Python 全国城市租房洞察系统 Django框架 Requests爬虫 可视化 房子 房源 大数据 大模型 计算机毕业设计源码(建议收藏)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
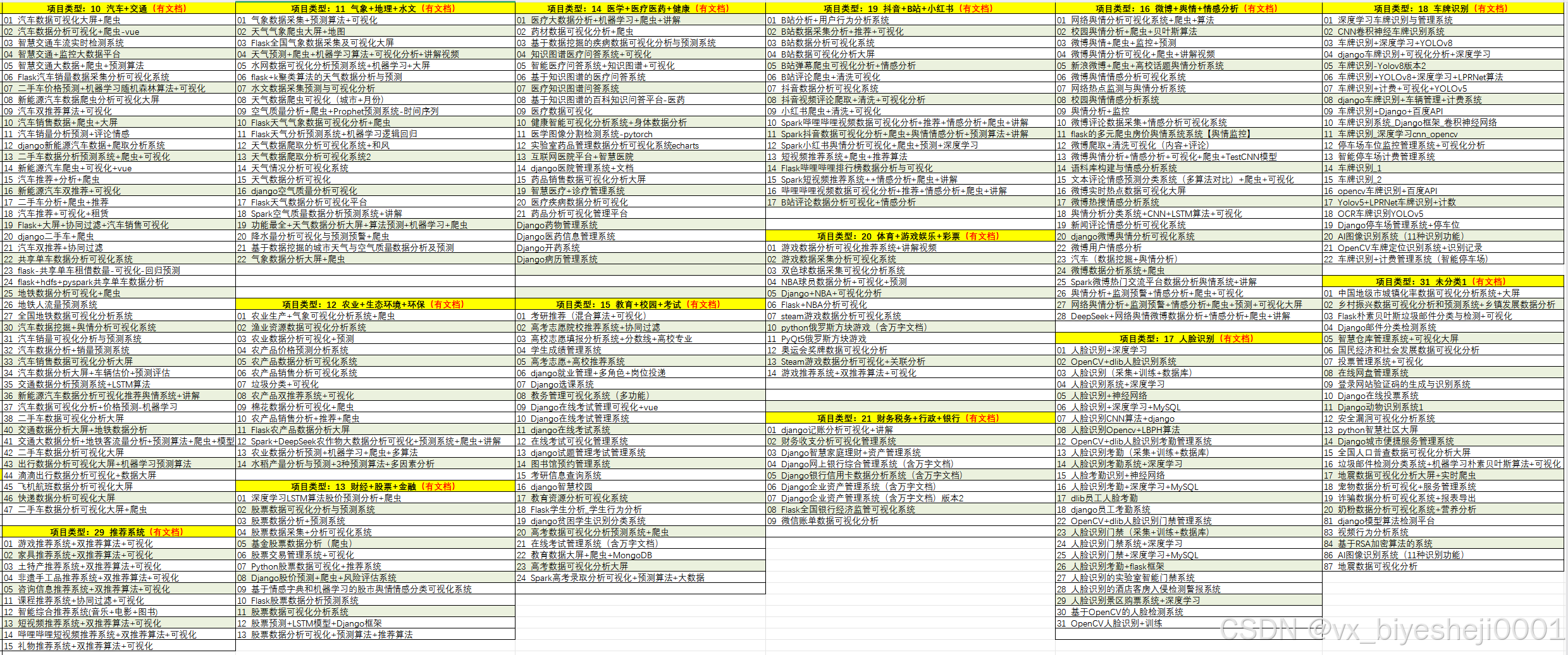
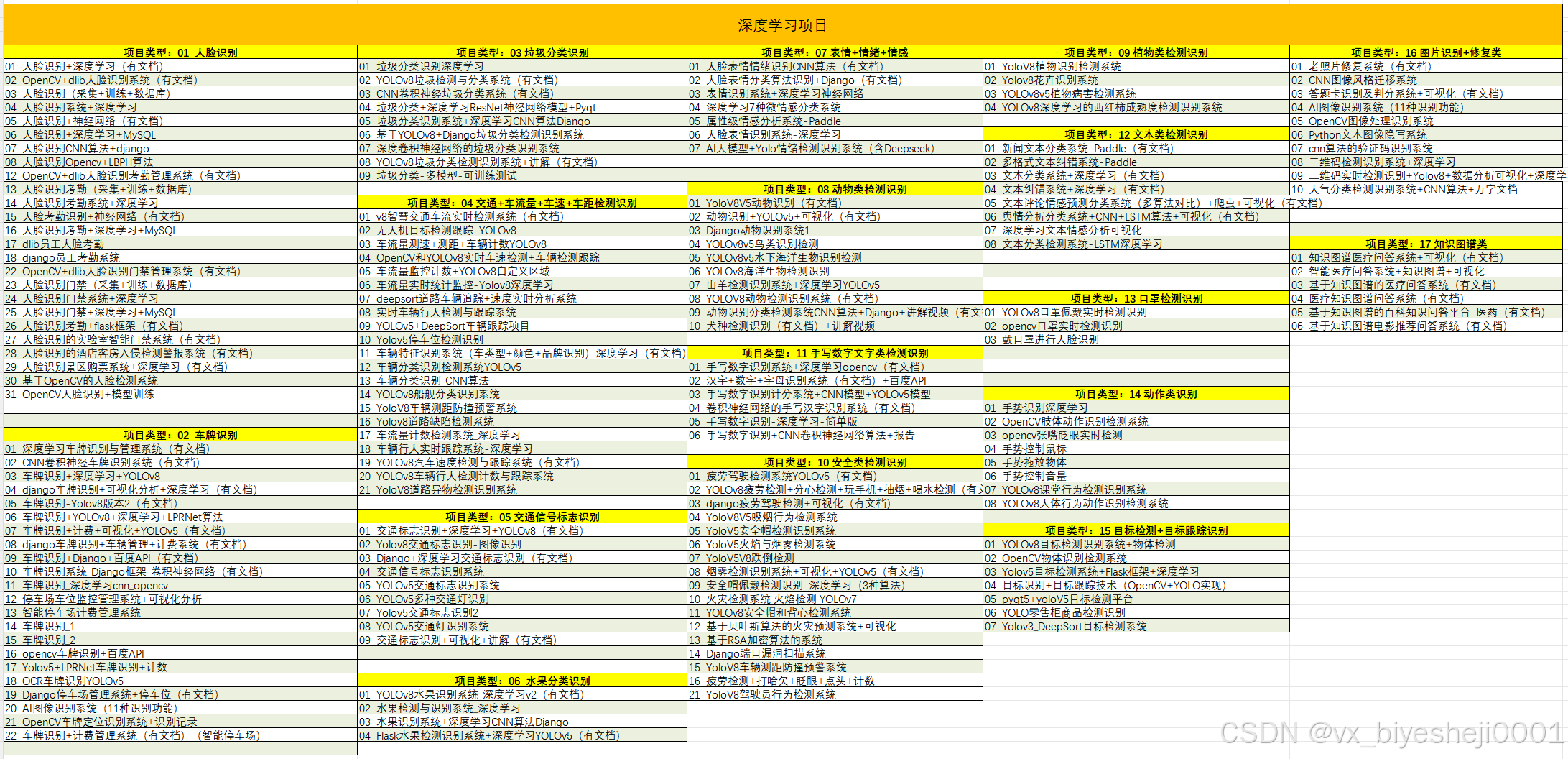
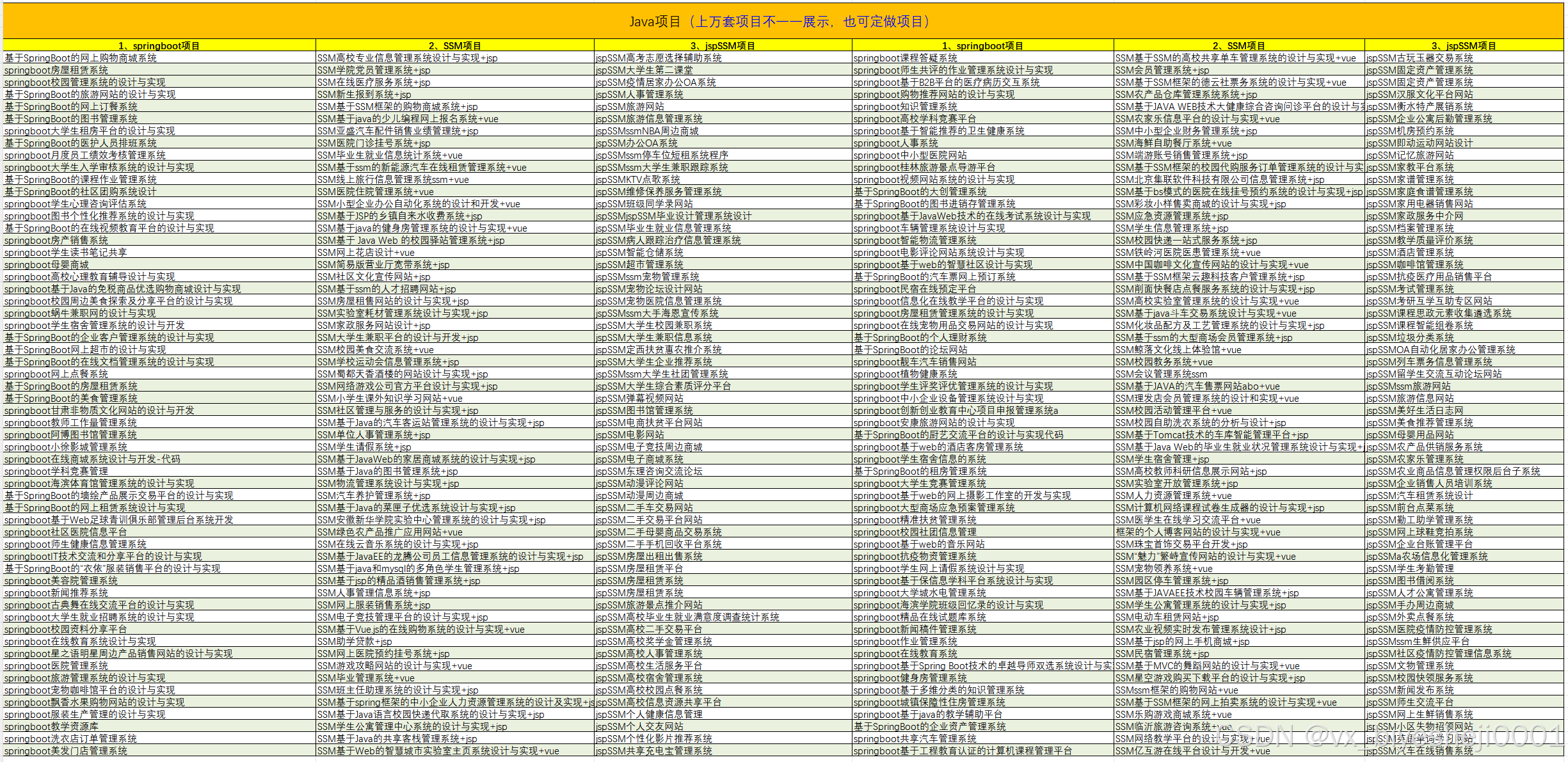
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2026年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
1、项目介绍
技术栈
Python语言、Django框架、requests爬虫、Echarts可视化工具、Bootstrap框架、jQuery、CSS、JavaScript、HTML
功能模块
• 租房信息数据展示模块
• 租房地址数量分布分析模块
• 租房类型统计模块
• 租房价格统计分析模块
• 租房面积分析模块
• 房屋朝向分析模块
• 房屋户型平均价格统计分析模块
• 房屋楼层统计分析模块
• 房屋楼层与价格统计分析模块
• 房屋地址与价格统计分析模块
• 房屋相关信息词云展示模块
项目介绍
本系统是基于Python与Django框架构建的全国租房数据分析平台,以贝壳租房网为数据源,通过requests爬虫技术实现全国各城市租房数据的自动化采集,涵盖租金、面积、户型、朝向、楼层、地址等核心字段。系统后端采用Django框架搭建Web应用层,保障数据处理与页面交互的稳定性;前端集成Bootstrap、jQuery及Echarts可视化工具,结合HTML、CSS、JavaScript实现页面布局与动态图表渲染,确保数据展示清晰直观、操作体验流畅。核心功能围绕租房数据全流程分析展开,包括租房信息分页展示、租房地址数量分布统计、整租合租类型占比分析、租金价格区间与平均值统计、面积分布规律挖掘、房屋朝向占比可视化、不同户型平均租金对比、楼层数量分布统计、楼层与租金关联分析、地址与租金关系探究,以及租房相关信息词云生成。系统覆盖全国租房市场数据,通过多维度可视化图表将复杂数据转化为直观结论,帮助用户快速把握不同城市、区域的租房市场特征,为租房决策提供科学数据支撑,兼具技术实用性与市场参考价值。
2、项目界面
(1)词云图分析
该页面是租房数据分析系统界面,包含租房信息数据展示、租房地址数量分布、租房类型统计、房价及面积分析、房屋朝向与户型均价统计、楼层及价格分析、地址与价格分析以及房屋相关信息词云展示等功能模块,可多维度呈现租房数据信息。

(2)房屋地址数量分布分析
该页面是租房数据分析系统界面,包含租房信息数据展示、租房地址数量分布可视化、租房类型统计、租房价格统计分析、租房面积分析、房屋朝向分析、房屋户型平均价格统计分析、房屋楼层统计分析、房屋楼层与价格统计分析、房屋地址与价格统计分析以及房屋相关信息词云展示等功能模块,可多维度呈现租房数据分布情况。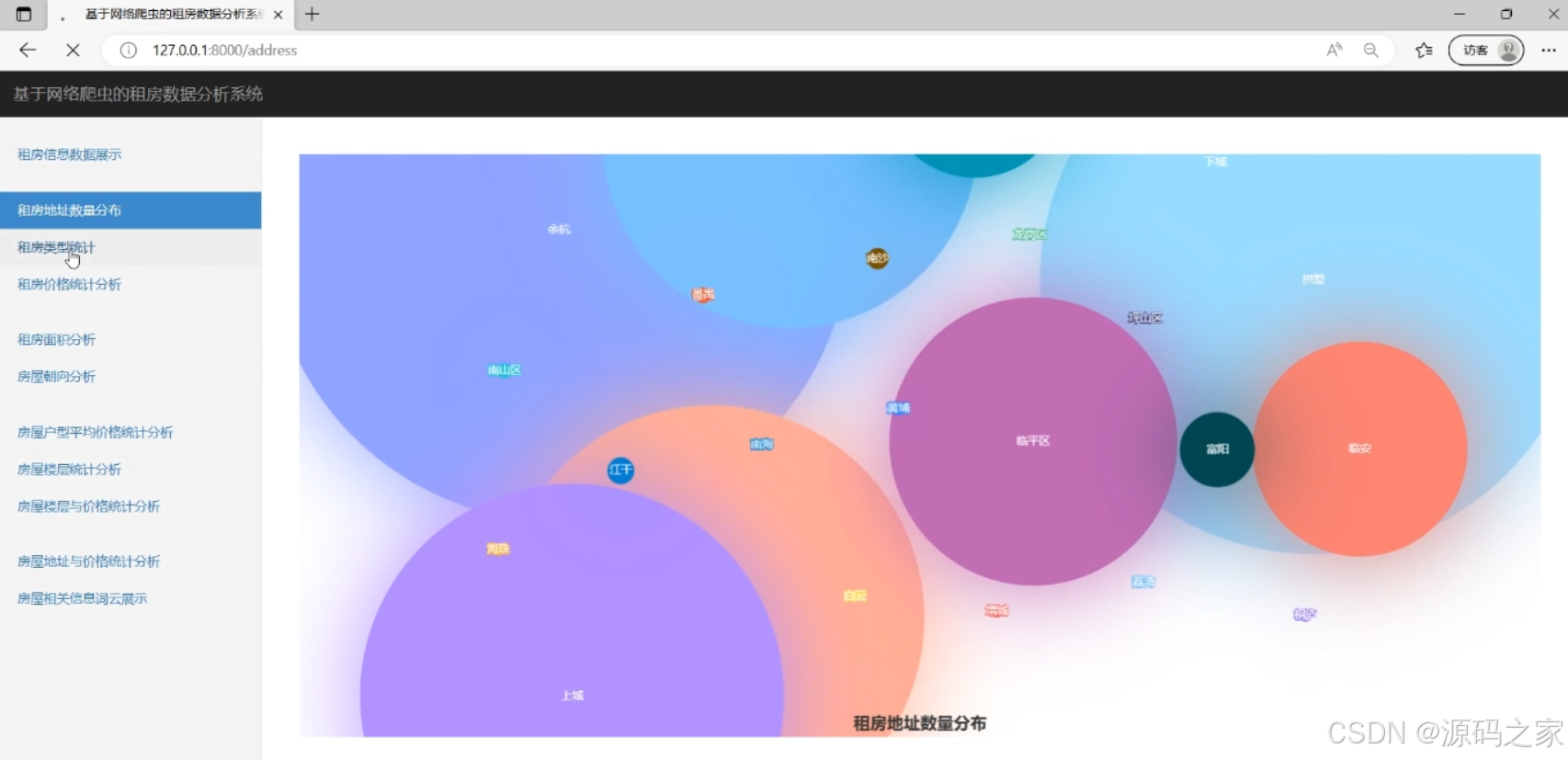
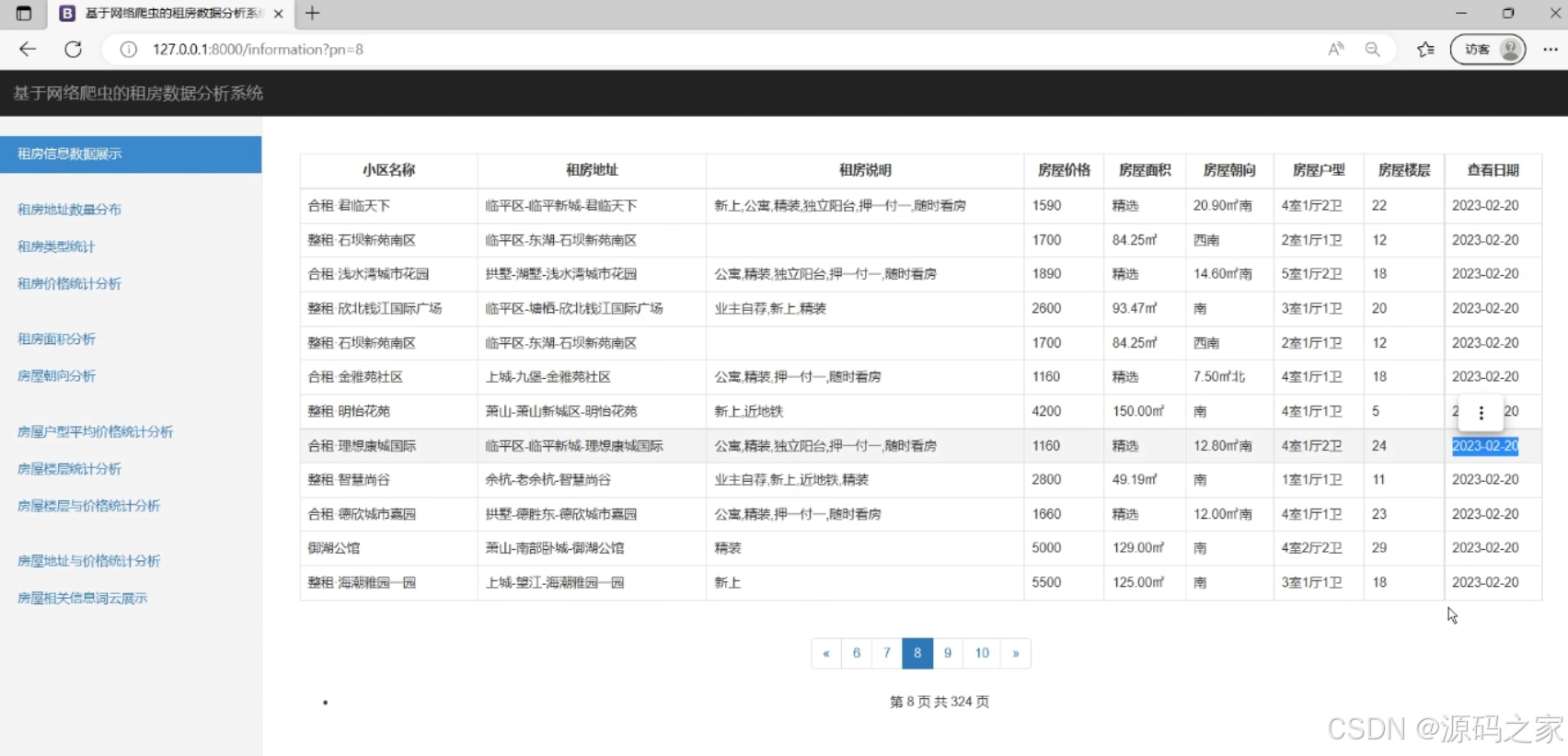
(3)租房数据
该页面是租房数据分析系统界面,包含租房信息数据展示、租房地址数量分布、租房类型统计、租房价格统计分析、租房面积分析、房屋朝向分析、房屋户型平均价格统计分析、房屋楼层统计分析、房屋楼层与价格统计分析、房屋地址与价格统计分析以及房屋相关信息词云展示等功能模块,可分页展示详细租房房源数据。
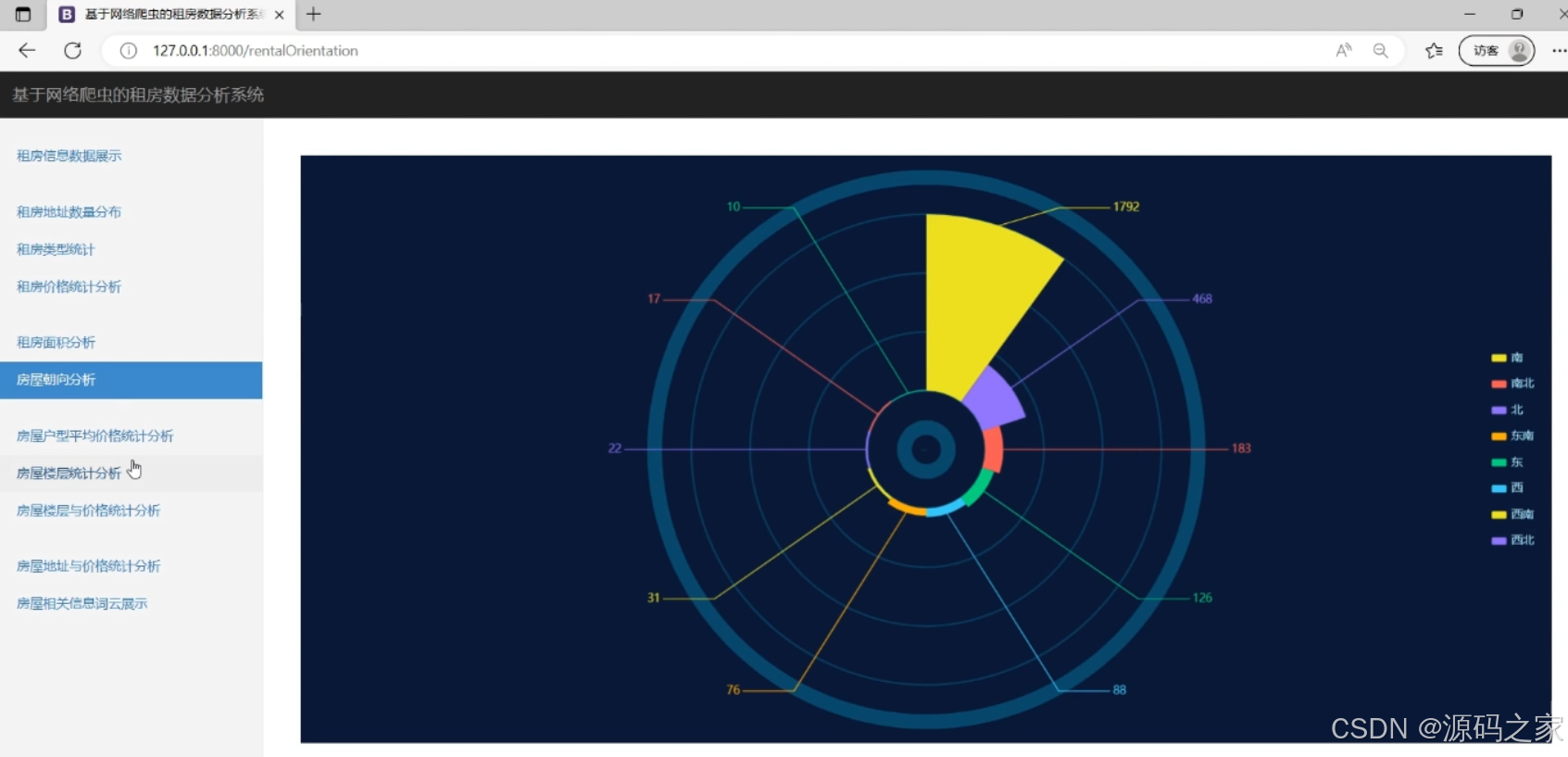
(4)房屋朝向分析
该页面是租房数据分析系统界面,包含租房信息数据展示、租房地址数量分布、租房类型统计、租房价格统计分析、租房面积分析、房屋朝向分析可视化、房屋户型平均价格统计分析、房屋楼层统计分析、房屋楼层与价格统计分析、房屋地址与价格统计分析以及房屋相关信息词云展示等功能模块,可多维度呈现租房数据特征。
3、项目说明
一、技术栈简要说明
本系统后端基于Python语言开发,采用Django框架构建Web应用层,负责处理业务逻辑与数据交互;数据采集环节使用requests库实现贝壳租房网全国各城市租房数据的精准抓取,涵盖租金、面积、户型、朝向等核心信息字段;前端页面集成Bootstrap框架与jQuery库,配合HTML、CSS、JavaScript技术实现响应式布局与动态交互效果;数据可视化层面引入Echarts工具,将分析结果以柱状图、饼图、折线图、词云图等形式进行直观呈现。
二、功能模块详细介绍
• 租房信息数据展示模块
该模块以分页列表形式展示爬取到的全国各城市租房房源数据,每页固定显示若干条记录,包含房屋标题、租金金额、建筑面积、户型结构、所在楼层、房屋朝向、详细地址等核心字段,支持用户浏览查看房源基本信息。
• 租房地址数量分布分析模块
模块对爬取数据中的地址字段进行统计聚合,计算各行政区或商圈内的房源数量,通过Echarts生成柱状图或地图形式展示不同地址的租房密度分布,直观呈现房源聚集区域特征。
• 租房类型统计模块
该模块对房源租赁方式进行分类统计,将整租与合租两类数据分别计数,利用饼图或环形图展示不同类型房源的占比情况,帮助用户了解不同租赁方式在市场中的供给比例。
• 租房价格统计分析模块
模块对全部房源租金数据进行计算分析,统计租金最大值、最小值及平均值,同时按价格区间划分段位统计房源数量分布,通过柱状图呈现各价格区间的房源占比,为用户提供价格参考依据。
• 租房面积分析模块
该模块对房屋建筑面积进行统计分析,计算面积最大值、最小值及平均值,并将面积划分为多个区间段,统计各区间内的房源数量,通过柱状图直观展示不同面积段的房源分布规律。
• 房屋朝向分析模块
模块对房源朝向字段进行统计分类,包括南北通透、朝南、朝北、东西向等常见朝向类型,利用饼图展示各类朝向的房源数量占比,清晰呈现市场房源朝向分布特征。
• 房屋户型平均价格统计分析模块
该模块按户型分类对房源进行分组统计,计算每种户型的平均租金价格,包括开间、一居室、两居室、三居室及以上等类型,通过柱状图展示不同户型的平均租金水平,揭示户型与价格之间的关联关系。
• 房屋楼层统计分析模块
模块对房源所在楼层进行分类统计,按低楼层、中楼层、高楼层划分区间,统计各楼层区间内的房源数量,通过柱状图呈现楼层分布情况,帮助用户了解不同楼层的房源供给比例。
• 房屋楼层与价格统计分析模块
该模块在楼层分类基础上,进一步计算各楼层区间的平均租金价格,通过折线图展示楼层变化与租金水平之间的关联趋势,分析楼层因素对租房价格的影响规律。
• 房屋地址与价格统计分析模块
模块按房源地址进行分组统计,计算各行政区域或商圈的平均租金价格,通过柱状图展示不同地址区域的租金水平差异,为用户选择租房区域提供价格参考。
• 房屋相关信息词云展示模块
该模块对房源标题、描述文本等非结构化数据进行分词处理,统计关键词出现频率,利用Echarts生成词云图进行可视化展示,字号大小代表词频高低,直观呈现租房市场的热点词汇与用户关注焦点。
三、项目总结
本系统以贝壳租房网为数据来源,构建了一套覆盖全国范围的租房数据分析可视化平台。后端采用Python与Django框架搭建Web应用,通过requests爬虫实现多城市租房数据的自动化采集与更新;前端集成Bootstrap、jQuery及Echarts工具,结合HTML、CSS、JavaScript技术打造响应式交互界面,确保数据展示清晰美观、操作流畅便捷。系统功能涵盖租房信息展示、地址分布统计、租赁类型分析、租金价格分析、面积分布挖掘、朝向占比可视化、户型均价对比、楼层统计、楼层与价格关联分析、地址与价格关系探究以及词云展示等十余个模块,从多个维度对租房市场数据进行深度剖析,将复杂数据转化为直观图表与结论。系统打破地域信息壁垒,帮助用户快速把握不同城市、区域的租房市场规律,为租房决策提供科学数据支撑,兼具技术实用性与市场参考价值。
4、核心代码
# coding:utf8
import os
import re
import json
from audioop import reverse
from os import path
import sqlite3
from urllib.request import urlretrieve
import jieba
from PIL import Image
from django.contrib.auth import authenticate
from django.http import HttpResponseRedirect
from django.shortcuts import render, HttpResponse, redirect
from django.contrib.auth.decorators import login_required # 导入登录验证
from django.views.generic import View, ListView # 视图基类
from datetime import datetime
import hashlib
# 导入模型
from wordcloud import WordCloud, ImageColorGenerator
from app00 import models
from django.conf import settings
# 创建模板对象
from django.template import Template, Context
# 导入分页类
from django.core.paginator import Paginator, InvalidPage, EmptyPage, PageNotAnInteger
# 导入数据分析类
import pymysql
import pandas as pd
import numpy as np
from django.urls import reverse,resolve
# 租房类型统计
def rentalType(request):
data = obtainData()
# 缺失值处理
data.dropna(subset=['community'], inplace=True)
types = data['community'].values
type = []
for m in types:
type.append(m[:2])
typeData = pd.DataFrame({"rentalType": type})
# print(addData)
typeDict = dict(typeData.rentalType.value_counts())
for k in [*typeDict.keys()]:
if k not in ['整租','合租','独栋']:
del typeDict[k]
typeList = list(typeDict.keys())
typeCount = list(typeDict.values())
print(typeDict)
# print(typeList)
# print(typeCount)
pi = []
for i in typeCount:
pi.append(i / 2850)
context = {
"rentalType": "active",
"typeDict":json.dumps({k:int(v) for k,v in typeDict.items()}),
}
return render(request, 'visualization/rentalType.html', context)
# 租房价格统计分析
def rentalPrice(request):
data = obtainData()
# 缺失值处理
data.dropna(subset=['price'], inplace=True)
prices = data['price'].values
price = []
for m in prices:
# 有的价格数据是区间形式,需要进行处理, 求平均值
if '-' in m:
temp = m.split('-')
price.append((int(temp[0]) + int(temp[1])) / 2)
else:
price.append(int(m))
# print(price)
# 进行数据统计
a, b, c, d, e = (0, 0, 0, 0, 0)
for t in price:
if t < 1000:
a += 1
elif 1000 <= t < 2000:
b += 1
elif 2000 <= t < 3000:
c += 1
elif 3000 <= t < 4000:
d += 1
else:
e += 1
priceList = ['1000以下', '1000-2000', '2000-3000', '3000-4000', '4000以上']
priceCount = [a, b, c, d, e]
print(dict(zip(priceList,priceCount)))
context = {
"rentalPrice": "active",
"priceList": priceList,
"priceCount": priceCount
}
return render(request, 'visualization/rentalPrice.html', context)
# 租房面积分析
def rentalArea(request):
data = obtainData()
# 缺失值处理
data.dropna(subset=['area'], inplace=True)
areas = data['area'].values
area = []
for m in areas:
try:
area.append(float(m[:-1]))
except:
area.append(0)
a, b, c, d, e, f = (0, 0, 0, 0, 0, 0)
for t in area:
if t <= 10:
a += 1
elif 10 < t <= 50:
b += 1
elif 50 < t <= 100:
c += 1
elif 100 < t <= 120:
d += 1
elif 120 < t <= 150:
e += 1
else:
f += 1
areaList = ['10平方以下', '10-50', '50-100', '100-120', '120-150', '150平方以上']
areaCount = [a, b, c, d, e, f]
context = {
"rentalArea": "active",
"areaList": areaList,
"areaCount": areaCount
}
print(dict(zip(areaList,areaCount)))
return render(request, 'visualization/rentalArea.html', context)
# 房屋朝向分析
def rentalOrientation(request):
data = obtainData()
orientationDict = dict(data.orientation.value_counts())
orientationList = list(orientationDict.keys())
orientationList = orientationList[:15] + orientationList[18:20]
orientationCount = list(orientationDict.values())
orientationCount = orientationCount[:15] + orientationCount[18:20]
# print(orientationDict)
# print(orientationList)
# print(orientationCount)
context = {
"rentalOrientation": "active",
"orientationList": orientationList[:10],
"orientationCount": orientationCount[:10]
}
print(dict(zip(orientationList[:10],orientationCount[:10])))
return render(request, 'visualization/rentalOrientation.html', context)
# 房屋户型平均价格统计分析
def rentalPattern(request):
data = obtainData()
data.dropna(how='any', inplace=True)
"""
print(len(data.price.values))
for i in range(len(data.price.values)):
if '-' in str(data.price.values[i]):
data.drop(data.index[i], inplace=True)
"""
data['price'] = data['price'].map(lambda x:re.search(r'\d+',x).group()).astype(int)
group = data.groupby('pattern').price.mean()
patternDict = dict(data.pattern.value_counts())
patternList = list(group.index)
t = list(group.values)
patternCount = []
for i in t:
patternCount.append(int(i))
# print(type(group))
# print(group.index)
# print(group.values)
context = {
"rentalPattern": "active",
"patternList": patternList[:10],
"patternCount": patternCount[:10]
}
print(dict(zip(patternList[:10],patternCount[:10])))
return render(request, 'visualization/rentalPattern.html', context)
# 房屋楼层统计分析
def rentalFloor(request):
data = obtainData()
# 缺失值处理
data.dropna(subset=['floor'], inplace=True)
m = data.floor.values
dataNew = []
for i in m:
dataNew.append(i[:3])
p = pd.DataFrame({"data": dataNew})
rentalFloorDict = dict(p["data"].value_counts())
rentalFloorDict=dict(sorted([[k,v] for k,v in rentalFloorDict.items()],key=lambda x:int(x[0])))
rentalFloorList = list(rentalFloorDict.keys())
rentalFloorCount = list(rentalFloorDict.values())
# print(rentalFloorDict)
context = {
"rentalFloor": 'active',
"rentalFloorList": rentalFloorList[:],
"rentalFloorCount": rentalFloorCount[:]
}
print(dict(zip(rentalFloorList[:],rentalFloorCount[:])))
return render(request, 'visualization/rentalFloor.html', context)
# 房屋楼层与价格统计分析
def floorAndPrice(request):
data = obtainData()
data.dropna(how='any', inplace=True)
data[['price']] = data[['price']].astype(float)
m = data.floor.values
dataNew = []
for i in m:
dataNew.append(i[:3])
p = pd.DataFrame({"floor": dataNew, 'price': list(data.price.values)})
level=pd.cut(p['floor'].astype(int),bins=3,right=True,labels=['低楼层','中楼层','高楼层'])
p['level'] = level
group = p.groupby('level').price.mean()
print(group)
# print(group)
floorAndPriceList = list(group.index)
t = list(group.values)
floorAndPriceCount = []
for i in t:
floorAndPriceCount.append(int(i))
context = {
"floorAndPrice": "active",
"floorAndPriceDict":json.dumps(dict(zip(floorAndPriceList[:],floorAndPriceCount[:])))
# "floorAndPriceList": floorAndPriceList,
# "floorAndPriceCount": floorAndPriceCount
}
print(dict(zip(floorAndPriceList[:],floorAndPriceCount[:])))
return render(request, 'visualization/floorAndPrice.html', context)
# 房屋地址与价格统计分析
def addressAndPrice(request):
data = obtainData()
data.dropna(how='any', inplace=True)
data[['price']] = data[['price']].astype(float)
m = data.address.values
dataNew = []
for i in m:
dataNew.append(i.split('-')[0])
p = pd.DataFrame({"address": dataNew, 'price': list(data.price.values)})
group = p.groupby('address').price.mean()
# print(group)
addressAndPriceList = list(group.index)
t = list(group.values)
addressAndPriceCount = []
for i in t:
addressAndPriceCount.append(int(i))
# print(addressAndPriceList)
# print(addressAndPriceCount)
dd = [{"address":k,"count":v}for k,v in dict(zip(addressAndPriceList[:],addressAndPriceCount[:])).items()]
context = {
"addressAndPrice": "active",
"addressAndPriceDict":json.dumps(dd)
# "addressAndPriceList": addressAndPriceList[1:],
# "addressAndPriceCount": addressAndPriceCount[1:]
}
print(dict(zip(addressAndPriceList[:],addressAndPriceCount[:])))
return render(request, 'visualization/addressAndPrice.html', context)
# 房屋相关信息词云展示
def introduction(request):
context = {
"introduction": "active"
}
return render(request, 'visualization/introduction.html', context)
def introduction_pic(request):
data = obtainData()
data = data.dropna()
m = data['introduction'].values
result = []
for i in m:
result.append(i)
txt = ' '.join(result)
# join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串
cut_text = " ".join(jieba.cut(txt))
# mask参数=图片背景,必须要写上,另外有mask参数再设定宽高是无效的
wordcloud = WordCloud(font_path="./simhei.ttf", background_color="white",width=1200,height=600).generate(cut_text)
wordcloud.to_file("test.jpg")
return HttpResponse(open('test.jpg','rb').read(),content_type="image/jpg")
5、项目列表
6、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)