第七节,自然语言处理与bert
引子
NLP:nature language process自然语言处理


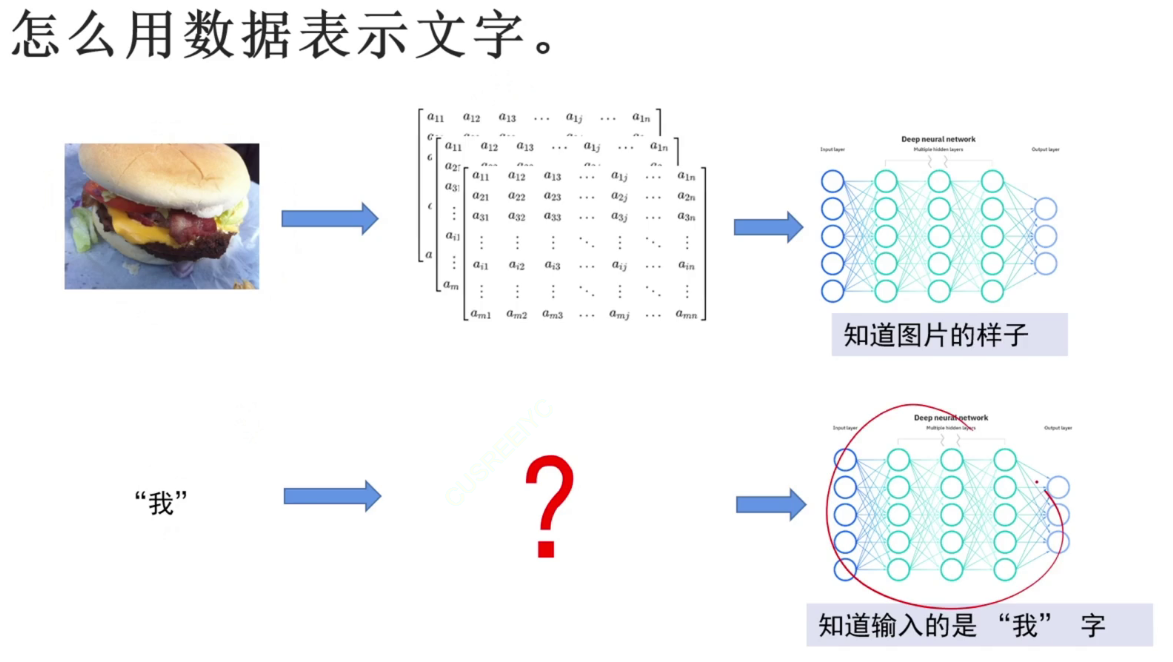
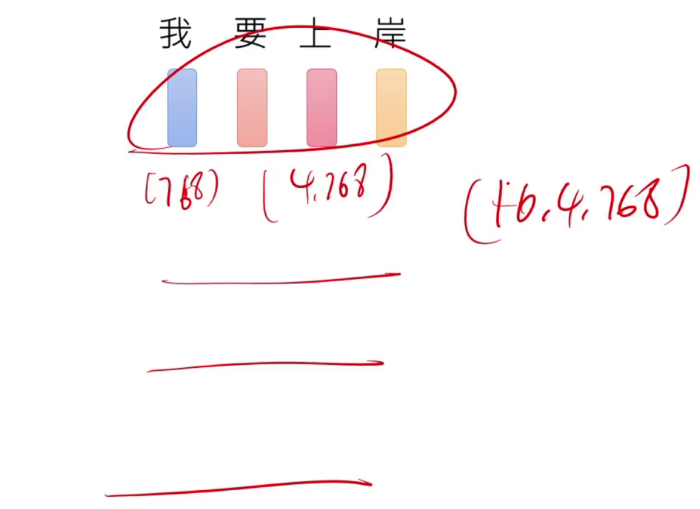
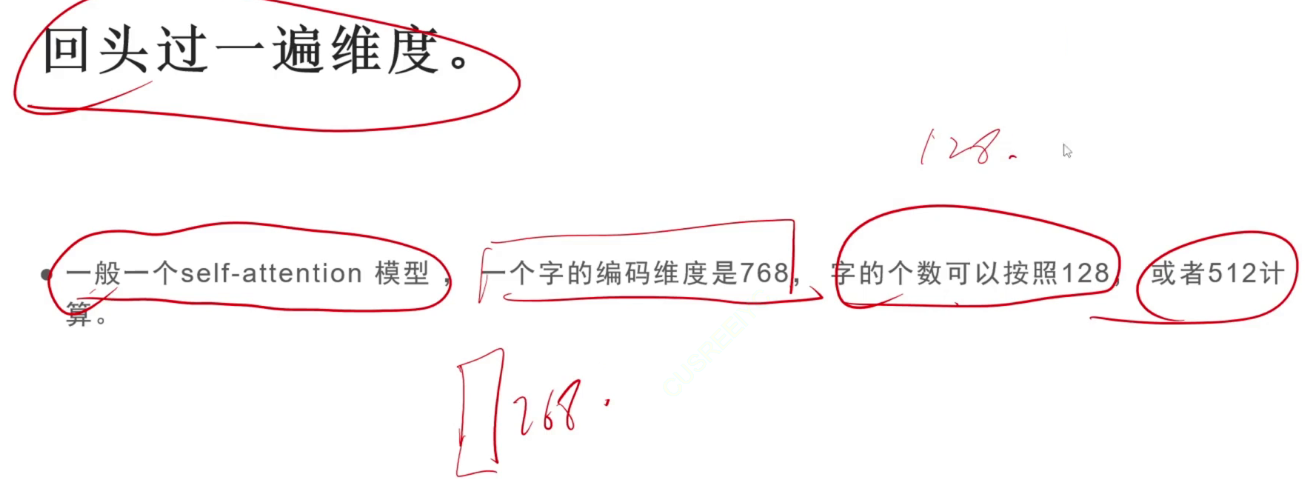
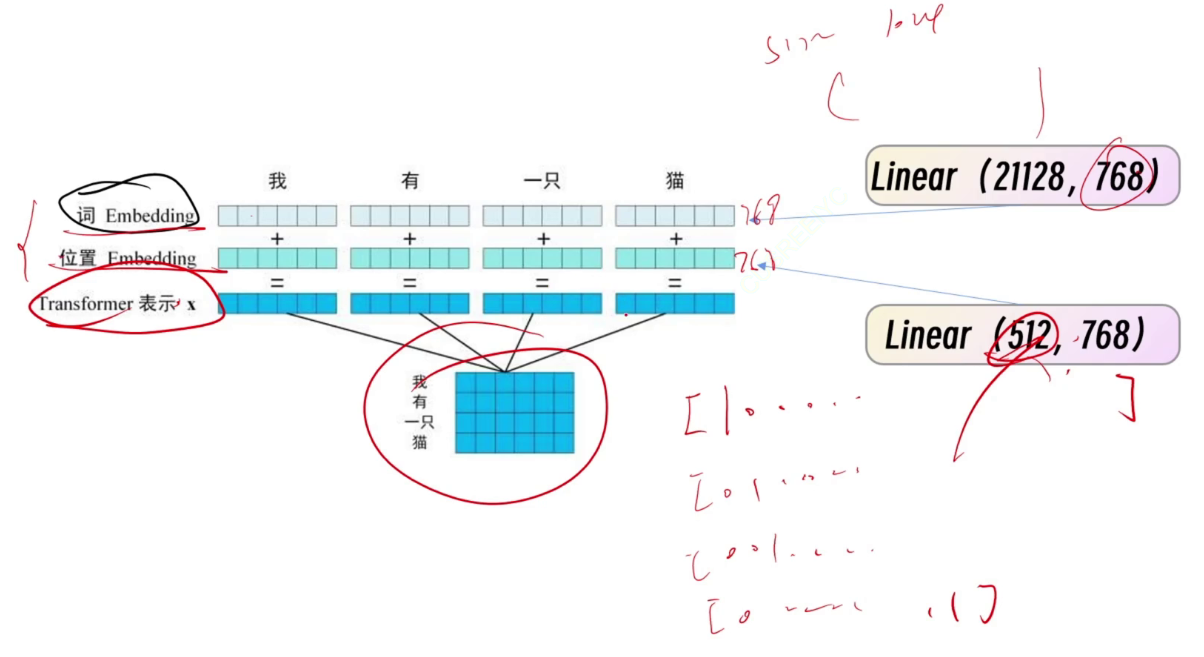
如何表示文字,用向量编码。图中的(16,4,768)为(batch,4个,768个/行向量)(一般的transformer模型用768维向量表示字)
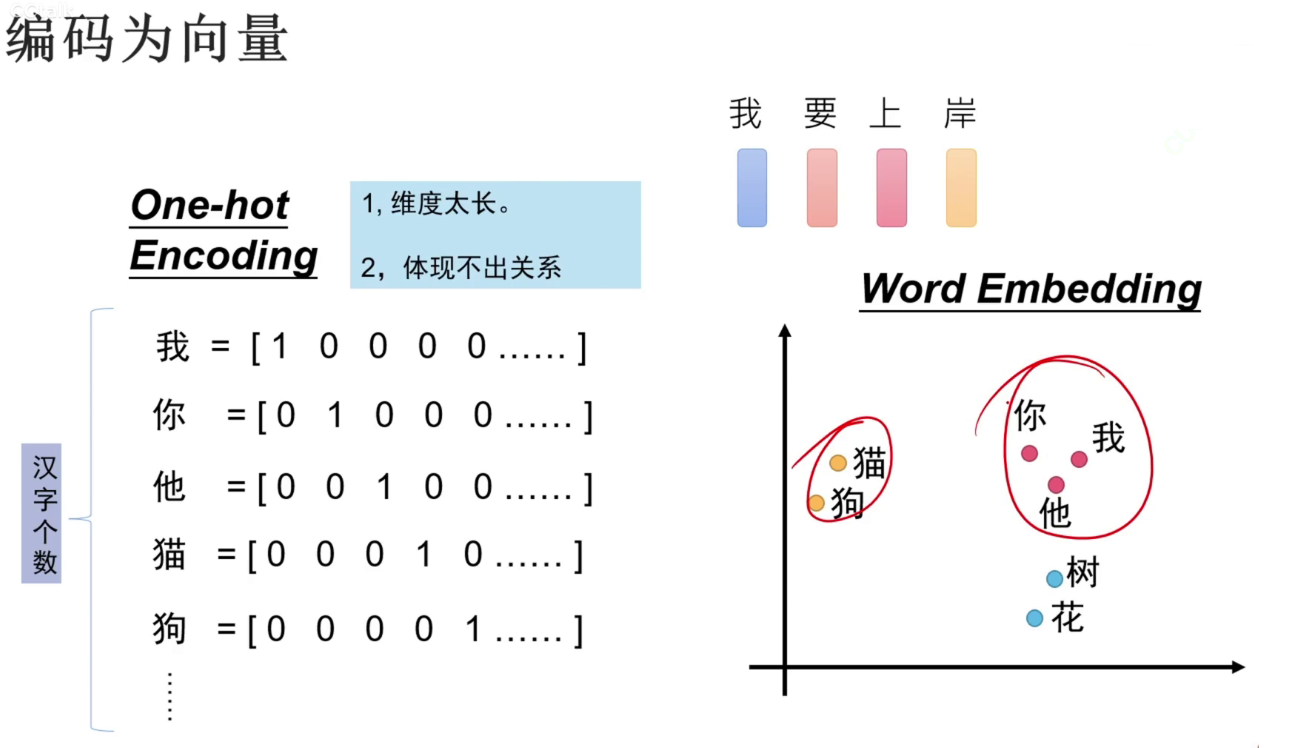
独热编码(一个超长向量表示字,是哪个字,对应的位置置1)表示字的缺点:
1、向量很长。2、不能表示字的含义,例如猫和狗理论上都属于动物,但是独热编码体现不出这种关系。
替代方案:word embedding==》one-hot encoding
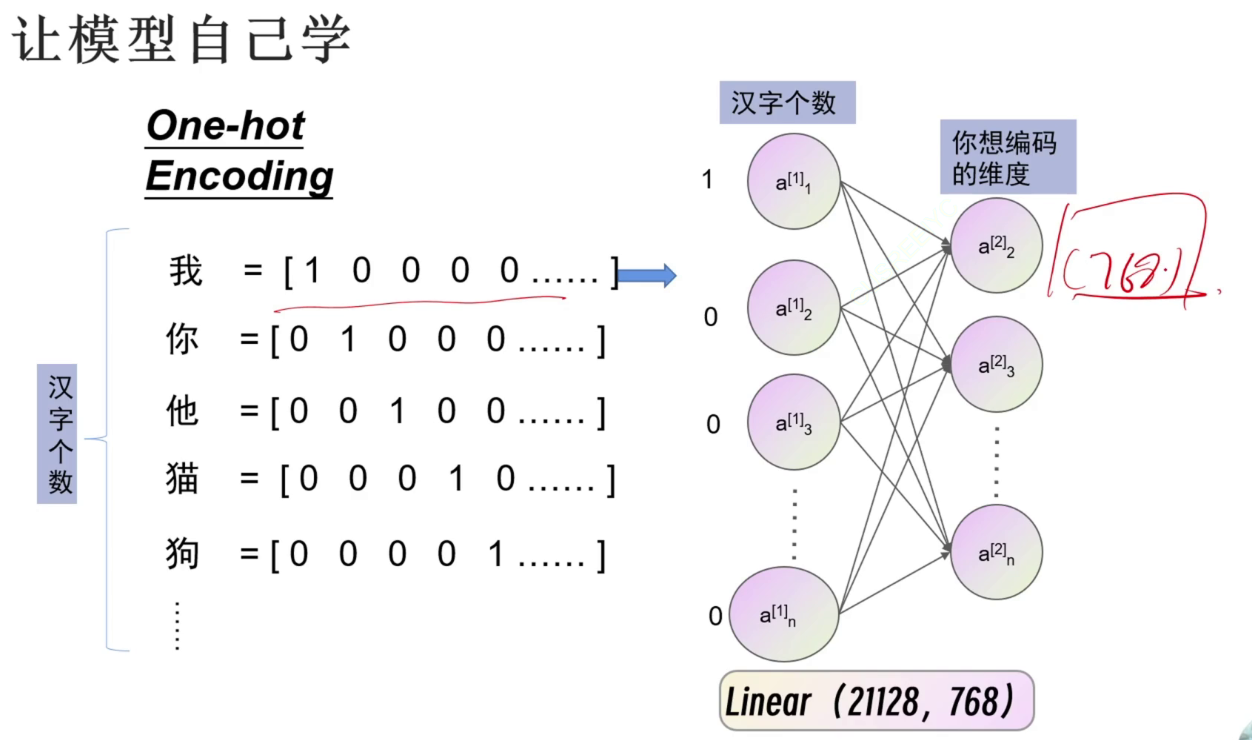
让模型通过一个全连接自己学习训练并将汉字编码为人类想要的维度。此方法称为:word embedding 词embedding

类似于分类任务
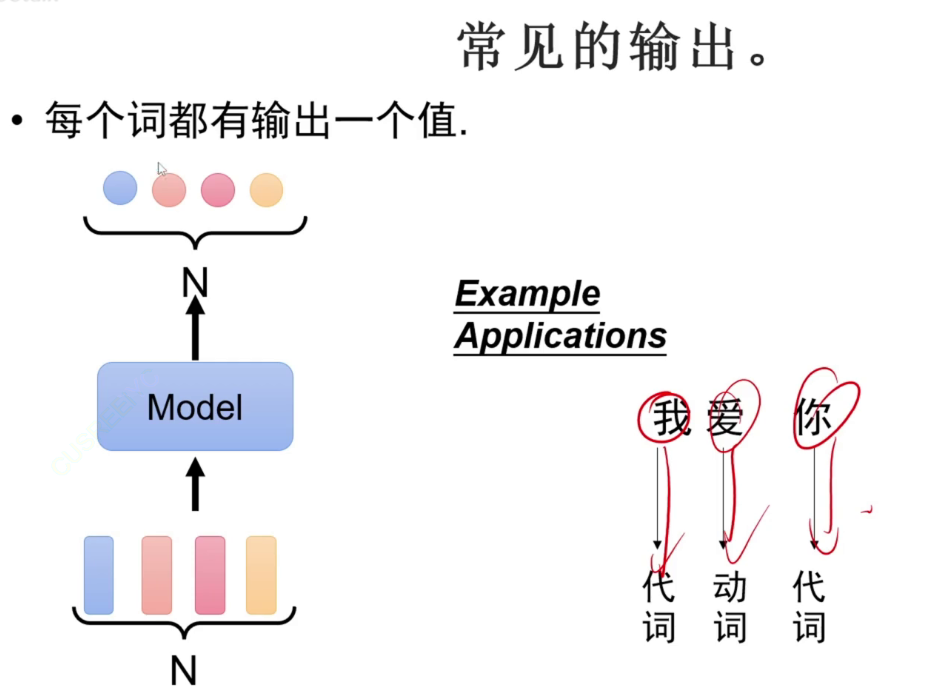
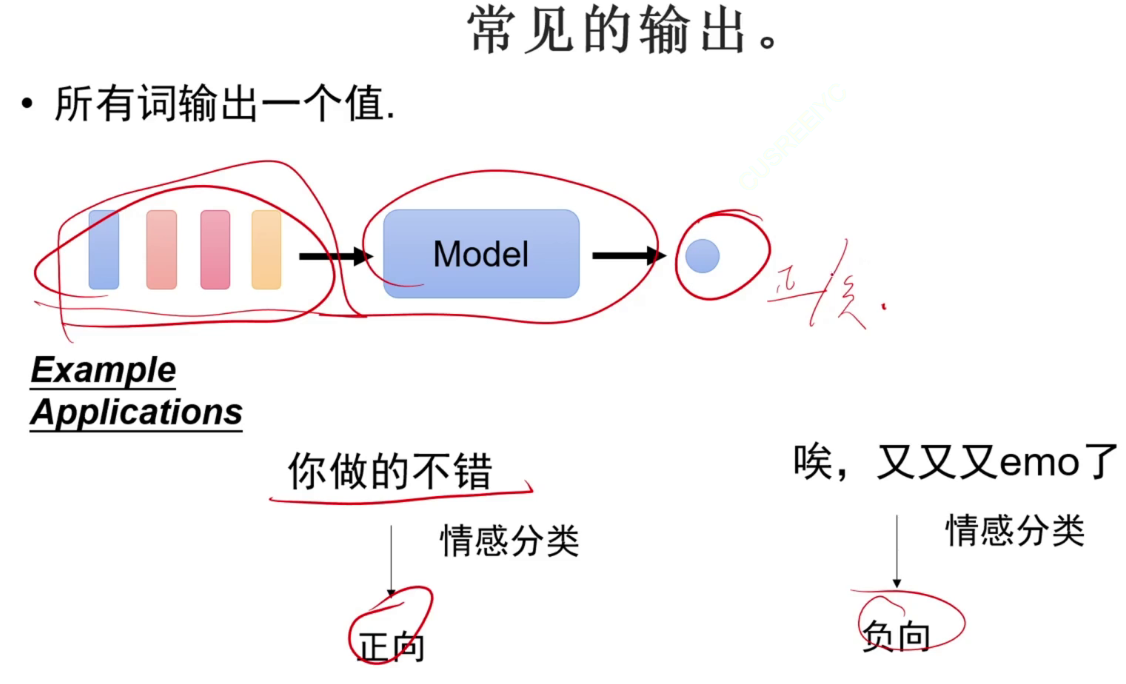
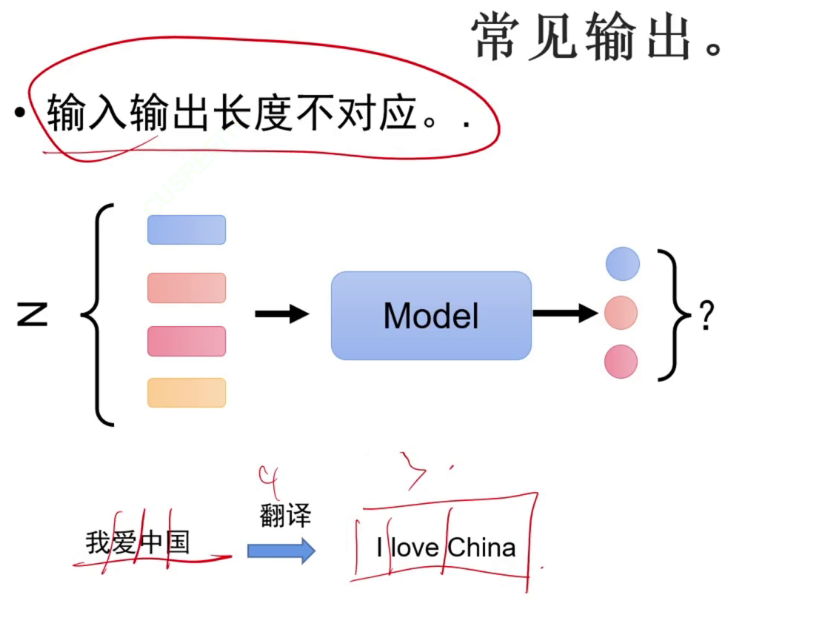
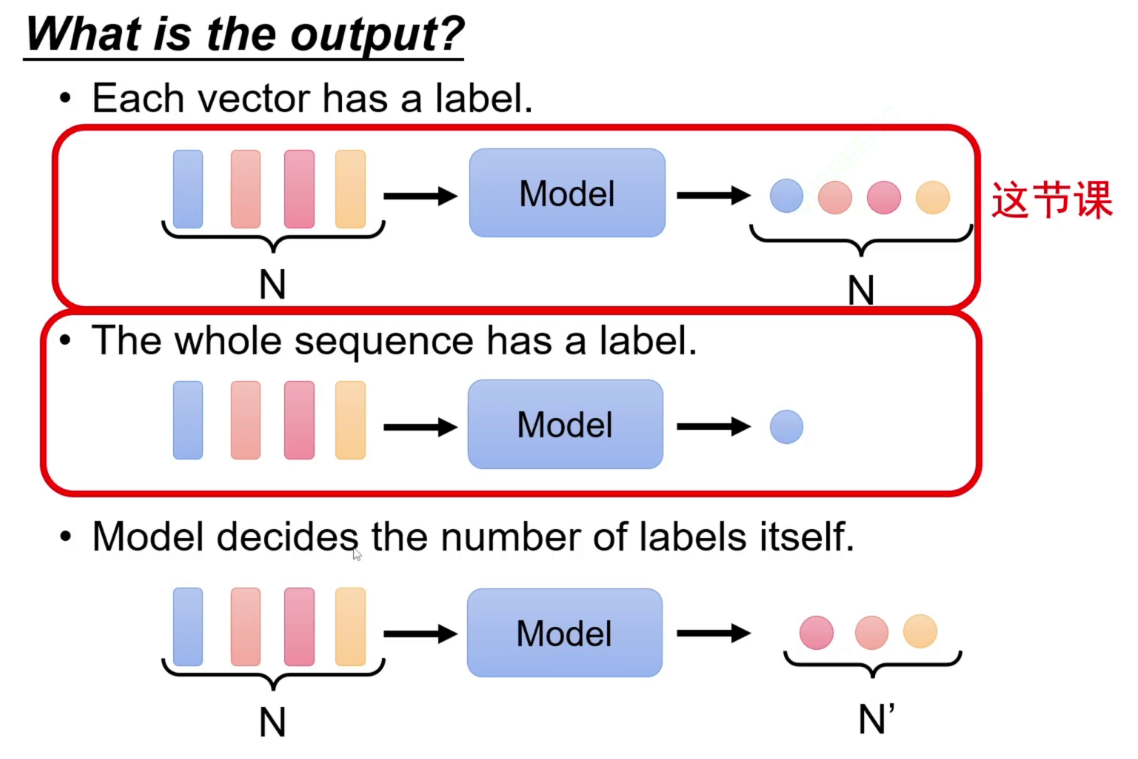
词性识别任务
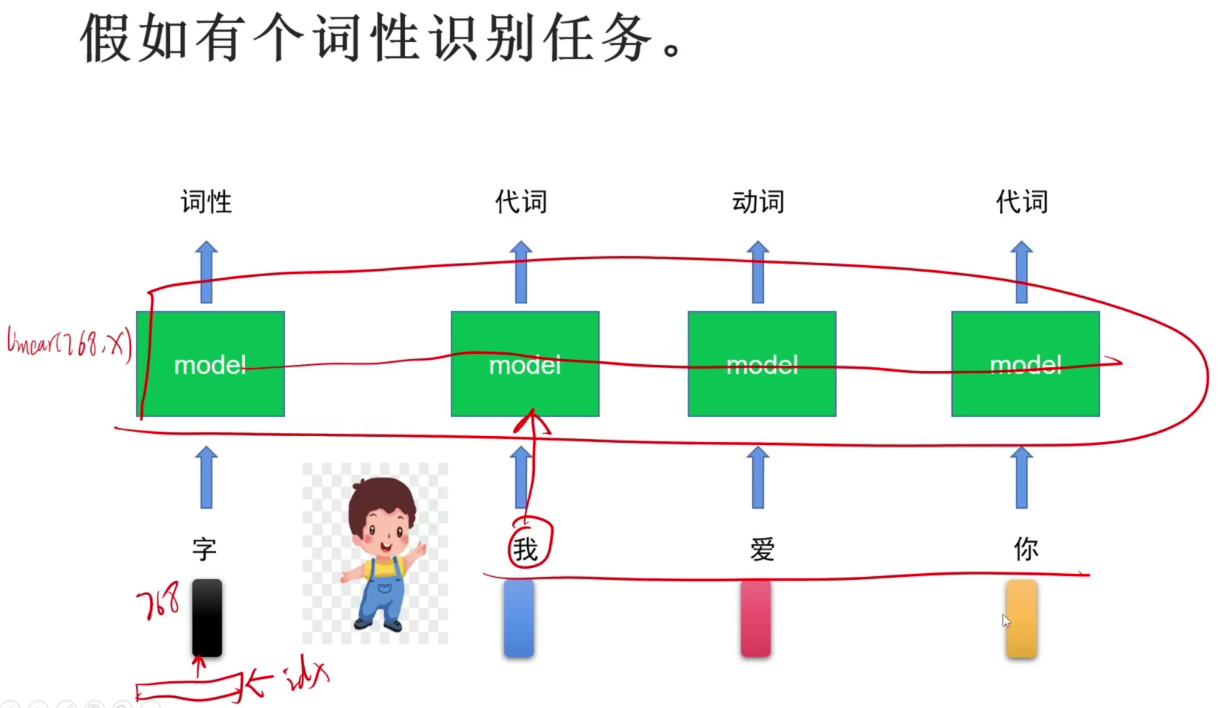
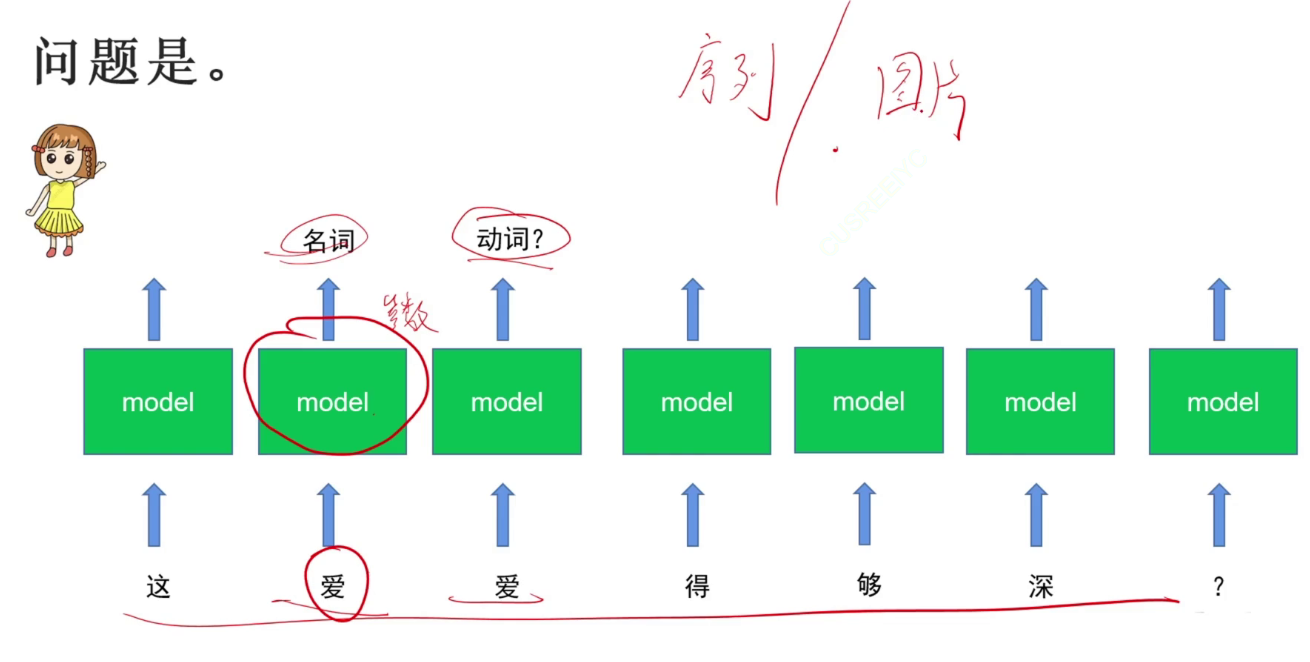
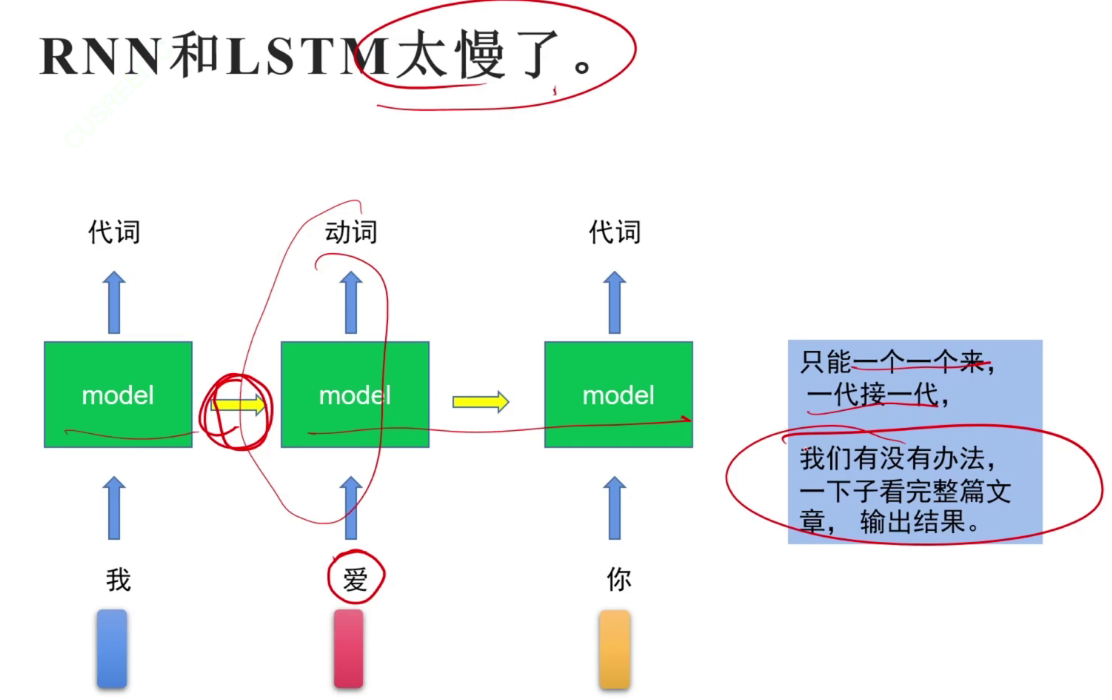
序列任务与图片分类任务的区别:序列任务不仅与自己相关,还与输入的序列相关。需要考虑上下文。Can you can a can as a canner can a can?
RNN(Recurrent Neural Network)循环神经网络
最早研究序列问题的网络:用向量来记忆并存储数据。记忆向量。
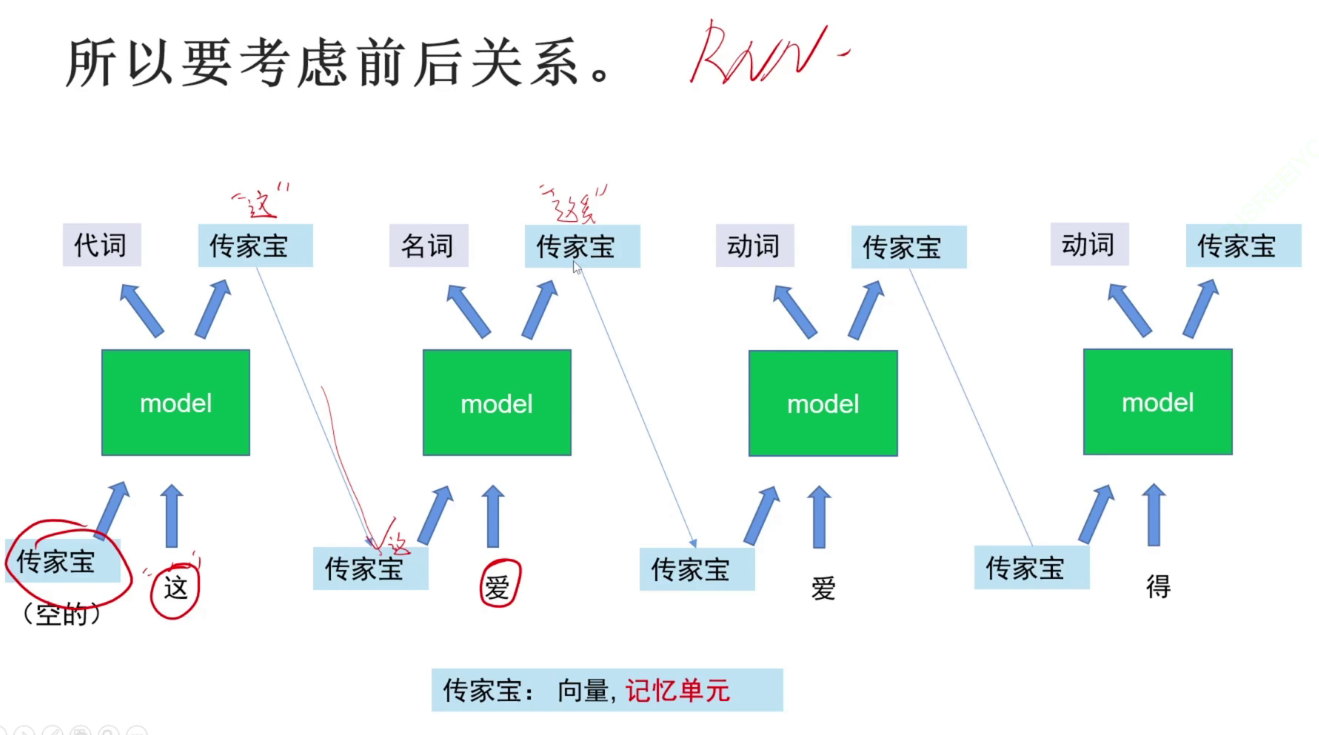
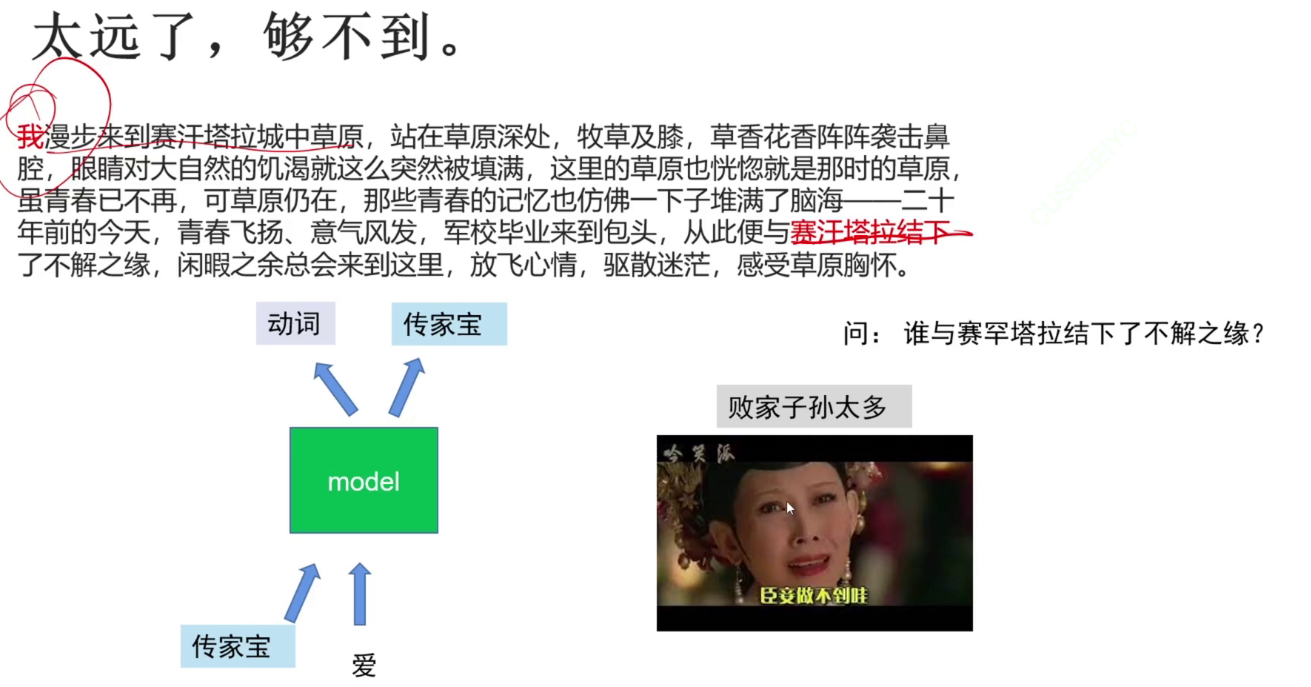
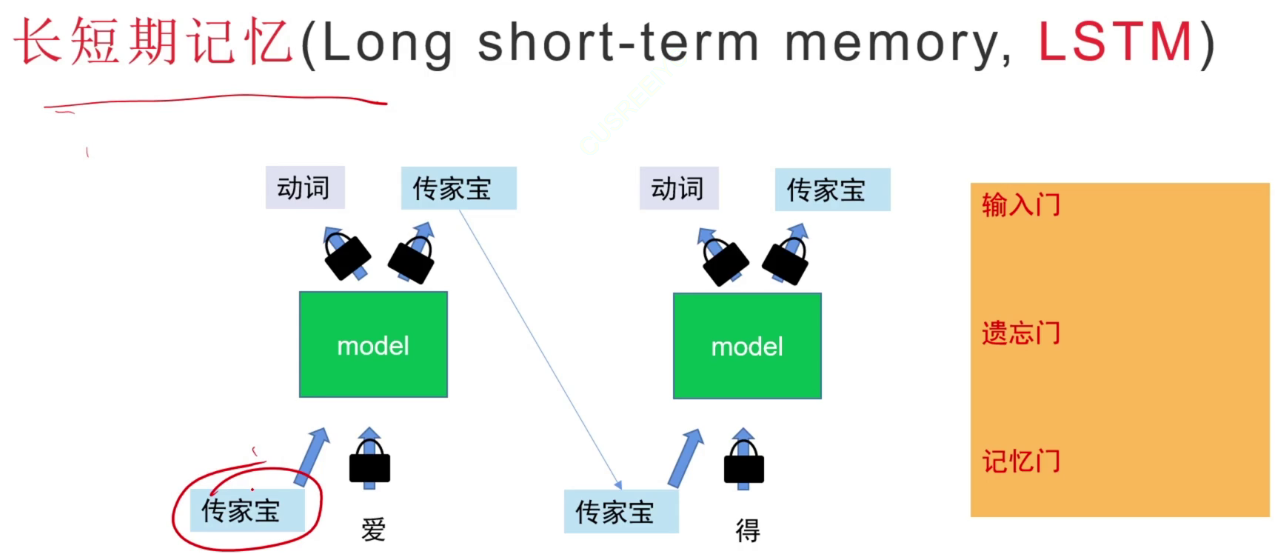
要防止不好的层将干扰内容放入“传家宝”记忆单元。

当上下文太长,要防止干扰,方案:给部分内容“加锁”,设置长短期记忆(LSTM),输入门、遗忘门、记忆门。
长短期记忆LSTM
RNN和LSTM只能串行不能并行。
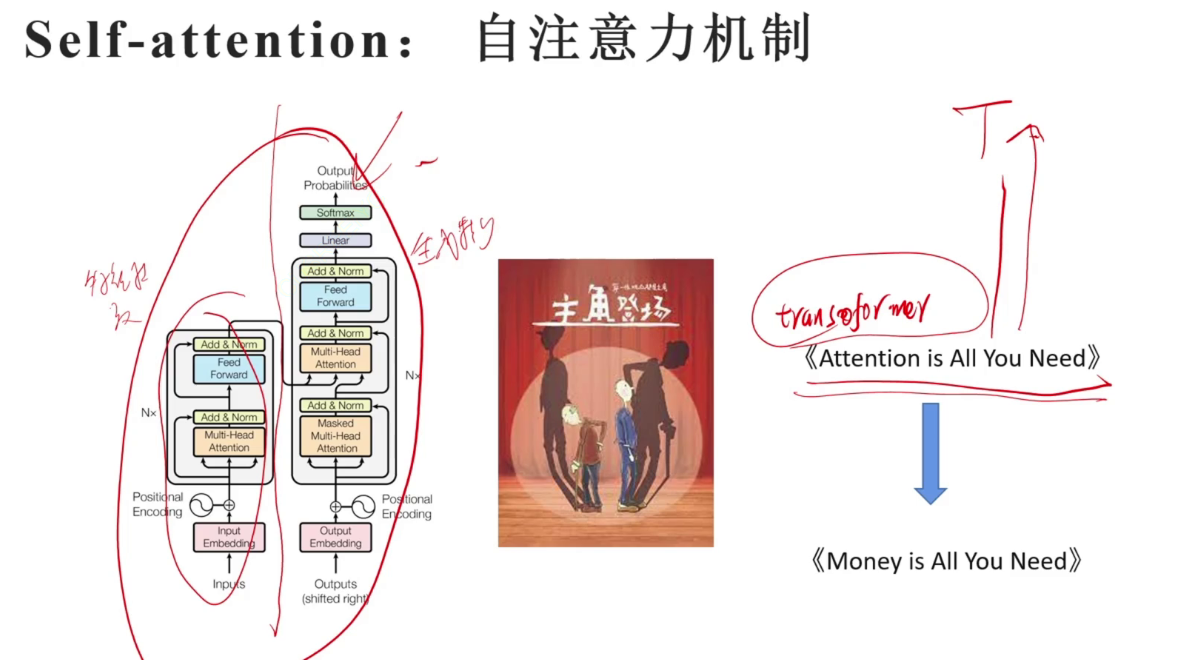
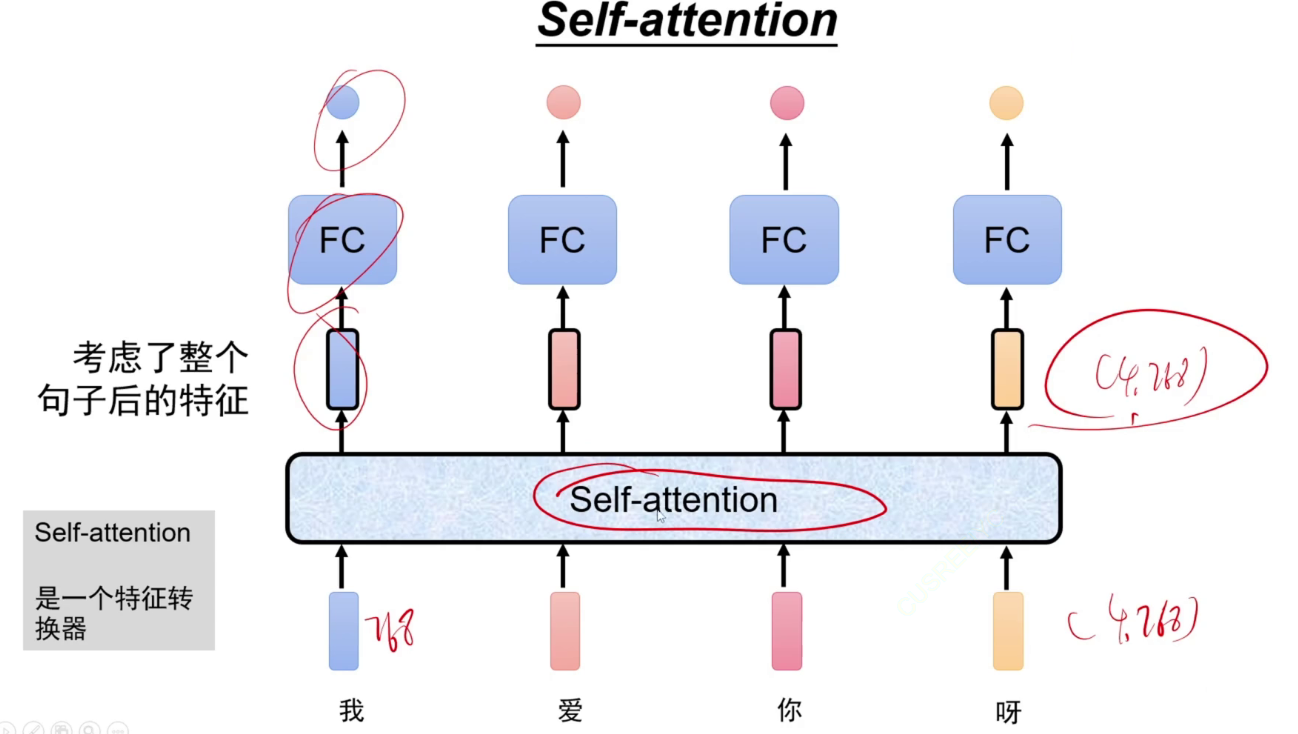
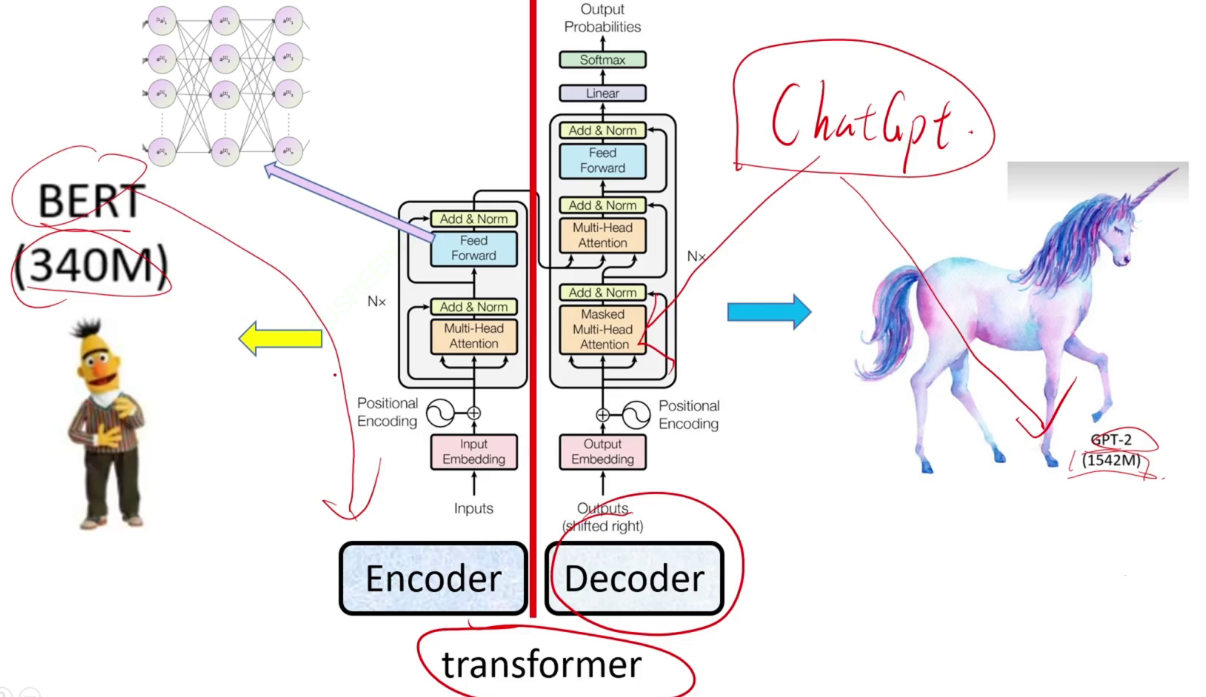
transformer,自注意力机制。左边为特征提取器,右边为生成模型。模型参数量急剧上升。
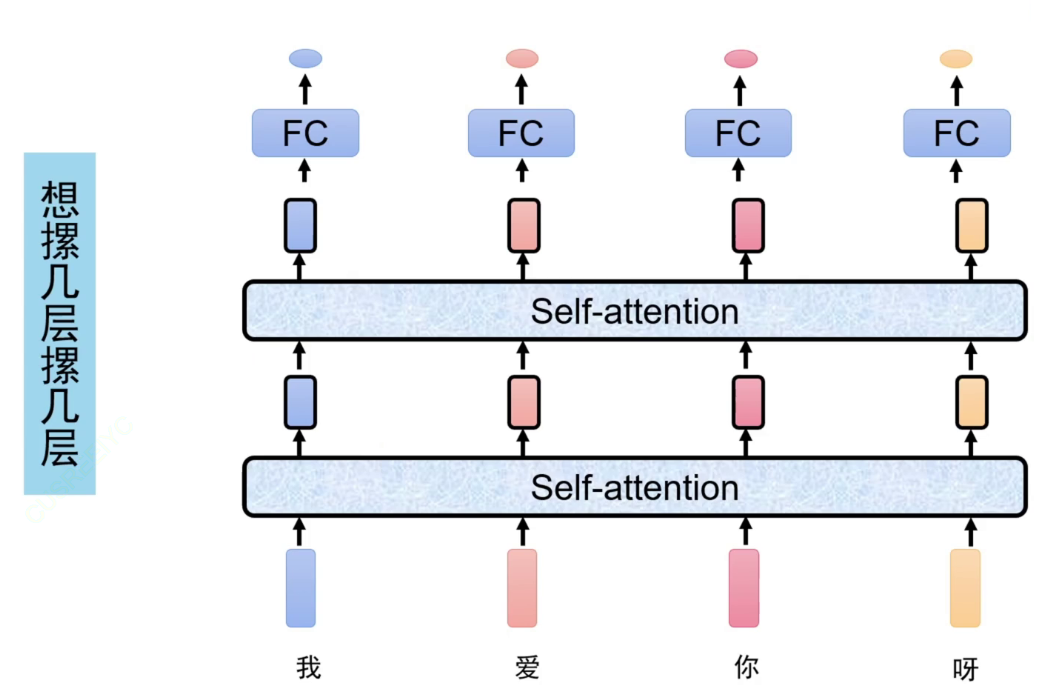
将一句话同时输入到self-attention模型中,每个特征都会得到一个输出特征,这个输出特征是考虑了整个句子的。
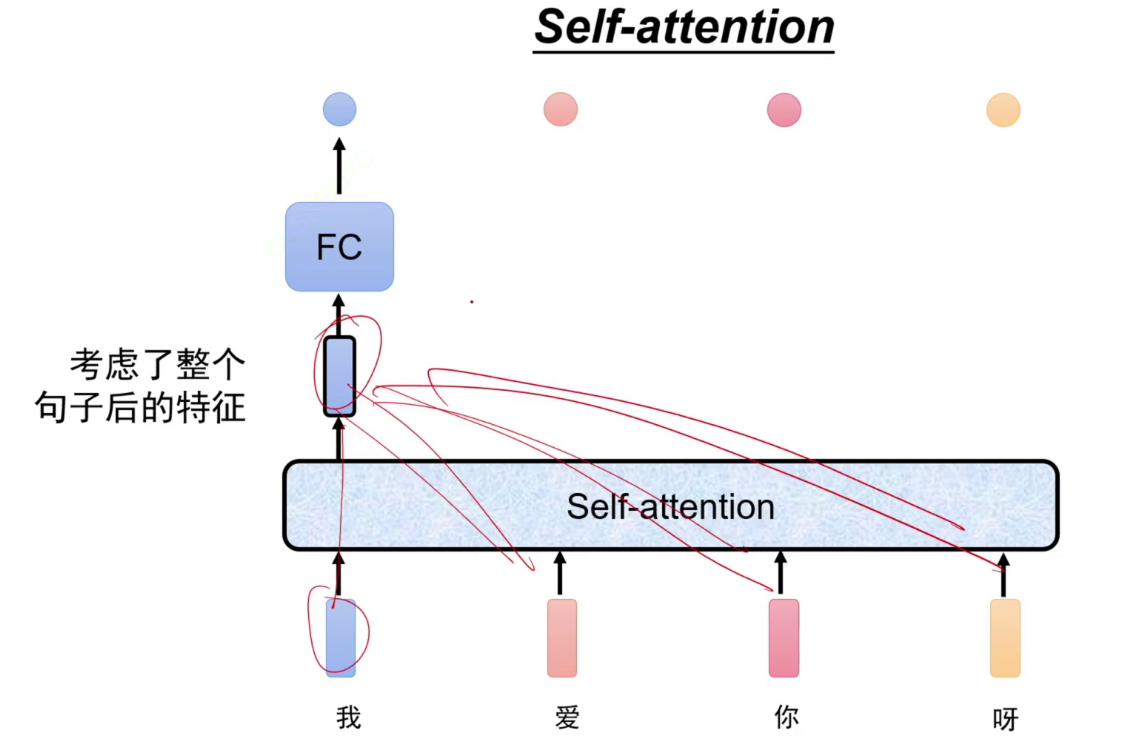
self-attention是一个特征转换器,不改变维度。
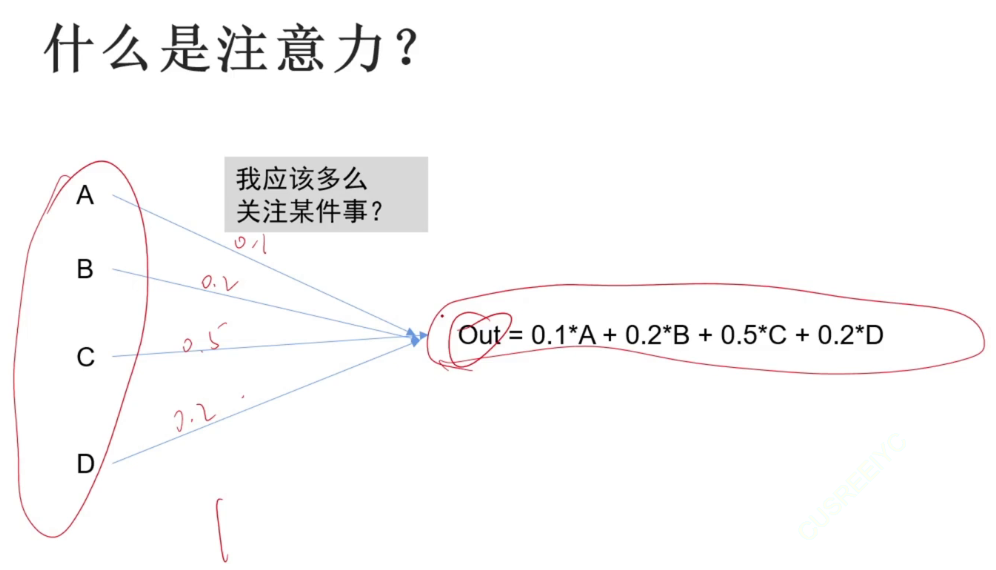
注意力:输出是综合了所有输入的加权值。相乘相加。
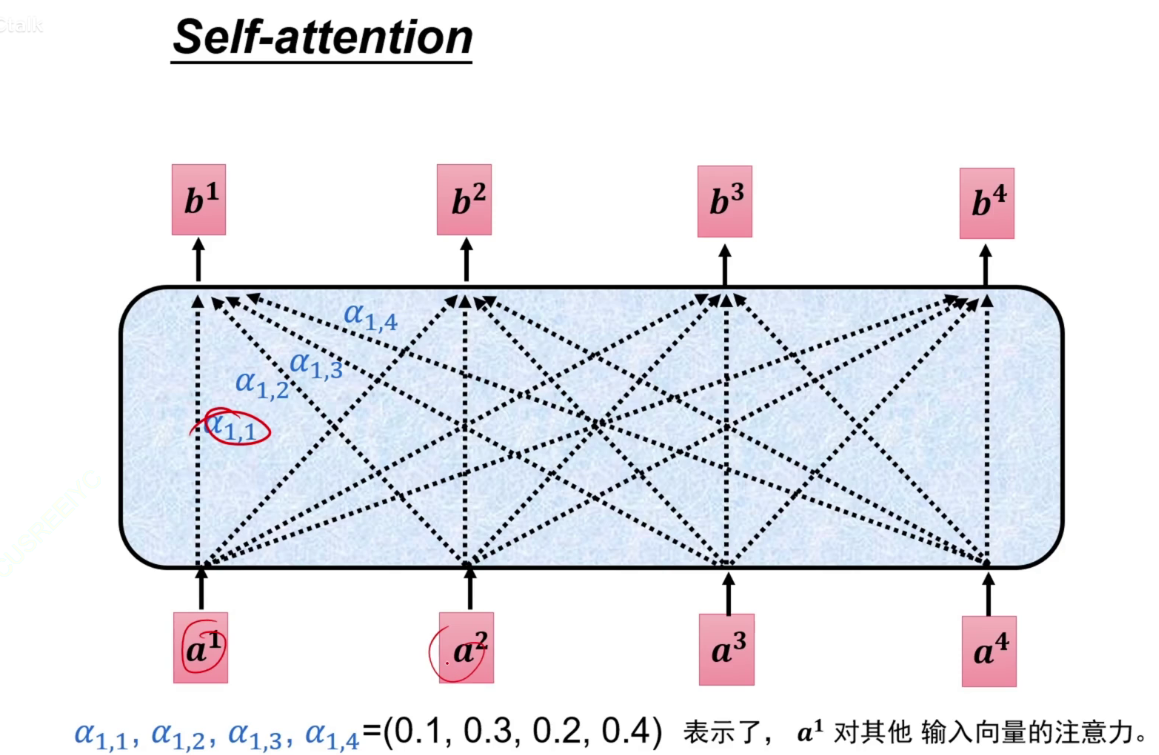
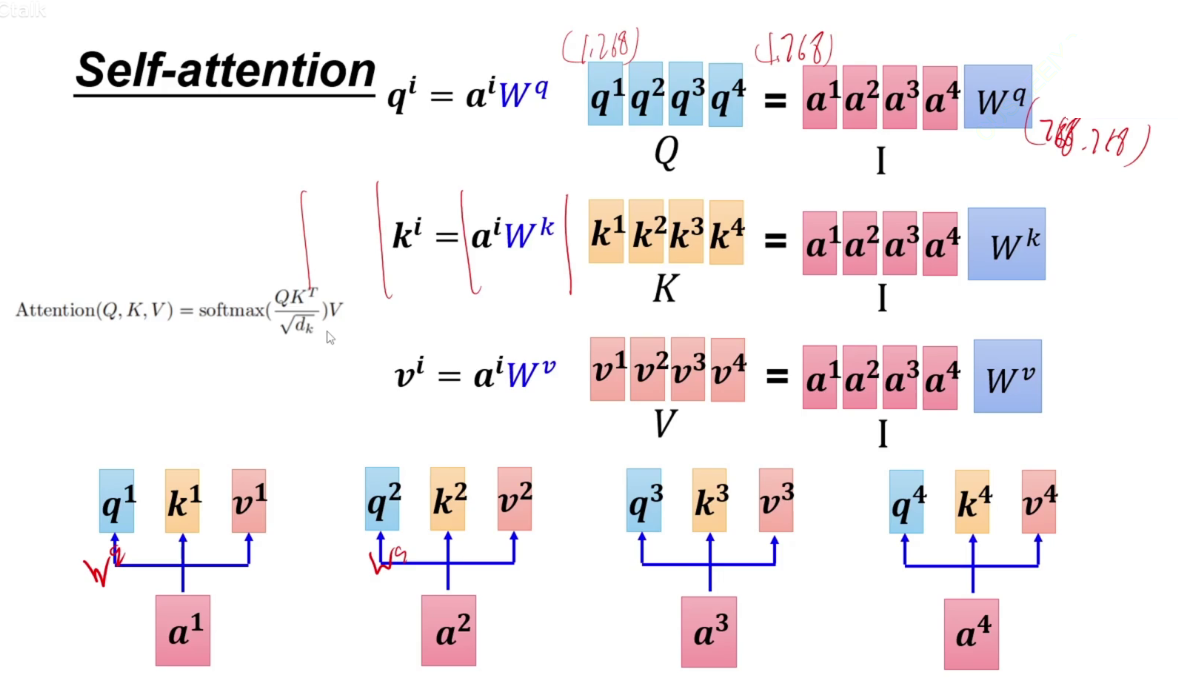
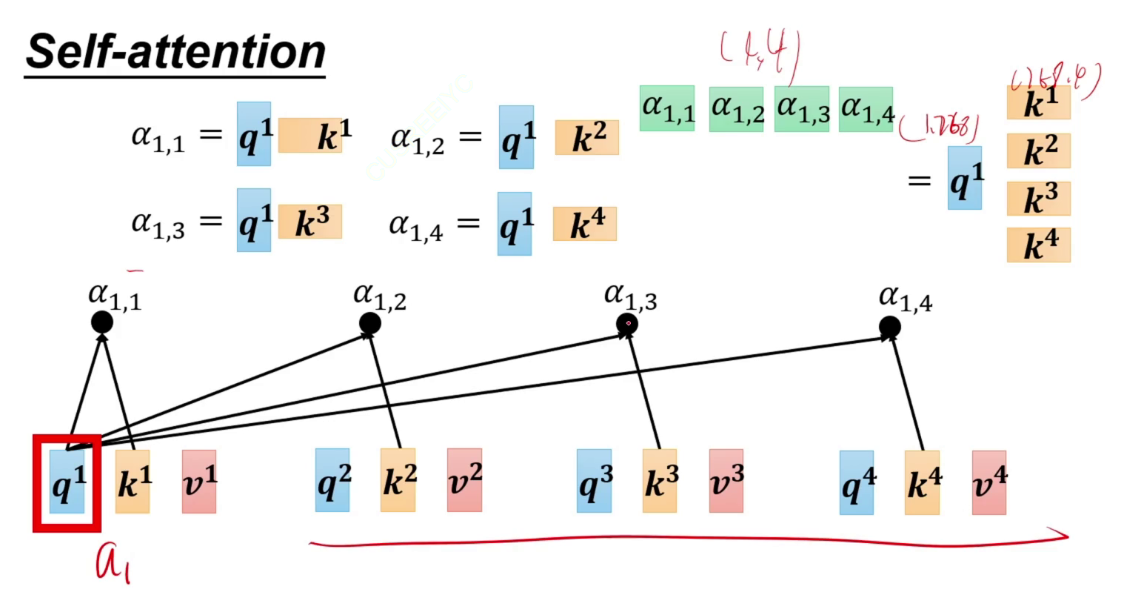
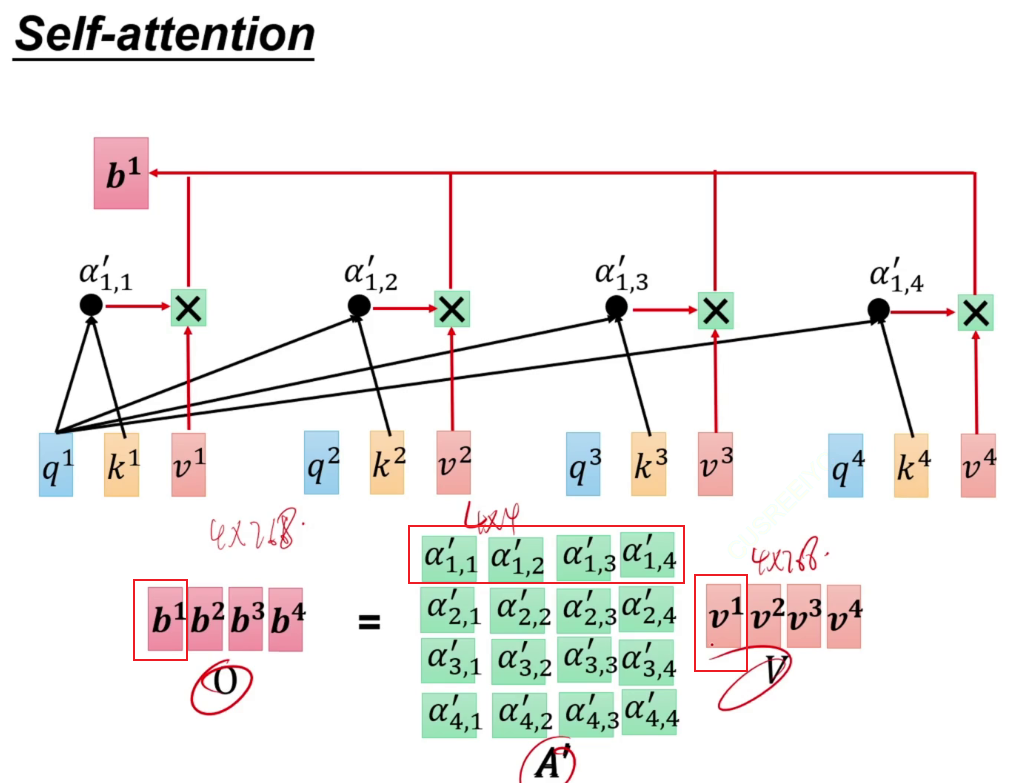
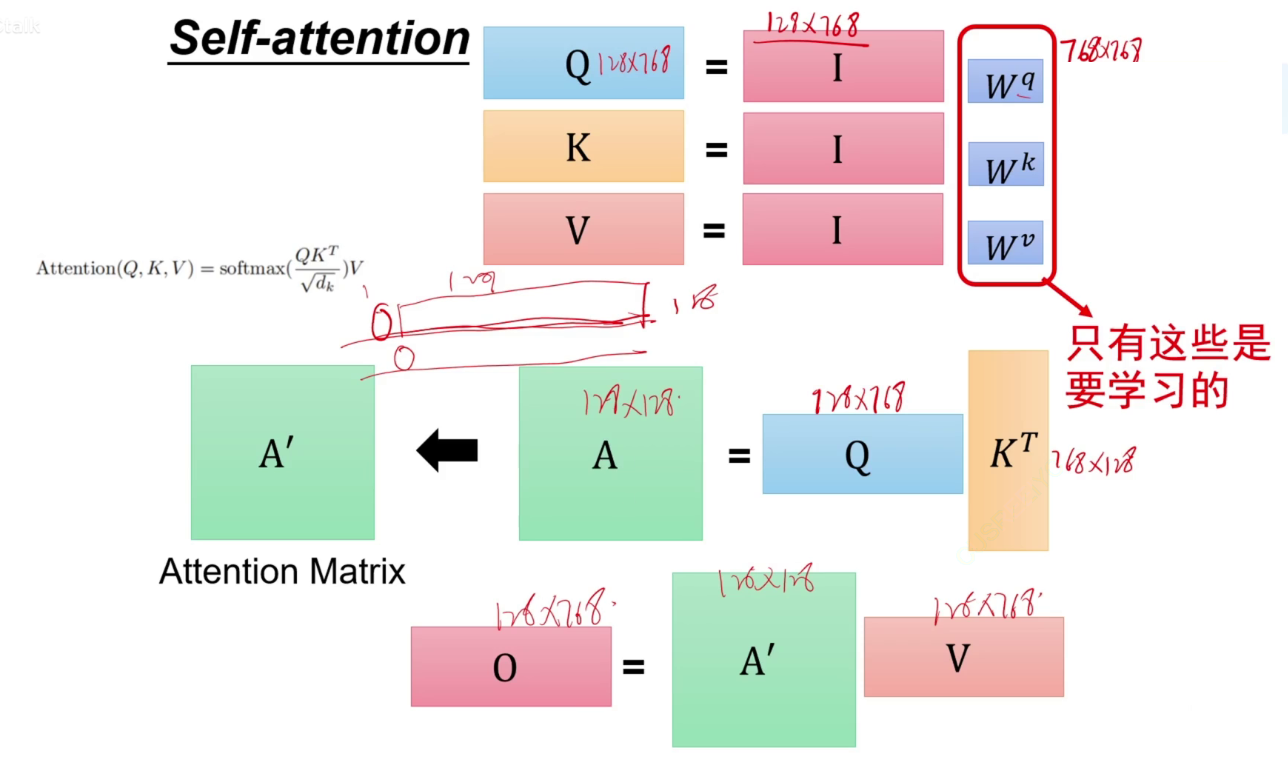
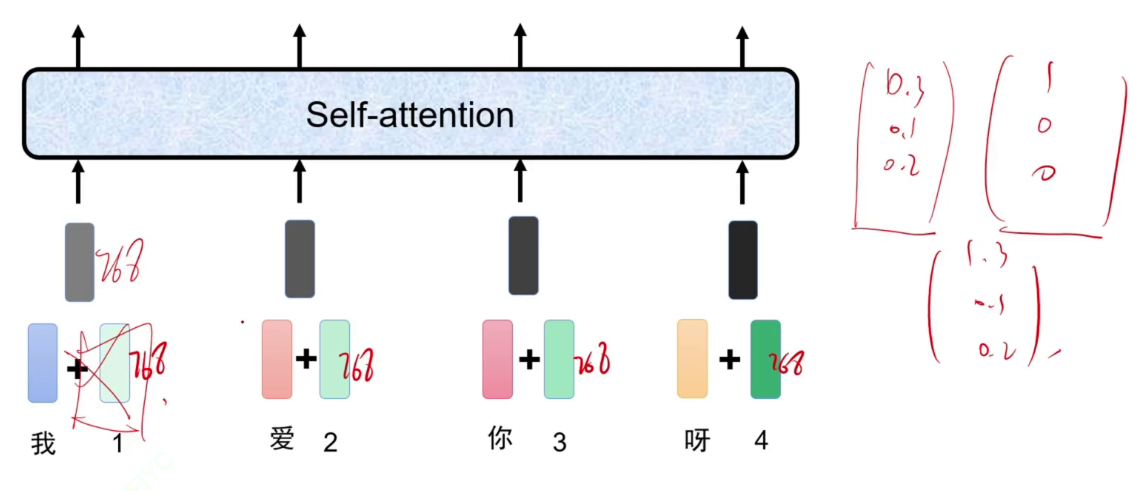
计算注意力,不能写死,让字通过一个矩阵,a1生成q a2生成k,a1生成q,表示a1对别人的注意力是多少,再与别人生成的k相乘(扫码),这样就知道a1要给a2分配多少注意力。



a1~a4通过各自的矩阵后得到a11,再通过softmax,得到和为1的注意力a'11~a'14。即a1应该分配给其他每一份多少的注意力。凭借此注意力将a1*a11~a1*a14加起来,得到输出b。

此时不直接用a1与a11相乘,而是乘以Wv矩阵得到v,再让算出来的a'11与v相乘。

输入输出维度未被改变,都是768维。
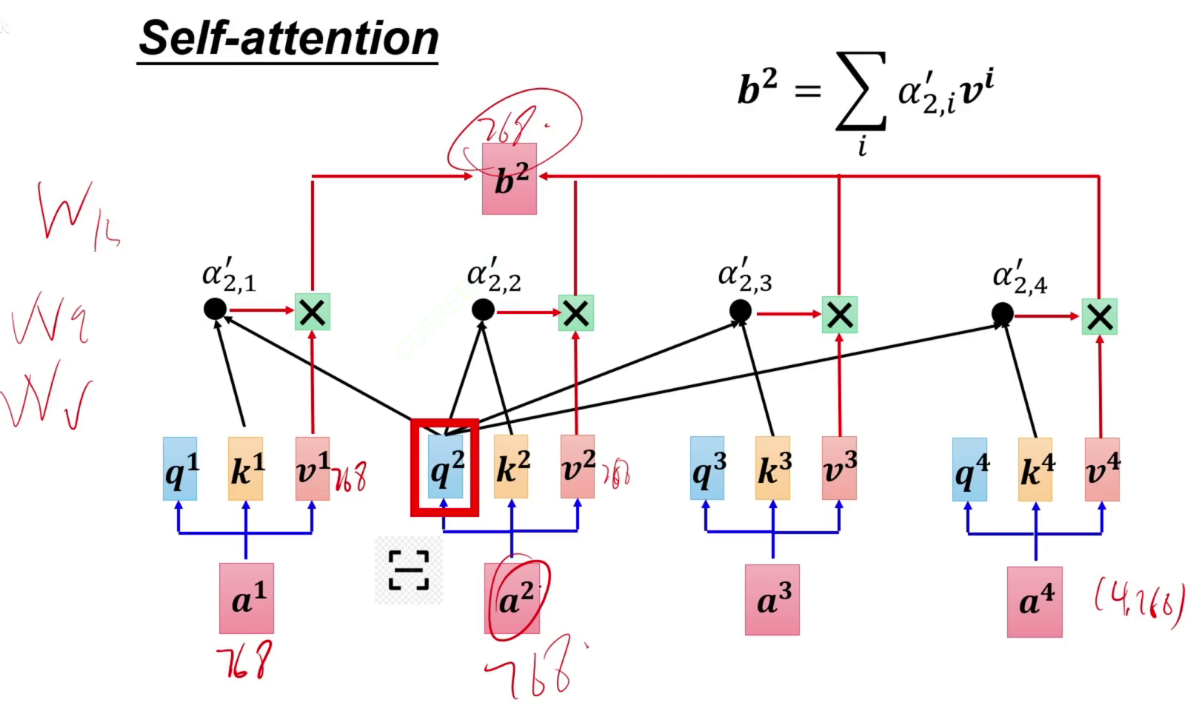
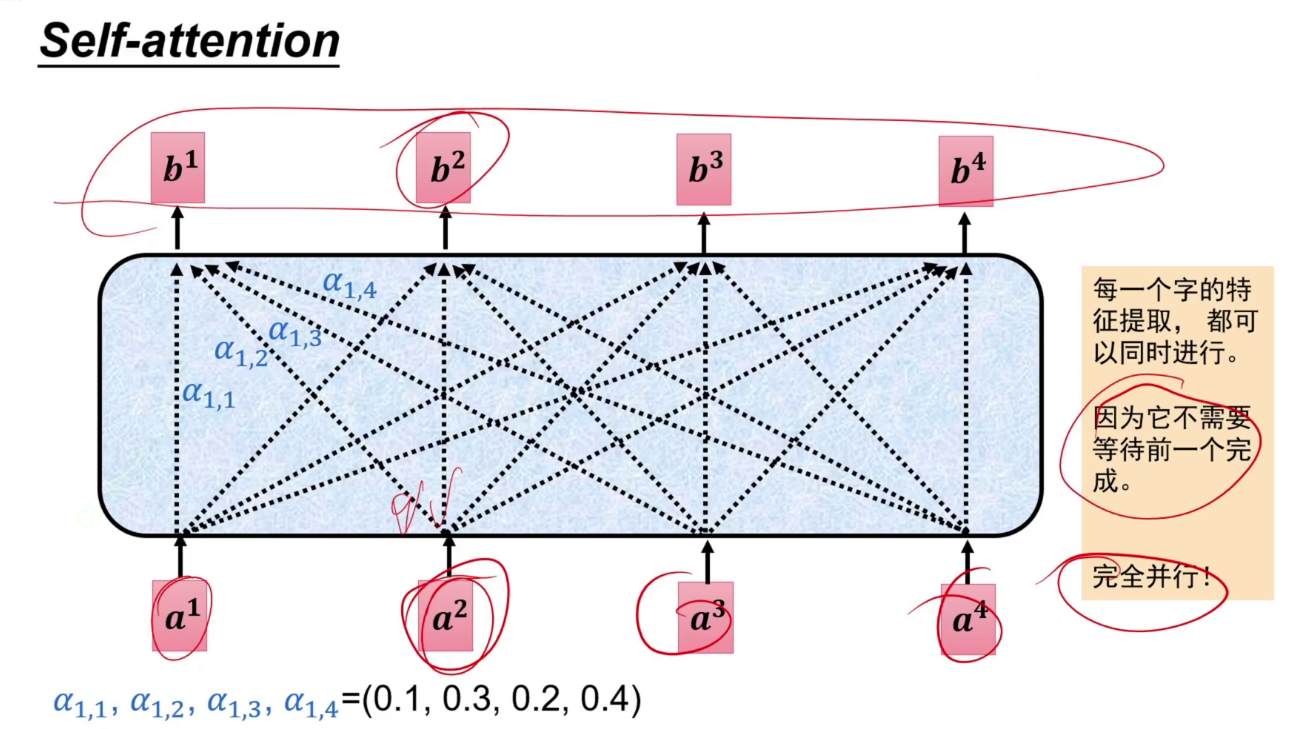
每个计算完全并行,比RNN和LSTM快。
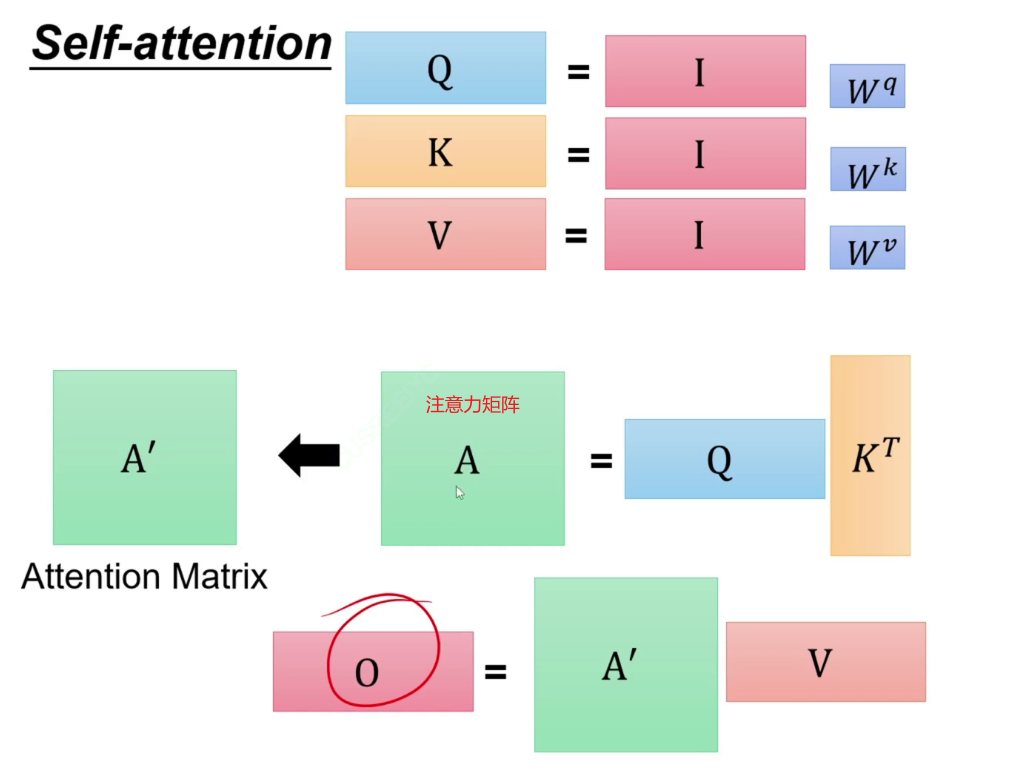
对输入I通过Wq矩阵进行linear得到Q矩阵。(1,768)*(768,768)=(1,768)。同样的方式得到K、V矩阵。
注意力:q1与k1做点乘,与其他3个做点乘,最后得到注意力矩阵,经过softmax。这个softmax是在a1生成的这一行注意力中进行的。
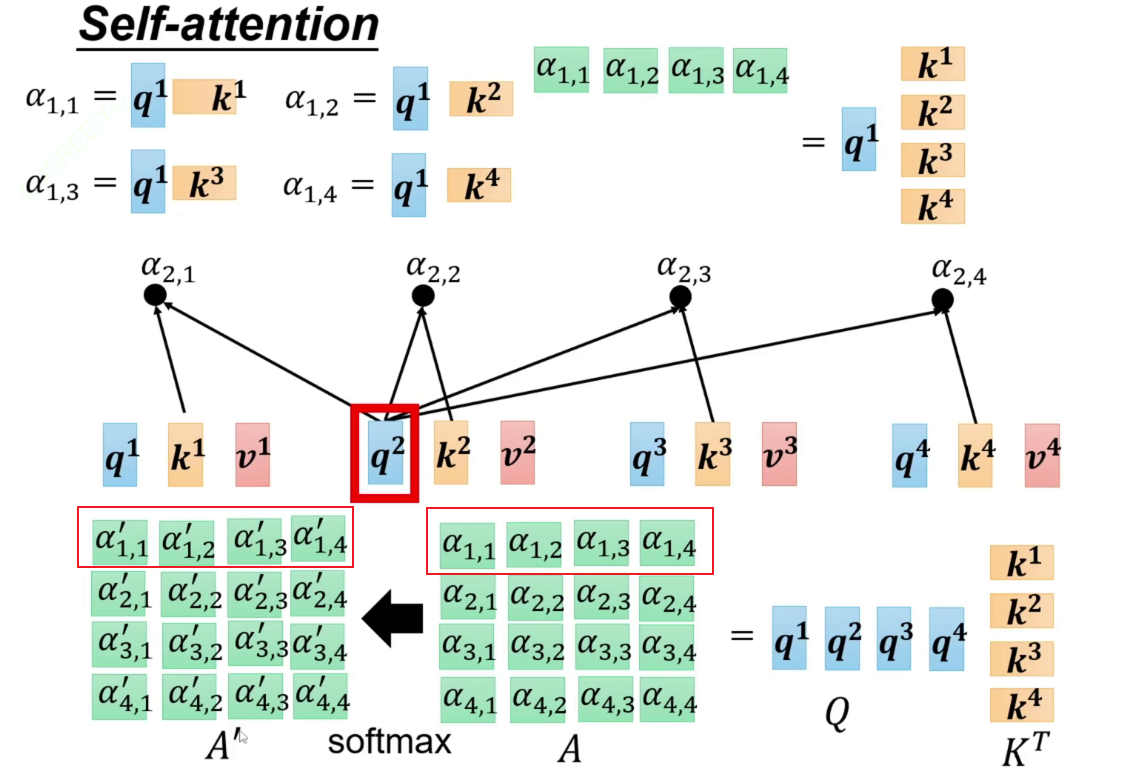
总过程。
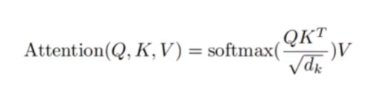
dk是归一化(除以维度的开根号)
这个过程中,只有QKV是需要学习的。
维度变化过程如下。说明自注意力没有改变维度。
位置信息
上述算法没有考虑位置,导致下面两种情况被判断为相同的值。
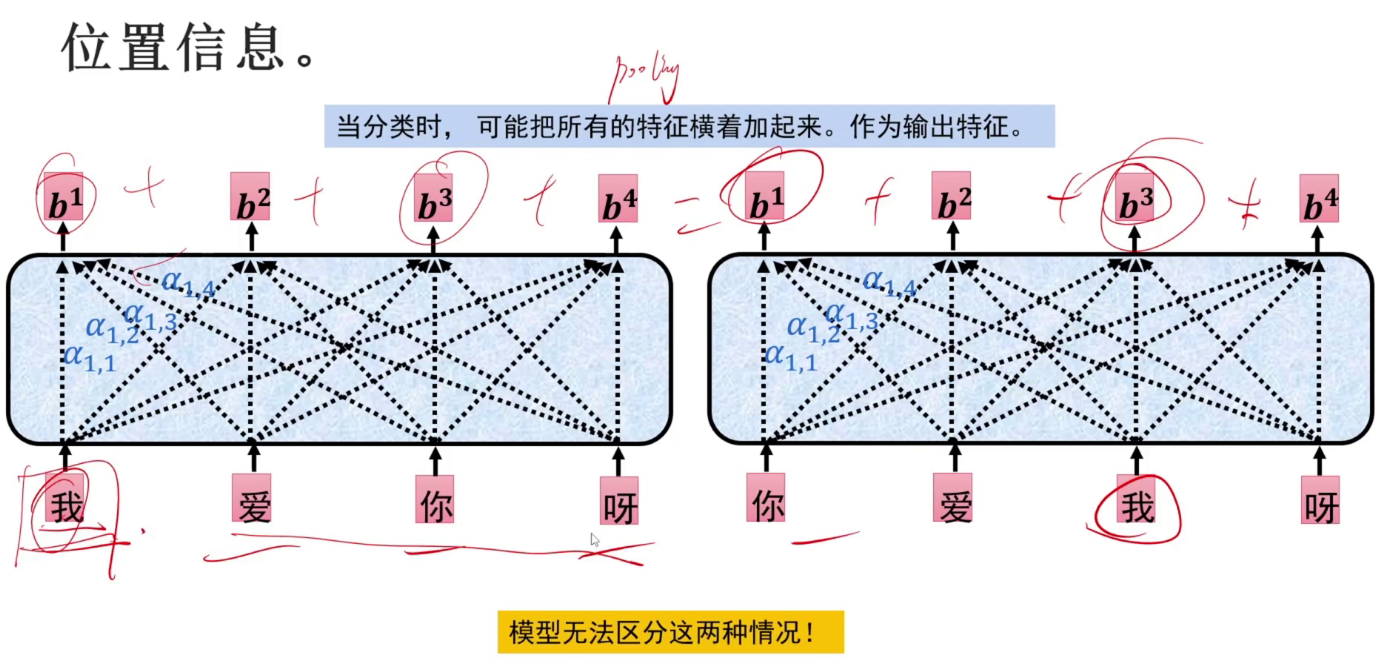
解决方案:加同样维度的位置参数。且算法为直接相加。
词编码得到的向量与位置编码(通过linear(512,768))得到的向量相加。
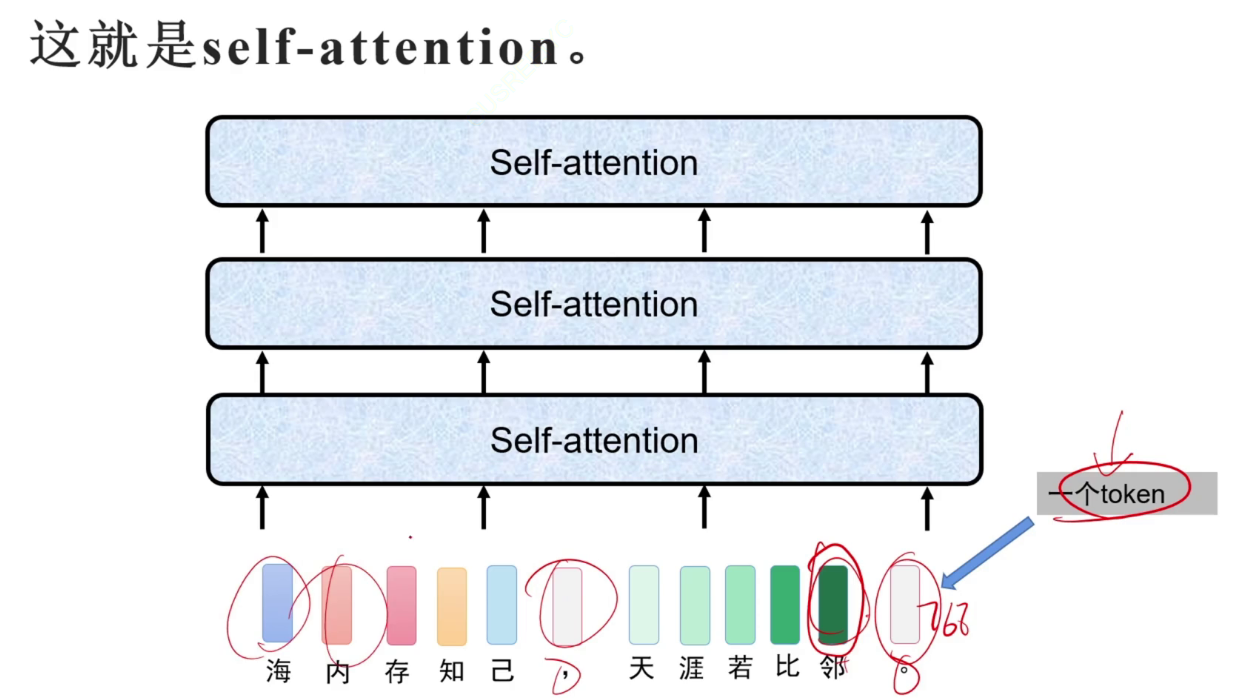
RNN不需要位置信息,是因为它就是一个位置一个位置地计算的。而self-attention是并行计算的。
transformer模型架构
看一个大模型的时候,最应该关注的是输入和输出(维度变化),不要迷失在过程中。
第一部分,输入字的one-hot coding,输出768维的向量。
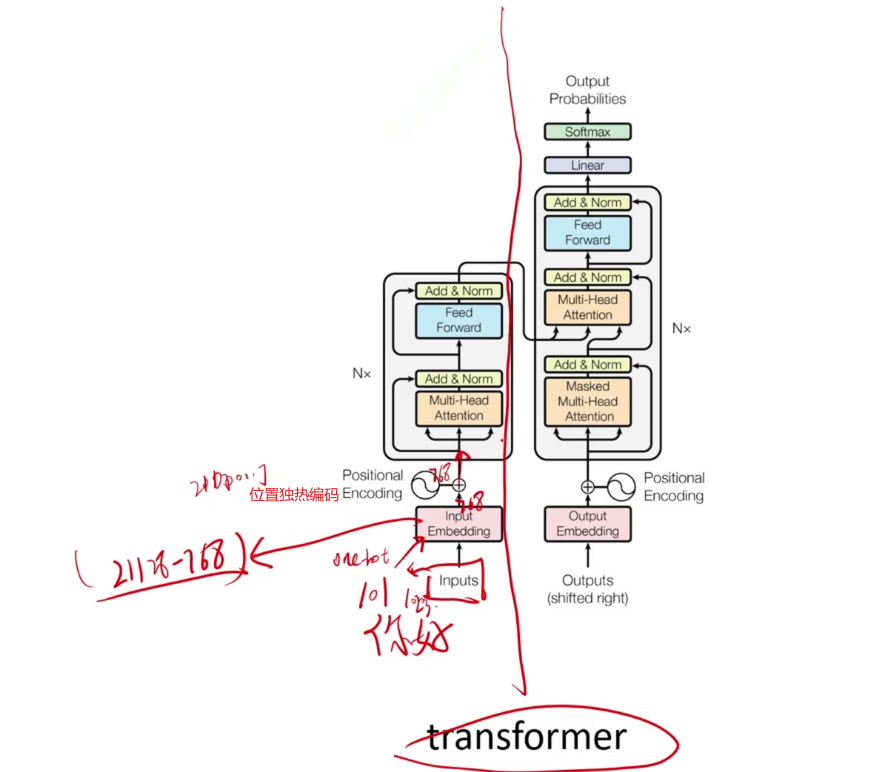
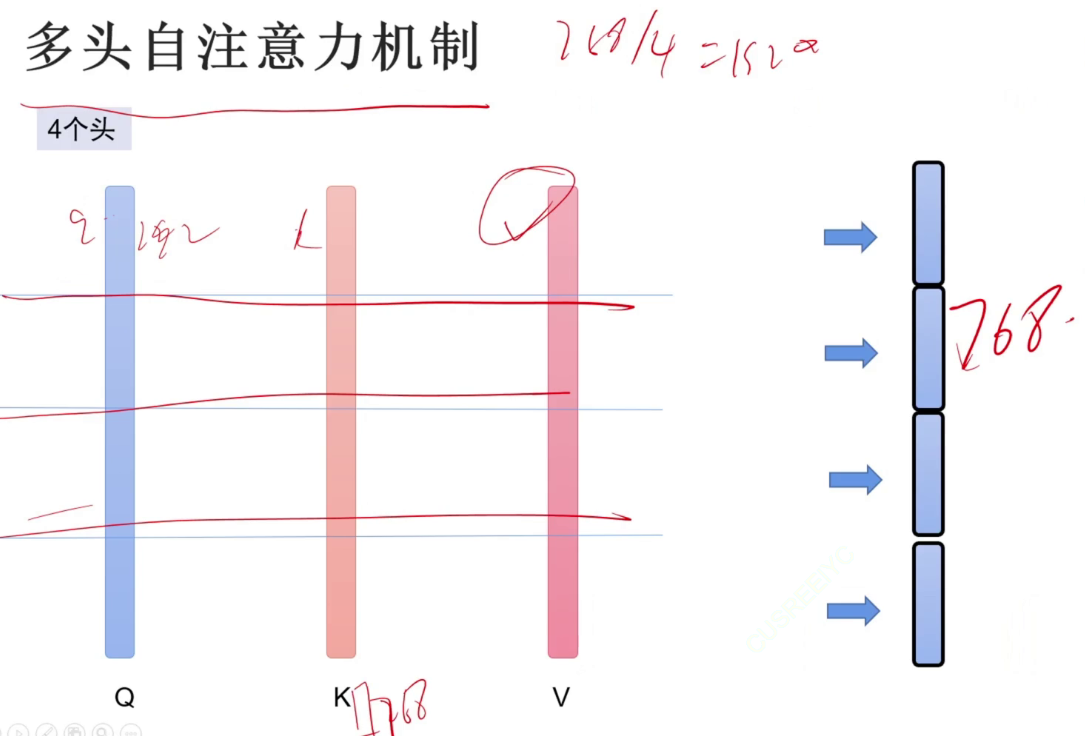
第二部分,768的向量通过多头注意力机制与Wq、Wk、Wv(都是768*768)相乘,得到768输出。
norm为归一化。
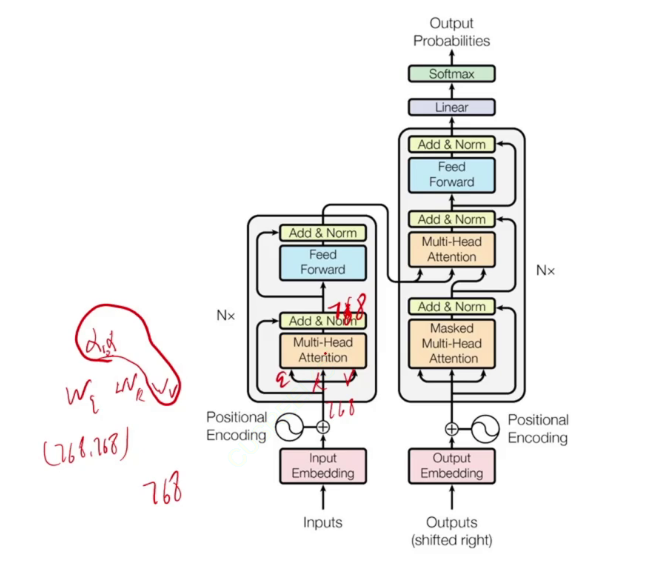
从输入连接到输出的,是resnet残差连接。
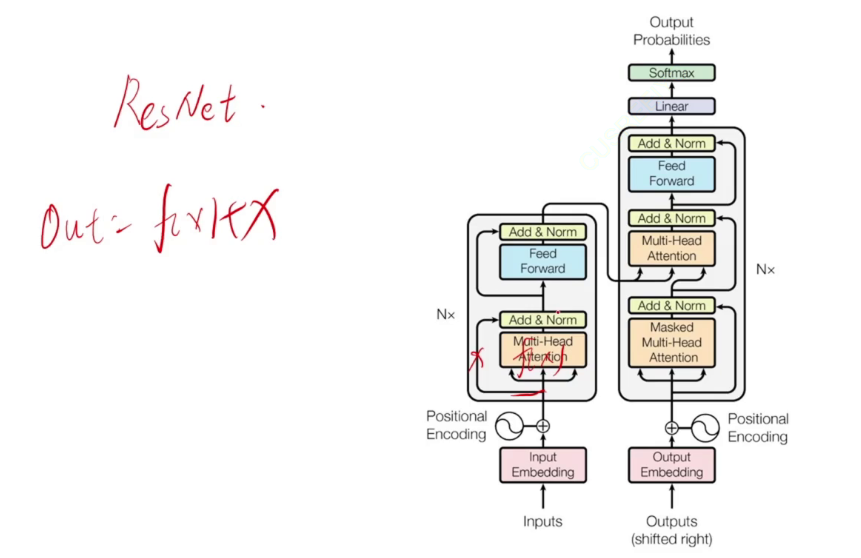
feed前向内为两个全连接,先升维再降维,再通过残差连接、归一化,得到768维。
MLP多层感知机(Multilayer Perceptron)。一种前馈人工神经网络。
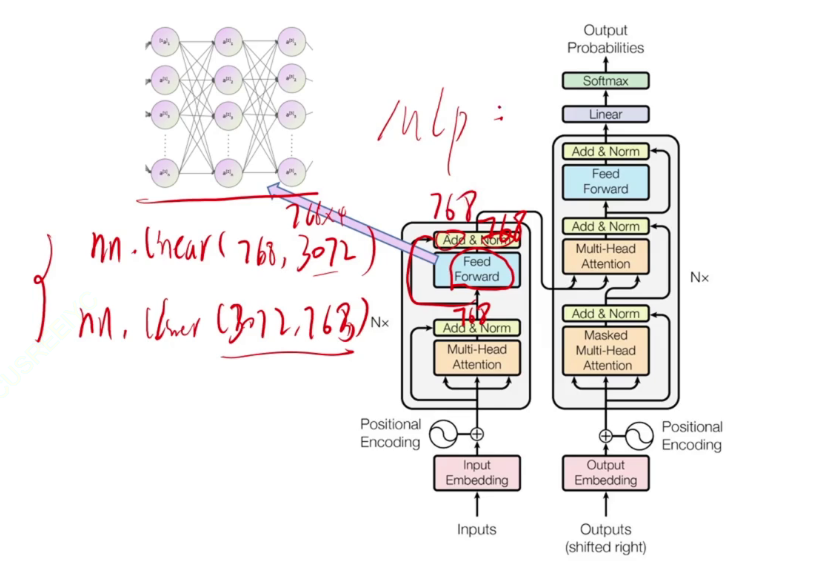
至此,左边的encoder编码器运行结束,768维的特征已提取出来。Nx表示重叠很多层。
右边的解码器通过左边的输出生成文本。
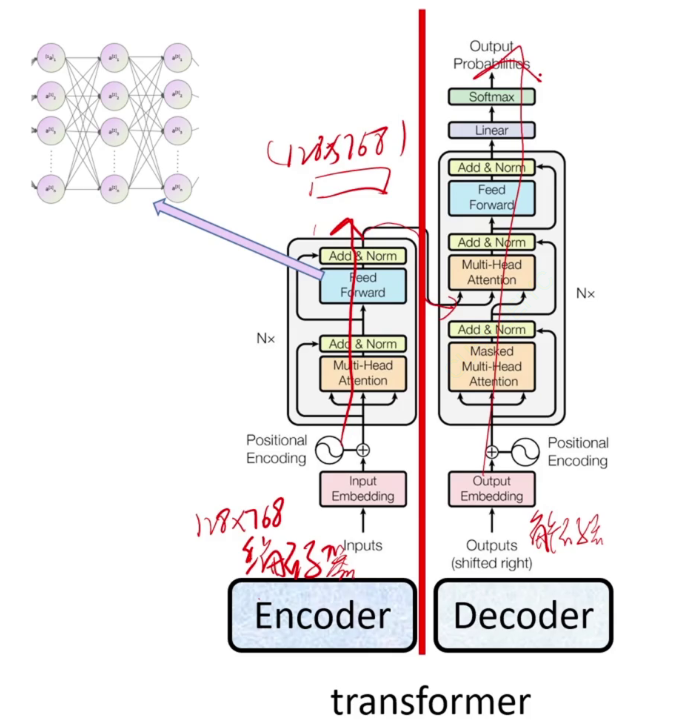
左右各自分开可以分别演化为文字处理的强大模型bert和生成模型GPT。1542M代表million百万级参数、
bert
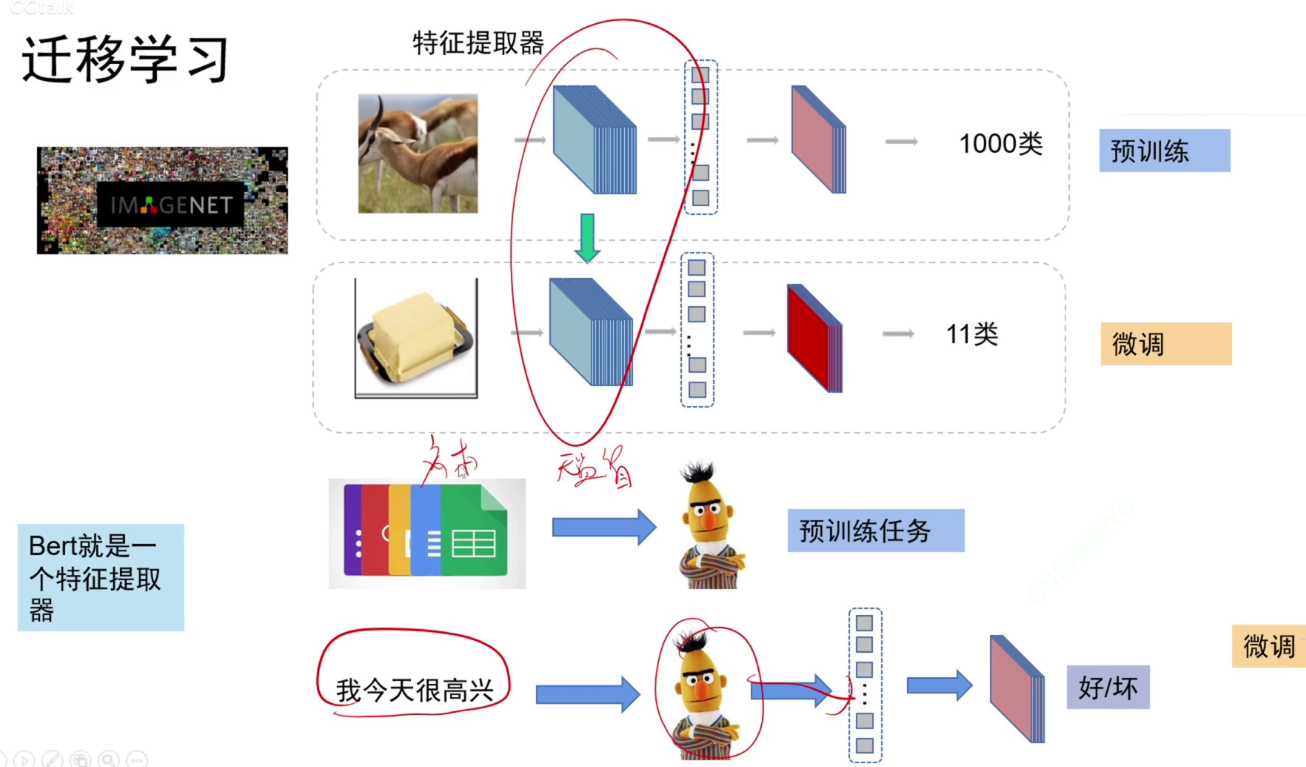
通过无监督进行训练的特征提取器,不需要人工标注数据,所以所有文本都可以用于训练。
提取特征后,加一个分类头即可做广泛使用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)