大模型本地部署与调优
一、本地部署大模型概述
本地部署大模型主要是为了省钱、为了安全和实现离线使用的标准操作。本地部署大模型的运行逻辑是:用户输入提示词->软件(例如:Ollama)加载本地大模型/工具->再返回Token数据,从而避免请求云端大模型,也就省了钱,避免了数据泄露的风险。
二、Ollama软件介绍
ollama名称解析:O我猜是open的意思,llama:羊驼(产于南美)就是那种脖子很长的羊。

说起llama它还有另外一个产品:llama.cpp,所以从名称上看就可以知道,ollama是基于llama.cpp开发而来。而llama.cpp老司机看也可以知道,它是用c/c++写的。而Ollama是用Go(Golang)语言编写,通过CGo的方式,实现Go调用C代码。Ollama主要负责,模型下载、存储、API服务和用户交互,llama.cpp负责模型推理。
三、Ollama软件安装
首先下载Ollama软件(https://ollama.com),现在下来安装即可。安装好后,打开页面http://localhost:11434,如果返回:Ollama is running。就说明安装好了,接下来就是选择大模型了。
显卡内存 小于 8G或者没有显卡 :qwen3.5:0.8b、qwen3.5:2b(也可以选择其他同类(同类型的2、3b的)小模型,如果CPU和内存配置较好,也可以选择8b的模型)
显卡内存8G :qwen3.5:7b、deepseek-r1:8b
显卡内存16G :qwen3.5:14b
显卡内存24G :deepseek-r1:32b
显卡内存32G :qwen3.5:35b
具体命令如下:
ollama list(查看ollama已有大模型列表)
ollama pull qwen3.5:35b(ollama 拉取 大模型qwen3.5:35b)
ollama pull qwen3.5:0.8b
qwen3.5:0.8b的意思是:名称通义千问,版本号3.5,0.8b=8亿参数,b=Billion(十亿)。参数包含如下内容:权重、偏置。
执行这些命令后,便可以Open ollama打开
如果输入提示词后,运行很慢,这个时候就要把模型调低点,再试试效果,最后会找到合适的模型。
四、Ollama软件调优
如果简单换大模型无法解决大模型运行缓慢的问题,主要从这两方面:加显卡和内存和自定义大模型,接下来聊聊怎么自定义大模型,下面是Modelfile的配置:
FROM gemma2:2b
SYSTEM "你是一位医疗顾问助手。请根据用户描述的症状,提供可能的解释和建议,但必须在回答末尾声明:"本信息仅供参考,不能替代专业医生的诊断。如有紧急情况,请立即就医。"保持回答简洁、专业、有同理心。"
PARAMETER temperature 0.3
PARAMETER num_ctx 2048
PARAMETER top_p 0.9
PARAMETER repeat_penalty 1.2
PARAMETER num_predict 500
基础推理参数
| 参数名称 | 取值范围 | 默认值 | 作用简述 |
|---|---|---|---|
| temperature | 0.0 - 1.0 | 0.8 | temperature(温度的意思)值越高越吹牛,越有创造性 |
| top_p | 0.0 - 1.0 | 0.9 | top_p,其中p=Probability(概率),选择高概率词的范围控制 |
| top_k | 整数 (通常 0-100) | 40 | 固定数量的词,比如:前100 |
| repeat_penalty | 1.0 及以上 | 1.1 | 避免重复token出现 |
| stop | 字符串序列 | 无 | 定义终止序列,当输出包含该序列时立即停止生成。 |
性能参数
| 参数名称 | 取值范围 | 默认值 | 作用简述 |
|---|---|---|---|
| num_ctx | 正整数 | 2048 | 设置模型的上下文窗口大小,即它能“记住”的 token 数量。 |
| num_batch | 正整数 | 512 | 控制推理时一次处理的 token 数量,影响 GPU 内存使用和速度。 |
| num_thread | 正整数 | CPU核心数 | 设置用于计算的 CPU 线程数,优化多核 CPU 性能。 |
角色设置参数
| 参数名称 | 取值范围 / 格式 | 默认值 | 作用简述 |
|---|---|---|---|
| SYSTEM | 字符串 | 无 | 设置模型的系统提示词,定义其核心身份和行为准则。 |
| TEMPLATE | 字符串 (含 {{ .Prompt }}) | 模型自带 | 定义对话的模板格式,将用户输入和系统提示组合成最终提示。 |
| PARAMETER mirostat | 0, 1, 2 | 0 (关闭) | 启用一种算法,动态调整温度以保持输出复杂度稳定。 |
模型与模型微调
| 参数/指令 | 取值范围 / 格式 | 默认值 | 作用简述 |
|---|---|---|---|
| FROM | 模型名称 (如 llama3.2) | 必须指定 | 指定构建新模型所基于的父模型,是 Modelfile 的必需指令。 |
| ADAPTER | 文件路径 | 无 | 适配器,针对模型进行微调。例如:LoRA |
注:会有针对LoRA专门的文章
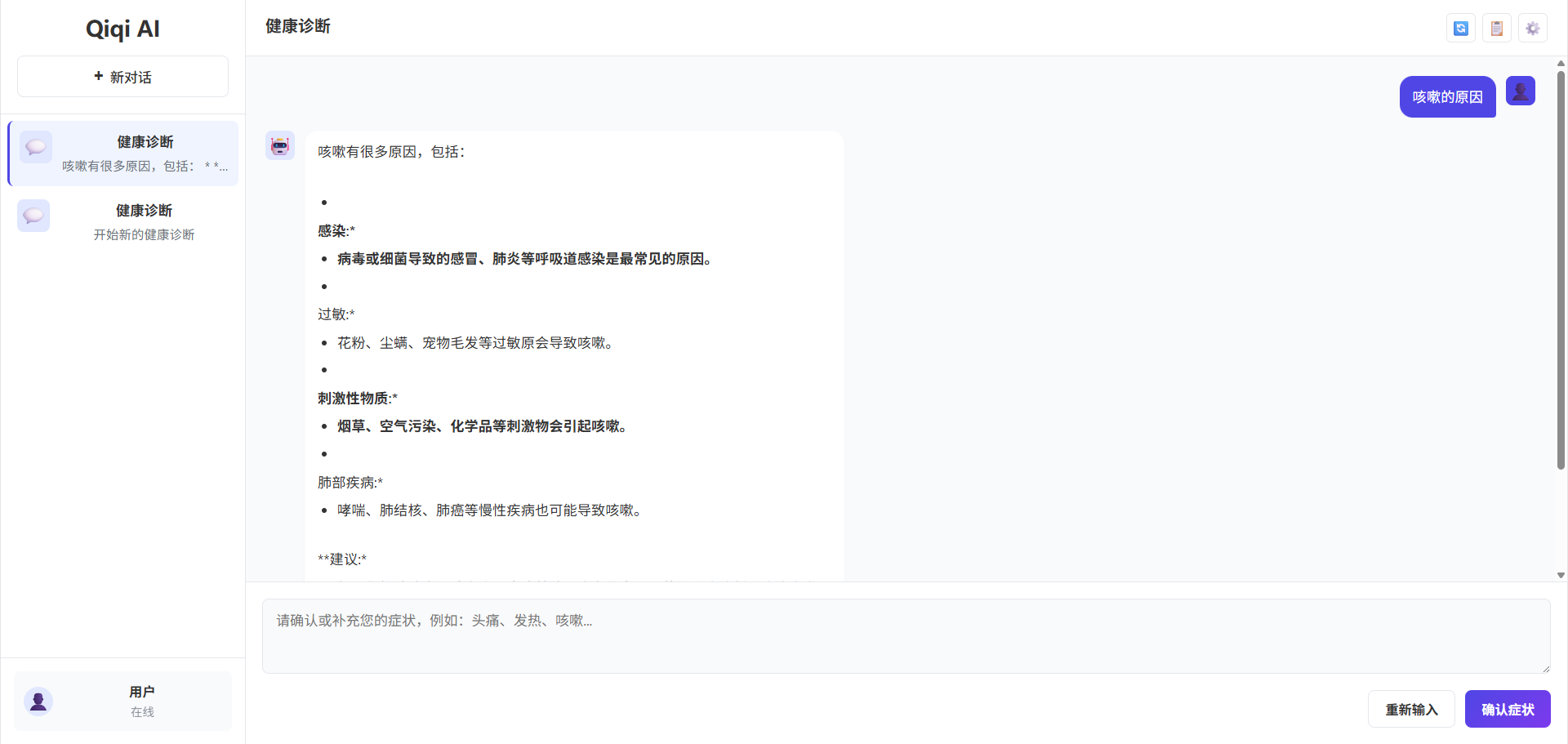
下图是基于此自定义模型开发简单应用
Have a nice day!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)