光伏发电短期功率预测——从数据到模型的完整技术实践(LSTM · TCN · CNN-LSTM · TCN-LSTM)
一、为什么要做光伏功率预测
近年来,光伏、风电等新能源装机规模快速增长,大量分布式光伏电站陆续并入电网。这带来了一个以前不那么突出的问题:电力系统的调度员越来越难干了。
传统的火电、水电出力是可以人工调节的,调度员根据用电负荷预报安排发电计划,整个系统能保持功率平衡。但光伏不一样——它完全靠天吃饭,云层飘过来就掉功率,晴转阴可能几分钟内出力跌掉一半。当光伏占比足够高的时候,这种波动就不是小事了,会直接影响电网频率稳定。
短期功率预测,就是在这个背景下诞生的核心技术需求。预测未来几小时的光伏出力,可以让调度员提前知道大概要从别的电源补多少功率,提前安排储能或调峰机组,从而减少甩负荷或弃光的概率。预测精度每提升一个百分点,背后节省的备用容量费用和弃光损失都是实实在在的经济效益。

本文聚焦短期多步预测这个更贴近实际调度需求的场景——给定过去24小时的气象和功率数据,一次性预测未来6小时的功率序列。这比逐点预测难得多,因为误差会累积,而且不同步的相关性需要模型同时捕捉。
二、数据集:PVDAQ 2012-2014
2.1 数据集简介
本研究使用的是 PVDAQ(Photovoltaic Data Acquisition)公开数据集,来源于美国国家可再生能源实验室(NREL)的实地测量项目。数据集包含一套光伏发电站从 2012 年到 2014 年的逐小时记录,时间跨度约三年,总行数超过两万条。
原始数据包含以下字段:
| 数据名称 | 输入/标签 | 说明 |
|---|---|---|
| ac_current | — | 交流电流 |
| ac_power | — | 交流功率 |
| ac_voltage | — | 交流电压 |
| ambient_temp | 输入 | 环境温度 |
| dc_current | — | 直流电流 |
| dc_power | 标签 | 直流功率(预测目标) |
| dc_voltage | — | 直流电压 |
| inverter_error_code | — | 逆变器故障码 |
| inverter_temp | 输入 | 逆变器温度 |
| module_temp | 输入 | 模块温度 |
| poa_irradiance | 输入 | 阵列面辐照度 |
| power_factor | — | 功率因数 |
| relative_humidity | 输入 | 相对湿度 |
| wind_direction | 输入 | 风向 |
| wind_speed | 输入 | 风速 |
我们在此基础上还引入了两个时间特征:hour(当前小时,0~23)和 month(当前月份,1~12)。这两个特征看起来简单,但对光伏预测非常有价值——光伏本质上有强烈的日周期性(正午最强、早晚最弱)和季节性(夏季比冬季强),显式告诉模型现在几点和现在几月,能帮它更快学到这些规律。
2.2 数据的基本特征
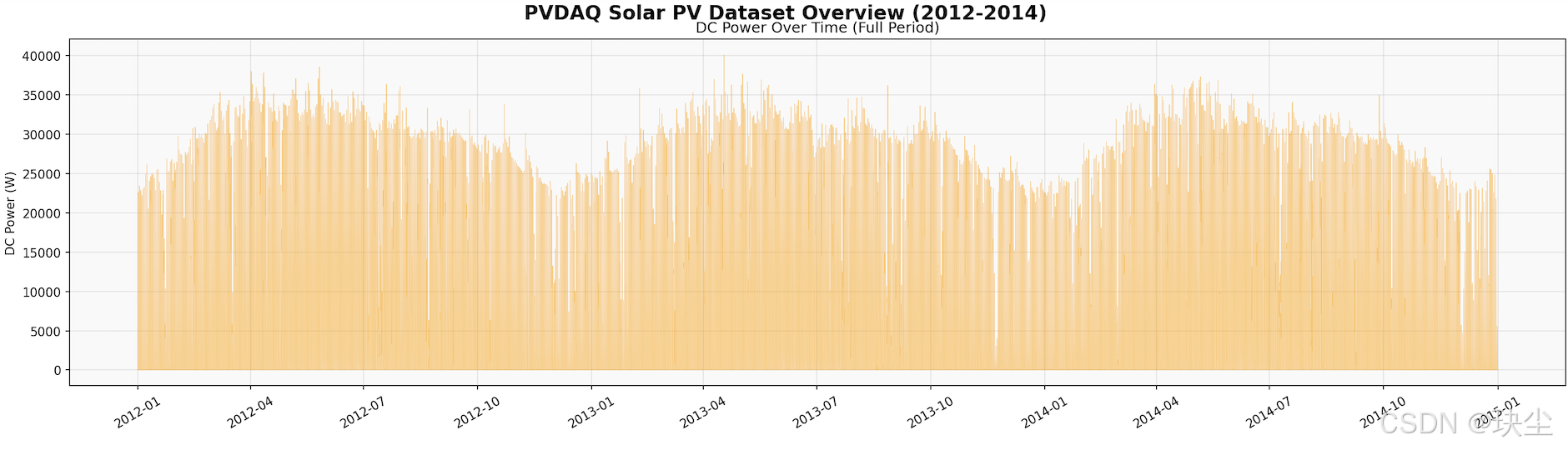
先看整体出力时序。数据在时间轴上呈现明显的周期性:每天白天有一个山峰形的出力曲线,夜间为零。这种结构非常规则,但受云量、季节、温度影响,每天的峰值和形状都有差异,这正是预测的难点所在。
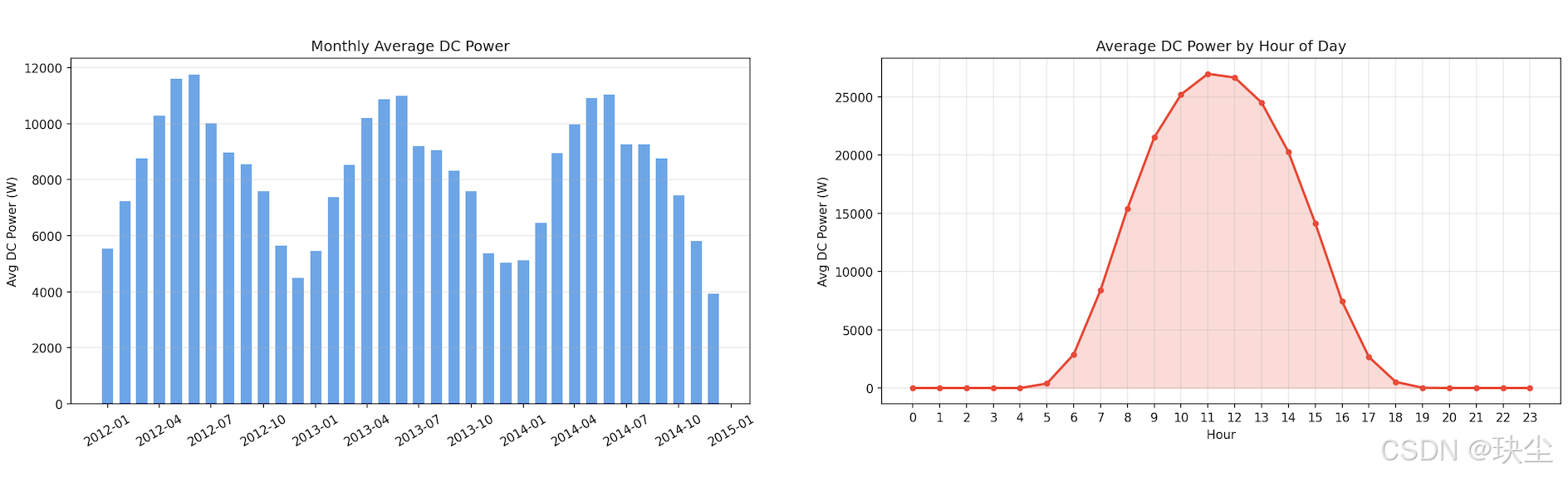
从月均功率来看,夏季(6-8月)明显高于冬季(12-2月),这与太阳高度角和日照时长的季节性变化完全吻合:
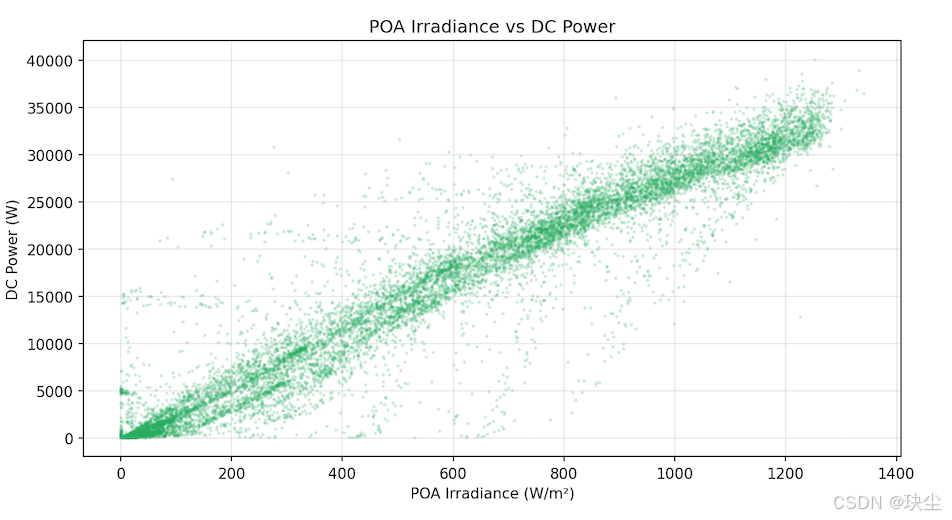
最能说明问题的是 POA 辐照度和 DC 功率的散点图——两者高度正相关,几乎是线性关系。这意味着辐照度是预测功率最强的特征,其他气象变量起到修正作用(比如温度会影响组件效率,高温反而会略降低功率):
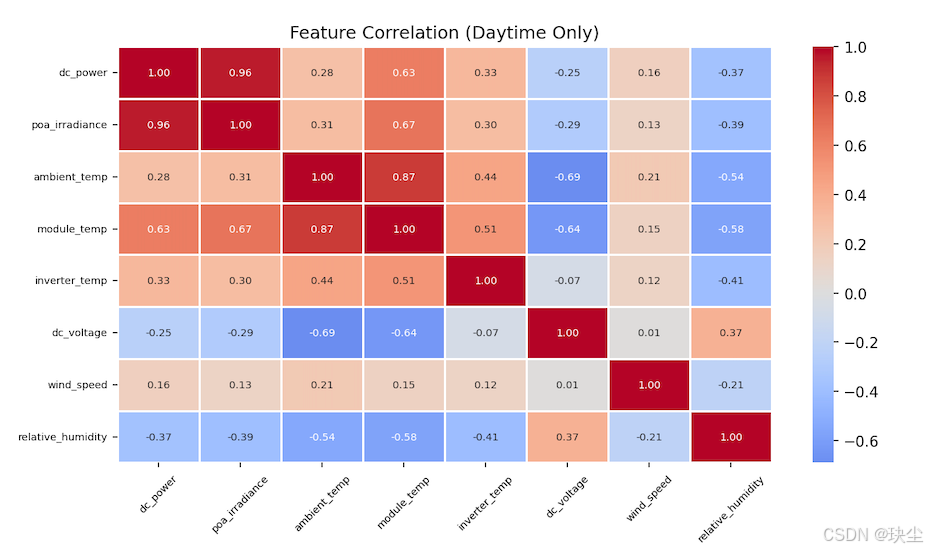
从热力图可以看出,poa_irradiance 与 dc_power 的相关系数高达 0.96,几乎是线性关系,是预测功率最核心的驱动变量。module_temp 和 ambient_temp 也有一定正相关(0.63 和 0.28),但这更多是"辐照强时组件被晒热"的伴随效应,而非温度本身在提升功率——物理上高温反而会拉低转换效率。dc_voltage 呈负相关(-0.25),符合硅基电池高温下开路电压下降的物理规律。wind_speed 和 relative_humidity 与 dc_power 的直接相关性较低,但风冷有助于降低组件温度、湿度反映天气状态,二者仍具备一定的物理意义,因此保留在输入特征中。总体来看,单靠辐照度就能捕捉功率变化的主体趋势,其余特征起修正作用,多特征联合输入有助于进一步降低预测残差。
💡 dc_voltage 不建议作输入特征的理由:
在电路上,dc_power = dc_voltage × dc_current,dc_voltage本身就是计算dc_power的组成部分。用它来预测dc_power属于数据泄露——相当于用答案的一部分去预测答案。
2.3 数据处理的几个细节
-
夜间负值修正:原始数据中夜间
dc_power偶尔出现负值(通常是逆变器待机功耗导致的测量误差),这些值在物理上不合理,统一修正为 0。 -
归一化时机:数据归一化放在构造滑动窗口样本之前,而不是之后。这个顺序很重要——如果先切样本再归一化,每个样本的归一化参数不同,会引入数据泄漏问题。正确做法是先在整段原始序列上统一 fit,记住全局的最大最小值,再 transform,最后才切窗口:
scaler = MinMaxScaler() dataset_scaled = scaler.fit_transform(dataset) # 先归一化 X, y = split_sequence_multi(dataset_scaled, ...) # 再切窗口 -
归一化反变换:评估指标要在原始量纲(瓦特)下计算,才有实际物理意义。模型预测的是归一化后的值,需要用 scaler 反变换回来。注意 MinMaxScaler 是对整个特征矩阵(10列)做的,反变换时需要填充一个同维度的 dummy 矩阵,只把目标列(最后一列)还原。
三、代码实现:从原始数据到可训练样本
3.1 项目结构
整个项目采用模块化设计,各模块职责清晰,互相解耦:
| 文件 | 职责 |
|---|---|
| data_utils.py | 数据加载、特征构造、滑动窗口切分、数据集划分 |
| model_zoo.py | 所有模型定义与注册表 |
| trainer.py | 训练、评估、绘图、保存的统一封装 |
| metrics.py | MAE、RMSE、sMAPE、R²的计算 |
| plot_utils.py | 训练曲线、预测曲线绘制 |
| run_experiment.py | 交互式实验入口 |
3.2 数据加载与特征构造
load_dataset 函数负责把 CSV 读进来,按固定顺序拼成一个 numpy 矩阵。这个顺序很关键,因为后续的归一化和反归一化都依赖最后一列是 dc_power 这个约定。
def load_dataset(csv_path: str) -> np.ndarray:
df = pd.read_csv(csv_path, parse_dates=['Date-Time'], index_col=['Date-Time'])
# 7项气象特征
feature_cols = [
'ambient_temp', 'inverter_temp', 'module_temp',
'poa_irradiance', 'relative_humidity',
'wind_direction', 'wind_speed',
]
# 目标功率标签
target_col = 'dc_power'
seqs = [df[col].values.reshape(-1, 1) for col in feature_cols]
# 2项时间特征
seqs.append(df.index.hour.values.reshape(-1, 1))
seqs.append(df.index.month.values.reshape(-1, 1))
# 目标列:负值修正为 0(夜间功率)
power = df[target_col].values.reshape(-1, 1)
power[power < 0] = 0
seqs.append(power)
return np.hstack(seqs)
接下来是构造多步预测样本的核心函数 split_sequence_multi。这是监督学习化时序数据的标准做法,也叫滑动窗口法(Sliding Window):
def split_sequence_multi(sequence: np.ndarray,
n_steps: int,
n_steps_out: int):
X, y = [], []
for i in range(len(sequence)):
end_ix = i + n_steps
out_ix = end_ix + n_steps_out
if out_ix > len(sequence):
break
# X:过去 n_steps 步的所有特征
X.append(sequence[i:end_ix, :])
# y:紧接着的 n_steps_out 步的功率(最后一列)
y.append(sequence[end_ix:out_ix, -1])
# X.shape: (samples, 24, 10)
# y.shape: (samples, 6)
return np.array(X), np.array(y)
每个训练样本 X[i]X[i]X[i] 是一个形状为 (24, 10) 的矩阵——24个时间步,每步10个特征;对应的标签 y[i]y[i]y[i] 是接下来6小时的功率序列。模型的任务就是学习从 XXX 到 yyy 的映射。
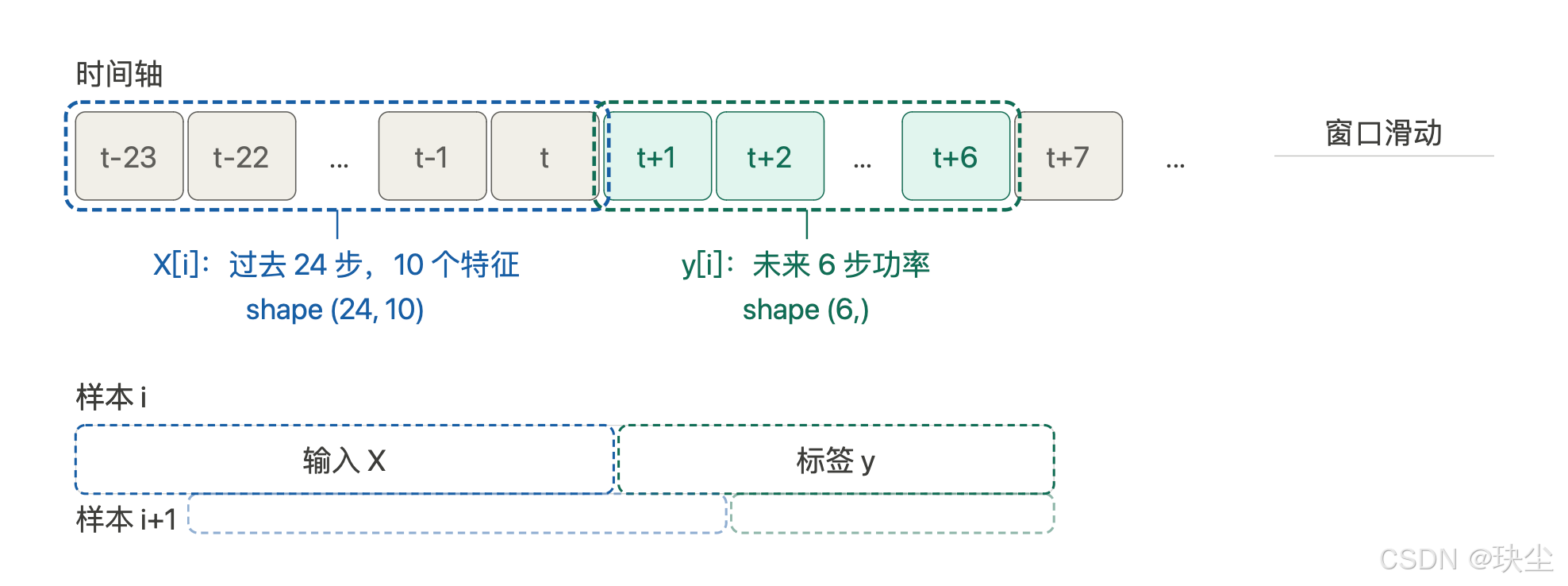
3.3 数据集划分策略
prepare_data 是对外的一站式接口,封装了归一化、窗口切分、数据打乱、集划分全过程:
def prepare_data(csv_path, n_steps=24, n_steps_out=6,
num_val=5000, num_test=5000,
shuffle=True, random_seed=42):
dataset = load_dataset(csv_path)
# ① 归一化(在切窗口之前做)
scaler = MinMaxScaler()
dataset_scaled = scaler.fit_transform(dataset)
# ② 构造滑动窗口
X, y = split_sequence_multi(dataset_scaled, n_steps, n_steps_out)
# ③ 整体打乱
if shuffle:
rng = np.random.default_rng(random_seed)
idx = rng.permutation(len(X))
X, y = X[idx], y[idx]
# ④ 按位置切分
train_X = X[:-(num_val + num_test)]
train_y = y[:-(num_val + num_test)]
val_X = X[-(num_val + num_test):-num_test]
val_y = y[-(num_val + num_test):-num_test]
test_X = X[-num_test:]
test_y = y[-num_test:]
print(f"[数据] train={train_X.shape}, val={val_X.shape}, test={test_X.shape}")
return dict(
train_X=train_X, train_y=train_y,
val_X=val_X, val_y=val_y,
test_X=test_X, test_y=test_y,
n_features=X.shape[2],
scaler=scaler, # ← 传出去用于反归一化
)
划分结果:训练集 16275 条、验证集 5000 条、测试集 5000 条。验证集用于 EarlyStopping 和学习率调整,测试集只在最终评估时使用一次。

四、模型设计:六种架构的对比实验
4.1 统一训练配置
为了让不同模型的对比有意义,所有模型使用完全相同的训练超参数配置。这是工程上非常重要的规范——如果 LSTM 用了 50 个 epoch 而 TCN 只用了 10 个,结果就没有可比性了。
| 超参数 | 设置值 | 说明 |
|---|---|---|
| 输入时间步长 n_steps | 24 | 用过去 24 小时数据 |
| 预测步长 n_steps_out | 6 | 预测未来 6 小时 |
| 学习率 | 0.001 | AdamW 优化器初始值 |
| 批大小 batch_size | 32 | — |
| 最大训练轮数 epochs | 50 | EarlyStopping 提前终止 |
| 早停容忍轮数 patience | 8 | 监控 val_loss |
| 学习率衰减 ReduceLR | 触发时 × 0.5 | min_lr = 1e-6 |
| 损失函数 | MAE | 对异常值更鲁棒 |
| 输入特征数 | 10 | 7气象 + 小时 + 月份 + 功率 |
4.2 基准模型:三种 LSTM 变体
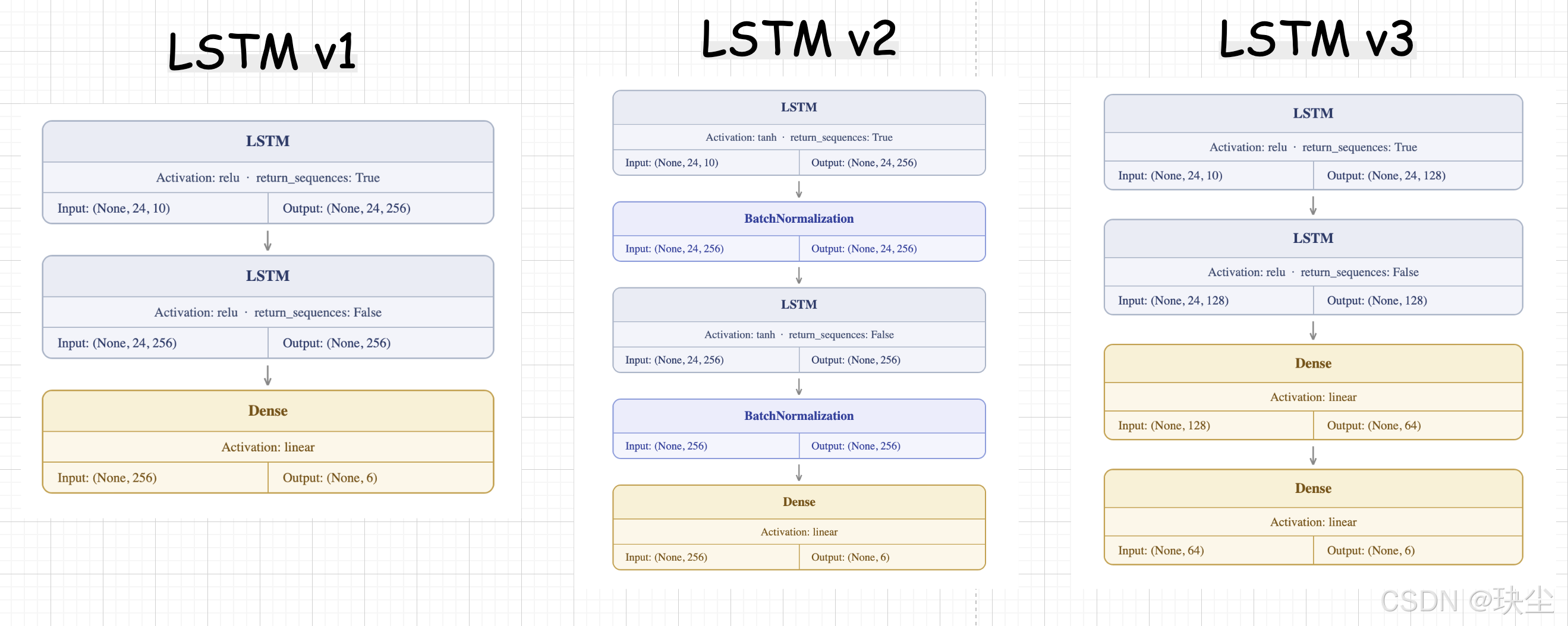
LSTM v1 —— 最简基线
两层 LSTM(每层 256 个单元,ReLU 激活),末接一个 Dense(6) 输出层。不含任何正则化手段,是其他模型的比较起点。输入之前加了 GaussianNoise(0.01) 层,相当于在数据层面做了一点正则化——训练时给输入加微小噪声,让模型不那么依赖精确的输入值,有助于泛化。
def build_lstm_v1(n_steps, n_features, n_steps_out):
"""
LSTM v1:双层 LSTM,无 BatchNorm
"""
model = Sequential([
GaussianNoise(0.01, input_shape=(n_steps, n_features)),
LSTM(256, activation='relu', return_sequences=True),
LSTM(256, activation='relu'),
Dense(n_steps_out),
], name='lstm_v1')
return model
LSTM v2 —— 加入 BatchNormalization
在每层 LSTM 后插入 BatchNormalization,激活函数换成 tanh。BatchNorm 的作用是对每一层的输出做标准化,加速收敛、缓解梯度问题。
但在本实验中,LSTM v2 的表现反而是所有模型里最差的——MAE 达到 1124.86,远高于其他模型。这是一个很有意思的反常结果,后面的实验分析部分会专门讨论原因。
def build_lstm_v2(n_steps, n_features, n_steps_out):
"""
LSTM v2:双层 LSTM + BatchNormalization
"""
model = Sequential([
GaussianNoise(0.01, input_shape=(n_steps, n_features)),
LSTM(256, activation='tanh', return_sequences=True),
BatchNormalization(),
LSTM(256, activation='tanh'),
BatchNormalization(),
Dense(n_steps_out, activation='linear'),
], name='lstm_v2')
return model
LSTM v3 —— 维度递减的轻量结构
把 LSTM 单元数缩减到 128,并在输出端用两层 Dense(128→64→6)逐步压缩。这个设计的出发点是:用更少的参数,通过多层映射来实现输出,探索轻量化结构的上限。
def build_lstm_v3(n_steps, n_features, n_steps_out):
"""
LSTM v3:双层 LSTM + 两个 Dense 层(维度递减)
"""
model = Sequential([
GaussianNoise(0.01, input_shape=(n_steps, n_features)),
LSTM(128, activation='relu', return_sequences=True),
LSTM(128, activation='relu'),
Dense(64, activation='linear'),
Dense(n_steps_out, activation='linear'),
], name='lstm_v3')
return model
4.3 基准模型:TCN(时序卷积网络)
TCN(Temporal Convolutional Network)是近年来在时序建模领域挑战 LSTM 统治地位的另一类架构。它的核心是膨胀因果卷积(Dilated Causal Convolution):
「因果」意味着卷积核只能看到当前和过去的时间步,不能看到未来——这是时序预测的基本物理约束。「膨胀」意味着随着层数增加,卷积的感受野指数级扩大,较深的层可以捕捉很长的时间依赖,而且计算是并行的,不像 LSTM 需要逐步展开。
本实验中 TCN 的配置:64 个卷积核,核大小 7,膨胀因子序列 [1, 2, 4, 8],dropout 率 0.5。感受野 = (7-1) × (1+2+4+8) + 1 = 91,覆盖了约 91 个时间步,远超输入长度 24,理论上感受野是够用的。
初始实验中dropout设置偏高(0.5),导致训练阶段loss虚高。后续已调整为0.1,两条曲线趋于一致,结果更具参考价值。
def build_tcn(n_steps, n_features, n_steps_out):
"""
TCN:时序卷积网络(膨胀因果卷积)
"""
from models.tcn import TCN as TCNLayer
model = Sequential([
GaussianNoise(0.01, input_shape=(n_steps, n_features)),
TCNLayer(64, 7, dilations=[1, 2, 4, 8], dropout_rate=0.5),
Dense(n_steps_out),
], name='tcn')
return model
4.4 改进模型:CNN-LSTM
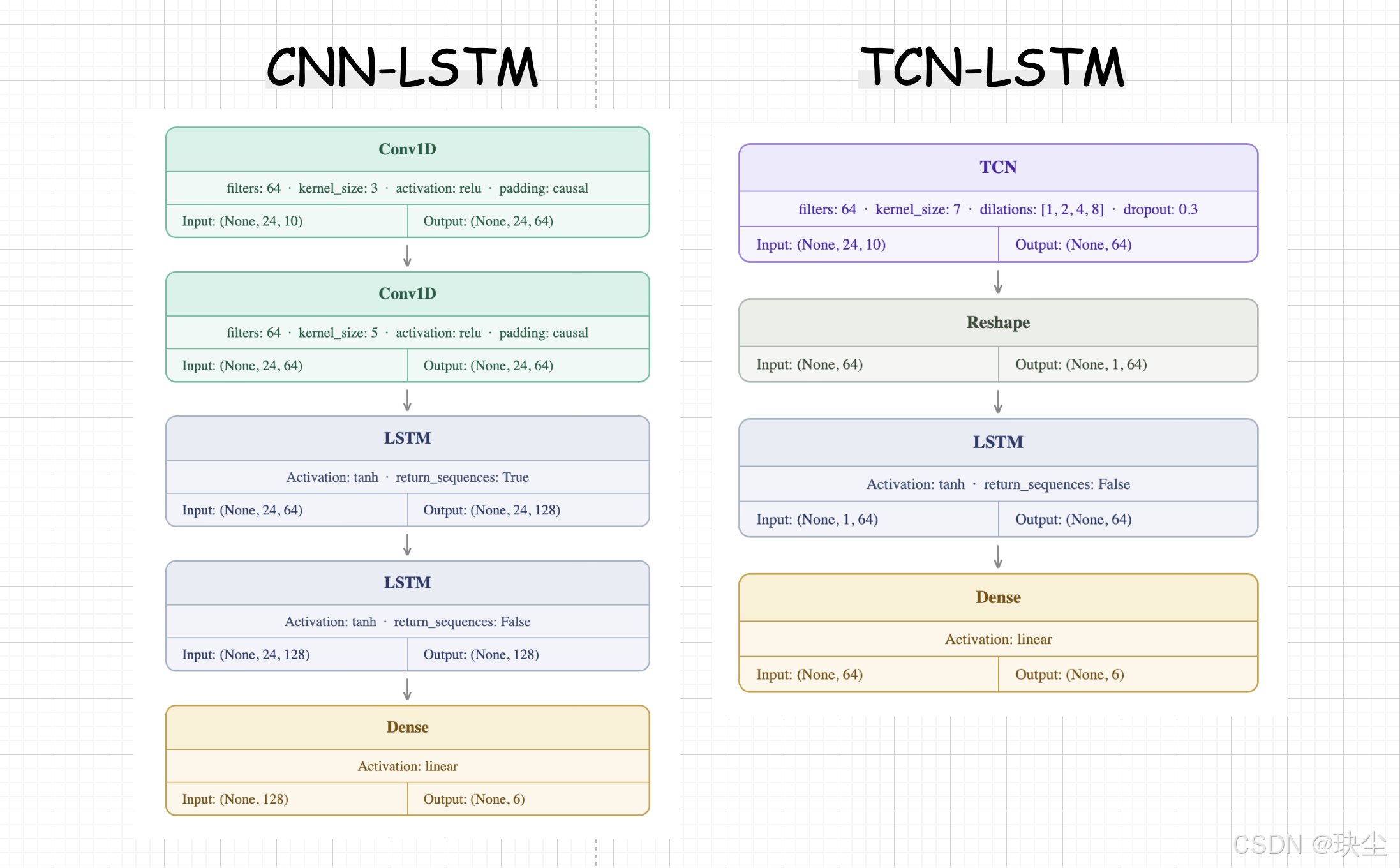
CNN-LSTM 是本研究中最有工程直觉的混合架构。它的思路是:局部短期模式 + 全局长期依赖,分两阶段处理。
第一阶段,两层 Conv1D(filters=64,kernel_size 分别为 3 和 5,因果填充,ReLU 激活)扫描输入序列,提取局部时序特征——比如辐照度的快速上升、温度的日变化斜率等。
第二阶段,LSTM(128→128 单元,tanh 激活)在卷积输出的特征图上建模更长程的时序依赖,整合全天的演变规律。
def build_cnn_lstm(n_steps, n_features, n_steps_out):
"""
CNN-LSTM:1D 卷积提取局部模式 → LSTM 建模长期依赖
Conv1D 负责捕捉短期局部特征(如日内辐照变化),
LSTM 负责捕捉跨小时的长期时序依赖。
"""
model = Sequential([
GaussianNoise(0.01, input_shape=(n_steps, n_features)),
# 局部特征提取
Conv1D(filters=64, kernel_size=3, activation='relu', padding='causal'),
Conv1D(filters=64, kernel_size=5, activation='relu', padding='causal'),
LSTM(128, activation='tanh', return_sequences=True),
LSTM(128, activation='tanh', return_sequences=False),
Dense(n_steps_out),
], name='cnn_lstm')
return model
4.5 改进模型:TCN-LSTM
TCN-LSTM 走的是另一条路:先用 TCN 的膨胀卷积做多尺度特征提取,再用 LSTM 精细建模顺序依赖。
TCN 在这里扮演特征提取器的角色,输出一个固定长度的 64 维向量,代表整段输入序列的时序特征摘要。然后经 Reshape 变成 (1, 64) 的单步序列送进 LSTM,让 LSTM 在这个压缩表示上做进一步的顺序推理。
def build_tcn_lstm(n_steps, n_features, n_steps_out):
"""
TCN-LSTM:TCN 多尺度时序特征提取 → LSTM 精细建模
TCN 的膨胀卷积覆盖多尺度感受野,
LSTM 在 TCN 输出的特征序列上进一步捕捉顺序依赖。
"""
model = Sequential([
GaussianNoise(0.01, input_shape=(n_steps, n_features)),
# TCN 输出保持时序维度(return_sequences=True 等效,TCN 默认输出 (batch, features))
# 此处用 TCN 输出 + Reshape 再接 LSTM
TCNLayer(64, 7, dilations=[1, 2, 4, 8], dropout_rate=0.3),
# TCN 输出为 (batch, 64),reshape 为 (batch, 1, 64) 后接 LSTM
Reshape((1, 64)),
LSTM(64, activation='tanh'),
Dense(n_steps_out),
], name='tcn_lstm')
return model
4.6 模型注册表:优雅的管理方式
所有模型都注册在一个字典里,通过名字字符串就能获取对应的构建函数。这个设计让实验脚本非常干净——run_experiment.py 不需要知道每个模型的具体实现,只需要传一个名字:
MODEL_REGISTRY = {
# 基准模型
'lstm_v1': build_lstm_v1,
'lstm_v2': build_lstm_v2,
'lstm_v3': build_lstm_v3,
'tcn': build_tcn,
# 改进模型
'cnn_lstm': build_cnn_lstm,
'tcn_lstm': build_tcn_lstm,
}
五、训练器:把训练流程标准化
5.1 为什么需要封装训练器
如果没有统一的 Trainer 类,跑六个模型就要写六段几乎相同的训练代码,不仅冗余,而且一旦要改某个设置(比如把 patience 从 5 改到 8),需要改六个地方,很容易出错。Trainer 类把所有重复的逻辑封装成可复用的方法,主程序只需要三行就能完成一个模型从编译到保存的全流程。
5.2 编译阶段
优化器使用的是 AdamW,而不是普通的 Adam。两者的区别在于 AdamW 把 L2 正则化(权重衰减)从梯度更新中解耦出来,单独处理,理论上对正则化的效果更准确。weight_decay 默认设为 1e-4。
def compile(self):
self.model.compile(
optimizer=AdamW(learning_rate=self.cfg['learning_rate'],
weight_decay=self.cfg.get('weight_decay', 1e-4)),
loss=self.cfg['loss'],
)
return self
5.3 训练策略:Early Stopping + ReduceLR
训练过程中同时启用两个 Keras 回调:
- EarlyStopping:监控验证集 loss,连续 patience=8 轮无改善就停止训练,并自动恢复到历史最优权重。这是防止过拟合最直接有效的手段。
- ReduceLROnPlateau:验证集 loss 停滞时自动把学习率乘以 0.5,最低降到 1e-6。这让模型在卡平台时能更精细地寻优,而不是在较大步长下来回震荡。
def fit(self, train_X, train_y, val_X, val_y):
callbacks = []
if self.cfg['early_stopping']:
callbacks.append(EarlyStopping(
monitor='val_loss', patience=self.cfg['patience'],
restore_best_weights=True, verbose=1,
))
if self.cfg['reduce_lr']:
callbacks.append(ReduceLROnPlateau(
monitor='val_loss', factor=0.5,
patience=max(2, self.cfg['patience'] // 2),
min_lr=1e-6, verbose=1,
))
self.history = self.model.fit(
train_X, train_y,
batch_size=self.cfg['batch_size'],
epochs=self.cfg['epochs'],
validation_data=(val_X, val_y),
callbacks=callbacks,
verbose=1,
)
return self
5.4 评估阶段与反归一化
评估时,模型输出的是归一化空间里的预测值,需要先反变换到原始量纲再计算指标。这里有一个容易踩的坑:MinMaxScaler 是在 10 维特征上 fit 的,反变换需要 10 维输入。解决方案是构造一个全零的 dummy 矩阵,把预测值填到最后一列(功率列),然后 inverse_transform,取回最后一列。
def _inverse_power(scaler, y_scaled: np.ndarray) -> np.ndarray:
"""将归一化后的功率列还原到原始量纲(只还原最后一列)"""
y_flat = y_scaled.ravel()
dummy = np.zeros((len(y_flat), scaler.n_features_in_))
dummy[:, -1] = y_flat
return scaler.inverse_transform(dummy)[:, -1].reshape(y_scaled.shape)
六、评估指标体系
模型好不好,要用数字说话。本研究采用四项核心指标,从不同角度衡量预测精度:
| 指标 | 公式含义 | 越好的方向 | 特点 |
|---|---|---|---|
| MAE(平均绝对误差) | 预测误差绝对值的平均 | 越小越好 | 对异常值不敏感,直观反映平均偏差幅度 |
| RMSE(均方根误差) | 误差平方均值的开方 | 越小越好 | 对大误差惩罚更重,反映极端偏差 |
| sMAPE(对称MAPE) | 对称处理的相对误差 | 越小越好 | 避免真实值为0时除零,适合含零值的功率序列 |
| R²(决定系数) | 解释方差比例 | 越接近1越好 | 反映模型对数据变化趋势的捕捉能力 |
sMAPE 的定义稍微特殊,值得单独解释。传统 MAPE 定义为:
MAPE=1n∑i=1n∣ypred−ytrue∣∣ytrue∣MAPE = \frac{1}{n}\sum_{i=1}^{n}\frac{|y_{pred} - y_{true}|}{|y_{true}|}MAPE=n1i=1∑n∣ytrue∣∣ypred−ytrue∣
当 ytruey_{true}ytrue 接近 0(夜间光伏功率为零)时,分母趋零导致指标失控。sMAPE 将分母替换为真实值与预测值的均值,对两者对等处理,数值更稳定:
sMAPE=1n∑i=1n2∣ypred−ytrue∣∣ytrue∣+∣ypred∣sMAPE = \frac{1}{n}\sum_{i=1}^{n}\frac{2|y_{pred} - y_{true}|}{|y_{true}| + |y_{pred}|}sMAPE=n1i=1∑n∣ytrue∣+∣ypred∣2∣ypred−ytrue∣
def smape(y_true: np.ndarray, y_pred: np.ndarray) -> float:
"""对称平均绝对百分比误差 (sMAPE)"""
return float(np.mean(
2 * np.abs(y_pred - y_true) / (np.abs(y_true) + np.abs(y_pred) + 1e-8)
))
七、实验结果与分析
7.1 定量指标对比
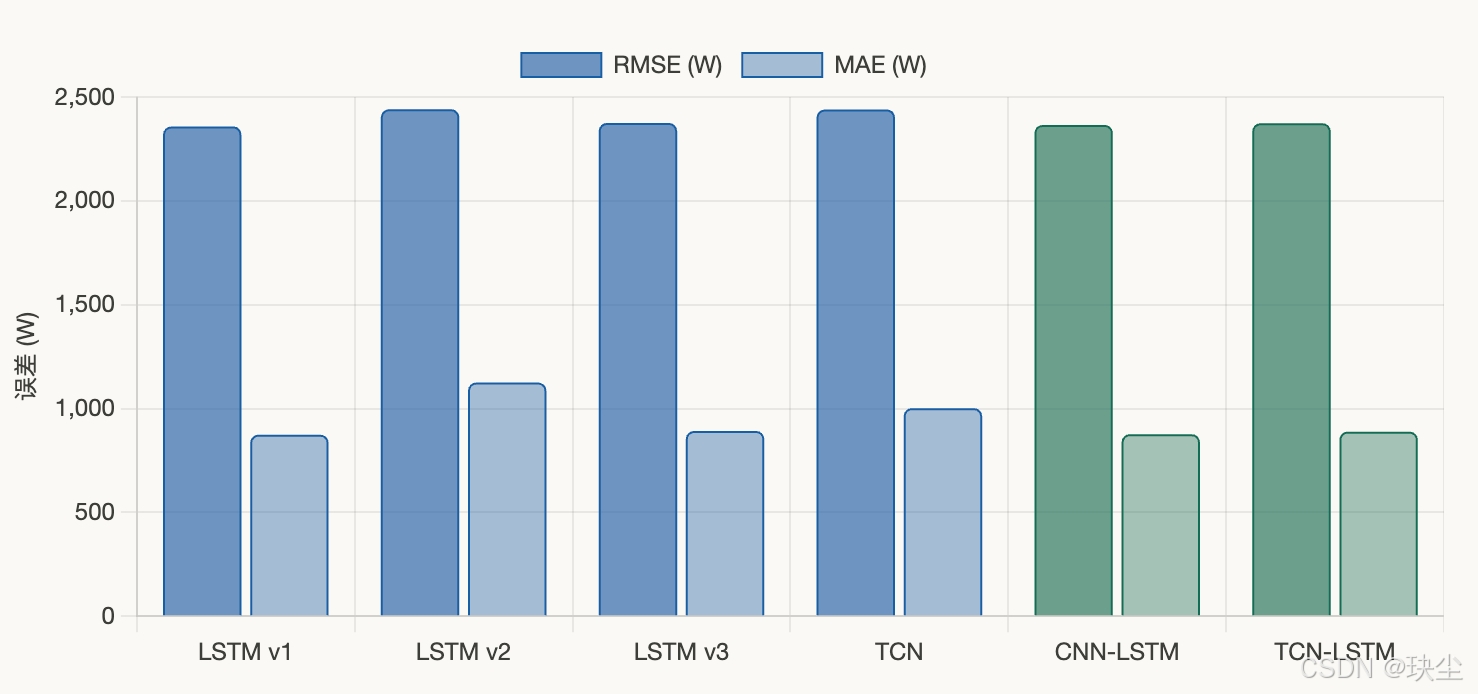
六个模型在测试集(5000 条样本)上的评估指标如下:
| 模型 | RMSE (W) | MAE (W) | 类型 |
|---|---|---|---|
| LSTM v1 | 2358.10 | 873.69 | 基准 |
| LSTM v2 | 2441.05 | 1124.86 | 基准(最差) |
| LSTM v3 | 2374.98 | 891.75 | 基准 |
| TCN | 2439.66 | 1001.51 | 基准 |
| CNN-LSTM | 2365.52 | 876.30 | 改进 |
| TCN-LSTM | 2373.55 | 888.48 | 改进 |
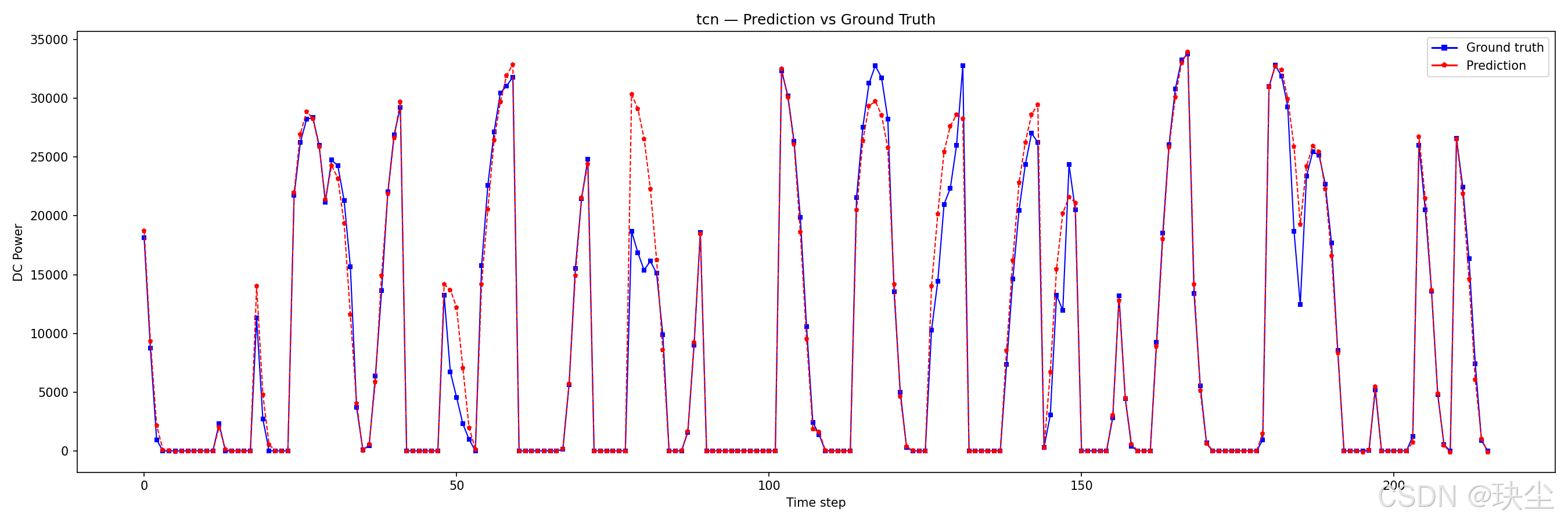
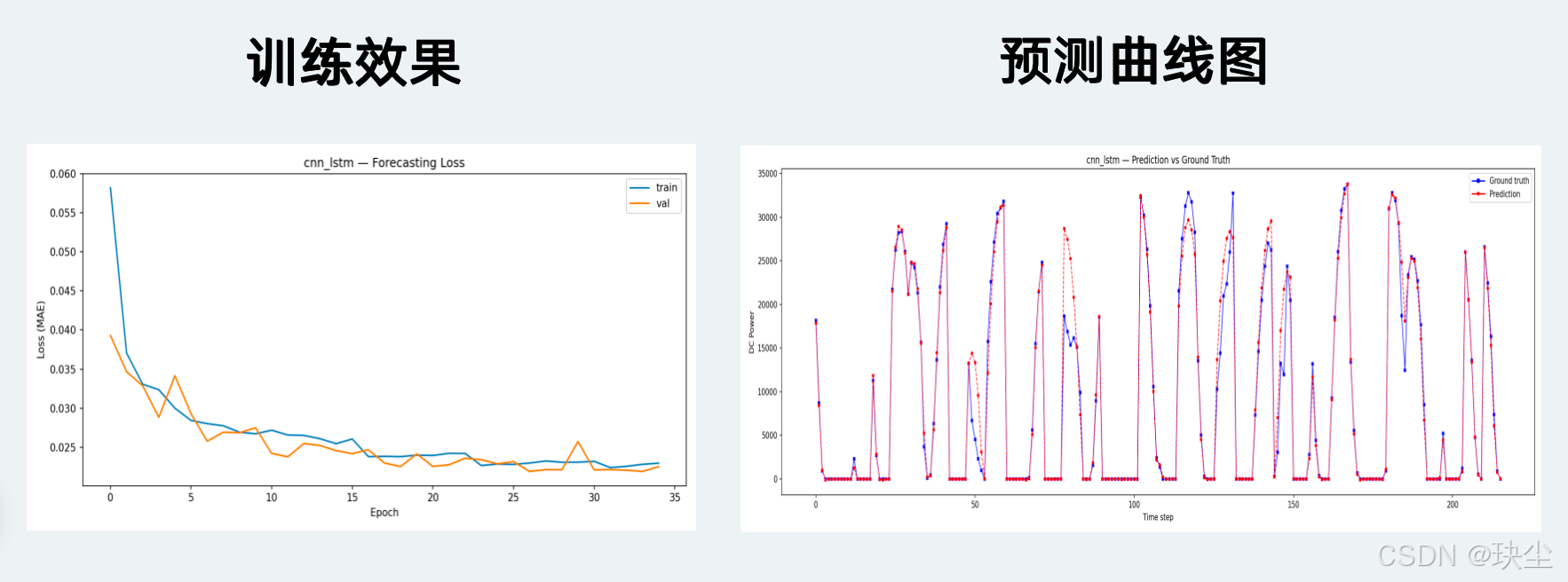
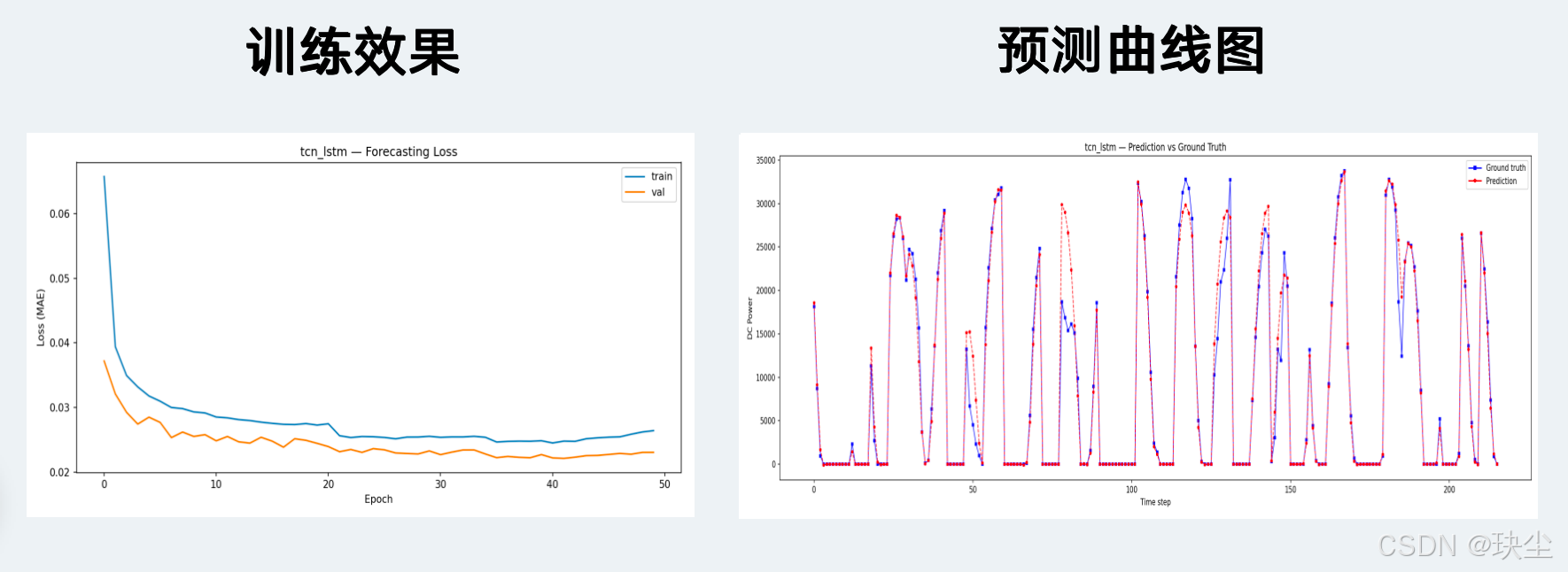
7.2 模型预测曲线对比
下图为六个模型的训练/验证 loss 曲线与测试集预测曲线。
LSTM v1
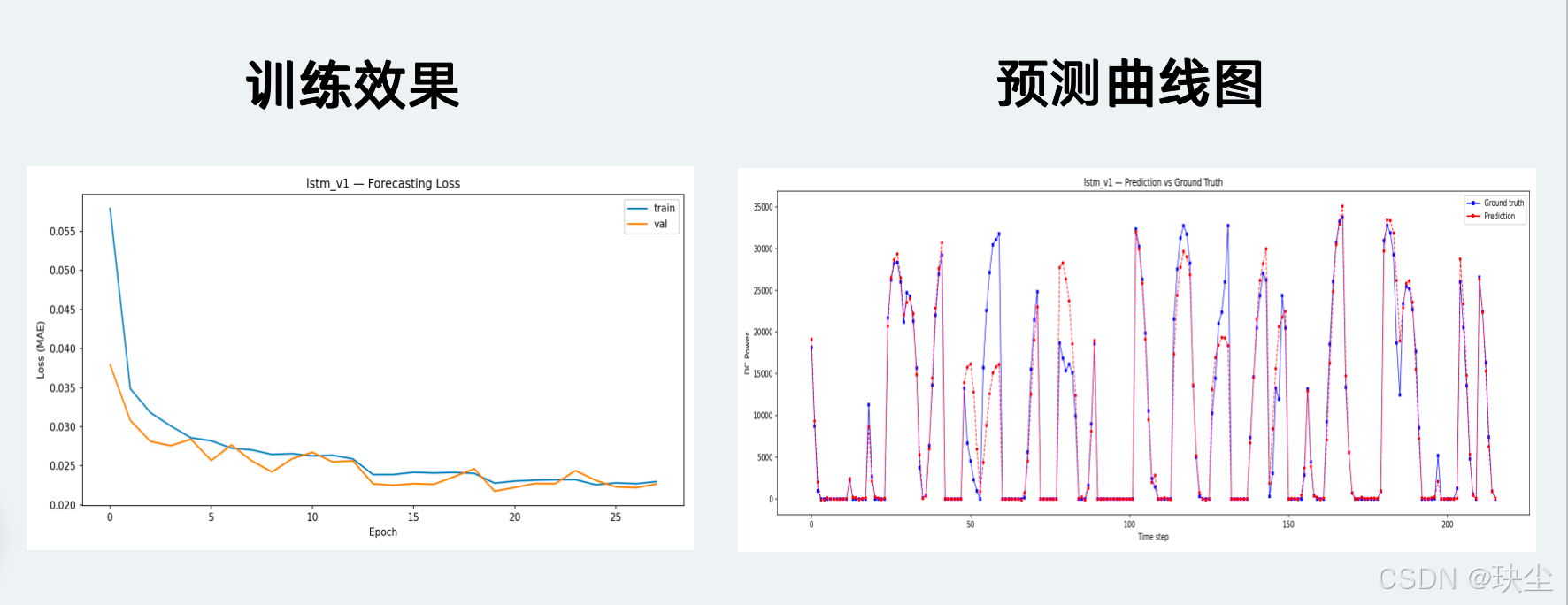
LSTM v2
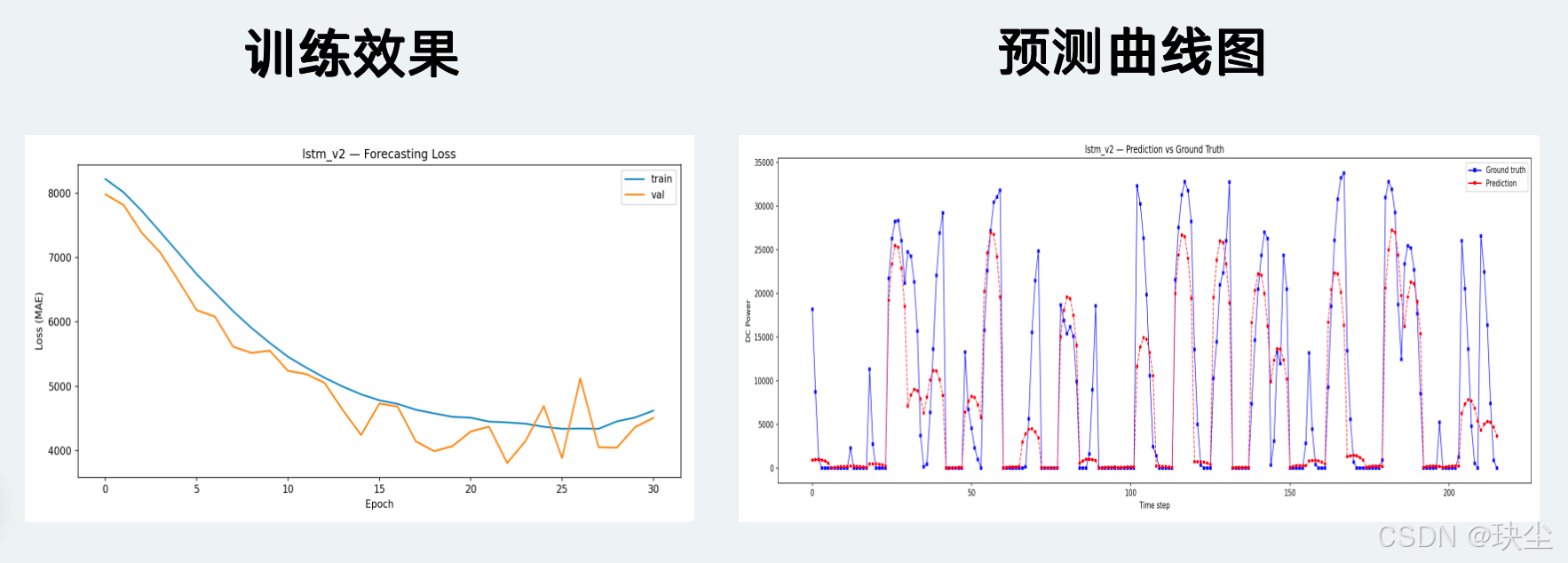
LSTM v3
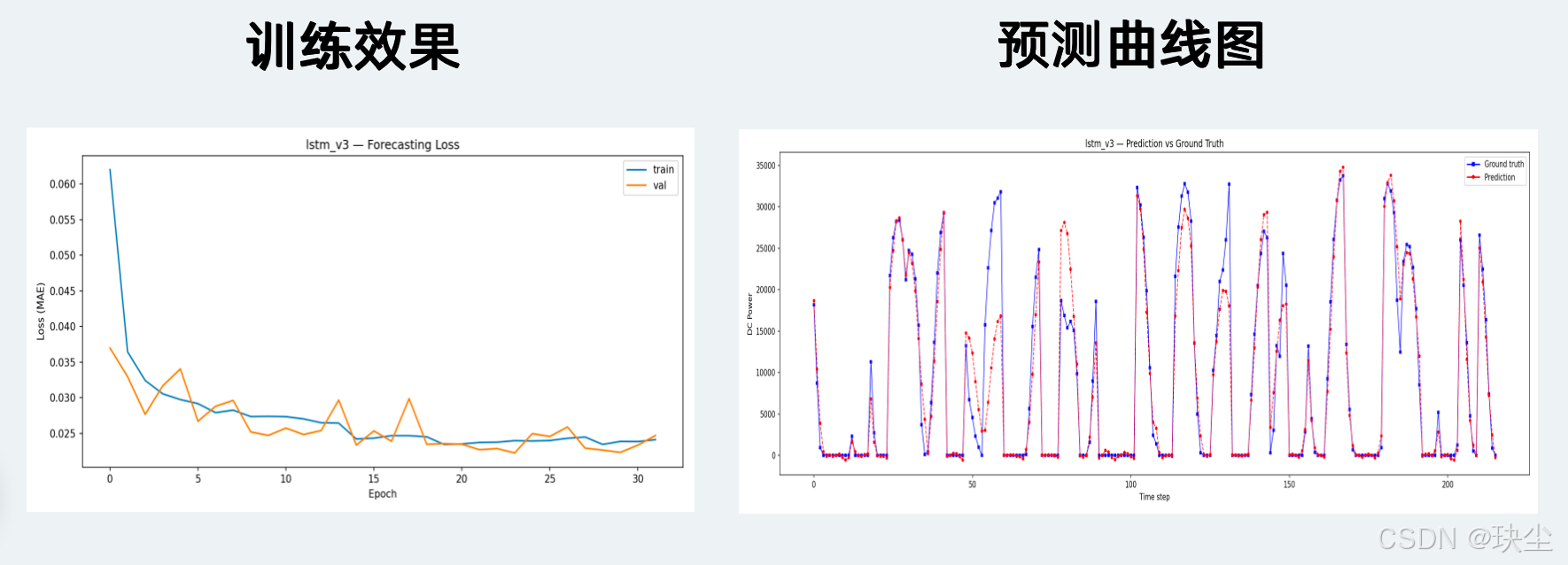
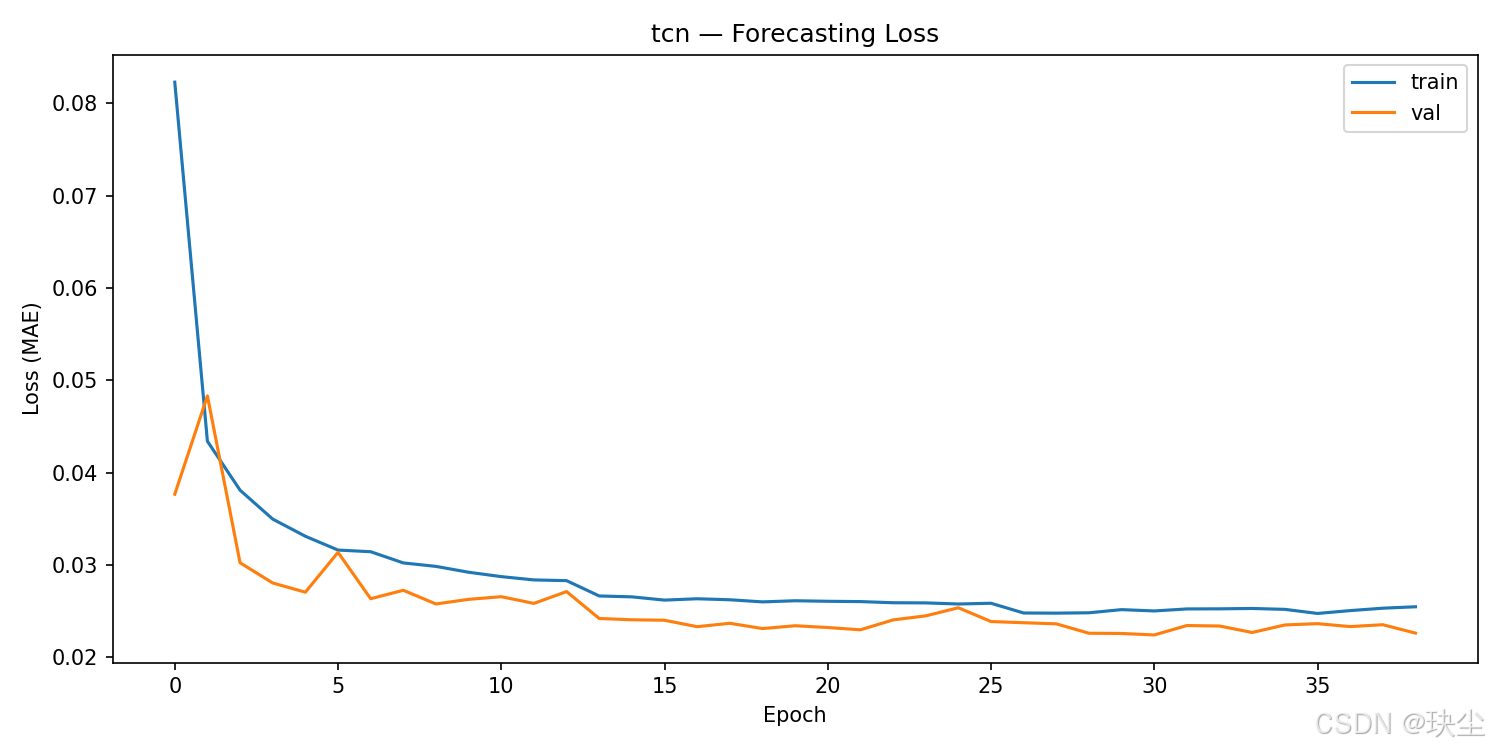
TCN
初始实验中dropout设置偏高(0.5),导致训练阶段loss虚高。后续已调整为0.1,两条曲线趋于一致,结果更具参考价值。
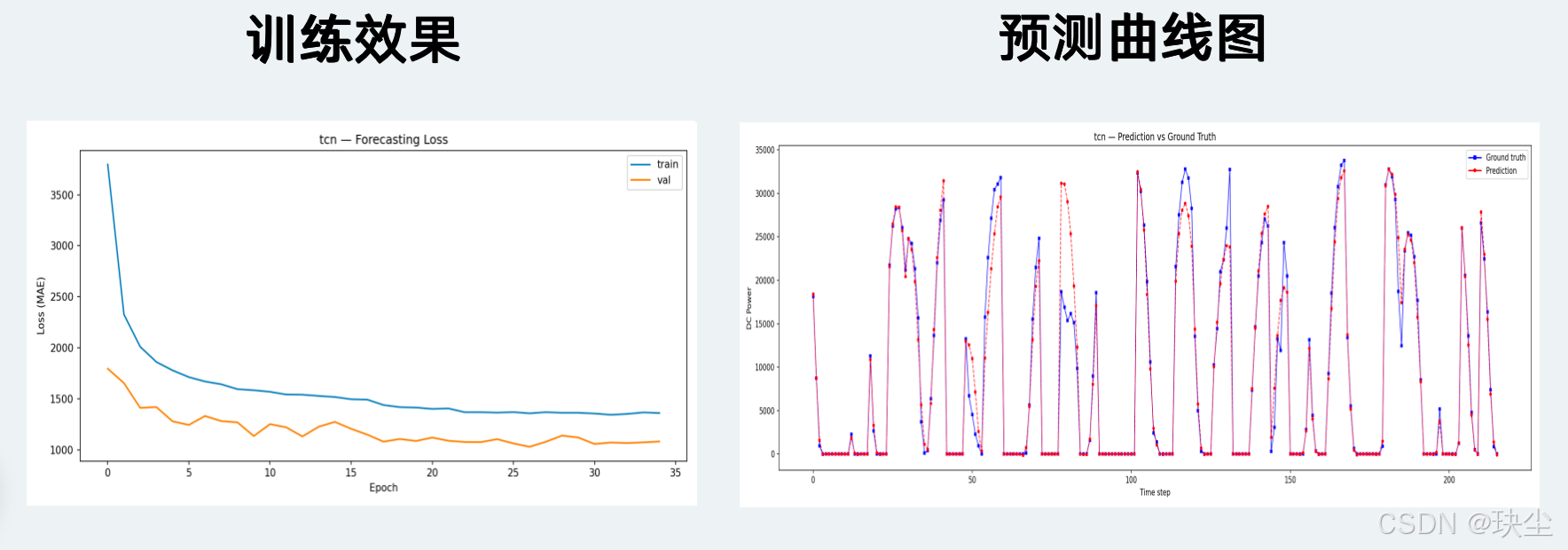
CNN-LSTM
TCN-LSTM
7.3 结果解读
发现一:LSTM v1 意外夺得最优
说实话这个结果一开始让我有点意外。本来以为混合架构会赢,毕竟花了更多时间设计,结果最简单的 LSTM v1 反而拿了最低的 RMSE(2358 W)和 MAE(873 W)。这是一个典型的奥卡姆剃刀现象:在数据量和任务规模都不太大的情况下,更简单的模型反而表现更好。双层 LSTM 加 256 个单元,对于这个 10 维输入、24步、6步输出的任务来说,容量已经足够;额外引入的结构复杂性没有换来精度提升,反而带来了过拟合风险。
发现二:BatchNorm 插入 LSTM 之间适得其反
LSTM v2 是本次实验里最惨的模型,MAE 1124 W,比 LSTM v1 差了将近 30%。当时加 BatchNorm 的时候完全没多想,CNN 里用得好好的,理所当然地就加进去了。结果出来之后查了很多资料才搞明白问题在哪:LSTM 依赖跨时间步传递的隐状态 (ht,ct)(h_t, c_t)(ht,ct),BatchNorm 会在每一层的输出上强行做批归一化,打乱了这个状态的分布,训练和推理时的统计量还不一致,直接破坏了时序记忆。
发现三:混合架构训练曲线更平稳
CNN-LSTM(MAE 876)和 TCN-LSTM(MAE 888)与 LSTM v1 的差距非常小(分别只差 0.3% 和 1.7%),但它们的训练 loss 曲线更为平滑,波动更小。这意味着混合架构的优势不在绝对精度,而在训练稳定性——这一点在面对更嘈杂的数据或更长的训练时可能会体现出更明显的优势。
发现四:纯 TCN 在多步预测场景有局限
TCN 的 MAE 是 1001 W,比前三名差了大约 14%。理论上膨胀卷积的感受野覆盖很广,捕捉长程依赖应该没问题,但实际跑下来效果不如预期。我的理解是多步预测这个任务对"记住过去某个具体状态、在之后多步中持续使用"这种能力要求比较高,而 TCN 没有显式的记忆机制,每一步的输出只依赖固定窗口内的卷积结果,这方面天然不如 LSTM 的门控结构。TCN-LSTM 把两者结合之后效果就好多了,也从侧面印证了这个判断。

八、踩过的坑与工程经验
坑一:归一化和窗口切分的顺序
这个坑在第一次跑实验的时候没注意,先切了窗口再对每个样本归一化,结果模型收敛得出奇地快,指标也好看得不正常。后来才意识到问题所在——每个样本单独归一化,测试集的 min/max 是从测试集自身算出来的,相当于模型提前"看到"了测试数据的分布,评估结果完全失真。改成先在整段序列上统一 fit_transform 再切窗口之后,指标回落到了正常水平。
坑二:反归一化时 scaler 维度不匹配
模型预测完直接调 inverse_transform,结果报错——scaler 是在 10 列特征上 fit 的,你给它传一个 (N, 6) 的数组它根本不认。当时找了一会儿才想明白,需要构造一个全零的 dummy 矩阵,把预测值塞进最后一列,反变换完再取出来。不绕这个弯的话指标全在归一化空间里算,数字好看但没有任何实际意义。
坑三:BatchNorm 不适合 LSTM 层间
当时以为 BatchNorm 是万能的,就直接加进去了。结果 LSTM v2 的 MAE 比最简单的 LSTM v1 差了将近 30%,一度以为是代码写错了,反复检查了好几遍。后来查资料才搞清楚,BatchNorm 会干扰 LSTM 跨时间步传递的隐状态分布,训练和推理阶段的 batch 统计量不一致,直接破坏了时序记忆。如果真的想加归一化,应该用 LayerNorm,对每个样本单独处理,不依赖 batch。
坑四:随机性控制
跑了两次同一个模型,指标差了一截,找了很久原因。深度学习的随机性来源比想象的多:数据打乱的种子、权重初始化、Dropout 的随机掩码,每一处都可能导致结果不一样。后来统一在 prepare_data 里固定 random_seed=42,并在训练开始前加上 tf.random.set_seed(42),结果才稳定下来。
坑五:测试集只能用一次
调参阶段为了图方便,每改一版结构就在测试集上跑一下看看效果,跑了十几次之后模型指标越来越好看。但后来意识到这已经不叫"未见数据"了,自己在无意识地朝测试集的方向过拟合。正确的做法是调参阶段只看验证集,测试集留到最后所有模型都定了之后统一评估一次,结果才有参考价值。这个教训代价不小,等于前面一部分调参工作的可信度都打了折扣。
九、总结
做完这个项目,收获最大的其实不是某个具体的模型结论,而是对"怎么做实验"这件事有了更清晰的认识。
以前觉得深度学习就是搭网络、跑训练、看指标,真正动手之后才发现坑大多不在模型本身,而在数据处理的细节、实验流程的规范、以及对结果的解读方式。归一化顺序、反变换的维度对齐、测试集只能用一次——这些听起来都是小事,但每一条背后都有一次实实在在踩坑的经历。
另一个收获是对"复杂不等于更好"有了更直观的感受。设计 CNN-LSTM 和 TCN-LSTM 的时候投入了更多精力,最终却被最简单的 LSTM v1 压了一头。这让我意识到,在动手堆结构之前,应该先想清楚任务的规模和瓶颈在哪里,容量够用的模型不需要额外的复杂度。
还有就是写代码的习惯。项目初期各个功能散落在不同地方,改一个参数要翻好几个文件。后来把数据、模型、训练、评估拆成独立模块之后,整个实验流程清晰了很多,复现和对比也方便了不少。这种模块化的思路以后做项目应该会一直沿用下去。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 17
17 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)