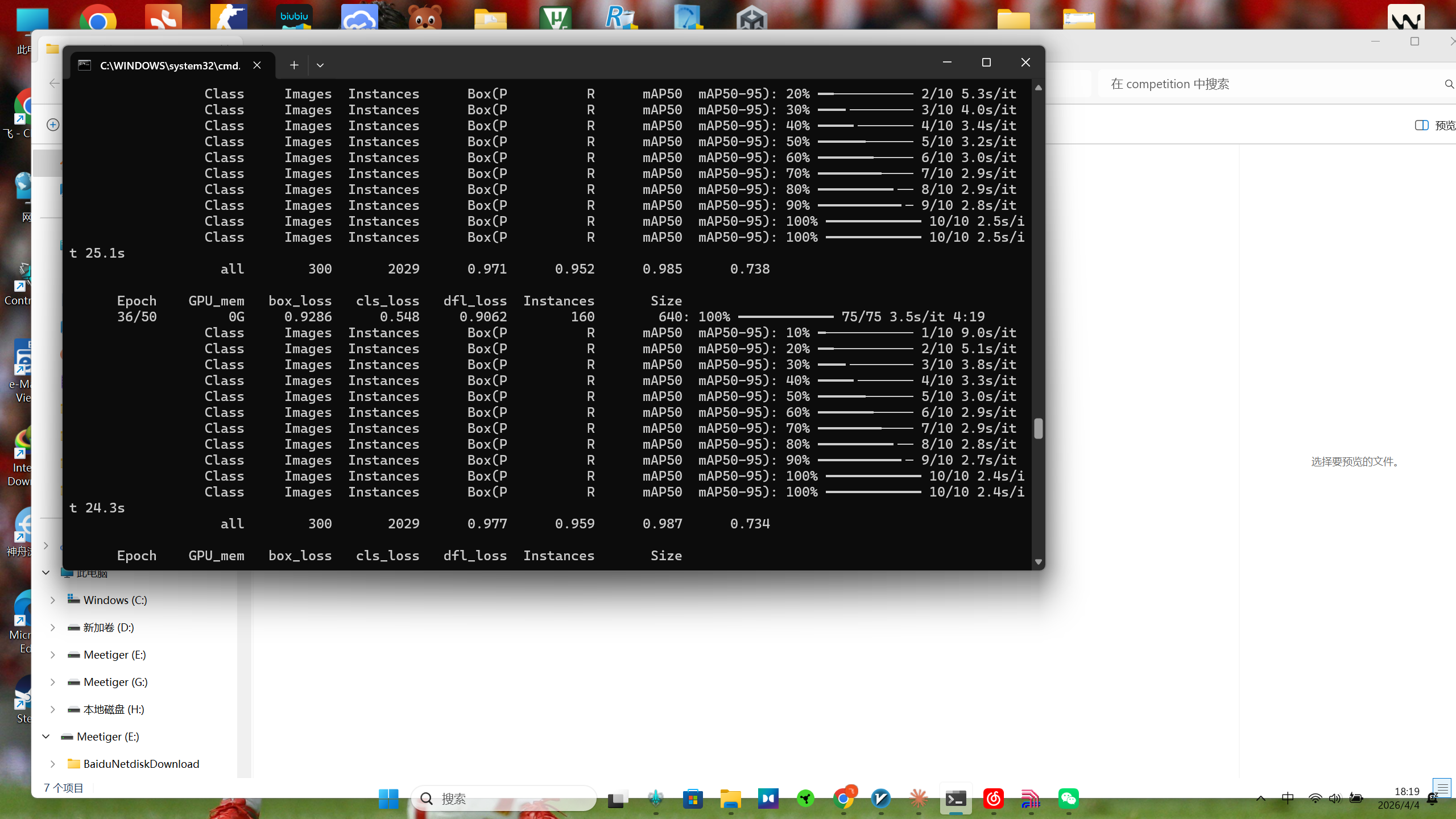
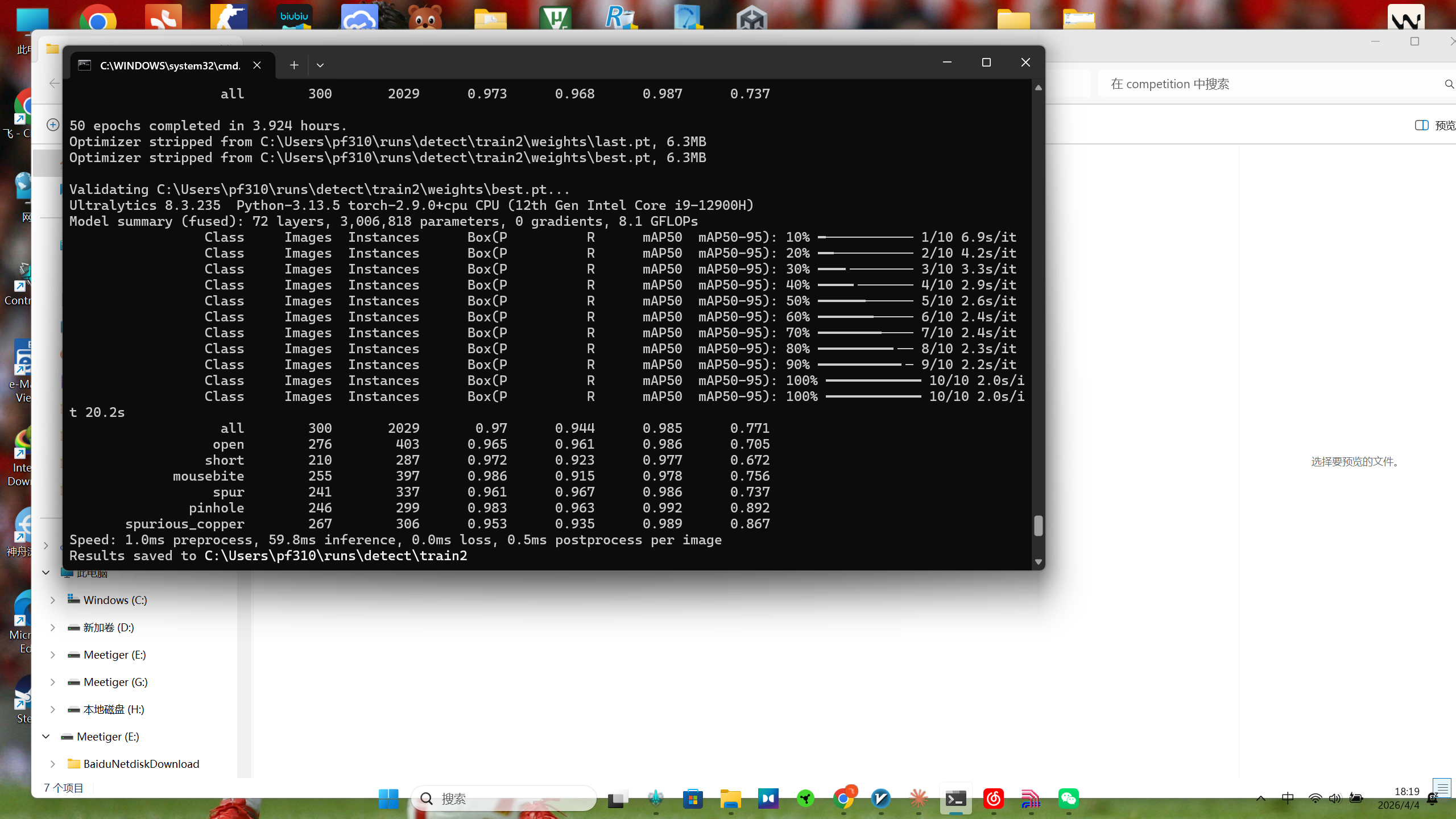
搞定数据后,在本地 CPU 环境(Intel i9-12900H)跑了 50 个 Epoch,耗时大概将近 4 个小时。
最终的验证集指标非常漂亮:
-
总体 mAP50 达到了 98.5%
-
各类缺陷检出率:其中 Pinhole(针孔) 高达 99.2%,最低的 Short(短路) 也有 97.7%。
-
模型体积:仅 6.3MB(8.1 GFLOPs),对于算力有限的嵌入式平台极其友好。
四、 PyQt5 工业级可视化界面集成
为了让系统真正“可用”,我用 PyQt5 写了一个本地 GUI 工具(pcb_demo.py)。逻辑不复杂:上传图片 -> 触发推理 -> 解析检测框 -> 渲染状态。
在实际工业场景中,操作员最关心的就是“良品(PASS)”和“不良品(NG)”。我在代码里对 YOLO 输出的 boxes 做了状态判定:
# 截取 pcb_demo.py 核心推理与告警逻辑片段
results = self.model(img)
boxes = results[0].boxes
# 判断逻辑:如果未检测到任何缺陷框,判定为 PASS
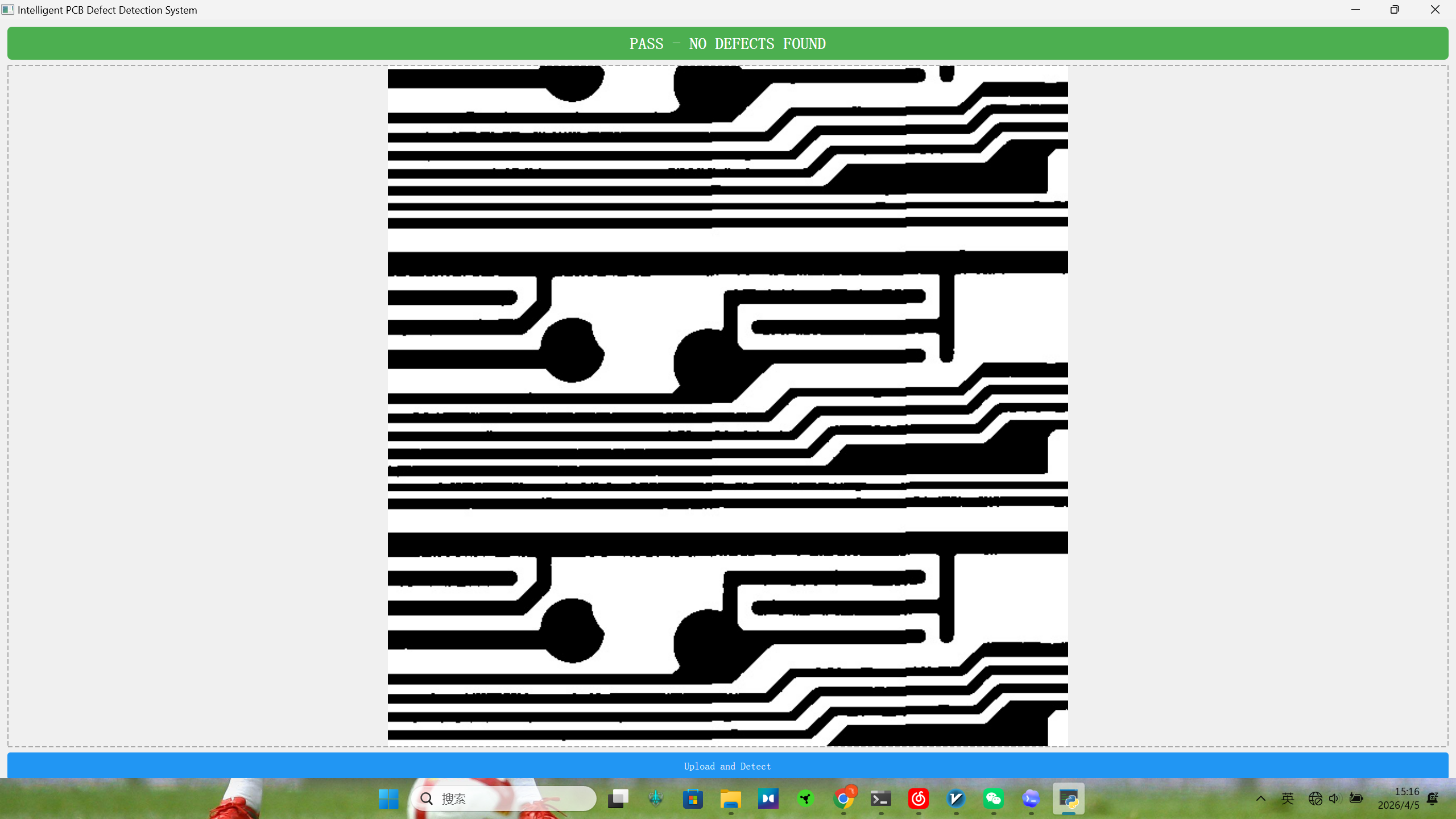
if len(boxes) == 0:
self.status_label.setText("PASS - NO DEFECTS FOUND")
self.status_label.setStyleSheet("font-size: 28px; font-weight: bold; color: white; background-color: #4CAF50; padding: 15px; border-radius: 8px;")
else:
# 提取所有检测到的缺陷种类,去重后拼接到告警字符串中
detected_classes = [self.model.names[int(c)] for c in boxes.cls]
unique_defects = list(set(detected_classes))
defects_str = ", ".join(unique_defects)
self.status_label.setText(f"NG - DEFECT DETECTED: {defects_str.upper()}")
self.status_label.setStyleSheet("font-size: 28px; font-weight: bold; color: white; background-color: #F44336; padding: 15px; border-radius: 8px;")
# 绘制标注框并转换为 Qt 图像显示 (注意 OpenCV 默认 BGR,Qt 需要 RGB)
annotated_img = results[0].plot()
annotated_img = cv2.cvtColor(annotated_img, cv2.COLOR_BGR2RGB)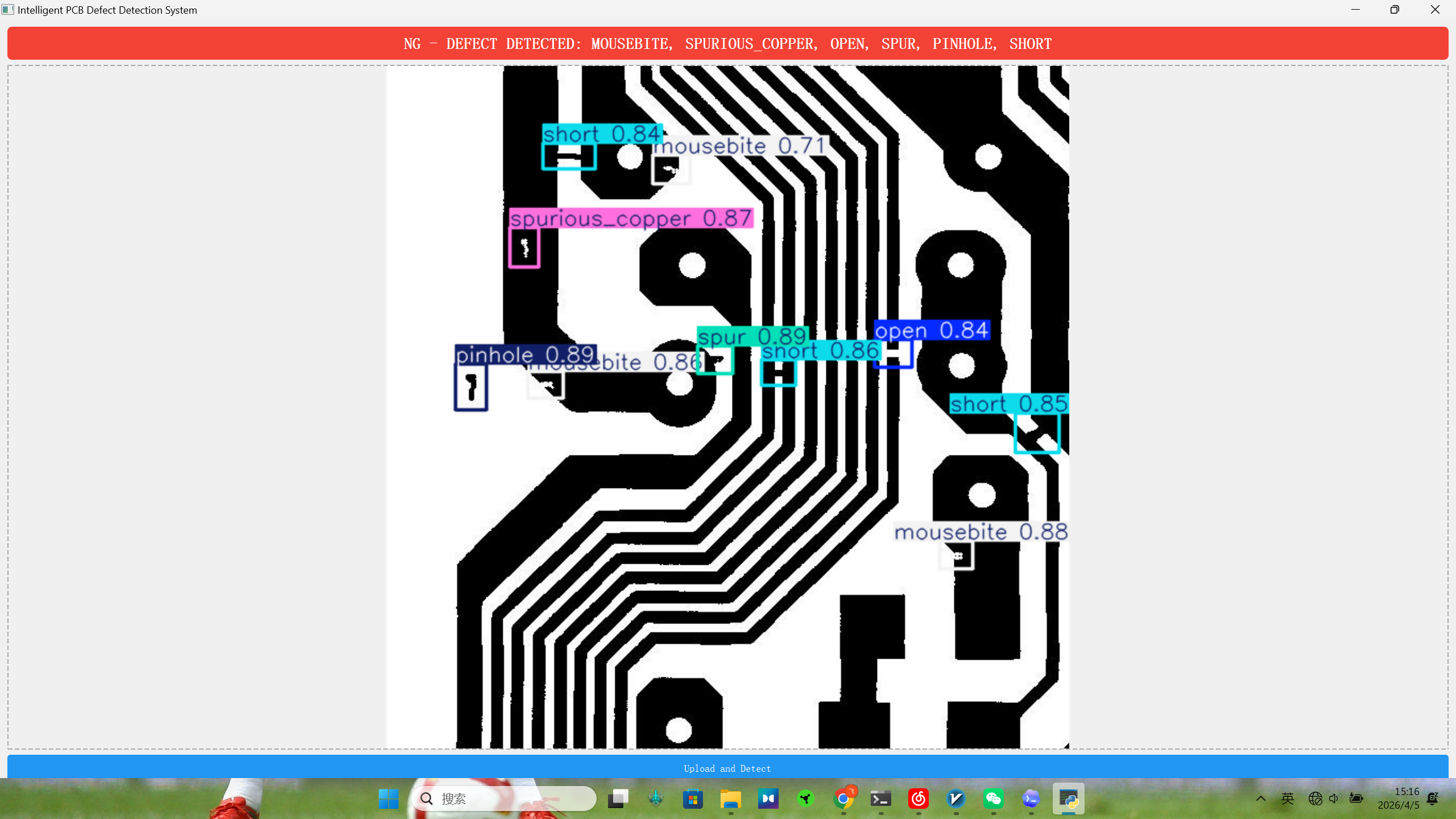
经典踩坑点: 注意倒数第二行代码!OpenCV 读取图片默认是 BGR 格式,而 PyQt 的 QImage 默认吃 RGB 格式。如果不做 cv2.cvtColor 转换,显示出来的画面颜色会像阴间滤镜一样,这在刚开始搞 Python 视觉集成时是必踩的坑。
五、 总结与交流
整个项目走下来,我们完成了从数据集构建清洗 -> 模型训练优化 -> GUI 可视化告警 的全闭环。基于 6.3MB 的轻量化体积,这套模型接下来完全可以部署到边缘计算设备甚至高端的 ARM 核心板上,结合我们熟悉的 C 语言底层驱动,实现真正的“边缘检测 + 产线联动”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)