英伟达GTC 2026大会深度解读——Vera Rubin平台如何重塑AI算力格局
北京时间2026年3月17日凌晨,英伟达GTC 2026大会在加州圣何塞开幕。CEO黄仁勋发布了Vera Rubin下一代AI计算平台及Feynman架构原型。此次发布不仅展示了**300%**的性能代际提升,更标志着AI算力竞争从单一芯片性能比拼,转向全栈基础设施的系统级优化。
根据英伟达官方公告,Vera Rubin平台已全面投产,预计2026年下半年交付。黄仁勋预测,Blackwell与Rubin架构的综合采购订单将在2027年前达到1万亿美元规模——是去年预测的两倍,凸显AI基础设施投资加速态势。
本文基于今日实时热点挖掘与深度技术搜索,从技术架构、产业影响、竞争格局、趋势前瞻四个维度,系统解读Vera Rubin平台的技术突破及其对全球AI算力格局的重塑作用。
一、技术架构深度解析:六芯协同的全栈基础设施
1.1 Rubin GPU:50 PFLOPS推理算力的代际飞跃

Vera Rubin平台的核心是Rubin GPU,采用台积电3nm工艺,集成3360亿个晶体管,较Blackwell提升60%。关键性能指标:
- 推理算力:50 PFLOPS(FP4精度),是Blackwell的5倍
- 训练算力:35 PFLOPS,超出Blackwell 3.5倍
- 内存带宽:22TB/秒(HBM4),是HBM3e的2.8倍
根据英伟达技术博客,Rubin GPU采用第六代Tensor核心架构(NVFP4),支持动态精度调度,实现计算效率与精度的智能平衡。
1.2 Feynman架构:1.6nm制程的物理极限突破
英伟达提前两年披露Feynman架构原型,采用台积电A16(1.6nm)制程,成为全球首款迈入1nm时代的量产AI芯片。关键技术:
- 制程革命:晶体管密度提升1.1倍,进入原子级制造区间
- 背面供电:SuperPowerRail技术改善供电效率
- 3D堆叠LPU:语言处理单元直接集成在GPU核心之上
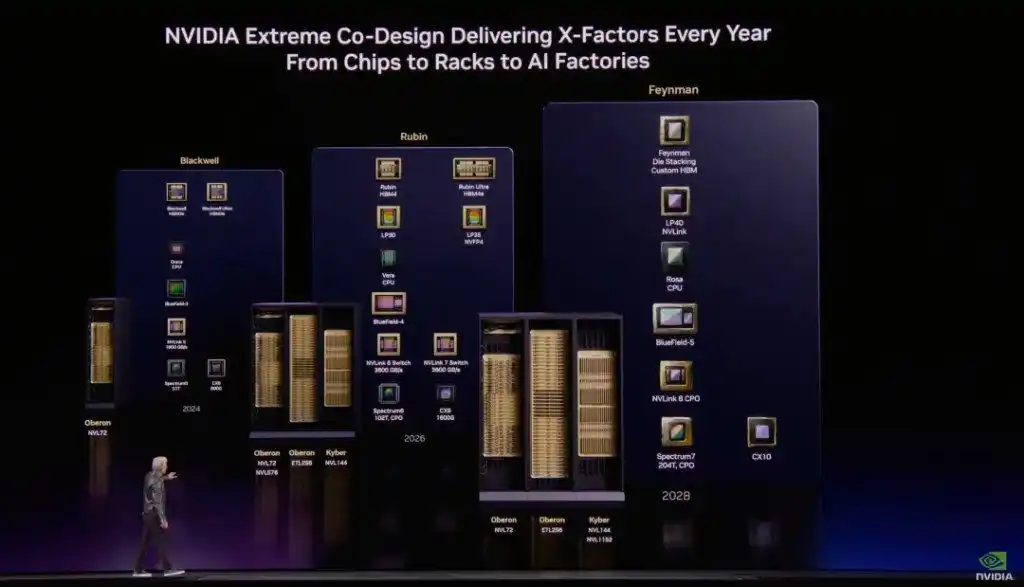
行业分析师指出,Feynman架构通过制程微缩、架构重构、LPU集成三大技术叠加,实现**300%**性能代际提升。
1.3 NVL72机架:260 TB/s互联带宽的集群革命
Vera Rubin NVL72系统整合72颗Rubin GPU与36颗Vera CPU,通过NVLink 6实现全连接拓扑:
- 单GPU带宽:3.6 TB/s(双向),是上一代2倍
- 机架总带宽:260 TB/s,超过整个互联网带宽总量
- NVLink-C2C:CPU与GPU间带宽1.8 TB/s,翻倍提升
根据NVIDIA NVLink技术白皮书,第六代NVLink交换机内置网络计算引擎,加速集合运算,适配混合专家模型(MoE)通信密集型场景。
1.4 BlueField-4 STX:AI原生存储架构的5倍吞吐量提升
针对智能体AI长上下文推理需求,英伟达推出BlueField-4 STX存储架构:
- 吞吐量提升:每秒Token处理量提升5倍
- 能效优化:比传统CPU架构高出4倍
- 数据摄取速度:每秒页面处理量实现翻倍
技术专家分析,STX架构集成了专为存储优化的BlueField-4处理器,配合Spectrum-X以太网和DOCA软件,形成端到端加速方案。
二、产业影响评估:AI算力市场的格局重塑
2.1 成本拐点:训练与推理成本的数量级下降
Vera Rubin平台带来AI计算成本断崖式下降:
- 训练成本:训练GPT-4级别模型成本较2023年下降87%
- MoE训练效率:仅需1/4的GPU数量
- 单Token成本:降至Blackwell平台的1/10
财务分析师测算,10万张GPU的AI工厂年电费约3亿美元,采用Feynman架构可节省1.5亿美元以上。
2.2 云巨头竞赛:270亿美元基础设施投资加速
英伟达技术突破触发云服务商军备竞赛:
- Meta与Nebius:签署五年270亿美元AI基础设施协议
- 微软承诺:部署Vera Rubin NVL72系统用于Fairwater AI超级工厂
- 首批部署:AWS、谷歌云、Azure、甲骨文云等
行业观察家指出,这些投资反映了企业对AI算力长期需求的确定性判断。
2.3 硬件产业链:五大环节确定性受益
Rubin与Feynman技术突破带动产业链升级:
| 产业链环节 | 核心受益点 | 预计增长 |
|---|---|---|
| AI服务器整机 | 2000W+功耗推动重构,单机柜价值量提升60%+ | 2026年收入占比超50% |
| 高速光模块 | NVLink6带宽翻倍驱动800G/1.6T放量 | CPO渗透率2030年达35% |
| 液冷散热设备 | 液冷从可选变刚需 | 2026年订单增长250% |
| 先进封装与HBM | HBM4带宽提升46% | 全球市场规模超600亿美元 |
| 高端PCB与覆铜板 | 78层PCB设计推升单价 | 出货量增长120% |
2.4 应用场景扩展:从云端到终端的全场景覆盖
LPU架构推动AI推理从云端向终端延伸:
- 智能手机:离线实时语音翻译与智能创作
- 智能汽车:决策响应时间从0.5ms缩短至0.1ms
- 工业设备:终端推理实现实时故障预警
根据Gartner预测,2030年终端侧AI推理算力占比将从20%提升至80%。
三、全球竞争格局分析:地缘技术博弈的新维度
3.1 美国:技术领先优势与出口管制双重策略
英伟达技术突破发生在美国商务部强化AI芯片出口管制背景下:
- 管制动态:3月13日撤回拟议新规,维持高性能AI芯片全球许可制
- 技术领先:Feynman架构1.6nm制程领先AMD至少一代半
- 产能独占:成为台积电A16节点初期“第一位客户,可能也是唯一客户”
3.2 欧盟:监管先行与产业追赶的平衡挑战
欧盟AI法案实施一周年,面临产业竞争力挑战:
- 分级监管:根据风险等级分级管理,高风险应用需严格合规
- 合规成本:中国企业出海欧盟AI合规成本激增45%
- 产业差距:在AI芯片制造领域仍显著落后,依赖进口
3.3 中国:自主创新与国产替代的加速推进
在“人工智能+”行动方案推动下加速自主创新:
- 政策目标:到2027年形成具有国际竞争力的AI产业集群
- 技术路线:聚焦国产AI芯片自主可控、算法框架开源生态
- 产业进展:华为昇腾、寒武纪等国产芯片实现规模化部署
3.4 供应链安全:重构风险与国产替代机遇
Vera Rubin平台量产凸显全球AI供应链重构:
- 产能集中:台积电高雄工厂优先保障英伟达产能,形成壁垒
- 技术依赖:全球AI实验室高度依赖英伟达算力
- 替代窗口:国产供应链在封装测试、PCB制造等环节加速突破
四、技术趋势前瞻:AI算力发展的三大方向
4.1 能效优先:从算力堆砌到系统优化的范式转移
Vera Rubin平台标志AI算力进入“能效优先”时代:
- 每瓦性能:每瓦推理吞吐量提升10倍
- 散热革命:100%液冷设计将PUE逼近1.1
- 成本效益:单Token成本降至1/10
4.2 智能体基础设施:从模型训练到代理推理的架构演进
GTC 2026核心叙事是AI从工具向“智能体”范式转移:
- NemoClaw平台:开源AI智能体操作系统,支持一键部署
- 上下文内存存储:CMX平台为长上下文推理提供硬件加速
- 专用处理器:Vera CPU专为智能体推理优化
4.3 端云协同架构:从集中式计算到分布式智能的体系重构
Feynman架构推动AI计算从云端向终端延伸:
- 边缘推理:LPU边缘版本功耗降至传统芯片1/10
- 实时响应:延迟降低40%-85%,适配自动驾驶等场景
- 数据隐私:本地化处理降低数据上云风险
结论:AI算力格局进入系统性重构周期
英伟达GTC 2026大会的发布,不仅展示了300%的性能代际提升,更标志着全球AI算力竞争进入系统性重构周期。Vera Rubin平台通过六芯协同的全栈设计,实现了从芯片性能到系统能效的范式转移;Feynman架构的1.6nm制程突破,为AI算力发展开辟了新物理空间。
从产业影响看,训练成本87%的下降与单Token成本90%的降低,将推动AI应用从科技巨头专属走向中小企业普惠;云巨头270亿美元的基础设施投资,揭示了算力军备竞赛的加速态势。
在全球竞争维度,美国的技术领先优势扩大,欧盟的监管框架面临产业竞争力挑战,中国的自主创新进程加速。供应链安全成为各国AI战略核心关切。
展望未来,AI算力发展将沿着能效优先、智能体基础设施、端云协同架构三大方向演进。对于技术从业者、产业投资者、政策制定者而言,理解这一系统性重构的逻辑与路径,将是把握AI时代机遇的关键。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)